
Claude Code Agent Teams превращают однопоточный опыт работы с Claude Code в координированную мультиагентную систему, где независимые экземпляры Claude обмениваются сообщениями, распределяют задачи и параллельно работают над вашей кодовой базой. Эта экспериментальная функция, выпущенная в феврале 2026 года, представляет собой фундаментальный сдвиг во взаимодействии разработчиков с ИИ-ассистентами для написания кода — переход от одного диалога к оркестрации целых команд разработки. Данное руководство проведёт вас через всё необходимое для создания эффективных агентных команд: от начальной настройки до продакшен-паттернов.
Краткое содержание
Agent Teams позволяют запускать несколько сессий Claude Code, которые работают совместно над общим проектом. Одна сессия выступает в роли лидера команды и координирует работу, а участники команды (teammates) выполняют задачи независимо в собственных контекстных окнах. В отличие от субагентов (которые работают внутри одной сессии и могут отчитываться только перед родительским агентом), участники команды могут обмениваться сообщениями напрямую, делиться находками в процессе работы и координироваться без посредничества лидера. Для активации установите CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=true в переменных окружения или settings.json, а также убедитесь, что у вас Claude Code v2.1.32 или новее. Anthropic продемонстрировала мощь этого подхода, используя 16 параллельных агентов для создания компилятора C на 100 000 строк, способного компилировать ядро Linux, — при стоимости приблизительно $20 000 за 2 000 сессий (документировано в инженерном блоге Anthropic, февраль 2026).
Что такое Claude Code Agent Teams? (И чем они отличаются от субагентов)
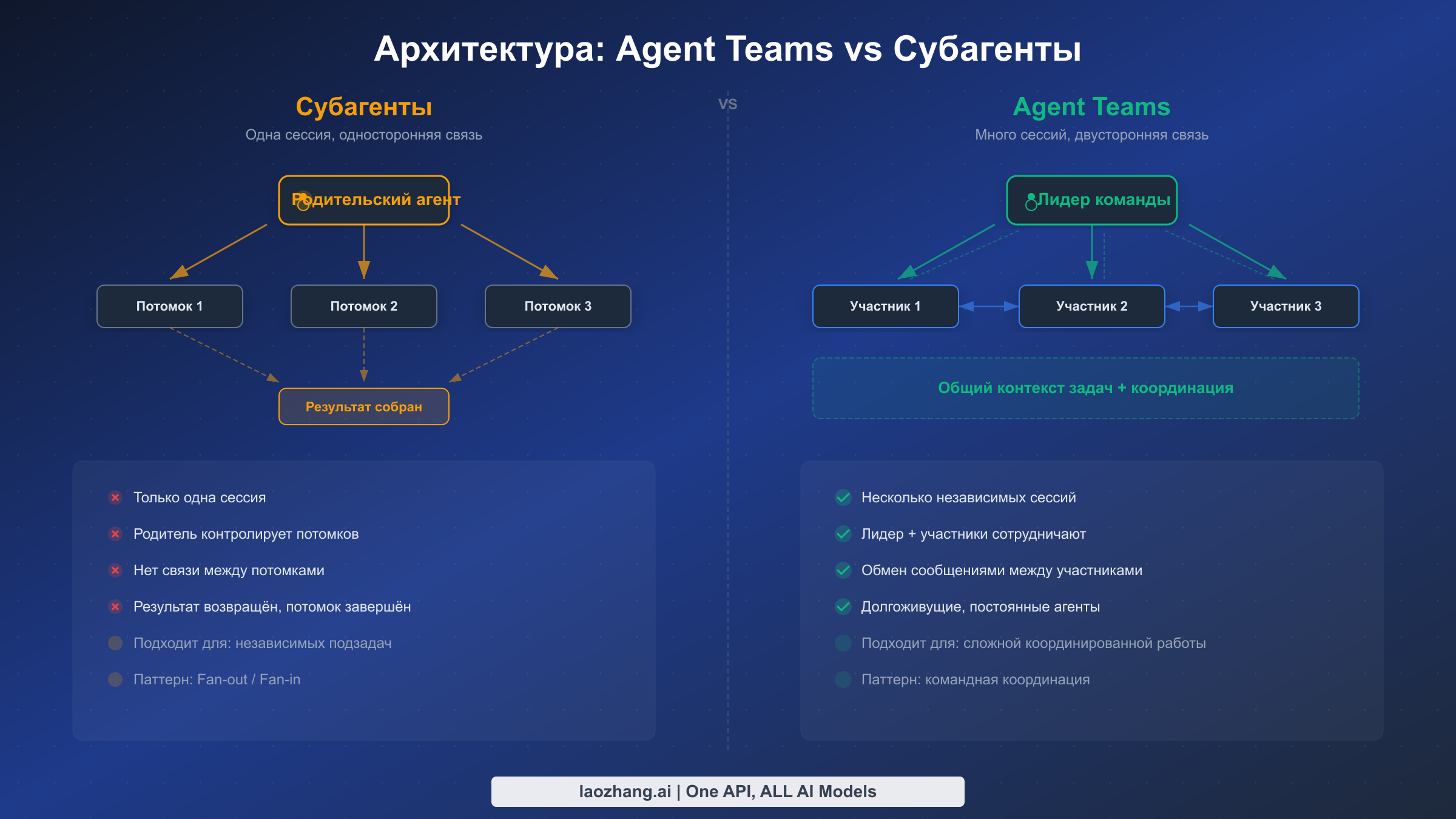
До появления агентных команд Claude Code предлагал субагентов как основной способ параллелизации работы. Субагенты работают в контексте одной сессии, выполняют ограниченную задачу и возвращают результаты родительскому агенту. Они полезны для изоляции исследовательской работы от основного диалога — например, для поиска паттерна в кодовой базе, пока основной агент продолжает рассуждать об архитектуре. Однако у субагентов есть фундаментальное ограничение: они не могут общаться друг с другом. Если агент A обнаруживает что-то важное для работы агента B, эта информация должна пройти через родительский агент, создавая узкое место, которое ограничивает возможности координации.
Agent Teams решают эту проблему, предоставляя каждому участнику собственную полноценную сессию Claude Code с независимым контекстом, доступом к инструментам и возможностью отправлять сообщения любому другому участнику или лидеру. Это архитектурное отличие открывает паттерны, невозможные с субагентами: фронтенд-агент может напрямую сообщить бэкенд-агенту об изменении API-контракта, тестовый агент может уведомить автора кода о провалившемся тесте без ожидания, пока лидер передаст сообщение, а несколько агентов могут прийти к общему пониманию проблемы через прямой диалог.
Следующая таблица помогает определить, когда использовать каждый подход, поскольку неправильный выбор приводит либо к излишней сложности (агентные команды для простого поиска), либо к координационным узким местам (субагенты для сквозных изменений):
| Параметр | Субагенты | Agent Teams |
|---|---|---|
| Сессии | Работают внутри родительской сессии | Каждый получает собственную полноценную сессию |
| Коммуникация | Односторонняя: потомок -> родитель | Двунаправленная: любой -> любой |
| Контекст | Общий контекст родительского окна | Независимые контекстные окна |
| Координация | Родитель как посредник | Прямой обмен между участниками |
| Подходит для | Изолированных, сфокусированных задач | Сложных многокомпонентных проектов |
| Настройка | Встроенная, без конфигурации | Требуется экспериментальный флаг |
| Стоимость | Ниже (накладные расходы одной сессии) | Выше (накладные расходы нескольких сессий) |
Субагентов можно сравнить с наймом узкого консультанта, который отчитывается перед вами, тогда как агентные команды — это формирование проектной группы, где каждый может общаться с каждым. Если вы уже знакомы с возможностями Claude Code и хотите понять, где агентные команды вписываются в общий инструментарий, наше руководство по установке Claude Code охватывает базовую настройку.
Как Agent Teams работают «под капотом»
Архитектура агентных команд состоит из трёх основных компонентов: сессия лидера команды, одна или несколько сессий участников и общий координационный слой, построенный на файлах задач и межагентных сообщениях.
Лидер команды — это ваша основная сессия Claude Code, в которую вы вводите начальный промпт с описанием того, что должна выполнить команда. Когда Claude определяет, что задача выиграет от параллельной работы, он использует инструмент Teammate для создания дополнительных процессов Claude Code. Каждый запущенный процесс работает как независимая сессия Claude Code с собственным контекстным окном, правами доступа к инструментам и историей диалога. Лидер назначает начальные задачи каждому участнику и отслеживает прогресс через общую систему задач.
Участники команды — это полностью автономные экземпляры Claude Code, которые получают начальный промпт от лидера и затем работают самостоятельно. Они могут читать и записывать файлы, выполнять команды, производить поиск по кодовой базе и использовать все стандартные инструменты Claude Code. Ключевое отличие — они также могут отправлять сообщения лидеру и другим участникам с помощью инструмента SendMessage, что обеспечивает координацию в реальном времени и отличает агентные команды от простого параллельного выполнения.
Координационный слой состоит из двух механизмов, работающих совместно. Во-первых, общий список задач, хранящийся на диске, который все участники команды могут читать и обновлять. Задачи имеют статусы (pending, in_progress, completed), могут блокировать другие задачи и содержат метаданные о том, кто над чем работает. Когда участник завершает задачу, зависимые задачи, которые были заблокированы, автоматически становятся доступными для других участников. Во-вторых, API SendMessage обеспечивает прямую межагентную коммуникацию для ситуаций, требующих большей детализации, чем изменение статуса задачи, — обмен находками, запрос уточнений или предложение изменений в подходе.
Эта архитектура означает, что агентные команды порождают всплеск параллельной активности при запуске, постепенно сходятся по мере завершения задач и обмена находками, и в конечном итоге сворачиваются обратно в сессию лидера, который синтезирует результаты и представляет их вам. Весь процесс виден в терминале: вы можете наблюдать за потоком сообщений между агентами, следить за обновлением статусов задач и вмешиваться, если команда отклоняется от курса.
Понимание жизненного цикла сессии агентной команды помогает прогнозировать затраты и сроки. На фазе запуска (обычно 10-30 секунд) лидер создаёт сессии участников и назначает начальные задачи. На фазе параллельного выполнения (основная часть сессии, от минут до часов) участники работают независимо с периодическим обменом сообщениями. Фаза конвергенции начинается, когда первые участники завершают свои задачи и начинают помогать с оставшейся работой или проверять результаты других. Наконец, фаза синтеза — лидер собирает все результаты, разрешает конфликты и формирует единый ответ. Каждая фаза имеет разные характеристики потребления токенов — запуск обходится дёшево, параллельное выполнение стоит дороже всего, а синтез зависит от объёма необходимой согласованности.
Стоит отметить, что каждая сессия участника наследует права доступа и набор инструментов от сессии лидера, но не историю диалога. Участники начинают с чистого контекста, содержащего только описание назначенной задачи и начальный контекст, предоставленный лидером. Это означает, что участники не знают, что вы обсуждали с лидером до создания команды, что на самом деле является преимуществом — это заставляет лидера предоставлять явные, самодостаточные инструкции вместо того, чтобы полагаться на неявный контекст из предыдущей части диалога. Если участнику нужна информация из истории беседы, лидер должен включить её в описание задачи или отправить через сообщение.
Настройка первой агентной команды (пошаговая инструкция)
Для запуска агентных команд необходимо активировать экспериментальный флаг функции и разобраться в нескольких параметрах конфигурации, влияющих на поведение команды. Процесс настройки занимает менее пяти минут, но выбранные параметры определяют эффективность работы ваших команд.
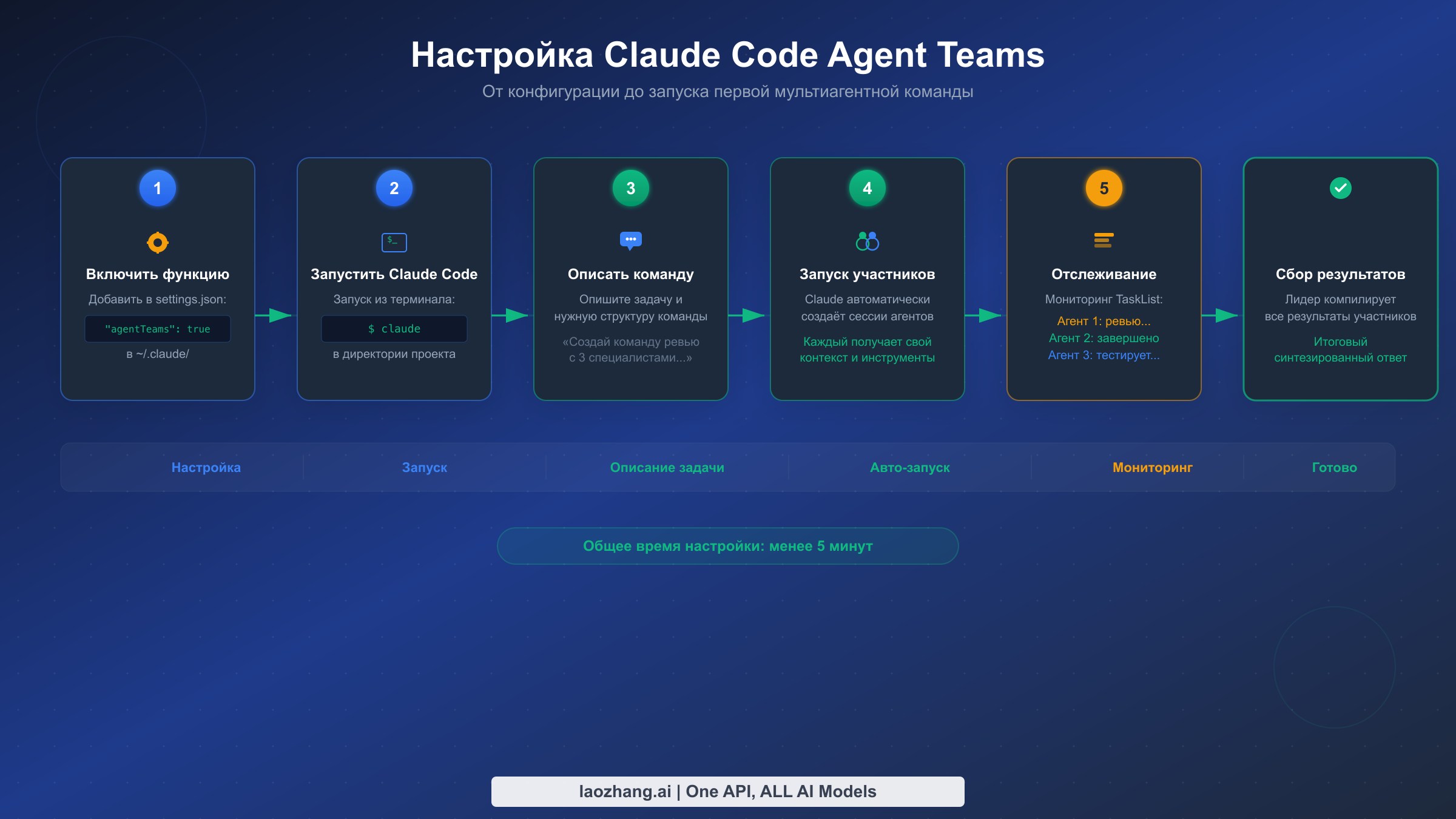
Шаг 1: Проверьте версию Claude Code. Agent Teams требуют версию v2.1.32 или новее. Проверьте свою версию командой claude --version в терминале. Для обновления выполните npm install -g @anthropic-ai/claude-code@latest или используйте подходящий для вашей установки пакетный менеджер.
Шаг 2: Включите экспериментальный флаг. Есть три варианта включения агентных команд, и выбор зависит от того, хотите ли вы активировать функцию глобально или для конкретного проекта:
json// Вариант A: Настройки проекта (.claude/settings.json) { "env": { "CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "true" } } // Вариант B: Пользовательские настройки (~/.claude/settings.json) { "env": { "CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "true" } } // Вариант C: Переменная окружения (на уровне сессии) // export CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=true
Настройки на уровне проекта рекомендуются для команд, поскольку они гарантируют, что у всех, кто работает с тем же репозиторием, агентные команды включены без необходимости менять личную конфигурацию. Настройка сохраняется между сессиями и фиксируется в системе контроля версий вместе с вашим проектом.
Шаг 3: Запустите Claude Code и опишите командную задачу. Запустите Claude Code в директории проекта и сформулируйте промпт, который естественно предполагает параллельную работу. Ключ в том, чтобы описать желаемый результат и отдельные потоки работы, а не микроменеджерить структуру команды. Например, вместо «создай трёх агентов» скажите: «Проведи ревью этого pull request на предмет уязвимостей безопасности, проблем производительности и пробелов в тестовом покрытии. Каждая область должна быть исследована независимо, а результаты скомпилированы в единый отчёт.»
Claude проанализирует ваш промпт, определит оптимальное количество участников, запустит их с фокусированными инструкциями и настроит структуру координации задач. В терминале вы увидите сообщения о создании участников и начале их работы.
Шаг 4: Отслеживайте прогресс. Пока команда работает, вы можете наблюдать за общим списком задач и межагентными сообщениями в выводе терминала. Лидер периодически проверяет состояние участников и может перераспределять задачи, если кто-то завершил работу раньше или столкнулся с блокирующими проблемами. Если нужно скорректировать курс команды, отправьте сообщение лидеру, который передаст соответствующие инструкции затронутым участникам.
Шаг 5: Соберите и проверьте результаты. Когда все задачи выполнены, лидер синтезирует результаты всех участников и формирует единый ответ. Участники автоматически завершаются через протокол выключения SendMessage: лидер отправляет shutdown_request, каждый участник подтверждает shutdown_response, и сессии корректно закрываются.
Если вы столкнётесь с проблемами при настройке, наиболее распространённые причины — несовместимость версий (обновите Claude Code), отсутствие флага функции (проверьте все три возможных места настройки) и ошибки прав доступа (убедитесь, что ваш API-ключ или подписка имеют достаточную квоту для нескольких параллельных сессий). Для пользователей API особенно важно помнить, что каждый участник потребляет собственное выделение токенов, что может значительно ускорить исчерпание лимитов.
Ещё один практический момент — ресурсы вашей системы. Каждый участник запускается как отдельный процесс Node.js, поэтому создание большой команды на машине с ограниченной оперативной памятью может вызвать проблемы производительности. На большинстве рабочих машин комфортно работают три-пять одновременных участников. Для более крупных команд (десять и более) используйте машину с не менее 16 ГБ оперативной памяти и контролируйте потребление памяти процессами. Пропускная способность сети редко является узким местом, поскольку обмен данными между участниками происходит через операции с локальной файловой системой и вызовы API, но задержки при обращении к API Anthropic могут влиять на скорость ответа участников.
Для команд, использующих Claude Code с бесплатным тарифом, агентные команды доступны, но ограниченная квота расходуется значительно быстрее при нескольких параллельных сессиях. Рассмотрите переход на Pro или Max, прежде чем полагаться на агентные команды для серьёзной работы, или используйте API-доступ с достаточной квотой уровня, чтобы избежать досадных прерываний посреди командной сессии.
Архитектурные паттерны команд для реальных проектов

Разница между продуктивной агентной командой и хаотичным набором параллельных сессий Claude определяется тем, как вы структурируете зоны ответственности команды и паттерны коммуникации. Из опыта сообщества и собственного тестирования Anthropic выделились четыре архитектурных паттерна, стабильно эффективных для разных типов работы.
Паттерн 1: Review Squad (команда ревью). Этот паттерн назначает один и тот же артефакт нескольким ревьюерам, каждый из которых анализирует его через свою призму. Типичная конфигурация создаёт трёх участников — один сфокусирован на уязвимостях безопасности, другой на узких местах производительности, третий на стиле кода и поддерживаемости. Лидер собирает все ревью и формирует единый отчёт с приоритизацией по серьёзности. Этот паттерн особенно хорошо работает для ревью pull request, оценки архитектуры и аудита документации, поскольку ревьюерам не нужно координироваться друг с другом — они анализируют одно и то же содержимое независимо, а лидер обеспечивает синтез. Стоимость в токенах относительно невысока, так как каждый ревьюер читает те же файлы без генерации больших изменений кода.
Паттерн 2: Feature Builder (создание функциональности). При разработке новой функциональности, охватывающей несколько уровней стека, паттерн Feature Builder назначает по одному участнику на каждый уровень: фронтенд, бэкенд, база данных и тесты. Лидер заранее определяет интерфейсы между уровнями (API-контракты, схемы данных), а затем позволяет каждому участнику реализовывать свою часть независимо. Именно здесь межагентный обмен сообщениями становится критически важным — когда бэкенд-участник обнаруживает необходимость корректировки API-контракта, он сообщает об этом фронтенд-участнику напрямую, минуя лидера. Паттерн Feature Builder наиболее эффективен, когда границы функциональности чётко определены и интерфейсы между компонентами можно задать до начала работы.
Паттерн 3: Debug Swarm (рой отладки). Отладка сложных проблем часто выигрывает от одновременной проверки нескольких гипотез. Debug Swarm запускает нескольких участников, каждый из которых проверяет свою теорию о первопричине. Один может исследовать недавние изменения кода, другой анализирует паттерны в логах, третий проверяет различия в конфигурациях между окружениями. По мере того как участники отбрасывают гипотезы или находят подтверждающие доказательства, они делятся находками друг с другом. Рой естественно сходится по мере накопления данных, и лидер формирует диагноз, когда вырисовывается чёткая картина. Этот паттерн особенно ценен при работе с прерывистыми сбоями, состояниями гонки или проблемами, затрагивающими несколько сервисов.
Паттерн 4: Cross-Layer (межуровневая координация). Самый сложный паттерн обрабатывает задачи, где изменения в одной области каскадируют на несколько других — например, переименование ключевой модели данных, затрагивающей API-уровень, миграции базы данных, фронтенд-компоненты и тестовые фикстуры. Лидер планирует последовательность изменений, назначает каждый уровень участнику, а участники координируют конкретные изменения через прямой обмен сообщениями. Этот паттерн требует наибольшего объёма межагентной коммуникации и выигрывает от чёткой системы зависимостей задач: миграция базы данных должна завершиться до изменений API, которые, в свою очередь, должны завершиться до обновления фронтенда.
Реальный пример иллюстрирует работу этих паттернов на практике. В одном задокументированном случае разработчик попросил Claude: «Use a team of agents to do QA against my blog at localhost:4321.» Лидер создал пять участников на базе Sonnet, каждому назначив свой аспект QA: ответы основных страниц, рендеринг постов блога, навигация и ссылки, RSS/sitemap/SEO и доступность. Участники работали независимо — агент проверки страниц проверил 16 страниц на статус HTTP 200, проверщик ссылок валидировал 146 внутренних URL, а агент доступности обнаружил такие проблемы, как преобразованный в строку булев атрибут в HTML-классе и отсутствующие ARIA-метки на переключателе темы. Лидер синтезировал все находки в приоритизированный отчёт из 10 проблем (4 критических, 2 средних, 4 незначительных) — работу, которая заняла бы у одного агента значительно больше времени при последовательном выполнении.
Мощная, но часто упускаемая из виду возможность — шлюз утверждения плана. При создании участника вы можете потребовать, чтобы он представил план реализации на утверждение, прежде чем вносить какие-либо изменения. Участник работает в режиме планирования только для чтения — он может читать файлы и анализировать кодовую базу, но не может ничего менять, пока лидер (или вы) не одобрит его план. Если план отклонён, участник получает обратную связь и пересматривает свой подход. Это незаменимо для критически важных изменений, где необходима контрольная точка с участием человека перед модификацией кода, при этом сохраняя преимущества параллельного анализа, предоставляемого агентными командами.
Выбор между этими паттернами зависит от двух факторов: степени взаимодействия между потоками работы (низкое взаимодействие подходит для Review Squad, высокое — для Cross-Layer) и того, создаёте ли вы новый код или модифицируете существующий (новый код — Feature Builder, существующий — Debug Swarm или Cross-Layer). Для большинства проектов начните с паттерна Review Squad, чтобы освоиться с агентными командами, прежде чем переходить к более сложным координационным паттернам.
Коммуникация и управление задачами: детальный разбор
Эффективность агентных команд напрямую зависит от того, насколько хорошо участники коммуницируют и как структурированы задачи. Понимание коммуникационных примитивов, доступных участникам, помогает проектировать промпты, ведущие к лучшим координационным паттернам.
SendMessage — основной инструмент коммуникации. Он поддерживает несколько типов сообщений для различных целей координации. Стандартные сообщения передают текст от одного агента к другому — отправитель указывает получателя (по имени или роли в команде) и содержимое сообщения. Широковещательные сообщения отправляются всем участникам одновременно, что полезно, когда лидеру нужно объявить об изменении направления или поделиться важной для всех находкой. Запросы на завершение и ответы на них формируют протокол корректного завершения, гарантирующий, что ни один участник не будет прерван в середине задачи.
Важное проектное решение Anthropic заключается в том, что SendMessage является единственным каналом прямой коммуникации. Нет общей памяти, общего буфера обмена и возможности для одного участника читать историю диалога другого. Это ограничение сделано намеренно — оно заставляет коммуникацию быть явной и структурированной, предотвращая неявные связи, которые сделали бы поведение команды непредсказуемым. Когда участнику A нужна информация от участника B, он должен запросить её через сообщение, а участник B должен ответить с соответствующим контекстом. Это делает информационный поток проверяемым и отлаживаемым.
Управление задачами обеспечивает структурную основу координации. Задачи создаются через TaskCreate, обновляются через TaskUpdate и запрашиваются через TaskList и TaskGet. У каждой задачи есть тема, описание, статус, владелец и опциональные связи зависимостей. Система зависимостей особенно мощна: вы можете указать, что задача B заблокирована задачей A, и когда задача A завершится, задача B автоматически станет доступной для участника.
Вот пример того, как лидер может структурировать задачи для команды Feature Builder:
pythonTaskCreate(subject="Define API contract for user profiles", description="...") TaskCreate(subject="Implement backend API endpoints", description="...", addBlockedBy=["task-1"]) # Заблокирована до определения API-контракта TaskCreate(subject="Build frontend profile components", description="...", addBlockedBy=["task-1"]) # Также заблокирована до API-контракта TaskCreate(subject="Write integration tests", description="...", addBlockedBy=["task-2", "task-3"]) # Заблокирована до завершения обеих реализаций
Эта структура зависимостей гарантирует, что ни один участник не начнёт реализацию до определения контракта, а тесты запустятся только после завершения и фронтенда, и бэкенда. Участники самостоятельно берут следующую доступную незаблокированную задачу по завершении текущей, что означает автоматическую балансировку нагрузки без необходимости вмешательства лидера.
Распространённая ошибка — чрезмерное усложнение графа зависимостей задач. Зависимости должны отражать реальные требования к последовательности выполнения — задача B действительно не может начаться до завершения задачи A, — а не выражать предпочтения относительно порядка выполнения. Избыточные зависимости снижают параллелизм, так как участники тратят больше времени в ожидании разблокировки. И наоборот, недостаточные зависимости приводят к конфликтам, когда два участника одновременно модифицируют пересекающийся код. Золотая середина — создавать зависимости только при наличии реальной зависимости на уровне данных или файлов и использовать широкие определения областей задач, дающие участникам чёткое владение файлами.
Для команд, обрабатывающих большие кодовые базы, мониторинг объёма коммуникации между агентами служит полезным индикатором здоровья. Если агенты отправляют больше нескольких сообщений на задачу, это обычно указывает на слишком мелкую декомпозицию задач — агенты тратят избыточные токены на координацию вместо продуктивной работы. Идеальный паттерн показывает короткую вспышку сообщений после запуска (агенты подтверждают понимание задач), периодические сообщения во время выполнения (обмен находками или запрос уточнений) и финальный раунд сообщений при синтезе. Для разработчиков, создающих приложения с использованием API-возможностей Claude Code, руководство по интеграции MCP объясняет, как расширять агентные команды пользовательскими инструментами через Model Context Protocol.
Анализ стоимости — сколько на самом деле стоят Agent Teams?
Понимание стоимости агентных команд критически важно для принятия обоснованных решений о том, когда параллельное выполнение оправдывает вложения, а когда достаточно одной сессии Claude Code. Модель стоимости агентных команд проста в теории, но имеет нюансы, существенно влияющие на реальные расходы.
Базовая формула: общая стоимость = количество участников x средний расход токенов на участника x цена за токен. Каждый участник — это независимая сессия, потребляющая токены на чтение файлов, размышления, генерацию вывода и коммуникацию с другими участниками. Сессия лидера также потребляет токены на координационные накладные расходы. В отличие от подписки с фиксированным месячным бюджетом, агентные команды на базе API тарифицируются строго по токенам, делая стоимость прямо пропорциональной объёму выполненной работы.
Эксперимент Anthropic с компилятором C предоставляет наиболее конкретный ориентир стоимости. Используя 16 параллельных агентов Opus 4.6 в приблизительно 2 000 сессиях Claude Code, команда создала компилятор C на 100 000 строк на базе Rust, способный компилировать ядро Linux для архитектур x86, ARM и RISC-V. Общая стоимость составила приблизительно $20 000 за использование API (по данным инженерного блога Anthropic, февраль 2026). Это примерно $0,20 за строку кода или $10 за сессию в среднем. Это сценарий верхней границы с использованием самой дорогой модели (Opus) для крайне сложной задачи — большинство рабочих процессов разработчиков будут стоить значительно меньше.
Выбор модели кардинально влияет на стоимость. Использование Sonnet 4.6 вместо Opus 4.6 снижает стоимость за токен на 40% (Sonnet по $3/$15 за MTok против Opus по $5/$25, по данным claude.com/pricing, март 2026). Для многих задач агентных команд — ревью кода, генерация документации, написание тестов — Sonnet обеспечивает сопоставимое с Opus качество при существенном снижении затрат. Практичная стратегия — использовать Opus для агента-лидера (которому нужны лучшие способности рассуждения для координации) и Sonnet для участников (которые выполняют более сфокусированные, чётко определённые задачи).
Стратегии оптимизации стоимости, позволяющие снизить расходы на агентные команды без ущерба качеству, включают: ограничение размера команды минимальным количеством участников, способных эффективно распараллелить работу (оптимально три-пять), установку чётких границ области для каждого участника во избежание дублирующего исследования, использование зависимостей задач для предотвращения ненужного потребления токенов на заблокированную работу и мониторинг расхода токенов через панели реального времени Claude Console.
Для разработчиков, часто запускающих агентные команды и желающих дополнительно снизить расходы, сторонние сервисы маршрутизации API, такие как laozhang.ai, предлагают оплату за токен с доступом к моделям Claude и потенциально меньшими накладными расходами по сравнению с прямым управлением тарифными уровнями API у Anthropic. Этот подход может быть особенно выгодным для команд с переменной нагрузкой — некоторые недели интенсивное использование агентных команд, другие — минимальная активность, — потому что вы не платите за неиспользованную ёмкость подписки.
Ещё один часто упускаемый фактор стоимости — кэширование промптов. Когда несколько участников читают одни и те же большие файлы (что типично для паттерна Review Squad), кэширование промптов значительно снижает эффективную стоимость токенов. Система ITPM Anthropic, учитывающая кэш, означает, что кэшированные входные токены не учитываются в ваших лимитах скорости и тарифицируются по 10% от базовой цены входных токенов. Для агентных команд, разделяющих общий контекст кодовой базы, эффективное кэширование может снизить стоимость входных токенов на 50-80% по сравнению с наивными реализациями. Ключевая оптимизация — структурировать промпты участников так, чтобы общий контекст (системные инструкции и общие справочные файлы) располагался в начале каждого запроса, максимизируя процент попаданий в кэш между участниками. Для более глубокого понимания взаимодействия кэширования с лимитами скорости см. наше руководство по лимитам Claude Code.
| Сценарий | Агенты | Модель | Примерный расход токенов | Примерная стоимость |
|---|---|---|---|---|
| Ревью PR (3 перспективы) | 3 | Sonnet 4.6 | ~500K всего | ~$2-5 |
| Новая функция (3 уровня) | 4 | Opus+Sonnet | ~2M всего | ~$15-30 |
| Debug Swarm (4 гипотезы) | 4 | Sonnet 4.6 | ~1M всего | ~$5-12 |
| Крупный рефакторинг (межуровневый) | 5 | Смешанная | ~3M всего | ~$25-50 |
| Компилятор C (кейс Anthropic) | 16 | Opus 4.6 | ~Миллиарды | ~$20 000 |
Уроки из эксперимента Anthropic с компилятором C
Наиболее поучительный пример агентных команд в масштабе — собственная инженерная команда Anthropic, использовавшая 16 агентов Opus 4.6 для создания компилятора C с нуля на Rust. Этот эксперимент, задокументированный в инженерном блоге Anthropic в феврале 2026 года, выявил как необычайный потенциал, так и практические ограничения мультиагентной разработки. Ключевые уроки напрямую применимы к структурированию собственных агентных команд.
Урок 1: Параллелизация лучше всего работает с естественно декомпозируемыми задачами. Проект компилятора C удался, потому что компиляция по своей природе модульна — парсинг, проверка типов, генерация кода и оптимизация могут разрабатываться и тестироваться относительно независимо. Команда обнаружила, что максимальный параллелизм достижим, когда имеется множество различных проваливающихся тестов, так как каждый агент мог взять другой тест без координации. Когда набор тестов достигал 99% прохождения и оставшиеся сбои были взаимосвязаны, параллелизм естественно снижался, поскольку агенты должны были координироваться более тщательно. Вывод для разработчиков — определяйте естественные параллельные границы в вашем проекте до запуска команды, а не надейтесь, что Claude сам разберётся с декомпозицией.
Урок 2: «Оракул» упрощает всё. Для задачи компиляции ядра Linux команда использовала GCC как проверенный эталонный компилятор. Был создан тестовый стенд, который случайным образом компилировал большинство файлов ядра через GCC и лишь несколько файлов через новый компилятор, позволяя каждому агенту фокусироваться на исправлении разных ошибок в разных файлах одновременно. Этот паттерн — сравнение вашего вывода с доверенным эталоном — обобщается далеко за пределы компиляторов. Если вы рефакторите API, оставьте старую реализацию работающей рядом с новой и позвольте агентам верифицировать поведенческую эквивалентность. Если мигрируете базу данных, сравнивайте результаты запросов между старой и новой схемами. Паттерн «оракула» превращает открытую проблему качества в замкнутый цикл верификации, который агенты могут выполнять независимо.
Урок 3: Накладные расходы на коммуникацию реальны, но управляемы. При 16 агентах потенциал коммуникационного хаоса значителен. Команда Anthropic обнаружила, что структурированные зависимости задач снижают ненужный межагентный «шум»: вместо постоянного обмена сообщениями о текущей работе система задач обеспечивала видимость того, кто чем занимается. Прямой обмен сообщениями резервировался для реальных открытий или конфликтов — например, когда два агента пытались изменить один и тот же файл. Для собственных команд противьтесь искушению поощрять избыточную коммуникацию. Большинство задач агентных команд выигрывают от подхода «разделяй и властвуй с контрольными точками», а не от непрерывного обсуждения.
Урок 4: Стоимость в токенах масштабируется с исследованием, а не только с результатом. Стоимость $20 000 за 100 000 строк кода может показаться высокой, но она отражает обширное исследование и отладку, необходимые для создания компилятора, обрабатывающего всю сложность реального C-кода. Каждый агент не просто писал код — он читал существующий код, формулировал гипотезы об ошибках, тестировал исправления, откатывал неудачные попытки и итерировал. Стоимость этой исследовательской работы в токенах значительно превышает стоимость финального результата. Команды, работающие над более прямолинейными задачами (реализация функции по чётким спецификациям, например), увидят значительно более низкое соотношение стоимости к результату.
Урок 5: Вмешательство человека в ключевых точках принятия решений умножает эффективность команды. Хотя компилятор C был в основном создан автономно, команда Anthropic обнаружила, что периодическое человеческое руководство в точках архитектурных решений — например, выбор между конкурирующими подходами к генерации кода — предотвращало трату агентами тысяч токенов на исследование неоптимальных путей. Наиболее эффективный рабочий процесс был не полностью автономным, а полуавтономным: агенты работают независимо над чётко определёнными подзадачами, а люди принимают стратегические решения высокого уровня, формирующие рамки этих подзадач. Этот гибридный подход уважает сильные стороны обеих сторон — агенты отлично справляются с параллельным выполнением чётко определённых задач, а люди превосходят в стратегическом суждении и долгосрочном планировании.
Урок 6: Ценность агентных команд растёт со сложностью проекта. Для простого добавления функции одна сессия Claude Code обычно быстрее и дешевле, чем создание команды. Точка окупаемости — когда агентные команды дают лучшие результаты на доллар, чем последовательная работа, — наступает, когда задача включает действительно параллельные потоки работы (разные файлы, разные аспекты) или когда задача выигрывает от множества перспектив (ревью кода, оценка архитектуры). Проект компилятора C был далеко за точкой окупаемости, поскольку включал тысячи независимых тестовых случаев, которые можно было отлаживать параллельно. Для большинства рабочих процессов разработчиков точка окупаемости находится в районе трёх-пяти действительно независимых подзадач — при меньшем количестве накладные расходы на координацию команды перевешивают выгоды от параллелизма.
Часто задаваемые вопросы
Сколько участников использовать для типичного проекта?
Начните с трёх-пяти участников для большинства задач. Паттерн Review Squad хорошо работает с тремя специализированными ревьюерами, а Feature Builder обычно требует четырёх (по одному на уровень плюс тесты). Более пяти участников редко повышают производительность, поскольку накладные расходы на координацию начинают перевешивать преимущества параллелизма. Исключение — задачи с высокой степенью декомпозиции, как эксперимент Anthropic с компилятором, где 16 агентов были эффективны, потому что каждый работал над действительно независимыми тестовыми случаями с минимальной потребностью в координации.
Работают ли агентные команды с подпиской Pro или Max, или требуется API-доступ?
Агентные команды работают как с планами подписки, так и с прямым API-доступом. При использовании подписки (Pro за $20/месяц или Max за $100-200/месяц) каждый участник потребляет токены из вашей общей квоты подписки, что означает более быстрое достижение лимитов использования, чем с одной сессией. API-доступ обеспечивает более гранулярный контроль бюджетов токенов на участника и позволяет обойти потолок квоты подписки, что делает его более подходящим для интенсивного использования агентных команд. Независимо от метода доступа, убедитесь, что у вас достаточная квота для запланированного количества параллельных сессий.
Что происходит, если два участника пытаются редактировать один файл одновременно?
Claude Code обрабатывает параллельный доступ к файлам через стандартные механизмы блокировки файлов и разрешения конфликтов. На практике правильно структурированные зависимости задач предотвращают большинство конфликтов, гарантируя, что только один участник работает с конкретным файлом в каждый момент времени. Если конфликты всё же возникают, лидер обычно обнаруживает их на этапе синтеза и разрешает, отдавая приоритет изменениям одного из участников. Конфликты можно минимизировать, структурируя задачи вокруг владения файлами — назначая каждому участнику ответственность за отдельные файлы или директории, а не за пересекающиеся области.
Можно ли сохранять и повторно использовать конфигурации команд?
В настоящее время агентные команды не имеют встроенного шаблона или конфигурационного файла для предопределённых командных структур. Однако вы можете реализовать переиспользуемые конфигурации, создав инструкции в CLAUDE.md с описанием предпочтительных командных паттернов или написав пользовательские навыки (skills), кодирующие конкретные командные архитектуры. Сообщество также разработало конфигурационные паттерны, распространяемые через GitHub gists и репозитории. По мере выхода функции из экспериментального статуса ожидаются более структурированные варианты конфигурации.
Как агентные команды взаимодействуют с ветками git и контролем версий?
Каждый участник работает в той же рабочей директории и состоянии git, что и лидер. Это означает, что все участники видят ту же ветку, незафиксированные изменения и состояние файлов. Для сложных задач лидер может поручить участникам работать в изолированном режиме с использованием git worktrees, что даёт каждому участнику отдельную копию репозитория. Это предотвращает конфликты слияния при параллельной работе, но требует этапа согласования в конце. Для более простых задач, где участники модифицируют разные файлы, прямой параллельный доступ к основной рабочей директории работает хорошо.
Достаточно ли стабильны агентные команды для продакшен-процессов?
Агентные команды в настоящее время помечены как экспериментальные, что означает возможность изменения API, поведения или доступности без предупреждения со стороны Anthropic. Для продакшен-процессов этот экспериментальный статус несёт риски — обновление Claude Code может изменить механизм координации команд или внести несовместимые изменения в протокол SendMessage. Тем не менее многие разработчики успешно используют агентные команды в повседневной работе для ревью кода, разработки функциональности и отладки. Рекомендация — использовать их для задач, где допустим частичный сбой и ручное вмешательство возможно, а не для полностью автоматизированных CI/CD-пайплайнов, где критична надёжность. Среди текущих известных ограничений: отсутствие возобновления сессий (команда /resume не восстанавливает участников), только одна команда на сессию, отсутствие вложенных команд (участники не могут создавать свои команды), а также участники иногда не отмечают задачи как завершённые, что может блокировать зависимые задачи. Ожидается, что эти ограничения будут устранены по мере выхода функции из экспериментального статуса.