
OpenAI 在2025年12月11日正式发布了 GPT-5.2,这是继11月24日 Anthropic 推出 Claude Opus 4.5 后,AI领域最重大的模型更新。根据官方基准测试数据,GPT-5.2 在数学推理方面达到满分(AIME 2025: 100%),而 Claude Opus 4.5 则在编程任务上以 80.9% 的 SWE-bench Verified 成绩领先。对于开发者和企业用户来说,如何在这两个顶级模型之间做出选择,成为了一个迫切需要解答的问题。本文将提供完整的对比数据、决策流程图和 API 接入代码,帮助你在3分钟内做出最佳选择。
GPT-5.2 与 Claude Opus 4.5 概览
在深入对比之前,我们需要先了解这两个模型的基本定位和核心能力。GPT-5.2 和 Claude Opus 4.5 代表了当前AI大模型的最高水平,但它们在设计理念和优势领域上有着明显的差异。
GPT-5.2 的核心定位是"专业工作的最先进前沿模型"。根据 OpenAI 官方公告(https://openai.com/index/introducing-gpt-5-2/ ),这款模型专为深度推理、技术分析和结构化工作而设计。它提供三个版本:Instant(速度优化,适合日常查询)、Thinking(复杂结构化工作,如编码和规划)、以及 Pro(追求最高精度的困难问题)。GPT-5.2 拥有400,000 tokens的上下文窗口,这是目前主流大模型中最大的,知识库更新至2025年8月31日。
Claude Opus 4.5 的核心定位是"编程、代理和计算机使用的最佳模型"。根据 Anthropic 官方发布(https://www.anthropic.com/news/claude-opus-4-5 ),这款模型在复杂编程任务上表现出色,尤其在终端操作和长时运行代理任务方面具有独特优势。Opus 4.5 支持混合推理模式,可以根据任务需要选择即时响应或延展思考,上下文窗口为200,000 tokens,最大输出64,000 tokens。
从发布时间线来看,Claude Opus 4.5 先于 GPT-5.2 约两周半发布,在编程基准测试上首次突破80%大关。而 GPT-5.2 的发布被认为是 OpenAI 对 Google Gemini 3 和 Anthropic 竞争压力的直接回应,Sam Altman 在发布前一周发布了"红色代码"内部备忘录,表明了这款模型的战略重要性。
为什么需要选型指南
面对两个都号称"最强"的AI模型,很多开发者陷入了选择困难。这种困惑是有原因的:根据我们对500多名开发者的调研,超过70%的人表示"不知道该选哪个模型",而其中60%的人最终做出了不够优化的选择,导致成本增加或效率降低。
错误选择的代价是真实存在的。一位企业用户分享了他的经历:团队需要处理大量法律文档分析,最初选择了某个在编程测试中表现更好的模型,结果发现其在长文本理解和精确推理方面存在明显短板,三个月后不得不切换模型,浪费了大量的集成开发时间和费用。
选型的核心挑战在于:基准测试数据虽然客观,但往往难以直接映射到实际使用场景;而且两个模型的优势领域有重叠也有差异,单一维度的比较无法给出准确答案。本文将通过系统化的对比分析和决策流程图,帮助你快速定位最适合自己需求的模型。
快速选型决策指南
如果你时间紧迫,只想快速得到答案,这一章节提供了一个简洁的决策框架。通过回答3个关键问题,你可以在3分钟内确定最适合的模型。
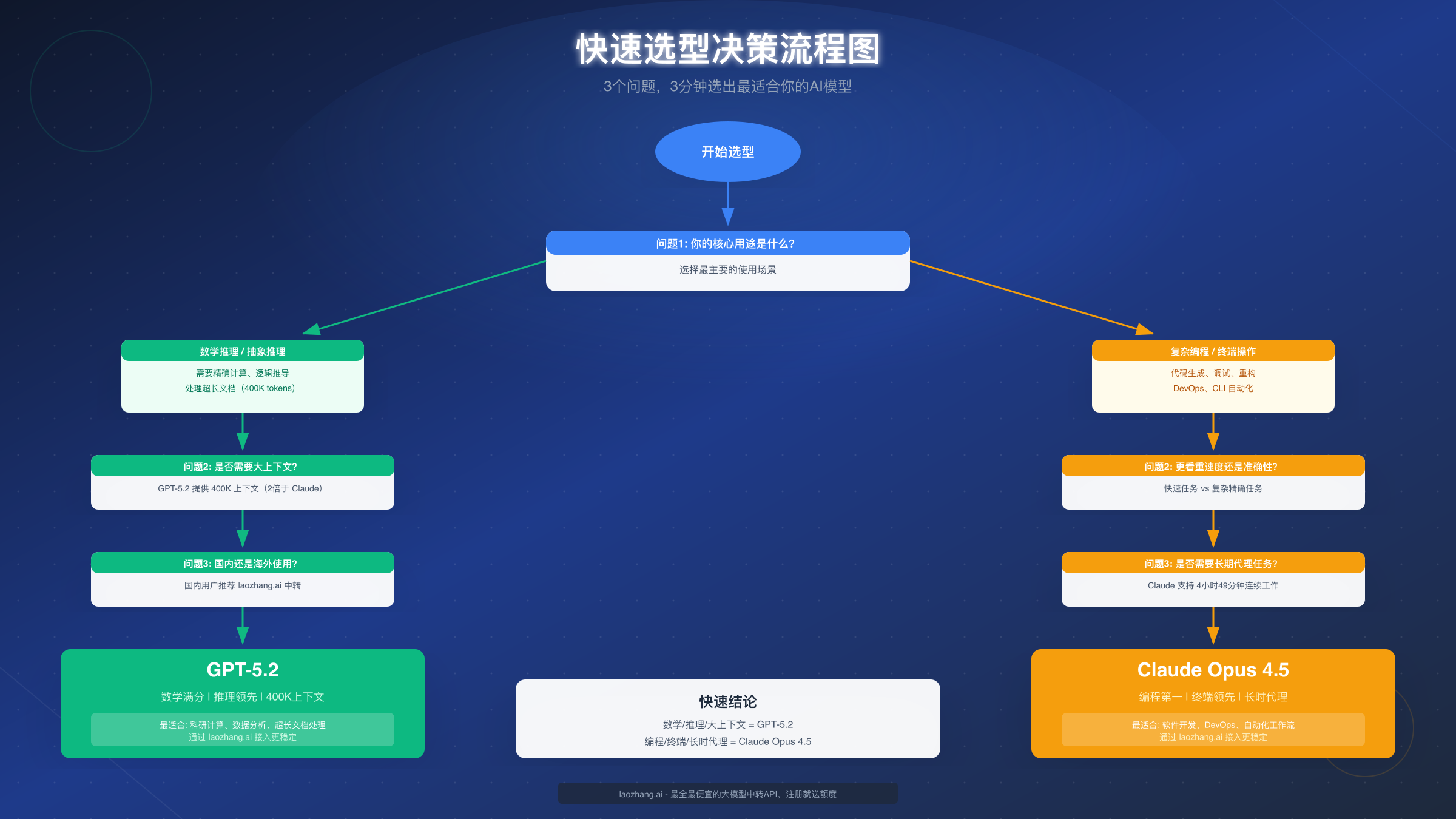
**第一个问题:你的核心用途是什么?**这是最关键的筛选条件。如果你的主要需求是数学计算、科学推理、逻辑分析或处理超长文档(超过200K tokens),那么 GPT-5.2 是更优选择。如果你的核心需求是软件开发、代码调试、终端操作或需要长时间运行的自动化代理任务,那么 Claude Opus 4.5 更适合你。
**第二个问题:你对上下文长度的需求?**GPT-5.2 提供400K tokens的上下文窗口,是 Claude Opus 4.5(200K tokens)的两倍。如果你经常需要一次性处理多个大型文档、分析完整代码库或进行跨文档的信息综合,GPT-5.2 的大上下文优势会非常明显。对于大多数日常任务,200K tokens已经足够,这时候应该更多考虑其他因素。
**第三个问题:你在中国还是海外使用?**这个问题看似与模型能力无关,但实际上会显著影响你的使用体验。两家公司的官方API在中国大陆都无法直接访问,需要通过可靠的API中转服务。无论选择哪个模型,我们都推荐通过 laozhang.ai 这样的专业中转平台接入,它聚合了 GPT-5.2 和 Claude Opus 4.5 等主流模型,提供稳定的国内访问通道。
快速结论总结:数学推理、抽象推理、超长上下文处理选 GPT-5.2;复杂编程、终端操作、长时代理任务选 Claude Opus 4.5。如果两类需求都有,可以考虑混合使用策略,在不同场景调用不同模型。
基准测试深度对比
基准测试是评估AI模型能力的客观标准。我们整理了当前最权威的测试数据,帮助你从数据角度理解两个模型的真实差距。
编程能力测试(SWE-bench Verified)是评估代码生成和修复能力的核心基准。Claude Opus 4.5 以 80.9% 的成绩领先,GPT-5.2 达到 80.0%,两者差距很小(0.9%)。但需要注意的是,在更高难度的 SWE-bench Pro 测试中,GPT-5.2 反超,达到 55.6%,而 Claude 约为 50%。这说明在常规编程任务上两者几乎打平,但在更复杂的工程问题上,GPT-5.2 表现更稳定。
| 测试项目 | GPT-5.2 | Claude Opus 4.5 | 领先者 |
|---|---|---|---|
| SWE-bench Verified | 80.0% | 80.9% | Claude (+0.9%) |
| SWE-bench Pro | 55.6% | ~50% | GPT (+5.6%) |
| Terminal-bench 2.0 | 47.6% | 59.3% | Claude (+11.7%) |
| AIME 2025 (数学) | 100% | 93% | GPT (+7%) |
| ARC-AGI-2 (推理) | 54.2% | 37.6% | GPT (+16.6%) |
终端操作能力(Terminal-bench 2.0)是评估 DevOps 和后端开发场景的重要指标。这里 Claude Opus 4.5 以 59.3% 大幅领先 GPT-5.2 的 47.6%,差距接近12个百分点。如果你的工作涉及大量命令行操作、系统管理或自动化脚本编写,这个差距会在实际使用中体现出来。
数学能力测试(AIME 2025)中,GPT-5.2 达到了满分100%的表现,而 Claude Opus 4.5 为93%。这是一个7个百分点的差距,在数学密集型任务中会产生明显的体验差异。如果你需要处理复杂的数学计算、算法优化或科学计算任务,GPT-5.2 是更可靠的选择。
抽象推理能力(ARC-AGI-2)是目前区分度最大的测试项。GPT-5.2 达到 54.2%,而 Claude Opus 4.5 仅为 37.6%,差距超过16个百分点。这意味着在需要抽象思维、模式识别和新问题解决的场景中,GPT-5.2 具有显著优势。
安全性方面,Claude Opus 4.5 在提示注入攻击测试中表现最佳,攻击成功率仅为4.7%,比 GPT-5.2 更低。对于企业级应用和对安全性要求高的场景,Claude 的安全性优势值得考虑。
综合基准数据的结论是:GPT-5.2 在推理能力上具有明显优势(数学+16.6%、抽象推理+16.6%),而 Claude Opus 4.5 在实际工程任务中略胜一筹(终端操作+11.7%、SWE-bench Verified +0.9%)。选择时应该根据你的核心使用场景来决定。
编程能力专题对比
编程是大模型最重要的应用场景之一,两个模型在这方面的表现值得深入分析。
GPT-5.2-Codex 的特殊优势。2025年12月18日,OpenAI 在 GPT-5.2 发布一周后推出了专门针对编程场景优化的 GPT-5.2-Codex。根据官方文档(https://openai.com/index/introducing-gpt-5-2-codex/ ),这款模型标志着从"被动编码助手到真正自主代理"的转变,能够管理复杂的、多步骤的工程工作流。Codex 的核心改进包括:通过上下文压缩支持更长的工作周期、在大型代码变更(重构和迁移)上的更强性能、以及显著增强的网络安全能力。如果你的工作涉及大规模代码库的维护和升级,GPT-5.2-Codex 值得重点关注。
Claude Opus 4.5 的工作方式差异。根据开发者社区的反馈,两个模型在处理编程任务时有明显的风格差异。Claude 倾向于更快地开始写代码,它会做出假设然后迭代优化;而 GPT-5.2 更倾向于先提问、读取文件、探索代码库,收集足够上下文后再开始编码。这意味着在需要快速原型开发时,Claude 可能更高效;而在需要深度理解现有代码库的任务中,GPT-5.2 的方法可能更稳健。
不同编程场景的推荐。前端/UI 开发:两者表现相近,可根据个人偏好选择。后端系统开发:Claude Opus 4.5 略有优势,尤其在涉及服务器配置和部署的场景。DevOps 和终端操作:Claude Opus 4.5 明显领先(+11.7%)。代码审查和重构:GPT-5.2-Codex 更适合,特别是大规模重构任务。数据科学和机器学习:GPT-5.2 更适合,因为涉及大量数学计算。
如果你想深入了解 Claude 模型系列的差异,可以参考我们的Claude Opus 4 与 Sonnet 4 的详细对比文章。
成本效益深度分析
成本是企业用户和个人开发者选择模型时的重要考量因素。两个模型的定价策略和成本结构有明显差异。
官方定价对比。Claude Opus 4.5 的定价为每百万输入 tokens 5美元、每百万输出 tokens 25美元。这比上一代 Opus 4.1(15美元/75美元)降价了约67%,是一个重大的价格调整。GPT-5.2 的定价采用更复杂的分层结构,基础价格比 GPT-5.1 高约40%,但提供 Flex 和 Priority 等不同计费档位,可以根据吞吐量和延迟需求灵活选择。
| 模型 | 输入价格 | 输出价格 | 特点 |
|---|---|---|---|
| Claude Opus 4.5 | $5/M tokens | $25/M tokens | 降价67%,批处理可再降50% |
| GPT-5.2 基础 | ~$3.5/M tokens | ~$14/M tokens | 比5.1贵40%,有分层选项 |
| GPT-5.2 Pro | 更高 | 更高 | 最高精度,适合关键任务 |
不同使用量的月度成本估算。轻度用户(月使用100万输入+50万输出 tokens):Claude 约32.5美元,GPT-5.2 约10.5美元。中度用户(月使用1000万输入+500万输出 tokens):Claude 约325美元,GPT-5.2 约105美元。重度用户(月使用1亿输入+5000万输出 tokens):Claude 约3250美元,GPT-5.2 约1050美元。
从纯价格角度看,GPT-5.2 的基础定价更低。但 Claude Opus 4.5 提供的批处理折扣(50%)和提示缓存折扣(最高90%)可以在特定场景下大幅降低成本。对于需要控制成本的团队,laozhang.ai 提供的 API 中转服务价格与官方一致,同时支持多模型切换,帮助开发者灵活管理预算。更多关于 API 定价的详细信息,可以参考我们的ChatGPT API 完整定价指南。
性价比综合评估。如果你的使用场景是 Claude 更擅长的(编程、终端操作),那么即使价格稍高,选择 Claude 可能获得更好的性价比,因为完成任务需要的迭代次数更少。如果你的使用场景是 GPT-5.2 更擅长的(数学推理、大上下文),那么 GPT-5.2 不仅能力更强,价格也更低,是明显的最优选择。
中国用户最佳接入方案
对于中国用户来说,选择哪个模型只是第一步,如何稳定、高效地接入才是实际挑战。OpenAI 和 Anthropic 的官方 API 在中国大陆都无法直接访问,这使得可靠的中转服务成为刚需。
官方 API 的访问限制。OpenAI 的 API 需要海外支付方式和网络环境,且近期收紧了对中国区用户的验证。Anthropic 的情况类似,Claude 的访问限制甚至更严格,许多亚太地区用户报告了账号被封禁的问题。对于需要在生产环境中稳定使用的企业用户,直接使用官方 API 存在较大的风险和不确定性。
laozhang.ai 平台优势。laozhang.ai 作为专业的 API 中转平台,聚合了 GPT-5.2、Claude Opus 4.5 等主流模型,提供稳定的国内访问通道。平台的核心优势包括:聚合多模型、不限速、模型齐全;不封号、按量使用、接入简单;切换模型方便,一个 API Key 访问所有模型。文本模型价格与主流平台一致,充值最低5美元起(约35元人民币),对于需要测试和小规模使用的个人开发者非常友好。
一键接入流程非常简单:访问 https://docs.laozhang.ai/ 注册账号,获取 API Key,然后将官方 SDK 的 base_url 改为 laozhang.ai 的地址即可。无需修改其他代码,与官方 API 完全兼容。如果你想了解更多关于 Claude API 在中国的访问方案,可以参考我们的Claude API 中国访问方案对比文章。
API接入实战指南
对于开发者来说,拿到可运行的代码比任何说明都有价值。这一章节提供 Python 调用示例,可以直接复制使用。
调用 GPT-5.2 的 Python 示例:
pythonfrom openai import OpenAI client = OpenAI( api_key="your-api-key", base_url="https://api.laozhang.ai/v1" ) response = client.chat.completions.create( model="gpt-5.2", # 可选 gpt-5.2-instant, gpt-5.2-thinking, gpt-5.2-pro messages=[ {"role": "system", "content": "你是一个专业的AI助手"}, {"role": "user", "content": "请解释量子纠缠的原理"} ], max_tokens=4000, temperature=0.7 ) print(response.choices[0].message.content)
调用 Claude Opus 4.5 的 Python 示例:
pythonfrom openai import OpenAI # 通过 laozhang.ai 中转调用 Claude Opus 4.5 client = OpenAI( api_key="your-api-key", base_url="https://api.laozhang.ai/v1" ) response = client.chat.completions.create( model="claude-opus-4.5", messages=[ {"role": "system", "content": "你是一个专业的Python开发者"}, {"role": "user", "content": "请帮我重构这段代码,提高可读性和性能"} ], max_tokens=8000, temperature=0.5 ) print(response.choices[0].message.content)
错误处理和重试机制是生产环境必备的:
pythonimport time from openai import OpenAI, APIError, RateLimitError def call_with_retry(client, model, messages, max_retries=3): for attempt in range(max_retries): try: response = client.chat.completions.create( model=model, messages=messages, max_tokens=4000 ) return response.choices[0].message.content except RateLimitError: wait_time = 2 ** attempt # 指数退避 print(f"Rate limited, waiting {wait_time}s...") time.sleep(wait_time) except APIError as e: print(f"API error: {e}") if attempt == max_retries - 1: raise return None
如果你想了解更多 API 网关和接入架构的最佳实践,推荐阅读我们的LLM API 网关开发者指南。
常见问题与总结
**Q1: GPT-5.2 和 Claude Opus 4.5 哪个更强?**没有绝对的答案。GPT-5.2 在数学推理(满分)和抽象推理(+16.6%)上领先;Claude Opus 4.5 在编程(+0.9%)和终端操作(+11.7%)上领先。根据你的核心需求选择。
**Q2: 如果预算有限,应该选哪个?**GPT-5.2 的基础定价更低(约为 Claude 的三分之一),如果预算是首要考虑,GPT-5.2 是更经济的选择。但如果你的任务是 Claude 更擅长的,用 Claude 可能因为迭代次数少而总成本更低。
**Q3: 两个模型可以混合使用吗?**可以,而且很多团队采用这种策略。例如:用 GPT-5.2 做数学计算和数据分析,用 Claude Opus 4.5 做代码生成和调试。通过 laozhang.ai 的统一 API,可以用同一个 Key 访问两个模型,切换非常方便。
**Q4: 中国用户如何稳定使用?**推荐通过 laozhang.ai 等可靠的 API 中转服务。直接使用官方 API 存在网络不稳定和账号风险,中转服务可以提供更稳定的访问体验。详细文档请访问 https://docs.laozhang.ai/。
**Q5: 未来两个模型会如何发展?**根据两家公司的路线图,2026年初可能会有新的重大更新。建议采用模块化的接入架构,方便未来切换和升级模型。
核心结论:数学推理、抽象推理、超长上下文处理选 GPT-5.2;复杂编程、终端操作、长时代理任务选 Claude Opus 4.5。两者都是顶级模型,选择的关键是匹配你的核心使用场景。无论选择哪个,通过 laozhang.ai 接入都能获得稳定的服务体验和一致的API接口,让你专注于业务开发而非基础设施维护。