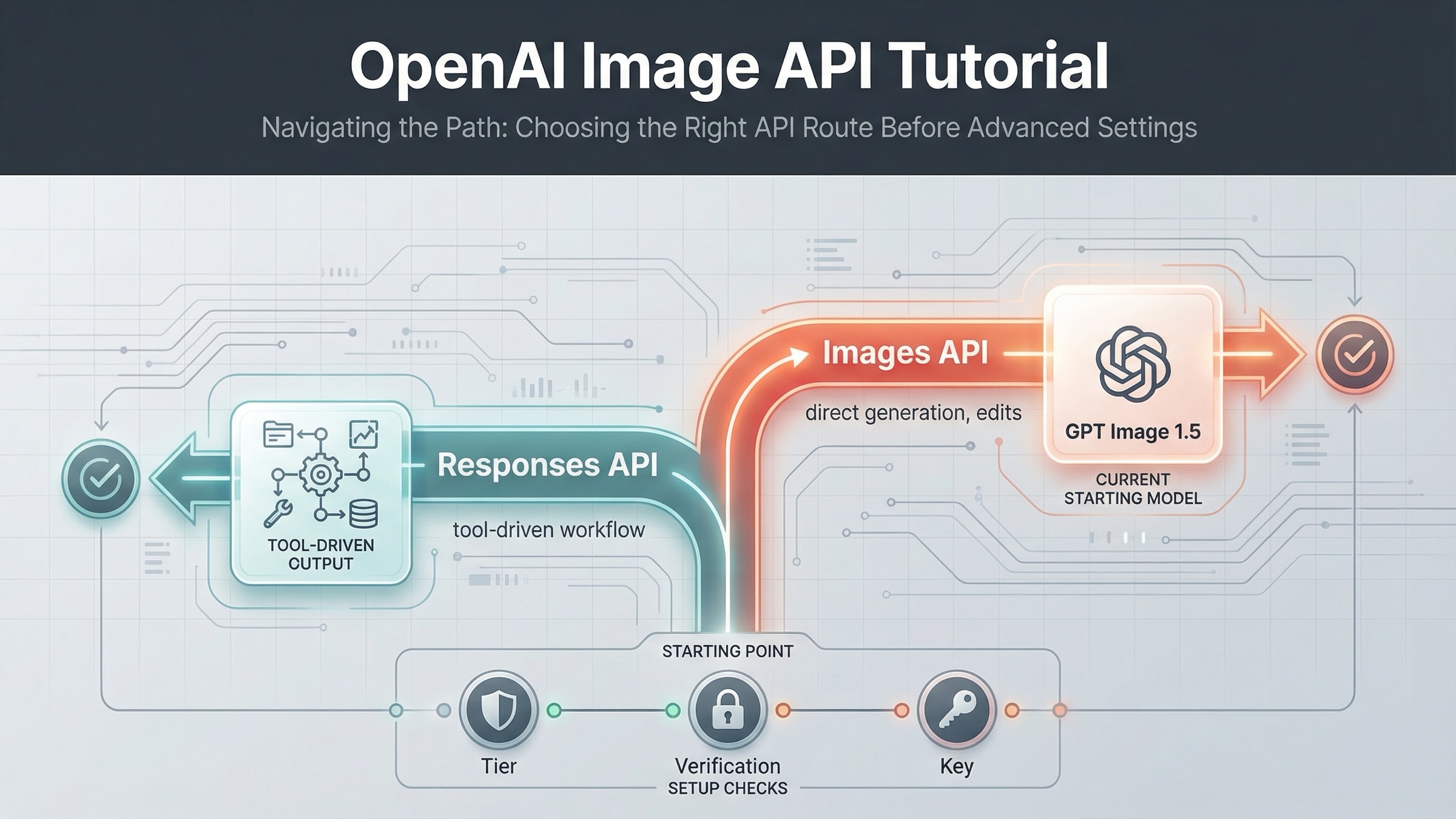
A 22 de marzo de 2026, la ruta más segura por defecto es esta: si quieres generar o editar imágenes de forma directa, empieza con Images API; si la generación de imágenes es solo una herramienta dentro de un flujo multimodal mayor, pasa a Responses API. Esa decisión resuelve más problemas que cualquier ajuste temprano del SDK.
Este keyword sigue pareciendo más confuso de lo que debería porque OpenAI reparte la respuesta entre varias páginas. El image generation guide cubre generación y edición directas. El images and vision guide enseña la ruta del tool image_generation dentro de Responses API. Y el catálogo actual de modelos deja claro que GPT Image 1.5 es la línea principal, gpt-image-1-mini es la ruta de coste bajo, chatgpt-image-latest es el alias de ChatGPT y DALL-E 3 ya aparece como deprecated. Si lees una sola página, te falta la película completa.
Por eso tantos tutorials empiezan mal aunque los snippets sean válidos. Unos siguen arrastrando el marco mental de DALL-E. Otros se lanzan a tocar código sin confirmar usage tier, organization verification o incluso la organización activa. El objetivo aquí no es repetir otra vez la documentación, sino ponerla en el orden que realmente evita trabajo perdido.
Resumen rápido
- Generación directa, edits simples y onboarding más corto: usa Images API.
- La imagen es solo una herramienta dentro de un assistant workflow: usa Responses API.
- El default actual para empezar es
gpt-image-1.5; solo si el coste manda desde el principio conviene benchmarkeargpt-image-1-mini. - Si el ejemplo parece correcto pero falla, revisa primero tier, verification, active org y API key, no el prompt.
Primero decide la ruta correcta
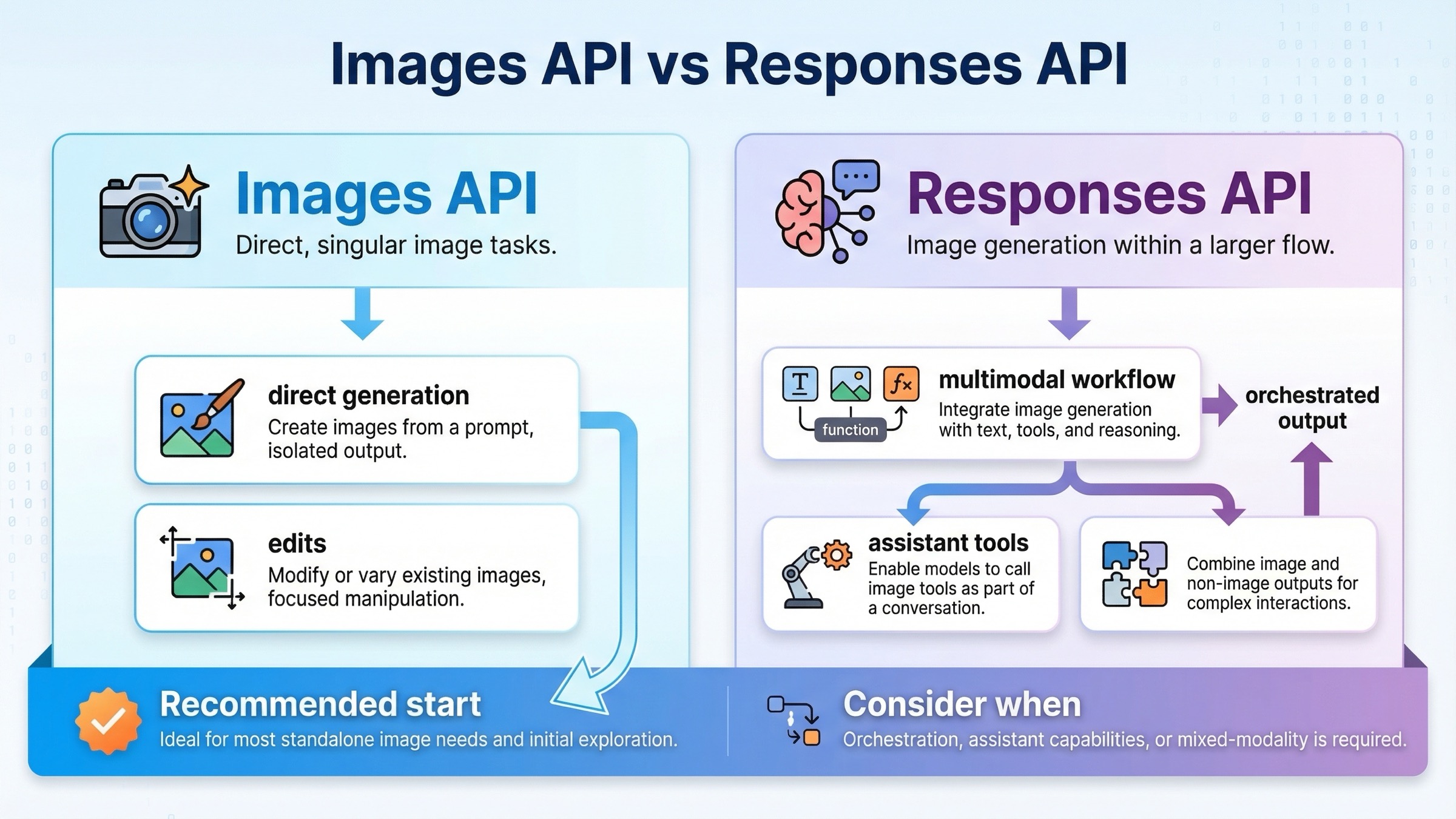
En esta consulta, elegir la superficie correcta importa más que memorizar parámetros.
| Situación | Mejor punto de partida | Por qué |
|---|---|---|
| Solo quieres lanzar una petición que genere una imagen y guardarla | Images API | Es la ruta más directa y la más fácil de entender como tutorial |
| Quieres editar una o varias imágenes existentes | Images API | Aquí están documentados edit, masks y input_fidelity |
| Quieres mezclar texto, herramientas e imágenes en un mismo flujo | Responses API | La generación de imágenes encaja mejor como tool dentro de un flujo mayor |
| Quieres que el equipo saque un working example cuanto antes | Images API | Menos capas y menos posibilidades de escoger el nivel equivocado demasiado pronto |
| Estás construyendo un assistant o agent con varios outputs | Responses API | Su patrón de tool orchestration es más natural en ese contexto |
La regla práctica es muy simple: si la imagen es el surface principal, empieza con client.images.generate() o client.images.edit(); si la imagen es una herramienta más, usa client.responses.create().
Las docs oficiales ya insinúan esta división, pero como la reparten entre varias páginas, el lector de un tutorial sigue teniendo que coser la respuesta por su cuenta. Aquí hacemos esa costura primero y dejamos los parámetros después.
Antes del código: access y model IDs
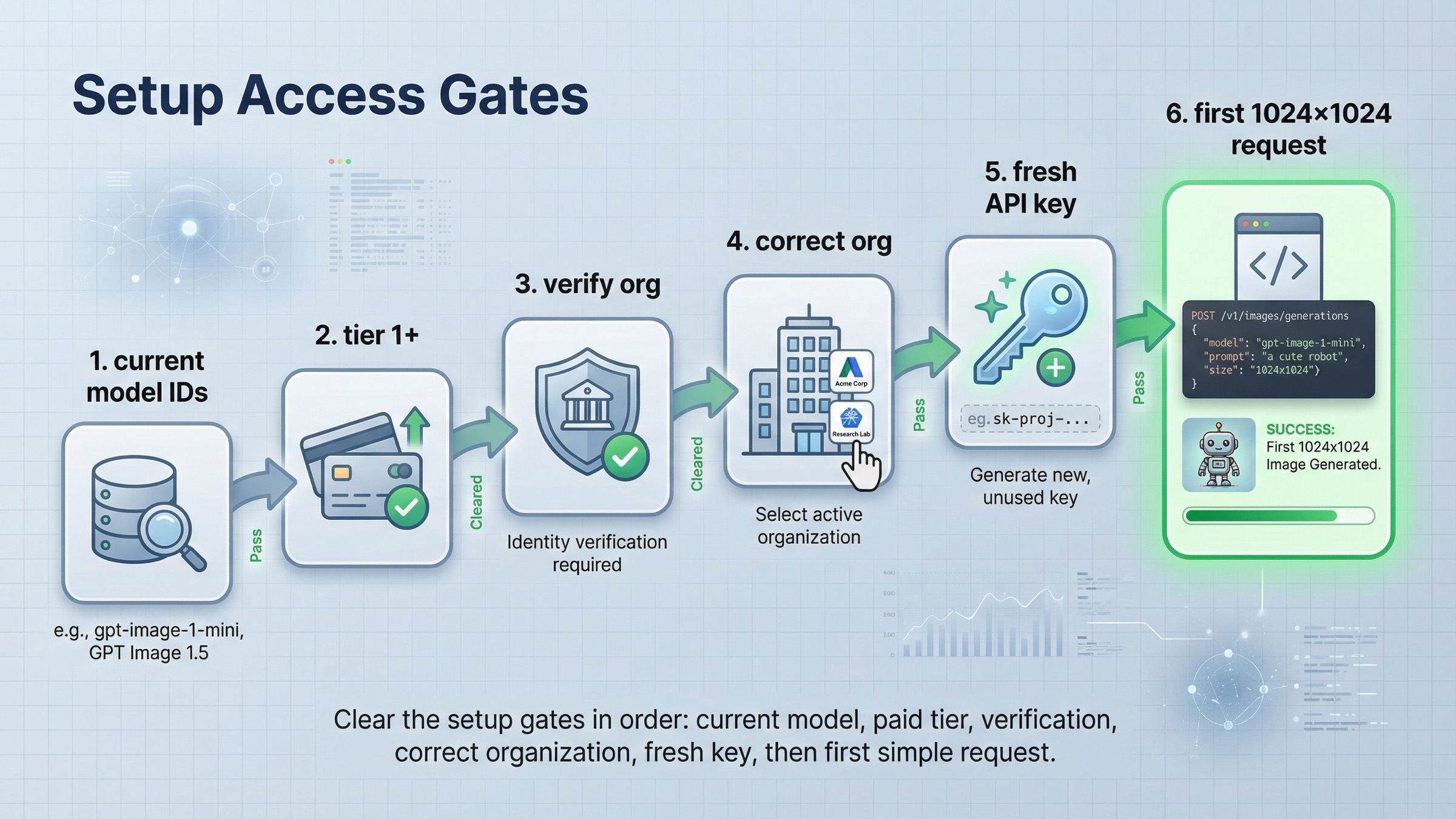
En esta query se pierde mucho tiempo cuando se da por hecho que el acceso ya está resuelto y se empieza por el SDK.
Primero, usa los model IDs actuales:
| Modelo | Rol actual | Cuándo usarlo |
|---|---|---|
| GPT Image 1.5 | current flagship | Nuevo proyecto, quality-first, edits, mejor prompt following |
gpt-image-1-mini | budget lane | prototipos baratos, tests en volumen, coste primero |
chatgpt-image-latest | alias de ChatGPT | si buscas intencionadamente el snapshot actual de ChatGPT |
| GPT Image 1 | modelo previo | compatibilidad legacy o referencia de migración |
| DALL-E 3 / DALL-E 2 | deprecated | no deberían ser la base de un tutorial fresco |
Esto importa porque la SERP todavía mezcla páginas viejas y páginas realmente actuales. Si arrancas con una idea mental vieja, el tutorial ya nace torcido.
Segundo, confirma el acceso. La página vigente API Model Availability by Usage Tier and Verification Status indica que GPT-image-1 y GPT-image-1-mini están disponibles para usuarios API de tiers 1 through 5, con parte del acceso sujeta a organization verification. La página actual de GPT Image 1.5 además marca Free not supported y muestra Tier 1 desde 100,000 TPM y 5 IPM. O sea: puedes fracasar antes de que el código sea relevante.
Si sospechas de verification, no sigas tocando prompts. La ayuda actual API Organization Verification recomienda confirmar la organización correcta, esperar hasta 30 minutos, crear una nueva API key, refrescar la sesión y probar otra vez. Esa es una rama de acceso, no una rama de sintaxis.
Instalar el SDK es lo más fácil:
bashnpm install openai
bashpip install openai
Después define OPENAI_API_KEY y haz una primera petición lo más aburrida posible: 1024x1024, prompt corto, una imagen, sin edits. El guide actual dice de forma explícita que la imagen cuadrada es el default y también la opción más rápida para empezar.
El primer working example con Images API
Para una guía directa, Images API sigue siendo el mejor comienzo porque deja clara toda la cadena: model choice, output settings y guardado del resultado.
Ejemplo mínimo en JavaScript:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.generate({ model: "gpt-image-1.5", prompt: "Create a clean editorial illustration of a robot camera operator in a bright studio", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; const imageBytes = Buffer.from(imageBase64, "base64"); fs.writeFileSync("openai-image-api-demo.jpg", imageBytes);
La versión equivalente en Python:
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.generate( model="gpt-image-1.5", prompt="Create a clean editorial illustration of a robot camera operator in a bright studio", size="1024x1024", quality="medium", output_format="jpeg", output_compression=80, ) image_base64 = result.data[0].b64_json image_bytes = base64.b64decode(image_base64) with open("openai-image-api-demo.jpg", "wb") as f: f.write(image_bytes)
Esta ruta es buena porque usa el modelo actual correcto, mantiene size y quality en una zona segura y además enseña a manejar el output base64 sin depender de suposiciones viejas sobre URLs.
Cuando la generación básica ya funciona, entonces sí tiene sentido ir a edits. El guide actual documenta edits con varias imágenes de entrada y input_fidelity. Si lo que te importa es un edit más fiel a la imagen original, input_fidelity: "high" es hoy una de las opciones más útiles para recordar.
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1.5", image: [ fs.createReadStream("woman.jpg"), fs.createReadStream("logo.png"), ], prompt: "Add the logo to the woman's jacket as if stitched into the fabric.", input_fidelity: "high", }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync( "woman-with-logo.png", Buffer.from(imageBase64, "base64") );
La regla importante no es el nombre de cada campo, sino el orden: primero estabiliza una generación simple; después abre la rama de edits.
Cuándo sí conviene pasar a Responses API
Responses API no es “mejor por ser más nueva”. Es mejor cuando la generación de imágenes es solo una parte de un flujo mayor. Por eso las docs actuales la muestran con image_generation como tool dentro de responses.create().
JavaScript:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const response = await client.responses.create({ model: "gpt-5", input: "Draw a transparent sticker-style icon of a paper airplane for a travel app", tools: [ { type: "image_generation", background: "transparent", quality: "high", }, ], }); const imageBase64 = response.output .filter((item) => item.type === "image_generation_call") .map((item) => item.result)[0]; fs.writeFileSync("paper-airplane.png", Buffer.from(imageBase64, "base64"));
Python:
pythonfrom openai import OpenAI import base64 client = OpenAI() response = client.responses.create( model="gpt-4.1-mini", input="Generate a product hero image of a ceramic mug on a white background", tools=[{"type": "image_generation"}], ) image_data = [ output.result for output in response.output if output.type == "image_generation_call" ] if image_data: with open("mug.png", "wb") as f: f.write(base64.b64decode(image_data[0]))
Este camino encaja mejor cuando:
- la imagen convive con texto y otros tools
- necesitas una respuesta multimodal única
- la generación de imágenes ya no es una feature aislada
Si el objetivo es simplemente “genera una imagen y guárdala”, Responses API complica el tutorial demasiado pronto.
Aquí también importa la fecha. El changelog de OpenAI muestra que el 19 de diciembre de 2025 añadió gpt-image-1.5 y chatgpt-image-latest al soporte del image generation tool en Responses API. O sea: los posts de lanzamiento que hablan de “coming soon” ya son historia, no guía actual.
Los ajustes que sí cambian resultado y coste
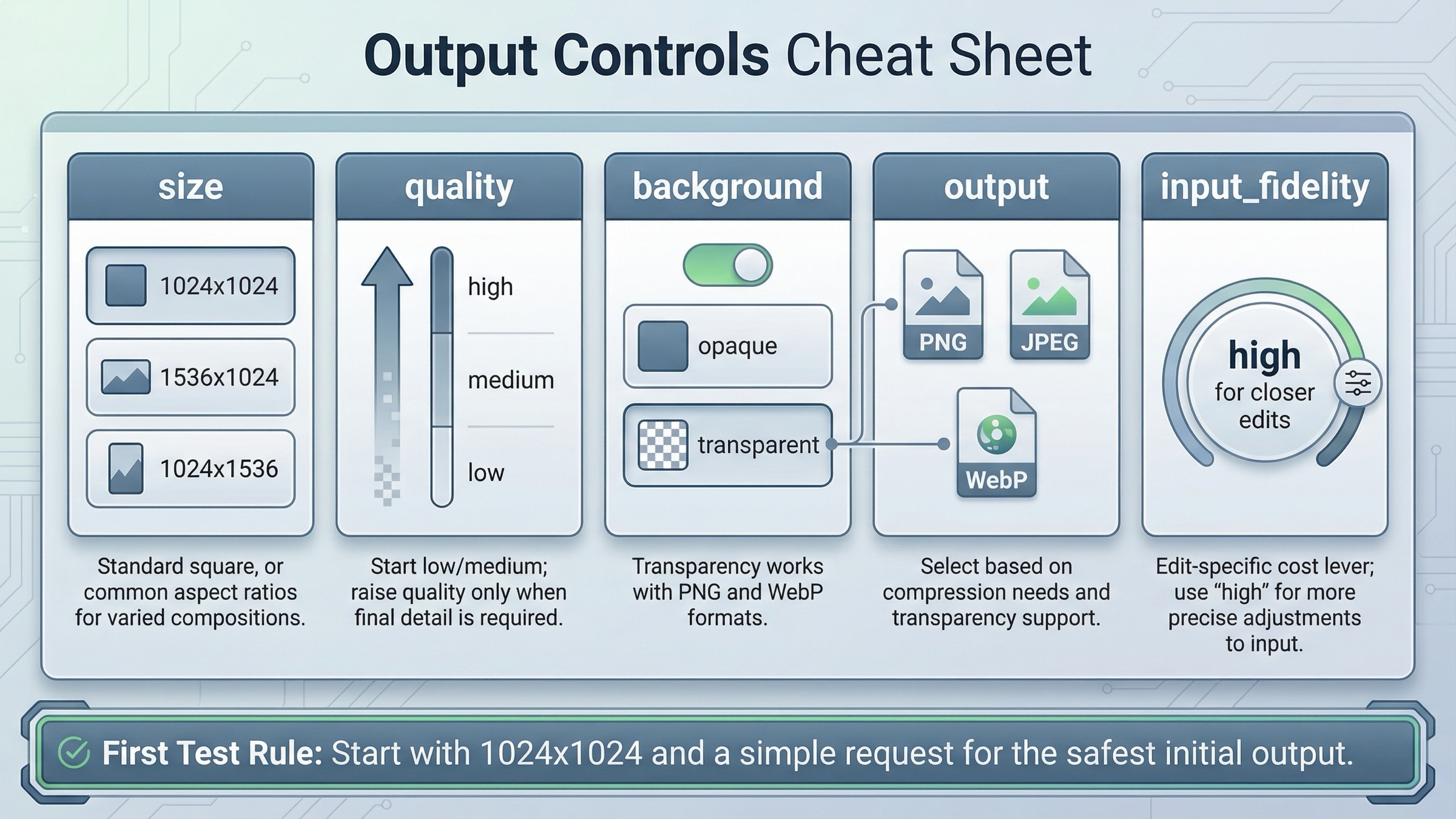
Cuando la primera petición ya sale, la prioridad no es activar todas las opciones avanzadas, sino entender qué ajustes realmente cambian calidad, latencia o coste.
El guide actual insiste sobre todo en:
sizequalitybackgroundoutput_formatoutput_compressioninput_fidelity
La forma más útil de leerlos es por la decisión que cambian.
Size cambia composición y coste. Para el primer test, lo prudente sigue siendo 1024x1024. La propia guía actual señala que el cuadrado es el default y la opción más rápida.
Quality cambia latencia y gasto. La página actual de GPT Image 1.5 marca $0.009 para low en 1024x1024, $0.034 para medium y $0.133 para high. La diferencia ya es suficiente para no usar high como default de prototipo.
Background importa cuando quieres transparencia. Las docs actuales explican que background: "transparent" funciona con PNG y WebP. Si un tutorial omite esto, muchos usuarios confunden un problema de formato con un problema del modelo.
Output format y compression afectan al shape final del archivo. Image API devuelve base64 image data y el format por defecto es PNG, aunque también puedes pedir JPEG o WebP. Si tu restricción principal es latencia y no alfa, JPEG suele ser más práctico.
input_fidelity es un lever específico de edit. Sirve para edits más cercanos al input, pero no es la mejor pieza para meter en la primera request.
La mejor disciplina sigue siendo una: cambiar una variable cada vez. Si cambias modelo, size, quality, background y edit inputs a la vez, ya no sabes qué decisión mejoró el resultado ni qué disparó el coste.
Si tu pregunta real ya es más de presupuesto que de integración, el siguiente paso es la guía en español de precios de OpenAI Image Generation API.
Las ramas de fallo que muchos tutorials no muestran
Lo que más tiempo hace perder en este tema no es la sintaxis, sino el orden equivocado del diagnóstico. Los tutorials de happy path no dejan claro de qué rama sospechar cuando algo falla.
Primero, 403 de verificación. Si el error menciona organization verification, no sigas retocando prompts ni wrappers. La ayuda actual recomienda confirmar la organización activa, esperar hasta 30 minutos, crear una nueva API key, refrescar la sesión y probar otra vez. La comunidad sigue mostrando casos donde el dashboard ya marca verified pero Images Playground continúa bloqueado. Eso es un problema de contexto de acceso, no de código.
Segundo, 429 en una cuenta que parece financiada. En OpenAI Developer Community hay varios casos donde el usuario ya añadió credits y aun así recibe rate_limit_exceeded con modelos de imagen. Ahí la variable clave no es el saldo visible, sino el usage tier.
Tercero, fallos de edit y masks. El guide actual dice que la imagen a editar y la máscara deben tener el mismo formato, el mismo tamaño y menos de 50MB. Si saltas esto, la rama de edits parece aleatoria aunque la API esté funcionando bien.
Y hay otro fallo silencioso: seguir pensando en outputs basados en URL porque un tutorial viejo te acostumbró a ello. La ruta actual de GPT Image gira alrededor de base64 image data. Si tu postprocesado sigue suponiendo URLs hospedadas, romperás la cadena incluso con una request correcta.
Si el problema parece más amplio que tu llamada concreta, revisa OpenAI Status. A fecha de 22 de marzo de 2026, el estado público es normal. Eso no descarta incidentes futuros, pero hoy hace más sentido revisar configuración local antes de culpar a un outage general.
Si tu bloqueo principal sigue siendo verification y no implementation, la siguiente lectura útil es la guía en español sobre errores de verificación en OpenAI Image API.
Checklist antes de producción
Cuando la primera request ya funciona, toca fijar decisiones importantes.
- Fija la ruta. direct generation y edits se quedan en Images API; la generación de imágenes dentro de un flujo mayor va a Responses API.
- Fija el modelo.
Empieza con GPT Image 1.5 y deja
gpt-image-1-minicomo branch de comparación de coste. - Fija un perfil de salida por defecto. Decide size, quality y format antes de abrir demasiadas opciones.
- Registra el contexto del fallo. active org, model ID, endpoint y failure type ahorran mucho tiempo después.
- Separa tutorial success de budget success. Que funcione una vez no significa que el flujo ya sea razonable a escala.
Los siguientes enlaces merecen prioridad:
- Precios de OpenAI Image Generation API
- Errores de verificación en OpenAI Image API
- English fallback: How to get an OpenAI API key
- English fallback: OpenAI API key requirements
En resumen, un buen tutorial actual de OpenAI Image API no consiste en repetir más code blocks, sino en ordenar correctamente la ruta: API surface, model IDs actuales, access gates y solo después output controls de calidad, latencia y coste. Cuando respetas ese orden, el tema es bastante más claro de lo que parece en la SERP.
FAQ
¿Con qué conviene empezar: Images API o Responses API?
Si tu tarea es generar o editar imágenes de forma directa, empieza con Images API. Responses API encaja mejor cuando la imagen es un tool dentro de un assistant workflow mayor.
¿Cuál es el model ID más seguro para un tutorial nuevo?
Para la mayoría de casos, gpt-image-1.5 es el current default. Si el coste manda, compara después con gpt-image-1-mini.
¿Por qué falla un sample aparentemente correcto?
Lo más habitual no es la sintaxis, sino usage tier, organization verification, active org o una API key vieja.
¿Cuándo usar chatgpt-image-latest en vez de gpt-image-1.5?
Solo cuando quieras de forma explícita el snapshot de imagen actual de ChatGPT. Para un tutorial de producción, gpt-image-1.5 suele ser la opción más limpia.