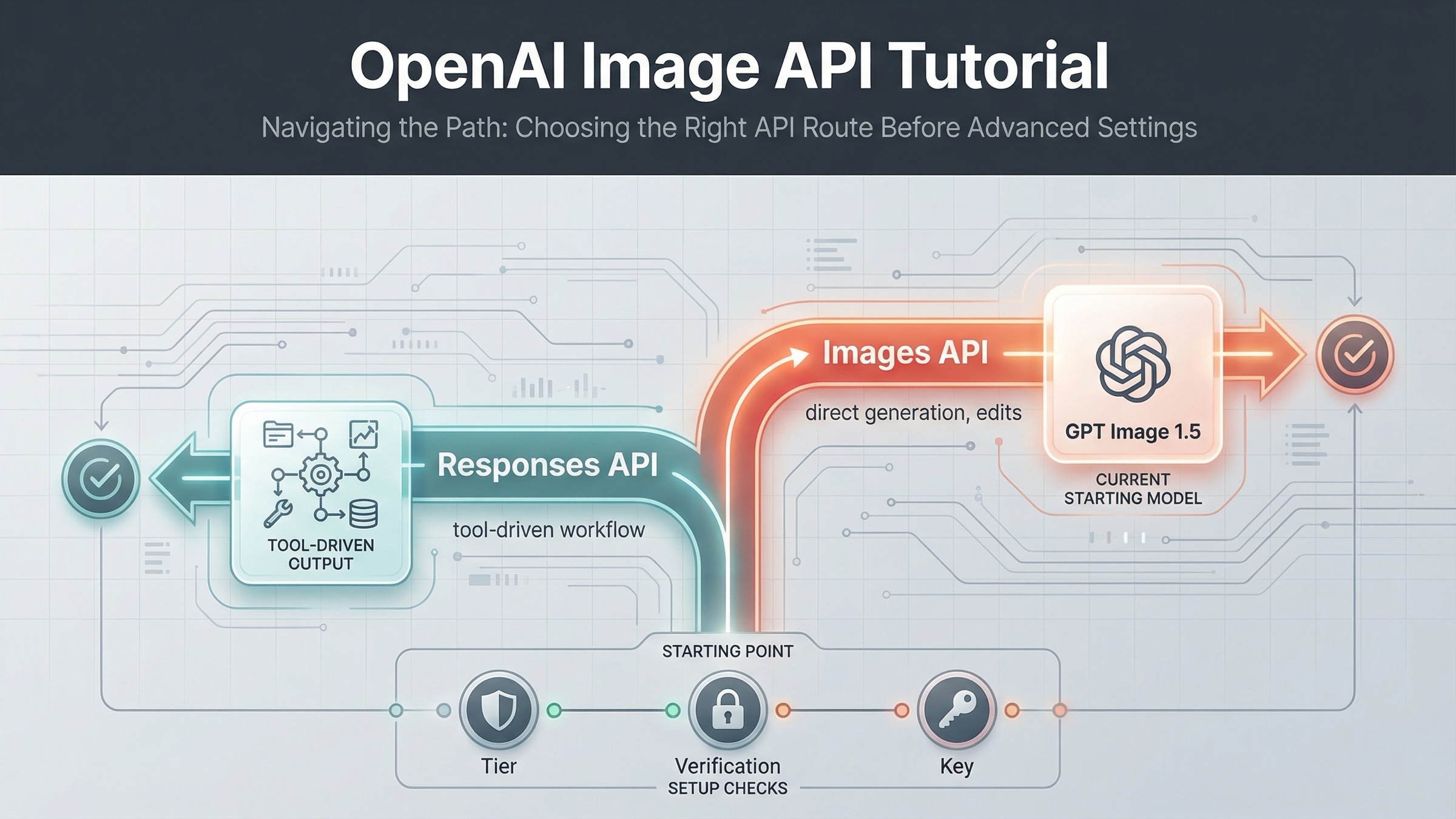
По состоянию на 22 марта 2026 года самый безопасный дефолт такой: если вам нужна прямая генерация изображения или edit existing image, начинайте с Images API; если image generation — только один tool внутри большего multimodal workflow, переходите к Responses API. Именно этот route split чаще всего и отсутствует в слабых tutorials.
Этот keyword кажется сложнее, чем должен быть, потому что OpenAI разнесла ответ по нескольким страницам. Основной guide по image generation показывает direct generation и edits. Более широкий images and vision guide показывает image_generation tool внутри Responses API. Текущий модельный каталог уже ставит GPT Image 1.5 как текущий flagship, gpt-image-1-mini как budget lane, chatgpt-image-latest как ChatGPT alias, а DALL-E 3 помечает как deprecated. Если читать только одну страницу, картинка получается неполной.
Из-за этого многие разработчики начинают не с той ветки. Кто-то берет старый DALL-E tutorial. Кто-то сразу идет в SDK code и не проверяет usage tier, organization verification или правильный active org. Эта статья нужна именно для того, чтобы вернуть правильный порядок: сначала route, потом access, потом examples, потом tuning.
Краткое содержание
- Прямая генерация, single-step edits, самый короткий onboarding: начинайте с Images API.
- Image generation как часть большего assistant workflow: используйте Responses API.
- Стартовый current model —
gpt-image-1.5; если cost — первый вопрос, отдельно тестируйтеgpt-image-1-mini. - Если пример "валидный", но ничего не работает, сперва проверяйте tier, verification, active organization и API key, а не prompt wording.
Сначала выберите правильный маршрут API
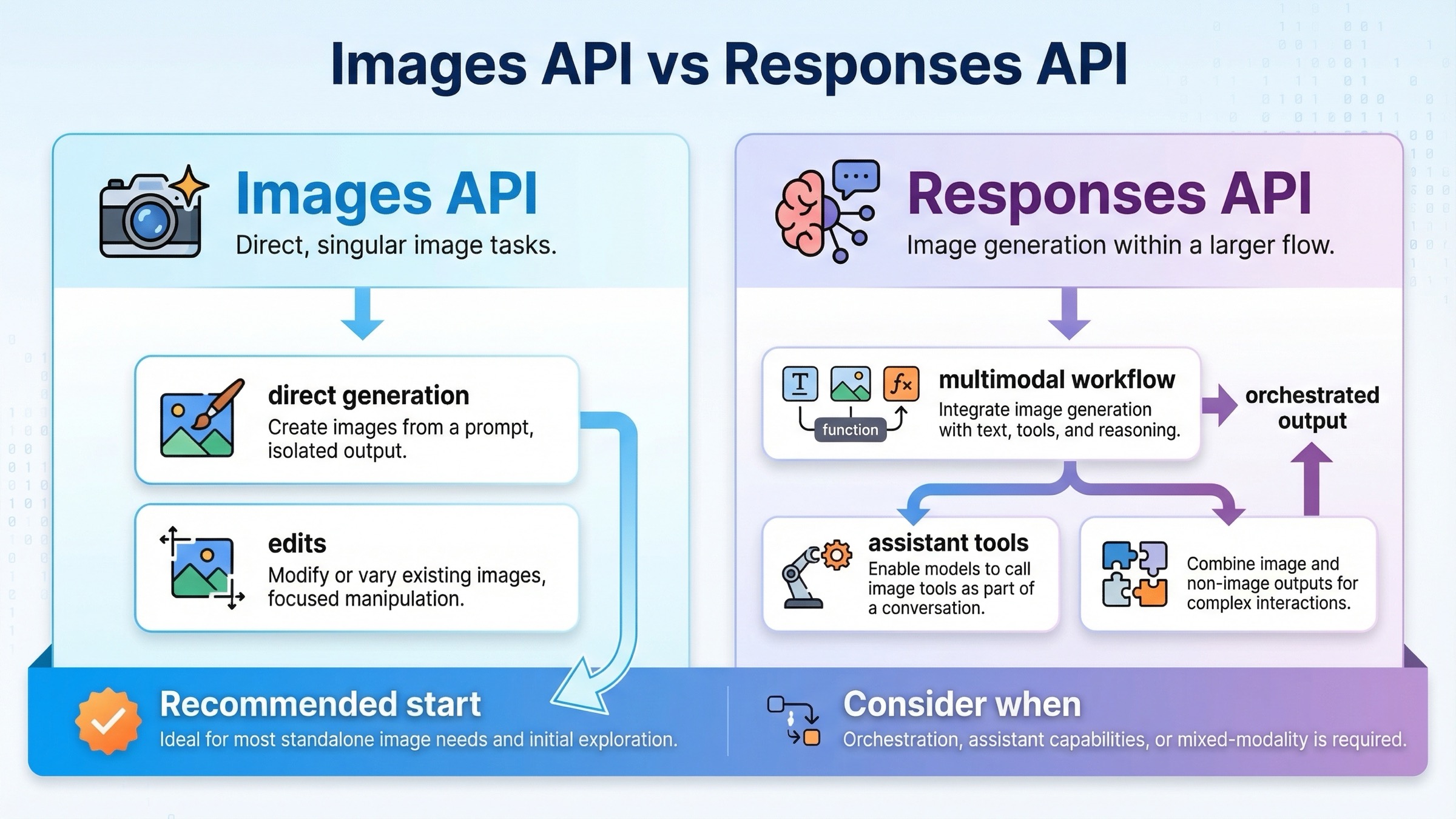
Если запомнить только одну вещь, пусть это будет именно она: текущий OpenAI image stack проще всего использовать, когда вы не пытаетесь решить все задачи одним и тем же endpoint.
| Ситуация | Лучший старт | Почему |
|---|---|---|
| Нужен один request, который просто сгенерирует изображение и сохранит его | Images API | Наименьше абстракций и самый прямой tutorial path |
| Нужно отредактировать одну или несколько исходных картинок | Images API | Official docs собирают edit flow, masks и input_fidelity именно здесь |
| Вы строите assistant, где image generation только часть larger flow | Responses API | Картинка работает как встроенный tool рядом с text и другими outputs |
| Нужно быстро дать команде working proof of concept | Images API | Меньше orchestration и меньше шансов выбрать неправильный слой слишком рано |
| Нужно смешивать images, text, tools и conversation state | Responses API | В этом случае его tool model уже лучше соответствует задаче |
Практическое правило очень простое: если image generation — сам продуктовый surface, держитесь client.images.generate() и client.images.edit(); если картинка — только один шаг, используйте client.responses.create() с image_generation tool.
Именно это лучше всего объясняет различие между official docs и реальной tutorial intent. Для reference pages нормально, что одна страница про direct generation, а другая — про broader multimodal path. Но для tutorial page, которую читает разработчик "сделать первую картинку сегодня", такой split нужно объяснить в первых абзацах.
Прежде чем писать код, проверьте access и model IDs
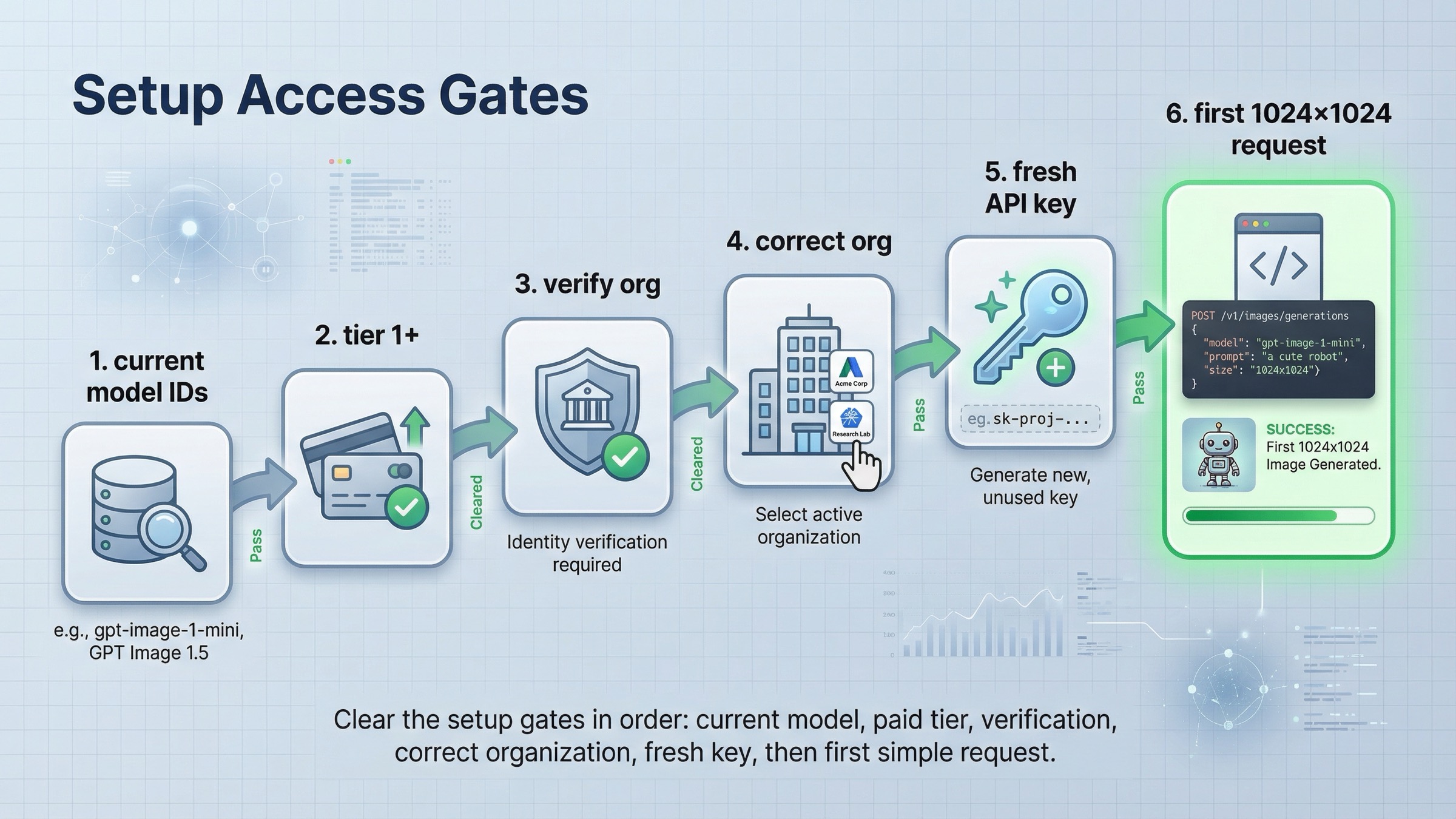
Слишком многие tutorials начинают с кода и молча предполагают, что доступ уже есть. В этой теме это плохая привычка.
Сначала используйте актуальные model IDs. Текущий каталог OpenAI раскладывает image family так:
| Модель | Роль сейчас | Когда брать |
|---|---|---|
| GPT Image 1.5 | current flagship | Новый проект, quality-first scenarios, edits, более надежное prompt following |
gpt-image-1-mini | budget lane | Массовые tests, cheap prototypes, cost-first flows |
chatgpt-image-latest | ChatGPT alias | Только если вы сознательно хотите current ChatGPT image snapshot |
| GPT Image 1 | previous model | Legacy compatibility и migration reference |
| DALL-E 3 / DALL-E 2 | deprecated | Не стоит строить на них fresh tutorial |
Это уже само по себе снимает половину путаницы. Поисковая выдача до сих пор смешивает launch-era и DALL-E-era pages с текущими GPT Image docs, поэтому route без model freshness сейчас особенно важен.
Далее проверьте account access. Текущая статья API Model Availability by Usage Tier and Verification Status прямо говорит, что GPT-image-1 и GPT-image-1-mini доступны пользователям API на tiers 1 through 5, а часть доступа зависит от organization verification. Текущая страница GPT Image 1.5 также указывает Free not supported и показывает Tier 1 с 100,000 TPM и 5 IPM. Это значит, что ваша tutorial failure может произойти еще до того, как код вообще станет релевантен.
Если подозрение падает на verification, перестаньте менять prompt. Текущая API Organization Verification рекомендует проверить правильную organization, подождать до 30 минут, создать новый API key, обновить сессию и только потом повторять тест. Это access branch, а не code branch.
SDK setup при этом максимально простой. В Node.js:
bashnpm install openai
В Python:
bashpip install openai
Затем выставьте OPENAI_API_KEY и сделайте один максимально boring test: 1024x1024, короткий prompt, никакого multi-image edit и никаких transparency tricks на первом же request. Current guide прямо говорит, что square image — стандартный и самый быстрый старт.
Самый быстрый working example на Images API
Для прямого tutorial path Images API по-прежнему лучшее начало, потому что держит всю ментальную модель прозрачной: вы явно выбираете image model, явно задаете output settings и явно сохраняете результат.
Минимальный JavaScript example выглядит так:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.generate({ model: "gpt-image-1.5", prompt: "Create a clean editorial illustration of a robot camera operator in a bright studio", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; const imageBytes = Buffer.from(imageBase64, "base64"); fs.writeFileSync("openai-image-api-demo.jpg", imageBytes);
Python-path почти такой же:
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.generate( model="gpt-image-1.5", prompt="Create a clean editorial illustration of a robot camera operator in a bright studio", size="1024x1024", quality="medium", output_format="jpeg", output_compression=80, ) image_base64 = result.data[0].b64_json image_bytes = base64.b64decode(image_base64) with open("openai-image-api-demo.jpg", "wb") as f: f.write(image_bytes)
Это хороший first success target по трем причинам. Во-первых, он использует текущий flagship model ID. Во-вторых, держит size и quality на безопасном уровне. В-третьих, он сразу показывает, как обращаться с base64 output, а не заставляет вас опираться на старые URL-oriented assumptions.
Когда basic generation уже работает, можно идти в edits. Current OpenAI guide показывает edit flow с несколькими input images и input_fidelity. Если вам нужен более близкий edit к исходной картинке, а не вольная перерисовка, именно этот параметр сейчас особенно полезен.
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1.5", image: [ fs.createReadStream("woman.jpg"), fs.createReadStream("logo.png"), ], prompt: "Add the logo to the woman's jacket as if stitched into the fabric.", input_fidelity: "high", }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync( "woman-with-logo.png", Buffer.from(imageBase64, "base64") );
Самая полезная operational rule здесь такая: сначала добейтесь стабильного direct generation, а уже потом усложняйте задачу edit-потоком.
Когда Responses API действительно лучше
Responses API нужен не потому, что он "новее", а потому, что он лучше подходит для случаев, где image generation — только одна часть большего reasoning или assistant workflow. Именно поэтому official examples показывают image_generation как встроенный tool в responses.create().
JavaScript example выглядит так:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const response = await client.responses.create({ model: "gpt-5", input: "Draw a transparent sticker-style icon of a paper airplane for a travel app", tools: [ { type: "image_generation", background: "transparent", quality: "high", }, ], }); const imageBase64 = response.output .filter((item) => item.type === "image_generation_call") .map((item) => item.result)[0]; fs.writeFileSync("paper-airplane.png", Buffer.from(imageBase64, "base64"));
Python version:
pythonfrom openai import OpenAI import base64 client = OpenAI() response = client.responses.create( model="gpt-4.1-mini", input="Generate a product hero image of a ceramic mug on a white background", tools=[{"type": "image_generation"}], ) image_data = [ output.result for output in response.output if output.type == "image_generation_call" ] if image_data: with open("mug.png", "wb") as f: f.write(base64.b64decode(image_data[0]))
Этот маршрут становится логичным, когда:
- вам нужен unified assistant flow
- картинка должна возвращаться рядом с text и другими tools
- image generation — это не отдельная feature, а один из шагов
Если же задача звучит как "сделать и сохранить картинку", Responses API на старте только повышает cognitive load. Он хорош там, где уже оправдан broader orchestration.
Отдельно важна и date context. OpenAI changelog показывает, что 19 декабря 2025 года OpenAI добавила gpt-image-1.5 и chatgpt-image-latest в support для image generation tool внутри Responses API. Поэтому старые launch posts, где Responses support описывается как coming soon, исторически верны, но уже не актуальны.
Какие настройки реально меняют результат и стоимость
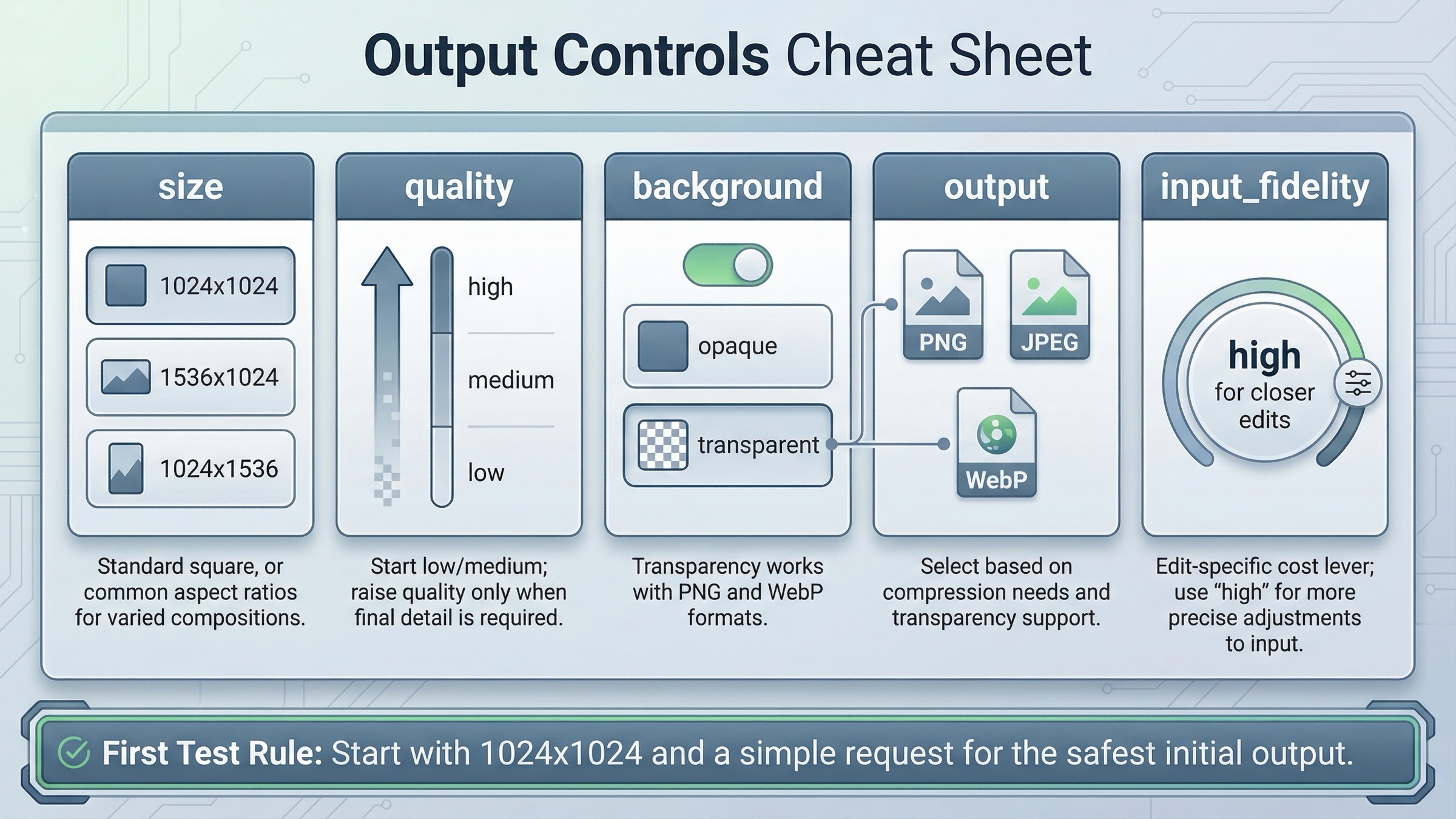
После первого успешного request не нужно сразу включать все advanced options. Намного полезнее понять, какие параметры действительно меняют качество, latency или spend.
В current image guide ключевые группы такие:
sizequalitybackgroundoutput_formatoutput_compressioninput_fidelity
Лучше думать не "какие тут есть поля", а "какое решение они меняют".
Size меняет композицию и cost. Для первого smoke test держитесь 1024x1024. Official guide прямо говорит, что square images — fastest starting point. Переходите к 1536x1024 или 1024x1536 только когда композиция действительно этого требует.
Quality меняет и latency, и budget. На current GPT Image 1.5 model page 1024x1024 low стоит $0.009, medium — $0.034, high — $0.133. Разница уже достаточно большая, чтобы не делать high своим дефолтом для prototypes.
Background становится важным, когда нужен transparent asset. Current docs говорят, что background: "transparent" поддерживается у GPT Image models вместе с PNG и WebP. Если tutorial этого не объясняет, люди часто принимают transparency issues за model weakness.
Output format и compression — это уже вопрос delivery shape. Current guide говорит, что Image API возвращает base64-encoded image data, default format — PNG, а также поддерживает JPEG и WebP. Если latency важнее alpha channel, JPEG часто оказывается более practical.
input_fidelity — это отдельный edit-specific lever. Он особенно важен, когда вы не хотите свободную переработку, а хотите closer edit к исходной картинке. Именно поэтому его разумно объяснять после first working request, а не в самом первом tutorial example.
Лучшая operational привычка здесь одна: меняйте по одному параметру за раз. Не переключайте одновременно model, size, quality, transparency и edit inputs. Иначе вы не поймете, что именно дало лучший результат или резкий рост cost.
Если ваша реальная следующая задача уже не "как запустить", а "сколько это будет стоить на масштабе", дальше логичнее идти в локальную статью про OpenAI Image Generation API pricing.
Те failure branches, которые tutorials обычно не показывают
В этой теме самое дорогое по времени — не syntax errors, а неверно выбранная branch of troubleshooting. Многие tutorials заканчиваются после happy path и молча предполагают, что если у вас не заработало, значит вы где-то не так скопировали код. На практике это не так.
Сначала 403 verification errors. Если ошибка прямо говорит про organization verification, не трогайте prompt и SDK version. Current help-center guidance советует проверить active org, подождать до 30 минут, создать новый API key, обновить session и только потом пробовать снова. Community threads переполнены кейсами, где dashboard уже говорит "verified", а Images Playground все еще заблокирован. Это access-context problem, а не code problem.
Дальше 429 на аккаунте, который выглядит funded. Это один из самых раздражающих branches. В OpenAI Developer Community есть несколько threads, где пользователи пополняли баланс и все равно получали rate_limit_exceeded на image models. Практический вывод один: проверяйте usage tier, а не только visible balance.
Потом идут edit failures и mask constraints. Current guide прямо пишет, что image и mask должны быть одного формата, одного размера и меньше 50MB. Если эту часть пропустить, edit flow начинает казаться случайным, хотя API ведет себя предсказуемо.
Есть и более тихая ошибка: старые tutorials до сих пор предполагают URL-centric output. Но current GPT Image path завязан на base64 image data. Если вы продолжаете строить post-processing вокруг старой URL-модели, downstream logic сломается даже тогда, когда request technically успешен.
Если проблема выглядит шире, чем один ваш request, проверьте OpenAI Status. На 22 марта 2026 года публичный статус говорит, что система fully operational. То есть local troubleshooting сегодня важнее, чем гипотеза о глобальном outage.
Если ваш реальный blocker по-прежнему verification, а не implementation, дальше полезнее читать локальную статью про verification error в OpenAI Image API.
Чеклист перед продакшном
Когда первый request уже работает, правильный следующий шаг — не "срочно усложнить архитектуру", а зафиксировать решения, которые действительно важны в продакшне.
- Сначала зафиксируйте маршрут. Для direct generation и edits оставайтесь на Images API. В Responses идите только если картинка — часть larger workflow.
- Затем зафиксируйте модель.
Начинайте с GPT Image 1.5, а
gpt-image-1-miniтестируйте как отдельный cost-first branch. - Определите один safe default output profile. Выберите базовый size, quality и output format, прежде чем добавлять десятки user-facing options.
- Логируйте контекст ошибки. Active org, model ID, endpoint и failure type дают больше пользы, чем хаотичное повторение одного и того же request.
- Разделяйте tutorial success и budget success. То, что запрос заработал один раз, не означает, что весь workflow уже оптимален по cost.
Отсюда и лучший набор follow-up readings:
- OpenAI Image Generation API pricing
- OpenAI Image API verification troubleshooting
- English fallback: How to get an OpenAI API key
- English fallback: OpenAI API key requirements
В сухом остатке, хороший current OpenAI Image API tutorial нужен не затем, чтобы еще раз перепечатать code blocks, а затем, чтобы сначала помочь выбрать правильный API surface, потом убедиться в current model IDs и access gates, и только после этого разбираться с quality, latency и cost controls. Как только этот порядок соблюден, тема становится гораздо проще, чем кажется по поисковой выдаче.
FAQ
С чего начинать: Images API или Responses API?
Если вам нужна прямая генерация или edit existing image, начинайте с Images API. Responses API лучше тогда, когда image generation — только один tool в larger assistant flow.
Какой model ID безопаснее всего брать для fresh tutorial?
Для большинства случаев — gpt-image-1.5. Если первый вопрос у вас про cost, тестируйте gpt-image-1-mini уже после того, как basic path стабильно заработал.
Почему code sample выглядит правильным, но все равно не работает?
Чаще всего причина не в syntax, а в usage tier, organization verification, active org или устаревшем API key.
Когда стоит использовать chatgpt-image-latest, а не gpt-image-1.5?
Только если вам сознательно нужен current ChatGPT image snapshot. Для стабильного production tutorial gpt-image-1.5 обычно остается более чистым выбором.