Выбор правильного провайдера AI API — это уже не просто техническое решение. При стоимости GPT-5.4 от OpenAI в $2,50 за миллион входных токенов, Gemini 3.1 Pro от Google с сопоставимым уровнем интеллекта по $2,00, и Claude Opus 4.6 от Anthropic с премиальной ценой $5,00 за его глубину рассуждений, цена за токен — это лишь часть картины. Что на самом деле определяет ваш ежемесячный счёт — это комбинация выбора модели, характеристик рабочей нагрузки и стратегий оптимизации, которые большинство сравнительных обзоров полностью игнорируют. В этом руководстве представлены актуальные верифицированные данные о ценах на март 2026 года, рассчитаны реальные месячные затраты для трёх бизнес-сценариев и предложен конкретный план действий по сокращению расходов на API на 60-80%.
Краткое содержание
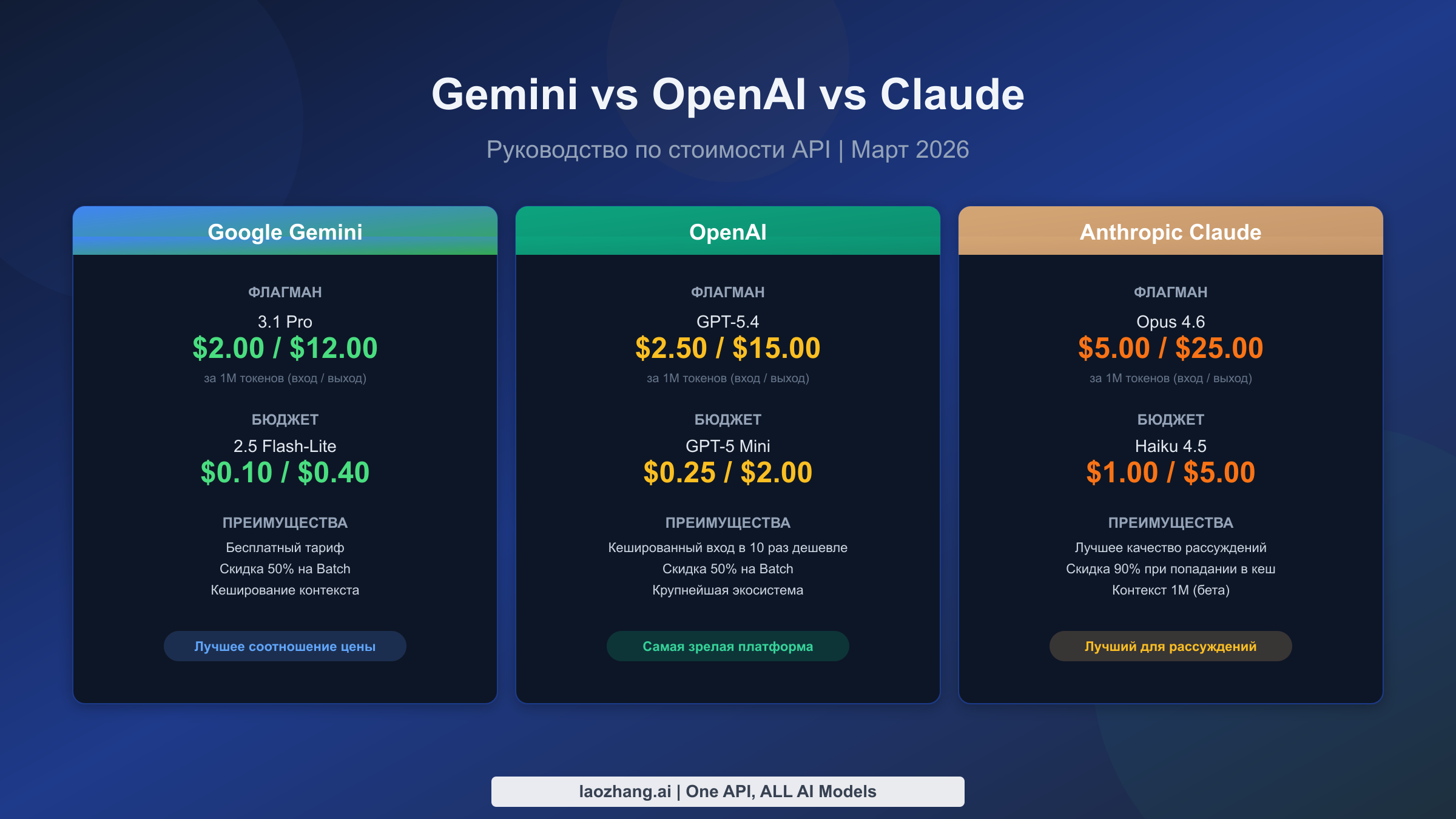
Google Gemini предлагает самый широкий ценовой диапазон — от $0,10/MTok (Flash-Lite) до $2,00/MTok (3.1 Pro), что делает его наиболее гибкой по цене платформой с щедрым бесплатным тарифом. GPT-5.4 от OpenAI стоит $2,50/$15,00 с самой зрелой экосистемой и кешированным вводом, который примерно в десять раз дешевле. Claude занимает премиальный сегмент (Sonnet 4.6 по $3,00/$15,00, Opus 4.6 по $5,00/$25,00), но обеспечивает превосходное качество рассуждений и скидку 90% при попадании в кеш. Для большинства продакшн-нагрузок комбинация многоуровневого использования моделей с пакетной обработкой и кешированием промптов снижает затраты на 60-80% вне зависимости от выбранного провайдера.
Полная разбивка цен API (март 2026)
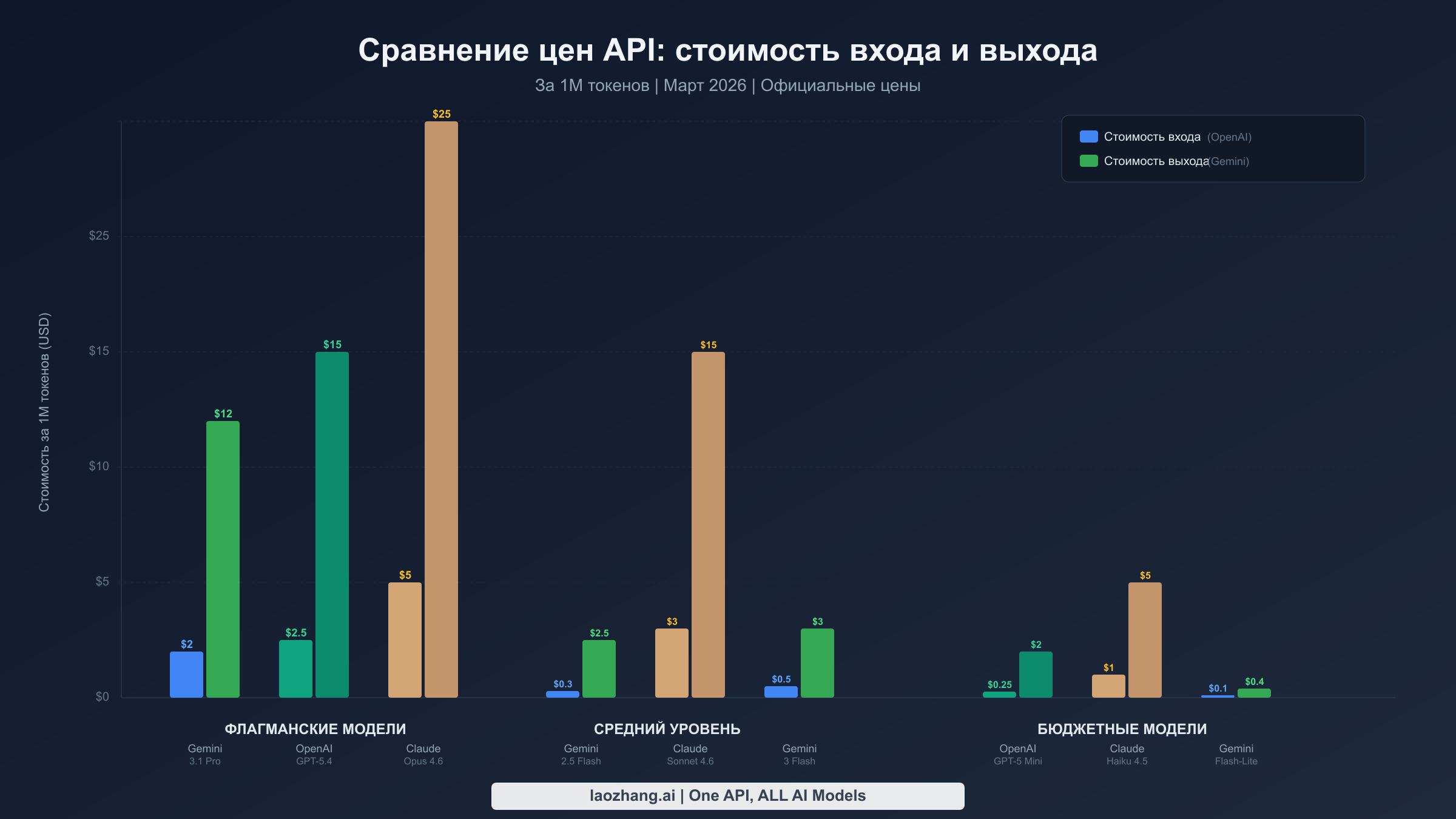
Для понимания полной ценовой картины необходимо смотреть дальше флагманских моделей. Каждый провайдер предлагает линейку уровней, рассчитанных на разные компромиссы между качеством и стоимостью, и разница между самыми дешёвыми и самыми дорогими моделями часто превышает 50 раз. Приведённые данные верифицированы по официальным страницам с ценами 17 марта 2026 года с указанием источников для каждого показателя.
Google Gemini имеет самый широкий ассортимент моделей с принципиально разными ценовыми уровнями. Недавно выпущенный Gemini 3.1 Pro Preview стоит $2,00 за миллион входных токенов и $12,00 за миллион выходных токенов для промптов до 200 000 токенов, с повышением до $4,00 и $18,00 для более длинных контекстов (ai.google.dev, март 2026). В бюджетном сегменте Gemini 2.5 Flash-Lite предлагает производственный уровень качества всего за $0,10 на входе и $0,40 на выходе за миллион токенов, что примерно в 20 раз дешевле флагманской модели. Gemini 3 Flash Preview занимает промежуточную позицию по $0,50/$3,00, предлагая сильные возможности рассуждения за малую долю цены Pro. Пожалуй, самое важное — Gemini предоставляет действительно полезный бесплатный тариф, охватывающий большинство моделей, что делает его единственным крупным провайдером, где можно прототипировать и запускать небольшие приложения при нулевых затратах. Для разработчиков, изучающих полный спектр вариантов ценообразования Gemini API, многоуровневая структура означает, что практически всегда найдётся модель под любые бюджетные ограничения.
| Модель | Вход ($/1M) | Выход ($/1M) | Пакетный вход | Пакетный выход | Контекст |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | $2,00 / $4,00 | $12,00 / $18,00 | $1,00 / $2,00 | $6,00 / $9,00 | 1M |
| Gemini 3 Flash | $0,50 | $3,00 | $0,25 | $1,50 | 1M |
| Gemini 2.5 Pro | $1,25 / $2,50 | $10,00 / $15,00 | $0,625 / $1,25 | $5,00 / $7,50 | 1M |
| Gemini 2.5 Flash | $0,30 | $2,50 | $0,15 | $1,25 | 1M |
| Gemini 2.5 Flash-Lite | $0,10 | $0,40 | $0,05 | $0,20 | 1M |
OpenAI позиционирует GPT-5.4 как текущий флагман по $2,50 за миллион входных токенов и $15,00 за миллион выходных токенов при стандартном использовании контекста. Существенная ценовая инновация — разделение на короткий и длинный контексты: промпты, превышающие 272 000 токенов на GPT-5.4, облагаются двукратной надбавкой на вход и полуторакратной на выход ($5,00/$22,50), что существенно влияет на стоимость для задач RAG и анализа документов. GPT-5 Mini остаётся основным бюджетным вариантом по $0,25/$2,00, обеспечивая качество уровня GPT-4 при значительно меньших затратах. Самое сильное ценовое преимущество OpenAI — кешированный ввод, который часто снижает стоимость входных токенов примерно на 90% для повторяющихся системных промптов, а Batch API предоставляет фиксированную скидку 50% на всю обработку, не требующую реального времени.
| Модель | Вход ($/1M) | Выход ($/1M) | Кешированный вход | Скидка Batch | Контекст |
|---|---|---|---|---|---|
| GPT-5.4 (короткий) | $2,50 | $15,00 | $0,25 | 50% | 1,05M |
| GPT-5.4 (длинный >272K) | $5,00 | $22,50 | $0,50 | 50% | 1,05M |
| GPT-5 | $1,25 | $10,00 | $0,125 | 50% | 128K |
| GPT-5 Mini | $0,25 | $2,00 | $0,025 | 50% | 128K |
Anthropic Claude занимает премиальный сегмент, а его ценообразование отражает акцент платформы на глубине рассуждений и безопасности. Claude Opus 4.6, флагманская модель, стоит $5,00 на входе и $25,00 на выходе за миллион токенов, что делает его самым дорогим вариантом среди трёх провайдеров, но при этом он стабильно занимает лидирующие позиции в бенчмарках рассуждений. Claude Sonnet 4.6 по $3,00/$15,00 предлагает привлекательный компромисс с сильными возможностями в кодинге и аналитике, тогда как Haiku 4.5 по $1,00/$5,00 обеспечивает точку входа. Кеширование промптов Claude обеспечивает значительную экономию: попадания в кеш оцениваются всего в 10% от стандартной стоимости входных токенов. Как мы подробно рассматривали в нашем разборе цен Claude API, ключевым фактором стоимости является характер ответов Claude, ориентированных на объёмный вывод.
| Модель | Вход ($/1M) | Выход ($/1M) | Попадание в кеш | Запись в кеш | Контекст |
|---|---|---|---|---|---|
| Opus 4.6 | $5,00 | $25,00 | $0,50 | $6,25 | 200K |
| Sonnet 4.6 (до 200K) | $3,00 | $15,00 | $0,30 | $3,75 | 200K-1M |
| Haiku 4.5 | $1,00 | $5,00 | $0,10 | $1,25 | 200K |
Реальные сценарии месячных затрат
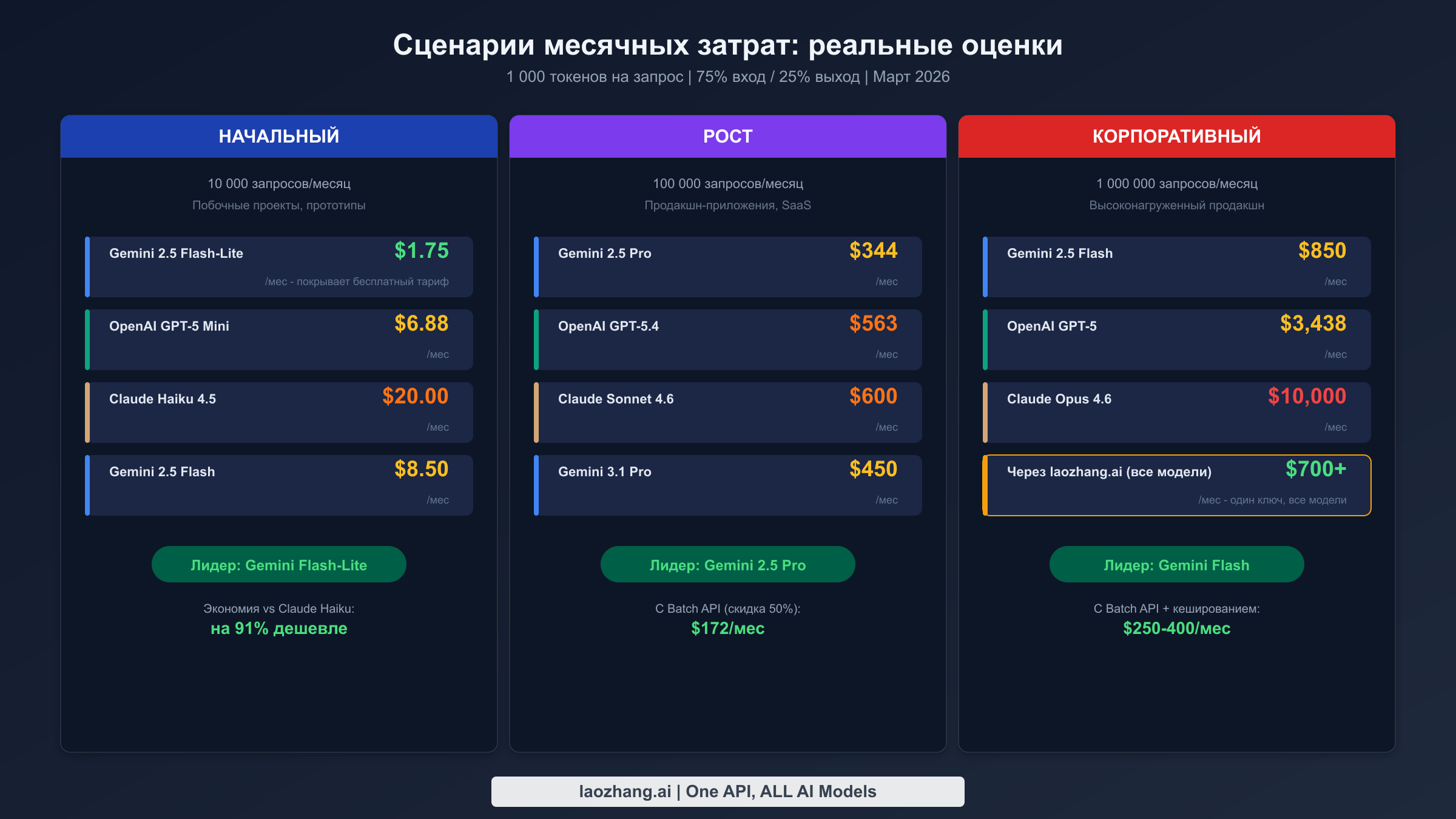
Цены за токен приобретают смысл только при переводе в реальные ежемесячные счета. В следующих сценариях принято 1 000 токенов на запрос с соотношением входа к выходу 75/25, что представляет типичную разговорную или аналитическую нагрузку. Расчёты используют стандартные цены без скидок оптимизации, обеспечивая базовый уровень, который можно значительно снизить с помощью стратегий, описанных далее в этом руководстве.
Начальный уровень (10 000 запросов в месяц) охватывает индивидуальных разработчиков, побочные проекты и ранние прототипы. На этом масштабе Gemini 2.5 Flash-Lite стоит примерно $1,75 в месяц, а бесплатный тариф полностью покрывает эту нагрузку. OpenAI GPT-5 Mini обойдётся примерно в $6,88, а Claude Haiku 4.5 — около $20,00. Разница в стоимости на этом масштабе относительно невелика в абсолютных величинах, что означает, что приоритет следует отдавать качеству модели и удобству разработки, а не чистой цене. Если ваш проект только начинается, бесплатный тариф Gemini — непревзойдённая точка входа, и вы всегда можете перейти на платные модели по мере роста требований без смены провайдера.
Уровень роста (100 000 запросов в месяц) — это тот этап, когда ценовые решения начинают иметь реальное значение. Продакшн-приложение, обрабатывающее 100 тыс. запросов в месяц на флагманской модели, выявляет существенные ценовые разрывы. Gemini 2.5 Pro стоит примерно $344 в месяц, GPT-5.4 — около $563, а Claude Sonnet 4.6 достигает $600. Эти цифры предполагают стандартное ценообразование, но в реальности большинство продакшн-приложений должны использовать пакетную обработку и кеширование, что может сократить эти суммы примерно вдвое. На этом уровне выбор между провайдерами часто сводится к тому, нужен ли вам баланс стоимости и качества Gemini, зрелость экосистемы OpenAI или глубина рассуждений Claude для вашего конкретного варианта использования.
Корпоративный уровень (1 000 000 запросов в месяц) многократно усиливает каждую ценовую разницу, превращая её в тысячи долларов. Выполнение миллиона запросов через Gemini 2.5 Flash стоит примерно $850, GPT-5 — около $3 438, а Claude Opus 4.6 достигает $10 000 в месяц по стандартным тарифам. На этом масштабе многоуровневое использование моделей становится необходимостью. Грамотно спроектированная система, направляющая 70% простых запросов на Flash-Lite ($175), 25% на модель среднего уровня ($860) и всего 5% на премиальную модель ($500), может обработать ту же нагрузку примерно за $1 535, что представляет снижение на 55-85% в зависимости от выбранной премиальной модели.
Скрытые затраты, меняющие расчёты
Цены за токен на официальных страницах рассказывают неполную историю. Несколько множителей стоимости остаются скрытыми в документации или проявляются только после значительного использования, и неучёт их может привести к превышению бюджета на 30-100%. Понимание этих скрытых затрат критически важно для точного финансового планирования.
Thinking-токены представляют собой самый крупный скрытый расход для задач, требующих интенсивных рассуждений. И Gemini 2.5 Pro, и Claude Sonnet 4.6 генерируют внутренние токены рассуждений, которые учитываются по тарифу выходных токенов, но не отображаются в финальном ответе. Запрос, генерирующий видимый ответ из 500 токенов, на самом деле может потребить 2 000-5 000 выходных токенов с учётом рассуждений, фактически умножая стоимость вывода в 4-10 раз для сложных задач на рассуждение. На страницах ценообразования Gemini явно указано, что цена вывода включает thinking-токены, и функция расширенного мышления Claude работает аналогично. При бюджетировании приложений, сильно зависящих от рассуждений — таких как генерация кода, математический анализ или многошаговое планирование — всегда умножайте предполагаемый объём вывода как минимум на 3, чтобы учесть накладные расходы на мышление.
Надбавки за длинный контекст применяются и к Gemini, и к OpenAI, когда ваши промпты превышают определённые пороги. Gemini 2.5 Pro и 3.1 Pro взимают двукратную плату за вход и полуторакратную за выход при промптах, превышающих 200 000 токенов. OpenAI GPT-5.4 применяет аналогичный множитель 2x/1,5x при превышении 272 000 токенов. Для приложений RAG и рабочих процессов анализа документов, регулярно обрабатывающих длинные контексты, это может удвоить эффективную стоимость за токен. Claude, напротив, сохраняет фиксированные цены независимо от длины контекста в рамках стандартного окна 200K, что делает его наиболее предсказуемым вариантом для задач с длинным контекстом.
Плата за поисковое заземление добавляет ещё один уровень затрат для пользователей Gemini. Модели Gemini 3.x взимают $14 за 1 000 поисковых запросов при использовании заземления через Google Search (после первых 5 000 бесплатных ежемесячных промптов). Для приложений, которые заземляют каждый ответ в результатах веб-поиска, это добавляет $14 на тысячу запросов сверх стоимости токенов. OpenAI и Claude в настоящее время не предлагают интегрированное поисковое заземление на уровне API, поэтому эта статья расходов уникальна для Gemini, но также представляет возможность, которую другие провайдеры не могут обеспечить.
Какой провайдер лучше для вашего сценария

Вместо объявления единственного победителя, оптимальный выбор полностью зависит от характеристик вашей рабочей нагрузки. Каждый провайдер сформировал чёткие преимущества в определённых областях, и следующие рекомендации основаны как на анализе цен, так и на наблюдениях за реальной производительностью в продакшн-развёртываниях.
Чат-боты и автоматизация поддержки клиентов приоритизируют скорость, экономичность и адекватное качество для разговорного взаимодействия. Gemini 2.5 Flash-Lite по $0,10/$0,40 за миллион токенов обеспечивает лучшую экономику для высоконагруженных разговорных приложений, особенно в сочетании с бесплатным тарифом для разработки и тестирования. Для приложений, требующих более высокого качества ответов, Gemini 2.5 Flash по $0,30/$2,50 предоставляет отличные возможности рассуждения по всё ещё доступной цене. Наличие бесплатного тарифа означает, что вы можете проверить архитектуру чат-бота, прежде чем выделять бюджет.
Приложения RAG и базы знаний требуют точного поиска, верного суммирования и обычно включают обработку длинных документных контекстов. Gemini 2.5 Pro по $1,25/$10,00 предлагает лучшее сочетание контекстного окна в 1M токенов и разумных цен для промптов стандартной длины, хотя двукратную надбавку при превышении 200K токенов следует учитывать в прогнозах затрат. Claude Sonnet 4.6 превосходит конкурентов в точности и следовании инструкциям в задачах RAG, но стоит дороже — $3,00/$15,00. Для бюджетно-ориентированных развёртываний RAG маршрутизация запросов с дополненным поиском в Gemini и резервирование Claude для синтеза наиболее сложных извлечённых контекстов создаёт эффективный гибридный подход.
Генерация кода и инструменты разработки больше всего выигрывают от сильных возможностей рассуждения и следования инструкциям. Сравнение Claude Opus 4.6 и GPT-5 показало, что Claude стабильно лидирует в бенчмарках качества генерации кода. Claude Sonnet 4.6 по $3,00/$15,00 обеспечивает оптимальное соотношение возможностей кодирования и стоимости, что делает его самым популярным выбором среди компаний, создающих инструменты для разработчиков. Если бюджет является основным ограничением, Gemini 3 Flash Preview по $0,50/$3,00 обеспечивает удивительно сильную генерацию кода за шестую часть цены.
Агентные рабочие процессы и многошаговое рассуждение требуют моделей, способных поддерживать контекст, эффективно планировать и надёжно использовать инструменты на протяжении расширенных цепочек взаимодействий. Claude Opus 4.6, несмотря на премиальное ценообразование $5,00/$25,00, остаётся золотым стандартом для агентных приложений благодаря превосходному следованию инструкциям и способностям планирования. Накладные расходы на thinking-токены делают агентные нагрузки особенно дорогими, но для критически важных автоматизированных процессов ценовая надбавка оправдана значительно более высоким процентом успешного выполнения задач.
Пакетная обработка и офлайн-анализ должны всегда использовать Batch API для получения прямой скидки 50% на стоимость. Пакетное ценообразование Gemini снижает стоимость Gemini 2.5 Flash до $0,15/$1,25, делая масштабную обработку документов исключительно доступной. Batch API от OpenAI применяет ту же скидку 50% ко всем моделям с возвратом результатов в течение 24 часов.
Стратегии оптимизации затрат, которые действительно работают
Переход от понимания ценообразования к активному снижению затрат требует внедрения конкретных стратегий. Следующие подходы ранжированы по эффекту и сложности внедрения, с конкретными расчётами ожидаемой экономии.
Многоуровневое использование моделей обеспечивает наибольшую немедленную экономию для большинства приложений и требует лишь изменений в логике маршрутизации. Принцип прост: направляйте запросы к самой дешёвой модели, способной справиться с конкретной задачей. Грамотно спроектированная система отправляет 70% простых запросов на бюджетные модели (Flash-Lite по $0,10/$0,40 или GPT-5 Mini по $0,25/$2,00), 25% задач средней сложности на модели среднего уровня (Gemini 2.5 Flash по $0,30/$2,50 или Claude Sonnet по $3,00/$15,00) и только 5% действительно сложных задач на рассуждение — на премиальные модели (Opus по $5,00/$25,00 или GPT-5.4 по $2,50/$15,00). Для нагрузки в 100 тыс. запросов, которая стоила бы $600 на одном Claude Sonnet, многоуровневая маршрутизация снижает счёт примерно до $160 — экономия 73%.
Пакетная обработка через Batch API предоставляет гарантированную скидку 50% на входные и выходные токены для любого запроса, не требующего ответа в реальном времени. Все три провайдера теперь предлагают пакетную обработку: Gemini явно указывает пакетные цены для каждой модели, OpenAI предоставляет фиксированную скидку 50% с SLA 24 часа, а Claude предлагает аналогичные пакетные возможности. Для конвейеров обработки данных, анализа контента и запланированных задач генерации практически нет причин не использовать пакетное ценообразование. Если 40% вашей нагрузки допускает отложенную обработку, один только Batch API сокращает общий счёт на 20%.
Кеширование промптов трансформирует экономику приложений с повторяющимися системными промптами. Система кеширования промптов Claude снижает стоимость входных токенов при попадании в кеш до 10% от стандартной цены, тогда как контекстное кеширование Gemini предлагает аналогичное снижение с дополнительным ценообразованием на основе хранения. Если ваше приложение использует системный промпт из 4 000 токенов для всех запросов, кеширование этого промпта экономит примерно 90% стоимости этих входных токенов. Для приложения на 100 тыс. запросов это составляет примерно $300-500 месячной экономии в зависимости от модели.
Платформы агрегации API, такие как laozhang.ai, предлагают прагматичное решение для команд, которые хотят использовать нескольких провайдеров, не управляя отдельными API-ключами, биллинговыми аккаунтами и интеграционным кодом. Эти платформы предоставляют единую OpenAI-совместимую API-точку, которая направляет запросы к любой модели от Gemini, OpenAI или Claude с конкурентоспособными ценами, часто совпадающими с прямыми тарифами провайдеров или ниже их. Помимо ценообразования, операционное преимущество значительно: один API-ключ даёт мгновенный доступ ко всем моделям, и вы можете переключаться между провайдерами без изменений в коде. Для команд, оценивающих несколько моделей или использующих гибридные архитектуры, снижение интеграционных накладных расходов и гибкость выбора провайдера обычно оправдывают подход агрегации.
Принятие решения: практические следующие шаги
Объём ценовых данных и стратегий оптимизации может показаться ошеломляющим, но структура принятия решений на самом деле проста, когда вы фокусируетесь на своих основных ограничениях.
Если стоимость — ваше основное ограничение, начните с Gemini. Бесплатный тариф позволяет проверить приложение без каких-либо затрат, а прогрессия от Flash-Lite ($0,10/$0,40) через Flash ($0,30/$2,50) до Pro ($1,25/$10,00) обеспечивает естественные пути повышения по мере роста требований к качеству. Gemini также предлагает самое агрессивное пакетное ценообразование, снижая и без того доступные модели до исключительно низкой стоимости за токен.
Если качество и рассуждение превыше всего, инвестируйте в Claude. Sonnet 4.6 предлагает лучшее соотношение качества и стоимости для приложений, требующих точных, нюансированных и хорошо аргументированных ответов. Система кеширования промптов делает повторные взаимодействия значительно дешевле, а расширенный контекст бета-версии на 1M открывает возможности для анализа длинных документов, которые другие провайдеры не могут обеспечить на аналогичном уровне качества. Подписка Pro за $20 в месяц также включает щедрое использование для прототипирования.
Если экосистема и инструменты важнее всего, OpenAI остаётся самым безопасным выбором. Самая широкая поддержка сторонних интеграций, самая зрелая экосистема SDK и крупнейшее сообщество разработчиков означают более высокую скорость разработки. Кешированный ввод (в 10 раз дешевле) и Batch API (скидка 50%) предоставляют мощные рычаги оптимизации затрат, а цена GPT-5.4 в $2,50/$15,00 конкурентоспособна с флагманом Gemini.
Для команд, создающих продакшн-приложения, которым нужна гибкость, использование платформы агрегации API, такой как laozhang.ai, даёт возможность протестировать всех трёх провайдеров через единую точку интеграции. С ценообразованием, соответствующим прямым тарифам провайдеров, и возможностью мгновенного переключения моделей, она устраняет риск привязки к поставщику, возникающий при раннем выборе одного провайдера. Вы можете начать на docs.laozhang.ai с кредитами от $5.
Часто задаваемые вопросы
Какой AI API самый дешёвый в 2026 году?
Google Gemini 2.5 Flash-Lite по $0,10 за вход и $0,40 за выход на миллион токенов — самый дешёвый продакшн-готовый API от крупного провайдера по состоянию на март 2026 года. В сочетании с Batch API (скидка 50%) стоимость снижается до $0,05/$0,20, а бесплатный тариф покрывает небольшие объёмы использования при нулевых затратах. GPT-5 Mini от OpenAI по $0,25/$2,00 — самый дешёвый вариант OpenAI, а Claude Haiku 4.5 по $1,00/$5,00 — наиболее доступная модель Anthropic.
Сколько стоит выполнение 100 000 запросов к API в месяц?
Ежемесячные затраты на 100 тыс. запросов (при 1 000 токенов каждый, соотношение вход-выход 75/25) варьируются от примерно $18 с Gemini Flash-Lite до $1 000 с Claude Opus 4.6. Наиболее популярные варианты среднего уровня стоят $344 (Gemini 2.5 Pro), $563 (GPT-5.4) и $600 (Claude Sonnet 4.6). Применение Batch API и оптимизации кеширования обычно снижает эти суммы на 40-60%.
Влияют ли thinking-токены на стоимость API?
Да, существенно. И Gemini 2.5 Pro, и модели Claude генерируют внутренние токены рассуждений, которые тарифицируются по ставке выходных токенов, но не отображаются в видимом ответе. Для задач с интенсивными рассуждениями thinking-токены могут умножить эффективную стоимость вывода в 3-10 раз. Всегда отслеживайте фактическое потребление токенов через панель использования вашего провайдера, а не оценивайте на основе длины ответа.
Стоит ли переходить с OpenAI на Gemini для экономии?
Для чувствительных к стоимости нагрузок переход на Gemini может сократить расходы на API на 30-70% в зависимости от текущего использования моделей. Компромисс заключается в том, что качество моделей Gemini, хотя и быстро улучшается, может отличаться от OpenAI для конкретных сценариев использования. Практичный подход — направлять чувствительные к стоимости массовые операции в Gemini, сохраняя критически важные для качества потоки на текущем провайдере. Платформы агрегации API делают этот гибридный подход простым во внедрении.
Как снизить расходы на AI API на 50% и более?
Три стратегии в совокупности обычно обеспечивают снижение затрат на 60-80%: (1) Многоуровневое использование моделей направляет 70% запросов на бюджетные модели, экономя 40-60%. (2) Пакетная обработка через Batch API предоставляет фиксированную скидку 50% для нагрузок, не требующих реального времени. (3) Кеширование промптов снижает стоимость повторяющихся входных данных на 75-90%. Начните с многоуровневого использования моделей, так как оно не требует изменений API — только логику маршрутизации.