
先说结论:截至 2026 年 3 月 19 日,如果你最在意的是低成本、高速度和高吞吐推理任务,Gemini 3.1 Flash-Lite 更值得优先试用;如果你更在意 Stable 生命周期、免费 Google Search grounding 和更可预测的生产行为,Gemini 2.5 Flash 仍然是更稳的默认盘。 这个关键词真正要解决的不是“谁更强”这么抽象的问题,而是“我要不要把现有 2.5 Flash 路由整体换掉”。
之所以容易误判,是因为很多人看到 Flash-Lite 这个名字,会本能地把它理解成“比旧的完整 Flash 更弱的一档”。但 Google 当前官方文档给出的信号恰恰更复杂。价格页显示 3.1 Flash-Lite 比 2.5 Flash 更便宜,DeepMind 的对比页又显示它在速度和多项 benchmark 上更强;可同一批官方材料里,2.5 Flash 依然保留 Stable/GA、免费 Search grounding,以及 FACTS 和 1M MRCR 上的领先。这不是一场“新款秒杀旧款”的发布会故事,而是一道标准的路由决策题。
要点速览
如果你只想看实用答案,可以直接记住这句话:高频、低延迟、以翻译/抽取/分类/路由为主的任务,优先试 Gemini 3.1 Flash-Lite;依赖 grounding、追求 Stable、或者对 1M 长上下文更谨慎的任务,优先保留 Gemini 2.5 Flash。
2026 年 3 月 19 日的官方对比可以压缩成下面这张表:
| 维度 | Gemini 3.1 Flash-Lite | Gemini 2.5 Flash | 实际含义 |
|---|---|---|---|
| 当前状态 | Preview | Stable / GA | 3.1 更新更快,但 2.5 仍是更稳妥的生产默认 |
| Model ID | gemini-3.1-flash-lite-preview | gemini-2.5-flash | 不要盲目热切换,应该显式路由 |
| 标准输入价格 | 免费,之后 $0.25 / 1M | 免费,之后 $0.30 / 1M | 3.1 输入更便宜 |
| 标准输出价格 | 免费,之后 $1.50 / 1M | 免费,之后 $2.50 / 1M | 3.1 输出便宜很多 |
| 上下文窗口 | 1,048,576 tokens | 1,048,576 tokens | 上限不是关键差异点 |
| 最大输出 | 65,536 tokens | 65,536 tokens | 输出上限也相同 |
| 免费层 grounding | 无免费 Search grounding | Search grounding 免费到 500 RPD | 2.5 对 grounded assistant 更友好 |
| 官方速度对比 | 363 tokens/s | 249 tokens/s | 3.1 速度领先 |
| 关键 caveat | GPQA、MMMU-Pro、LiveCodeBench、128k MRCR 更强 | FACTS 与 1M MRCR 更强 | 3.1 不是“全指标通吃” |
这些信息来自官方 Gemini API pricing、Gemini 3.1 Flash-Lite model page、Gemini 2.5 Flash model page、release notes 与 DeepMind 的 Flash-Lite comparison page。
最可执行的建议其实很简单:
- 想先吃到速度和成本红利,就先把翻译、抽取、路由这些高吞吐任务迁到 3.1 Flash-Lite。
- 依赖免费 grounding、面向真实用户、或者对 Preview 变动更敏感的链路,继续保留 2.5 Flash。
- 能做分流就别单选。2026 年 3 月 19 日最稳的答案就是双路由。
为什么这个对比会让人误判
这个关键词的奇怪之处在于,它不是“同代同档”的整齐对比。更自然的名字对应该是 Gemini 3.1 Flash-Lite vs Gemini 2.5 Flash-Lite,或者 Gemini 3 Flash vs Gemini 2.5 Flash。但真实团队关心的不是命名学,而是“我现在在用的 2.5 Flash,会不会被 3.1 Flash-Lite 替掉”。
这也是为什么 2.5 Flash 才是这里真正的基线。它一直是 Gemini API 里成熟、低延迟、好上手的 reasoning 型默认盘。官方 Gemini 2.5 Flash 页面 仍然把它放在 Stable 版本里,而 Gemini 2.5 Flash model card 还明确写着 general availability。
Gemini 3.1 Flash-Lite 的定位则完全不同。Google 在官方 release notes 里写明,它于 2026 年 3 月 3 日上线,是 Gemini 3 系列里的第一款 Flash-Lite。官方 model page 直接把它定位在翻译、转写、简单文档处理、高吞吐结构化抽取和模型路由这些任务上。也就是说,Google 自己并没有把它包装成“玩具 Lite”,而是在把它推成一个更快、更便宜的生产车道。
所以比较的正确心智模型应该是:
- Gemini 2.5 Flash 是稳定工作马。
- Gemini 3.1 Flash-Lite 是更快更便宜的 Preview 挑战者。
- 问题不是谁更像“旗舰”,而是谁更适合你当前的路由组合。
2026 年 3 月 19 日的价格、免费层与 grounding

大多数搜索结果只说对了一半:它们知道 3.1 Flash-Lite 比 2.5 Flash 便宜,但没有把真正影响部署的那一半讲透。
按照官方 pricing 页面,截至 2026 年 3 月 19 日:
- Gemini 3.1 Flash-Lite Preview:标准调用免费,之后输入
\$0.25/ 1M,输出\$1.50/ 1M - Gemini 2.5 Flash:标准调用免费,之后输入
\$0.30/ 1M,输出\$2.50/ 1M
这意味着:
- 输入成本大约便宜 17%
- 输出成本便宜 40%
对于摘要、分类、带理由的判定、JSON 抽取、客服短回复这类输出占比不低的任务,输出价格往往比输入价格更影响月账单,所以 3.1 Flash-Lite 的优势并不是“纸面上便宜一点”,而是很多流水线里真正能省到钱。
Batch 价格也保持同样方向:
- 3.1 Flash-Lite Batch:
\$0.125输入,\$0.75输出 - 2.5 Flash Batch:
\$0.15输入,\$1.25输出
如果你的任务是异步批处理,3.1 依旧是更省的一侧。
但价格页同时也解释了为什么 2.5 Flash 还没有被彻底替掉。关键差异不是 token,而是 grounding。官方页面显示:
- Gemini 2.5 Flash 仍然提供免费层 Google Search grounding,额度写到 500 RPD
- Gemini 3.1 Flash-Lite Preview 没有免费 Search grounding,而是按每月 5,000 prompts 的付费层免费额度后再收费
这会直接改变 grounded assistant 的默认选型。如果你的应用严重依赖内置 Google Search 工具,2.5 Flash 的免费层故事明显更顺手,试验和早期部署成本也更低。如果你根本不依赖 grounding,而更看重吞吐和响应速度,那 3.1 Flash-Lite 的价格优势就会变得非常明显。
如果你还要单独研究 Gemini API 的整体价格结构,中文环境里可以继续看我们的 Google Gemini API 定价 2026 指南。如果你关心免费层本身现在还剩下什么,相关背景在 Gemini API 免费额度 2026 里已经单独拆过。
基准测试:3.1 Flash-Lite 赢在哪里,2.5 Flash 为什么还没过时
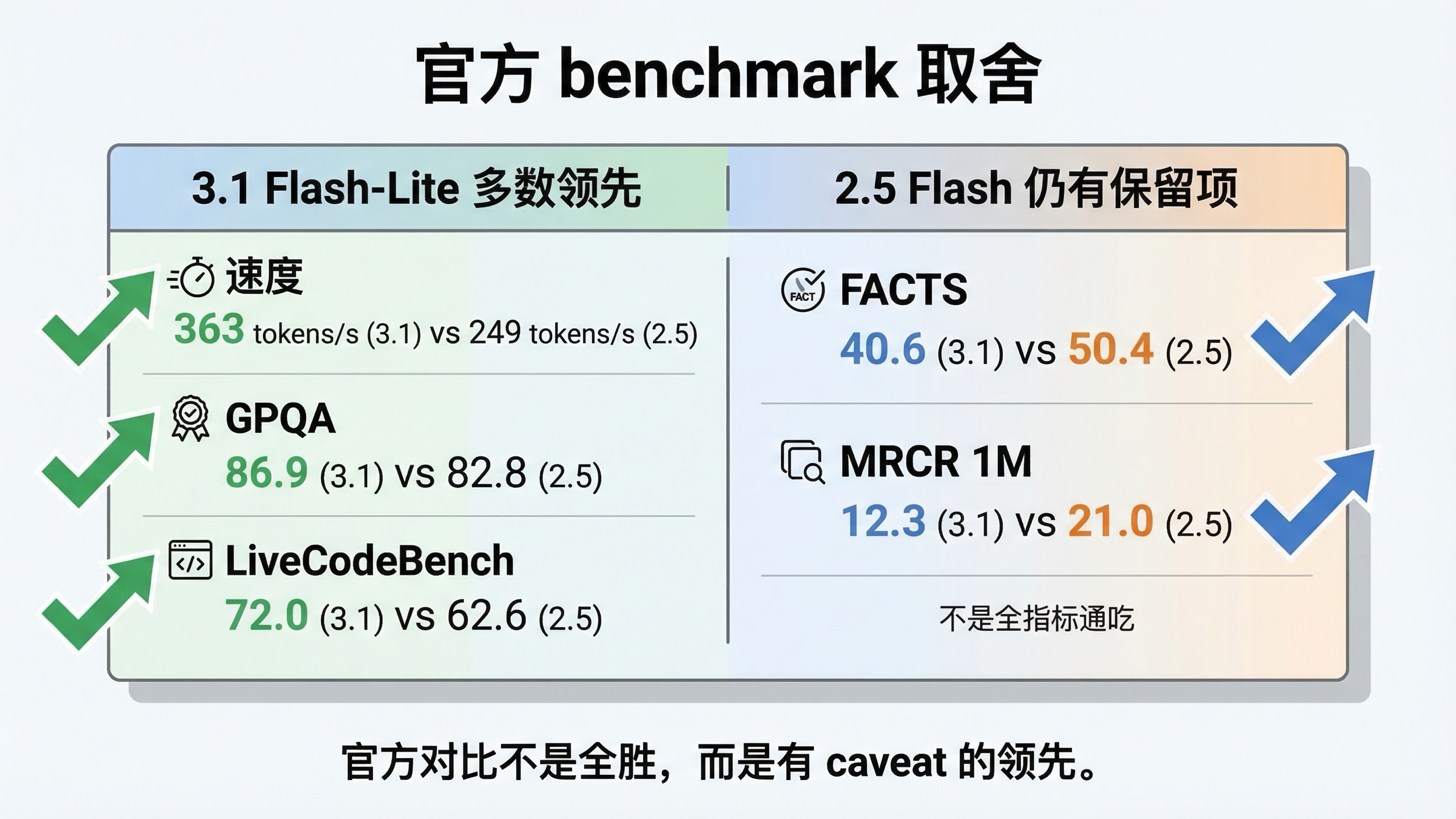
这组比较里最有价值的官方页面,其实是 DeepMind 的 Gemini 3.1 Flash-Lite page。它把 Gemini 3.1 Flash-Lite High 与 Gemini 2.5 Flash Dynamic 放在同一张表上,比很多转述文章更适合直接做工程判断。
真正该看的几行如下:
| 指标 | Gemini 3.1 Flash-Lite | Gemini 2.5 Flash | 倾向 |
|---|---|---|---|
| 输出速度 | 363 tokens/s | 249 tokens/s | 3.1 Flash-Lite |
| Humanity's Last Exam | 16.0% | 11.0% | 3.1 Flash-Lite |
| GPQA Diamond | 86.9% | 82.8% | 3.1 Flash-Lite |
| MMMU-Pro | 76.8% | 66.7% | 3.1 Flash-Lite |
| LiveCodeBench | 72.0% | 62.6% | 3.1 Flash-Lite |
| MRCR v2 at 128k | 60.1% | 54.3% | 3.1 Flash-Lite |
| FACTS | 40.6% | 50.4% | Gemini 2.5 Flash |
| MRCR v2 at 1M | 12.3% | 21.0% | Gemini 2.5 Flash |
所以最重要的判断不是“3.1 赢没赢”,而是“它赢的是哪些任务、又输在哪些任务”。
对想迁移的人来说,正面信号很明显:
- 3.1 更快
- 3.1 更便宜
- 3.1 在 reasoning、coding、multimodal 这些高曝光 benchmark 上多数领先
但 2.5 的保留理由也不是虚的。官方表里它仍然在:
- FACTS 上更强,这和 grounded factuality 更接近
- 1M MRCR 上更强,这对真正吃长文档的工作流有现实意义
所以我不会建议团队在第一天就把 2.5 Flash 全量删除。如果你的产品本身严重依赖 grounded answer,或者你的评测集中在真正接近 1M context 的长文档检索,2.5 Flash 依旧有继续存在的充分理由。
Google 自己在官方 launch post 里给出的叙事也很清楚:3.1 Flash-Lite 相比 2.5 Flash 有 2.5 倍更快的首 token 时间 和 45% 更高的输出速度。这些 headline 数字确实有吸引力,但并没有抹掉上面那些 caveat 行。
Preview 风险、速率限制,以及 Stable 仍然值钱的地方
生产选型不可能只看 benchmark。生命周期状态仍然很重要。
官方 rate limits 页面 里有三条很容易被忽略的信息:
- 限额按 project 计算,不是按 API key 计算
- Preview 模型通常有更严格的速率限制
- 页面明确写着 specified rate limits are not guaranteed and actual capacity may vary
这就是 “Preview” 在工程语境里的真正含义。它不等于不能上生产,但确实意味着你应该把它看成一个变化中的车道,而不是已经沉淀成默认基线的车道。
同一张限额页上也有一个对 3.1 有利的信号:Tier 1 的 Batch API 表格里,
- Gemini 3.1 Flash-Lite Preview:10,000,000 enqueued batch tokens
- Gemini 2.5 Flash:3,000,000 enqueued batch tokens
如果你做的是大规模异步批处理,这是一条真实的吞吐优势。但它依然不是无限制承诺,因为官方同页也强调实际容量会波动。
Stable 仍然值钱,主要体现在三件事上:
- 生命周期更稳。2.5 Flash 仍被列在 Stable 版本里,3.1 Flash-Lite 明确是 Preview。
- 公开 grounding 故事更清晰。价格页上,2.5 Flash 仍然保留免费层 Search grounding。
- 更容易做默认盘解释。当客户链路出问题时,“我们保留了稳定模型为默认”比“我们为了 benchmark 提升把 Preview 提上去了”更容易自证合理。
如果你还想深入看 thinking 控制的差异,当前仓库里这部分仍然主要是英文资料,可以参考英文版 Gemini API thinking-level guide。同样,速率限制的更细拆解目前也是英文版更完整,对应是 Gemini API rate-limits-per-tier guide。
不同工作负载该选哪个模型
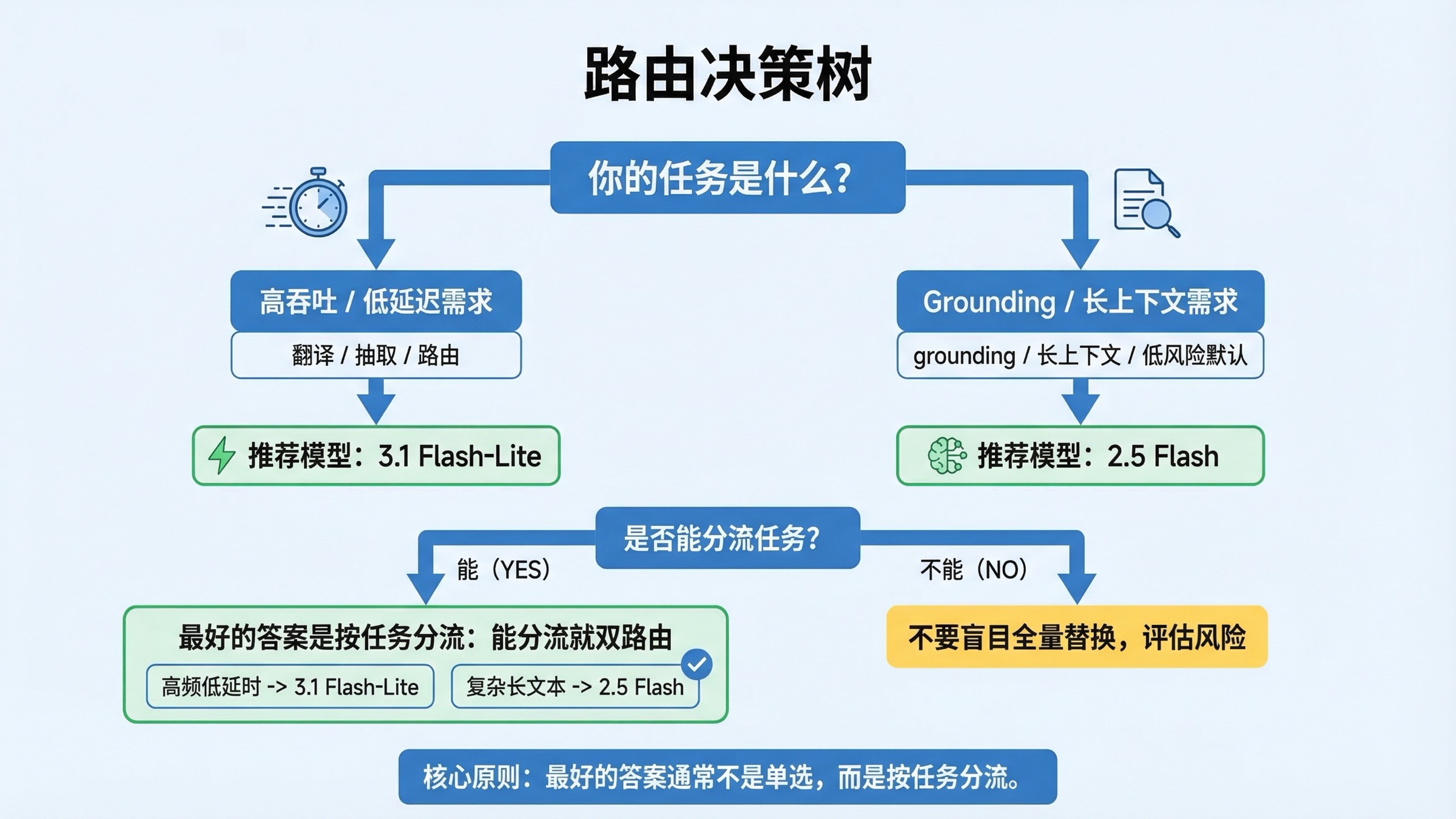
把这篇文章变得真正有用的方式,不是再贴一遍 benchmark,而是直接给路由建议。
| 工作负载 | 优先选项 | 原因 |
|---|---|---|
| 大规模翻译 | Gemini 3.1 Flash-Lite | 官方就把 translation 列为最佳场景,价格与速度也正好匹配 |
| 结构化抽取 / JSON pipeline | Gemini 3.1 Flash-Lite | 输出更便宜、延迟更低,比 Stable 生命周期更关键 |
| 路由层 / 分类层 | Gemini 3.1 Flash-Lite | 官方 model page 直接把 routing 作为适配场景 |
| 轻量 coding / UI 生成 | Gemini 3.1 Flash-Lite | LiveCodeBench 更强,速度也更占优 |
| Search-grounded factual assistant | Gemini 2.5 Flash | 免费 grounding 与 FACTS 优势让它更适合起步 |
| 接近 1M context 的超长文档任务 | Gemini 2.5 Flash | 官方 MRCR 1M 行仍然更强 |
| 风险容忍度低的大盘生产默认 | Gemini 2.5 Flash | Stable / GA 的价值仍然真实存在 |
| 能做按任务分流的系统 | 两者都用 | 2.5 管 grounding / 长上下文,3.1 管高速高吞吐 |
再补一个容易被忽略的细节:thinking 控制模型不同。 官方 Gemini 2.5 Flash model card 把 2.5 Flash 描述为可配置 thinking budget 的 hybrid reasoning model;而 3.1 Flash-Lite 的发布叙事则更强调 reasoning levels。如果你的系统本身高度依赖推理预算调参,这部分不能只看价格表。
怎样迁移才不会后悔
2026 年 3 月最稳的迁移策略不是“全量切换”,而是分三层推进。
-
先迁低风险高吞吐任务
把翻译、抽取、分类、路由这些流水线先迁到 3.1 Flash-Lite。这里最容易马上吃到速度和成本收益,而且就算出现波动,也比面向用户的 grounded assistant 更容易回滚。 -
保留 grounded 与超长上下文链路在 2.5 Flash
只要你还依赖免费 Search grounding,或者你自己的评测在 1M context 附近对检索能力很敏感,就不要急着把 2.5 Flash 从默认盘里删除。 -
保留回退与回归测试车道
不要因为 3.1 在公开表格里更亮眼,就把 2.5 路由直接删掉。至少在你自己的 prompt、延迟预算、错误模式都重新跑完之前,应该留一个清晰的 fallback。相关的工程排错可以继续看中文版 Gemini API 错误排查指南。
一句话总结最可执行的迁移原则:
- 成本和速度是瓶颈:优先迁到 3.1
- grounding、超长上下文、稳定性更重要:继续保留 2.5
- 工程能力允许分流:同时保留两条车道,不要硬选一个
常见问题
Gemini 3.1 Flash-Lite 一定比 Gemini 2.5 Flash 更好吗?
不一定。如果你的“更好”定义是更快输出、更低 token 成本、更多 benchmark 领先,那多数情况下是的;如果你的定义包含 Stable 状态、免费 Search grounding、FACTS 表现和 1M context 行为,那 2.5 Flash 仍然可能更好。
Gemini 3.1 Flash-Lite 真的更便宜吗?
是的,但这里的比较对象是 Gemini 2.5 Flash,不是 2.5 Flash-Lite。官方价格页写得很清楚:3.1 Flash-Lite 是 \$0.25 输入、\$1.50 输出,而 2.5 Flash 是 \$0.30 输入、\$2.50 输出。
为什么 3.1 更强了,还不建议所有人立刻全量替换?
因为它仍然是 Preview,而且同一套官方对比里,2.5 Flash 在 FACTS 和 1M MRCR 上仍然领先。如果你的产品更看重 grounded factuality 或长上下文稳定性,这两个 caveat 就不能当作小字忽略。
现在最稳的做法是什么?
最稳的是分流:把高吞吐、低延迟、低风险任务先迁到 3.1 Flash-Lite,把 grounded、长上下文、风险敏感任务继续留在 2.5 Flash。这样做最符合 2026 年 3 月 19 日官方资料反映出来的真实情况。