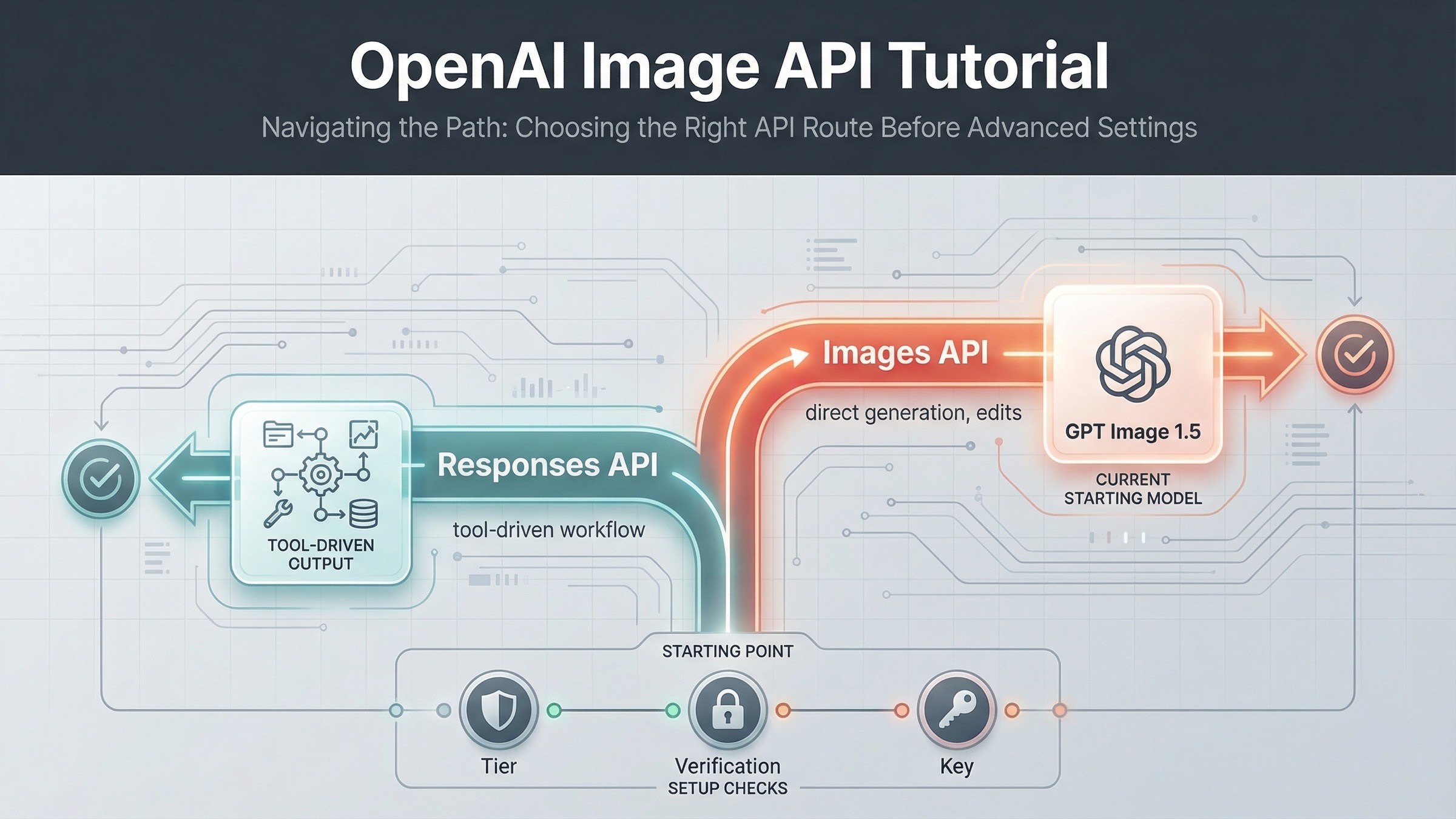
2026년 3월 22일 기준으로 가장 안전한 기본 경로는 이렇습니다. 직접 이미지를 만들거나 편집하려면 먼저 Images API 를 쓰고, 이미지 생성이 더 큰 멀티모달 workflow 안의 한 단계일 때만 Responses API 로 넘어갑니다. 이 판단을 먼저 두면 불필요한 우회를 대부분 줄일 수 있습니다.
이 키워드가 계속 헷갈리는 이유는 OpenAI 가 답을 한 페이지에 모아두지 않았기 때문입니다. 메인 image generation guide는 direct generation 과 edits 를 설명합니다. 넓은 images and vision guide는 Responses API 안의 image_generation tool 을 보여줍니다. 현재 models catalog는 GPT Image 1.5 를 현재 flagship, gpt-image-1-mini 를 budget lane, chatgpt-image-latest 를 ChatGPT alias, DALL-E 3 를 deprecated 로 정리합니다. 한 페이지만 읽으면 route 전체가 보이지 않습니다.
그래서 많은 튜토리얼이 코드 예제는 맞아도 순서가 틀립니다. 오래된 DALL-E 전제를 들고 오거나, usage tier 와 organization verification 을 확인하기 전에 SDK 코드만 만집니다. 이 글의 목적은 syntax 를 다시 적는 것이 아니라, 올바른 순서를 잡아주는 것입니다.
핵심 요약
- 직접 생성, 단일 편집, 가장 짧은 온보딩이면 Images API.
- 이미지 생성이 assistant workflow 안의 한 tool이면 Responses API.
- 기본 current model 은
gpt-image-1.5. cost-first 일 때만gpt-image-1-mini를 별도로 비교한다. - 예제가 맞아 보이는데도 실패하면 tier, verification, active org, API key 부터 확인한다.
먼저 API 경로를 고른다: Images API vs Responses API
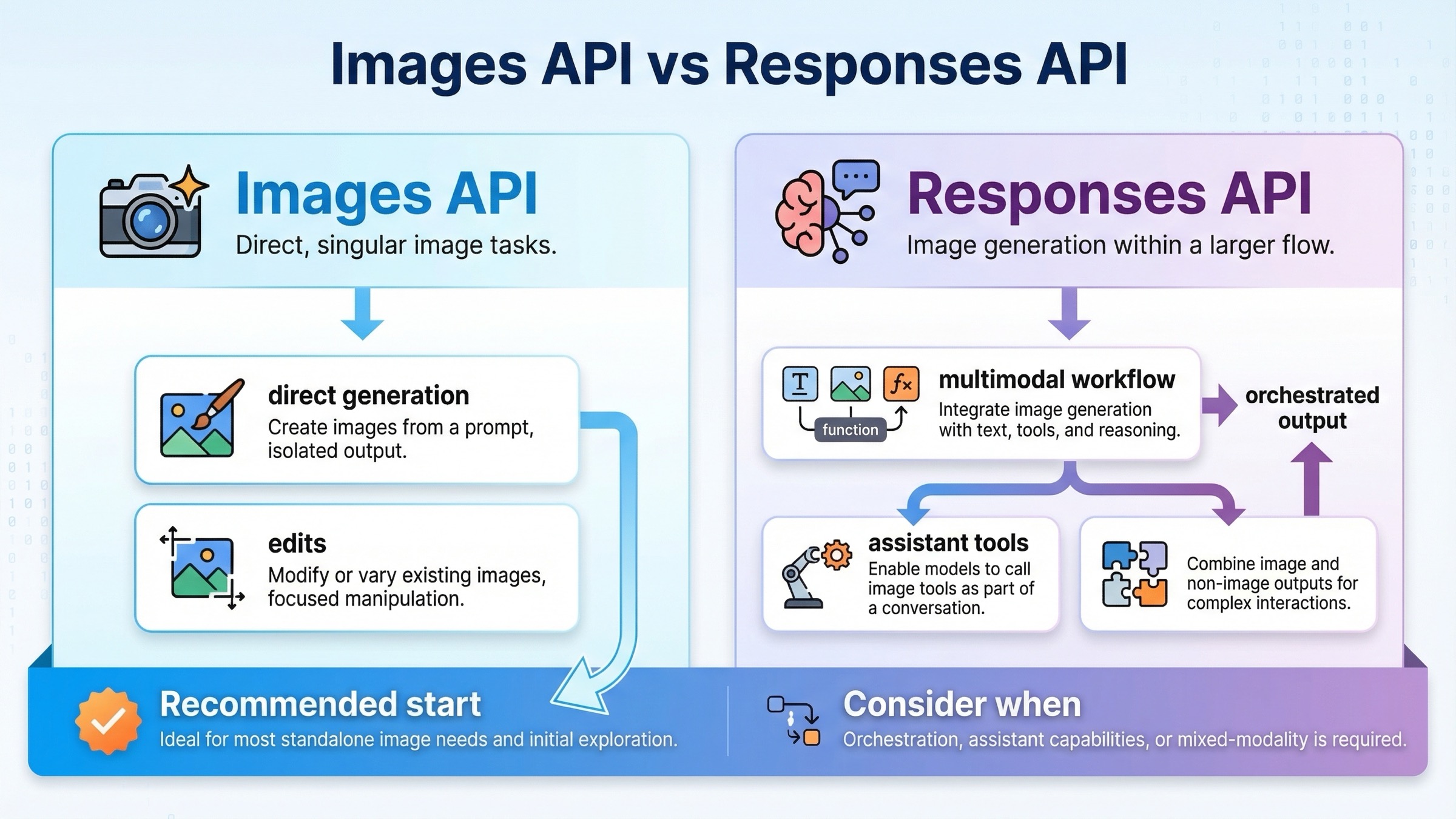
이 주제에서는 parameter 보다 먼저 API surface 를 고르는 것이 중요합니다.
| 상황 | 먼저 선택할 경로 | 이유 |
|---|---|---|
| 한 번의 request 로 이미지를 만들고 저장하고 싶다 | Images API | 가장 직접적이고 튜토리얼 시작점으로도 가장 명확하다 |
| 기존 이미지를 편집하고 싶다 | Images API | edit, mask, input_fidelity 설명이 여기에 모여 있다 |
| text, tools, image 를 한 flow 로 묶고 싶다 | Responses API | image generation 을 tool 로 넣는 편이 자연스럽다 |
| 팀에서 먼저 working sample 을 빨리 통과시키고 싶다 | Images API | 추상화가 적어서 실패 원인 구분이 쉽다 |
| assistant / agent 안에서 이미지를 하나의 출력으로 다루고 싶다 | Responses API | 더 큰 orchestration 에 잘 맞는다 |
실무 규칙은 간단합니다. 이미지 생성 자체가 기능이라면 client.images.generate() / client.images.edit() 로 시작하고, 이미지 생성이 더 큰 흐름의 일부일 때만 client.responses.create() 를 사용합니다.
공식 문서는 이 둘을 모두 보여주지만, tutorial 의 첫 화면에서는 한쪽을 기본으로 추천해야 합니다. 그렇지 않으면 독자가 스스로 페이지를 이어 붙여야 하고, 바로 그 지점에서 오래된 예제와 최신 문서를 섞기 쉽습니다.
코드보다 먼저 access 와 model ID 를 확인한다
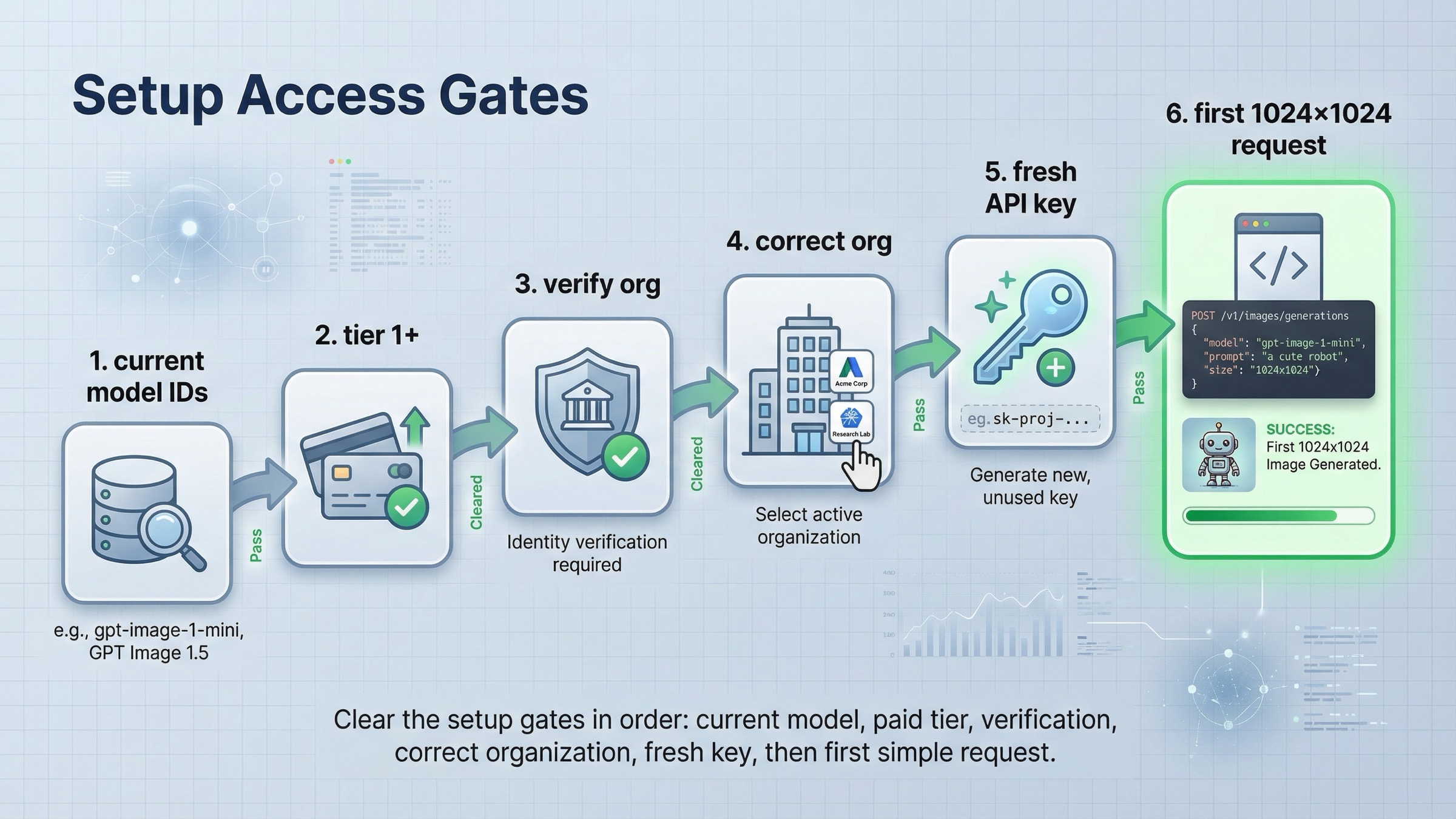
이 키워드에서 시간을 가장 많이 잃는 지점은 코드가 틀렸다고 생각하고 setup gate 를 나중에 보는 것입니다.
먼저 current model IDs 부터 정리합니다.
| 모델 | 현재 위치 | 언제 쓰나 |
|---|---|---|
| GPT Image 1.5 | current flagship | 새 프로젝트의 기본 경로, quality-first, edits, 더 안정적인 prompt following |
gpt-image-1-mini | budget lane | cheap tests, prototypes, volume-heavy runs |
chatgpt-image-latest | ChatGPT alias | ChatGPT 의 current image snapshot 을 의도적으로 맞추고 싶을 때 |
| GPT Image 1 | previous model | legacy compatibility 나 migration reference |
| DALL-E 3 / DALL-E 2 | deprecated | fresh tutorial 의 기본값으로 두지 않는다 |
이 정리가 필요한 이유는 검색 결과에 여전히 오래된 페이지가 섞여 있기 때문입니다. GPT Image 1 이나 DALL-E 3 를 current default 로 전제하면, 시작부터 route 가 어긋납니다.
그 다음은 access 입니다. 현재 API Model Availability by Usage Tier and Verification Status는 GPT-image-1 과 GPT-image-1-mini 가 tiers 1 through 5 의 API users 에게 열려 있고, 일부 access 는 organization verification 에 달려 있다고 설명합니다. 현재 GPT Image 1.5 page 역시 Free not supported 와 Tier 1 = 100,000 TPM / 5 IPM 을 보여줍니다. 즉, 코드가 맞아도 request 이전에 막힐 수 있습니다.
verification 이 의심되면 prompt 를 고치기 전에 current API Organization Verification 를 확인하세요. OpenAI 는 올바른 organization 확인, 최대 30분 대기, 새 API key 생성, session refresh 순서를 권장합니다. 이건 code branch 가 아니라 access branch 입니다.
SDK 설치는 간단합니다.
bashnpm install openai
bashpip install openai
그 다음 OPENAI_API_KEY 를 설정하고 첫 request 는 최대한 boring 하게 유지합니다. 1024x1024, 짧은 prompt, single image, edit 없음. current guide 도 square image 가 default 이고 가장 빠른 starting point 라고 말합니다.
Images API 로 첫 번째 working request 를 통과시키기
direct tutorial 로 시작할 때는 Images API 가 가장 이해하기 쉽습니다. model choice, output settings, save flow 가 한 줄로 연결되기 때문입니다.
JavaScript 최소 예제는 다음과 같습니다.
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.generate({ model: "gpt-image-1.5", prompt: "Create a clean editorial illustration of a robot camera operator in a bright studio", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; const imageBytes = Buffer.from(imageBase64, "base64"); fs.writeFileSync("openai-image-api-demo.jpg", imageBytes);
Python 도 거의 같습니다.
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.generate( model="gpt-image-1.5", prompt="Create a clean editorial illustration of a robot camera operator in a bright studio", size="1024x1024", quality="medium", output_format="jpeg", output_compression=80, ) image_base64 = result.data[0].b64_json image_bytes = base64.b64decode(image_base64) with open("openai-image-api-demo.jpg", "wb") as f: f.write(image_bytes)
이 경로가 좋은 이유는 current flagship model 을 명시하고, 안전한 기본값으로 시작하며, base64 output 처리까지 한 번에 보여주기 때문입니다.
기본 생성이 성공한 뒤에는 edit 로 넘어갈 수 있습니다. current guide 는 multi-image edit 와 input_fidelity 도 보여줍니다. 입력 이미지를 더 가깝게 유지한 편집이 필요하면 input_fidelity: "high" 가 현재 가장 실용적인 옵션 중 하나입니다.
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1.5", image: [ fs.createReadStream("woman.jpg"), fs.createReadStream("logo.png"), ], prompt: "Add the logo to the woman's jacket as if stitched into the fabric.", input_fidelity: "high", }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync( "woman-with-logo.png", Buffer.from(imageBase64, "base64") );
핵심은 simple generation 이 먼저 안정적으로 되어야 edit 로 넘어간다는 점입니다. 첫 request 에 transparency, multiple inputs, large aspect ratio 까지 동시에 얹으면 어디서 실패하는지 읽기 어렵습니다.
Responses API 가 더 맞는 순간
Responses API 는 "더 최신이니까" 선택하는 것이 아니라, 이미지 생성이 larger reasoning flow 의 한 단계일 때 선택하는 편이 맞습니다. 그래서 current docs 도 responses.create() 안에 image_generation tool 을 넣는 예제를 보여줍니다.
JavaScript 예제:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const response = await client.responses.create({ model: "gpt-5", input: "Draw a transparent sticker-style icon of a paper airplane for a travel app", tools: [ { type: "image_generation", background: "transparent", quality: "high", }, ], }); const imageBase64 = response.output .filter((item) => item.type === "image_generation_call") .map((item) => item.result)[0]; fs.writeFileSync("paper-airplane.png", Buffer.from(imageBase64, "base64"));
Python 예제:
pythonfrom openai import OpenAI import base64 client = OpenAI() response = client.responses.create( model="gpt-4.1-mini", input="Generate a product hero image of a ceramic mug on a white background", tools=[{"type": "image_generation"}], ) image_data = [ output.result for output in response.output if output.type == "image_generation_call" ] if image_data: with open("mug.png", "wb") as f: f.write(base64.b64decode(image_data[0]))
이 route 가 좋은 경우는 분명합니다.
- image generation 이 larger assistant flow 안에 있을 때
- text, tools, images 를 하나의 응답 구조 안에 넣고 싶을 때
- 이미지가 독립 기능이 아니라 workflow step 일 때
반대로 "한 장 만들고 저장"이 목표라면, Responses API 는 tutorial 의 시작점을 오히려 무겁게 만듭니다.
날짜 관점에서도 한 가지는 기억할 가치가 있습니다. OpenAI changelog 에 따르면 2025년 12월 19일에 gpt-image-1.5 와 chatgpt-image-latest 가 Responses API 의 image generation tool 지원에 추가되었습니다. 즉, launch 시점의 “coming soon” 문구를 current tutorial 에 그대로 가져오면 안 됩니다.
실제로 결과와 비용을 바꾸는 설정
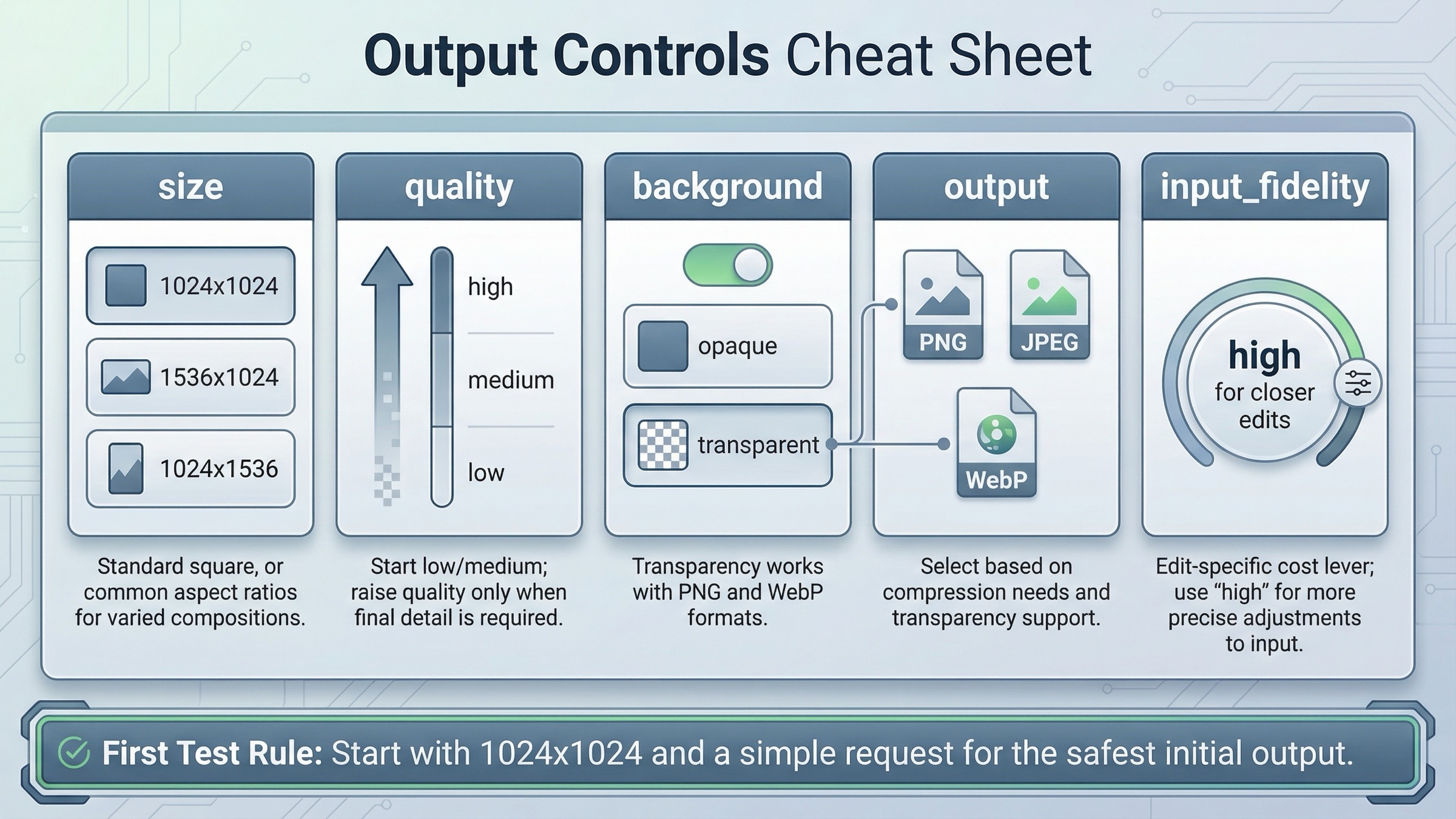
첫 request 가 통과한 다음에는 advanced option 을 전부 여는 것보다, 어떤 설정이 무엇을 바꾸는지 이해하는 편이 훨씬 중요합니다.
현재 guide 에서 기억할 가치가 큰 항목은 다음입니다.
sizequalitybackgroundoutput_formatoutput_compressioninput_fidelity
이걸 외울 때는 field name 보다 decision 으로 기억하는 편이 좋습니다.
Size 는 composition 과 cost 를 바꿉니다. 첫 테스트는 1024x1024 로 시작하는 것이 안전합니다. current guide 도 square image 가 default 이고 가장 빠르다고 설명합니다.
Quality 는 latency 와 spend 를 동시에 바꿉니다. current GPT Image 1.5 page 에서 1024x1024 low 는 $0.009, medium 은 $0.034, high 는 $0.133 입니다. prototype 단계에서 high 를 기본값으로 둘 이유는 약합니다.
Background 는 transparent asset 에서 의미가 큽니다. current docs 는 background: "transparent" 가 PNG 와 WebP 에서 동작한다고 적고 있습니다. 이걸 모르면 transparency issue 를 model quality 문제로 착각하기 쉽습니다.
Output format 과 compression 은 전달 형식을 바꿉니다. Image API 는 base64 image data 를 반환하고 default format 은 PNG 입니다. 필요하면 JPEG 와 WebP 도 요청할 수 있습니다. alpha channel 이 중요하지 않다면 JPEG 가 더 실용적인 경우도 많습니다.
input_fidelity 는 edit-specific lever 입니다. closer edit 가 필요할 때 중요하지만, first request 에 넣기에는 정보량이 많아서 tutorial 후반에 다루는 편이 자연스럽습니다.
운영 원칙은 하나입니다. 한 번에 하나의 변수만 바꾼다. model, size, quality, background, edit inputs 를 동시에 바꾸면 어떤 선택이 결과를 바꿨는지 읽기 어렵습니다.
이제 관심사가 "어떻게 호출하나" 보다 "얼마나 드나" 로 옮겨갔다면, 다음은 한국어판 OpenAI Image Generation API 가격 가이드 가 더 도움이 됩니다.
많은 튜토리얼이 먼저 설명하지 않는 failure branch
이 주제에서 시간을 가장 많이 낭비하게 만드는 것은 syntax error 가 아니라 diagnosis order 입니다. happy path 만 보여주는 튜토리얼은 실패했을 때 어디부터 의심해야 하는지 남기지 않습니다.
먼저 403 verification error 입니다. 에러가 organization verification 을 명시하면 prompt 나 SDK version 보다 access branch 를 먼저 봐야 합니다. current help-center guidance 는 올바른 organization 확인, 최대 30분 대기, 새 API key 생성, session refresh 순서를 권장합니다. Community threads 에는 dashboard 는 verified 인데 Images Playground 는 막혀 있는 경우가 여전히 많습니다. 이건 code problem 이 아니라 context problem 입니다.
다음은 잔액이 있어 보이는데 429 가 나는 경우입니다. OpenAI Developer Community 에는 credits 를 넣고도 image models 에서 rate_limit_exceeded 를 본 사례가 여러 개 있습니다. 이때 봐야 할 것은 visible balance 가 아니라 usage tier 입니다.
그다음은 edit / mask 조건 입니다. current guide 는 edit image 와 mask 가 같은 format, 같은 size, 50MB 미만 이어야 한다고 설명합니다. 이걸 놓치면 edit path 가 랜덤하게 느껴집니다.
또 하나의 조용한 실패는 오래된 URL mental model 입니다. current GPT Image route 는 base64 image data 중심입니다. 예전 tutorial 처럼 hosted URL 을 전제로 downstream logic 를 만들면 request 가 성공해도 후처리가 엉킬 수 있습니다.
문제가 내 request 하나만의 문제가 아닌 것처럼 보이면 OpenAI Status 를 먼저 확인하세요. 2026년 3월 22일 기준 공개 status 는 정상입니다. 즉, 오늘의 local failure 는 global incident 보다 account / config 쪽을 먼저 보는 편이 합리적입니다.
verification 자체가 main blocker 라면, 다음은 한국어판 OpenAI Image API 검증 오류 해결 가이드 가 더 적합합니다.
프로덕션 전 체크리스트
첫 request 가 성공한 뒤에는 필요한 결정을 고정해야 합니다.
- route 를 고정한다. direct generation / edits 는 Images API, larger workflow inside image generation 은 Responses API.
- model 을 고정한다.
먼저 GPT Image 1.5, cost-first branch 로
gpt-image-1-mini를 별도 비교. - default output profile 을 정한다. size, quality, format 의 기본값부터 정한다.
- failure context 를 남긴다. active org, model ID, endpoint, failure type 을 기록한다.
- tutorial success 와 budget success 를 구분한다. 한 번 동작하는 것과 scale 에서 합리적인 것은 다르다.
다음 읽을거리도 분명합니다.
- OpenAI Image Generation API 가격 가이드
- OpenAI Image API 검증 오류 해결 가이드
- English fallback: How to get an OpenAI API key
- English fallback: OpenAI API key requirements
결국 좋은 current OpenAI Image API 튜토리얼은 code block 을 늘리는 글이 아니라, 올바른 API route 와 current model IDs, access gates 를 먼저 정리한 뒤 quality / latency / cost control 로 내려가는 글입니다. 이 순서만 맞으면 주제는 검색 결과보다 훨씬 단순해집니다.
FAQ
먼저 배워야 할 것은 Images API 인가요, Responses API 인가요?
직접 생성과 편집이라면 Images API 입니다. Responses API 는 image generation 이 assistant / agent workflow 의 한 단계일 때 더 자연스럽습니다.
fresh tutorial 의 기본 model 은 무엇인가요?
대부분의 경우 gpt-image-1.5 가 current default 입니다. cost 가 첫 질문이라면 그다음에 gpt-image-1-mini 를 비교하면 됩니다.
sample code 는 맞아 보이는데 왜 실패하나요?
가장 흔한 원인은 syntax 가 아니라 usage tier, organization verification, active org, 오래된 API key 입니다.
chatgpt-image-latest 는 언제 써야 하나요?
ChatGPT 의 current image snapshot 을 의도적으로 맞추고 싶을 때만 우선합니다. 장기적인 production tutorial 에서는 보통 gpt-image-1.5 가 더 깔끔합니다.