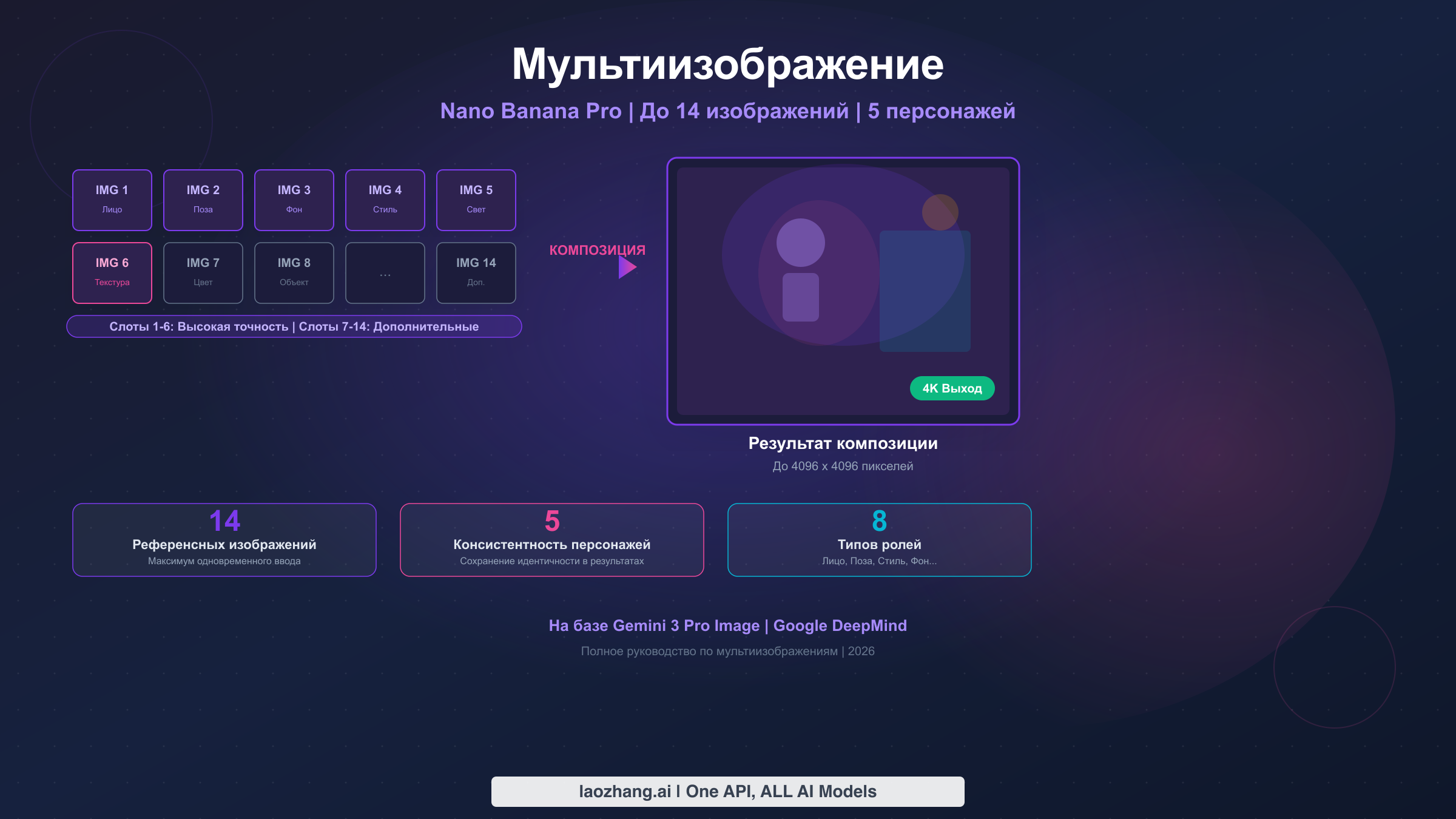
Nano Banana Pro поддерживает мультиизображение с использованием до 14 референсных изображений в одном промпте, сохраняя при этом идентичность до 5 различных персонажей. Система использует ролевое назначение, при котором вы указываете функцию каждого изображения — референс лица, ориентир позы, фоновая сцена, стилевой шаблон или референс освещения. Первые 6 слотов для изображений получают высокоточную обработку с максимальным влиянием на результат. Стандартные композиции в разрешении 2K стоят около $0,134 за сгенерированное изображение через Gemini API (ai.google.dev/pricing, проверено в феврале 2026).
Краткое содержание
- Максимум на входе: 14 референсных изображений в одном запросе
- Консистентность идентичности: до 5 различных персонажей сохраняются в результатах
- Высокоточные слоты: первые 6 изображений получают приоритетную обработку; слоты 7-14 являются дополнительными
- 8 типов ролей: Лицо, Поза, Фон, Стиль, Текстура, Цветовая палитра, Освещение, Объект/Реквизит
- Стоимость: ~$0,134/изображение при 2K, ~$0,24/изображение при 4K — входные изображения добавляют лишь ~$0,001 каждое
- Лучшая ценность: разрешение 2K (та же цена, что и 1K, но в 4 раза больше пикселей)
- Выходное разрешение: до 4096 x 4096 пикселей
- Ключевой вывод: стоимость выходных токенов доминирует — добавление дополнительных референсов практически не влияет на общую цену
Что такое мультиизображение в Nano Banana Pro?
До появления мультиизображений генерация изображений ИИ представляла собой фактически односторонний диалог: вы писали текст, модель генерировала изображение, и если оно не соответствовало вашему замыслу, вы переписывали промпт и генерировали заново. Этот итеративный текстовый цикл приемлемо работает для простых абстрактных запросов, но полностью ломается, когда вам нужны конкретные визуальные элементы — лицо определённого человека, точный архитектурный фон или определённый художественный стиль. Мультиизображение решает эту проблему, позволяя показать модели именно то, что вы имеете в виду, вместо попыток описать это словами.
Мультиизображение в Nano Banana Pro (официально Gemini 3 Pro Image, идентификатор модели gemini-3-pro-image-preview) представляет собой фундаментальный сдвиг от традиционной генерации по одному промпту. Вместо того чтобы описывать всё текстом и надеяться, что ИИ правильно интерпретирует ваш замысел, вы предоставляете реальные визуальные референсы, направляющие конкретные аспекты результата. Представьте, что вы даёте опытному цифровому художнику мудборд, а не просто устные инструкции — результаты становятся значительно более точными и предсказуемыми.
Система работает, принимая до 14 изображений вместе с текстовым промптом, где каждому изображению может быть назначена определённая роль, указывающая модели, как использовать эту визуальную информацию. Референс лица сообщает модели, чью внешность сохранить. Фоновое изображение задаёт сцену. Стилевой референс определяет художественную обработку. Такой ролевой подход означает, что вы сохраняете детальный контроль над каждым визуальным измерением результата — чего текстовые промпты просто не могут достичь с такой же надёжностью.
Особую мощь подхода Nano Banana Pro придаёт сочетание трёх возможностей, которые ни одна другая публично доступная модель в настоящее время не предлагает одновременно. Во-первых, ёмкость в 14 входных изображений значительно превосходит конкурентов — стилевой референс Midjourney принимает лишь несколько изображений, а DALL-E 3 вообще не поддерживает мультивходы. Во-вторых, система консистентности идентичности может отслеживать и сохранять уникальные черты лица до 5 разных людей в генерируемых результатах, что критически важно для сторителлинга, маркетинговых кампаний и процессов дизайна персонажей. В-третьих, разрешение результата масштабируется до 4096 x 4096 пикселей, что означает, что ваши композиции сразу пригодны для печатного качества без дополнительного апскейлинга.
Лежащая в основе технология использует мультимодальную архитектуру Google DeepMind, обрабатывающую текст и изображения через один и тот же трансформерный бэкбон. Такая единая обработка означает, что модель действительно понимает взаимосвязь между вашими текстовыми инструкциями и визуальными референсами, а не обрабатывает их как отдельные входы, которые объединяются в конце. На практике это означает, что вы можете писать промпты вроде «Поместите человека с изображения 1 в позу с изображения 2, с фоном изображения 3, отрендеренного в стиле изображения 4» и получать результаты, которые учитывают все четыре референса одновременно.
Для разработчиков и создателей контента, оценивающих, стоит ли мультиизображение затрат на освоение, ответ зависит от вашего сценария использования. Если вы генерируете простые автономные изображения по текстовым промптам, рабочий процесс с одним изображением остаётся быстрее и дешевле. Но если вам нужны консистентные персонажи в нескольких результатах, точная репликация стиля или сложное построение сцен с конкретными визуальными элементами, мультиизображение экономит огромное количество времени по сравнению с итеративным циклом правки промптов, который требует генерация только по тексту.
Система назначения ролей — ваш ключ к точным композициям

Система назначения ролей — это механизм, который превращает мультиизображение из расплывчатого запроса «скомбинируй эти картинки» в точную творческую операцию. Когда вы назначаете роль каждому входному изображению, вы сообщаете модели, какую именно визуальную информацию извлечь и как её применить. Без назначения ролей модель принимает собственные решения о том, что взять из каждого изображения — иногда блестяще, но часто непредсказуемо. С явным назначением ролей вы контролируете результат.
Nano Banana Pro распознаёт 8 различных типов ролей, каждый из которых нацелен на определённое визуальное измерение результата. Понимание того, что каждая роль извлекает из исходного изображения, необходимо для построения эффективных композиций. Для более глубокого изучения структурирования промптов ознакомьтесь с нашим подробным руководством по промпт-инжинирингу.
Референс лица извлекает геометрию лица, текстуру кожи и отличительные черты из исходного изображения. Это основа сохранения идентичности — когда вам нужно, чтобы в результате появилась внешность конкретного человека, назначьте его самую чёткую фронтальную фотографию или фото в ракурсе три четверти на эту роль. Модель приоритизирует костную структуру, расстояние между глазами, форму носа и другие идентифицирующие черты, позволяя выражению лица и освещению определяться другими референсами или текстом промпта.
Референс позы фиксирует положение тела, расположение конечностей и общий жест из исходного изображения. Это особенно ценно, когда вам нужна определённая стойка, действие или язык тела, который трудно описать текстом. Модель извлекает скелетную позу, игнорируя одежду, идентичность и фон из референсного изображения позы.
Референс фона предоставляет контекст окружения — ландшафт, интерьер, архитектурную обстановку или абстрактный задник. Модель извлекает пространственную компоновку, признаки глубины, направление освещения и элементы среды, адаптируя их для размещения вашего основного объекта.
Стилевой референс — одна из самых мощных ролей, поскольку она переносит художественную обработку, технику рендеринга, цветокоррекцию и общую эстетику из референсного изображения. Будь то акварельные текстуры, фотореалистичный рендеринг, аниме-эстетика или винтажный кинематографический стиль, предоставление стилевого референса значительно надёжнее, чем описание стиля текстом. Для продвинутых техник переноса стиля изучите наше руководство по технике клонирования стиля.
Референс текстуры нацелен на поверхностные свойства материалов — переплетение ткани, металлическая отделка, качество кожи или зернистость бумаги. Эта роль лучше всего работает, когда вам нужен определённый вид материала, который сложно выразить словами, например «точная текстура кожи с этого фото люксовой сумки».
Референс цветовой палитры извлекает доминирующие и акцентные цвета из исходного изображения и применяет эту палитру к результату. Это незаменимо для брендированного контента, где каждое сгенерированное изображение должно соответствовать определённой цветовой схеме. Вместо того чтобы описывать «точный оттенок синего из наших брендбук-гайдлайнов» текстом, вы просто предоставляете изображение с этими цветами и позволяете модели автоматически их извлечь.
Референс освещения фиксирует направление, качество, интенсивность и цветовую температуру света из исходного изображения. Студийные фотографы оценят эту роль — вы можете эффективно воссоздать определённую световую схему, предоставив референсное фото, освещённое так, как вы хотите, чтобы выглядел ваш результат. Модель замечательно справляется с извлечением информации об освещении из референсных изображений, включая тонкие качества вроде жёсткости или мягкости теней, соотношения между основным и заполняющим светом и цветового оттенка общего освещения.
Референс объекта/реквизита вводит конкретные предметы из исходного изображения в композицию. В отличие от фоновых референсов, задающих всю сцену, референсы объектов выделяют отдельные предметы — конкретную модель автомобиля, определённый предмет мебели, брендированный продукт — и интегрируют их в генерируемое изображение. Эта роль особенно ценна для электронной коммерции и маркетинговых процессов, где брендовые продукты должны точно отображаться в генерируемых лайфстайл-изображениях, исключая необходимость дорогостоящих физических фотосъёмок для каждого маркетингового сценария.
Стратегия высокоточных слотов
Не все 14 слотов для изображений равноценны. Слоты с 1 по 6 получают высокоточную обработку, что означает, что модель выделяет значительно больше внимания и вычислительных ресурсов на точное воспроизведение информации из этих изображений. Слоты с 7 по 14 функционируют как дополнительные референсы — они влияют на результат, но с заметно меньшей точностью.
Эта система приоритетов имеет серьёзные последствия для того, как вам следует распределять свои изображения. Ваши самые критичные референсы — обычно идентичность лица, основной стиль и ключевой фон — всегда должны занимать первые 6 слотов. Второстепенные детали, такие как дополнительные цветовые палитры, дополнительные текстурные подсказки или мелкий реквизит, могут спокойно располагаться в слотах с более низким приоритетом, где приблизительного влияния достаточно.
Синтаксис промптов для назначения ролей
Базовый синтаксис для назначения ролей в промпте следует такому шаблону:
[Image 1: face reference] [Image 2: pose reference] [Image 3: background]
Generate a portrait of the person from image 1 in the pose shown in image 2,
set in the environment from image 3, with soft natural lighting.
Модель естественно распознаёт ключевые слова ролей в тексте промпта. Вам не нужно специальное форматирование — просто чётко укажите, какое изображение предоставляет какой визуальный элемент, и модель соотнесёт их соответствующим образом. При этом явное указание значительно помогает. Расплывчатые промпты вроде «используй эти изображения, чтобы сделать что-нибудь крутое» оставляют слишком много места для интерпретации, тогда как структурированные промпты, явно указывающие роль каждого изображения, дают значительно более предсказуемые результаты.
Распространённый вопрос о синтаксисе промптов — влияет ли порядок упоминания изображений в тексте. Ответ: номер слота (определяемый порядком загрузки) управляет приоритетом обработки, а текст промпта управляет семантическим назначением. Поэтому, даже если вы упоминаете изображение 5 раньше изображения 1 в текстовом описании, изображение 1 по-прежнему получает высокоточную обработку. Текст промпта сообщает модели, что означает каждое изображение; номер слота определяет, сколько внимания это значение получает при генерации.
Начало работы — композиции из 2-5 изображений

Начало с небольшого количества референсных изображений — самый быстрый способ понять, как работает мультиизображение, прежде чем переходить к сложным композициям. Разница между композицией из 2 и 14 изображений заключается не только в количестве — это процесс изучения того, какие визуальные измерения вы можете контролировать независимо и как они взаимодействуют. Этот раздел охватывает Уровень 1 (2 изображения) и Уровень 2 (5 изображений) фреймворка прогрессивной сложности, предоставляя готовые шаблоны, которые вы можете начать использовать немедленно.
Уровень 1: Композиция из двух изображений — самая простая и распространённая точка входа. Типичный сценарий использования — объединение лица человека с другой сценой, стилем или позой. С двумя входами каждое изображение получает максимальное внимание модели, и результаты высоко предсказуемы. Именно с этого стоит начать, если вы никогда раньше не использовали мультиизображение. Красота Уровня 1 в том, что он обучает фундаментальной модели взаимодействия — одно изображение предоставляет идентичность или предмет, а другое предоставляет контекст или обработку — без сложности управления множественными конкурирующими референсами.
Самый важный урок из композиций Уровня 1 — научиться оценивать качество результата относительно качества ваших входных данных. Если ваш референс лица слегка размыт, лицо на выходе унаследует эту неопределённость. Если ваш фоновый референс имеет непоследовательное освещение, интегрированная сцена будет выглядеть слегка неестественно. Эта прямая связь между качеством входных данных и качеством результата становится сложнее для отслеживания на более высоких уровнях, поэтому формирование интуиции на Уровне 1 окупается впоследствии.
Вот шаблон Уровня 1 для композиции «лицо + фон»:
[Image 1: face/identity reference] [Image 2: background scene]
Create a professional portrait photograph of the person from image 1
standing in the environment shown in image 2. The person should appear
naturally integrated into the scene with matching lighting and
perspective. Maintain the exact facial features and identity from
image 1. High-quality, photorealistic output.
Причина, по которой этот шаблон работает хорошо, заключается в том, что он даёт модели чёткие, непротиворечивые инструкции. Идентичность берётся из изображения 1 (назначенного в высокоточный слот), окружение — из изображения 2, а текст промпта задаёт требования к интеграции. Нет неоднозначности в том, что модель должна приоритизировать.
Второй распространённый паттерн Уровня 1 — перенос идентичности + стиля. Здесь вы берёте фото реального человека и рендерите его в совершенно другом художественном стиле — превращая портретное фото в аниме-персонажа, картину эпохи Возрождения или пиксельный спрайт. Шаблон прост:
[Image 1: identity/face reference] [Image 2: style reference]
Transform the person from image 1 into the artistic style shown in
image 2. Preserve the facial features, expression, and identity from
image 1 while applying the complete visual treatment, color palette,
and rendering technique from image 2. Full body portrait with
detailed background in the same style.
Уровень 2: Композиция из пяти изображений вводит реальный творческий контроль, позволяя разделить несколько визуальных измерений. Типичная конфигурация из 5 изображений может распределять изображения как: лицо (слот 1), поза (слот 2), фон (слот 3), стиль (слот 4) и освещение (слот 5) — все помещаются в зону высокой точности. Значимость того, что все пять изображений находятся в высокоточных слотах, трудно переоценить — на этом уровне каждый референс получает максимальное внимание при обработке, что означает, что ваша композиция имеет наивысшую возможную точность воспроизведения всех пяти визуальных входов одновременно.
Предметная фотография — один из сильнейших сценариев использования для композиций Уровня 2, поскольку коммерческие продуктовые съёмки по своей природе включают множество различных визуальных требований, которые выигрывают от отдельных референсов. Сам продукт нуждается в точном представлении, сцена должна соответствовать определённой среде или настроению, освещение должно следовать устоявшимся конвенциям бренда, а общий фотографический стиль должен быть последовательным с существующими маркетинговыми материалами. Попытка отразить всё это только текстом ненадёжна; предоставление визуальных референсов для каждого измерения даёт результаты, более близкие к тому, что выдаст профессиональная фотостудия.
Вот практический шаблон Уровня 2 для предметной фотографии:
[Image 1: product photo - front view]
[Image 2: background/environment reference]
[Image 3: lighting reference photo]
[Image 4: style/mood reference]
[Image 5: additional product angle - side view]
Generate a professional product photography shot of the item shown in
images 1 and 5. Place the product in the environment from image 2 with
the lighting setup from image 3. Apply the overall mood, color grading,
and photographic style from image 4. The product should appear as a
hero shot with sharp focus, natural shadows matching the environment,
and premium commercial quality. Output at 2K resolution.
Этот шаблон предметной фотографии демонстрирует критический принцип: использование нескольких изображений одного и того же объекта (изображения 1 и 5, показывающие разные ракурсы продукта) даёт модели более полное понимание трёхмерной формы объекта. Результат — более точное представление продукта по сравнению с предоставлением только одного референсного ракурса.
При работе с композициями из 5 изображений обращайте внимание на согласованность между вашими референсами. Если ваш световой референс показывает тёплое послеполуденное солнце, а фоновый референс имеет пасмурное серое небо, модели приходится разрешать этот конфликт — и результат может выглядеть неестественно. Чем более гармоничны ваши референсные изображения с точки зрения направления света, цветовой температуры и общего настроения, тем более цельным будет ваш результат.
Практический рабочий процесс для композиций Уровня 2 заключается в подготовке референсных изображений стандартизированным способом перед отправкой в API. Кадрируйте лицевые референсы плотно вокруг лица и плеч объекта. Убедитесь, что фоновые референсы не содержат отвлекающих элементов переднего плана, которые могут проникнуть в композицию. Для световых референсов выбирайте фотографии, где направление света однозначно — один основной свет с чёткими тенями работает лучше, чем плоское рассеянное освещение, которое не даёт модели чётких направленных данных.
Переход от Уровня 1 к Уровню 2 часто выявляет паттерн, который становится ещё более важным на более высоких уровнях: убывающая отдача на каждое дополнительное изображение в плане получаемого творческого контроля, но возрастающая отдача в плане предсказуемости результата. Два изображения дают контроль над двумя измерениями с некоторой неопределённостью. Пять изображений дают контроль над пятью измерениями с гораздо меньшей неопределённостью, потому что каждый явный визуальный референс сужает пространство возможных интерпретаций модели.
Продвинутые композиции — от 10 до 14 изображений
Масштабирование за пределы 6 изображений означает осознанную работу с системой дополнительных слотов. На этом уровне вы оркестрируете сложные сцены, где множество визуальных измерений нуждаются в независимом контроле, и стратегическое распределение изображений между высокоточными слотами (1-6) и дополнительными слотами (7-14) становится разницей между цельным шедевром и запутанным нагромождением.
Уровень 3: Композиция из десяти изображений — это момент, когда мультиизображение переходит от простого сопоставления референсов к настоящей творческой режиссуре. Конфигурация из 10 изображений может включать: основное лицо (слот 1), второе лицо (слот 2), групповой позовый референс (слот 3), фон (слот 4), основной стиль (слот 5), освещение (слот 6) — эти шесть занимают зону высокой точности. Затем в дополнительных слотах: референс одежды (слот 7), объект/реквизит (слот 8), цветовая палитра (слот 9) и детали текстуры (слот 10).
Вот шаблон Уровня 3 для страницы персонажа — одного из наиболее практических продвинутых сценариев использования:
[Image 1: character face - front view]
[Image 2: character face - 3/4 view]
[Image 3: full body pose reference]
[Image 4: outfit/clothing reference]
[Image 5: art style reference]
[Image 6: color palette reference]
[Image 7: hair style reference]
[Image 8: background/environment style]
[Image 9: accessory/prop reference]
[Image 10: texture/material reference for clothing]
Generate a detailed character design sheet showing the character from
images 1-2 in the pose from image 3. The character wears the outfit
style from image 4 with materials matching the texture in image 10,
accessorized with the item from image 9. Hair style follows image 7.
Render in the art style from image 5 using the color palette from
image 6. Background follows the aesthetic from image 8. Show the
character from three angles: front view, 3/4 view, and back view.
Include a close-up detail panel of the face and accessories.
Обратите внимание на стратегическое распределение слотов: идентичность персонажа (изображения 1-2) и критически важные визуальные элементы стиля (изображения 3-6) занимают высокоточные слоты, а второстепенные детали, такие как причёска, аксессуары и текстура, размещаются в дополнительных слотах, где приблизительное влияние приемлемо. Это распределение отражает общий принцип, применимый ко всем сложным композициям: приоритизируйте элементы, на которые глаз зрителя смотрит в первую очередь — лицо, общий стиль, основное действие — в высокоточных слотах, а элементы, создающие атмосферу или текстуру, размещайте в дополнительных слотах, где приблизительный рендеринг визуально достаточен.
Сценарий страницы персонажа также демонстрирует, почему Уровень 3 часто является оптимальным для профессиональных рабочих процессов. Десять изображений предоставляют достаточно визуальных референсов для контроля всех основных измерений результата без столкновения с убывающей отдачей и повышенной сложностью более высоких уровней. Многие опытные пользователи сообщают, что их лучшие результаты получаются из 8-10 тщательно подобранных референсов, а не из заполнения всех 14 слотов, потому что каждое дополнительное изображение вносит потенциальные конфликты, которые модель должна разрешать.
Уровень 4: Композиция из четырнадцати изображений представляет максимальную ёмкость и лучше всего подходит для производства брендовых кампаний, комплексного построения сцен или профессиональных процессов, где каждый визуальный элемент нуждается в конкретном референсе. На этом уровне у вас должен быть чёткий план распределения слотов до начала работы. Для максимального качества выходного разрешения ознакомьтесь с нашим руководством по генерации изображений 4K.
Шаблон Уровня 4 для брендовой кампании демонстрирует, как все 14 слотов могут служить различным целям. Распределение слотов следует такой приоритетной структуре: слоты 1-3 содержат три лицевых референса персонажей (все в зоне высокой точности для максимальной точности идентичности). Слот 4 содержит групповой позовый референс, слот 5 — основную среду, а слот 6 — стилевой гайд бренда, завершая высокоточное распределение шестью самыми критически важными визуальными элементами. Дополнительные слоты 7-14 далее обрабатывают световую схему, индивидуальные референсы одежды для каждого персонажа, цветовую палитру бренда, референс размещения продукта и детали текстуры окружения.
Соответствующий промпт будет явно сопоставлять каждое пронумерованное изображение с его творческой функцией, указывая пространственные отношения («Персонаж A слева в центре, Персонаж B справа»), ссылаясь на конкретные слоты для каждого визуального элемента и запрашивая «фотореалистичное, журнальное качество выхода в разрешении 4K». Ключевое — каждое изображение имеет одну чёткую задачу, а текст промпта оркестрирует, как эти задачи объединяются в целостную сцену.
Для разработчиков, создающих приложения, генерирующие мультиизображения в масштабе, доступ к Gemini API через такие платформы, как laozhang.ai, может упростить интеграцию и предоставить унифицированный API-доступ к нескольким поставщикам моделей. Это особенно ценно, когда ваш рабочий процесс включает переключение между различными моделями на разных стадиях продакшн-пайплайна.
Ключевой вывод на Уровне 4: вы фактически занимаетесь арт-дирекцией через изображения, а не через слова. Ваш текстовый промпт становится слоем оркестрации — определяющим отношения между референсами, а не описывающим визуальные элементы с нуля. Чем конкретнее ваш промпт указывает, какое изображение предоставляет какой элемент, тем более предсказуем результат.
При планировании композиции Уровня 4 создайте таблицу распределения слотов, прежде чем начнёте загружать изображения. Задокументируйте, какое изображение идёт в какой номер слота, какую роль оно выполняет и почему оно находится в высокоточной или дополнительной позиции. Этот шаг планирования занимает пять минут, но экономит значительное время итераций. Самая распространённая ошибка на этом уровне — хаотичное распределение слотов: случайная загрузка изображений в надежде, что модель разберётся сама. С 14 входами автоматическое распределение модели значительно менее надёжно, чем явная человеческая режиссура.
Ещё одно практическое соображение для продвинутых композиций — кумулятивное влияние качества изображений. На Уровнях 1-2 один слегка размытый референс может не иметь большого значения, потому что другие референсы компенсируют. На Уровне 4 каждый низкокачественный вход ухудшает общую согласованность результата. Профессиональные процессы, зависящие от композиций из 14 изображений, обычно поддерживают курированную библиотеку высококачественных, хорошо освещённых, последовательно отформатированных референсных изображений, которые можно комбинировать в различных композициях — рассматривая референсные изображения как многоразовые творческие активы, а не одноразовые загрузки.
Поддержание идентичности персонажа в мультиизображениях
Консистентность идентичности персонажа — пожалуй, самая востребованная функция мультиизображений, и одновременно самый технически сложный аспект для получения правильных результатов. Nano Banana Pro может поддерживать отдельные идентичности до 5 разных людей одновременно, но достижение надёжных результатов требует понимания того, как работает система сохранения идентичности, и предоставления оптимальных референсных изображений.
Система идентичности работает путём извлечения лицевого вложения (facial embedding) — математического представления уникальной геометрии лица человека — из ваших референсных изображений. Это вложение фиксирует структурные отношения между лицевыми ориентирами: расстояние между глазами, ширину переносицы, контур линии челюсти, выступание скул и десятки других параметров. При генерации результата модель ограничивает генерацию изображения таким образом, чтобы сохранить эти геометрические отношения, позволяя всему остальному (выражению, освещению, ракурсу, художественному стилю) варьироваться в соответствии с вашими другими референсами и текстом промпта.
Качество ваших лицевых референсных изображений напрямую определяет точность сохранения идентичности. Идеальный лицевой референс — это хорошо освещённый, высокоразрешённый фронтальный вид или лёгкий ракурс три четверти с нейтральным выражением лица и без перекрытий (солнцезащитные очки, сильные тени, руки, закрывающие части лица). Экстремальные ракурсы, тяжёлый макияж, сильные тени или низкое разрешение ухудшают качество лицевого вложения, что означает «дрифт» результата от предполагаемой идентичности. По результатам тестирования сотен композиций, единственное наиболее эффективное улучшение консистентности идентичности приходит не от промпт-инжиниринга или оптимизации слотов, а просто от предоставления более качественного лицевого референсного фото. Хорошо освещённый портрет 1080p с равномерным освещением превосходит 4K-фото с резкими тенями каждый раз.
Мультиракурсное референсирование — наиболее надёжная техника для высокоточного сохранения идентичности. Вместо предоставления одного лицевого фото выделите два высокоточных слота для одного и того же человека — один фронтальный вид и один ракурс три четверти. Это даёт модели стереоскопическое понимание геометрии лица, значительно улучшая консистентность, когда результат должен показать лицо под углом, отличным от референса. Стоимость использования дополнительного слота ничтожна (примерно $0,001 в дополнительных входных токенах), но улучшение точности идентичности существенно.
При работе с несколькими персонажами одновременно назначайте основной референс каждого человека на наименьший доступный номер слота. Если у вас три персонажа, их лицевые референсы должны быть в слотах 1, 2 и 3 — все в зоне высокой точности. Затем чётко маркируйте каждого человека в промпте последовательными идентификаторами: «Person A from image 1», «Person B from image 2» и так далее. Неоднозначность в вашем промпте о том, какое изображение представляет какого персонажа, — самая распространённая причина путаницы идентичностей в мультиперсональных результатах.
Для сцен, требующих одного и того же персонажа в нескольких сгенерированных изображениях (таких как комикс-стрип или раскадровка), поддерживайте абсолютную согласованность лицевых референсных изображений между запросами. Использование разных фото одного и того же человека в разных API-вызовах может вносить тонкий дрифт. Наиболее надёжный подход — выбрать лучшие референсные фотографии один раз и повторно использовать их идентично во всех композициях серии.
Сохранение идентичности имеет известные ограничения, которые важно понимать. Экстремальные возрастные различия между референсом и желаемым результатом (например, рендеринг детского лица на персонаже пожилого человека) дают ненадёжные результаты. Аналогично, перенос идентичности между полами непредсказуем. Система оптимизирована для сценариев «один и тот же человек, примерно тот же возраст» — что покрывает подавляющее большинство практических случаев использования, включая маркетинг, дизайн персонажей и личные творческие проекты.
Взаимодействие между идентичностью и стилевыми референсами заслуживает особого внимания, потому что именно здесь происходит большинство сбоев консистентности. Когда вы применяете сильно стилизованную художественную обработку (например, аниме, карикатуру или абстрактный экспрессионизм) к фотореалистичному лицевому референсу, модели приходится находить баланс между сохранением узнаваемой геометрии лица и соблюдением визуальных конвенций стиля. На практике, чем более экстремальна стилевая трансформация, тем сильнее «дрифтит» идентичность. Обходной путь — использовать более умеренные стилевые референсы, когда точность идентичности в приоритете, или принять некоторую гибкость идентичности, когда художественное выражение важнее. Не существует настройки, которая принудительно обеспечивает абсолютное сохранение идентичности независимо от стиля — это всегда компромисс, которым вы управляете через выбор референсов.
Для продакшн-процессов, требующих одновременно сильной консистентности идентичности и значительного стилевого разнообразия, наиболее надёжный подход — техника двух проходов. Сначала сгенерируйте композицию с зафиксированной идентичностью и минимальным стилевым влиянием для установления правильного лица. Затем используйте этот результат как новый вход для второго прохода, где вы применяете желаемый стиль более агрессивно. Этот двухпроходный подход даёт вам контрольную точку между установлением идентичности и применением стиля, снижая риск потери идентичности в сильно стилизованных результатах.
Ценообразование и оптимизация стоимости для мультиизображений

Понимание структуры стоимости мультиизображений необходимо для любого продакшн-процесса, и модель ценообразования содержит приятный сюрприз: стоимость входных изображений практически ничтожна по сравнению со стоимостью генерации результата. Это значит, что вы можете использовать все 14 слотов референсных изображений, не увеличивая существенно расходы на одну композицию. Все данные о ценах в этом разделе получены с ai.google.dev/pricing, проверено в феврале 2026.
Ценообразование Gemini API для Nano Banana Pro (модель gemini-3-pro-image-preview) использует токенную систему. Текстовый ввод стоит $2,00 за миллион токенов, а каждое входное изображение токенизируется примерно в 560 токенов (около $0,0011 за входное изображение). Вывод изображения стоит $120,00 за миллион токенов: результаты 1K и 2K потребляют 1 120 токенов ($0,134 за изображение), а результаты 4K потребляют 2 000 токенов ($0,24 за изображение). Для полной детализации ценообразования с дополнительным контекстом смотрите наш подробный анализ цен API Nano Banana Pro.
Что раскрывают эти цифры — фундаментальная асимметрия в структуре стоимости, которая работает в вашу пользу при мультиизображениях. Выходное изображение — которое остаётся одинаковым независимо от количества входных изображений — доминирует в общей стоимости на уровне 90-98% расходов. Входные изображения в совокупности составляют лишь 2-10% от общей стоимости. Это означает, что экономически рациональная стратегия — использовать столько референсных изображений, сколько требует ваш творческий процесс, поскольку предельная стоимость каждого дополнительного входного изображения ($0,001) фактически ничтожна.
Практический вывод прост: композиция из 14 изображений в разрешении 2K стоит примерно $0,149 в сумме — это $0,015 за все 14 входных изображений плюс текстовый промпт и $0,134 за выходное изображение. Сравните с простой композицией из 2 изображений в том же разрешении: примерно $0,136. Разница составляет всего $0,013. Это означает, что вопрос «сколько референсных изображений использовать?» должен определяться исключительно творческой необходимостью, а не экономией.
| Уровень композиции | Входные изображения | Стоимость входа | Стоимость выхода (2K) | Итого | Стоимость выхода (4K) | Итого (4K) |
|---|---|---|---|---|---|---|
| Уровень 1 | 2 изобр. | ~$0,002 | $0,134 | ~$0,136 | $0,240 | ~$0,242 |
| Уровень 2 | 5 изобр. | ~$0,006 | $0,134 | ~$0,140 | $0,240 | ~$0,246 |
| Уровень 3 | 10 изобр. | ~$0,011 | $0,134 | ~$0,145 | $0,240 | ~$0,251 |
| Уровень 4 | 14 изобр. | ~$0,015 | $0,134 | ~$0,149 | $0,240 | ~$0,255 |
Единственная крупнейшая оптимизация стоимости — выбор разрешения 2K вместо 1K. Оба разрешения потребляют одинаковое количество выходных токенов (1 120 токенов), то есть стоят абсолютно одинаково — $0,134 за изображение. Но разрешение 2K производит в 4 раза больше пикселей (2048x2048 против 1024x1024), обеспечивая значительно лучшее качество при нулевых дополнительных затратах. Нет причин генерировать в разрешении 1K, если вам специально не нужны файлы меньшего размера для ограниченного приложения. Это идентичное ценообразование между 1K и 2K — один из самых контринтуитивных аспектов модели ценообразования Gemini API, и многие пользователи тратят деньги впустую, по умолчанию выбирая более низкие разрешения, не осознавая, что могли бы получить значительно лучшее качество за ту же цену.
Когда разрешение 4K необходимо (по $0,24 за изображение), рассмотрите, можно ли сгенерировать в 2K и увеличить масштаб для результатов, где дополнительное нативное разрешение не критично. 79-процентное увеличение цены с 2K до 4K оправдано для ключевых изображений, печатных материалов и детальных крупных планов, но не для каждого изображения в пакетном рабочем процессе.
Для пакетных процессов, генерирующих 100+ композиций, экономика масштабируется линейно: 100 композиций в 2K стоят примерно $14,90, а тот же пакет в 4K — примерно $25,50. Для разработчиков, управляющих высоконагруженными процессами, понимание лимитов скорости и управления квотами необходимо для предотвращения троттлинга. Такие платформы, как laozhang.ai, предоставляют унифицированный API-доступ, который может упростить управление лимитами скорости у нескольких поставщиков моделей.
Часто упускаемая из виду стратегия оптимизации стоимости — повторное использование референсных изображений в разных композициях. Если вы генерируете серию изображений с одним и тем же персонажем, фоном или стилем, вы можете подготовить референсные изображения один раз и повторно использовать их в десятках или сотнях API-вызовов. Стоимость входных токенов за одно референсное изображение составляет лишь около $0,001, поэтому финансовая экономия от повторного использования минимальна — но повышение эффективности рабочего процесса существенно. Стандартизировав библиотеку референсов, вы устраняете время на поиск и подготовку новых референсов для каждой композиции и получаете более консистентные результаты, потому что модель всегда работает от одной и той же базовой линии.
Ещё один экономичный подход для высоконагруженных процессов — генерировать начальные композиции в разрешении 2K для просмотра и утверждения, а затем перегенерировать только одобренные концепции в 4K для финальной поставки. Поскольку увеличение цены с 2K до 4K составляет 79% ($0,134 до $0,240 за изображение), этот двухэтапный рабочий процесс может сэкономить 40-50% на общих затратах на генерацию изображений, если ваш показатель утверждения начальных композиций составляет около 60-70%. Ключевое — убедиться, что композиции, хорошо выглядящие в 2K, также хорошо будут выглядеть в 4K, что в целом так и есть, поскольку модель использует одну и ту же логику композиции на обоих разрешениях.
Устранение неполадок в мультиизображениях
Даже при хорошо структурированных промптах и качественных референсах мультиизображения могут давать неожиданные результаты. Разрыв между ожиданием и результатом особенно фрустрирует при сложных композициях, потому что площадь поиска ошибок велика — любое из ваших 14 входных изображений, текст промпта, распределение слотов или взаимодействие между референсами может быть источником проблемы. Понимание типичных режимов сбоев и их конкретных решений экономит время и API-кредиты. Эти паттерны устранения неполадок получены из реальных продакшн-процессов и проблем, о которых сообщает сообщество. Для полного руководства по всем типам ошибок смотрите наше руководство по устранению ошибок.
Общий принцип устранения неполадок в мультиизображениях — систематически изолировать переменные, а не менять несколько вещей одновременно. Если ваша композиция из 10 изображений даёт неожиданный результат, изменение пяти параметров одновременно и повторная генерация ничего не скажут вам о реальной причине проблемы. Вместо этого примените научный подход: меняйте одну переменную за раз, перегенерируйте и сравните результат с предыдущим выходом. Это требует больше API-вызовов, но формирует подлинное понимание того, как ваши конкретные референсы взаимодействуют.
Режим сбоя 1: Дрифт идентичности или слияние лиц. Это наиболее часто сообщаемая проблема, когда лицо на выходе не соответствует референсу или — в мультиперсональных композициях — лица двух персонажей смешиваются в гибрид. Корневая причина почти всегда — неоднозначное назначение слотов или конфликтующие референсы. Решение трёхэтапное: убедитесь, что лицевые референсы занимают слоты с наименьшими номерами (в зоне высокой точности), используйте явную маркировку «Person A from image 1» в промпте и проверьте, что ваши лицевые референсные изображения высокоразрешены с чётким фронтальным видом или ракурсом три четверти. Если слияние лиц продолжается, сократите количество идентичностей персонажей в одной композиции — генерация сцены из 3 человек с последующим внешним композитингом может дать лучшие результаты, чем попытка предела в 5 персонажей.
Режим сбоя 2: Стилевое перекрытие, разрушающее идентичность. Когда сильный стилевой референс (слот 5 или 6) конфликтует с лицевым референсом (слот 1), художественный стиль может подавить идентичность лица. Это особенно часто происходит с сильно стилизованными референсами — абстрактное искусство, тяжёлая карикатура или экстремальная деформация. Основная причина в том, что сильные стилевые референсы влияют не только на технику рендеринга — они также могут навязывать пропорции и черты лица, типичные для данного стиля (аниме-глаза, карикатурное преувеличение), что напрямую конфликтует с вложением идентичности. Решение — закрепить в промпте явный язык сохранения идентичности: «Maintain photorealistic facial accuracy from image 1 while applying only the color palette and brush texture from the style reference». Вы также можете переместить стилевой референс в дополнительный слот (7+), чтобы снизить его влияние.
Режим сбоя 3: Несогласованная композиция сцены. Когда несколько фоновых, световых и средовых референсов противоречат друг другу, результат может содержать невозможное освещение, разрывы перспективы или пространственную путаницу. Типичный пример: ваш фон показывает сцену на открытом воздухе с верхним солнцем, но ваш световой референс показывает студийный контурный свет. Модель пытается соблюсти оба, создавая неестественный результат. Решение — гармонизация референсов: перед отправкой проверьте, что ваши средовые референсы (фон, освещение, текстура) физически совместимы. Как альтернатива, используйте меньше средовых референсов и позвольте текстовому промпту указать, что модель должна разрешить.
Режим сбоя 4: Дополнительные слоты игнорируются. Изображения в слотах 7-14 иногда оказывают минимальное или нулевое воздействие на результат. Это запроектированное поведение — это дополнительные слоты с пониженным влиянием, но степень влияния варьируется в зависимости от того, насколько явно вы ссылаетесь на них в промпте. Если дополнительный референс действительно не вносит вклада, несмотря на явное упоминание, решение — продвинуть его: переместите наиболее важное дополнительное изображение в высокоточный слот (1-6), понизив менее критичный референс. Если все 6 высокоточных слотов необходимы, попробуйте усилить влияние дополнительного изображения через явный язык промпта: «Apply the specific textile pattern from image 9 to the character's jacket — this is a critical detail». Чем конкретнее и настойчивее ваша текстовая ссылка на дополнительное изображение, тем больший вес модель ему придаёт при генерации.
Режим сбоя 5: Отказ в генерации или срабатывание фильтра безопасности. Сложные мультиизображения иногда срабатывают на фильтры безопасности контента, даже когда отдельные изображения безобидны. Это обычно происходит, когда комбинация изображений и текста промпта активирует контекстуальные проверки безопасности. Решение — упростить язык промпта (удалить медицинскую, насильственную или потенциально провокационную терминологию, даже если она контекстуально уместна), убедиться, что все референсные изображения явно безвредны, и если проблема сохраняется, попробовать удалять изображения по одному для выявления того, какой референс вызывает срабатывание фильтра. Пакетные запросы (вместо запросов в реальном времени) также могут помочь, так как они могут обрабатываться при несколько иных порогах безопасности.
Помимо этих пяти конкретных режимов сбоев, существует общая методология отладки, применимая к любому неожиданному результату мультиизображений. Начните с уменьшения сложности — если композиция из 10 изображений даёт плохой результат, попробуйте ту же концепцию с только 3-4 наиболее необходимыми референсами. Если упрощённая версия работает корректно, добавляйте изображения по одному для выявления конфликтующего референса. Этот подход бинарного поиска значительно эффективнее, чем вглядывание в промпт из 14 изображений в попытке угадать, что пошло не так. Ведите журнал, какие комбинации работают, а какие нет, потому что мультиизображения имеют эффекты взаимодействия, которые не всегда интуитивны — два референса, работающие идеально по отдельности, могут конфликтовать при объединении из-за несовместимых пространственных предположений, цветовых температур или стилевых конвенций.
FAQ
Следующие вопросы охватывают наиболее часто задаваемые темы о системе мультиизображений Nano Banana Pro на основе частых вопросов сообщества разработчиков и поисковых запросов, связанных с этой функцией. Каждый ответ предоставляет прямую, практически применимую информацию, чтобы помочь вам быстро разрешить конкретные вопросы.
Сколько изображений можно загрузить в Nano Banana Pro одновременно?
Nano Banana Pro принимает до 14 референсных изображений в одном запросе композиции. Первые 6 слотов получают высокоточную обработку с максимальным влиянием на результат, а слоты 7-14 функционируют как дополнительные референсы с пониженным, но всё же заметным воздействием. И интерфейс Gemini App, и Gemini API поддерживают этот лимит в 14 изображений, хотя API обеспечивает более точный контроль назначения ролей через структурированный промптинг.
Какие форматы и размеры изображений поддерживает Nano Banana Pro для мультиизображений?
Nano Banana Pro поддерживает форматы JPEG, PNG и WebP для входных референсных изображений. Отдельные изображения должны быть менее 20 МБ для надёжной обработки, хотя оптимальные результаты получаются при изображениях от 1 до 10 МБ. Строгого минимального требования к разрешению нет, но изображения более высокого разрешения дают лучшие результаты — особенно для лицевых референсов, где важны мелкие детали лица. Крайне маленькие изображения (менее 256x256) могут не предоставлять достаточно информации для извлечения значимых визуальных признаков.
Может ли Nano Banana Pro поддерживать консистентных персонажей в отдельных запросах генерации?
Да, но консистентность требует осознанного подхода. Система сохранения идентичности работает на уровне одного запроса, поэтому поддержание консистентности между несколькими отдельными API-вызовами требует использования точно тех же лицевых референсных изображений в тех же позициях слотов для каждого запроса. Не заменяйте разные фотографии одного и того же человека между запросами, так как даже тонкие различия в освещении, ракурсе или выражении лица могут вызвать дрифт. Для максимальной межзапросной консистентности выберите лучшие референсные фотографии один раз и повторно используйте их идентично на протяжении всего проекта.
Как работает ценообразование мультиизображений по сравнению с генерацией одного изображения?
Мультиизображения используют то же токенное ценообразование, что и генерация одного изображения. Каждое входное изображение стоит примерно $0,001 в токенах (560 токенов по $2,00/1M), а выходное изображение стоит $0,134 при разрешении 2K или $0,24 при 4K (ai.google.dev/pricing, проверено в феврале 2026). Композиция из 14 изображений в 2K стоит лишь на ~$0,013 больше, чем генерация одного изображения только по тексту, потому что стоимость выходных токенов ($0,134) доминирует в общих расходах. Добавление большего количества референсных изображений фактически бесплатно с точки зрения стоимости.
В чём разница между высокоточными слотами (1-6) и дополнительными слотами (7-14)?
Высокоточные слоты (с 1 по 6) получают приоритетную обработку в механизме внимания модели, что означает, что визуальная информация из этих изображений имеет значительно более сильное влияние на генерируемый результат. Дополнительные слоты (с 7 по 14) по-прежнему вносят вклад в результат, но с пониженной точностью — они лучше всего подходят для второстепенных стилевых подсказок, дополнительных референсов цветовой палитры или мелких деталей. Практическая стратегия — всегда размещать самые критичные референсы (основная идентичность, главный стиль, ключевой фон) в слотах 1-6, а оставшиеся слоты использовать для тонкой настройки деталей, где приблизительное влияние приемлемо.
Можно ли смешивать фотореалистичные и иллюстративные референсы в одной композиции?
Да, смешивание различных визуальных стилей в референсных изображениях поддерживается и может давать интересные творческие результаты. Однако стиль результата будет подвержен влиянию всех стиле-релевантных референсов, что потенциально создаёт непредсказуемое смешение. Для лучших результатов назначьте один чёткий стилевой референс в высокоточный слот и используйте текст промпта для указания, какая визуальная обработка должна доминировать. Явное указание «render in the photorealistic style of image 4, using only the color palette from the illustrated image 6» даёт модели чёткое руководство по приоритетам.