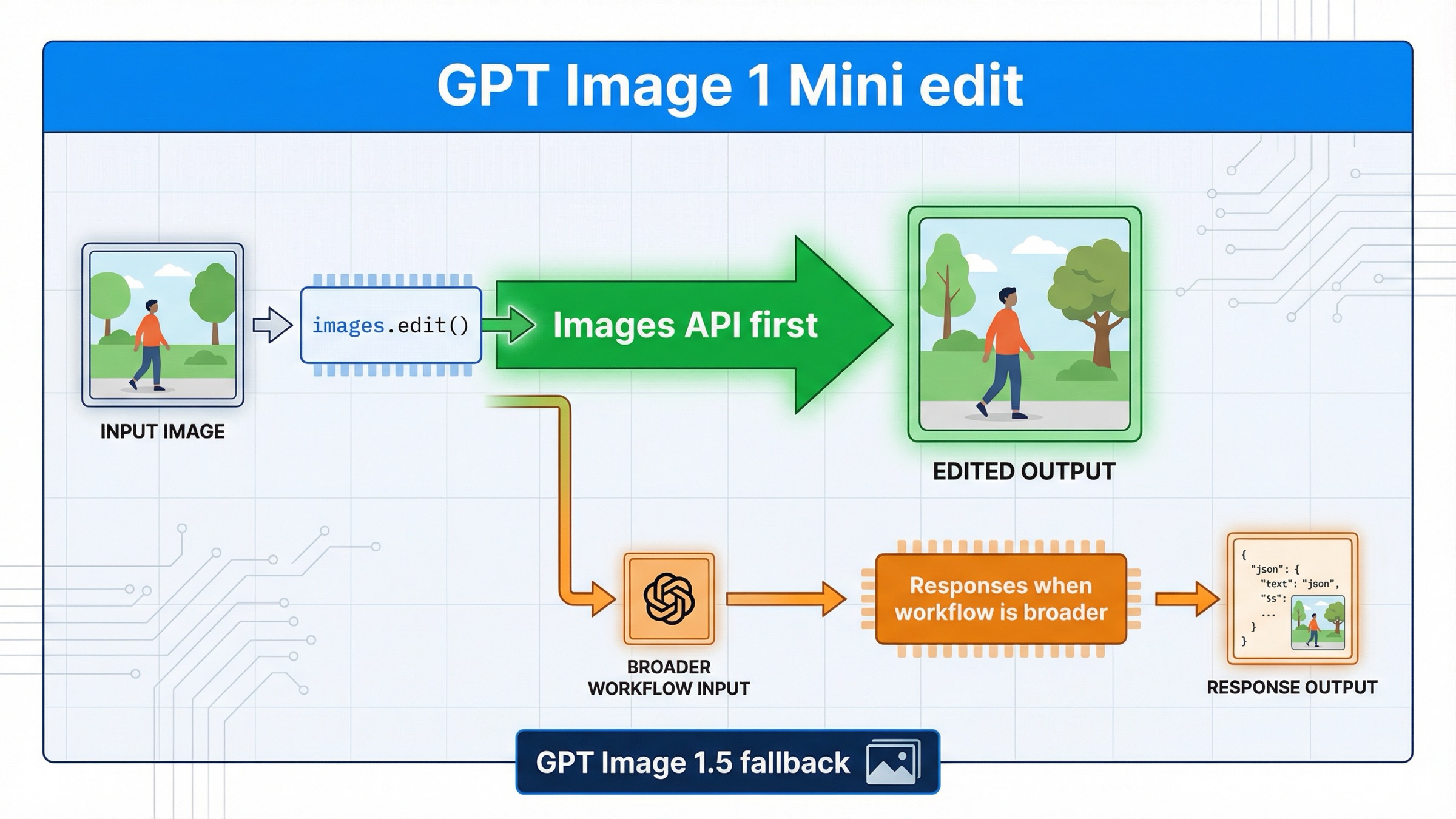
Si el 29 de marzo de 2026 quieres editar una imagen con gpt-image-1-mini, la ruta más segura no es Responses sino el Images API directo: client.images.edit() en el SDK o POST /v1/images/edits en HTTP puro. Solo tiene sentido pensar primero en Responses cuando la edición de imagen no es toda la función, sino un paso dentro de un assistant, una conversación o un workflow multimodal más amplio.
Este matiz merece una página propia porque la respuesta actual está repartida entre varias páginas oficiales y una SERP bastante irregular. La gpt-image-1-mini model page lista de forma explícita v1/images/edits. La image generation guide explica que, si solo necesitas una generación o una edición a partir de un prompt, Image API es la mejor elección. Y la image generation tool guide documenta el action del lado de Responses sobre todo para gpt-image-1.5 y chatgpt-image-latest, no como contrato principal para mini. Juntas, esas tres piezas dejan una regla más útil que la mayoría de resultados actuales: si tu trabajo es mini edit directo, empieza por /v1/images/edits.
Ese orden también te ahorra una clase de errores bastante común. Mucha gente ve antes un ejemplo de Responses y asume que, por parecer más moderno o más general, también será el mejor punto de partida. En gpt-image-1-mini suele ocurrir lo contrario: la ruta directa encaja mejor con la documentación, reduce la superficie de depuración y hace más visibles los límites reales de mini.
Resumen rápido
- Si tu tarea es simplemente "editar esta imagen", empieza con
client.images.edit()oPOST /v1/images/edits. - Si la edición es solo una parte de un assistant o un workflow multimodal, entonces valora Responses.
- Si necesitas mayor fidelidad con varias imágenes, mejor preservación o una ruta claramente orientada a calidad, compara pronto con GPT Image 1.5.
- Antes de reescribir código, confirma tier de pago, verification de la organización, project y API key.
| Situación | Mejor punto de partida | Por qué |
|---|---|---|
| Editar una o varias imágenes y guardar el resultado | images.edit() | Es la ruta más directa y más claramente documentada para mini |
| Editar con mask o reference images en la misma llamada | images.edit() | La subida de archivos, el mask y la salida son más claros en la ruta directa |
| La edición es solo un paso dentro de un workflow más grande | Responses | Lo que manda ya no es la edición, sino la orquestación exterior |
| Necesitas conservar mejor varios inputs o elementos de marca | GPT Image 1.5 + images.edit() | OpenAI coloca 1.5 como la rama quality-first |
Para mini edit directo, empieza por /v1/images/edits
En esta búsqueda, lo más valioso no es una teoría complicada de APIs, sino una primera ruta de éxito pequeña y fácil de comprobar. Aquí la documentación oficial no deja demasiado margen a la interpretación: la página del modelo mini lista v1/images/edits, y la guía de imágenes dice que, si solo necesitas una generación o una edición a partir de un prompt, Image API es el mejor camino. Eso coincide con la mayoría de trabajos reales detrás de "gpt-image-1-mini edit".
Por eso tu primer objetivo debería ser deliberadamente aburrido:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1-mini", image: [fs.createReadStream("room.png")], prompt: "Replace the blank wall art with a framed abstract poster. Preserve the room layout, lighting, furniture, and camera angle. Do not change anything else.", input_fidelity: "high", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync("room-edited.jpg", Buffer.from(imageBase64, "base64"));
Si estás depurando con HTTP puro, recuerda además que este endpoint usa multipart form-data, no JSON:
bashcurl https://api.openai.com/v1/images/edits \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1-mini" \ -F "image[]=@room.png" \ -F 'prompt=Replace the blank wall art with a framed abstract poster. Preserve the room layout, lighting, furniture, and camera angle. Do not change anything else.' \ -F "input_fidelity=high" \ -F "size=1024x1024" \ -F "quality=medium"
¿Por qué conviene empezar por aquí?
Primero, porque alinea la elección del modelo con la superficie de API. Estás llamando al endpoint que mini soporta de forma explícita, en vez de pedirle a una capa de orquestación más grande que decida cómo resolver la edición.
Segundo, porque la depuración se vuelve más limpia. Si falla, normalmente el problema cae en uno de cuatro grupos: acceso, formato de archivo, formulación del prompt o manejo de la salida. No tienes que preguntarte a la vez si la culpa fue del top-level model de Responses, de la configuración de tools o del estado de la conversación.
Tercero, porque así esta página mantiene un scope claro. La explicación más amplia ya existe en nuestra guía de OpenAI image editing API. Esta página es más estrecha: qué hacer cuando ya sabes que quieres mini para editar imágenes.
Cuándo sí ayuda Responses y por qué esa frontera importa más con mini
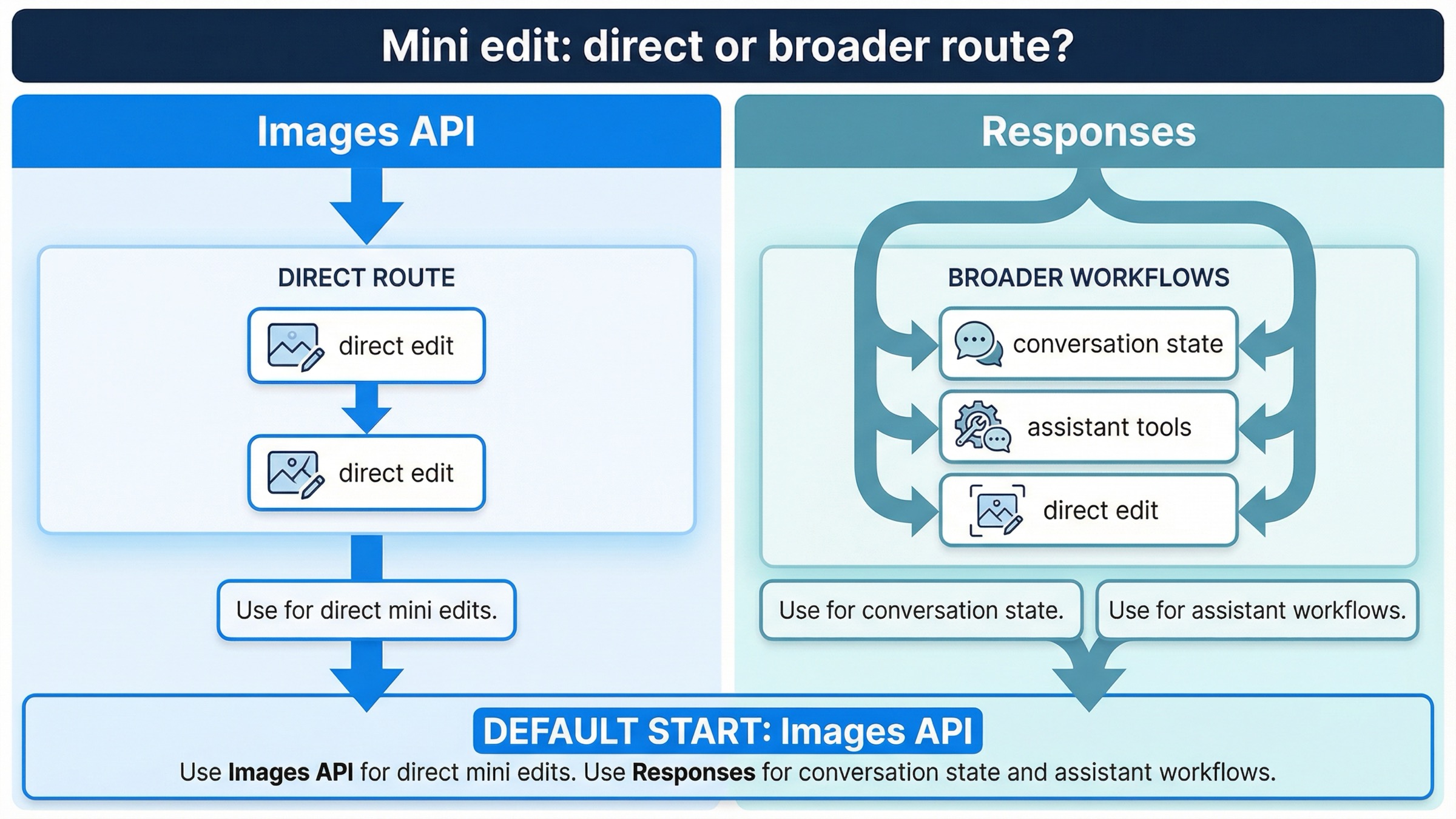
Responses sigue siendo útil. La cuestión es que, si tu requisito completo es "editar una imagen con gpt-image-1-mini", normalmente no debería ser tu primera decisión.
La actual image generation tool guide deja clara la razón. En Responses, el model de nivel superior debe ser un modelo de texto como gpt-4.1 o gpt-5. Los modelos GPT Image no son el model principal ahí; la generación o edición de imagen vive dentro del tool. En otras palabras, cuando eliges Responses ya no estás eligiendo solo una ruta de mini edit, sino un workflow abstraction mucho más amplio.
Esa distinción importa todavía más con mini porque la documentación actual del action en Responses se centra en gpt-image-1.5 y chatgpt-image-latest, no en mini como la vía de edición más clara. No estoy deduciendo que mini jamás pueda funcionar dentro de Responses. Estoy haciendo una inferencia más útil y más prudente: si quieres una ruta mini edit predecible, explícitamente documentada y fácil de depurar, el contrato más claro sigue estando en Images API directo.
¿Cuándo sí compensa Responses?
- cuando necesitas varias rondas de edición con previous response IDs o image generation call IDs
- cuando estás construyendo un assistant que mezcla reasoning, tools y edición de imagen
- cuando la edición debe vivir dentro de una conversación más larga
- cuando necesitas que una sola request decida entre varias tools y no solo lanzar una edición
La regla mental más útil sigue siendo esta:
- "La edición de imagen es la función": empieza con
images.edit() - "La edición de imagen es una tool dentro de una función mayor": valora Responses
Si tu duda real es más amplia que el edit y quieres ver el mapa completo de mini, el siguiente paso lógico es gpt-image-1-mini API. Esta página se mantiene estrecha a propósito.
Mask, reference images e input_fidelity en mini
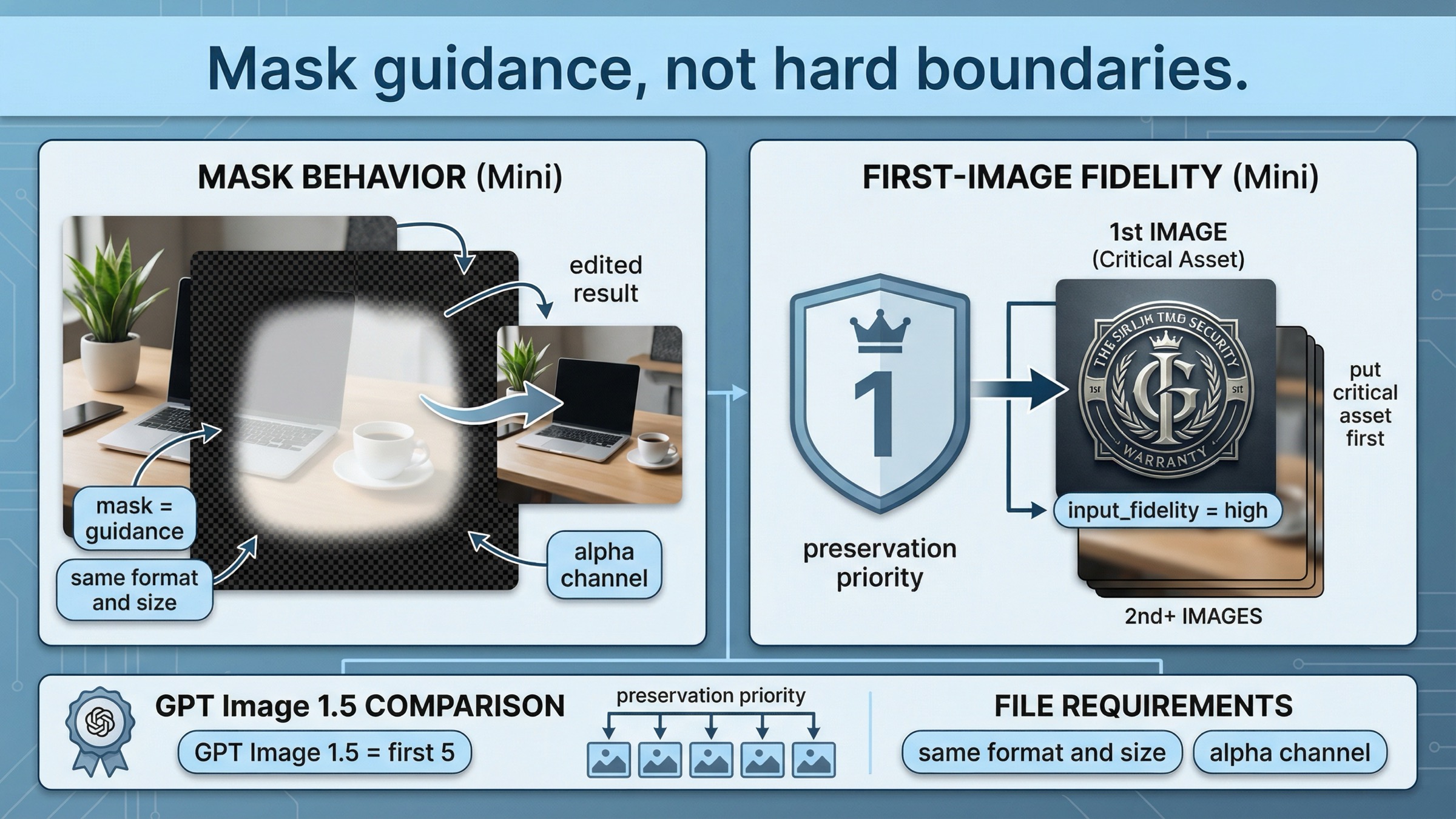
Esta es la sección más mini-specific de todo el artículo, y una de las razones principales por las que esta página mejora a tantos resultados genéricos.
La actual image generation guide en su parte de edit dice que la imagen y el mask deben tener el mismo formato y el mismo tamaño, que el total debe quedar por debajo de 50 MB y que el mask necesita alpha channel. Pero el detalle realmente importante es otro: en GPT Image, la edición con mask sigue siendo prompt-based. El mask orienta la edición, pero no equivale a un límite duro al estilo Photoshop.
Eso significa que con mini debes pensar el mask como una guía fuerte, no como una promesa de "solo se tocarán estos píxeles y nada más".
La otra regla importante aparece en la documentación actual de input_fidelity. OpenAI explica que, cuando usas gpt-image-1 o gpt-image-1-mini con alta fidelidad de entrada, la primera imagen recibe una preservación más fuerte de texturas y detalles. Si tu workflow incluye una cara, un logo, un producto o cualquier anchor visual crítico, debe ir en la primera posición. GPT Image 1.5 es más fuerte aquí porque puede preservar mejor las primeras cinco imágenes de entrada.
Esto no es una simple nota de implementación. Cambia de verdad la forma de diseñar una request de edición en mini.
Mini suele ser suficiente cuando el trabajo se parece a esto:
- una imagen principal y una referencia pequeña
- una cara o un logo que claramente merece la primera posición
- un cambio principal sobre una escena, sin demasiadas transformaciones en conflicto
- un mockup de ecommerce o una variante creativa de riesgo bajo o medio
Conviene ser más prudente cuando el trabajo se parece a esto:
- varias referencias son igual de importantes
- hay varios elementos de marca que deben sobrevivir a la vez
- el typography o el layout admiten muy poco margen
- es un activo comercial de alto valor y cada retry cuesta tiempo real
El patrón de implementación sigue siendo simple:
jsconst result = await client.images.edit({ model: "gpt-image-1-mini", image: [ fs.createReadStream("base-scene.jpg"), fs.createReadStream("logo.png"), ], prompt: "Place the logo from image 2 onto the tote bag in image 1. Preserve the model, pose, bag shape, camera framing, and lighting.", input_fidelity: "high", });
Lo importante no es la sintaxis del código, sino el orden de las entradas. En mini, la primera imagen es el slot de preservación más fuerte.
Antes de tocar el código, revisa precio, límites y verification
Aquí es donde muchas páginas exact-match hacen perder más tiempo al lector. Enseñan el sample code, pero tardan demasiado en admitir que el fallo puede no estar en el código.
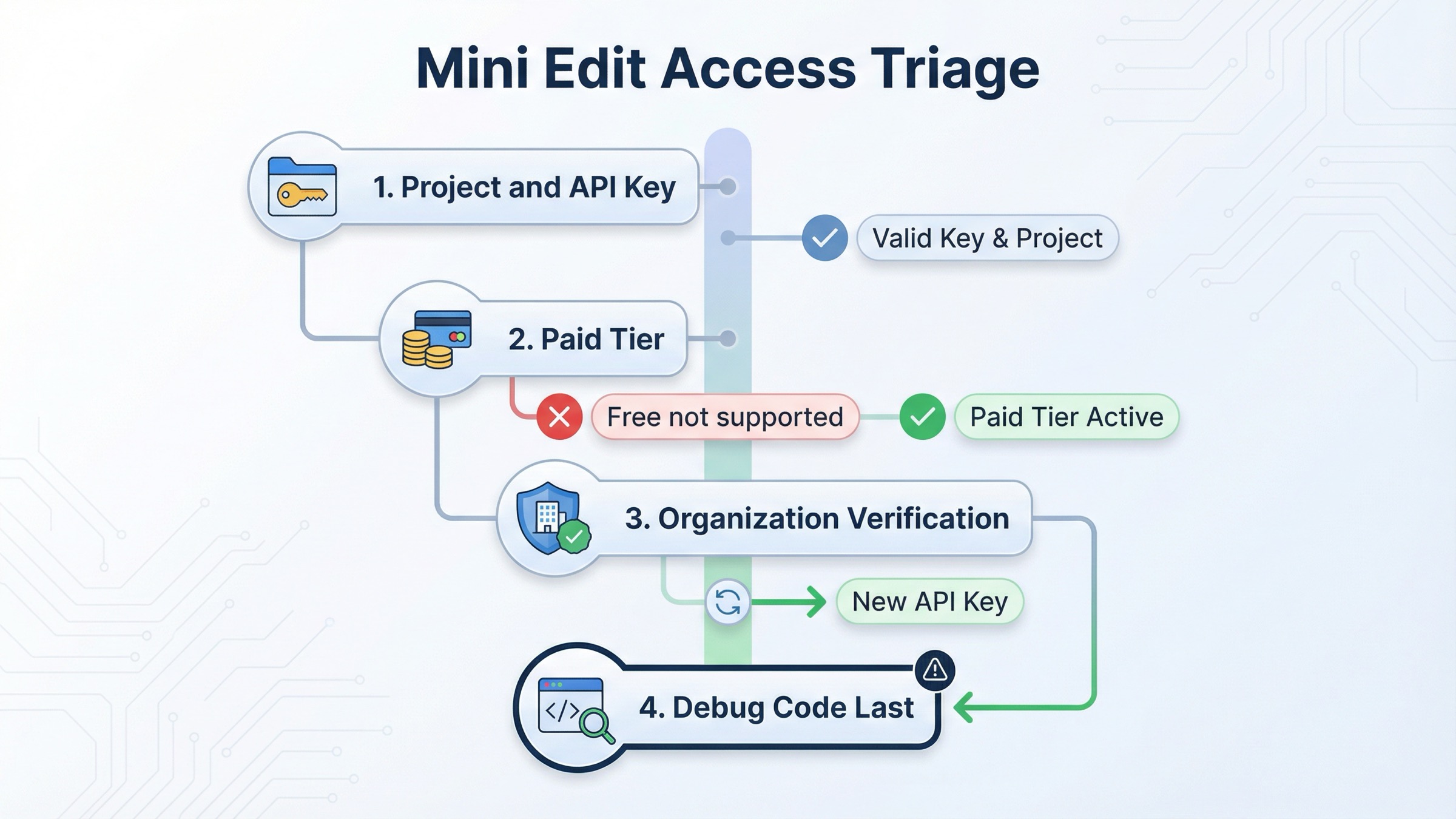
A 29 de marzo de 2026, la gpt-image-1-mini model page sigue mostrando para 1024x1024 estos precios: $0.005 low, $0.011 medium y $0.036 high. La misma página deja claro que Free not supported y que el punto de partida en Tier 1 es 100,000 TPM y 5 IPM.
La actual model availability article indica que GPT-image-1 y GPT-image-1-mini están disponibles para usuarios API en tiers 1 a 5, pero que parte del acceso puede seguir dependiendo de organization verification. La actual organization verification article añade dos datos prácticos: la propagación del estado puede tardar hasta 30 minutos, y generar una API key nueva suele resolver errores persistentes de tipo “not verified”.
Por eso, el orden correcto de diagnóstico es:
- confirmar que la API key pertenece al project y a la organization correctos
- confirmar que la cuenta está en un tier de pago con acceso a mini image
- si todavía parece un problema de acceso, revisar organization verification
- esperar el margen completo de 30 minutos
- si la organización ya está verificada, crear una API key nueva
- solo entonces reescribir la integración
Este orden importa porque una request de mini edit puede fallar aunque la sintaxis sea correcta. Si el problema real es el estado de la cuenta, ni un prompt más bonito ni una migración apresurada a Responses van a solucionarlo.
Si tu bloqueo real es access y no edit logic, el siguiente artículo útil es OpenAI image generation API verification. Si lo que necesitas es presupuesto, sigue con GPT Image 1 Mini pricing.
Los fallos que las páginas exactas suelen ocultar
El primer error típico es arrancar en la superficie de API equivocada. Si la tarea es una edición directa, no hace falta ir a Responses solo porque el ejemplo parezca más nuevo.
El segundo error es usar el modelo mental equivocado dentro de Responses. Los modelos GPT Image no son el model de nivel superior; la parte de imagen vive dentro del tool.
El tercero es tratar el mask como si fuera cirugía de píxel con borde duro. La documentación deja claro que el masking en GPT Image sigue siendo prompt-driven. Si necesitas cambios ultra locales sin movimiento colateral, esa suposición hay que validarla pronto.
El cuarto es poner el asset más importante fuera de la primera posición. Si la cara, el logo o el producto principal no va primero, estás renunciando al slot de preservación más fuerte que mini ofrece ahora mismo.
El quinto es depurar el prompt antes de confirmar el acceso. Si el tier, la verification o el project context no están alineados, un prompt más largo no arreglará nada.
El sexto es pedir demasiado a una sola request barata de edición. En las limitations actuales, OpenAI recuerda que los prompts complejos pueden tardar hasta 2 minutos, y la familia sigue teniendo límites en tipografía precisa, consistencia entre referencias y control fino de composición. Si necesitas exactitud de marca, texto bien colocado y varias referencias preservadas a la vez, probablemente el problema ya no sea la ruta sino la elección del modelo.
El hábito operativo más útil suele ser este:
- lanzar primero un direct edit mínimo
- poner el input más importante en la primera posición
- usar
input_fidelity="high"solo cuando la preservación realmente importa - dividir un cambio complejo en dos rondas más pequeñas si el primer resultado ya va cerca
Ese orden suele ahorrar más tiempo que seguir estirando el prompt.
Cuándo mini ya basta para editar y cuándo conviene subir a GPT Image 1.5

La decisión real detrás de esta keyword no es "mini o Responses", sino "mini basta o ya es momento de pasar a 1.5".
La actual model comparison section dice de forma bastante directa que gpt-image-1.5 ofrece la mejor calidad global y que gpt-image-1-mini es la opción más rentable cuando la calidad no es la prioridad principal. Traducido al lenguaje del edit workflow, queda así.
Mini suele ser suficiente para:
- variantes creativas internas
- mockups de ecommerce o habitaciones de riesgo bajo
- edición centrada en una sola imagen principal
- benchmarks baratos previos antes de decidir si necesitas la vía flagship
- workflows donde el coste pesa más que la preservación máxima
GPT Image 1.5 suele ser más seguro para:
- varias reference images importantes en una misma request
- trabajos con más exigencia de preservación de marca
- edits sensibles a typography o layout
- activos de marketing donde un retry ya implica mucho coste
- casos en los que quieres el mejor default quality lane de OpenAI hoy
Por eso la recomendación honesta no es "mini vs Responses". Es: para mini-specific edit, empieza por Images API directo; si la propia carga de trabajo demuestra que mini se queda corto, pasa a GPT Image 1.5.
Si necesitas una evaluación más amplia de coste frente a calidad, el siguiente paso lógico es GPT Image 1 Mini review. Si quieres el mapa general del family-level route, sigue con OpenAI Image API tutorial. Si lo siguiente que vas a comparar es el coste de 1.5, ve a GPT Image 1.5 pricing API.
FAQ
¿gpt-image-1-mini puede editar imágenes de forma directa ahora mismo?
Sí. La página actual del modelo gpt-image-1-mini lista v1/images/edits, así que el Images API directo es un current route válido para mini edit.
Si solo necesito una edición, por qué no empezar con Responses?
Porque la image guide actual dice claramente que, si solo necesitas una image job a partir de un prompt, Image API es la mejor opción. Responses aporta valor cuando la edición vive dentro de una conversación o un workflow mayor.
¿El mask obliga al modelo a cambiar solo los píxeles enmascarados?
No. La documentación actual explica que el masking en GPT Image sigue siendo prompt-based. El mask guía la edición, pero no garantiza un borde duro perfecto.
¿Cuándo debería cambiar de mini a GPT Image 1.5?
Cuando importen más la preservación de varias imágenes, el control de marca, la estabilidad en assets sensibles al layout o simplemente la mejor calidad posible por defecto.
Recomendación final
Si tu trabajo exacto a 29 de marzo de 2026 es editar una imagen con gpt-image-1-mini, empieza con images.edit() o POST /v1/images/edits. Es la ruta más clara en la documentación actual, la más fácil de depurar y la que mejor evita confundir el comportamiento específico de mini con una capa de workflow más grande.
Pasa a Responses solo cuando el producto de verdad necesite estado conversacional, orquestación de tools o una lógica multimodal de varios pasos. Y mantén separada la segunda decisión: si mini se queda corto, no sigas optimizando la ruta; benchmarkea GPT Image 1.5 cuanto antes.