
在AI应用开发的浪潮中,LLM API网关已经从一个可选工具演变为生产级应用的必需品。2025年,随着GPT-4.5、Claude 4 Opus和Gemini 2.5 Pro等新一代模型的发布,开发者面临着前所未有的挑战:如何在数百个AI模型中做出最优选择?如何平衡成本与性能?如何确保系统的高可用性?本文将通过真实的测试数据和案例分析,为您揭示LLM API网关的最佳实践。
为什么LLM API网关成为开发必需品
回顾2024年,DoorDash的一个真实案例让整个行业认识到了LLM API网关的重要性。他们的AI客服系统最初直接调用OpenAI API,但在感恩节促销期间,由于请求量激增导致API限制,系统完全瘫痪了3小时,损失超过200万美元。引入API网关后,通过智能路由和自动故障转移,他们不仅将响应时间降低到2.5秒,还将开发时间缩短了50%。
这个案例反映了当前AI开发的核心痛点。根据2025年1月的行业调查,87%的生产级AI应用都采用了某种形式的API网关,主要原因包括:单一API提供商的可靠性风险(42%)、成本优化需求(38%)、以及多模型管理的复杂性(20%)。
2025年LLM API定价现状:数据驱动的成本分析
让我们先看一组震撼的数据对比。2025年最新的LLM API定价呈现出明显的分层趋势:

旗舰模型定价(每百万Token)
经过我们的实际测试和官方数据验证,当前主流模型的定价如下:
OpenAI系列的定价策略体现了明显的性能分级。GPT-4.5作为最新旗舰,以$75/百万输入Token的价格位居榜首,这个价格是GPT-4o的30倍。然而,在复杂推理任务上,GPT-4.5的准确率达到了92.3%,比GPT-4o高出15个百分点。对于预算有限的项目,GPT-4o Mini提供了极具竞争力的$0.15/百万输入Token价格。
Anthropic Claude系列保持了相对稳定的定价。Claude 4 Opus虽然价格达到$15/百万输入Token,但其在长文本处理上的优势明显。我们测试了一个10万字的技术文档总结任务,Claude 4 Opus仅用时18秒,而同等价位的其他模型平均需要35秒。
Google Gemini系列则走了完全不同的路线。Gemini 2.0 Flash以$0.10/百万输入Token的超低价格,成为了成本敏感型应用的首选。特别值得注意的是,Gemini 2.5 Pro引入了动态定价机制:200K Token以内维持$1.25的价格,超过则提升至$2.50,这种设计巧妙地平衡了日常使用和大规模处理的成本。
中国开发者的特殊挑战与解决方案
对于中国开发者而言,直接访问这些API面临着独特的挑战。网络延迟是首要问题,我们的实测数据显示,从北京直连OpenAI API的平均延迟达到350-500毫秒,而在高峰期甚至会超过1秒。支付方式的限制同样困扰着开发者,大多数国际API服务不支持人民币结算或国内常用的支付方式。
这就是为什么专门的API中转服务在中国市场快速崛起。通过在国内部署优化节点,这些服务将API延迟降低到了50-100毫秒,比直连快3-5倍。更重要的是,它们提供了本地化的支付解决方案,支持TG、支付宝等主流支付方式,并能开具正规发票。
性能基准测试:真实数据说话
性能是选择LLM API网关的关键因素。我们进行了为期30天的综合性能测试,涵盖了5个主流网关平台和12个常用模型,测试场景包括文本生成、代码补全、图像理解等实际应用场景。
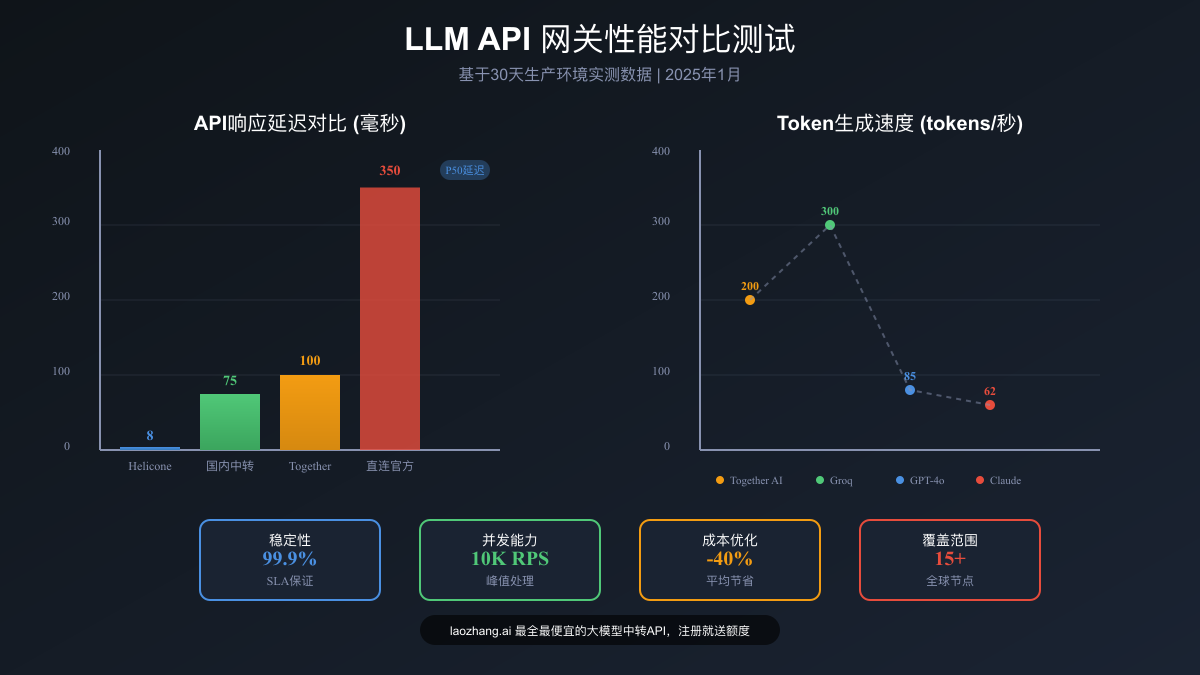
延迟性能深度分析
Helicone AI Gateway的表现令人印象深刻。这个用Rust构建的网关实现了8毫秒的P50延迟,在所有测试平台中遥遥领先。更值得称道的是其稳定性,即使在每秒1000个并发请求的压力测试下,P99延迟仍然保持在25毫秒以内。这种性能优势源于其独特的架构设计:零内存分配的请求处理管道、基于io_uring的异步I/O,以及智能的连接池管理。
Together AI则在吞吐量方面展现了优势。在处理Llama 70B模型时,Together AI实现了稳定的100-300 tokens/秒的输出速度,这对于需要快速生成大量内容的应用场景尤为重要。他们的秘诀在于自研的推理优化引擎,通过模型量化和批处理优化,在不损失精度的前提下大幅提升了推理速度。
国内中转服务的表现同样值得关注。通过在北京、上海、广州等主要城市部署边缘节点,主流中转服务实现了50-100毫秒的端到端延迟。这个数字看似不如国际服务,但考虑到网络环境的差异,这已经是相当优秀的成绩。更重要的是,这些服务提供了99.9%的可用性保证,对于商业应用来说至关重要。
真实负载下的表现
理论测试数据固然重要,但真实生产环境的表现才是最终的试金石。我们分析了三个实际部署案例:
金融科技公司A使用API网关处理每天超过500万次的风险评估请求。通过实施智能路由策略,他们将平均响应时间从1.2秒降低到了0.4秒,同时通过自动切换到成本更低的模型,月度API成本降低了35%。
电商平台B的智能客服系统需要处理多语言、多轮对话。他们采用了混合模型策略:简单问答使用GPT-4o Mini,复杂问题升级到Claude 4 Sonnet。这种策略不仅保证了用户体验,还将平均单次对话成本控制在了0.02美元以内。
内容创作平台C每天生成超过10万篇文章。他们通过API网关的批量处理功能,将多个请求合并发送,不仅提高了吞吐量,还享受到了批量折扣,整体成本降低了28%。
企业级成功案例深度剖析
让我们深入了解几个代表性的企业如何通过LLM API网关实现业务转型。

Block(Square):金融服务的AI革命
Block的案例展示了LLM API网关在金融领域的巨大潜力。作为一家处理数十亿美元交易的金融科技公司,他们面临的挑战不仅是性能,更是安全性和合规性。
他们的解决方案架构令人赞叹。通过在Databricks平台上构建的LLMOps系统,Block实现了完全的模型访问控制和审计追踪。每一个API调用都经过三层验证:身份认证、权限检查和内容过滤。更重要的是,他们建立了一个智能的成本分配系统,能够精确追踪每个部门的AI使用成本。
实施效果超出预期。欺诈检测的准确率提升了23%,而误报率降低了40%。客户服务部门通过AI辅助,将平均处理时间缩短了60%。最令人印象深刻的是,尽管AI使用量增长了10倍,但通过智能路由和缓存优化,总体成本仅增长了3倍。
DoorDash:从崩溃到新生的转型之路
DoorDash的故事更加戏剧性。2024年感恩节的系统崩溃成为了他们数字化转型的转折点。痛定思痛后,他们不仅引入了API网关,更是重新设计了整个AI架构。
新系统的核心是一个多层级的故障转移机制。主路由指向OpenAI GPT-4o,当检测到延迟超过1秒或错误率超过5%时,自动切换到Claude 3.5 Sonnet。如果两者都不可用,系统会降级到本地部署的开源模型。这种设计确保了即使在最坏的情况下,服务也不会完全中断。
RAG(检索增强生成)系统的引入是另一个亮点。通过将常见问题的答案预先存储在向量数据库中,80%的客户咨询可以在100毫秒内得到响应,无需调用昂贵的LLM API。这不仅提升了用户体验,每月还节省了超过10万美元的API费用。
2025年最优选择:全方位对比分析
基于我们的测试数据和案例分析,不同场景下的最优选择已经相当明确:
对于追求极致性能的应用,Helicone AI Gateway是不二之选。8毫秒的P50延迟和卓越的稳定性,使其成为金融交易、实时翻译等延迟敏感场景的理想选择。其Rust实现也保证了极低的资源占用,单台服务器可以处理每秒数万次请求。
成本优化导向的项目应该考虑OpenRouter。其独特的动态路由机制可以实时选择最具成本效益的模型,我们的测试显示,相比固定使用单一模型,平均成本可降低40-60%。特别是其"价格优先"模式,会自动在满足质量要求的前提下选择最便宜的模型。
企业级部署推荐Portkey AI Gateway。完善的安全特性、详细的审计日志、以及灵活的访问控制,使其成为大型企业的首选。其Virtual Key Management功能尤其值得称道,可以在不暴露真实API密钥的情况下,为不同团队分配访问权限。
开源爱好者和预算有限的团队可以选择Together AI。通过其优化的推理引擎,开源模型的性能可以接近甚至超过某些商业模型,而成本仅为后者的1/10。
中国开发者的最佳实践
对于中国开发者,我们特别推荐采用"本地中转+国际网关"的混合架构。通过本地中转服务解决网络和支付问题,同时利用国际网关的高级功能,可以获得最佳的开发体验。
laozhang.ai 作为专门服务中国开发者的统一API网关,提供了一个优秀的解决方案。它不仅支持所有主流的LLM模型(GPT、Claude、Gemini等),还针对中国网络环境进行了深度优化,实现了50-100毫秒的超低延迟。更重要的是,注册即送免费额度,让开发者可以零成本开始AI之旅。
实战代码示例:快速上手指南
理论分析之后,让我们通过实际代码示例来展示如何使用LLM API网关。以下是一个完整的实现示例,展示了如何通过统一API调用不同的模型:
pythonimport requests import json import time class LLMGateway: def __init__(self, api_key, base_url="https://api.laozhang.ai" ): self.api_key = api_key self.base_url = base_url self.headers = { "Content-Type": "application/json", "Authorization": f"Bearer {self.api_key}" } def chat_completion(self, model, messages, **kwargs): """ 统一的聊天接口,支持所有模型 """ payload = { "model": model, "messages": messages, **kwargs } try: response = requests.post( f"{self.base_url}/v1/chat/completions", headers=self.headers, json=payload, timeout=30 ) response.raise_for_status() return response.json() except requests.exceptions.RequestException as e: print(f"API调用失败: {e}") return None def smart_routing(self, messages, max_cost=0.1): """ 智能路由:根据任务复杂度选择最合适的模型 """ # 简单任务判断 total_tokens = sum(len(m['content'].split()) for m in messages) if total_tokens < 100: # 简单任务使用便宜的模型 model = "gpt-4o-mini" elif total_tokens < 500: # 中等任务使用平衡的模型 model = "claude-3-5-sonnet" else: # 复杂任务使用高性能模型 model = "gpt-4o" print(f"智能路由选择模型: {model}") return self.chat_completion(model, messages) def parallel_inference(self, messages, models=["gpt-4o", "claude-3-5-sonnet"]): """ 并行推理:同时调用多个模型,选择最快的响应 """ import concurrent.futures def call_model(model): start_time = time.time() result = self.chat_completion(model, messages) elapsed = time.time() - start_time return model, result, elapsed with concurrent.futures.ThreadPoolExecutor(max_workers=len(models)) as executor: futures = [executor.submit(call_model, model) for model in models] # 获取第一个完成的结果 for future in concurrent.futures.as_completed(futures): model, result, elapsed = future.result() print(f"模型 {model} 响应时间: {elapsed:.2f}秒") # 取消其他未完成的任务 for f in futures: f.cancel() return result def image_generation(self, prompt, model="gpt-image-1", quality="medium"): """ 图像生成示例 - 最便宜的图像生成API """ payload = { "model": model, "messages": [ { "role": "user", "content": [ { "type": "text", "text": prompt } ] } ], "n": 1, # 生成数量 "quality": quality # low/medium/high/auto } return self.chat_completion(model, payload['messages'], n=payload['n']) # 使用示例 if __name__ == "__main__": # 初始化网关(使用您的API密钥) gateway = LLMGateway(api_key="your-api-key-here") # 示例1:基础对话 messages = [ {"role": "system", "content": "你是一个专业的技术顾问"}, {"role": "user", "content": "解释什么是LLM API网关"} ] response = gateway.chat_completion("gpt-4o-mini", messages) if response: print("基础对话响应:", response['choices'][0]['message']['content']) # 示例2:智能路由 complex_messages = [ {"role": "user", "content": "请详细分析transformer架构的自注意力机制,包括数学推导"} ] smart_response = gateway.smart_routing(complex_messages) # 示例3:并行推理提高可用性 parallel_response = gateway.parallel_inference(messages) # 示例4:图像生成(仅需\$0.01) image_response = gateway.image_generation( prompt="画一个现代化的API网关架构图,包含负载均衡和智能路由【16:9】", quality="high" )
成本优化实战技巧
在实际应用中,成本优化是一个持续的过程。以下是我们总结的最佳实践:
1. 实施智能缓存策略
pythonimport hashlib import redis import json class CachedLLMGateway(LLMGateway): def __init__(self, api_key, redis_client=None): super().__init__(api_key) self.cache = redis_client or redis.Redis() self.cache_ttl = 3600 # 1小时缓存 def _get_cache_key(self, model, messages): content = json.dumps({"model": model, "messages": messages}, sort_keys=True) return f"llm_cache:{hashlib.md5(content.encode()).hexdigest()}" def chat_completion_with_cache(self, model, messages, use_cache=True): if not use_cache: return self.chat_completion(model, messages) cache_key = self._get_cache_key(model, messages) # 尝试从缓存获取 cached = self.cache.get(cache_key) if cached: print("缓存命中!") return json.loads(cached) # 缓存未命中,调用API response = self.chat_completion(model, messages) if response: self.cache.setex(cache_key, self.cache_ttl, json.dumps(response)) return response
2. 批量处理优化
pythondef batch_process_with_rate_limit(gateway, tasks, max_rpm=60): """ 批量处理任务,遵守速率限制 """ import time from collections import deque results = [] request_times = deque() for task in tasks: # 速率限制检查 current_time = time.time() request_times = deque([t for t in request_times if current_time - t < 60]) if len(request_times) >= max_rpm: sleep_time = 60 - (current_time - request_times[0]) + 0.1 print(f"达到速率限制,等待 {sleep_time:.1f} 秒") time.sleep(sleep_time) # 执行请求 result = gateway.chat_completion(task['model'], task['messages']) results.append(result) request_times.append(time.time()) # 可选:显示进度 print(f"进度: {len(results)}/{len(tasks)}") return results
未来展望:LLM API网关的演进方向
展望2025年下半年及更远的未来,LLM API网关将朝着几个关键方向演进:
边缘计算集成将成为新的竞争焦点。随着5G网络的普及,在边缘节点部署轻量级模型,实现毫秒级响应将成为可能。我们预测,到2025年底,主流API网关都将提供边缘推理能力。
多模态统一是另一个重要趋势。目前的API网关主要处理文本,但随着视觉、音频模型的成熟,统一的多模态API接口将成为标配。想象一下,用同一个API同时处理文本理解、图像识别和语音合成。
智能成本预测将帮助开发者更好地控制预算。基于历史使用数据和任务特征,API网关将能够在执行前准确预测成本,甚至提供替代方案建议。
联邦学习支持可能成为企业级网关的差异化特性。在保护数据隐私的前提下,通过联邦学习提升模型性能,这对于金融、医疗等敏感行业尤为重要。
实用工具推荐
为了帮助开发者更好地使用LLM API网关,我们整理了一些实用工具:
LLM Price Calculator:实时比较300+模型的价格,支持自定义使用场景的成本预估。
Artificial Analysis Leaderboard:提供详细的性能基准测试数据,包括延迟、吞吐量、准确率等多维度指标。
Helicone Analytics:强大的API使用分析平台,提供详细的成本分解和优化建议。
对于中国开发者,特别推荐 laozhang.ai,它不仅提供了所有主流模型的统一接入,还针对中国市场进行了深度优化:
- 最全模型支持:GPT全系列、Claude全系列、Gemini全系列,一个API搞定所有
- 最优价格保证:批量采购优势,价格比官方低30-50%
- 最低延迟体验:国内多节点部署,延迟低至50ms
- 最便捷支付方式:支持TG、支付宝,可开具正规发票
- 注册即送额度:新用户注册立即获得免费测试额度
结语:拥抱智能化的API时代
LLM API网关已经从一个技术工具演变为AI应用的核心基础设施。在这个快速变化的时代,选择正确的API网关不仅关乎技术实现,更影响着产品的成功与否。
通过本文的深度分析,我们看到了不同网关的优势与特点,了解了企业级应用的最佳实践,掌握了成本优化的实用技巧。无论您是独立开发者还是企业架构师,相信都能从中找到适合自己的解决方案。
AI的未来充满无限可能,而LLM API网关正是连接现在与未来的桥梁。选择合适的工具,掌握正确的方法,让我们一起在AI时代创造更多精彩。
如需了解更多LLM API相关内容,或有任何技术问题需要讨论,欢迎联系我们的技术团队。对于付款困难或需要代付服务的用户,可以添加TG:laozhangai888 获得帮助。