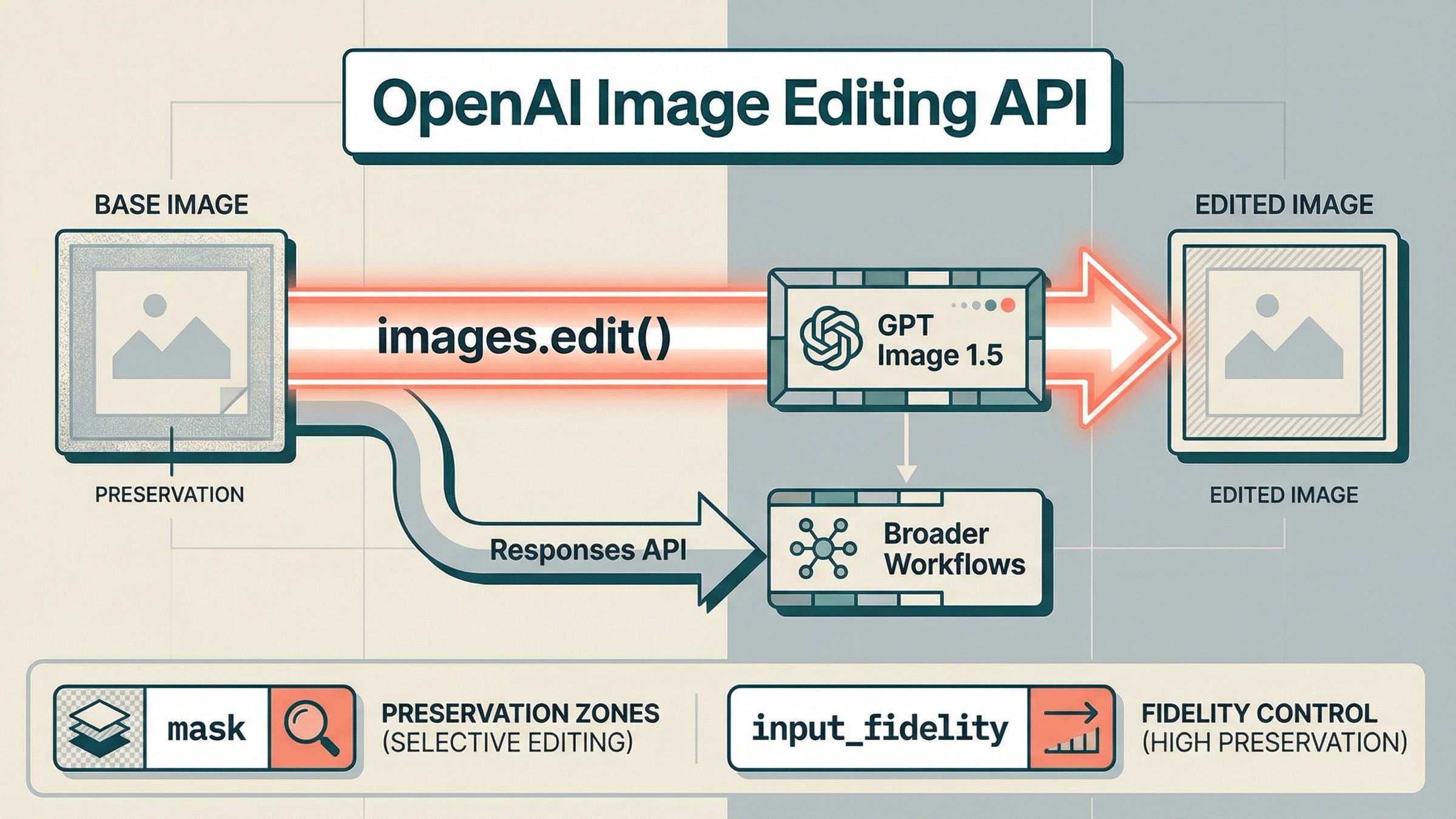
Si hoy necesitas editar imágenes con OpenAI API, a 23 de marzo de 2026 el default más seguro sigue siendo bastante claro: empieza por Images API y gpt-image-1.5. Para la mayoría de los trabajos donde la edición es la función principal, eso significa client.images.edit() en el SDK o POST /v1/images/edits en HTTP crudo. Responses API tiene más sentido después, cuando la edición de imágenes es solo un paso dentro de una conversación, un assistant o un workflow con agents.
Ese matiz importa porque la documentación actual de OpenAI sobre imágenes sigue repartida entre varias páginas. El image generation guide ya usa gpt-image-1.5 en ejemplos directos de edición. La página actual de GPT Image 1.5 lo presenta como latest image generation model. Pero la guía más amplia de Images and vision todavía conserva un contexto viejo donde gpt-image-1 aparece como latest. Si lees solo una página, es fácil copiar un flow válido en sintaxis pero desactualizado en estrategia.
El segundo error suele ser más caro que el primero. Mucha gente escucha “image editing API” y piensa de inmediato en un parche local tipo Photoshop. Sin embargo, la documentación actual de OpenAI es más cuidadosa. Pide describir la imagen final completa, no solo la zona borrada. Los threads de la comunidad muestran por qué esto sigue importando: las masked edits de GPT Image todavía pueden comportarse como una reescritura semántica más amplia, no como un reemplazo estrictamente limitado al área enmascarada. Este artículo existe para corregir esa expectativa antes de que se convierta en un problema de producto.
Resumen rápido
- Para editar imágenes con OpenAI, empieza por
images.edit()ygpt-image-1.5. - Usa mask cuando necesites indicar dónde debe enfocarse el modelo, pero no la interpretes como garantía de un parche pixel-perfect local.
- Añade
input_fidelity="high"cuando importe preservar caras, logos, composición o brand visuals. - Pasa a Responses solo cuando la edición forme parte de un workflow multimodal o agent más amplio.
Empieza por aquí: la ruta directa actual para editar imágenes
Para un workflow normal de edición, el mental model más corto y seguro es este:
- envías una o varias imágenes de entrada
- describes el resultado final que quieres
- añades preservation controls solo si hacen falta
- decodificas la imagen en base64 y la guardas
El patrón directo actual en JavaScript se ve así:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1.5", image: [fs.createReadStream("room.jpg")], prompt: "Replace the empty wall art with a framed abstract poster. Preserve the room layout, lighting, shadows, and all furniture. Do not change the camera angle.", input_fidelity: "high", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; const imageBuffer = Buffer.from(imageBase64, "base64"); fs.writeFileSync("room-edited.jpg", imageBuffer);
La versión equivalente en Python es igual de directa:
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.edit( model="gpt-image-1.5", image=[open("room.jpg", "rb")], prompt=( "Replace the empty wall art with a framed abstract poster. " "Preserve the room layout, lighting, shadows, and all furniture. " "Do not change the camera angle." ), input_fidelity="high", size="1024x1024", quality="medium", output_format="jpeg", output_compression=80, ) image_base64 = result.data[0].b64_json image_bytes = base64.b64decode(image_base64) with open("room-edited.jpg", "wb") as f: f.write(image_bytes)
Si necesitas la forma en HTTP crudo, el detalle clave es este: los image edits usan multipart form data, no JSON.
bashcurl https://api.openai.com/v1/images/edits \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "image[]=@room.jpg" \ -F 'prompt=Replace the empty wall art with a framed abstract poster. Preserve the room layout, lighting, shadows, and all furniture. Do not change the camera angle.' \ -F "input_fidelity=high" \ -F "size=1024x1024" \ -F "quality=medium"
Esta es la mejor ruta de partida porque mantiene el workflow obvio. Eliges el modelo actual con capacidad de edición, pasas la imagen de origen, describes la imagen final y guardas el base64 devuelto. No estás pidiendo a un reasoning layer más general que decida si debe editar o generar. No estás gestionando conversation state desde el primer minuto. Solo estás haciendo la edición.
Si tu duda real es más amplia que editar imágenes, la siguiente lectura natural es el tutorial OpenAI Image API en español. Esta página se mantiene deliberadamente más estrecha.
Images API vs Responses cuando necesitas edits
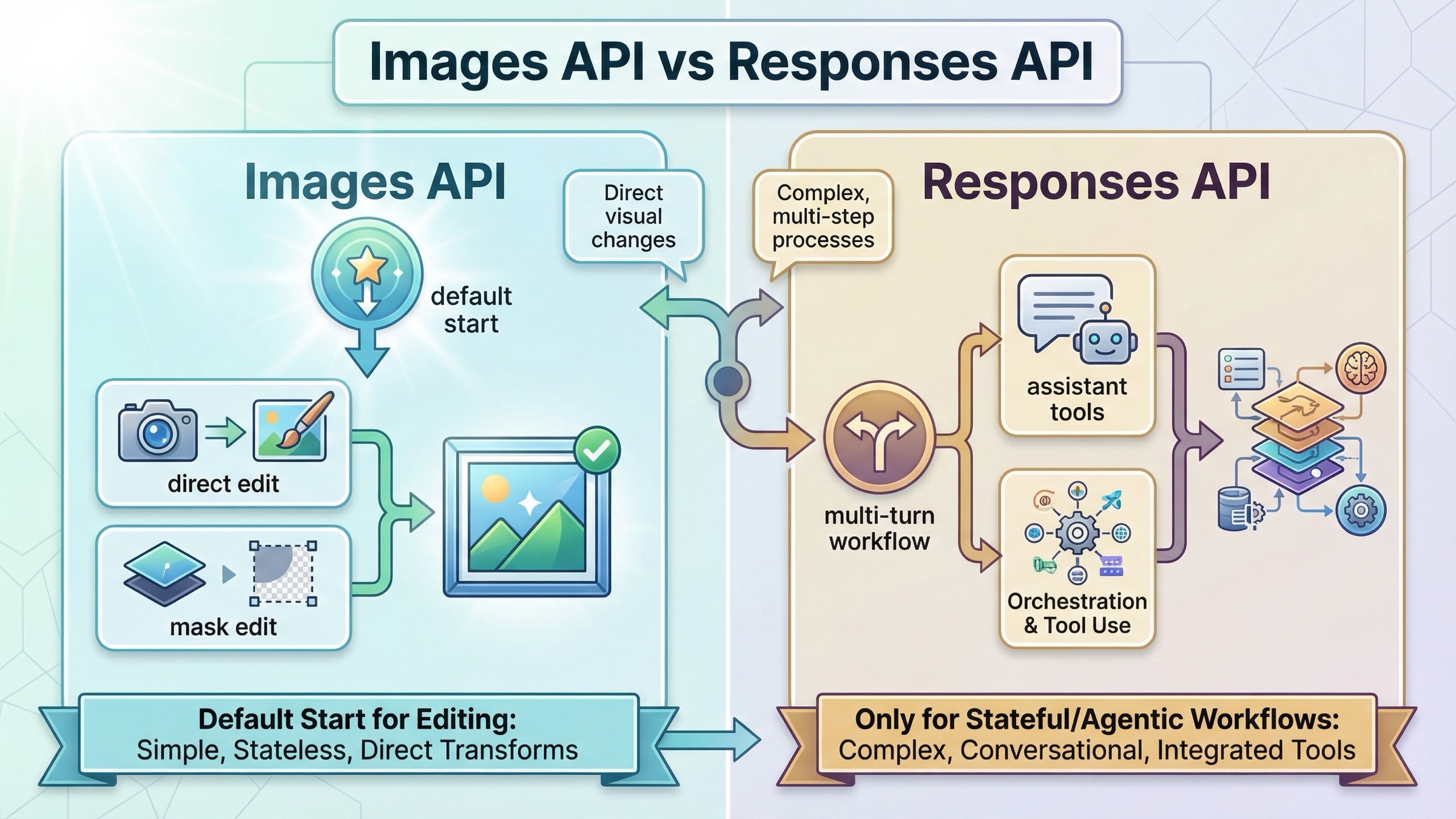
Aquí es donde muchos resultados de page one siguen siendo imprecisos.
| Situación | Mejor default | Por qué |
|---|---|---|
| Editar una o varias imágenes y guardar el output | Images API | Es la ruta directa más corta y el contrato del request se depura mejor |
| Insertar o sustituir un elemento preservando cara, logo o product shot | Images API | El flujo directo con input_fidelity=high es el setup más claro para preservar |
| Usar un mask para guiar dónde debe concentrarse la edición | Images API | Los masks, la subida multipart y el manejo del output ya son de primera clase aquí |
| Continuar una edición dentro de una conversación multi-turn usando el output previo | Responses API | El estado conversacional y el uso iterativo de tools se manejan mejor |
| Construir un assistant que razona, llama tools y a veces edita imágenes | Responses API | La edición se convierte en un tool dentro de un workflow mayor |
La regla más importante es sencilla: no empieces con Responses solo porque parezca más nuevo. La actual guía del tool deja claro que Responses está pensado para workflows de imagen más amplios. Incluso especifica que los modelos GPT Image no son válidos como model de nivel superior en Responses API. En Responses debes usar un modelo principal con capacidad de texto, como gpt-5, y dejar que el tool image_generation ejecute la edición o la generación.
Eso hace a Responses muy potente, pero también facilita elegir la abstracción equivocada. Si tu producto hoy solo necesita un endpoint de edición directa, estabiliza primero la ruta con Images API. Si más adelante el producto crece hacia multi-turn editing, memory o más tools, entonces sí Responses pasa a ser la mejor opción.
Elige el modo de edición antes de tocar el prompt
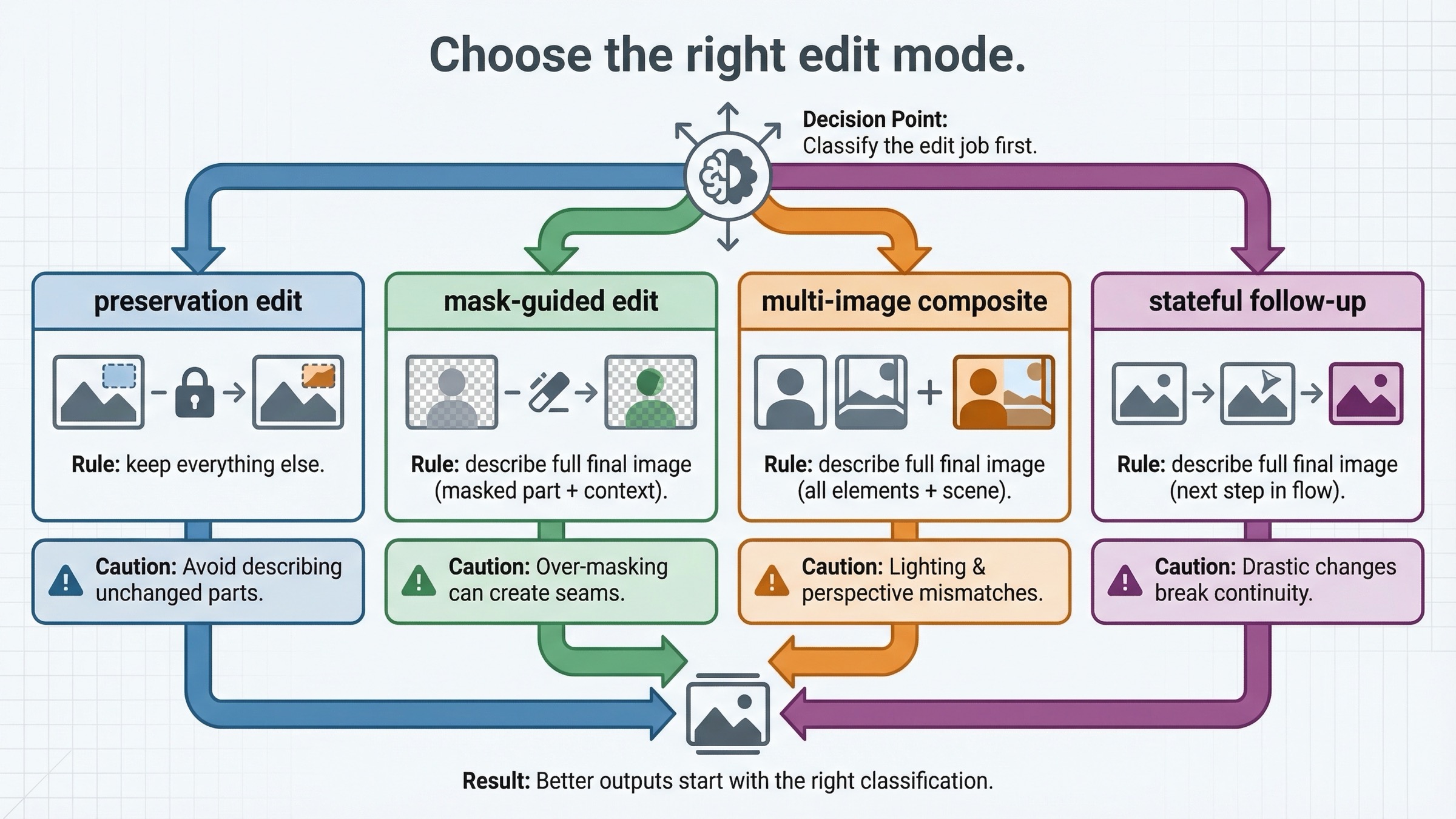
Muchos tutoriales flojos tratan “image editing” como si fuera una sola operación. No lo es. El prompt se vuelve mucho más claro cuando primero decides qué tipo de edición estás pidiendo.
El primer tipo es una preservation-heavy single-image edit. Ya tienes la escena y solo necesitas un cambio controlado: cambiar ropa, añadir un cartel, sustituir un póster, eliminar un elemento molesto, retocar el estilo de un objeto o ajustar el mood manteniendo la composición. En estos trabajos la preservation importa más que la creatividad, así que input_fidelity="high" suele merecer la pena.
El segundo tipo es una mask-guided edit. Aquí no solo le dices al modelo qué cambiar, sino también dónde mirar. Eso ayuda, pero no convierte a GPT Image en una herramienta determinista de parche local. El mask es una guía, no una garantía de que solo esos píxeles vayan a cambiarse en sentido estricto.
El tercer tipo es una multi-image reference o compositing edit. La guía actual y el cookbook de OpenAI muestran que puedes pasar más de una imagen y pedir al modelo que inserte, combine o arrastre rasgos de una imagen a otra. Así se construyen workflows como:
- poner el logo de la imagen dos sobre la camiseta de la imagen uno
- llevar el perro de la imagen dos a la escena de la imagen uno
- conservar el mismo producto, pero recolocarlo en otro entorno
El cuarto tipo es la iterative follow-up editing. Si el primer resultado ya está cerca, pero quieres seguir afinándolo dentro de una conversación, Responses empieza a tener más sentido. En ese caso lo importante es el contexto continuo, no solo un edit call aislado.
Conviene hacer esta distinción al principio porque cada modo necesita un estilo de prompt distinto. Una edición con mucha preservation necesita lenguaje explícito de “keep everything else”. Una edición con mask necesita una descripción de la imagen final completa más la guía espacial. Un compositing edit necesita atribución clara: qué tomar de cada input, qué conservar de la imagen base y qué no debe cambiar.
Cómo se comportan de verdad mask e input_fidelity

Esta es la parte que mucha gente está buscando de verdad, aunque no siempre la formule así.
El image generation guide actual de OpenAI dice que la imagen y el mask deben tener el mismo formato y tamaño, que el payload debe mantenerse por debajo de 50 MB y que el mask necesita un canal alpha. Pero la instrucción más importante es otra: describe la imagen final completa, no solo el área borrada.
Esa línea cambia por completo cómo debes pensar la API. Significa que el modelo no solo “rellena un hueco”. Interpreta la imagen fuente, el mask y el prompt juntos para producir un resultado final coherente.
Por eso las quejas de la comunidad no vienen de la nada. Un thread de OpenAI Developer Community del 27 de abril de 2025 decía que las masked edits se sentían como si regeneraran toda la imagen. En respuestas posteriores se citó a OpenAI Support explicando que el inpainting preciso seguía siendo una limitación conocida para gpt-image-1 en ese momento. Aunque GPT Image 1.5 es claramente mejor que GPT Image 1 en tareas con preservation, la lección operativa sigue siendo la misma: prueba los workflows con mask como un sistema de edición semántica, no como cirugía determinista por capas.
input_fidelity="high" ayuda cuando la edición debe preservar con más cuidado estilo y rasgos del input. OpenAI lo usa en la guía directa para el ejemplo de colocar un logo, y la guía actual de Azure OpenAI explica algo muy parecido: un input fidelity alto hace que el modelo trabaje más para conservar rasgos del input, especialmente faciales, durante edits sutiles. Por eso encaja bien en escenarios como:
- cambiar el fondo manteniendo intacto el producto
- cambiar la ropa de una persona preservando su identidad facial
- colocar un logo de marca sobre un objeto o prenda
- hacer un ajuste pequeño de escena sin perder camera angle ni composición
El tradeoff no es misterioso. Más esfuerzo de preservation suele implicar más coste y un comportamiento más conservador. Si la tarea no necesita preservar de forma estricta, no ganas mucho forzando high fidelity en todas partes.
La costumbre más útil es esta:
- empieza con un direct edit simple
- añade
input_fidelity=highsolo cuando la preservation importe - usa mask solo cuando la guía espacial importe
- mantén el prompt centrado en la imagen final, en los elementos que deben conservarse y en una o dos cosas que sí deben cambiar
Si el primer resultado ya está cerca, no saltes enseguida a un prompt gigante. Suele funcionar mejor una corrección de seguimiento más estrecha.
Las edits con mucha preservation funcionan mejor en pasos pequeños
La GPT Image 1.5 prompting guide actual es útil precisamente porque se comporta más como production advice que como lista de parámetros. En traducción, compositing, style preservation y scene changes, el patrón se repite: restricciones explícitas más cambios iterativos pequeños superan a la estrategia de meterlo todo en el primer request.
Eso también debería guiar cómo escribes prompts en producto.
Mal edit prompt:
textMake this look better, more modern, cleaner, more premium, maybe add some flowers, maybe change the colors, and make it suitable for a landing page.
Mejor prompt preservation-first:
textReplace only the poster on the wall with a framed abstract print. Preserve the room layout, furniture, lighting, floor shadows, and camera angle. Do not move or redesign any other object. Photorealistic interior photography.
Mejor prompt de compositing:
textPlace the logo from image 2 onto the front of the tote bag in image 1. Match the bag's fabric texture and lighting. Keep the model, pose, background, and camera framing unchanged.
Mejor prompt de follow-up:
textKeep the edited image exactly the same, but make the poster slightly larger and reduce glare on the frame. Do not change anything else.
Esa última línea importa mucho. Cuanto más valor tenga la imagen original, más deberías pensar como un operador que protege estado y menos como un prompt writer que persigue estilo.
Por eso también importa el post de OpenAI del 16 de diciembre de 2025. Allí OpenAI posicionó GPT Image 1.5 como más fuerte que GPT Image 1 para edits que conservan logos de marca, key visuals y consistencia facial. Eso no significa que cada prompt preservation-heavy vaya a salir perfecto. Significa que ahora la disciplina del prompt y la secuencia de edits pesan más que en la fase inicial de GPT Image 1.
Si después de esta página necesitas la decisión más amplia de routing entre image models, el siguiente paso natural es la guía en español sobre OpenAI image generation API models.
Troubleshooting: fallos que page one todavía deja a los foros
El primer fallo es empezar por la API surface equivocada. Si solo necesitas editar una imagen, no montes antes de tiempo un workflow con Responses ni pongas gpt-image-1.5 en el model de nivel superior. Ese no es el contrato correcto. Primero Images API directo; Responses después, si el producto realmente necesita un workflow mayor.
El segundo fallo es confiar en la página oficial equivocada para freshness. A 23 de marzo de 2026, la página de GPT Image 1.5 dice que es el latest image generation model, mientras que la guía más amplia de Images and vision todavía conserva la formulación vieja con gpt-image-1. Si tu documentación interna o tu artículo se apoya en la página equivocada, tu equipo puede parecer desactualizado aunque el código siga funcionando.
El tercer fallo es mandar JSON al raw edit endpoint. Los direct image edits son multipart form data. Si depuras con curl o con tu propio cliente HTTP, ese detalle no es opcional.
El cuarto fallo es tratar mask como una promesa dura en vez de una herramienta de guidance. Si tu workflow depende de parches diminutos con cero cambios colaterales, valida esa suposición pronto con muestras reales. No prometas comportamiento de producto solo porque la palabra “mask” aparece en la documentación.
El quinto fallo es escribir prompts que describen solo el objeto cambiado. La guía actual de OpenAI dice que describas la imagen final completa. Si solo escribes “add a beach ball”, el modelo tiene demasiada libertad sobre el resto de la escena.
El sexto fallo es mezclar access con sintaxis. GPT Image 1.5 sigue teniendo límites actuales por tier, y la página del modelo indica Free not supported. Si la request falla antes de devolver una imagen utilizable, confirma access antes de reescribir el prompt. Si sospechas que ese es tu bloqueo real, la lectura correcta es la guía en español sobre OpenAI image generation API verification.
El séptimo fallo es forzar demasiados cambios en un solo request. En tareas con mucha preservation, los compound prompts largos dificultan entender si el fallo vino de la composición, la preservation, el wording o el propio mask. Un edit y luego una follow-up correction siguen siendo una costumbre de producción más limpia.
FAQ
¿Debo usar gpt-image-1 o gpt-image-1.5 para edits ahora mismo?
Para trabajo nuevo de edición directa, usa gpt-image-1.5. A 23 de marzo de 2026, la página actual de GPT Image 1.5 lo presenta como latest image generation model, mientras que solo páginas oficiales más viejas siguen mencionando gpt-image-1. Deja gpt-image-1 para mantener o comparar workflows antiguos.
¿Por qué mi mask edit cambia más que el área enmascarada?
Porque las edits de GPT Image son guided semantic rewrites, no parches locales garantizados pixel a pixel. La guía actual de OpenAI pide describir la imagen final completa, y los threads de la comunidad muestran que los usuarios siguen viendo rerenders más amplios cuando esperaban inpainting con límites duros.
¿Necesito input_fidelity=high para cada edit?
No. Úsalo cuando preservar caras, logos, geometría de producto, camera angle u otra identidad visual importante importe más que velocidad o coste. Si la tarea es más generativa y no te importa que el modelo restylee más, no hace falta activarlo siempre.
¿Cuándo debería moverme de Images API a Responses?
Muévete a Responses cuando la edición forme parte de una conversación multi-turn, de un assistant workflow o de un producto más amplio que usa tools. Quédate en Images API directo cuando la edición de imagen sea la feature que estás intentando shippear.
Recomendación final
La regla limpia hoy es esta: si quieres editar imágenes con OpenAI API, empieza por images.edit() más gpt-image-1.5, no por un workflow más amplio con Responses. Usa mask para guiar dónde debe enfocarse el modelo, pero escribe los prompts como si estuvieras especificando la imagen final completa. Añade input_fidelity=high cuando la preservation sea el trabajo, no como valor por defecto en cada request.
Eso es precisamente lo que page one todavía suele dejar difuso. La respuesta ganadora no es “OpenAI puede editar imágenes”. La respuesta ganadora es “esta es la ruta directa de edición, así es cuando debes usar la ruta alternativa y esto es lo que mask no garantiza”.
Si después de esta página quieres la visión más amplia de la surface, sigue con el tutorial OpenAI Image API en español. Si lo siguiente que necesitas son ejemplos de generación que funcionen hoy, pasa a la página de OpenAI image generation API example.