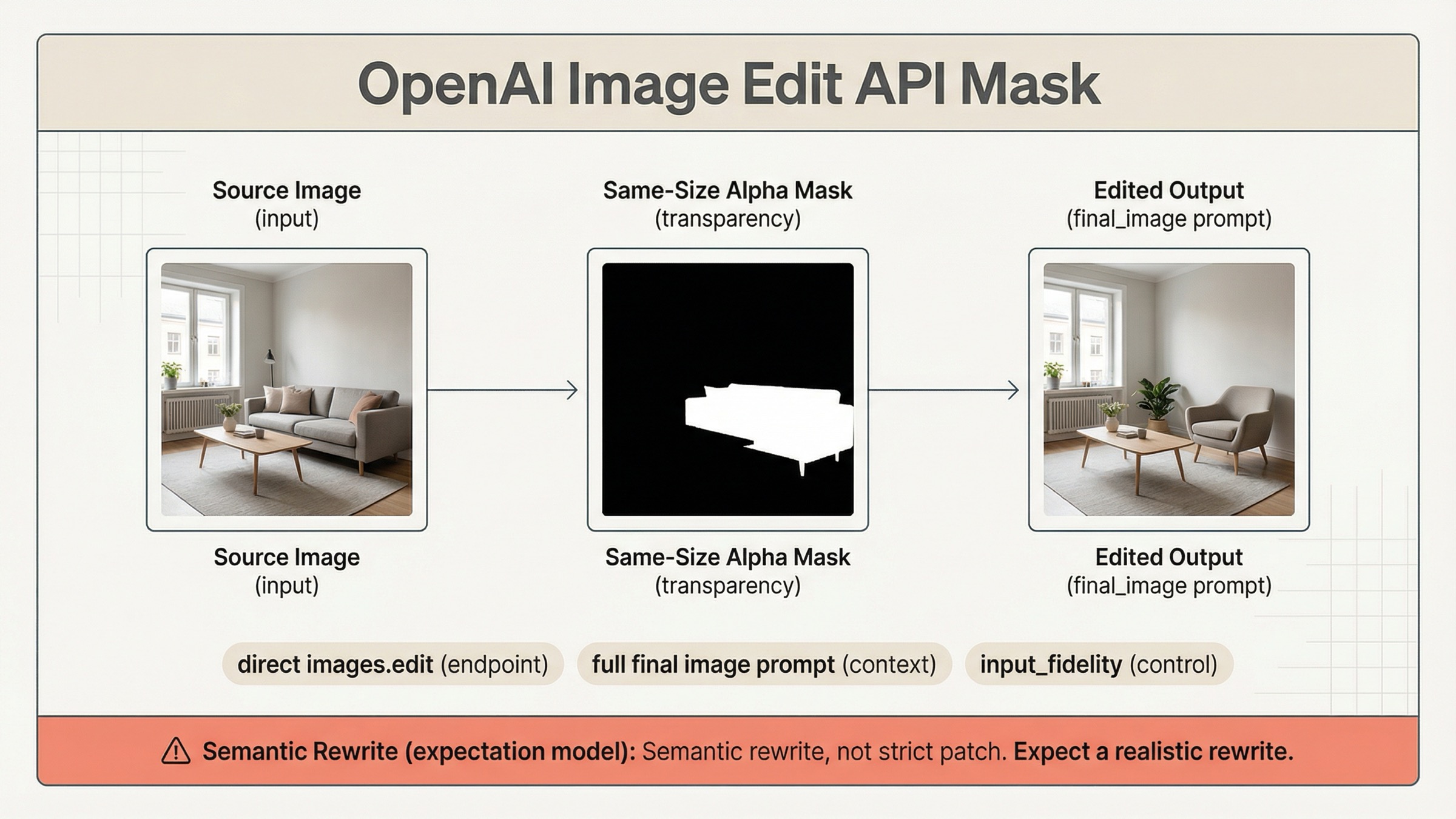
2026년 3월 29일 기준으로 OpenAI mask edits 의 가장 안전한 current default 는 direct images.edit() 를 gpt-image-1.5 와 함께 쓰고, same-size alpha mask 를 보내며, prompt 를 빈 구역 설명이 아니라 final image 전체 설명으로 쓰는 것이다. 이 한 가지 route decision 만 제대로 잡아도 Responses 로 너무 빨리 넘어가거나, 예전 inpainting 처럼 strict local patch 를 기대하다가 실패하는 일을 크게 줄일 수 있다.
이 query 가 아직도 괜히 복잡해 보이는 이유는 답이 한 페이지에 모여 있지 않기 때문이다. image generation guide 는 mask 의 mechanical requirements 를 설명하고, input fidelity 는 preservation side 를 보강하며, Responses image tool options 는 action=auto|generate|edit 를 다른 곳에서 다룬다. 한 페이지만 보면 route decision 에 필요한 그림이 반쪽만 남는다.
게다가 OpenAI 는 이미 분명히 말하고 있다. GPT Image 의 masking 은 prompt-based guidance 이며 exact mask shape 를 완전히 보장하지 않는다. 그래서 valid mask 인데도 결과가 whole-image rewrite 처럼 보이는 complaint 가 계속 나온다. 여기서 mask 는 focus signal 이지 deterministic layer editor 가 아니다.
핵심 요약
- one-shot mask edit 라면 먼저 direct
client.images.edit()또는POST /v1/images/edits로 시작한다. - prompt 를 바꾸기 전에 mask 자체를 본다: same format, same dimensions,
50 MB미만, real alpha channel. - prompt 는 빈 구역 설명이 아니라 최종 전체 이미지 설명이어야 한다.
- face, logo, product detail preservation 이 중요할 때만
input_fidelity="high"를 켠다. - mental model 은 strict local patch 가 아니라 constrained semantic rewrite 에 더 가깝다.
가장 안전한 OpenAI mask-first route 부터 시작하기
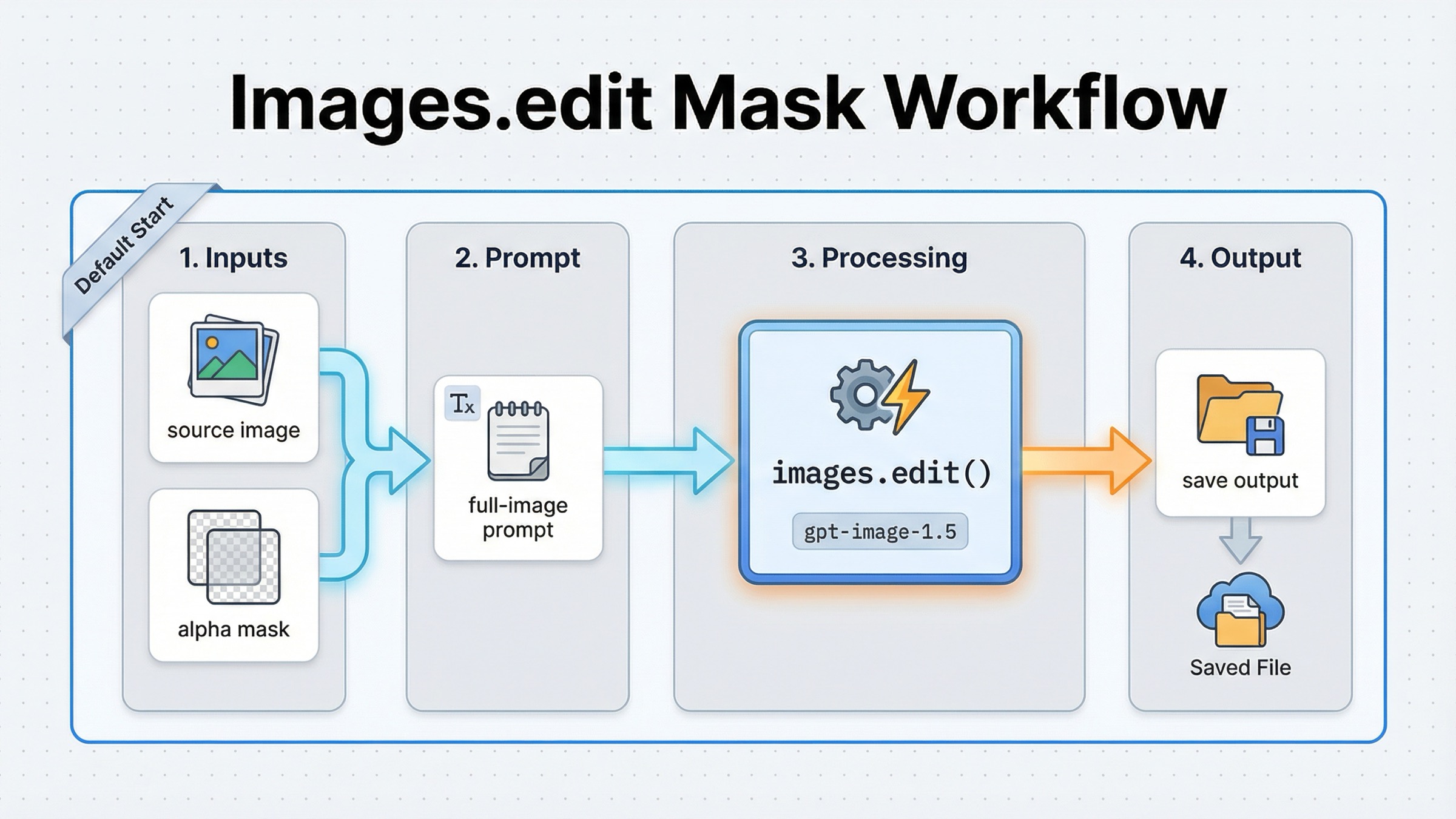
당장 필요한 일이 “이 이미지의 이 영역을 수정하는 것”이라면 굳이 conversation wrapper 를 먼저 가져올 이유가 없다. current OpenAI docs 가 보여 주는 가장 짧고 안정적인 path 는 여전히 direct Images API 다. base image, mask, final-image prompt, base64 output, save step 이 전부다.
JavaScript current shape 는 다음과 같다.
jsimport fs from "fs"; import OpenAI, { toFile } from "openai"; const client = new OpenAI(); const result = await client.images.edit({ model: "gpt-image-1.5", image: await toFile(fs.createReadStream("sunlit_lounge.png"), null, { type: "image/png", }), mask: await toFile(fs.createReadStream("mask.png"), null, { type: "image/png", }), prompt: "A sunlit indoor lounge area with a pool containing a flamingo. Preserve the room, lighting, reflections, and camera angle.", input_fidelity: "high", size: "1024x1024", quality: "medium", }); const imageBase64 = result.data[0].b64_json; const imageBytes = Buffer.from(imageBase64, "base64"); fs.writeFileSync("lounge.png", imageBytes);
Python 도 같다.
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.edit( model="gpt-image-1.5", image=open("sunlit_lounge.png", "rb"), mask=open("mask.png", "rb"), prompt=( "A sunlit indoor lounge area with a pool containing a flamingo. " "Preserve the room, lighting, reflections, and camera angle." ), input_fidelity="high", size="1024x1024", quality="medium", ) image_base64 = result.data[0].b64_json image_bytes = base64.b64decode(image_base64) with open("lounge.png", "wb") as f: f.write(image_bytes)
raw HTTP 로 보면 current multipart path 는 이렇게 간다.
bashcurl -s -X POST "https://api.openai.com/v1/images/edits" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "mask=@mask.png" \ -F "image[]=@sunlit_lounge.png" \ -F 'prompt=A sunlit indoor lounge area with a pool containing a flamingo'
이 route 가 좋은 이유는 failure surface 가 작기 때문이다. 문제를 account access, mask validity, prompt scope, output handling 중 어디서 봐야 하는지 금방 좁힐 수 있다. 첫 성공 조건을 boring 하게 만드는 것이 이 topic 에서는 오히려 강점이다.
실무에서는 이 첫 성공이 특히 중요하다. 팀이 처음부터 Responses, 여러 input images, 복잡한 preservation 요구, 후처리까지 한 번에 올리면 결국 어떤 층이 실패했는지 분리하기가 훨씬 어려워진다. 반대로 direct route 로 한 번 통과시키면, 그다음부터는 “mask 가 문제인가, prompt 가 문제인가, access 가 문제인가”를 차례로 좁혀 갈 수 있다. 이 keyword 에서 route 를 먼저 고르는 이유가 바로 여기에 있다.
그리고 current /v1/images/edits 는 multipart-only 가 아니다. JSON 으로 image_url 과 file_id 를 쓰는 route 도 있으므로, assets 가 이미 업로드돼 있다는 이유만으로 바로 Responses 로 넘어갈 필요는 줄어들었다.
API 가 실제로 받는 mask 부터 만들기
이 keyword 에서 제일 흔한 wasted work 는 mask 가 invalid 인데 prompt tuning 부터 하는 것이다. current mask requirements 는 짧지만 hard requirement 들이다.
- base image 와 mask 는 같은 format
- base image 와 mask 는 같은 pixel dimensions
- payload 는
50 MB미만 - mask 는 alpha channel 을 가져야 한다
특히 놓치기 쉬운 것은 alpha 다. 겉보기에는 흑백 mask 같아 보여도 실제로는 opaque bitmap 인 경우가 많다. OpenAI 가 black-and-white image 에 alpha 를 추가하는 예제를 따로 넣은 이유도 그 혼동이 계속되기 때문이다.
하지만 mechanical validity 와 strict behavior 는 다르다. docs 는 transparent area 가 replace region 이라고 말하면서도, GPT Image masking 이 exact shape 를 완전히 따르지 않을 수 있다고 같이 말한다. 결국 valid mask 와 strict patch behavior 는 동의어가 아니다.
실무에서는 다음 순서가 가장 안전하다.
- export 전에 base image 와 mask 를 같은 최종 크기로 맞춘다
- mask 는 RGBA PNG 로 저장한다
- 바꾸려는 영역이 실제로 transparent 인지 확인한다
- mask 영역은 가능한 한 좁게 유지한다
multi-image edit 에서는 또 하나의 current rule 이 중요하다. mask 는 first input image 에 적용된다. 그래서 첫 번째 이미지는 base scene 으로 두고, 뒤의 이미지는 reference 로 보는 편이 맞다.
Prompt 는 빈 부분이 아니라 final image 전체를 써야 한다
current OpenAI docs 에서 이 query 에 가장 중요한 문장은 “describe the full new image, not only the erased area” 다. 이를 놓치면 mask 가 맞아도 output 이 이상해진다.
GPT Image 는 단순히 구멍을 메우는 것이 아니라, 새 final image 를 다시 만들어 낸다. 따라서 prompt 는 최소한 세 가지를 동시에 해야 한다.
- 무엇을 바꾸는지
- 무엇을 유지해야 하는지
- 최종 scene 이 어떻게 보여야 하는지
약한 prompt:
textPut a flamingo in the pool.
더 좋은 prompt:
textA sunlit indoor lounge area with a pool containing a flamingo. Preserve the pink room walls, the pool tile pattern, the reflections, the furniture, and the camera angle. Do not redesign the rest of the room.
label, logo, packaging 같은 preservation-heavy job 에서는 constraint 를 더 강하게 적어야 한다.
textReplace only the blank label area on the bottle with a clean gold logo. Preserve the bottle shape, cap, glass reflections, lighting, shadows, background, and camera framing. Do not change any other packaging detail.
이 점에서는 GPT Image 1.5 prompting guide 가 얇은 third-party tutorial 보다 낫다. 핵심은 더 긴 prompt 가 아니라, change list 와 preserve list 를 분리하고 다음 turn 에서는 single-change iteration 으로 가는 것이다.
output 이 거의 맞으면 다음 prompt 는 짧아도 된다. “keep everything the same, but enlarge the logo slightly” 같은 한 변수 수정이 전체 재작성보다 drift 를 덜 만든다.
언제 input_fidelity=high 가 실제로 결과를 바꾸는가
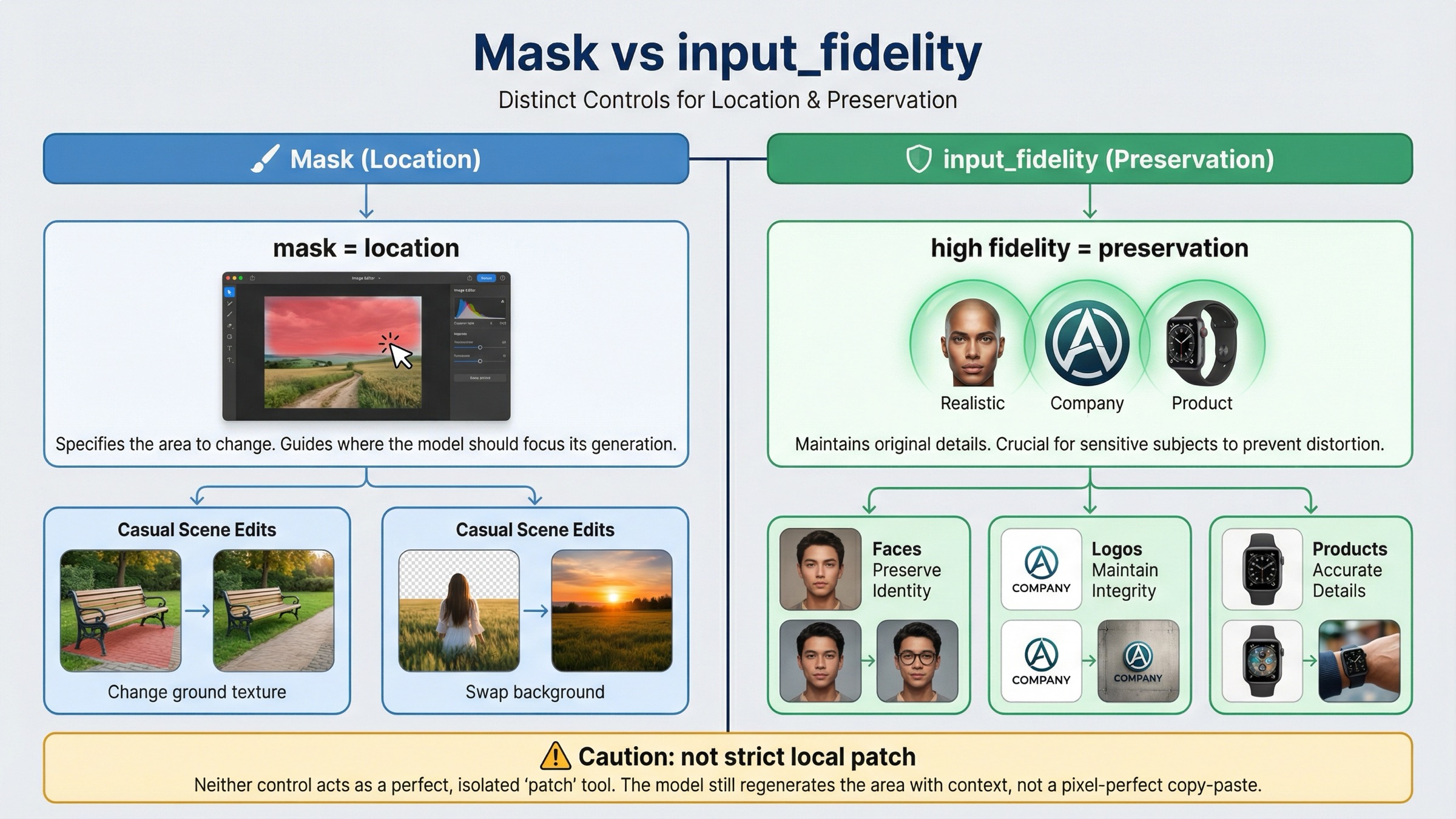
Mask 와 input_fidelity 는 다른 문제를 푼다. Mask 는 어디를 바꿀지, input_fidelity 는 입력 이미지의 디테일을 얼마나 강하게 보존할지 를 담당한다.
current input fidelity section 은 faces 와 logos 에 high 가 특히 유용하다고 말한다. gpt-image-1 과 gpt-image-1-mini 는 first input image 가 더 강하게 preserve 되고, gpt-image-1.5 는 처음 5 개 input images 까지 higher fidelity preservation 이 적용된다. default 는 low 다.
실전 split 은 아래 표로 충분하다.
| 상황 | mask 만으로 충분한 경우가 많은가 | input_fidelity="high" 를 추가할까 | 이유 |
|---|---|---|---|
| casual scene 의 simple object replacement | 대체로 yes | 보통 no | 위치 문제가 더 크고 preservation cost 가 아깝다 |
| face 근처 edit | case by case | 대체로 yes | identity drift 비용이 크다 |
| logo 를 packaging / clothing / signage 에 넣기 | 드묾 | yes | mask 는 위치만 주고 logo preservation 은 별도다 |
| branded product hero shot | 드묾 | yes | geometry, reflections, recognizability 가 중요하다 |
| strict local patch 기대 | no | high 만으로는 부족 | fidelity 는 도와주지만 deterministic surgery 는 아니다 |
즉, “mask 는 맞는데 face 나 logo 가 drift 한다”는 보통 preservation problem 이다. high 는 image input token cost 를 올리므로 무조건 켤 필요는 없지만, drift 비용이 큰 workflow 에서는 prompt wording 보다 먼저 검토할 가치가 있다.
더 넓은 routing context 가 필요하면 OpenAI image generation API models 를 참고해도 좋지만, 이 query 에서는 mask = 위치, fidelity = 보존 압력 으로 이해하면 충분하다.
왜 masked edit 는 예상보다 넓게 다시 써지는가
OpenAI docs 는 이 점에서 꽤 솔직하다. mask section 은 transparent region 을 replace area 라고 설명하면서도, GPT Image masking 이 exact shape 를 완전히 따르지 않을 수 있다고 적는다. practical rule 로 바꾸면, current masked edit 는 constrained semantic rewrite 이지 strict layer patch 가 아니다.
커뮤니티에서는 2025년 4월 27일 전후부터 valid mask 인데도 scene 이 넓게 바뀐다는 complaint 가 이어졌다. 여기서 중요한 것은 “endpoint 가 고장났다”로 바로 가지 않는 것이다. 많은 경우 기대하는 behavior 가 current model behavior 보다 더 strict 하다.
overreach 의 흔한 원인은 네 가지다.
- prompt 가 inserted object 만 설명하고 나머지 scene 을 underspecify 한다
- face, logo, packaging 같은 high-salience details 에
input_fidelity="high"를 쓰지 않았다 - mask area 가 너무 넓어 주변 context 재해석이 필요하다
- 기대가 old-style inpainting 에 머물러 있다
fix 는 mask 를 버리는 것이 아니라 expectation 과 workflow 를 조정하는 것이다.
- 가능하면 edit scope 를 줄인다
- preserve list 를 명시한다
- preservation-sensitive 한 case 에만 high fidelity 를 쓴다
- truly local reliability 가 필요하면 crop / segmentation 을 먼저 넣는다
여기서 중요한 것은 “모델이 나쁘다”가 아니라 “지금 요구하는 제어 수준이 current model 이 잘하는 범위 안에 있는가”를 먼저 판단하는 일이다. 예를 들어 제품 컷의 로고 위치, 병 라벨, 인물 얼굴처럼 drift 비용이 큰 자산이라면, 애초에 한 번의 큰 edit 로 끝내려 하지 말고 더 작은 단계로 쪼개는 편이 안정적이다. mask 는 여전히 유용하지만, 그것만으로 모든 workflow constraint 를 해결해 준다고 기대하면 다시 같은 실패로 돌아온다.
business rule 이 “이 픽셀들만 바꾸고 나머지는 절대 건드리지 말 것”이라면, 그건 prompt tuning 보다 workflow design 문제에 가깝다. 이 경계를 빨리 인정하는 것이 더 중요하다.
Images API vs Responses for mask-heavy workflow
Responses 는 useful 하지만, 많은 mask-first workflow 에서는 너무 이르다. current image generation guide 와 tool options 를 같이 보면, gpt-image-1.5 나 chatgpt-image-latest 를 Responses 에서 쓸 때 action 을 auto / generate / edit 로 둘 수 있고, OpenAI 는 default auto 를 권장한다.
이 힌트로 route split 은 꽤 단순해진다.
- single edit request 로 끝나면 direct Images API
- multi-turn context 와 broader assistant chain 이 필요하면 Responses
- uploaded assets 재사용만 필요하면 JSON
/v1/images/edits도 가능
즉 “이미 files 를 올려놨다”는 이유만으로 Responses 로 넘어갈 필요는 예전보다 더 적다. 실제로 bigger orchestration 이 product requirement 인지가 핵심이다.
더 넓은 surface comparison 이 필요하면 OpenAI Image API 튜토리얼 이 다음 읽을거리지만, exact mask query 의 기본 답은 여전히 가장 짧은 direct route 로 시작하라 는 것이다.
Troubleshooting: mask 가 여전히 실패하거나 너무 넓게 먹는 이유
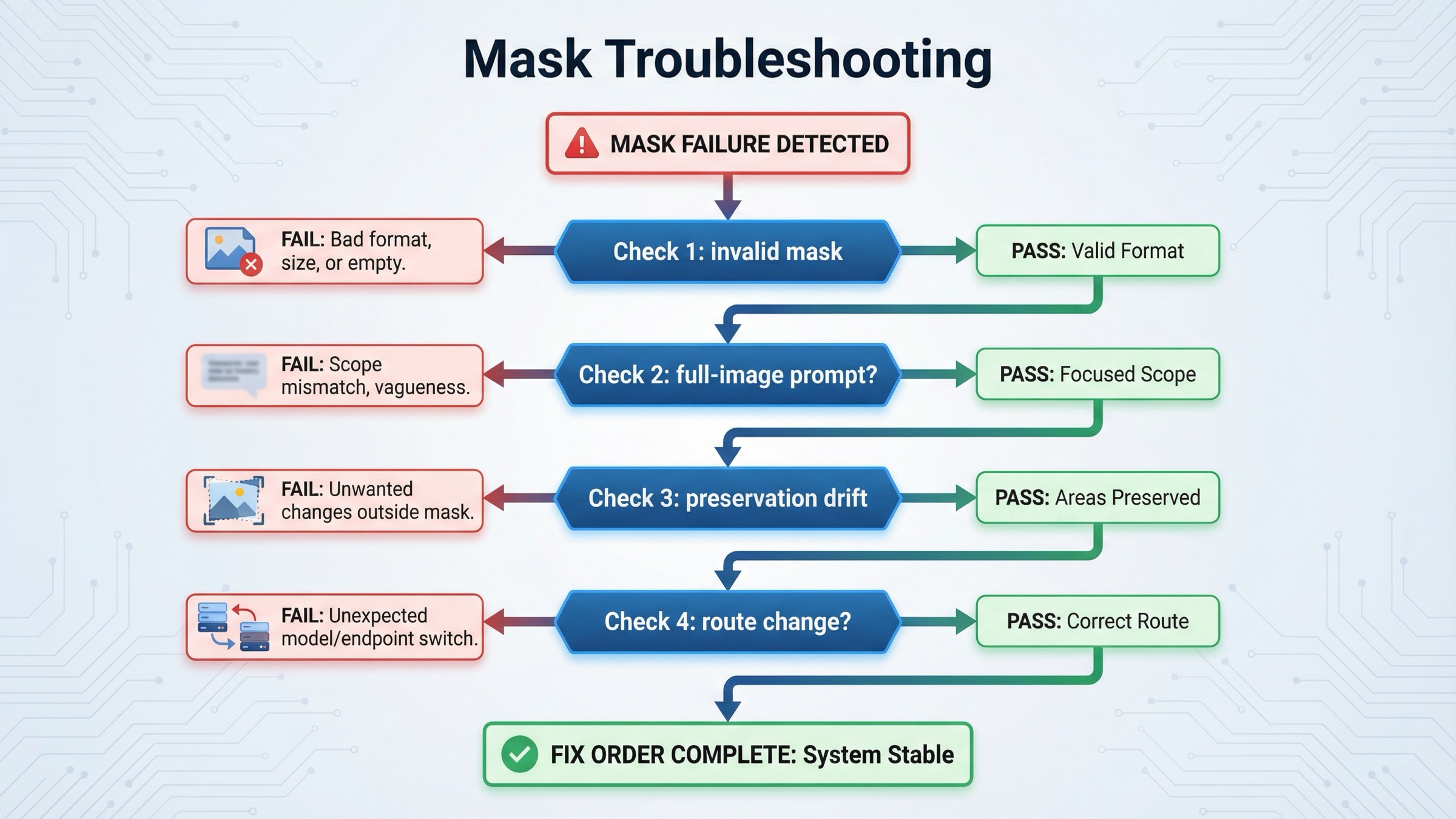
가장 시간을 덜 낭비하는 진단 순서는 이렇다.
-
API 가 mask 를 거절하거나 무시하는 것처럼 보인다.
먼저 format, dimensions, payload size, alpha 를 확인한다. 여기서 막히면 prompt 를 만져도 의미가 없다. -
수정 위치는 맞는데 scene 전체가 달라진다.
prompt 가 change 만 설명하고 preserved scene 을 충분히 설명하지 않았을 가능성이 높다. full final-image description 으로 다시 쓰고 preserve list 를 추가한다. -
변경이 mask 밖으로 spill 된다.
GPT Image 에서는 드문 일이 아니다. mask 를 더 좁히고, 한 번에 바꾸는 양을 줄이고, preserve wording 을 더 구체화한다. -
face, logo, branded object 가 계속 drift 한다.
이건 location 문제가 아니라 preservation 문제다.input_fidelity="high"를 켜고 must-keep details 를 prompt 에 적는다. -
여러 번의 iteration 과 stored asset references 가 필요하다.
이 단계에서 Responses 나 JSON/v1/images/edits를 검토하면 늦지 않다. -
진짜 pixel-local reliability 가 필요하다.
기대 자체가 current model boundary 를 넘는지 확인한다. 넘는다면 crop, segmentation, preprocessing 이 실제 fix 다.
이 triage order 를 처음부터 갖고 있다는 점이 이 페이지가 generic edit tutorial 보다 낫게 만드는 부분이다. 많은 페이지는 한 조각만 설명하지만, 사용자는 실제로 순서가 필요하다.
FAQ
transparent 한 mask area 라면 그 exact pixels 만 바뀌나요?
아니다. current docs 는 transparent region 을 replace area 로 설명하지만, GPT Image masking 이 exact shape 를 완전히 따르는 것은 보장하지 않는다. strict local surgery 가 아니라 constrained rewrite 로 봐야 한다.
mask edits 는 images.edit() 보다 Responses 로 시작하는 편이 맞나요?
default 로는 아니다. one-shot edits 는 direct Images API 가 먼저다. Responses 는 multi-turn conversation 이나 broader assistant workflow 안에 edit 가 들어갈 때 쓰면 된다.
mask 가 맞는데도 logo 나 face 가 drift 하는 이유는 뭔가요?
Mask 는 location control 이고 preservation control 이 아니기 때문이다. 이런 case 는 input_fidelity="high" 와 explicit preserve instructions 를 먼저 써야 한다.
마지막 권장안
current OpenAI mask edits 의 default route 는 단순하다. gpt-image-1.5 의 direct Images API 로 시작하고, mask 의 mechanical validity 를 먼저 고정하고, prompt 를 final image 전체 설명으로 쓰고, preservation 이 중요할 때만 input_fidelity="high" 를 추가한다. 이 조합이 더 큰 framework 로 먼저 들어가는 것보다 실제 failure 를 더 많이 줄여 준다.
결과가 여전히 기대보다 넓게 바뀐다면, 먼저 mask upload failure 를 의심하지 말고 product expectation 이 current GPT Image masking behavior 보다 더 strict 한지 확인하라. 더 넓은 edit route 는 OpenAI image editing API guide, rollout 전 access / capability checks 는 OpenAI image generation API verification guide 가 다음 단계다.