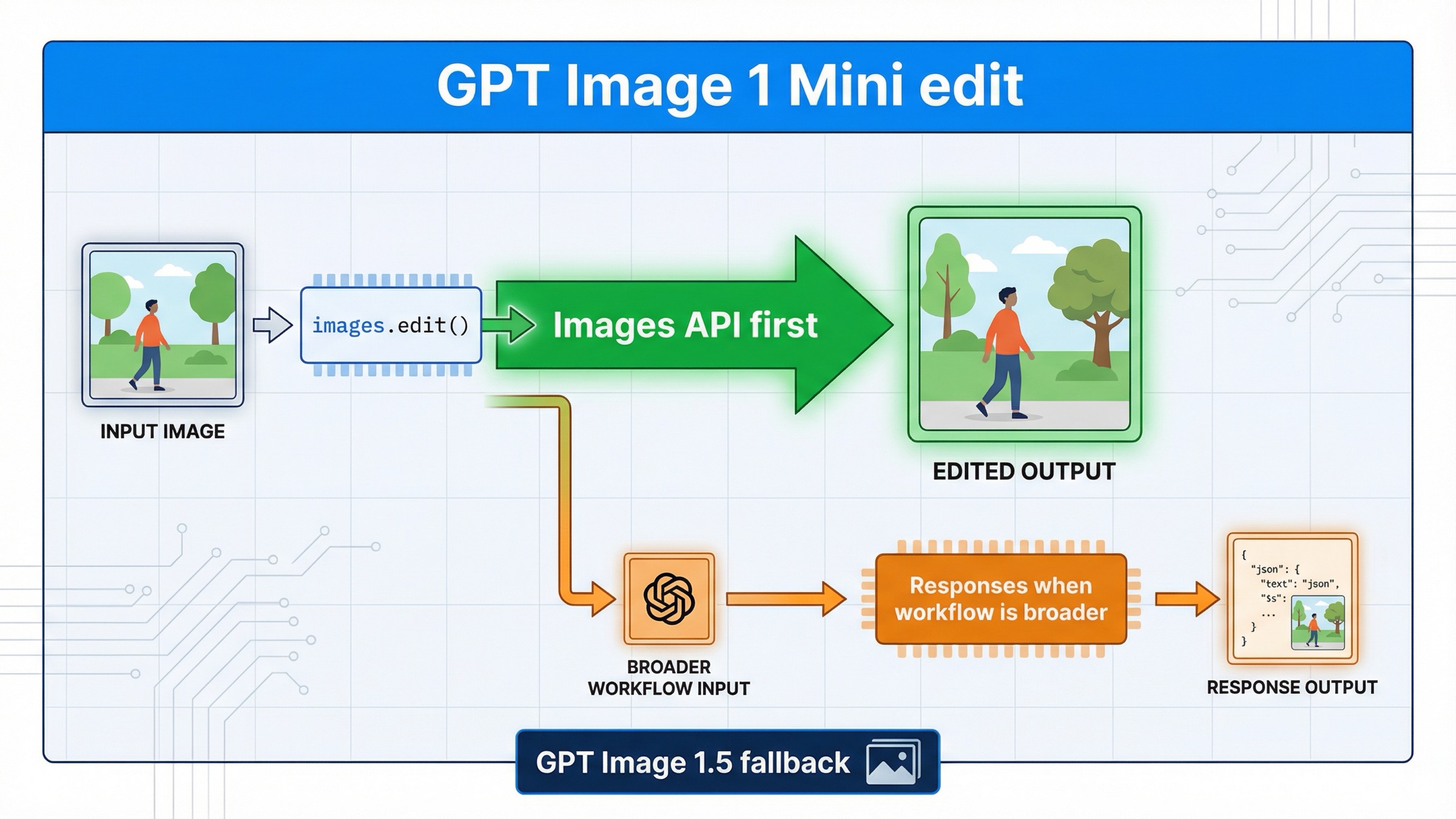
Если 29 марта 2026 года вам нужно редактировать изображение через gpt-image-1-mini, самый надежный стартовый маршрут — прямой Images API: client.images.edit() в SDK или POST /v1/images/edits в raw HTTP. К Responses стоит идти только в том случае, если редактирование изображения — это не вся задача, а один шаг внутри более крупного assistant, conversation или multi-tool workflow.
Этот вывод стоит проговорить отдельно, потому что текущая выдача и официальная документация раскладывают ответ по нескольким страницам. На текущей gpt-image-1-mini model page явно указан v1/images/edits. В актуальном image generation guide OpenAI прямо пишет, что Image API — лучший выбор, когда вам нужен один запрос на генерацию или редактирование по одному prompt. А в текущем image generation tool guide Responses-side action документирован прежде всего для gpt-image-1.5 и chatgpt-image-latest, а не как основной edit-контракт для mini. Если собрать эти страницы вместе, получается более полезное правило, чем дает средняя страница из выдачи: для mini-specific edit сначала идите в /v1/images/edits.
Это правило помогает еще и практически. Многие разработчики видят пример с Responses, решают, что более общий и новый abstraction автоматически лучше, и начинают строить интеграцию не с того слоя. Для gpt-image-1-mini это обычно ошибка. Direct edit проще сопоставить с документацией, проще дебажить и проще держать под контролем именно mini-specific ограничения.
Краткое содержание
- Если задача звучит как «отредактировать это изображение», начинайте с
client.images.edit()илиPOST /v1/images/edits. - Если редактирование — лишь часть более крупного assistant / multimodal workflow, тогда имеет смысл Responses.
- Если вам нужна более сильная многоизображенческая сохранность, более надежное качество или лучший quality-first default, сразу смотрите в сторону GPT Image 1.5.
- Прежде чем переписывать код, проверьте платный tier, верификацию организации, проект и API key.
| Ситуация | Лучший старт по умолчанию | Почему |
|---|---|---|
| Нужно отредактировать одно или несколько изображений и сохранить результат | images.edit() | Это самый прямой и четко документированный маршрут для mini |
| В одном edit-запросе нужен mask или reference image | images.edit() | Загрузка файлов, mask и декодирование ответа понятнее на direct route |
| Правка изображения — это только часть длинного workflow | Responses | Нужна не столько сама edit-операция, сколько состояние диалога и tool orchestration |
| Важно лучше удержать несколько input images, бренд-элементы или дорогие ассеты | GPT Image 1.5 + images.edit() | OpenAI прямо позиционирует 1.5 как более сильную quality-first ветку |
Для прямых правок mini сначала используйте /v1/images/edits
Для этого exact query самая полезная первая мысль довольно проста. Официальные docs не заставляют вас гадать: страница mini перечисляет v1/images/edits, а image guide говорит, что когда вам нужен один prompt для одной генерации или одной правки, Image API — правильный старт. Именно так выглядит большинство задач за запросом "gpt-image-1-mini edit".
Поэтому ваша первая успешная траектория должна быть намеренно простой:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1-mini", image: [fs.createReadStream("room.png")], prompt: "Replace the blank wall art with a framed abstract poster. Preserve the room layout, lighting, furniture, and camera angle. Do not change anything else.", input_fidelity: "high", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync("room-edited.jpg", Buffer.from(imageBase64, "base64"));
Если вы дебажите через raw HTTP, не забывайте: direct edit endpoint использует multipart form-data, а не JSON:
bashcurl https://api.openai.com/v1/images/edits \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1-mini" \ -F "image[]=@room.png" \ -F 'prompt=Replace the blank wall art with a framed abstract poster. Preserve the room layout, lighting, furniture, and camera angle. Do not change anything else.' \ -F "input_fidelity=high" \ -F "size=1024x1024" \ -F "quality=medium"
Почему именно этот direct route должен стоять первым?
Во-первых, он выравнивает модель и API surface. Вы вызываете endpoint, который mini сейчас явно поддерживает, а не просите более крупный orchestration layer самому решать, как именно должна произойти правка.
Во-вторых, он сужает зону отладки. Если запрос падает, чаще всего проблема быстро раскладывается в один из четырех классов: доступ, формат файлов, формулировка prompt или обработка результата. Вам не нужно одновременно гадать, не вмешались ли top-level Responses model, tool config или conversation state.
В-третьих, этот узкий маршрут помогает удержать страницу в точной теме. Более широкий обзор у нас уже есть в гайде по OpenAI image editing API. Эта статья не про весь family-level маршрут, а про более конкретный вопрос: что делать, когда вы уже знаете, что вам нужен именно mini edit.
Когда Responses действительно помогает и почему для mini эта граница важнее
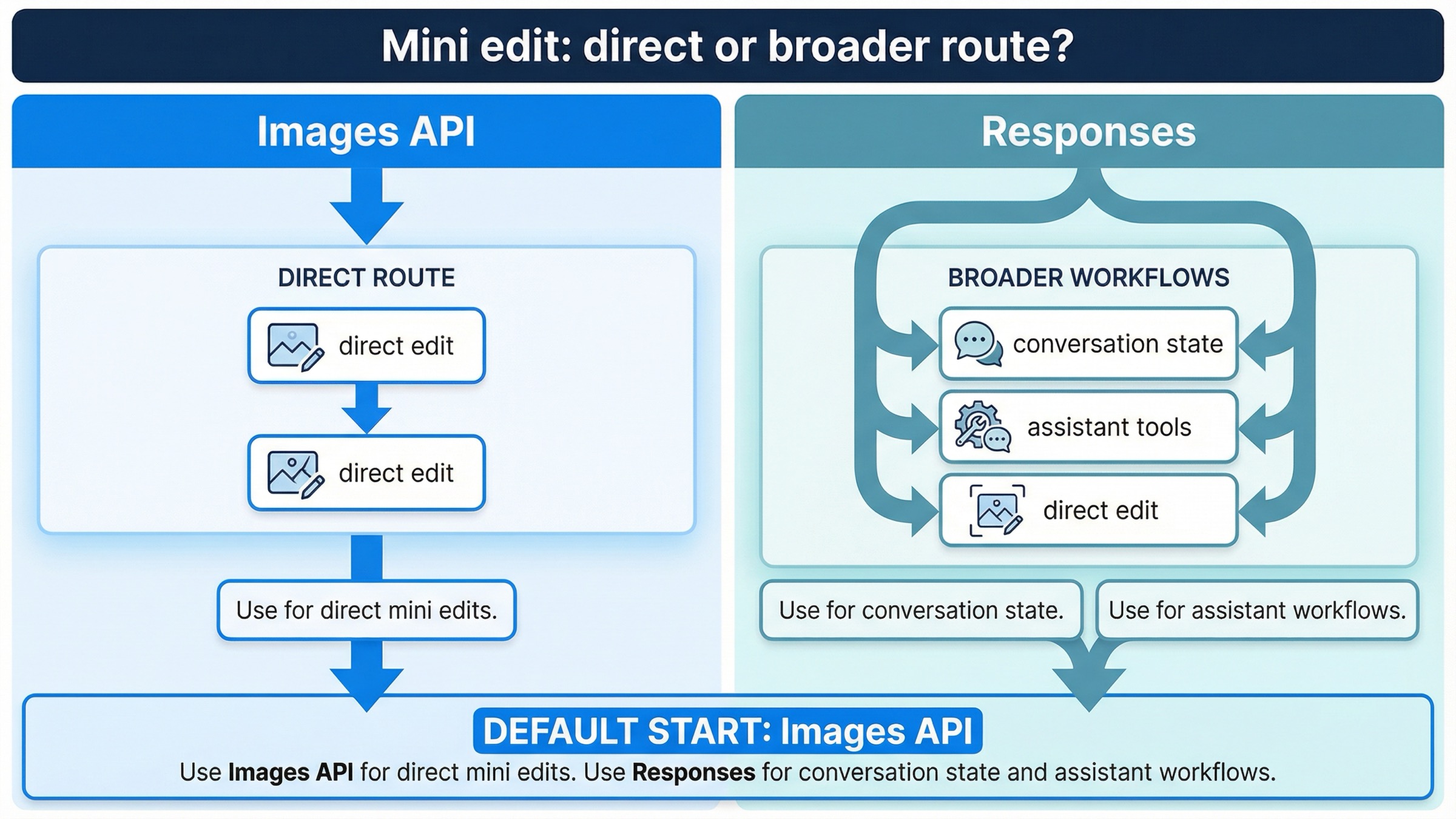
Responses — полезный инструмент. Но если вся ваша задача звучит как «отредактировать изображение через gpt-image-1-mini», он обычно не должен быть первой развилкой.
Текущий image generation tool guide показывает, почему. В Responses top-level model должен быть текстовой моделью вроде gpt-4.1 или gpt-5. GPT Image models не используются там как top-level model; image generation и editing идут через hosted tool. То есть, выбрав Responses, вы выбираете уже не просто «маршрут mini edit», а более широкий workflow abstraction.
Для mini это distinction особенно важно, потому что в документации Responses-side action явно описан для gpt-image-1.5 и chatgpt-image-latest, а не как основной путь именно для mini. Я не делаю вывод, что mini «никогда» не может работать через Responses. Вывод уже: если вам нужен предсказуемый, явно документированный и самый простой для дебага путь mini edit, direct Images API — более ясный контракт.
Когда Responses действительно лучше?
- когда вам нужна многошаговая правка с сохранением контекста через previous response IDs или image generation call IDs
- когда вы строите assistant, который смешивает reasoning, tools и image edits
- когда генерация или правка изображения должна жить внутри более длинного диалога
- когда вы хотите, чтобы одна большая request-цепочка сама решала, какой tool вызывать
Поэтому самое полезное ментальное правило остается таким:
- «Правка изображения и есть функция»: используйте
images.edit() - «Правка изображения — лишь один tool внутри более крупной функции»: рассматривайте Responses
Если ваш реальный вопрос шире, чем edit, и вам нужен весь маршрут по mini, следующая логичная статья — gpt-image-1-mini API guide. Эта же страница намеренно остается уже и точнее.
Маски, референсы и input_fidelity в mini
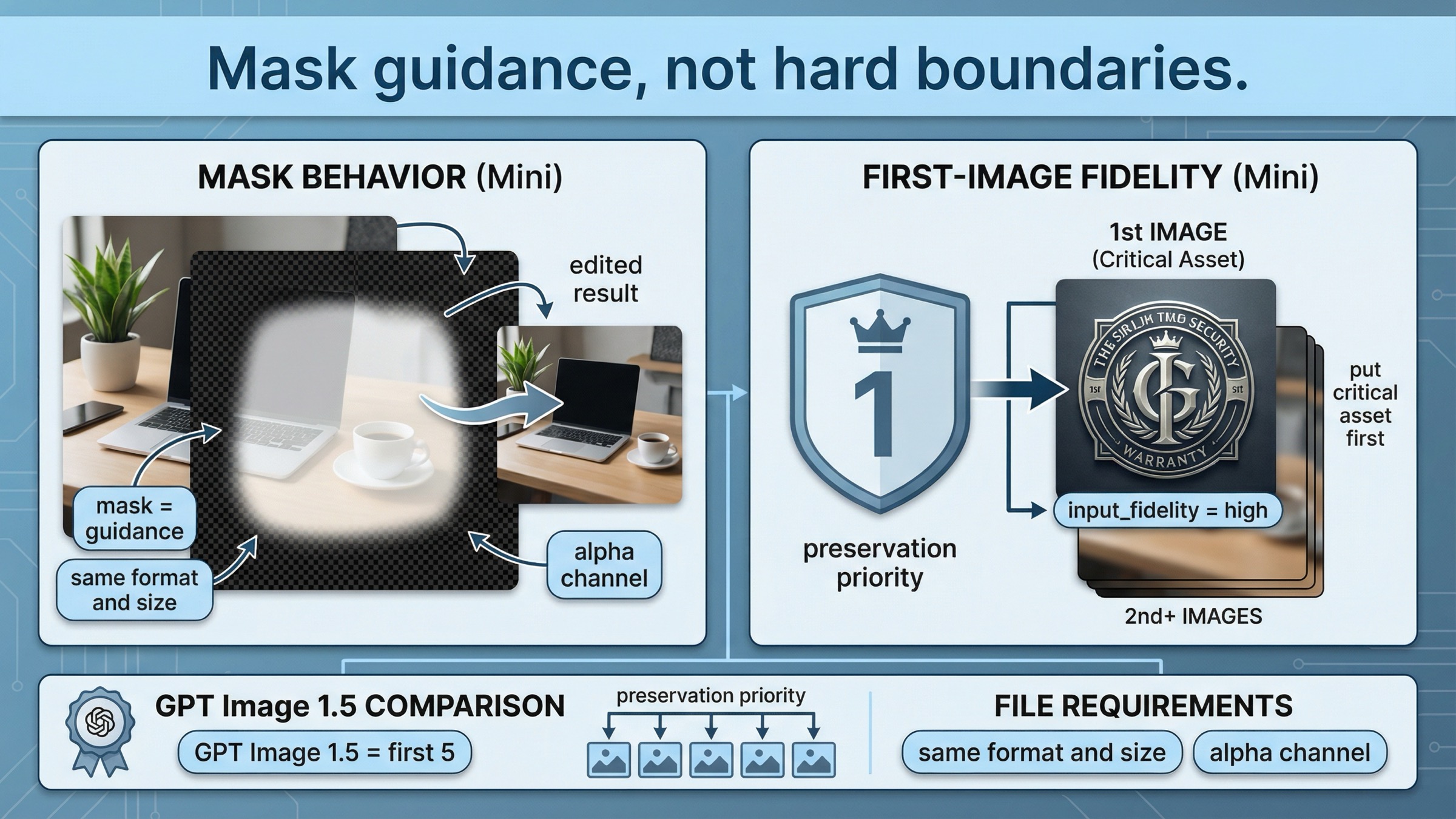
Это самый mini-specific раздел во всей статье, и именно он сильнее всего отличает страницу от generic OpenAI image edit content.
Текущий image generation guide в части про edit прямо говорит: изображение и mask должны иметь одинаковый формат и размер, суммарный размер должен оставаться ниже 50 MB, а mask обязан содержать alpha channel. Но ключевое поведение в другом: для GPT Image mask editing по-прежнему prompt-based. То есть mask направляет правку, но не гарантирует Photoshop-style пиксельную жесткость по границе.
Именно поэтому mask в mini лучше воспринимать как сильную подсказку, а не как обещание «модель точно не выйдет за эти пиксели».
Второе важное правило спрятано в текущей документации по input_fidelity. OpenAI сейчас прямо пишет: если использовать gpt-image-1 или gpt-image-1-mini с high input fidelity, первая входная картинка получает более сильное сохранение текстур и деталей. Если в запросе есть лицо, логотип, упаковка, товар или другой критичный визуальный anchor, его нужно ставить в первый слот. GPT Image 1.5 здесь сильнее, потому что лучше сохраняет уже первые пять input images.
Это не мелкая имплементационная сноска. Это правило, которое реально меняет то, как надо проектировать mini edit request.
Mini обычно хорошо подходит, когда:
- у вас одна главная картинка плюс маленький reference
- одно лицо или один logo явно заслуживает первого input slot
- нужно сделать одну основную сценовую правку без множества конфликтующих изменений
- это внутренний mockup, creative variant или среднерисковый продуктовый edit
А вот когда задача выглядит так, стоит быть осторожнее:
- несколько reference images одинаково важны
- несколько бренд-элементов должны сохраниться одновременно
- любая мелкая ошибка в типографике или layout дорого обходится
- edit используется в ценном коммерческом workflow, где ретраи уже стоят времени и денег
Прямой implementation pattern при этом остается простым:
jsconst result = await client.images.edit({ model: "gpt-image-1-mini", image: [ fs.createReadStream("base-scene.jpg"), fs.createReadStream("logo.png"), ], prompt: "Place the logo from image 2 onto the tote bag in image 1. Preserve the model, pose, bag shape, camera framing, and lighting.", input_fidelity: "high", });
Суть не в самом коде. Суть в порядке input images. Для mini первый input — это главный slot сохранности.
Сначала проверьте цену, лимиты и верификацию, а уже потом код
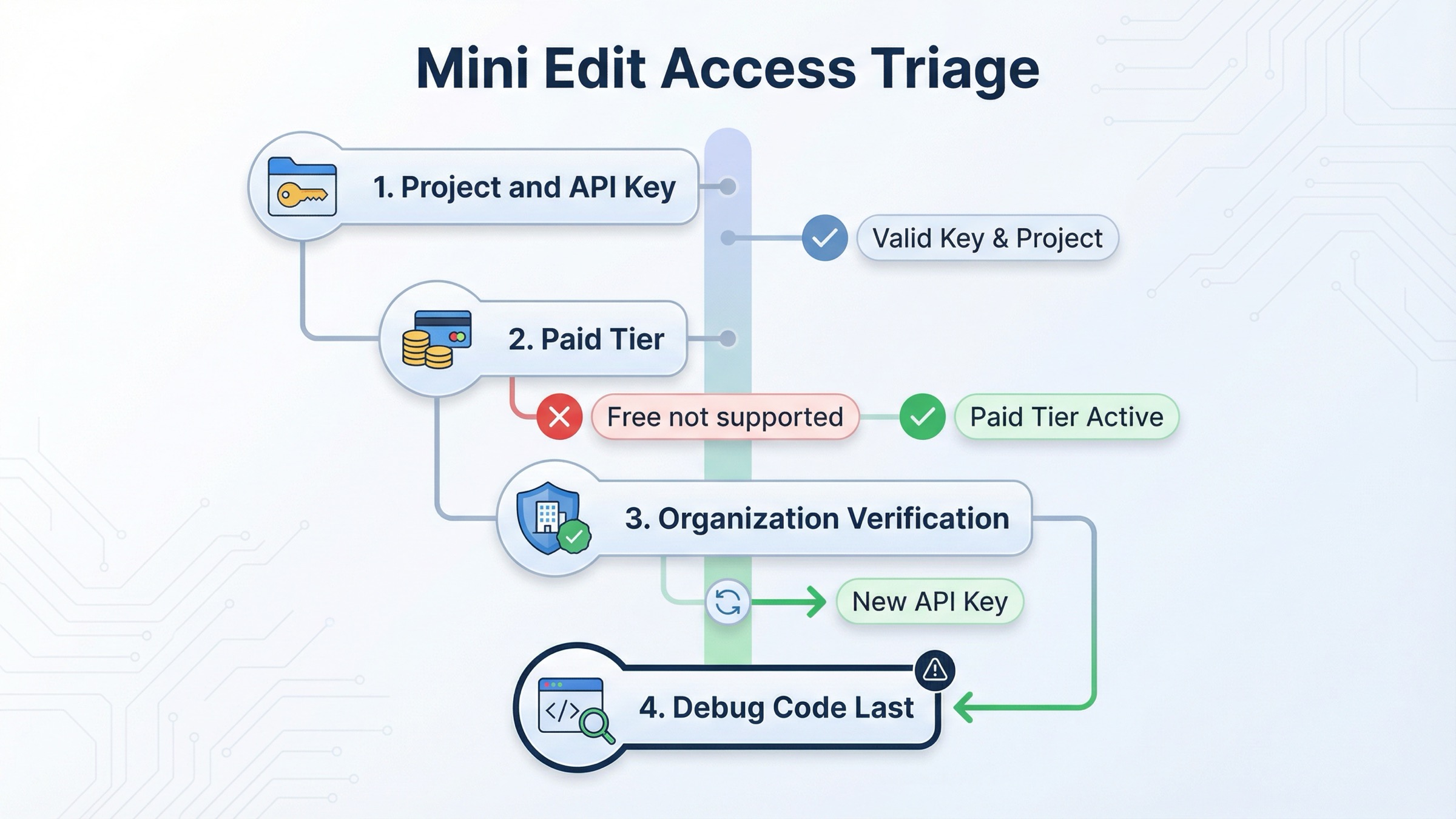
Многие exact-match страницы теряют читателя именно здесь. Они показывают sample code, но слишком поздно признают, что проблема может быть вообще не в синтаксисе.
По состоянию на 29 марта 2026 года текущая gpt-image-1-mini model page показывает для 1024x1024 цену $0.005 low, $0.011 medium и $0.036 high. На той же странице указано Free not supported, а стартовый лимит для Tier 1 — 100,000 TPM и 5 IPM.
Текущая статья про model availability говорит, что GPT-image-1 и GPT-image-1-mini доступны API-пользователям tier 1–5, но часть доступа может зависеть от organization verification. Текущая organization verification article также говорит, что обновление статуса может занимать до 30 минут, а выпуск нового API key часто решает затянувшиеся ошибки вида “not verified”.
Поэтому правильный troubleshooting order выглядит так:
- убедитесь, что API key относится к правильному project и organization
- убедитесь, что аккаунт находится на платном tier, где mini image access действительно доступен
- если симптомы все еще похожи на access issue, проверьте organization verification
- дайте системе полный 30-минутный propagation window
- если организация уже verified, сгенерируйте новый API key
- только потом переписывайте integration
Это важно, потому что direct mini edit request может падать даже при формально правильном коде. Если корень проблемы в account state, ни более красивый prompt, ни тотальный переход на Responses не помогут.
Если ваш блокер — это не edit logic, а именно доступ, следующая полезная статья — OpenAI image generation API verification guide. Если нужно считать бюджет, логичнее идти в GPT Image 1 Mini pricing.
Какие ошибки точные страницы по запросу чаще всего скрывают
Первая типичная ошибка — стартовать не с того API surface. Если задача — одна прямая правка, не надо идти в Responses только потому, что пример выглядит более современным. Документация уже дает вам более короткий и более понятный старт.
Вторая ошибка — неправильно понимать модельный слой в Responses. GPT Image models не выступают там как top-level model; top-level обычно остается текстовой моделью, а image work живет в tool layer.
Третья ошибка — ожидать от mask точной pixel-surgery семантики. OpenAI прямо пишет, что masking в GPT Image — prompt-based. Если у вас workflow, где допускается только сверхлокальное изменение без collateral movement, эту гипотезу нужно проверять очень рано.
Четвертая ошибка — поместить не тот asset в первый input slot. Если лицо, логотип или hero product не идут первыми, вы добровольно отдаете самый сильный preservation position, который mini сейчас предлагает.
Пятая ошибка — дебажить prompt раньше, чем доступ. Пока tier, verification или project context не выровнены, более длинный prompt не спасет запрос.
Шестая ошибка — просить слишком многого от одного дешевого edit-запроса. В текущих limitations OpenAI отдельно отмечает, что сложные prompts могут исполняться до 2 минут, а семейство моделей все еще упирается в точную типографику, стабильность layout и строгий structured composition control. Если вам одновременно нужны brand lockup accuracy, точный текст и несколько сохраненных reference images, очень вероятно, что проблема уже не в route, а в том, что mini — неправильная модель для этой edit-нагрузки.
Гораздо полезнее такая operational sequence:
- сначала сделайте один минимальный direct edit
- поместите самый важный asset в первый input slot
- включайте
input_fidelity="high"только там, где сохранность действительно критична - если результат близок, но недостаточно стабилен, разбейте большую правку на две более маленькие
Такая последовательность обычно экономит больше времени, чем еще один длинный prompt.
Когда mini для edit уже достаточно, а когда безопаснее сразу перейти на GPT Image 1.5

За этим keyword на самом деле скрывается не выбор «mini или Responses», а выбор «mini уже достаточно или нужно сразу идти в 1.5».
Текущий model comparison section формулирует ответ прямо: gpt-image-1.5 дает лучшее общее качество, а gpt-image-1-mini — более выгодный по стоимости вариант, когда image quality не является главным приоритетом. Если перевести это на язык edit-workflow, получится следующее.
Mini обычно уже достаточно, когда:
- вы делаете внутренние creative variations
- редактируете относительно недорогие ecommerce или room mockups
- работаете в основном с одной ключевой исходной картинкой
- хотите сначала прогнать дешевый benchmark, а потом решить, нужен ли flagship quality
- считаете cost важнее, чем максимальная сохранность и чистота результата
GPT Image 1.5 безопаснее, когда:
- в одном запросе есть несколько действительно важных reference images
- нужна более сильная brand preservation
- edit чувствителен к typography или layout
- вы работаете с дорогими marketing assets, где ретраи уже обходятся дорого
- вам нужен strongest current OpenAI image default, а не просто более низкая цена за картинку
Поэтому честная рекомендация звучит не как «mini vs Responses». Она звучит так: для mini-specific edit сначала direct Images API; если сама нагрузка показывает, что mini не хватает, переходите на GPT Image 1.5.
Если вам нужен более широкий quality-vs-cost контекст, следующая статья — GPT Image 1 Mini review. Если нужен более общий обзор OpenAI image family, логичнее продолжить с OpenAI Image API tutorial. Если дальше важна именно экономика 1.5, идите в GPT Image 1.5 pricing API.
FAQ
Может ли gpt-image-1-mini прямо сейчас напрямую редактировать изображения?
Да. На текущей model page для gpt-image-1-mini явно указан v1/images/edits, так что direct Images API — валидный current route для mini edit work.
Почему не начинать с Responses, если мне нужна только одна правка?
Потому что current image guide прямо говорит: если вам нужен один prompt и одна image job, Image API — лучший выбор. Responses сильнее тогда, когда edit — только часть более крупного conversation или tool workflow.
Mask заставляет модель менять только masked pixels?
Нет. Текущая документация OpenAI прямо говорит, что GPT Image masking остается prompt-based и не гарантирует идеальное следование по контуру mask. Воспринимайте mask как guidance, а не как hard-boundary pixel surgery.
Когда стоит сразу переключиться с mini на GPT Image 1.5?
Когда edit требует более сильной multi-image preservation, более надежной brand control, лучшей устойчивости на layout-sensitive assets или просто самого безопасного quality-first default от OpenAI.
Итоговая рекомендация
Если ваш точный сценарий на 29 марта 2026 года — отредактировать изображение через gpt-image-1-mini, начинайте с images.edit() или POST /v1/images/edits. Это самый ясный документированный путь, самый простой для отладки и самый безопасный способ не спутать mini-specific поведение с более общим workflow layer.
К Responses переходите только тогда, когда окружающий продукт действительно требует conversation state, tool orchestration или многошаговой мультимодальной логики. А второй вопрос решайте отдельно: если mini уже не хватает, не пытайтесь бесконечно оптимизировать маршрут — сразу benchmark GPT Image 1.5.