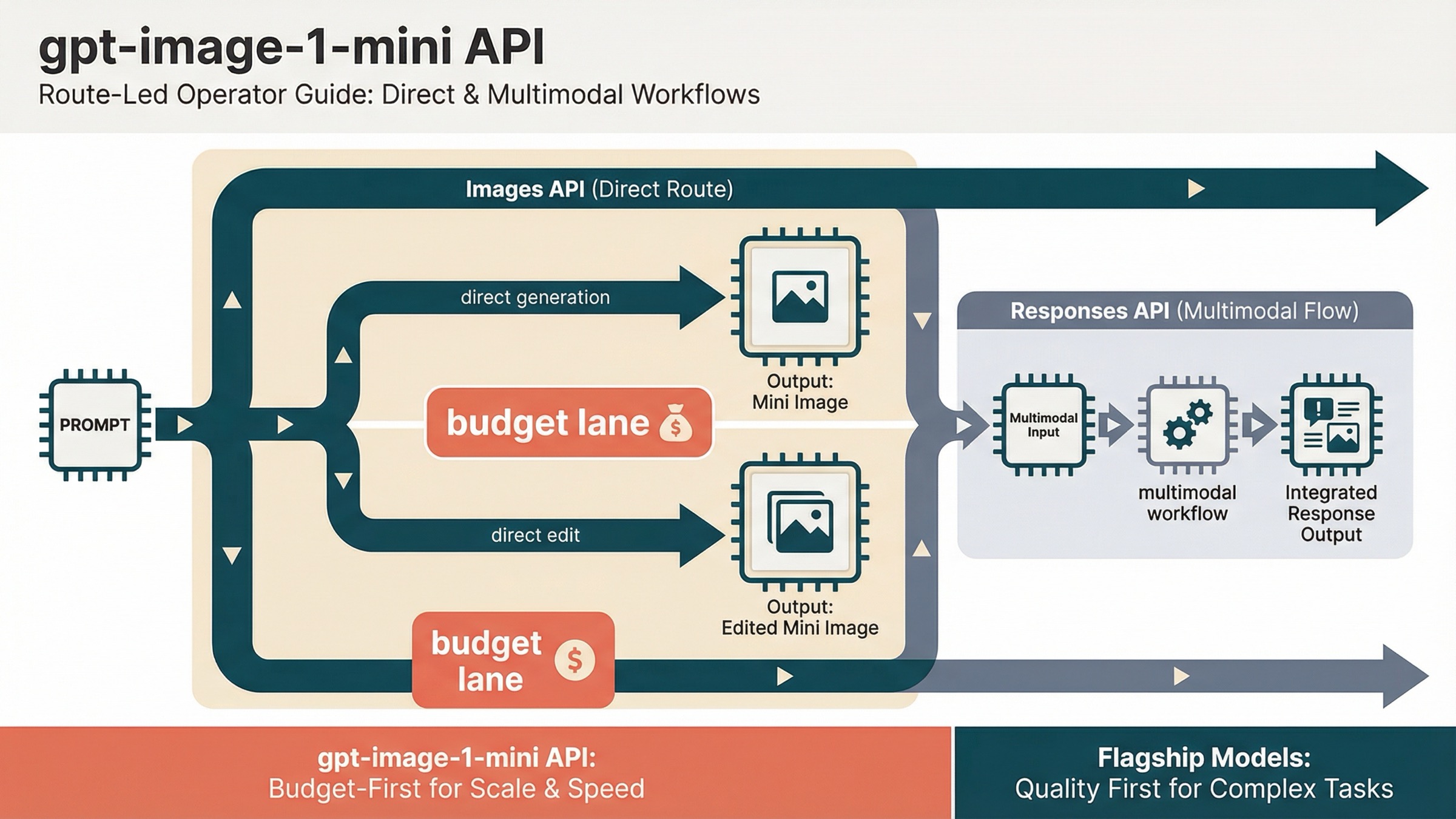
A 27 de marzo de 2026, el default más seguro para gpt-image-1-mini API es claro: si quieres generación directa o edición directa, empieza con OpenAI Images API; si la generación de imágenes es solo un tool dentro de un workflow multimodal más grande, entonces sí pasa a Responses API. Ese split sigue demasiado repartido en la página uno.
La consulta se siente más confusa de lo que debería no porque OpenAI oculte la respuesta, sino porque la divide entre varias páginas oficiales. La gpt-image-1-mini model page concentra pricing, endpoints y rate limits. El image-generation guide explica que Image API es la mejor opción cuando solo necesitas generar o editar una imagen a partir de un prompt, mientras que Responses encaja mejor en experiencias conversacionales o workflows más amplios. El images and vision guide enseña la ruta del tool dentro de Responses. Si lees una sola página, es fácil arrancar por la superficie equivocada.
Por eso muchas páginas exact-match se quedan en "mini es el modelo barato de OpenAI" y no responden lo más práctico: con qué API surface conviene empezar de verdad. Este artículo es más estrecho que el tutorial general de OpenAI Image API: aquí solo resolvemos qué hacer cuando ya sabes que quieres mirar gpt-image-1-mini.
Resumen rápido
- generación directa y edición directa: Images API;
- generación de imágenes como parte de un assistant workflow: Responses API;
gpt-image-1-minies la ruta budget, no la ruta flagship universal;- antes de reescribir código, revisa tier access y organization verification.
Empieza por la ruta directa más corta
En esta consulta, el primer éxito útil no es un request enorme con todos los parámetros, sino un request corto que reduzca al mínimo la superficie de fallo. El guide actual de OpenAI ya dice que Image API es la mejor elección cuando solo necesitas generar o editar una sola imagen a partir de un prompt. Mucha gente ve antes un ejemplo de Responses y asume que la abstracción más amplia es automáticamente la mejor. Para este keyword exacto, casi nunca lo es.
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.generate({ model: "gpt-image-1-mini", prompt: "Create a clean editorial illustration of a robot photographer in a bright studio", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync( "gpt-image-1-mini-demo.jpg", Buffer.from(imageBase64, "base64") );
En Python la lógica es la misma:
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.generate( model="gpt-image-1-mini", prompt="Create a clean editorial illustration of a robot photographer in a bright studio", size="1024x1024", quality="medium", output_format="jpeg", output_compression=80, ) image_base64 = result.data[0].b64_json with open("gpt-image-1-mini-demo.jpg", "wb") as f: f.write(base64.b64decode(image_base64))
El primer request conviene mantenerlo deliberadamente simple. Lo que quieres verificar es el model ID, el project activo, el access state y el output handling. Cuanto antes conviertas la primera prueba en un workflow grande, más difícil será saber si el problema está en la ruta, en la cuenta o en el código.
Dicho de otra forma: la primera integración debe ser intencionalmente aburrida. No estás demostrando en el minuto uno que dominas todos los parámetros; estás comprobando que el project correcto, el model correcto, el access correcto y el guardado correcto encajan al mismo tiempo. Las opciones avanzadas de size, quality, transparencia o edits siguen ahí, pero conviene sumarlas después de que la generación directa más corta ya funcione.
Images API vs Responses para gpt-image-1-mini
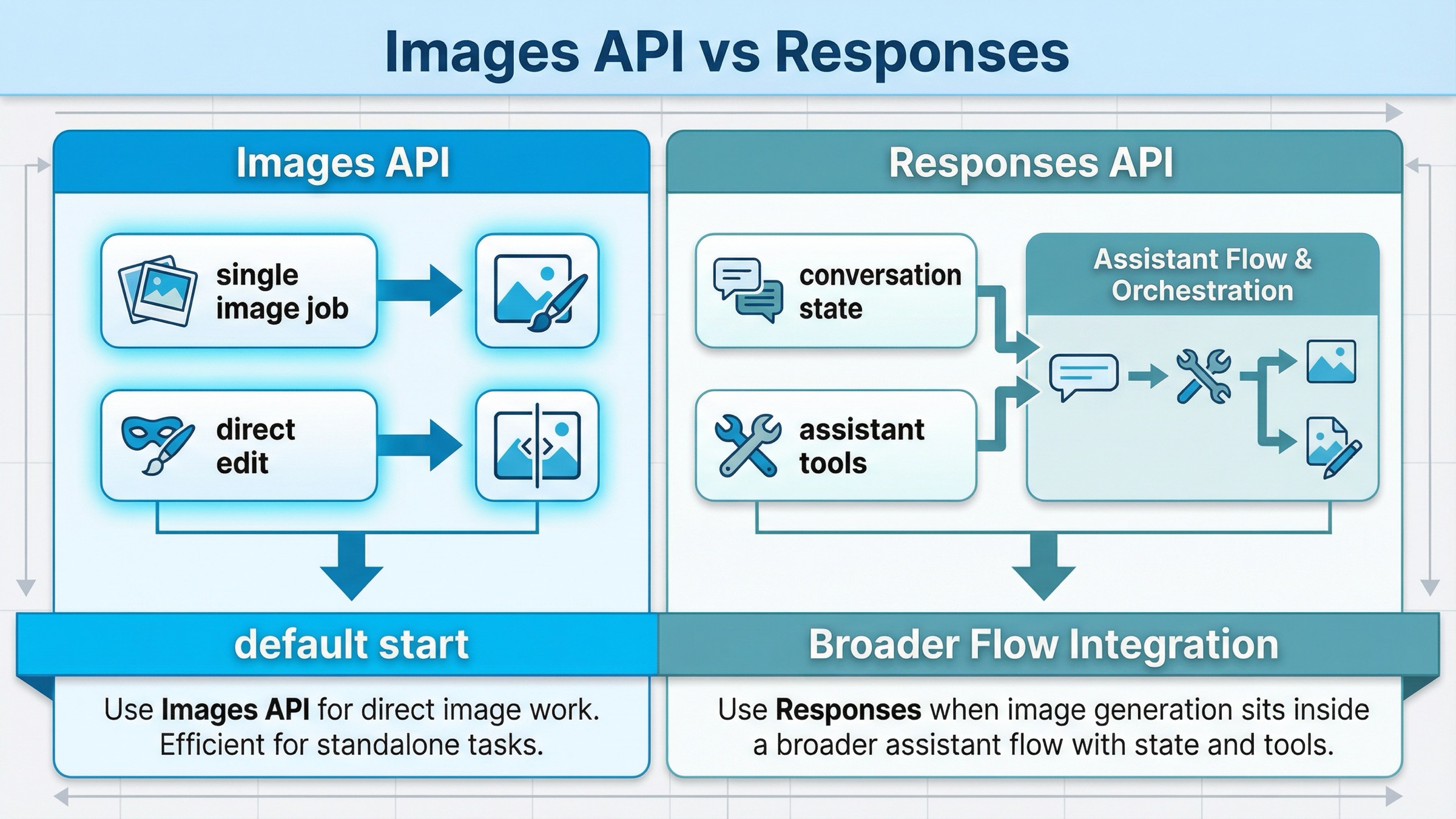
La tabla que de verdad importa aquí es esta:
| Situación | Mejor default | Por qué |
|---|---|---|
| Quieres un prompt y una imagen de salida | Images API | ruta más corta y debugging más claro |
| Quieres editar una o varias imágenes de entrada | Images API | la misma ruta directa resuelve el caso |
| La generación de imagen es un paso dentro de un assistant multimodal | Responses API | aquí manda el workflow externo |
| Necesitas conversation state, tools y salida de imagen en el mismo request | Responses API | la imagen es una pieza de un flujo mayor |
| Quieres validar rápido el model exacto | Images API | menos moving parts |
La regla práctica es simple: si la generación de imágenes es la feature, empieza con Images API; si la generación de imágenes vive dentro de un workflow más amplio, pasa a Responses.
Esa misma regla sirve cuando dentro del equipo aparece la tentación de unificar todos los proyectos nuevos en Responses solo porque parece la surface más moderna. La pregunta correcta no es qué API se ve más nueva, sino si ese request necesita de verdad conversation state, varios tools o salidas mixtas. Si la respuesta es no, empezar por la abstracción más grande solo añade complejidad temprana.
Cómo se ve la ruta de Responses cuando realmente hace falta
La mejor forma de no equivocarte con Responses es verlo en el contexto correcto. En la documentación actual de OpenAI, image generation dentro de Responses aparece como un tool dentro de un request más grande, no como el reemplazo por defecto de images.generate().
Eso cambia el mental model:
- el request top-level es multimodal o assistant-style;
- image generation es un tool dentro de ese request;
- la ruta cambia porque cambió el workflow de alrededor, no porque
gpt-image-1-miniobligue a usar otro endpoint para un job simple.
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const response = await client.responses.create({ model: "gpt-4.1-mini", input: "Generate a transparent sticker-style icon of a paper airplane", tools: [{ type: "image_generation", quality: "medium" }], }); const imageBase64 = response.output .filter((item) => item.type === "image_generation_call") .map((item) => item.result)[0]; fs.writeFileSync("paper-airplane.png", Buffer.from(imageBase64, "base64"));
Si tu trabajo real es solo "mandar un prompt, recibir una imagen y guardar los bytes", esta ruta solo te añade complejidad. Tiene sentido cuando ya necesitas el assistant flow mayor.
Por eso la SERP de este keyword sigue siendo engañosa. Parece que el desarrollador estuviera eligiendo entre dos rutas igual de válidas por preferencia personal, cuando en realidad casi siempre está decidiendo si quiere hacer la primera entrega más complicada de lo necesario. En ese escenario, Images API gana precisamente porque hace menos.
Revisa access primero y debugging después
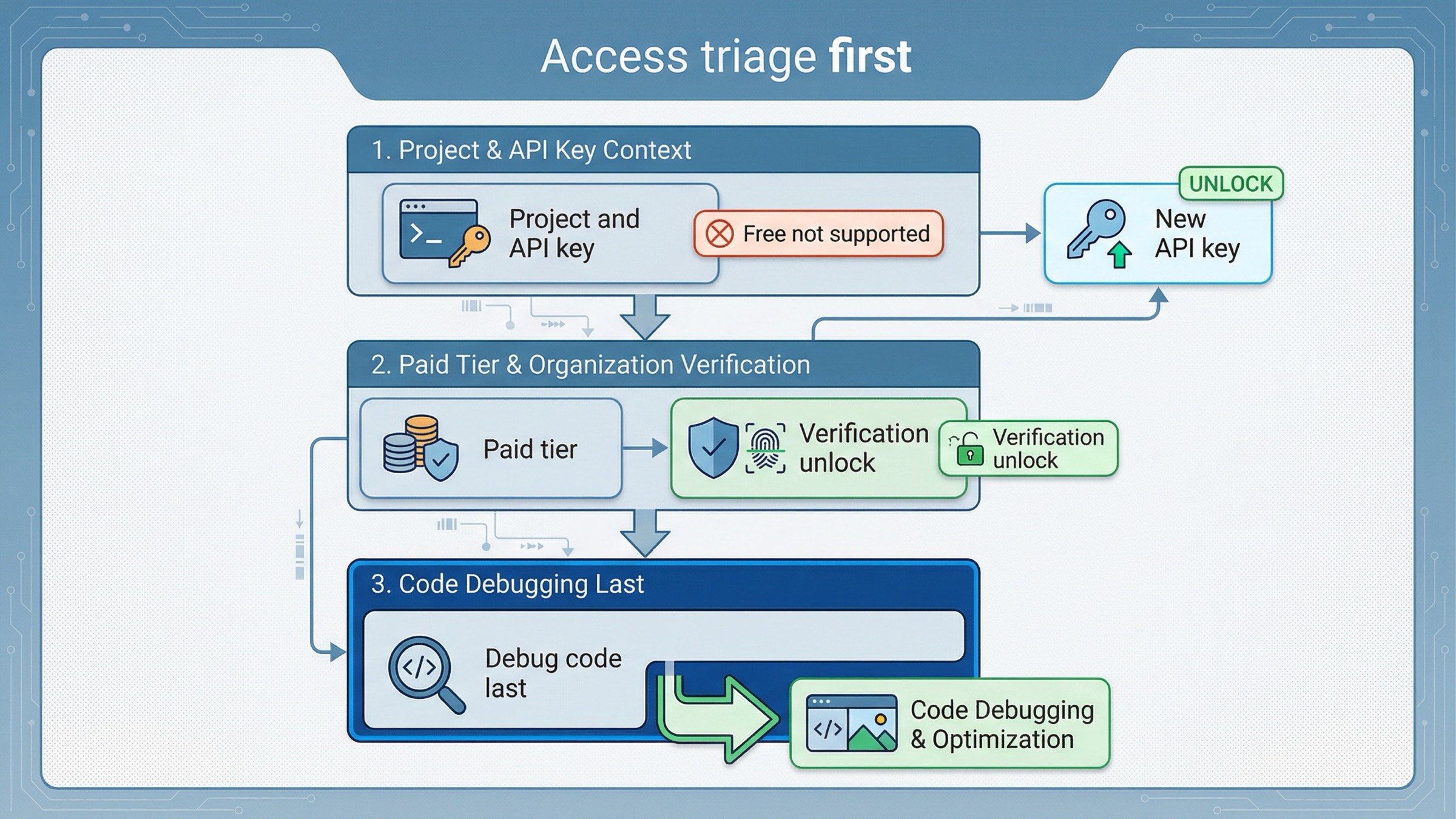
Otro punto donde la página uno suele hacer perder tiempo es este: enseñar sample code antes de admitir que la cuenta quizá ni siquiera está lista.
El artículo actual de API model availability dice que GPT-image-1 y GPT-image-1-mini están disponibles para usuarios API en tiers 1 through 5, con parte del access sujeto a organization verification. La gpt-image-1-mini model page además indica Free not supported y Tier 1 starting at 100,000 TPM y 5 IPM.
Por eso el orden más seguro es:
- comprobar que la API key pertenece al project y organization correctos;
- confirmar que la cuenta está en un paid tier compatible;
- si sigue bloqueado, revisar la rama de organization verification;
- solo entonces sospechar del prompt, del SDK sample o del parsing.
La help page actual sobre organization verification añade algo muy práctico: verification puede desbloquear image-generation capabilities, la propagación puede tardar hasta 30 minutos y generar una nueva API key a veces resuelve los errores persistentes. Eso es un branch de account state, no de model selection.
Vale la pena insistir en esto porque mucha gente cambia el prompt, actualiza el SDK o incluso reescribe la integración hacia Responses antes de confirmar el estado de la cuenta. Si el bloqueo real está en tier, project o verification, ninguna de esas maniobras arregla el problema. Con gpt-image-1-mini, sospechar primero del account state suele ahorrar más tiempo que sospechar del código.
Cuándo mini es el default correcto y cuándo no
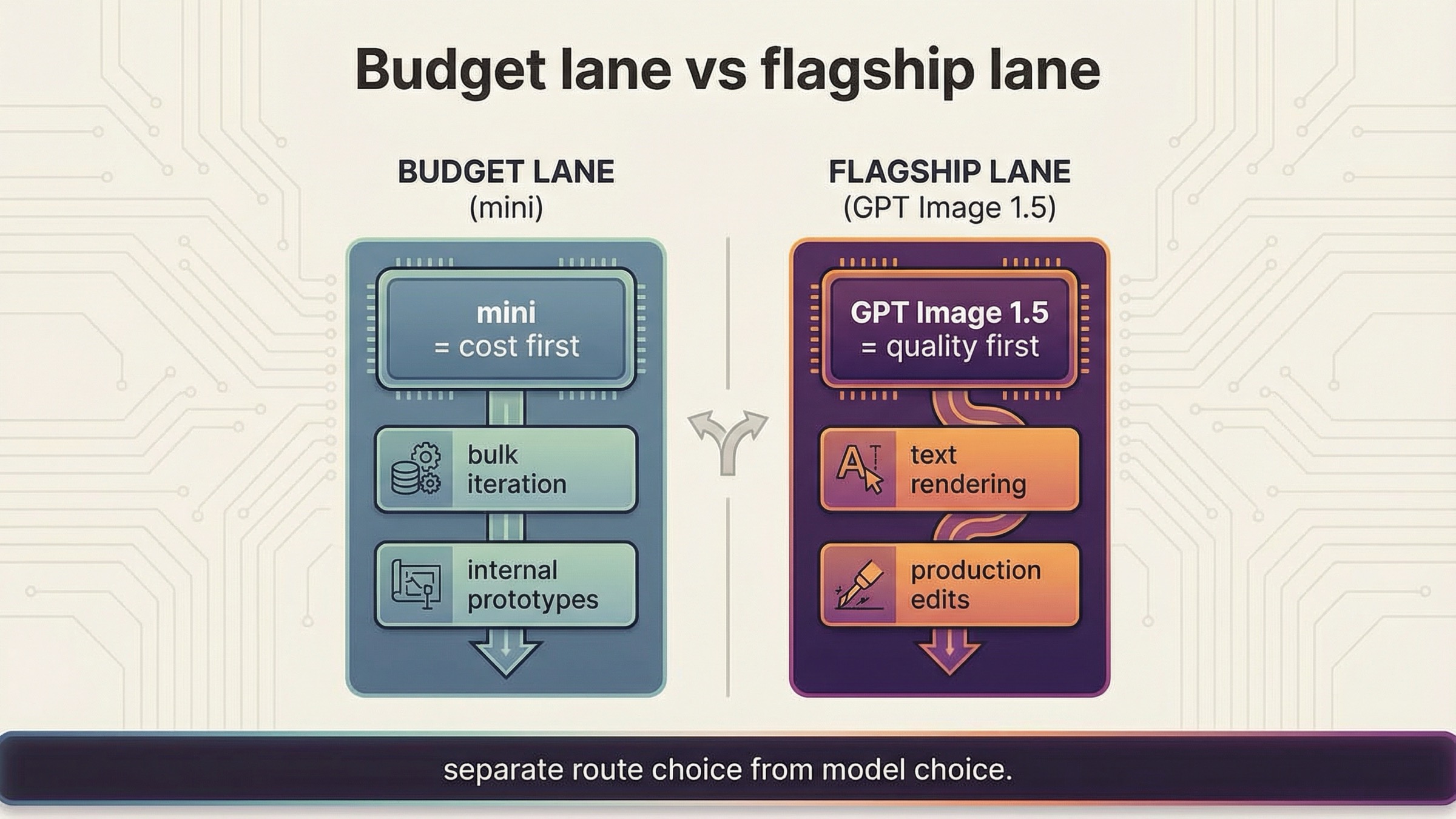
Aquí conviene ser muy claro. gpt-image-1-mini es la ruta budget, no la ruta universal. El guide actual de OpenAI recomienda GPT Image 1.5 para la mejor experiencia y señala mini cuando el coste importa más que la calidad. La model page actual muestra 1024x1024 low / medium / high a $0.005 / $0.011 / $0.036.
Eso es especialmente útil en workloads como:
- bulk iteration;
- prototipos internos;
- borradores de bajo riesgo;
- features donde el coste manda más que la mejor calidad posible.
La lectura incorrecta es "entonces todo nuevo proyecto debería empezar con mini". La correcta es otra: si el coste es la primera restricción, mini es el first benchmark actual.
Si el workflow depende de mejor text rendering, output más limpio, edits complejos o retries caros, entonces la comparación importante deja de ser mini vs Responses y pasa a ser mini vs GPT Image 1.5. En ese caso, la siguiente lectura útil es OpenAI image generation API pricing o GPT Image 1.5 API pricing, porque la pregunta ya no es solo la ruta, sino el coste total del workflow exitoso.
Aquí es donde muchas páginas de keyword exacto simplifican demasiado. Un precio por imagen más bajo no garantiza un workflow total más barato si luego necesitas más retries, más curación manual o más postprocesado para alcanzar el mismo nivel de calidad. mini sí es la rama cost-first, pero no por eso se convierte en la respuesta universal para cualquier producto con imágenes.
También conviene separar dos decisiones que la SERP mezcla demasiado: elegir la ruta y elegir el modelo. Que la mejor primera ruta sea Images API no significa automáticamente que mini sea el modelo final correcto para producción. Y al revés, descubrir que GPT Image 1.5 encaja mejor con tu quality bar no obliga a mover todo el workflow hacia Responses. Cuando separas esas decisiones, el diseño del sistema se vuelve mucho más claro.
El direct edit sigue en la misma ruta
Las wrapper pages a veces hacen parecer que edit implica otro mundo aparte. En realidad, la model page actual de mini lista v1/images/generations y v1/images/edits. Es decir: si la generación ya está en Images API, la edición normalmente sigue en esa misma surface directa.
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1-mini", image: fs.createReadStream("room.png"), prompt: "Turn this room into a bright Nordic living room with pale oak shelves and soft morning light.", size: "1024x1024" }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync("room-nordic.png", Buffer.from(imageBase64, "base64"));
Troubleshooting: lo que las thin wrapper pages no resuelven
El primer error repetido es pasar a Responses demasiado pronto. Si la feature es simplemente generar o editar una imagen, la abstracción más grande solo te hace depurar la capa equivocada.
El segundo es leer mini como respuesta para todos los workloads. La documentación oficial no lo posiciona así.
El tercero es reescribir código antes de confirmar el access state. Tier access y organization verification pueden bloquear la capability incluso con un sample válido.
El cuarto es pensar que una exact-match article debe ser solo una model card. En realidad, el lector quiere dos respuestas: por dónde empezar y cuándo dejar de confiar en ese default.
También conviene nombrar tres ramas de fallo muy comunes. Si el primer request cae con un error de access, normalmente es más útil revisar tier, project y verification que buscar otro sample. Si el request sí funciona pero la calidad no alcanza, el problema suele ser la idoneidad de mini para ese workload, no el endpoint. Y si el impulso de usar Responses viene solo de que aparece más en la documentación, hay que volver a la pregunta de producto: ¿ese request necesita de verdad un workflow multimodal más grande?
Hay una cuarta disciplina útil para equipos pequeños: ordenar las preguntas en el tiempo. Primero confirmas que la ruta directa funciona y que la cuenta está realmente lista para image generation. Después comparas mini frente a GPT Image 1.5 con criterios de calidad, retries y coste total. Si mezclas ambas discusiones demasiado pronto, acabas depurando la arquitectura antes de haber validado el acceso básico.
Llevado a un rollout real, el orden queda bastante claro. Primero haces pasar una generación directa por Images API y después una edición directa en la misma surface para comprobar que project, model, access y guardado están sanos. Luego revisas verification y estabilidad de la cuenta. Solo después tiene sentido comparar mini con GPT Image 1.5 por calidad, consistencia y coste del resultado conseguido, no solo por precio nominal.
FAQ
¿gpt-image-1-mini sirve para direct edits?
Sí. La model page actual lista tanto v1/images/generations como v1/images/edits.
¿Existe free tier para gpt-image-1-mini?
No en la página oficial actual revisada el 27 de marzo de 2026. Ahí figura Free not supported.
¿Cuándo conviene mirar GPT Image 1.5 desde el principio?
Cuando importan más la calidad, el text rendering, los edits complejos o el coste de cada retry que el precio mínimo por imagen.
Recomendación final
Si hoy vas a integrar gpt-image-1-mini, empieza con Images API. Haz así el primer generation request y el primer edit request, manteniendo el request lo bastante simple para separar access y output handling. Deja Responses para cuando image generation sea solo una pieza de un workflow multimodal mayor.
Después plantea la segunda pregunta por separado: ¿mini encaja de verdad con este workload? Si el coste es la primera restricción, es un benchmark muy fuerte. Si pesan más la calidad, el text rendering o los edits exigentes, el sticker price más bajo no decide solo. La clave de este keyword es mantener separadas route choice y model choice.
Ese orden, más que cualquier sample aislado, es lo que vuelve útil este keyword en producción. Primero eliges la surface más pequeña que resuelva el job. Luego haces el benchmark honesto del modelo. Cuando no mezclas route choice con model choice, gpt-image-1-mini api deja de ser una consulta confusa y pasa a ser una implementación mucho más predecible.
También mejora la conversación técnica dentro del equipo. En lugar de discutir al mismo tiempo endpoint, modelo, calidad y roadmap del producto, puedes resolver dos preguntas concretas en secuencia: qué route te da el primer éxito con menos moving parts y qué modelo te da el mejor equilibrio entre calidad y coste una vez que el access ya está confirmado. Esa separación reduce bastante el ruido de decisión.