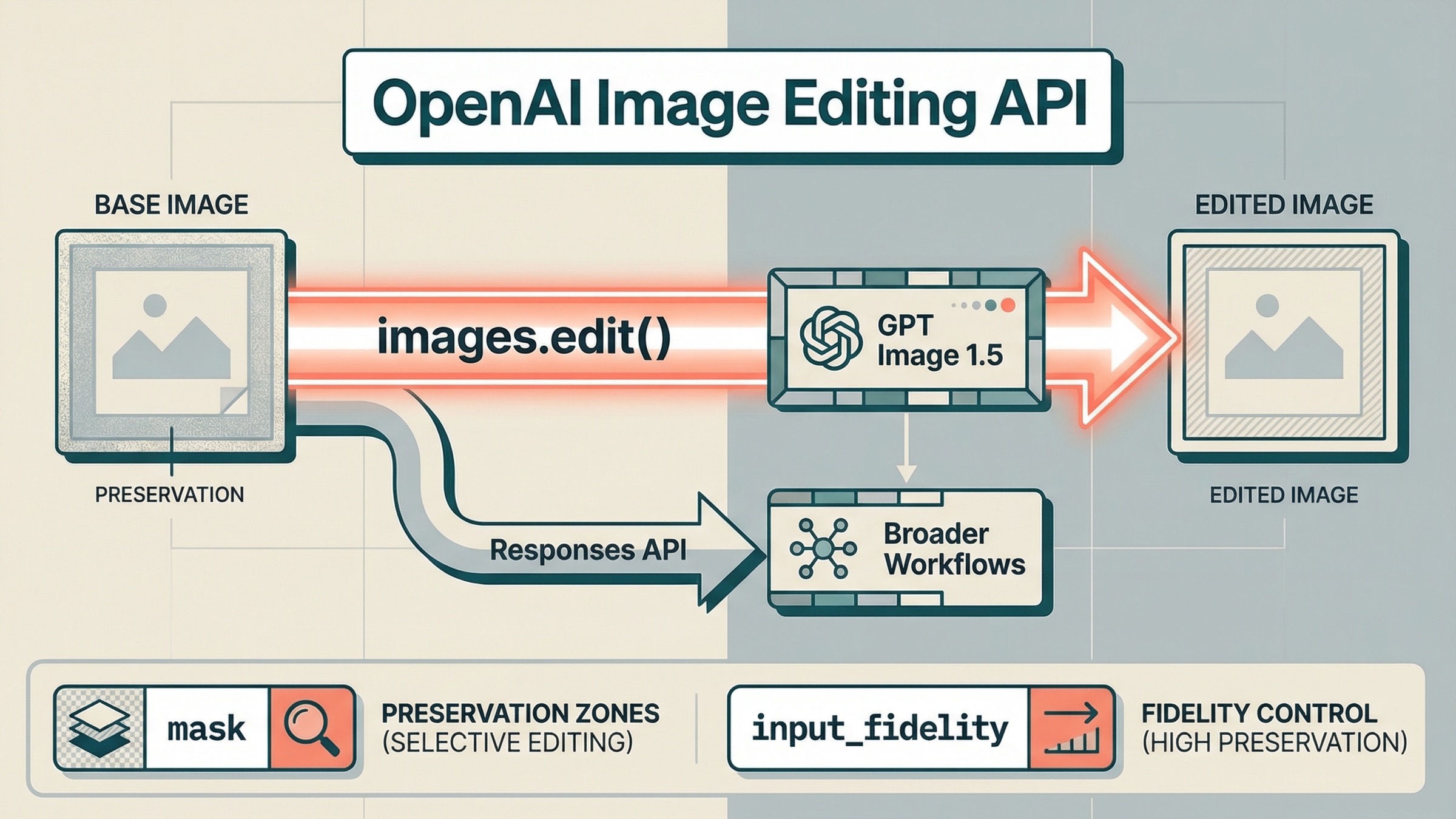
Если сегодня вам нужно редактировать изображения через OpenAI API, то по состоянию на 23 марта 2026 года safest default остаётся простым: берите прямой Images API и gpt-image-1.5. Для большинства задач, где важна именно правка изображения, это значит client.images.edit() в SDK или POST /v1/images/edits по HTTP. Responses API нужен позже, когда image edit становится только одним шагом внутри диалога, ассистента или agent workflow.
Это важно потому, что OpenAI по-прежнему разносит ответ по нескольким страницам. Основной image generation guide уже показывает gpt-image-1.5 в direct edit examples. Текущая страница GPT Image 1.5 называет его latest image generation model. Но более общий Images and vision guide всё ещё сохраняет старый контекст, где latest model обозначен как gpt-image-1. Если прочитать только одну страницу, легко унести в код рабочий, но уже стратегически устаревший маршрут.
Вторая ошибка обычно дороже первой. Очень многие слышат “image editing API” и ожидают поведение в духе Photoshop: стёр область, получил локальный патч. Но в текущих документах OpenAI формулировка заметно осторожнее. Они просят описывать всё финальное изображение, а не только стёртый кусок. И community threads хорошо показывают, почему это важно: masked edits GPT Image до сих пор нередко ведут себя как более широкий semantic rewrite, а не как строго ограниченная замена пикселей. Эта статья нужна именно затем, чтобы вы не строили workflow на неверной модели ожиданий.
Кратко
- Для прямого OpenAI image editing API сначала берите
images.edit()иgpt-image-1.5. - Используйте mask, когда нужно подсказать модели, где сфокусироваться, но не считайте mask гарантией пиксельно-локального патча.
- Подключайте
input_fidelity="high", когда важнее сохранить лицо, логотип, композицию или брендовый visual, чем сэкономить время и стоимость. - Переходите к Responses только тогда, когда edit уже живёт внутри более широкого multimodal или agent workflow.
С чего начинать: текущий прямой путь для image edits
Для обычного edit workflow самый полезный mental model выглядит так:
- передайте одно или несколько входных изображений
- опишите финальный результат
- добавьте preservation controls только там, где они действительно нужны
- декодируйте base64 и сохраните файл
Текущий прямой JavaScript-паттерн выглядит так:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1.5", image: [fs.createReadStream("room.jpg")], prompt: "Replace the empty wall art with a framed abstract poster. Preserve the room layout, lighting, shadows, and all furniture. Do not change the camera angle.", input_fidelity: "high", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; const imageBuffer = Buffer.from(imageBase64, "base64"); fs.writeFileSync("room-edited.jpg", imageBuffer);
Python-версия настолько же прямая:
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.edit( model="gpt-image-1.5", image=[open("room.jpg", "rb")], prompt=( "Replace the empty wall art with a framed abstract poster. " "Preserve the room layout, lighting, shadows, and all furniture. " "Do not change the camera angle." ), input_fidelity="high", size="1024x1024", quality="medium", output_format="jpeg", output_compression=80, ) image_base64 = result.data[0].b64_json image_bytes = base64.b64decode(image_base64) with open("room-edited.jpg", "wb") as f: f.write(image_bytes)
Если нужен raw HTTP, важная деталь одна: image edits используют multipart form data, а не JSON.
bashcurl https://api.openai.com/v1/images/edits \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "image[]=@room.jpg" \ -F 'prompt=Replace the empty wall art with a framed abstract poster. Preserve the room layout, lighting, shadows, and all furniture. Do not change the camera angle.' \ -F "input_fidelity=high" \ -F "size=1024x1024" \ -F "quality=medium"
Именно поэтому это лучший starting point. Вы выбираете текущую edit-capable model line, передаёте input image, описываете финальный результат и получаете base64 output. Вы не просите более общий reasoning layer решить, редактировать или генерировать. Вы не управляете conversation state. Вы просто делаете edit.
Если вам нужен более широкий контекст по всей surface, следующая логичная страница на русском — OpenAI Image API tutorial. Эта статья специально остаётся узкой и решает edit-specific вопрос.
Images API против Responses для edit-задач
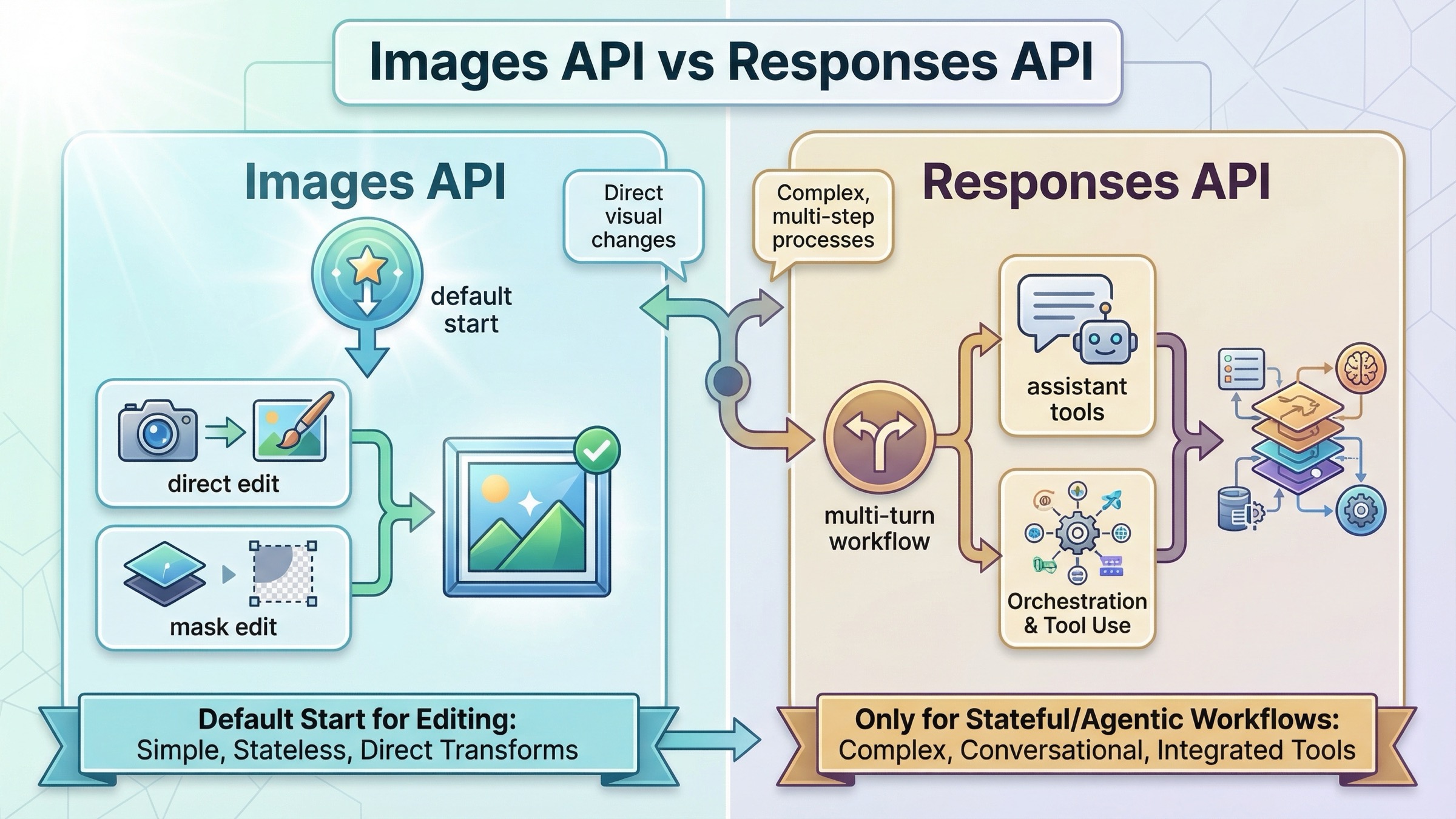
Именно этот выбор большинство page-one материалов до сих пор оставляет размытым.
| Ситуация | Лучший default | Почему |
|---|---|---|
| Нужно отредактировать одну или несколько картинок и сохранить результат | Images API | Это самый короткий direct edit path, который легче всего отлаживать |
| Нужно вставить или заменить элемент, сохранив лицо, логотип или product shot | Images API | Прямой edit flow плюс input_fidelity=high лучше всего работает как preservation-first setup |
| Нужен mask, чтобы подсказать, где редактировать | Images API | Mask inputs, multipart upload и direct output handling уже нативно поддерживаются здесь |
| Нужно продолжать edit внутри multi-turn conversation, опираясь на предыдущий output | Responses API | Conversation state и tool calls там естественнее |
| Вы строите assistant, который рассуждает, вызывает tools и иногда редактирует image | Responses API | Тогда image editing становится лишь одним инструментом внутри большего workflow |
Ключевое правило простое: не начинайте с Responses только потому, что он выглядит новее. Текущий tool guide прямо показывает, что Responses нужен для более широких hosted image workflows. Более того, GPT Image models нельзя ставить в top-level model поля Responses API. Там нужен text-capable model, например gpt-5, а сам edit или generation выполняется через image_generation.
Это делает Responses мощным, но также повышает шанс выбрать неверный уровень абстракции. Если вашему продукту сегодня нужен один прямой endpoint для image edits, сначала стабилизируйте direct Images API. Если позже появится multi-turn editing, memory или другие tools, тогда Responses действительно станет лучшим route.
Сначала выберите тип edit-задачи, и только потом пишите prompt
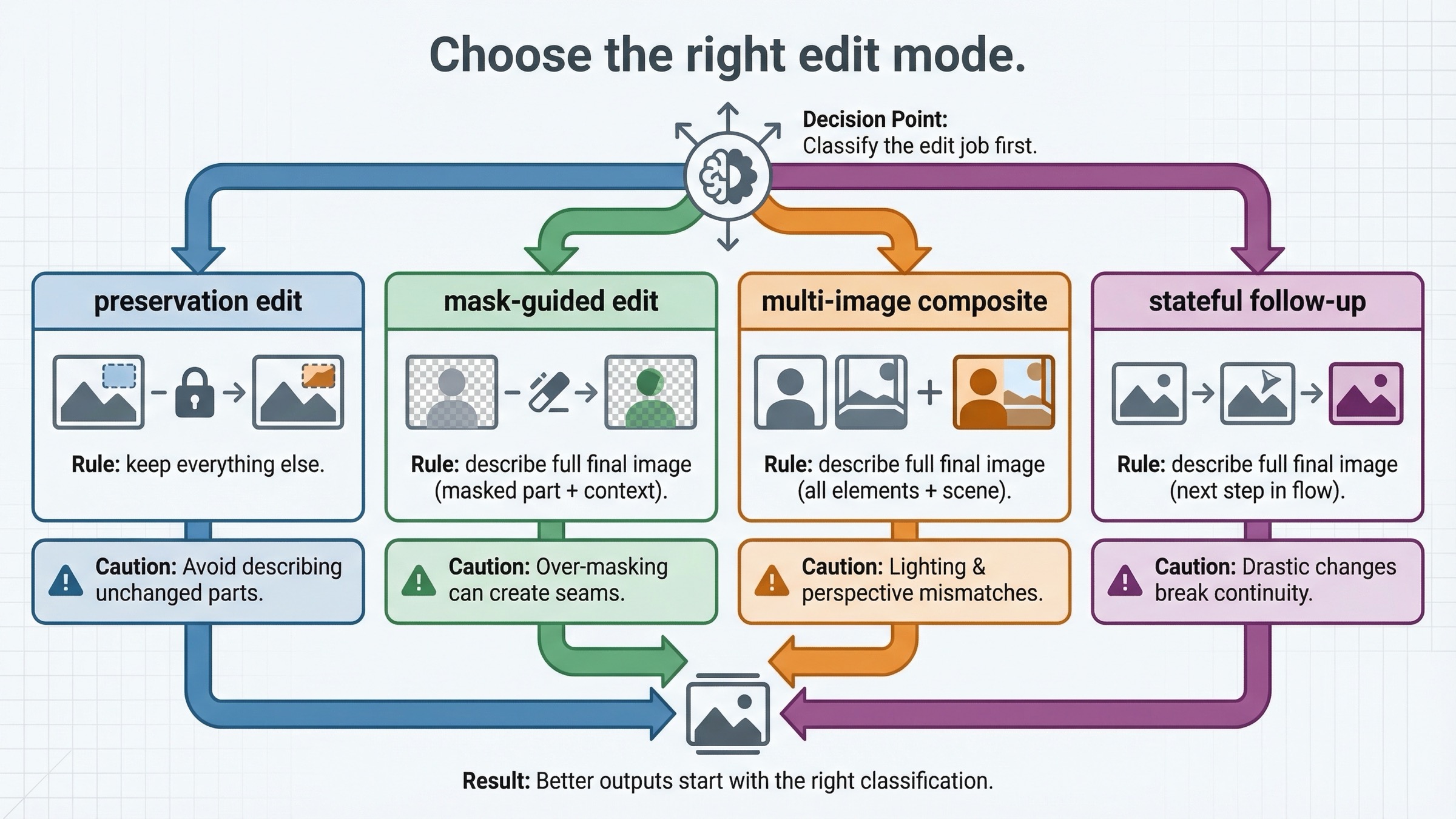
Большинство слабых tutorials говорят об “image editing” как об одной операции. Это ошибка. Prompt становится гораздо понятнее, когда вы сначала решаете, какой именно edit вы просите модель выполнить.
Первый тип — preservation-heavy single-image edit. Это ваш сценарий, когда сцена уже почти правильная, а изменить нужно лишь одну деталь: заменить одежду, добавить вывеску, обновить постер, убрать отвлекающий объект, слегка поменять стиль предмета или скорректировать настроение, не ломая композицию. В таких задачах preservation важнее raw creativity, поэтому input_fidelity="high" часто оправдан.
Второй тип — mask-guided edit. Здесь вы говорите модели не только что изменить, но и где смотреть. Это помогает, но не превращает GPT Image в deterministic local patch tool. Mask — это средство наведения, а не гарантия того, что в строгом смысле будут затронуты только эти пиксели.
Третий тип — multi-image reference / compositing edit. Актуальные guides и cookbook OpenAI показывают, что можно передавать более одного изображения и просить модель перенести, смешать или унаследовать признаки из одного input в другой. Именно так строятся сценарии вроде:
- перенести логотип из второго изображения на футболку в первом
- добавить собаку из изображения два в сцену из изображения один
- сохранить тот же продукт, но переставить его в новую среду
Четвёртый тип — iterative follow-up editing. Если первый результат уже близок, но вы хотите продолжать править его в рамках беседы, Responses начинает выигрывать. Здесь вам важнее не единичный direct call, а удобная работа с предыдущим состоянием.
Именно поэтому это различие нужно делать как можно раньше. Для preservation-heavy edit нужен явный язык “остальное не менять”. Для mask edit нужно полное описание финальной сцены плюс указание зоны внимания. Для compositing важно точно написать, что взять из какого input и что обязано остаться неизменным в базовом изображении.
Как реально ведут себя mask и input_fidelity

Эта часть обычно и есть настоящий вопрос читателя, даже если он не формулирует его прямо.
В текущем image generation guide OpenAI сказано, что image и mask должны быть одного формата и размера, общий payload должен быть меньше 50 MB, а mask обязан содержать alpha channel. Но самая важная строка там другая: нужно описывать всё финальное изображение, а не только стёртую область.
Эта фраза полностью меняет mental model API. Она означает, что модель не просто “заполняет дырку”, а интерпретирует исходное изображение, mask и prompt вместе, чтобы выдать связный финальный результат.
Именно поэтому community complaints нельзя списывать как шум. В одном треде OpenAI Developer Community от 27 апреля 2025 года разработчики писали, что masked edits ощущаются как регенерация всего изображения. В ответах позже цитировали OpenAI Support: для gpt-image-1 точный inpainting тогда был известным ограничением. Да, GPT Image 1.5 явно сильнее GPT Image 1 в задачах с сохранением, но практический вывод остаётся тем же: тестируйте masked workflows как semantic edit system, а не как deterministic layer surgery.
input_fidelity="high" полезен тогда, когда edit должен заметно аккуратнее сохранять исходные признаки. OpenAI использует его в direct guide на примере с добавлением логотипа, а текущий Azure OpenAI how-to объясняет это ещё более прикладно: высокий input fidelity заставляет модель сильнее удерживать особенности входного изображения, особенно facial ones, при тонких правках. Поэтому он особенно уместен в сценариях:
- смена фона при сохранении самого продукта
- изменение одежды человека при сохранении лица
- размещение брендового логотипа на объекте или одежде
- небольшая правка сцены без потери camera angle и композиции
Tradeoff здесь понятен. Более сильное preservation почти всегда означает больше осторожности и стоимости. Если задаче не нужна строгая сохранность, глобально включать high fidelity на всё подряд особого смысла нет.
Намного полезнее такая привычка:
- сначала один простой direct edit
input_fidelity=highтолько там, где preservation действительно важен- mask только там, где важна spatial guidance
- prompt описывает финальный image, сохраняемые элементы и одну-две реальные правки
Если первый результат уже близок, не спешите писать гигантский prompt. Одна более узкая follow-up правка обычно работает лучше.
Preservation-heavy edits лучше делать небольшими шагами
Текущий GPT Image 1.5 prompting guide полезен именно тем, что ведёт себя скорее как production advice, чем как dump параметров. В кейсах с переводом, compositing, style preservation и scene changes повторяется одна и та же схема: явные ограничения плюс небольшие итерации работают стабильнее, чем попытка запихнуть всё в первый же запрос.
Ровно так и стоит строить prompts в реальном продукте.
Плохой edit prompt:
textMake this look better, more modern, cleaner, more premium, maybe add some flowers, maybe change the colors, and make it suitable for a landing page.
Более сильный preservation-first prompt:
textReplace only the poster on the wall with a framed abstract print. Preserve the room layout, furniture, lighting, floor shadows, and camera angle. Do not move or redesign any other object. Photorealistic interior photography.
Более сильный compositing prompt:
textPlace the logo from image 2 onto the front of the tote bag in image 1. Match the bag's fabric texture and lighting. Keep the model, pose, background, and camera framing unchanged.
Более сильный follow-up prompt:
textKeep the edited image exactly the same, but make the poster slightly larger and reduce glare on the frame. Do not change anything else.
Эта последняя строка особенно важна. Чем ценнее исходный визуал, тем больше вам нужно мыслить как operator, который защищает состояние, а не как prompt writer, который каждый раз просит “сделать покрасивее”.
Поэтому важен и релизный пост OpenAI от 16 декабря 2025 года. В нём GPT Image 1.5 позиционируется как более сильный successor для edits, где нужно сохранять брендовые логотипы, key visuals и согласованность лиц. Это не обещание идеального preservation в каждом кейсе. Это скорее сигнал, что теперь quality результата всё сильнее зависит от вашей prompt discipline и sequencing, а не только от того, умеет ли модель базовую edit-задачу.
Если после этой статьи вам нужен более широкий model-routing answer, следующий логичный шаг — русская страница про OpenAI image generation API models.
Troubleshooting: что page one всё ещё часто не проговаривает
Первая ошибка — начинать не с той API surface. Если вам нужно просто редактировать image, не стройте с нуля Responses workflow и не ставьте gpt-image-1.5 в top-level model у Responses. Это неверный контракт. Сначала direct Images API, потом Responses, если продукт действительно дорос до broader workflow.
Вторая ошибка — доверять не той официальной странице как источнику freshness. По состоянию на 23 марта 2026 года страница GPT Image 1.5 говорит, что это latest image generation model, а более широкий Images and vision guide всё ещё сохраняет старую фразу про gpt-image-1. Если ваш внутренний runbook или статья опирается не на ту страницу, команда будет выглядеть устаревшей даже при рабочем коде.
Третья ошибка — посылать JSON в raw edit endpoint. Прямые image edits — это multipart form data. Если вы отлаживаетесь через curl или собственный HTTP client, этот detail обязателен.
Четвёртая ошибка — считать mask жёстким обещанием, а не guidance tool. Если вашему workflow нужны микро-правки с нулевыми побочными изменениями, проверяйте это допущение на ранних образцах, а не после интеграции.
Пятая ошибка — писать prompt только про изменяемый объект. OpenAI прямо советует описывать финальное изображение целиком. Если вы напишете только “add a beach ball”, модель получит слишком много свободы для остальной сцены.
Шестая ошибка — смешивать access problem и syntax problem. У GPT Image 1.5 всё ещё есть текущие tier limits, а модельная страница пишет Free not supported. Если запрос падает ещё до возврата usable image, сначала проверьте access, а не переписывайте prompt. Если это похоже на ваш реальный блокер, следующий полезный материал — OpenAI image generation API verification guide.
Седьмая ошибка — пытаться впихнуть слишком много изменений в один запрос. Для preservation-heavy edit большие compound prompts лишь усложняют диагностику: непонятно, модель ошиблась в композиции, сохранении, wording или самом mask. Один edit, потом одна follow-up correction — всё ещё более чистая продакшн-привычка.
FAQ
Что сейчас брать для edit-задач: gpt-image-1 или gpt-image-1.5?
Для нового direct edit workflow берите gpt-image-1.5. На 23 марта 2026 года текущая страница GPT Image 1.5 называет его latest image generation model, тогда как старые официальные guides всё ещё упоминают gpt-image-1. gpt-image-1 имеет смысл оставлять для поддержки или сравнения старого workflow.
Почему мой mask edit меняет больше, чем сама masked area?
Потому что GPT Image edits — это guided semantic rewrites, а не гарантированный pixel-only local patch. Текущий guide OpenAI просит описывать всё желаемое финальное изображение, а community threads показывают, что пользователи до сих пор получают более широкие перерисовки там, где ожидали жёсткий inpainting.
Нужно ли ставить input_fidelity=high для каждого edit?
Нет. Он нужен тогда, когда для вас критично сохранить лицо, логотип, геометрию продукта, ракурс или другой важный visual identity. Если задача более generative и вы не боитесь более свободного restyle, постоянно включать его не нужно.
Когда переходить с Images API на Responses?
Переходите к Responses тогда, когда edit становится частью multi-turn conversation, assistant workflow или broader tool-using product. Пока самой feature является именно правка изображения, direct Images API обычно остаётся лучшим выбором.
Финальная рекомендация
Самое чистое правило сейчас такое: если вы хотите редактировать изображения через OpenAI API, начинайте с images.edit() плюс gpt-image-1.5, а не с более широкой Responses-схемы. Используйте mask, чтобы направить внимание модели, но формулируйте prompt так, будто вы задаёте всю финальную картинку. Добавляйте input_fidelity=high тогда, когда preservation — это сама задача, а не автоматический флаг на каждый запрос.
Именно этого page one до сих пор часто не договаривает. Winning answer здесь не в том, что “OpenAI умеет редактировать изображения”. Winning answer — в прямом edit route, в моменте переключения на alternate route и в честном объяснении того, чего mask не гарантирует.
Если после этой страницы вам нужна более широкая API-картина, переходите к OpenAI Image API tutorial. Если дальше нужны именно working generation examples, логичный следующий шаг — OpenAI image generation API example.