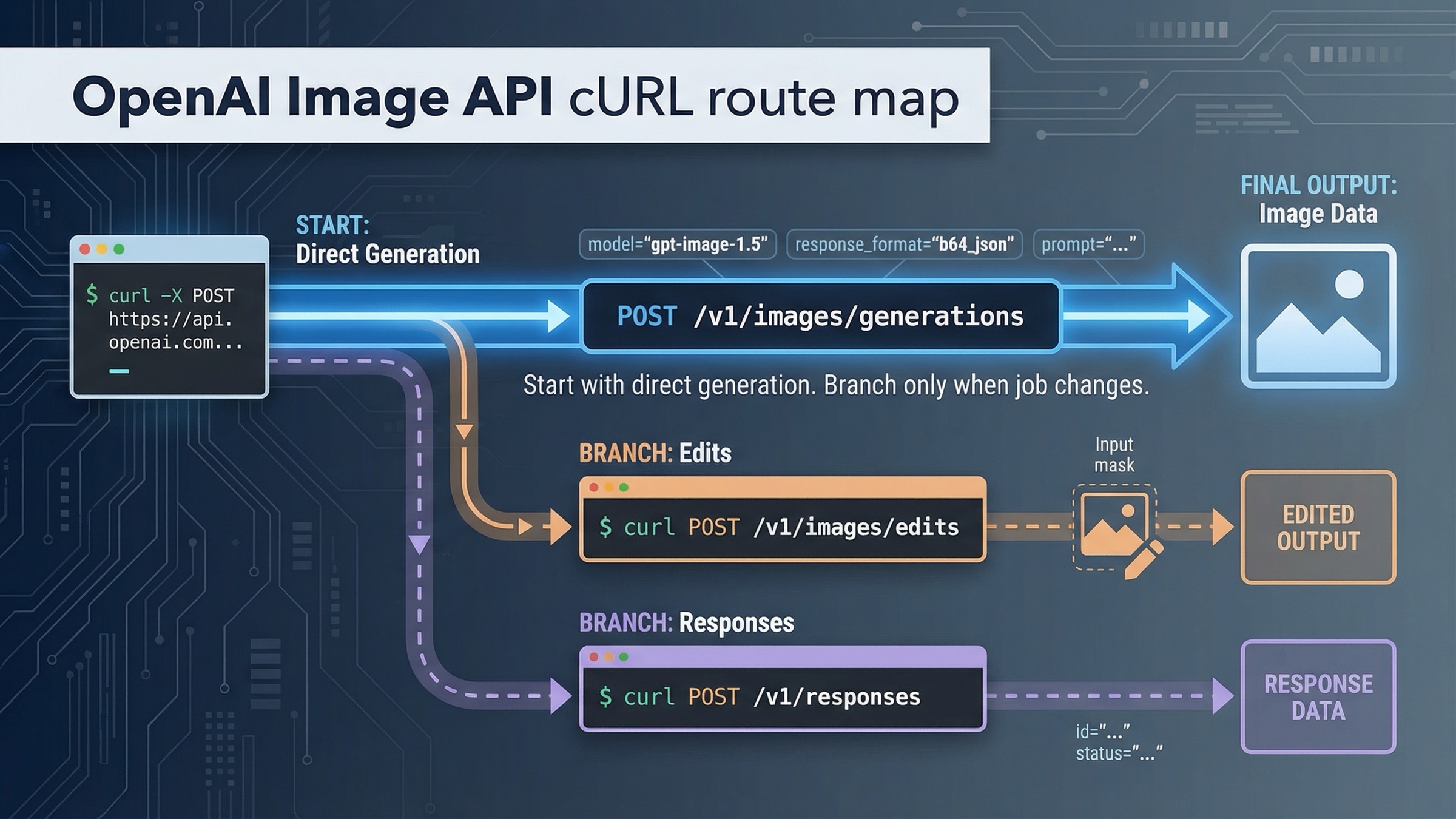
Если вам нужен рабочий OpenAI image generation API cURL запрос по состоянию на сейчас, самый безопасный стартовый маршрут такой: сначала используйте POST /v1/images/generations, сохраните сырой JSON-ответ и явно декодируйте .data[0].b64_json в файл. Для одноразовой генерации по текстовому prompt это по-прежнему самый короткий и наименее хрупкий путь.
Есть только две ситуации, когда этот default действительно стоит менять. Если у вас уже есть входные изображения и задача превратилась в редактирование, переходите на POST /v1/images/edits с multipart-полями. Если генерация изображения является только одним tool-шагом внутри более крупного multimodal workflow, переходите на POST /v1/responses и используйте hosted image_generation tool. Всё остальное чаще всего оказывается преждевременным усложнением.
Этот запрос продолжает казаться запутаннее, чем должен быть, потому что OpenAI разносит ответ по нескольким официальным страницам. Основной image generation guide объясняет общую маршрутизацию и параметры. Images API reference задаёт сырой контракт endpoint-ов. Responses image_generation tool guide описывает альтернативную tool-ветку. И по состоянию на 24 марта 2026 года официальный guide всё ещё показывал GPT Image cURL snippet против https://api.openai.com/v1/images, тогда как reference документировал /images/generations и /images/edits как сырые endpoint-ы. Эта статья нужна именно для того, чтобы собрать эти куски в один рабочий shell workflow.
Краткое содержание
- Для первого рабочего cURL-теста используйте
POST /v1/images/generationsиgpt-image-1.5. - По умолчанию GPT image models возвращают
b64_json, а не hosted image URL. - На
POST /v1/images/editsпереходите только тогда, когда у вас уже есть исходные изображения. - На
POST /v1/responsesпереходите только тогда, когда генерация картинки является частью более крупного tool-driven workflow.
Начните с POST /v1/images/generations для прямой генерации одной картинки

Если ваша реальная задача звучит как «отправить prompt из shell или backend smoke test и получить одну картинку», direct Images API остаётся лучшим местом для старта. Официальный Images API reference явно называет POST /images/generations raw route для генерации, то есть полный production URL выглядит как https://api.openai.com/v1/images/generations.
Именно этот путь стоит рекомендовать первым, потому что он делает первый успешный цикл минимальным:
- отправить JSON
- получить JSON
- извлечь base64
- сохранить финальный файл
Это ещё и соответствует актуальной линейке моделей. Официальная страница All models перечисляет GPT Image 1.5 как current state-of-the-art image generation model, а также показывает chatgpt-image-latest как ChatGPT alias, gpt-image-1 как previous model и gpt-image-1-mini как budget lane. Поэтому для нового cURL-примера правильный default сегодня это gpt-image-1.5, а не GPT Image 1 и уж точно не DALL-E-era fallback.
Начните с такого запроса:
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Create a clean editorial illustration of a robot camera operator in a bright studio", "size": "1024x1024", "quality": "medium" }' > response.json
Этот пример специально «скучный», и это правильно. Официальный guide по-прежнему пишет, что квадратные изображения обычно самые быстрые, а 1024x1024 остаётся default size. Первая проверка не должна одновременно доказывать прозрачный фон, landscape composition, streaming partial images, сложные edit-ветки и кроссплатформенный decode. Она должна подтвердить всего несколько вещей:
- У аккаунта есть доступ к модели.
- Endpoint выбран правильно.
- Payload имеет корректную форму.
- Ответ приходит в ожидаемой структуре.
- Вы реально можете превратить ответ в usable image file.
Краткое разделение маршрутов, которое нужно большинству читателей, выглядит так:
| Ситуация | Лучший raw path | Что делать с model | Почему это default |
|---|---|---|---|
| Одноразовая генерация из текста | POST /v1/images/generations | Просто использовать gpt-image-1.5 | Самый короткий и предсказуемый cURL workflow |
| Редактирование или комбинирование существующих изображений | POST /v1/images/edits | Всё ещё gpt-image-1.5 | Та же family direct Images API, но с multipart |
| Генерация картинки внутри более крупного assistant workflow | POST /v1/responses c image_generation tool | Наверху нужен текстовый mainline model вроде gpt-5 | Подходит только когда изображение уже не единственный output |
Эта таблица выглядит просто, потому что сама развилка действительно проста, если перестать смешивать разные API surfaces. Главная ошибка page one в том, что generation, edits и Responses подаются как будто это взаимозаменяемые «примеры image API». На практике они отвечают на разные задачи.
Есть и одна budget caveat, которую полезно назвать заранее. Если ваш первый вопрос не «какой default flagship выбрать», а «как дешевле прогнать первый benchmark», текущий model catalog также даёт gpt-image-1-mini как cost-efficient lane. Endpoint от этого не меняется, но меняется модель, с которой стоит начинать сравнение. Если именно это ваш следующий вопрос, переходите к нашему русскоязычному материалу OpenAI image generation API models.
Если после этой статьи вам нужна более широкая дискуссия именно про выбор surface, читайте OpenAI image generation API endpoint. Эта страница уже и уже сознательно: она должна сначала дать читателю надёжный raw shell path.
Что на самом деле возвращает ответ и как безопасно его декодировать

Самая частая cURL-специфическая проблема здесь вовсе не в самом POST. Она начинается сразу после успешного ответа.
Официальный Images API reference пишет, что объект Image содержит b64_json, revised_prompt и url, а затем добавляет деталь, которая для shell-пользователя важнее всего: для GPT image models b64_json возвращается по умолчанию, а URL output не является default path. Поэтому сильная cURL-статья не может останавливаться на фразе «вот request body». Она обязана закрыть и decode step.
Самая безопасная привычка оператора состоит в том, чтобы сначала сохранить сырой response:
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Create a clean editorial illustration of a robot camera operator in a bright studio", "size": "1024x1024", "quality": "medium" }' > response.json jq '.data[0] | {has_b64_json: has("b64_json"), revised_prompt, url}' response.json
Этот дополнительный jq шаг стоит тех секунд, которые на него уходят. Он подтверждает shape ответа до того, как вы отправите бинарные данные дальше по pipe, и даёт вам что посмотреть, когда HTTP request формально успешен, но финальный файл пустой или повреждённый.
В Linux или любой среде с GNU base64 decode может быть коротким:
bashjq -r '.data[0].b64_json' response.json | base64 --decode > openai-image.png
На macOS чаще нужен флаг -D вместо --decode:
bashjq -r '.data[0].b64_json' response.json | base64 -D > openai-image.png
Если вы хотите один переносимый способ, который полностью уходит от отличий между GNU и BSD, проще всего отдать decode Python:
bashjq -r '.data[0].b64_json' response.json \ | python -c 'import sys, base64; sys.stdout.buffer.write(base64.b64decode(sys.stdin.read()))' \ > openai-image.png
Это как раз то место, где статья может реально побить средний SERP-результат. Слабые cURL-примеры часто делают обратное: немедленно pipe-ят request в jq, предполагают, что один base64 флаг работает везде, и оставляют пользователя один на один с broken output file, если shell у автора отличался от shell у читателя.
Есть и ещё одна типичная путаница в форме ответа. Старый OpenAI image content приучил многих разработчиков ожидать URL field как основной happy path. Именно поэтому примечание из reference так важно. Для текущих GPT image models default response это base64 payload. Поэтому если ваш скрипт до сих пор пытается забирать .data[0].url, вы отлаживаете уже не ту эпоху API.
Именно здесь mismatch между guide и reference перестаёт быть абстракцией. Основной guide сейчас показывает GPT Image cURL snippet против https://api.openai.com/v1/images, в то время как raw reference называет POST /images/generations. Для cURL-first статьи более безопасно опираться на route names из reference, потому что именно там OpenAI публикует наиболее ясный сырой контракт.
Если дальше вам нужна более широкая page с JavaScript, Python и cURL примерами одновременно, переходите к OpenAI image generation API example. Здесь же задача уже: сделать raw HTTP workflow надёжным, а не просто показать ещё один snippet.
Используйте multipart POST /v1/images/edits, когда у вас уже есть исходные изображения
Если у вас уже есть product shot, brand asset или reference image, не стоит растягивать generation route до тех пор, пока он случайно не превратится в editing tutorial. Правильный ход не в том, чтобы менять surface, а в том, чтобы остаться на direct Images API и перейти на edit branch.
Официальный Images API reference называет POST /images/edits raw edit endpoint, а основной image generation guide уже содержит актуальный cURL пример с multipart upload и повторяющимися полями image[].
Сырой шаблон выглядит примерно так:
bashcurl -s -D >(grep -i x-request-id >&2) \ -o >(jq -r '.data[0].b64_json' | base64 --decode > edited-image.png) \ -X POST "https://api.openai.com/v1/images/edits" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "image[]=@product-shot.png" \ -F "image[]=@logo.png" \ -F 'prompt=Place the logo on the product box as if it were printed on the packaging.'
Первая важная развилка здесь такая: generation использует JSON, edits используют multipart form fields. Очень многие 400-level ошибки возникают не из-за экзотических параметров, а из-за попытки протолкнуть image upload через тот же Content-Type: application/json, который годится только для prompt-only generation.
Вторая развилка связана с fidelity. Официальный guide пишет, что для gpt-image-1.5 первые 5 входных изображений могут сохраняться с большей точностью, если добавить input_fidelity=high. Это имеет значение в тех случаях, когда вы действительно хотите сохранить composition, logo placement, лицо, фирменный стиль или другие source details, а не просто получить свободную вариацию.
В raw cURL это выглядит так:
bashcurl -s \ -X POST "https://api.openai.com/v1/images/edits" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "image[]=@woman.jpg" \ -F "image[]=@logo.png" \ -F "input_fidelity=high" \ -F 'prompt=Add the logo to the woman'\''s jacket as if stitched into the fabric.' \ > edit-response.json
Не стоит включать input_fidelity=high просто по привычке. Включайте его тогда, когда главная задача edit-запроса заключается именно в более точном сохранении исходного изображения. Если ваша цель более свободная, а cost или speed важнее, оставьте этот параметр в стороне.
Именно здесь многие «более продвинутые» tutorial-ы начинают уводить читателя не туда. Они видят, что image job стал сложнее, и почти автоматически отправляют пользователя на Responses API. Это неверный вывод. Editing по-прежнему остаётся first-class direct Images API use case. Менять route нужно тогда, когда меняется workflow, а не тогда, когда image task становится серьёзнее.
Если ваш реальный следующий вопрос уже шире route choice и вам нужен полный guide именно по editing, правильнее перейти к OpenAI image editing API. Для cURL query главный вывод проще: когда у вас уже есть source images, используйте multipart edits и не усложняйте surface раньше времени.
Переходите на /v1/responses только тогда, когда генерация изображений является частью большего workflow
Responses image_generation tool guide нужен для другой задачи, нежели direct Images API. Он предназначен для случаев, когда генерация изображения уже не является единственным продуктом запроса, а становится одним tool внутри более крупного model interaction.
Это различие важно потому, что меняются уже не только endpoint-ы, но и field-level rules.
Guide формулирует главное правило прямо: GPT image models не подходят в качестве значения для top-level model field в Responses API. Когда вы используете /v1/responses, верхнеуровневый model должен быть mainline text-capable model вроде gpt-4.1 или gpt-5, а hosted image_generation tool уже вызывает image layer внутри этого workflow.
Сырой cURL шаблон выглядит так:
bashcurl https://api.openai.com/v1/responses \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-5", "input": "Generate a transparent sticker-style icon of a paper airplane for a travel app", "tools": [ { "type": "image_generation", "background": "transparent", "quality": "high" } ] }' > responses-output.json jq -r '.output[] | select(.type=="image_generation_call") | .result' responses-output.json \ | python -c 'import sys, base64; sys.stdout.buffer.write(base64.b64decode(sys.stdin.read()))' \ > plane.png
Этот route оказывается правильным тогда, когда:
- один и тот же call может возвращать текст и изображение
- модель должна сама решать, когда вызывать image tool
- image output является только частью большего assistant или agent flow
И он оказывается избыточным тогда, когда:
- вы просто хотите один prompt-to-image request
- вам ещё нужно сначала доказать raw endpoint access
- вы всё ещё отлаживаете account state, model name или output decoding
Практическое правило остаётся очень простым. Не начинайте с Responses только потому, что он выглядит новее. Начинайте с Responses только тогда, когда orchestration и есть реальная задача.
Именно здесь статья должна показывать judgment, а не просто повторять структуру документации. Большинство людей, приходящих по exact-match query, на самом деле не ищут философское сравнение API. Им нужно понять, облегчит ли /v1/responses первую cURL-команду или усложнит её. В типичном случае усложнит.
Если вам нужна более широкая tutorial page после этого раздела, переходите к OpenAI image API tutorial. Здесь Responses branch намеренно оставлен узким, чтобы default workflow не размывался.
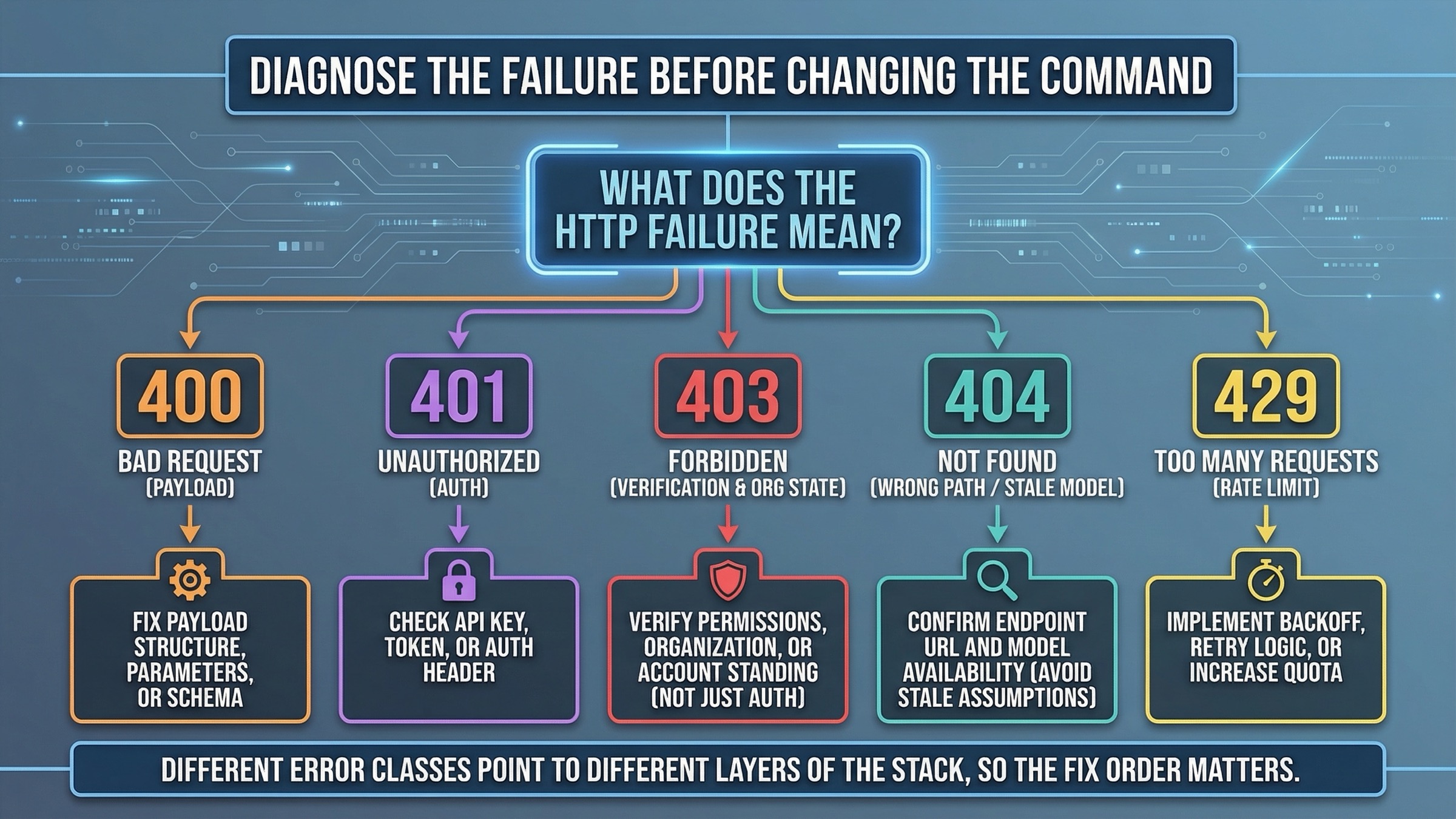
Troubleshooting: какие ошибки cURL означают проблему payload, а какие указывают на доступ
Это именно тот раздел, который page one чаще всего недостраивает.
Когда cURL example падает, следующий вопрос не в том, «какой параметр поменять случайно». Следующий вопрос такой: «какой это вообще класс ошибки?» Потому что fix order зависит от того, сломан ли у вас payload, API key, organization state, model assumption или account limits.
Начните с этой таблицы:
| Что вы видите | Что это обычно значит | Что проверять первым |
|---|---|---|
400 Bad Request | Неверная JSON shape, неправильный Content-Type или JSON там, где для edits нужен multipart | Снова проверить endpoint, body format и то, должны ли вы использовать -d или -F |
401 Unauthorized | Неверный или отсутствующий API key | Проверить OPENAI_API_KEY, shell expansion и то, что key относится к правильному project |
403 c verification или image-access wording | Проблема чаще связана с account state, а не с кодом | Проверить organization verification, active org, propagation delay и новую key |
404 или model-not-found wording | Неверный path, устаревшее предположение о модели или rollout-era snippet | Снова проверить endpoint path и актуальность model name |
429 или rate-limit wording | Это tier/throughput problem, а не malformed cURL | Проверить rate limits, usage tier и то, не стоит ли снизить volume или quality |
Ветка 403 особенно важна, потому что внешне она часто выглядит как проблема кода, хотя на деле это account-state problem. Официальная статья API Organization Verification прямо говорит, что verification unlocks image generation capabilities in the API, а если not-verified wording не исчезает, нужно подождать до 30 минут, создать новый API key, обновить сессию и убедиться, что активна правильная организация. Это не второстепенный cleanup. Это и есть самая ценная fix sequence для данного класса ошибки.
Официальная страница API Model Availability by Usage Tier and Verification Status добавляет вторую подсказку про access: gpt-image-1 и gpt-image-1-mini доступны для tiers 1 through 5, а часть доступа зависит от organization verification. Поэтому, если вы отлаживаете 403 или 429, не стоит автоматически трактовать их как JSON typo.
Ветка 404 требует другого типа осторожности. Официальный GPT-Image-1.5 rollout thread показывает, что во время первоначального rollout 16 декабря 2025 года разработчики действительно видели model-not-found errors и supported-value lists, где gpt-image-1.5 ещё отсутствовал. Это объясняет, почему по этому query до сих пор плавают stale snippets. Но это не означает, что rollout-era 404 надо считать default explanation сегодня. Сейчас безопаснее сначала проверить path, model name и источник snippet-а.
Есть и ещё один failure mode, который не является HTTP error вовсе: вы получили 200 OK, но финальный файл пустой или нечитаемый. В этом случае request может быть полностью корректным, а decode step ошибочным. Поэтому снова и снова полезнее всего сохранять response.json, проверять .data[0].b64_json и декодировать явно, а не предполагать, что shell pipeline уже идеален.
Ещё одна практическая привычка, которую стоит забрать из официального edit example: выводите request ID, когда можете. Для shell это дешёвый способ сократить путь до следующего debugging шага:
bashcurl -s -D >(grep -i x-request-id >&2) \ -o response.json \ https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Create a clean editorial illustration of a robot camera operator in a bright studio", "size": "1024x1024", "quality": "medium" }'
Это не исправит плохой request само по себе, но резко сократит следующий шаг, если проблема находится на стороне OpenAI или в account state, а не в вашей terminal command.
Если ваш blocker явно связан с verification, а не с payload shape, следующая точечная статья здесь это OpenAI image generation API verification.
Параметры, которые стоит менять только после того, как первый запрос уже работает
Когда базовый request уже успешен, только тогда имеет смысл начинать оптимизацию. Официальный guide и reference вместе подсказывают, какие knobs сегодня действительно важны:
size:1024x1024,1024x1536,1536x1024илиautoquality:low,medium,highилиautobackground:transparent,opaqueилиautooutput_format:png,webpилиjpeg
Самое практичное инженерное решение всё ещё одно и то же: первая successful request должна оставаться простой. Если вы меняете size, quality, output format и transparency ещё до того, как первый request вообще сработал, у вас не остаётся чистой baseline-точки, по которой можно понять, проблема ли это access, payload shape или output handling.
Для большинства one-shot generation tests лучше:
- оставить
sizeравным1024x1024 - оставить
qualityнаmedium - не трогать background, пока прозрачность не является реальным requirement
- отложить file-format optimization до тех пор, пока сам route не доказан
Если вам нужен прозрачный output, и guide, и reference поддерживают этот branch. Сырой запрос просто становится более явным:
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Draw a transparent sticker-style icon of a paper airplane for a travel app", "size": "1024x1024", "quality": "high", "background": "transparent", "output_format": "png" }' > transparent-response.json
Если вам важнее меньший transfer size, чем alpha support, переходите на jpeg или webp, но уже после того, как основной путь подтверждён. Если вас интересуют streaming previews или partial_images, официальный guide действительно показывает и этот branch, но это уже точно не то место, откуда стоит начинать cURL-first reader. Это optimize-later feature, а не главный ответ на данный query.
Здесь статья тоже может сэкономить читателю много времени. Многие разработчики делают prompt tuning первой оптимизацией. Для raw API workflow это обычно неверный порядок. Гораздо безопаснее идти так:
- доказать endpoint и output path
- доказать decode path
- доказать правильный route branch
- только потом оптимизировать quality, size, background и детализацию prompt-а
Если после этого вашим следующим вопросом становится cost, а не raw HTTP shape, переходите к OpenAI image generation API pricing. О цене всегда проще рассуждать после того, как сам route уже стабилен.
Итоговая рекомендация
Если нужен самый короткий безопасный rule, используйте такой: сначала POST /v1/images/generations, затем явное декодирование b64_json, переход на multipart /v1/images/edits только когда уже есть входные изображения, и переход на /v1/responses только тогда, когда генерация картинки является частью более крупного tool-driven workflow.
Именно это правило выигрывает у среднего результата в SERP, потому что оно закрывает весь shell workflow, а не только один screenshot-worthy request. Оно ещё и честно отражает то, как сейчас реально разбита документация OpenAI: guide нужен для route choice, reference нужен для raw endpoint-ов, model pages нужны для freshness, а help pages нужны для access failures. Сильная cURL-статья должна сшивать эти куски вместе так, чтобы читатель мог довести задачу до рабочего состояния, а не просто посмотреть на красивый snippet.