
随着人工智能技术的普及,越来越多的企业和开发者开始将ChatGPT的API集成到自己的产品中。然而,随之而来的API成本问题也成为许多决策者的关注焦点。本文将全面解析2025年最新的ChatGPT API收费标准,深入分析各模型的价格结构,并提供实用的成本优化策略,帮助您在保证性能的前提下有效控制API使用成本。
2025年最新ChatGPT各系列API价格对比,展示了从GPT-4o到GPT-4.1系列的价格层级与应用场景
引言:理解ChatGPT API价格体系
在探讨具体价格之前,我们需要先理解OpenAI的API计费基础——基于token的使用量计费模式。Token是OpenAI对文本进行处理的基本单位,大致可以理解为:
- 在英文文本中,1个token约等于4个字符或3/4个单词
- 在中文文本中,1个汉字通常对应1-2个token
- 标点符号、空格等也会计入token数量
OpenAI对API的收费分为两部分:输入token(您发送给模型的内容)和输出token(模型返回的回复)。通常情况下,输出token的价格会高于输入token的价格,这也是为什么优化prompt和控制输出长度能有效节约成本。
在2025年,OpenAI的产品线已经扩展到包含多个模型系列,每个系列针对不同的应用场景和性能需求,价格也各不相同。接下来,我们将详细分析各个模型系列的价格结构。
最新ChatGPT API价格明细(2025年6月更新)
OpenAI在2025年对API价格进行了多次调整,以下是截至2025年6月的最新价格表:
GPT-4o系列价格
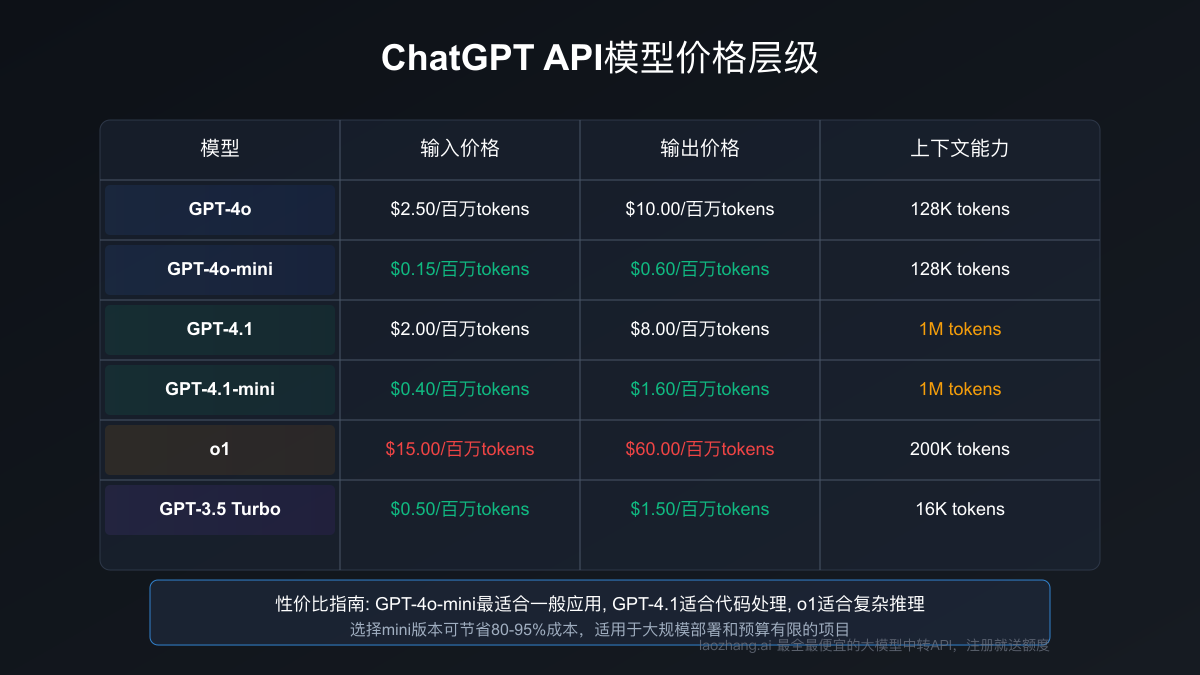
GPT-4o系列是OpenAI当前主力推广的多模态模型,支持文本、图像、音频和视频输入:
| 模型 | 输入价格(每百万token) | 输出价格(每百万token) | 上下文窗口 | 最大输出 |
|---|---|---|---|---|
| gpt-4o | $2.50 | $10.00 | 128K | 16K |
| gpt-4o-mini | $0.15 | $0.60 | 128K | 16K |
| gpt-4o-mini-audio | $0.15 | $0.60 | 128K | 16K |
| gpt-4o-audio | $2.50 | $10.00 | 128K | 16K |
| gpt-4o-mini-search | $0.15 | $0.60 | 128K | 16K |
| gpt-4o-search | $2.50 | $10.00 | 128K | 16K |
非文本数据的处理价格:
- 图片输入:每1,000张图片$3.60
- 音频输入:每分钟$0.006
- 视频输入:每分钟$0.030
图像生成价格:
- 标准分辨率(512×512):约$0.01/图
- 高清分辨率(1024×1024):约$0.015/图
- 超高清分辨率(2048×2048):约$0.0225/图
GPT-4.1系列价格
2025年4月推出的GPT-4.1系列是OpenAI在编程和指令遵循方面的最新突破,提供了三种不同性能和价格的变种:
| 模型 | 输入价格(每百万token) | 输出价格(每百万token) | 上下文窗口 | 最大输出 |
|---|---|---|---|---|
| gpt-4.1 | $2.00 | $8.00 | 1M | 32K |
| gpt-4.1-mini | $0.40 | $1.60 | 1M | 32K |
| gpt-4.1-nano | $0.10 | $0.40 | 1M | 32K |
GPT-4.1系列的核心优势在于超大的上下文窗口(1M tokens)和卓越的编程能力,特别适合需要处理大量代码或长文档的应用场景。
推理模型价格(o系列)
推理模型是OpenAI专为复杂推理和思考过程设计的模型系列:
| 模型 | 输入价格(每百万token) | 输出价格(每百万token) | 上下文窗口 |
|---|---|---|---|
| o3-mini | $1.10 | $4.40 | 200K |
| o1 | $15.00 | $60.00 | 200K |
| o1-mini | $1.10 | $4.40 | 200K |
| o1-pro | $150.00 | $600.00 | 200K |
虽然o系列模型价格较高,但在需要严格逻辑推理、多步骤分析和复杂问题解决的场景中表现卓越。
经典模型价格
为了完整性,以下是一些经典模型的价格,尽管这些模型已不再是OpenAI的主要推荐选择:
| 模型 | 输入价格(每百万token) | 输出价格(每百万token) |
|---|---|---|
| gpt-4 | $30.00 | $60.00 |
| gpt-4-turbo | $10.00 | $30.00 |
| gpt-3.5-turbo | $0.50 | $1.50 |
不同模型的性能对比与选择指南
在考虑API成本时,我们需要同时考虑模型性能,以获得最佳的性价比。以下是主要模型在几个关键领域的性能对比:
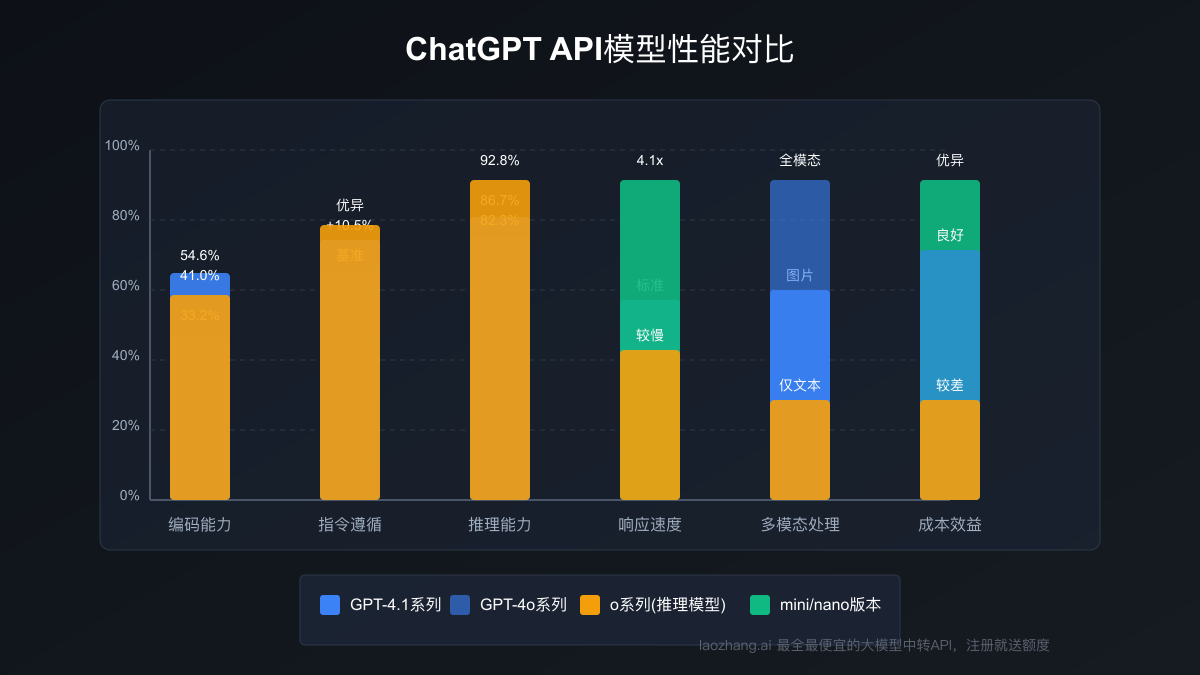
编码能力(SWE-Bench测试)
- GPT-4.1:54.6%
- GPT-4.1-mini:48.2%
- GPT-4.1-nano:32.5%
- GPT-4o:33.2%
- o1:41%
- 对比参考:Claude 3.7 Sonnet (62.3%)、Gemini 2.5 Pro (63.8%)
指令遵循能力(MultiChallenge测试)
- GPT-4.1:较GPT-4o提升10.5%
- GPT-4.1-mini:较GPT-4o-mini提升7.3%
- GPT-4o:基准参考
- o1:在复杂指令方面表现优异
推理能力(GSM8K数学推理)
- o1-pro:96.5%
- o1:92.8%
- GPT-4.1:86.7%
- GPT-4o:82.3%
- GPT-4.1-mini:78.5%
延迟表现(响应速度)
- GPT-4.1-nano:最快(是GPT-4.1的4.1倍)
- GPT-4.1-mini:较快(是GPT-4.1的2.4倍)
- GPT-4o:中等
- GPT-4.1:标准
- o1:较慢
基于以上性能对比,我们可以根据不同应用场景选择最适合的模型:
- 多模态应用(处理图像、音频、视频):优先选择GPT-4o系列
- 代码开发与审查:优先选择GPT-4.1系列
- 复杂推理与分析:优先选择o系列,特别是o1或o1-pro
- 高吞吐量、成本敏感应用:选择mini或nano变种
- 一般对话与内容生成:GPT-4o-mini提供最佳平衡
真实场景下的API成本估算
为了更直观地理解API成本,我们以几个典型应用场景为例进行成本估算:
场景一:客服聊天机器人
假设一个企业客服机器人,每天处理5,000次对话:
- 平均输入:每次对话200 tokens
- 平均输出:每次对话300 tokens
每日成本估算:
- 使用GPT-4o:(5,000 × 200 × $2.5/百万) + (5,000 × 300 × $10/百万) = $2.5 + $15 = $17.5/天
- 使用GPT-4o-mini:(5,000 × 200 × $0.15/百万) + (5,000 × 300 × $0.6/百万) = $0.15 + $0.9 = $1.05/天
- 每月成本(GPT-4o):约$525
- 每月成本(GPT-4o-mini):约$31.5
场景二:内容生成平台
一个内容营销平台,每天生成200篇产品描述:
- 平均输入:每篇150 tokens(指令和产品信息)
- 平均输出:每篇500 tokens(成品文案)
每日成本估算:
- 使用GPT-4.1:(200 × 150 × $2/百万) + (200 × 500 × $8/百万) = $0.06 + $0.8 = $0.86/天
- 使用GPT-4.1-mini:(200 × 150 × $0.4/百万) + (200 × 500 × $1.6/百万) = $0.012 + $0.16 = $0.172/天
- 每月成本(GPT-4.1):约$25.8
- 每月成本(GPT-4.1-mini):约$5.16
场景三:代码助手应用
一个面向程序员的代码助手工具,每天处理1,000次代码生成或修复请求:
- 平均输入:每次请求1,000 tokens(包括代码上下文)
- 平均输出:每次请求2,000 tokens(生成或修复的代码)
每日成本估算:
- 使用GPT-4.1:(1,000 × 1,000 × $2/百万) + (1,000 × 2,000 × $8/百万) = $2 + $16 = $18/天
- 使用o1:(1,000 × 1,000 × $15/百万) + (1,000 × 2,000 × $60/百万) = $15 + $120 = $135/天
- 每月成本(GPT-4.1):约$540
- 每月成本(o1):约$4,050
通过这些估算,我们可以看出选择合适的模型能带来显著的成本差异,特别是在大规模使用场景中。使用mini版本的模型通常可以节省80-90%的成本,这对于成本敏感的项目特别重要。
七大API成本优化策略
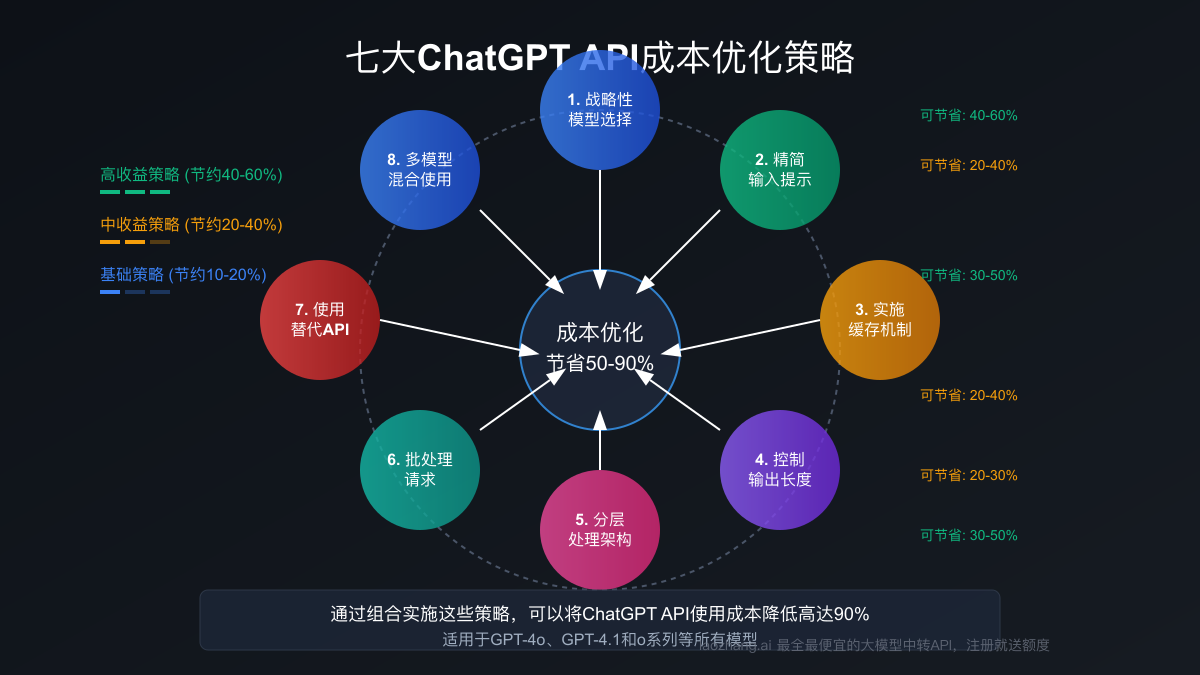
为了帮助开发者和企业更有效地控制API成本,以下是七种经过验证的成本优化策略:
1. 战略性模型选择
根据任务的复杂性动态选择不同的模型。例如:
- 使用mini或nano模型进行初步分类和意图识别
- 仅在需要深度处理时切换到更强大的模型
- 对不同类型的查询使用不同的模型
实现示例:
javascriptfunction selectOptimalModel(query, complexity) { if (complexity === 'low' || isSimpleQuery(query)) { return 'gpt-4o-mini'; } else if (complexity === 'medium') { return 'gpt-4.1-mini'; } else { return 'gpt-4.1'; } }
2. 精简输入提示
优化prompt可以显著降低输入token数量:
- 去除不必要的背景信息和冗余指令
- 使用简洁明了的语言表达需求
- 针对重复场景设计标准化的精简提示
优化前后对比:
// 优化前 (约85 tokens)
"你是一个专业的文案撰写助手。请为一款名为'清风净化器X9'的空气净化产品撰写一段吸引人的产品描述。这款产品主要特点是高效过滤PM2.5,静音运行,智能控制。描述应该突出产品优势,使用生动的语言,并包含促进消费者购买的内容。"
// 优化后 (约45 tokens)
"撰写销售文案:清风净化器X9。特点:过滤PM2.5,静音,智能控制。突出优势,促进购买。"
3. 实施缓存机制
对于频繁重复或相似的查询,实施缓存机制可以大幅降低API调用次数:
- 为常见问题存储预生成的回答
- 使用模糊匹配识别相似查询
- 基于用户交互历史建立动态缓存
缓存实现思路:
javascriptconst responseCache = new Map(); async function getChatResponse(prompt) { const cacheKey = createCacheKey(prompt); if (responseCache.has(cacheKey)) { return responseCache.get(cacheKey); } const response = await callChatGPTAPI(prompt); responseCache.set(cacheKey, response); return response; }
4. 控制输出长度
通过明确设置max_tokens参数限制输出长度:
- 根据实际需求设置合理的输出限制
- 在提示中明确指定期望的回复长度
- 使用流式响应(streaming),可以在获得满足需求的回答后立即终止
API调用示例:
javascriptconst response = await openai.chat.completions.create({ model: "gpt-4o", messages: [...], max_tokens: 150, // 限制输出长度 stream: true // 启用流式响应 });
5. 分层处理架构
设计分层处理架构,使用不同模型处理不同复杂度的任务:
- 第一层:使用轻量级模型进行初步处理和过滤
- 第二层:对需要深入处理的内容使用中等复杂度模型
- 第三层:仅对最复杂的问题使用高级模型
架构示例:
javascriptasync function processUserQuery(query) { // 第一层:意图分类(使用轻量级模型) const intent = await classifyIntent(query, 'gpt-4.1-nano'); if (intent === 'simple-faq') { return await getFromFAQDatabase(query); } else if (intent === 'moderate-complexity') { // 第二层:中等复杂度处理 return await processWithMidTierModel(query, 'gpt-4o-mini'); } else { // 第三层:复杂问题处理 return await processWithAdvancedModel(query, 'gpt-4.1'); } }
6. 批处理请求
将多个相关请求合并成一个批处理请求:
- 同时处理多个相似任务
- 减少API调用的总次数
- 降低与API通信的网络开销
批处理示例:
javascript// 单独处理(较低效率) for (const item of items) { const result = await processSingleItem(item); results.push(result); } // 批处理(更高效率) const prompt = createBatchPrompt(items); const batchResults = await processBatchItems(prompt); const parsedResults = parseBatchResults(batchResults);
7. 使用成本更低的API替代方案
考虑通过第三方API中转服务降低成本:
- API中转服务通常提供与原生API相同的功能
- 通过批量采购和资源优化提供更低的价格
- 保持API兼容性,无需修改现有代码
使用laozhang.ai API替代方案示例:
javascript// 原始OpenAI API调用 const response = await fetch("https://api.openai.com/v1/chat/completions", { method: "POST", headers: { "Content-Type": "application/json", "Authorization": `Bearer ${OPENAI_API_KEY}` }, body: JSON.stringify({ model: "gpt-4o", messages: [...] }) }); // 使用替代API(完全兼容原API) const response = await fetch("https://api.laozhang.ai/v1/chat/completions", { method: "POST", headers: { "Content-Type": "application/json", "Authorization": `Bearer ${LAOZHANG_API_KEY}` }, body: JSON.stringify({ model: "gpt-4o", messages: [...] }) });
通过这些优化策略的组合实施,企业和开发者可以显著降低API使用成本,在某些场景下甚至可以实现50-90%的成本节约。
企业级API使用的预算规划
对于大规模企业应用,合理的预算规划至关重要。以下是制定API使用预算的步骤:
1. 评估预期使用量
首先,对以下几个方面进行评估:
- 日均API调用次数
- 平均输入和输出token数
- 使用高峰期和增长预期
2. 制定分层预算模型
根据不同的使用场景和优先级设置预算上限:
- 核心功能:分配最大预算,使用高性能模型
- 辅助功能:使用成本较低的模型,实施更严格的使用限制
- 实验功能:设置固定预算上限,优先使用缓存和批处理
3. 实施监控与控制机制
为确保API使用不超出预算:
- 建立实时token使用量监控系统
- 设置每日/每周使用量警报
- 实施自动降级策略,在接近预算上限时切换到更经济的模型
4. 制定优化迭代计划
API使用优化是一个持续过程:
- 定期分析使用模式和成本构成
- 识别高成本低回报的使用场景
- 针对特定场景持续优化prompt和处理逻辑
结论:如何选择最适合您的ChatGPT API
选择合适的ChatGPT API应该是一个全面考量性能、成本和实际需求的过程。基于本文的分析,我们提供以下选择指南:
- GPT-4o系列:适合需要处理多模态输入(图像、音频、视频)的应用,性价比较高
- GPT-4.1系列:适合需要处理大量代码或长文本的场景,尤其是编程相关应用
- o系列:适合需要复杂推理和深度分析的高端应用,虽然成本较高但在特定场景下不可替代
- mini/nano变种:适合大规模部署和成本敏感的应用场景,可以通过架构设计弥补性能差距
无论您选择哪种模型,实施本文提供的成本优化策略都能帮助您在保持服务质量的同时有效控制API使用成本。随着AI技术的不断发展,OpenAI的价格策略也在持续调整,建议定期关注官方更新以获取最新的价格信息和优化建议。
通过合理选择模型、优化使用策略和持续监控调整,您可以充分发挥ChatGPT API的强大能力,同时将成本控制在可接受的范围内,实现业务价值和技术投资的最佳平衡。