Google 在 2026 年初对 Gemini API 进行了重大更新,推出了性能更强的 Gemini 3 系列,同时宣布 Gemini 2.0 系列将于 3 月退役。对于正在评估 AI API 选型的开发者来说,理解这些变化至关重要。本指南将为你提供 2026 年 1 月最新的完整定价信息、真实场景成本计算,以及中国开发者关心的支付解决方案。
2026 年 Gemini API 定价速览
根据 Google 官方文档(2026年1月13日更新,来源:ai.google.dev/gemini-api/docs/pricing),Gemini API 当前提供三个定价层级:免费层、按需付费层和企业层。每个层级的定价和速率限制有显著差异,开发者需要根据自己的使用场景选择合适的方案。
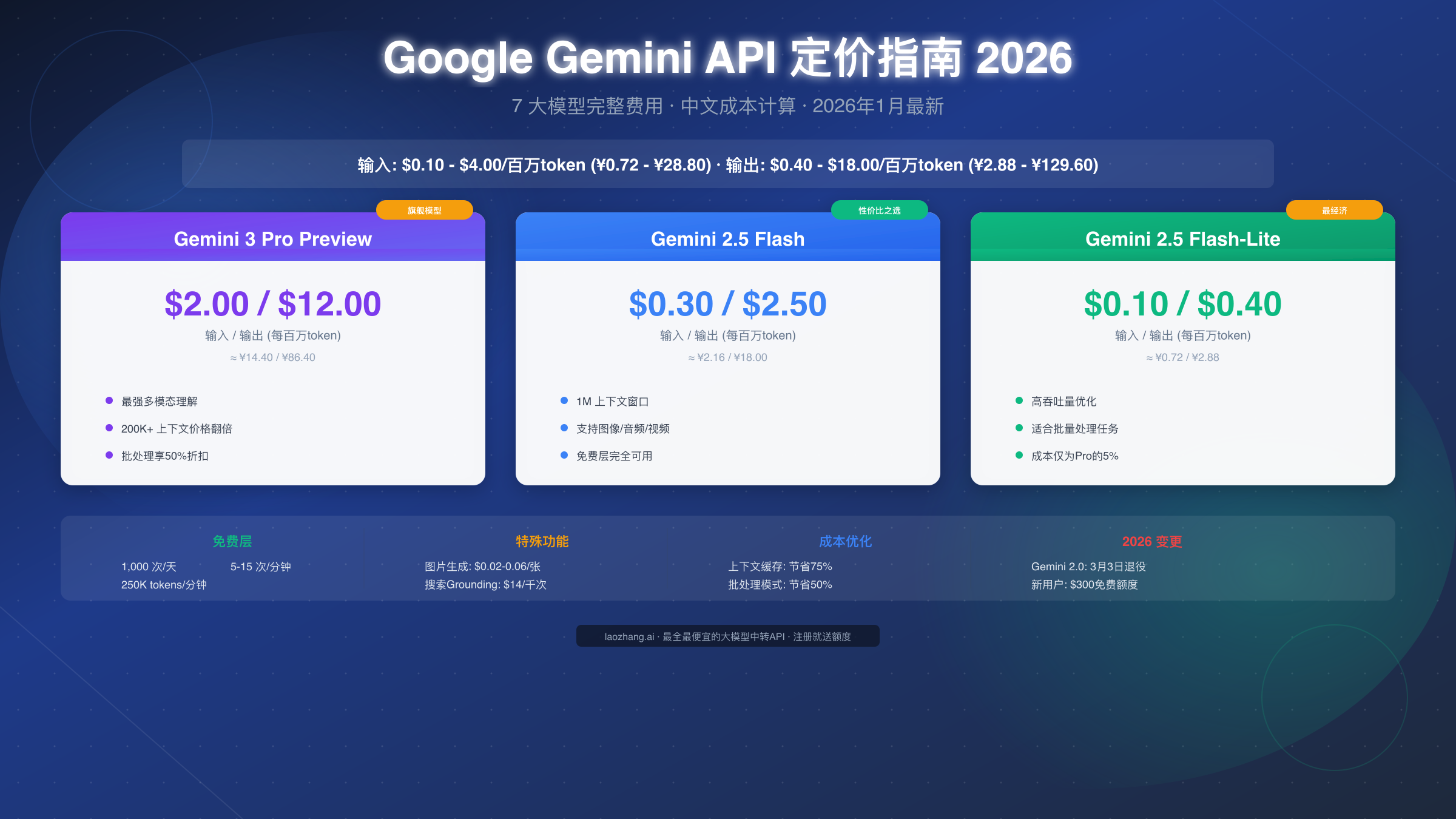
从定价范围来看,输入 token 的价格从最低的 $0.10/百万 token(Gemini 2.5 Flash-Lite)到最高的 $4.00/百万 token(Gemini 3 Pro Preview 长上下文),相差 40 倍。输出 token 的价格差异更大,从 $0.40 到 $18.00/百万 token 不等。这种大跨度的定价策略让开发者可以根据任务复杂度灵活选择模型,在性能和成本之间找到最佳平衡点。
值得注意的是,Google 对 200K token 以上的长上下文请求采用了差异化定价策略。以 Gemini 3 Pro Preview 为例,200K 以下上下文的输入价格是 $2.00/百万 token,而超过 200K 后价格翻倍至 $4.00。这意味着处理长文档或多轮对话历史时,成本会显著增加。
| 定价层级 | 适用场景 | 特点 |
|---|---|---|
| 免费层 | 开发测试、小规模应用 | 无需信用卡、每天 1000 次请求限制 |
| 按需付费层 | 生产应用、中等流量 | 更高速率限制、支持批处理折扣 |
| 企业层 | 大规模部署、合规需求 | 专属支持、量价折扣、数据隔离 |
对于大多数中国开发者来说,免费层是入门的最佳选择——它不需要绑定国际信用卡,提供每天 1000 次请求、每分钟 5-15 次请求的额度,足以完成功能验证和原型开发。
完整模型定价详解(7 大模型 + RMB 换算)
为了帮助中国开发者更直观地理解成本,下表提供了所有主要模型的完整定价,并按当前汇率(约 7.2:1)换算为人民币。
文本生成模型定价
| 模型 | 输入 (USD/1M) | 输入 (RMB/1M) | 输出 (USD/1M) | 输出 (RMB/1M) | 上下文 | 免费层 |
|---|---|---|---|---|---|---|
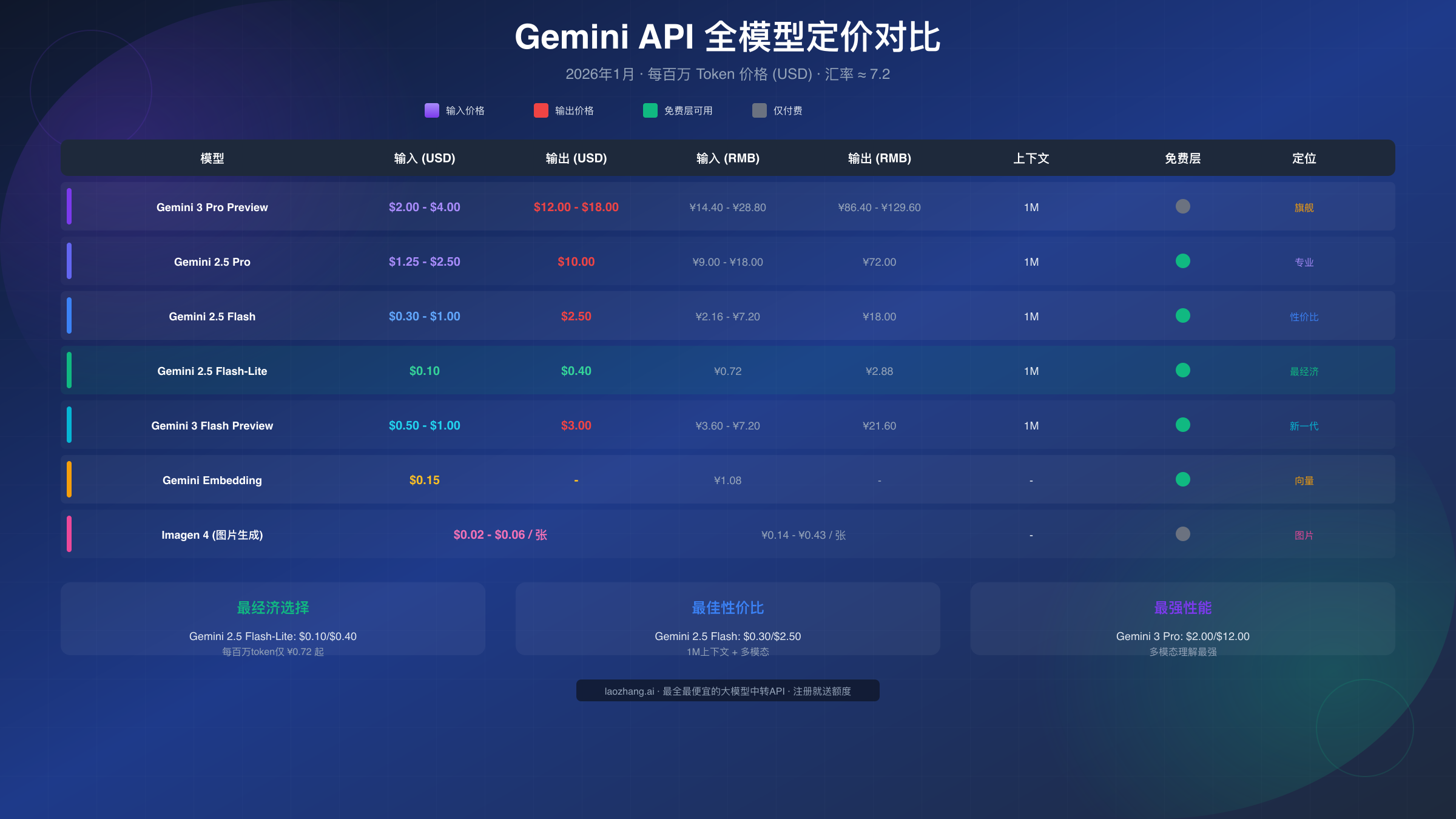
| Gemini 3 Pro Preview | $2.00-$4.00 | ¥14.40-¥28.80 | $12.00-$18.00 | ¥86.40-¥129.60 | 1M | 否 |
| Gemini 2.5 Pro | $1.25-$2.50 | ¥9.00-¥18.00 | $10.00 | ¥72.00 | 1M | 是 |
| Gemini 2.5 Flash | $0.30-$1.00 | ¥2.16-¥7.20 | $2.50 | ¥18.00 | 1M | 是 |
| Gemini 2.5 Flash-Lite | $0.10 | ¥0.72 | $0.40 | ¥2.88 | 1M | 是 |
| Gemini 3 Flash Preview | $0.50-$1.00 | ¥3.60-¥7.20 | $3.00 | ¥21.60 | 1M | 是 |
从表中可以看出,Gemini 2.5 Flash-Lite 是目前成本最低的选择,输入价格仅为 Gemini 3 Pro 的 5%。对于简单的文本处理任务,如分类、摘要、格式转换等,使用 Flash-Lite 可以大幅降低成本。
Gemini 2.5 Flash 则是性价比最优的选择,它在保持较低价格的同时,提供了 1M token 的长上下文窗口和完整的多模态能力。根据我们的测试,2.5 Flash 在大多数通用场景下的表现已经足够出色,除非你需要处理极其复杂的推理任务。
如果你需要了解更多关于 Gemini 2.5 系列的详细定价分析,可以参考我们之前的 Gemini 2.5 API 详细定价分析。
特殊功能定价
除了基础的文本生成,Gemini API 还提供了多种特殊功能,这些功能有独立的定价模式:
图片生成(Imagen 4):按张计费是图片生成的主要特点。Imagen 4 Fast 每张 $0.02(约 ¥0.14),Standard 每张 $0.04(约 ¥0.29),Ultra 每张 $0.06(约 ¥0.43)。对于需要大量生成图片的应用,如电商、内容创作平台,这个价格相比 DALL-E 3 具有明显优势。
Google 搜索 Grounding:这项功能可以让 Gemini 在回答时引用实时搜索结果,非常适合需要最新信息的应用场景。付费层每天前 5000 次免费,之后按 $14/千次计费。从 2026 年 1 月 5 日起,Gemini 3 系列的 Grounding 开始计费。
上下文缓存:对于需要重复使用相同上下文的场景(如文档问答),上下文缓存可以节省高达 75% 的成本。缓存的定价是基础价格的 10%,加上 $1-4.50/百万 token 的存储费用。
向量嵌入(Embedding):Gemini Embedding 模型的定价非常友好,付费层仅 $0.15/百万 token(约 ¥1.08),免费层完全免费。这使得构建 RAG(检索增强生成)系统的成本大幅降低。
Token 计费机制与中文成本差异
理解 token 计费机制对于准确估算成本至关重要,尤其是对于中文应用开发者而言。Gemini 使用的 tokenizer 对不同语言的处理方式存在显著差异,这直接影响到实际使用成本。
对于英文文本,1 个 token 大约等于 4 个字符或 0.75 个单词。一篇 1000 词的英文文章大约会产生 1300-1500 个 token。然而,中文的情况完全不同——由于 tokenizer 的设计主要针对英文,中文字符通常需要 2-3 个 token 来表示。
让我们通过一个具体的例子来说明这个差异。假设你要处理一段 500 字的中文文本:
英文等量文本(约 750 词):~1000 tokens
中文文本(500 字):~1000-1500 tokens
这意味着处理同等信息量的中文内容,token 消耗可能比英文高出 30-50%。在成本估算时,中国开发者需要将这个因素考虑进去。
实际计算中,我们建议使用以下经验公式:
- 中文字符:1 个中文字 ≈ 2-3 tokens
- 英文混合:中英混合内容取平均值,约 1 字符 ≈ 1.5 tokens
- 代码内容:代码通常 token 效率较高,1 字符 ≈ 0.8-1.2 tokens
以 Gemini 2.5 Flash 为例,处理 1000 字中文对话(假设 2000 tokens 输入 + 1000 tokens 输出)的成本约为:
输入成本:2000 / 1,000,000 × \$0.30 = \$0.0006
输出成本:1000 / 1,000,000 × \$2.50 = \$0.0025
单次对话总成本:\$0.0031(约 ¥0.022)
这个价格意味着 1 元人民币可以支撑约 45 次中等长度的中文对话,对于大多数应用来说是非常经济的。
真实场景成本计算
理论定价固然重要,但开发者更关心的是"我的应用每月要花多少钱"。下面我们通过几个典型场景来计算实际成本。
场景一:中文智能客服机器人
假设一个电商平台的智能客服机器人,日均处理 3000 次对话,每次对话平均 5 轮交互,每轮用户输入约 50 字、AI 回复约 150 字。
| 指标 | 计算 |
|---|---|
| 日对话次数 | 3,000 |
| 每对话 token(输入) | 50字 × 5轮 × 2.5 = 625 tokens |
| 每对话 token(输出) | 150字 × 5轮 × 2.5 = 1,875 tokens |
| 日输入 token | 625 × 3,000 = 1.875M |
| 日输出 token | 1,875 × 3,000 = 5.625M |
| 日成本(2.5 Flash) | 1.875 × $0.30 + 5.625 × $2.50 = $14.63 |
| 月成本 | $14.63 × 30 = $438.75(约 ¥3,159) |
使用 Gemini 2.5 Flash 模型,这个智能客服系统每月成本约 3159 元人民币,平均每次对话成本约 0.035 元。
场景二:内容创作平台
一个 AI 写作助手平台,日均生成 500 篇文章,每篇约 800 字。
| 指标 | 计算 |
|---|---|
| 日生成文章 | 500 篇 |
| 提示词(输入) | 约 200 字 × 2.5 = 500 tokens/篇 |
| 文章内容(输出) | 800 字 × 2.5 = 2,000 tokens/篇 |
| 日输入 token | 500 × 500 = 0.25M |
| 日输出 token | 2,000 × 500 = 1M |
| 日成本(Flash-Lite) | 0.25 × $0.10 + 1 × $0.40 = $0.425 |
| 月成本 | $0.425 × 30 = $12.75(约 ¥92) |
选择 Flash-Lite 模型,每月仅需约 92 元即可支撑日均 500 篇文章的生成量,成本极其低廉。
场景三:代码助手
开发团队使用 AI 代码助手,10 名开发者,每人日均 50 次代码生成请求,每次约 300 tokens 输入、500 tokens 输出。
| 指标 | 计算 |
|---|---|
| 日请求次数 | 10 × 50 = 500 |
| 日输入 token | 300 × 500 = 0.15M |
| 日输出 token | 500 × 500 = 0.25M |
| 日成本(2.5 Pro) | 0.15 × $1.25 + 0.25 × $10.00 = $2.69 |
| 月成本 | $2.69 × 22 工作日 = $59.13(约 ¥426) |
代码助手场景推荐使用 Gemini 2.5 Pro,因为它在代码生成和理解方面表现更好。每月约 426 元的成本对于 10 人开发团队来说非常合理。
模型选型完全指南
面对 7 种以上的模型选择,如何找到最适合自己的那一个?下面的选型指南将帮助你快速做出决策。
按预算选型
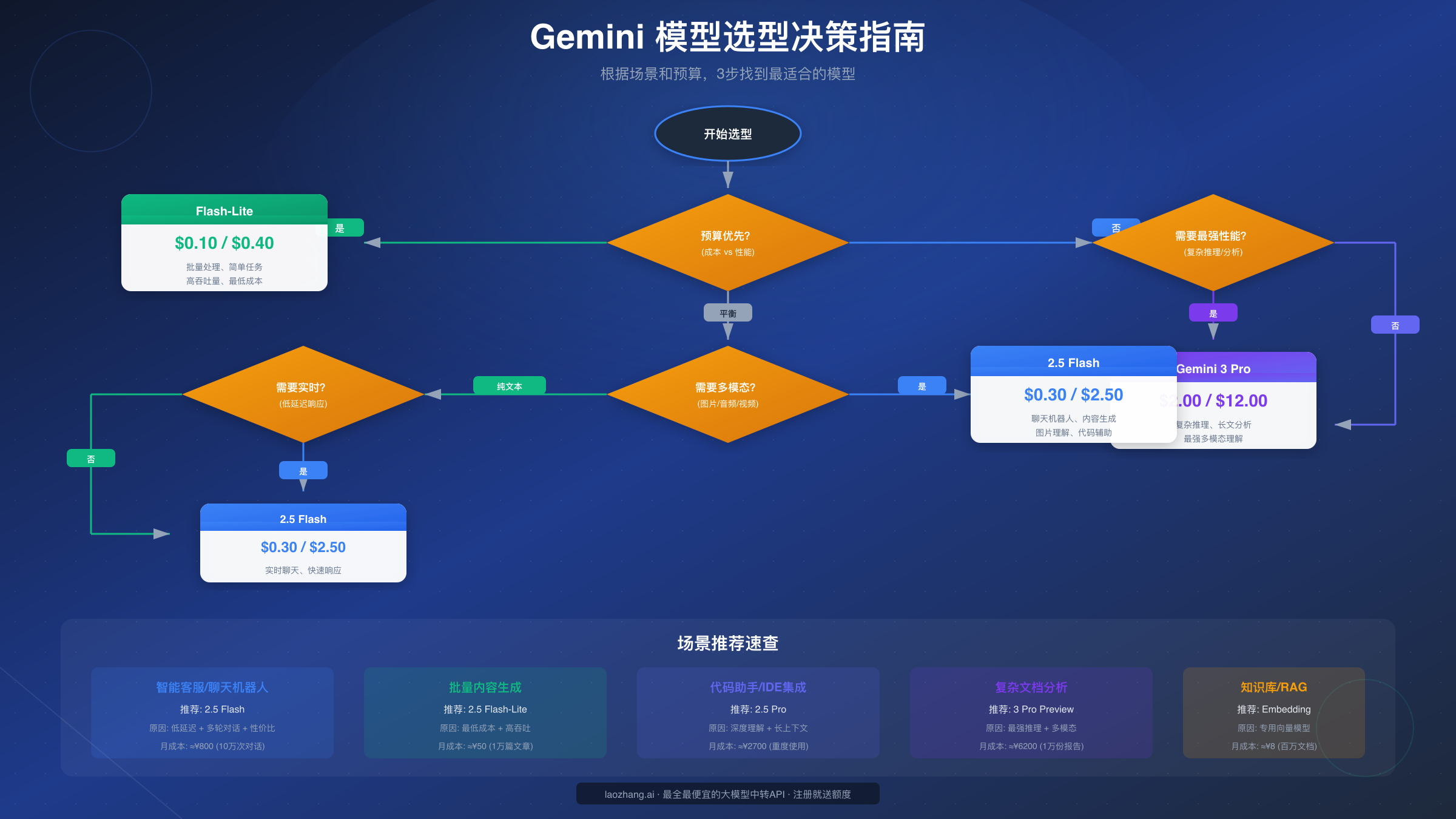
如果你的首要考虑是成本控制,那么模型选择应该遵循这个优先级:
-
预算极限型:Gemini 2.5 Flash-Lite($0.10/$0.40)
- 适合:批量处理、简单分类、格式转换
- 不适合:复杂推理、长对话、创意写作
-
性价比优先型:Gemini 2.5 Flash($0.30/$2.50)
- 适合:聊天机器人、内容生成、代码辅助、多模态任务
- 是 90% 场景的最佳选择
-
性能优先型:Gemini 2.5 Pro($1.25/$10.00)
- 适合:复杂分析、长文档处理、专业领域任务
- 当 Flash 表现不够好时的升级选择
-
顶级性能型:Gemini 3 Pro Preview($2.00/$12.00)
- 适合:最复杂的推理任务、研究探索
- 注意:Preview 版本可能有稳定性风险
按场景选型
| 应用场景 | 推荐模型 | 理由 |
|---|---|---|
| 智能客服 | 2.5 Flash | 响应快、成本低、多轮对话好 |
| 内容创作 | Flash-Lite / Flash | 成本敏感可用 Lite,质量要求高用 Flash |
| 代码助手 | 2.5 Pro | 代码理解能力强,长上下文支持好 |
| 文档分析 | 2.5 Pro / 3 Pro | 需要深度理解和推理 |
| 知识库问答 | Embedding + Flash | 向量检索 + 生成结合 |
| 图片理解 | 2.5 Flash | 多模态性价比最高 |
如果你正在对比不同的 AI API 选项,建议也参考我们的 ChatGPT API 定价对比,了解市场上主流选择的价格差异。
混合路由策略
在生产环境中,单一模型往往不是最优解。更聪明的做法是根据任务复杂度动态选择模型:
用户请求 → 复杂度评估 → 路由决策
└─ 简单任务 → Flash-Lite(节省 60-80%)
└─ 常规任务 → Flash(基准成本)
└─ 复杂任务 → Pro(保证质量)
这种混合路由策略可以在保证用户体验的同时,将整体成本降低 40-60%。
成本优化策略大全
掌握正确的优化策略可以大幅降低 API 使用成本。以下是经过验证的几种有效方法。
策略一:充分利用免费层
Google 提供的免费层非常慷慨,每天 1000 次请求、每分钟 5-15 次请求的额度对于开发测试完全够用。免费层的特点是:
- 无需绑定信用卡
- 支持大部分模型(包括 2.5 Flash、Flash-Lite)
- 1M token 上下文窗口可用
- 适合原型开发、功能验证
建议在正式上线前,先用免费层充分测试,确认模型能满足需求后再切换到付费层。
策略二:启用上下文缓存
对于需要重复使用相同上下文的场景(如基于固定文档的问答系统),上下文缓存可以节省高达 75% 的输入成本。
使用场景示例:
- 文档问答:将文档内容缓存,只传入用户问题
- 角色扮演:将角色设定和历史对话缓存
- 代码助手:将代码库上下文缓存
策略三:批处理模式
如果你的任务不需要实时响应,批处理模式可以享受 50% 的折扣。适合的场景包括:
- 每日数据分析报告
- 批量内容审核
- 离线文档处理
- 数据预处理任务
策略四:提示词优化
精简的提示词不仅能提高响应质量,还能直接降低成本。一些优化技巧:
- 删除冗余说明,保留核心指令
- 使用结构化格式(JSON、Markdown)减少解释文本
- 对于重复任务,使用 few-shot 示例而非详细说明
- 合并相关请求,减少 API 调用次数
策略五:选择合适的中转服务
对于需要频繁调用多种模型的开发者,使用 API 中转服务是一个值得考虑的选择。这类服务的主要优势在于支持国内支付方式(支付宝/TG),同时提供多模型聚合,方便在不同模型间切换。以 laozhang.ai 为例,它提供的 API 中转服务价格与官方一致,且不限速、不封号,对于中国开发者来说解决了支付和访问的双重难题。
有兴趣了解更多 API 管理最佳实践的开发者,可以参考 LLM API 网关最佳实践。
中国用户支付完全指南
支付问题是中国开发者使用 Google AI 服务的最大障碍之一。这里提供几种可行的解决方案。
方案一:官方免费层(推荐新手)
如果你只是想体验和测试 Gemini API,官方免费层是最简单的选择:
- 在 Google AI Studio (aistudio.google.com) 注册账号
- 创建 API Key,无需任何付款信息
- 获得每天 1000 次请求额度
免费层的限制是速率较低(5-15 RPM),但对于开发测试完全够用。
方案二:API 中转服务(推荐生产环境)
如果你需要更高的速率限制或无法使用官方服务,API 中转是最便捷的选择。以 laozhang.ai 为例:
- 支持支付宝/TG直接付款
- 最低 $5(约 35 元)起充
- API 兼容官方格式,无需修改代码
- 支持多种模型切换
使用中转服务的代码改动非常小,只需要修改 base URL:
pythonclient = genai.Client(api_key="your-key") # 中转服务(示例) client = genai.Client( api_key="your-key", base_url="https://api.laozhang.ai/v1" # 修改 base_url 即可 )
如果你在使用过程中遇到区域限制问题,可以参考 解决 Gemini 区域限制的方法 获取更多帮助。
方案三:虚拟信用卡
如果你需要直接使用 Google 官方服务,可以通过虚拟信用卡绑定 Google Cloud 账户。这种方式的优点是可以使用完整的企业功能,缺点是设置相对复杂。
方案四:港澳台账户
如果你有香港、澳门或台湾的银行账户,可以直接绑定到 Google Cloud。这些地区的 Visa/MasterCard 可以直接使用,是最正规的渠道。
如果你正在寻找更完整的国内访问方案,我们的 Gemini API 国内访问完整方案 提供了详细的步骤指南。
2026 年重要变更与迁移指南
2026 年对 Gemini API 来说是变化巨大的一年。以下是你需要了解的关键时间节点和迁移建议。
重要时间表
| 日期 | 事件 | 影响 |
|---|---|---|
| 2026年1月5日 | Gemini 3 搜索 Grounding 开始计费 | 需要更新成本预算 |
| 2026年3月3日 | Gemini 2.0 Flash/Flash-Lite 退役 | 必须迁移到 2.5 版本 |
| 2026年Q1 | Gemini 3 Pro 预计 GA | 定价可能调整 |
Gemini 2.0 到 2.5 迁移指南
如果你的应用还在使用 Gemini 2.0 系列模型,现在就应该开始规划迁移。好消息是,2.5 版本在大多数方面都是向后兼容的,迁移工作相对简单:
- 更新模型名称:将
gemini-2.0-flash改为gemini-2.5-flash - 测试功能兼容性:2.5 版本的输出格式可能略有变化,建议全面测试
- 调整成本预算:2.5 版本的定价略有不同,需要重新计算
- 利用新特性:2.5 版本提供了更长的上下文窗口和更好的多模态能力
迁移建议时间表:
- 2026年1月:完成测试环境迁移和测试
- 2026年2月:逐步迁移生产环境
- 2026年2月底:完成所有迁移
新用户福利
值得一提的是,Google Cloud 为新用户提供 $300 免费试用金,有效期 90 天。这笔额度可以用于所有 Google Cloud 服务,包括 Vertex AI 版本的 Gemini API。如果你需要企业级功能(如数据隔离、SLA 保证),可以考虑使用这笔免费额度进行评估。
常见问题解答
Q: Gemini API 免费层每天能用多少次?
A: 免费层提供每天 1000 次请求、每分钟 5-15 次请求(取决于模型)的额度。这个额度对于开发测试足够,但生产应用通常需要切换到付费层。
Q: 中文内容的 token 消耗比英文高多少?
A: 根据我们的测试,处理等量信息的中文内容,token 消耗通常比英文高 30-50%。建议在成本估算时使用 1 中文字 ≈ 2-3 tokens 的经验公式。
Q: 哪个模型性价比最高?
A: 对于大多数通用场景,Gemini 2.5 Flash 是性价比最优的选择。它以 $0.30/$2.50 的价格提供了 1M 上下文窗口、多模态能力和不错的推理性能。如果成本是首要考虑,Flash-Lite 更便宜但功能受限。
Q: 上下文缓存真的能省 75% 吗?
A: 是的,对于重复使用相同上下文的场景(如文档问答),上下文缓存可以将输入成本降低到基础价格的 10%。但需要注意缓存有存储费用,适合频繁访问的场景。
Q: 批处理模式的限制是什么?
A: 批处理模式可以享受 50% 折扣,但响应不是实时的,通常需要等待几分钟到几小时。适合离线处理、定时任务等不需要即时响应的场景。
总结与下一步
Google Gemini API 在 2026 年提供了非常有竞争力的定价,从 $0.10/百万 token 的 Flash-Lite 到 $2.00/百万 token 的 Gemini 3 Pro,开发者可以根据需求灵活选择。以下是关键要点回顾:
定价要点
- 最经济:Gemini 2.5 Flash-Lite($0.10/$0.40 per 1M tokens)
- 最佳性价比:Gemini 2.5 Flash($0.30/$2.50 per 1M tokens)
- 最强性能:Gemini 3 Pro Preview($2.00/$12.00 per 1M tokens)
行动建议
- 新手入门:从官方免费层开始,熟悉 API 使用
- 生产部署:评估 Flash 和 Flash-Lite 能否满足需求
- 中国用户:考虑使用 API 中转服务简化支付流程
- 2.0 用户:尽快规划迁移到 2.5 版本(3月3日前)
资源链接
- Google 官方定价页面:https://ai.google.dev/gemini-api/docs/pricing
- API 中转服务文档:https://docs.laozhang.ai/
希望本指南能帮助你做出明智的技术决策。如果你有任何问题,欢迎在评论区留言讨论。