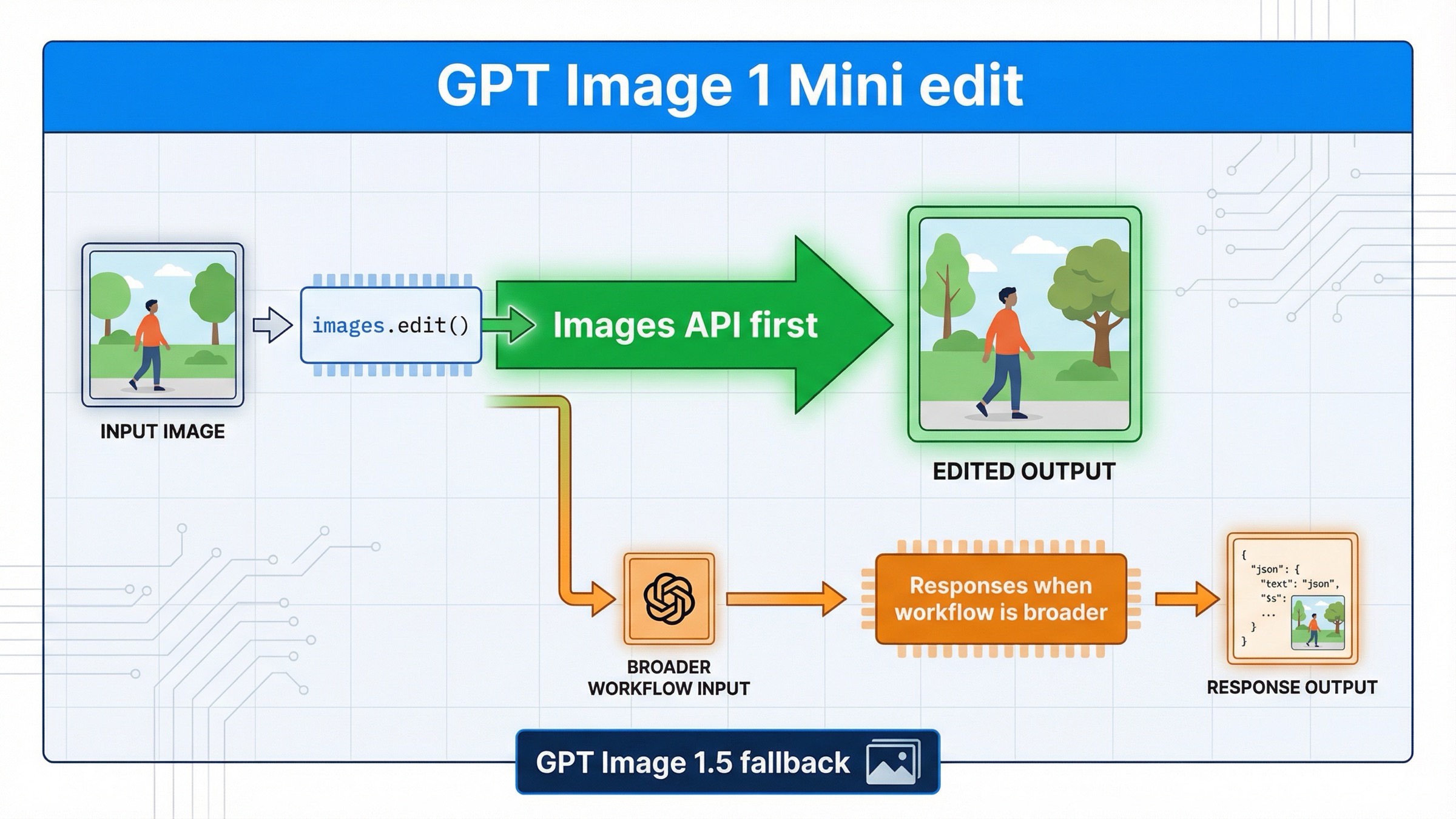
2026년 3월 29일 기준으로 gpt-image-1-mini 를 써서 이미지를 편집하려면, 가장 안전한 첫 선택은 Responses가 아니라 OpenAI Images API 직행 경로입니다. SDK에서는 client.images.edit(), raw HTTP 에서는 POST /v1/images/edits 를 먼저 쓰는 편이 맞습니다. Responses를 먼저 고민해야 하는 경우는 이미지 편집 그 자체가 핵심 기능이 아니라, assistant·conversation·multi-tool workflow 안의 한 단계일 때입니다.
이 결론을 따로 분리해서 설명할 가치가 있는 이유는, 현재 검색 결과와 공식 문서가 답을 여러 페이지에 나눠 놓고 있기 때문입니다. 현재 gpt-image-1-mini model page 에는 v1/images/edits 가 명시되어 있습니다. 최신 image generation guide 는 한 번의 prompt 로 한 번의 생성 또는 편집만 필요하다면 Image API 가 더 좋은 선택이라고 설명합니다. 반면 현재 image generation tool guide 에서 Responses 쪽 action 이 분명하게 문서화된 모델은 주로 gpt-image-1.5 와 chatgpt-image-latest 입니다. 이 셋을 같이 보면 평균적인 페이지보다 더 실용적인 규칙이 나옵니다. mini 의 direct edit 는 먼저 /v1/images/edits 로 시작하는 것이 맞습니다.
이 경로는 구현 관점에서도 유리합니다. 많은 개발자가 Responses 예제를 먼저 보고, 더 최신이고 범용적이니 더 맞는 추상화일 것이라 생각합니다. 하지만 gpt-image-1-mini edit 에서는 그 직감이 오히려 빗나가기 쉽습니다. direct route 가 docs 와 맞물리기 쉽고, 디버깅 범위가 작고, mini 특유의 한계도 더 명확하게 보입니다.
핵심 요약
- 작업이 "이 이미지를 편집하고 싶다" 라면 먼저
client.images.edit()또는POST /v1/images/edits. - 편집이 더 큰 assistant / multimodal workflow 의 일부라면 Responses 를 고려.
- 여러 input 유지력이나 더 안정적인 품질이 중요하면 GPT Image 1.5 도 빨리 비교.
- 코드를 갈아엎기 전에 유료 tier, 조직 verification, project 와 API key 소속을 먼저 확인.
| 상황 | 먼저 고를 기본값 | 이유 |
|---|---|---|
| 한 장 또는 몇 장의 이미지를 편집해서 저장하고 싶다 | images.edit() | mini 에서 가장 직접적이고 문서화가 명확한 경로이기 때문 |
| mask 나 reference image 를 같이 넣는 edit 요청 | images.edit() | 파일 입력, mask, 출력 처리 흐름이 더 분명함 |
| 이미지 편집이 긴 대화나 multi-tool workflow 의 일부 | Responses | 필요한 것은 편집 자체보다 바깥쪽 orchestration 임 |
| 여러 input 을 더 잘 보존하거나 브랜드 요소를 지켜야 한다 | GPT Image 1.5 + images.edit() | OpenAI 가 1.5 를 quality-first 분기로 제시하기 때문 |
direct mini edit 라면 먼저 /v1/images/edits
이 exact query 에서 가장 중요한 것은 복잡한 API 세계관이 아니라, 첫 성공 경로를 작게 유지하는 것입니다. 공식 docs 는 여기서 애매하게 말하지 않습니다. mini 모델 페이지는 v1/images/edits 를 적고 있고, image guide 는 한 번의 prompt 로 한 번의 생성이나 편집만 한다면 Image API 가 더 낫다고 설명합니다. "gpt-image-1-mini edit" 뒤에 있는 대부분의 실제 작업이 바로 이런 모양입니다.
그래서 첫 성공 목표는 일부러 단순해야 합니다.
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1-mini", image: [fs.createReadStream("room.png")], prompt: "Replace the blank wall art with a framed abstract poster. Preserve the room layout, lighting, furniture, and camera angle. Do not change anything else.", input_fidelity: "high", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync("room-edited.jpg", Buffer.from(imageBase64, "base64"));
raw HTTP 로 확인할 때는 이 endpoint 가 multipart form-data 이고 JSON 이 아니라는 점도 잊지 마세요.
bashcurl https://api.openai.com/v1/images/edits \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1-mini" \ -F "image[]=@room.png" \ -F 'prompt=Replace the blank wall art with a framed abstract poster. Preserve the room layout, lighting, furniture, and camera angle. Do not change anything else.' \ -F "input_fidelity=high" \ -F "size=1024x1024" \ -F "quality=medium"
왜 이 direct route 를 먼저 두는 편이 좋을까요?
첫째, 모델 선택과 API surface 가 깔끔하게 맞아떨어집니다. mini 가 지금 명시적으로 지원하는 endpoint 를 직접 호출하므로, 더 큰 orchestration layer 에 판단을 넘길 필요가 없습니다.
둘째, 디버깅 범위가 훨씬 좁아집니다. 요청이 실패하더라도 우선 access, 파일 형식, prompt, 출력 처리 중 어디가 문제인지 보면 되고, Responses 쪽 model·tool config·conversation state 를 한꺼번에 의심할 필요가 없습니다.
셋째, 이 페이지의 역할이 분명해집니다. 더 넓은 family-level 설명은 이미 OpenAI image editing API 가이드 에 있습니다. 이 글은 그보다 좁게, mini 로 edit 할 때 가장 먼저 무엇을 해야 하는가에만 집중합니다.
Responses 가 정말 도움이 되는 경우와, mini 에서 이 경계가 더 중요한 이유
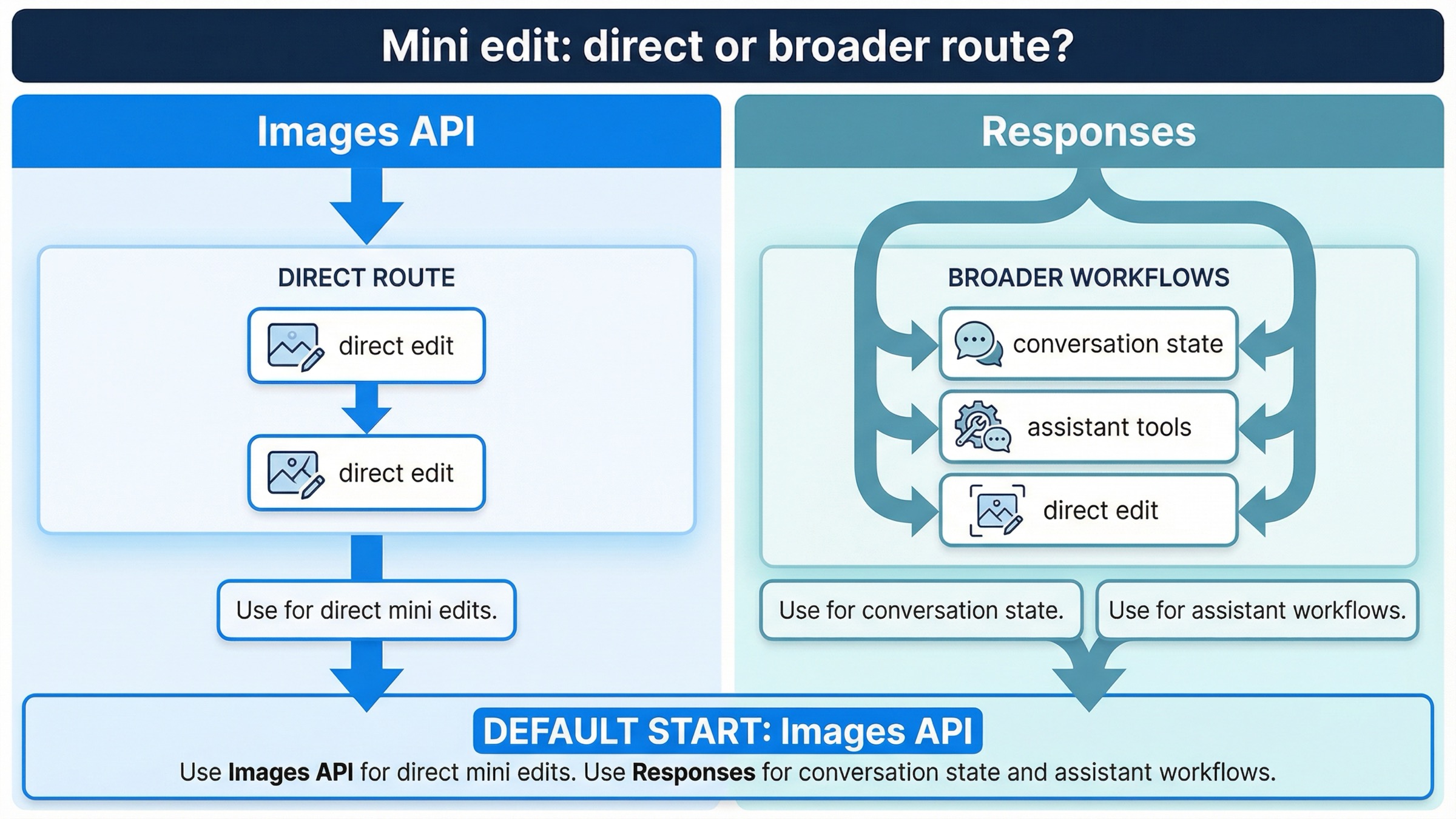
Responses 는 유용합니다. 다만 요구사항 전체가 "gpt-image-1-mini 로 이미지를 편집하고 싶다" 라면, 보통 첫 답은 아닙니다.
이유는 현재 image generation tool guide 를 보면 분명합니다. Responses 에서는 top-level model 이 gpt-4.1 이나 gpt-5 같은 텍스트 모델이어야 하고, GPT Image 계열은 top-level model 이 아니라 tool 쪽에서 동작합니다. 즉 Responses 를 고르는 순간, 여러분은 "mini 의 편집 endpoint" 보다 더 큰 workflow abstraction 을 고르고 있는 셈입니다.
이 차이는 mini 에서 특히 중요합니다. 현재 docs 에서 Responses 쪽 action 을 분명하게 설명하는 모델은 주로 gpt-image-1.5 와 chatgpt-image-latest 이고, mini 를 가장 명확한 Responses edit contract 로 전면에 내세우지는 않습니다. 여기서의 판단은 좁고 실무적입니다. mini edit 를 예측 가능하고 문서에 맞게, 그리고 가장 쉽게 디버깅하려면 direct Images API 가 더 명확한 계약면입니다.
Responses 가 더 맞는 경우는 보통 다음과 같습니다.
- previous response IDs 나 image generation call IDs 를 이용해 여러 단계의 편집을 이어갈 때
- reasoning, tools, image edit 가 섞인 assistant 를 만들 때
- 이미지 편집이 더 긴 대화 UX 안에서 돌아야 할 때
- 하나의 request 안에서 어떤 tool 을 쓸지 판단해야 할 때
기억할 규칙은 단순합니다.
- "이미지 편집 자체가 기능" 이면
images.edit()부터 - "이미지 편집이 더 큰 기능 안의 한 tool" 이면 Responses 검토
정말 궁금한 것이 mini 전체 API 경로라면 다음으로는 gpt-image-1-mini API 가이드 가 더 맞습니다. 이 페이지는 의도적으로 scope 를 좁혔습니다.
mini 에서의 mask, reference image, input_fidelity
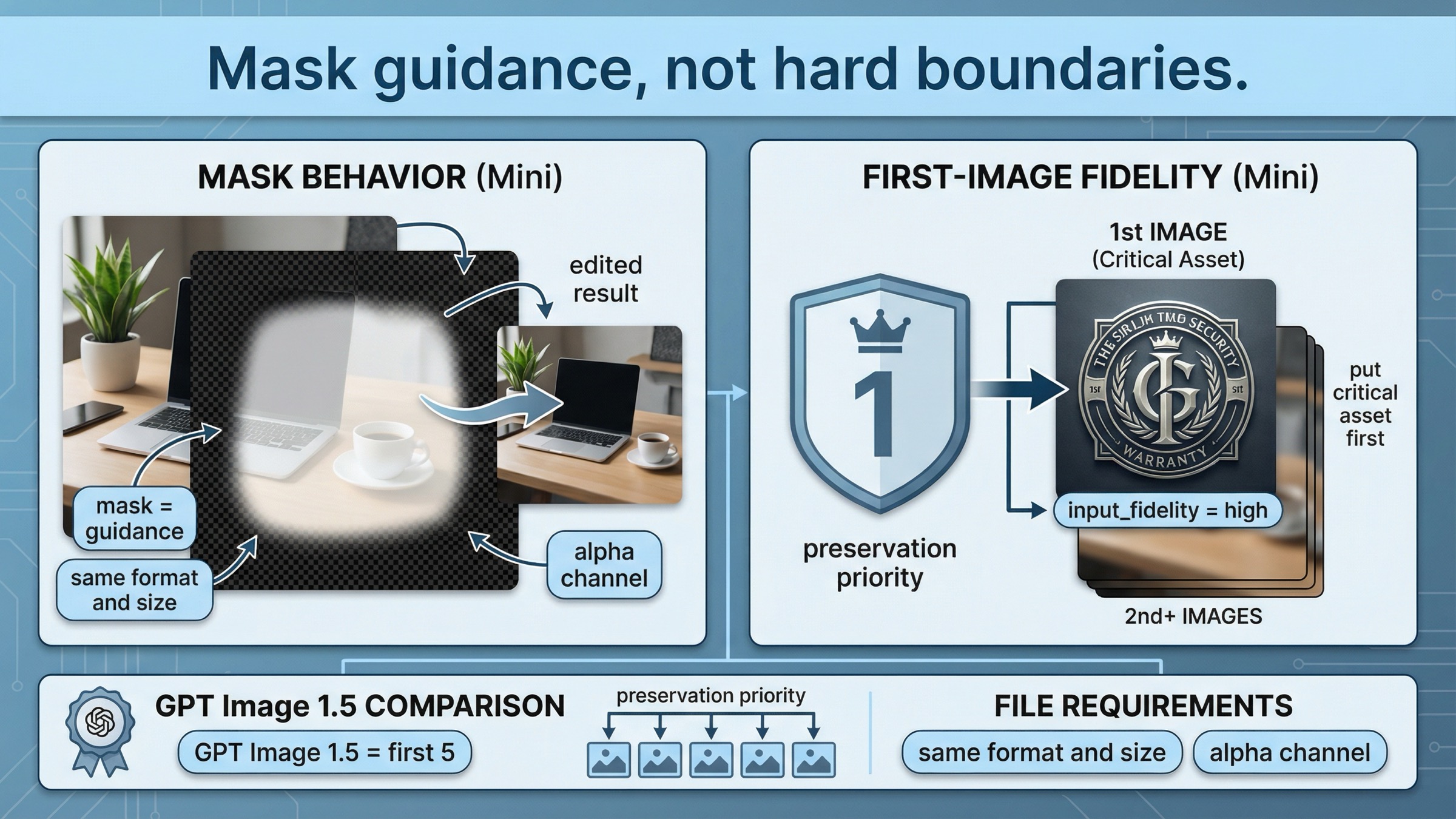
이 부분이야말로 이 글이 generic OpenAI image edit 페이지와 달라지는 핵심입니다. 많은 페이지가 여기서 mini-specific 행동을 놓칩니다.
현재 image generation guide 의 edit 섹션 은 이미지와 mask 가 같은 포맷, 같은 크기 여야 하고, 전체 크기는 50 MB 미만, mask 에는 alpha channel 이 필요하다고 설명합니다. 하지만 더 중요한 것은 GPT Image 의 mask editing 이 여전히 prompt-based 라는 점입니다. 즉 mask 는 편집 방향을 강하게 유도하지만, Photoshop 식의 픽셀 단위 hard boundary 를 보장하지는 않습니다.
그래서 mini 에서 mask 를 쓸 때는 mask 를 강한 힌트 로 봐야지, "딱 이 영역만 정확히 바꾸고 나머지는 절대 건드리지 않는다" 는 약속으로 보면 안 됩니다.
또 하나 중요한 mini-specific 규칙은 현재 input_fidelity 문서 에 있습니다. OpenAI 는 gpt-image-1 또는 gpt-image-1-mini 에서 high input fidelity 를 쓸 경우 첫 번째 입력 이미지 가 더 강하게 텍스처와 디테일을 유지한다고 설명합니다. 얼굴, 로고, 상품, 패키지처럼 절대 무너지면 안 되는 visual anchor 가 있다면 그것을 첫 번째 input 에 놓아야 합니다. GPT Image 1.5 가 더 강한 이유는 이 preservation 이 첫 5장 까지 넓기 때문입니다.
이것은 단순한 파라미터 팁이 아니라, edit request 를 설계하는 방식을 바꾸는 규칙입니다.
mini 가 잘 맞는 경우는 보통 이렇습니다.
- 한 장의 주 이미지와 작은 reference image 한 장
- 얼굴 하나나 로고 하나처럼 최우선 보존 대상이 분명할 때
- 한 장면에서 큰 변경점이 한 가지일 때
- 내부용 mockup 이나 creative variation 처럼 리스크가 낮거나 중간 정도일 때
반대로 다음과 같은 작업은 더 신중해야 합니다.
- 여러 reference image 가 모두 중요할 때
- 여러 브랜드 요소를 동시에 유지해야 할 때
- typography 나 layout 오차 허용치가 매우 작을 때
- 한 번의 실패가 큰 재작업 비용으로 이어지는 상업용 소재일 때
구현 패턴 자체는 단순합니다.
jsconst result = await client.images.edit({ model: "gpt-image-1-mini", image: [ fs.createReadStream("base-scene.jpg"), fs.createReadStream("logo.png"), ], prompt: "Place the logo from image 2 onto the tote bag in image 1. Preserve the model, pose, bag shape, camera framing, and lighting.", input_fidelity: "high", });
핵심은 코드 문법보다 입력 순서 입니다. mini 에서 가장 강한 preservation slot 은 첫 번째 input 입니다.
먼저 가격, 제한, verification 을 확인하고 그다음에 코드를 의심하기
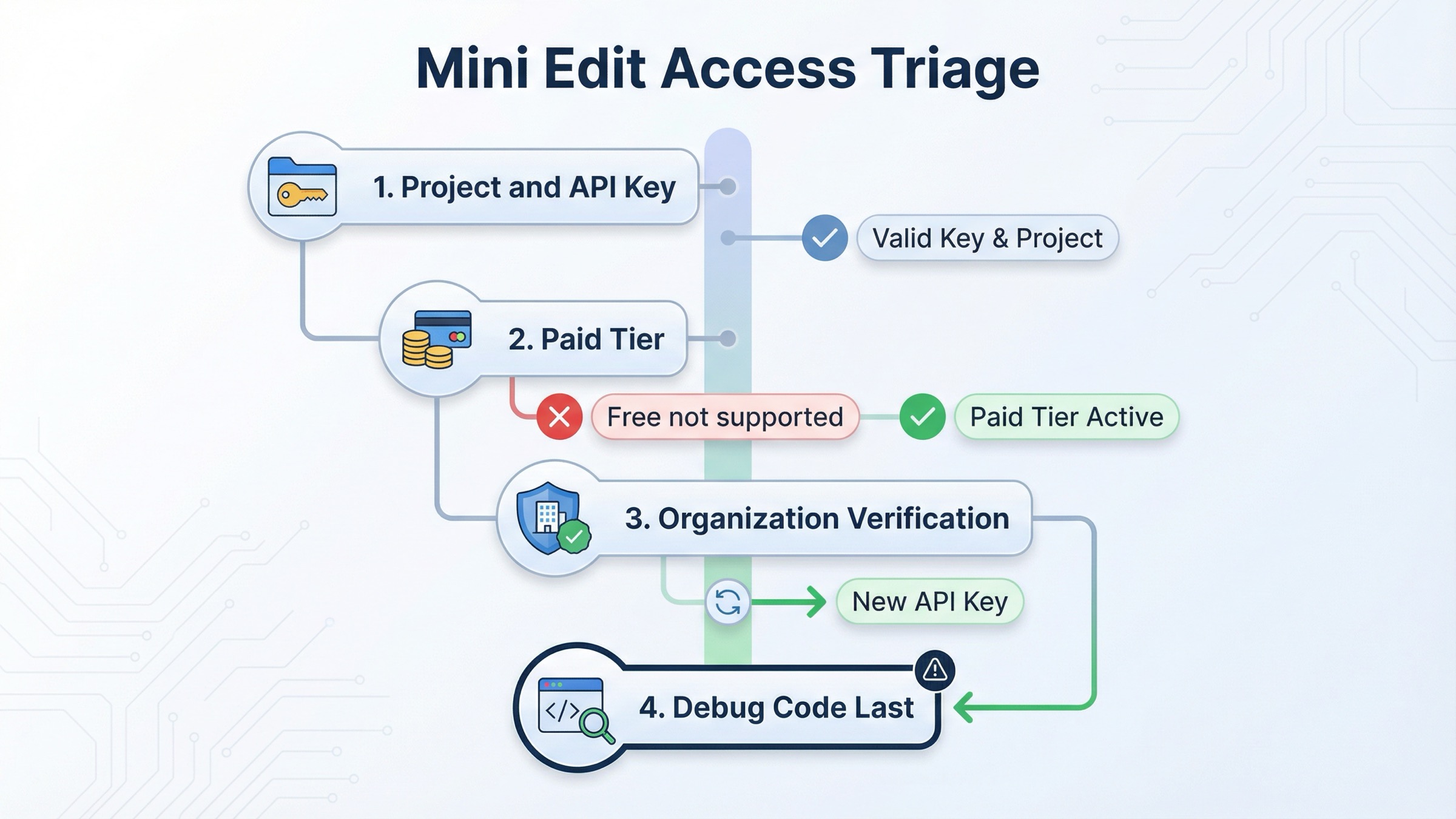
exact-match 페이지가 독자의 시간을 가장 많이 낭비하는 지점이 바로 여기입니다. sample code 는 보여주지만, 실제 문제는 코드가 아니라 account state 일 수 있다는 점을 늦게 말합니다.
2026년 3월 29일 기준 gpt-image-1-mini model page 에서 1024x1024 가격은 low $0.005, medium $0.011, high $0.036 입니다. 같은 페이지에는 Free not supported 와 함께 Tier 1 시작 제한으로 100,000 TPM 과 5 IPM 도 적혀 있습니다.
현재 model availability article 은 GPT-image-1 과 GPT-image-1-mini 가 tier 1~5 API 사용자에게 제공되지만, 일부 access 는 organization verification 에 영향을 받을 수 있다고 설명합니다. 현재 organization verification article 은 상태 반영에 최대 30분 이 걸릴 수 있고, verified 상태인데도 "not verified" 오류가 남으면 새 API key 발급이 해결하는 경우가 많다고도 말합니다.
그래서 맞는 troubleshooting order 는 다음과 같습니다.
- API key 가 올바른 project 와 organization 에 연결되어 있는지 확인
- mini image access 를 지원하는 유료 tier 인지 확인
- 여전히 access 문제처럼 보이면 organization verification 확인
- 30분 반영 시간을 충분히 기다리기
- 조직이 verified 인데도 이상하면 API key 를 새로 발급
- 그다음에야 integration 코드를 고치기
이 순서가 중요한 이유는 direct mini edit request 가 문법상 맞아도 account state 가 준비되지 않았으면 실패할 수 있기 때문입니다. 원인이 access 라면 prompt 를 더 다듬거나 Responses 로 크게 갈아타도 해결되지 않습니다.
진짜 병목이 edit logic 이 아니라 access 라면, 다음으로 볼 글은 OpenAI image generation API verification 가이드 가 맞습니다. 비용 계산이 목적이라면 GPT Image 1 Mini pricing 이 더 유용합니다.
exact query 페이지가 자주 숨기는 트러블슈팅 포인트
첫 번째 흔한 실수는 처음부터 잘못된 API surface 로 들어가는 것입니다. 작업이 단발성 direct edit 라면, Responses 예제가 더 최신처럼 보인다는 이유만으로 더 큰 추상화부터 잡을 필요가 없습니다.
두 번째는 Responses 의 model mental model 을 잘못 잡는 것입니다. GPT Image 계열은 top-level model 이 아니고, 이미지 처리는 tool layer 에서 일어납니다. Responses 로 가는 순간 route 의 의미 자체가 달라집니다.
세 번째는 mask 를 hard-boundary pixel control 로 생각하는 것입니다. GPT Image 의 mask editing 은 prompt-driven 이며, 완벽한 윤곽 고정을 보장하지 않습니다. 아주 작은 국소 수정만 허용되는 workflow 라면 그 가정을 일찍 검증해야 합니다.
네 번째는 가장 중요한 asset 를 첫 번째 input 에 두지 않는 것입니다. 얼굴, 로고, 주력 상품이 첫 번째가 아니라면, mini 가 가진 가장 강한 preservation slot 을 스스로 포기하는 셈입니다.
다섯 번째는 access 확인 전에 prompt 를 계속 고치는 것입니다. tier, verification, project context 가 어긋나 있으면 긴 prompt 는 해결책이 되지 않습니다.
여섯 번째는 하나의 저렴한 edit request 에 너무 많은 것을 요구하는 것입니다. 현재 limitations 에도 복잡한 prompt 는 최대 2분 까지 걸릴 수 있고, 정밀한 텍스트 배치나 여러 참조 이미지의 일관성, 엄격한 구도 제어에는 아직 한계가 있다고 나와 있습니다. 브랜드 lockup, 텍스트 정확도, 여러 input 유지가 모두 필요하다면 route 보다 model choice 를 의심해야 합니다.
더 실무적인 순서는 다음과 같습니다.
- 먼저 가장 작은 direct edit 를 한 번 시도
- 가장 중요한 input 을 첫 번째에 배치
- 보존이 정말 중요할 때만
input_fidelity="high"사용 - 복잡한 변경을 한 번에 몰아넣지 말고, 비슷한 결과가 나오면 두 단계 edit 로 쪼개기
이 순서가 prompt 를 계속 늘리는 것보다 시간을 더 아껴주는 경우가 많습니다.
mini edit 로 충분한 경우와 GPT Image 1.5 로 올리는 편이 안전한 경우

이 키워드 뒤의 진짜 판단은 "mini 인가 Responses 인가" 가 아니라, "mini 로 충분한가, 아니면 1.5 로 올려야 하는가" 입니다.
현재 model comparison section 에서 OpenAI 는 gpt-image-1.5 가 전반적으로 가장 좋은 품질 경험을 주고, gpt-image-1-mini 는 품질보다 cost 가 더 중요한 경우의 선택지 라고 설명합니다. 이것을 edit workflow 언어로 옮기면 다음과 같습니다.
mini 로 충분한 경우가 많은 상황:
- 내부용 creative variation
- 저위험 ecommerce mockup 또는 room edit
- 한 장의 주 이미지가 중심인 product edit
- 먼저 싼 benchmark 를 돌리고 quality lane 으로 올릴지 판단하려는 경우
- 최고의 품질보다 비용이 더 중요한 workflow
GPT Image 1.5 가 더 안전한 상황:
- 여러 중요한 reference image 를 한 번에 다뤄야 할 때
- 브랜드 요소 보존이 더 엄격할 때
- typography 나 layout 에 민감할 때
- 실패 시 재작업 비용이 큰 marketing asset 을 다룰 때
- 현재 OpenAI 이미지 편집에서 가장 안전한 quality-first default 를 원할 때
그래서 정직한 recommendation 은 "mini vs Responses" 가 아닙니다. mini-specific edit 는 direct Images API 로 시작하고, workload 자체가 mini 한계를 드러내면 route 를 더 만지는 대신 GPT Image 1.5 로 올린다 가 더 정확합니다.
mini 의 전체적인 가성비 판단을 더 보고 싶다면 GPT Image 1 Mini review 가 다음 읽을거리입니다. OpenAI image family 전체 경로를 보고 싶다면 OpenAI Image API tutorial 로 가는 편이 낫습니다. 1.5 의 비용까지 계산하고 싶다면 GPT Image 1.5 pricing API 가 더 적합합니다.
FAQ
gpt-image-1-mini 는 지금 직접 이미지 편집이 가능한가요?
네. 현재 gpt-image-1-mini model page 에 v1/images/edits 가 명시되어 있으므로, direct Images API 는 mini edit 의 유효한 current route 입니다.
한 번만 편집하면 되는데 왜 Responses 로 바로 시작하지 않나요?
current image guide 가 한 번의 prompt 와 한 번의 image job 이라면 Image API 가 더 적합하다고 분명히 말하기 때문입니다. Responses 는 더 큰 대화나 tool workflow 가 필요할 때 가치가 있습니다.
mask 를 쓰면 masked area 만 정확하게 바뀌나요?
아니요. 현재 docs 는 GPT Image masking 이 prompt-based 라고 설명합니다. mask 는 편집 방향을 유도하지만, 엄격한 픽셀 경계를 보장하지는 않습니다.
언제 mini 에서 GPT Image 1.5 로 바로 올려야 하나요?
여러 이미지 보존, 브랜드 요소 유지, layout-sensitive asset, quality-first default 가 중요해지는 시점부터는 GPT Image 1.5 를 빨리 benchmark 하는 편이 맞습니다.
마지막 추천
2026년 3월 29일 기준으로 gpt-image-1-mini 로 이미지를 편집하려면, 먼저 images.edit() 또는 POST /v1/images/edits 로 시작하세요. 이것이 현재 docs 기준으로 가장 명확하고, 가장 디버깅하기 쉽고, mini 특유의 동작을 놓치지 않기 쉬운 경로입니다.
Responses 로 넘어가는 것은 이미지 편집이 assistant / multimodal workflow 의 일부로 정말 필요할 때만 검토하면 됩니다. 그리고 두 번째 판단은 따로 하세요. mini 가 부족하다면 route 최적화에 시간을 더 쓰기보다 GPT Image 1.5 를 benchmark 하는 편이 더 낫습니다.