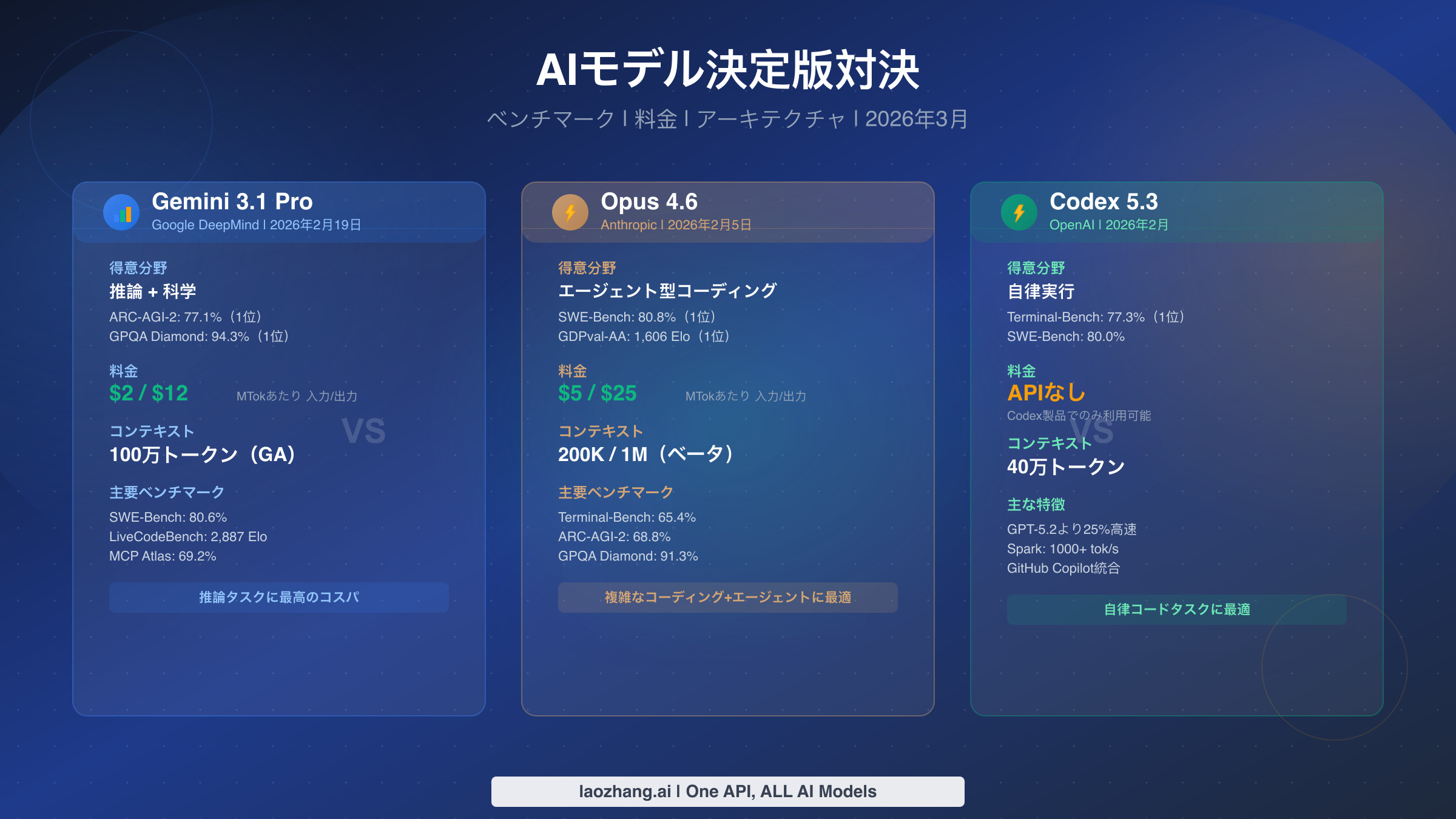
2026年2月、わずか数週間の間に前例のないフロンティアAIモデルの波が押し寄せましたが、比較記事の多くはすでに古い料金データや表面的なベンチマーク表で溢れています。公式の料金ページから直接すべてのデータポイントを検証した結果、Gemini 3.1 Pro、Claude Opus 4.6、GPT-5.3-Codexの中に単独の勝者は存在しないと断言できます。各モデルはそれぞれ異なる領域で優位性を持っています。Geminiは100万入力トークンあたり2ドルという価格で科学的推論とコスト効率においてリードし、Opusは独自のAgent Teamsアーキテクチャによりエージェント型コーディングで卓越し、Codexはサンドボックス環境を通じて比類のない自律実行速度を実現しています。以下は、2026年3月時点で最も徹底的に検証された比較です。
要点まとめ
詳細な分析に入る前に、現在プロダクション環境での導入判断を迫られている開発者にとって最も重要な観点での比較を以下にまとめます。この表のすべての料金は、2026年3月2日にブラウザ自動化ツールを使用して公式の料金ページから直接検証したものであり、複数の競合記事が特にOpus 4.6について誤った料金データを引用していることが判明しました。この点は非常に重要です。なぜなら、誤った料金に基づいてインフラの意思決定を行うと、月に数千ドル単位で予算の過不足が生じ、リソースの浪費やプロジェクト途中でのモデル切り替えを余儀なくされるコスト超過につながる可能性があるからです。
| 項目 | Gemini 3.1 Pro | Claude Opus 4.6 | GPT-5.3-Codex |
|---|---|---|---|
| リリース日 | 2026年2月19日 | 2026年2月5日 | 2026年2月 |
| 入力料金 | $2/MTok | $5/MTok | APIなし |
| 出力料金 | $12/MTok | $25/MTok | APIなし |
| コンテキストウィンドウ | 1M(GA) | 200K / 1M(ベータ) | 400K |
| 最大出力 | 64K | 128K | 128K |
| 最高ベンチマーク | ARC-AGI-2: 77.1% | SWE-Bench: 80.8% | Terminal-Bench: 77.3% |
| 得意分野 | 研究、科学、ロングコンテキスト | 複雑なコーディング、エージェント | 自律実行 |
| APIアクセス | 標準API | 標準API | Codex製品のみ |
最も重要なポイントは、GPT-5.3-CodexにはOpenAIの料金ページにスタンドアロンのAPI料金が存在しないということです。Codexアプリ、CLI、IDE拡張機能、GitHub Copilotを通じてのみ利用可能であり、ワークフローへの統合方法という点で他の2つのモデルとは根本的に異なります。トークン単位の課金でダイレクトAPIコールが必要な場合、実際の選択肢はGemini 3.1 ProとClaude Opus 4.6に絞られます。その判断は、コスト効率と推論の幅広さを重視するか、エージェント型コーディングの深さと信頼性を重視するかによって決まります。以下では、各モデルの競争領域を定義するベンチマーク数値から始め、多くの記事が誤って伝えている料金の実態に移り、最終的にはあなたの具体的なワークフローを最適なモデル選択にマッピングする実践的な判断フレームワークに到達します。
ベンチマーク直接対決 - 各モデルの勝利領域
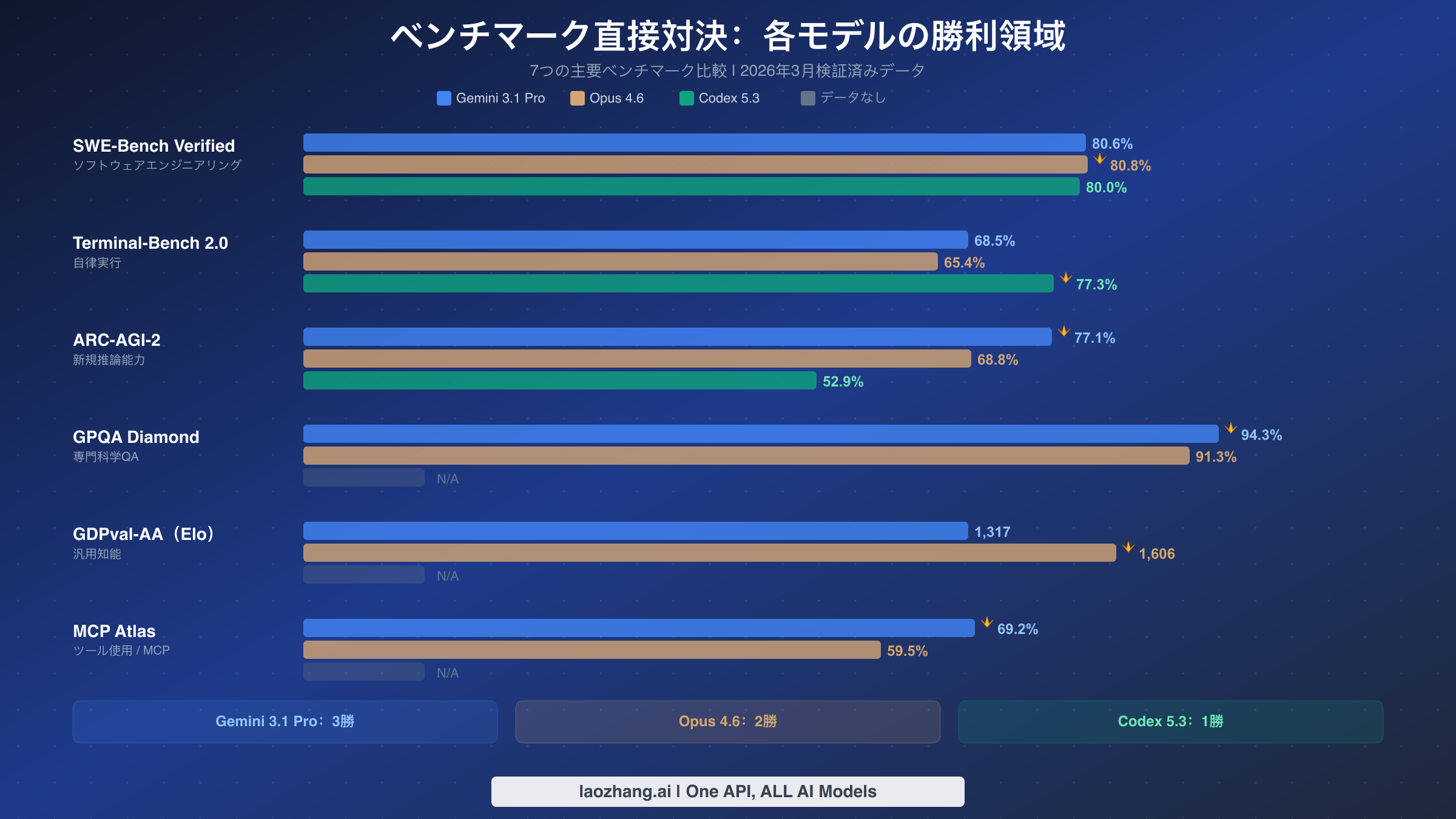
これら3つのモデルのベンチマーク状況は、「すべてを制する1つのモデル」という単純な物語に疑問を投げかけるパターンを明らかにしています。各モデルがそれぞれ独自の領域を確立しており、各モデルがどこで優れているかを理解するには、生の数値を超えてベンチマークが実際に何を測定しているかを見る必要があります。
SWE-Bench Verifiedは、ソフトウェアエンジニアリング評価のゴールドスタンダードであり、非常に接戦となっています。Opus 4.6が80.8%でわずかにリードし、Gemini 3.1 Proが80.6%、Codex 5.3が80.0%と続きます。ここでの差は、ほとんどの実用的な目的において誤差の範囲内であり、3つのモデルすべてが実世界のGitHub issueの解決においてほぼ同等であることを意味しています。これは6か月前にはなかった状況であり、当時はトップモデルと残りの間に明確な差が存在していました。OpusとCodexのコーディングタスクにおける具体的な比較については、Opus 4.6 vs GPT-5.3の詳細比較をご覧ください。
Terminal-Bench 2.0はまったく異なるストーリーを語っており、ここではCodex 5.3が77.3%で真に輝き、Geminiの68.5%とOpusの65.4%を大きく上回っています。このベンチマークは自律実行能力、つまりモデルがターミナルを操作し、コマンドを実行し、エラーをデバッグし、人間の介入なしにマルチステップタスクを完了する能力を測定します。Codexのリードは理にかなっています。なぜなら、Codexはモデルが自由にコードを実行し、出力を確認し、ソリューションを反復できるサンドボックス実行環境を中心に設計されたからです。AIエージェントにタスク全体を引き渡して完成した成果物を期待するユースケースの場合、これが最も重要なベンチマークです。
ARC-AGI-2は新規推論能力を測定し、Gemini 3.1 Proが77.1%で、Opusの68.8%とCodexの52.9%に対して圧倒的にリードしています。これは、すべてのベンチマークの中で、任意の2つのモデル間の最大の差であり、Mixture-of-Expertsアーキテクチャを通じたGoogleの推論能力への投資を反映しています。ARC-AGI-2ベンチマークは、モデルがこれまでに見たことのない問題を解決する能力を特にテストするため、トレーニングデータに対するパターンマッチングではなく汎用知能の代理指標となります。
GPQA Diamondは、専門家レベルの科学的質問への回答能力をテストし、Gemini 3.1 Proが94.3%、Opus 4.6が91.3%を記録しています。Codex 5.3はこのベンチマークのスコアを公開していません。ここでの3ポイントの差は意味があります。なぜなら、GPQA Diamondの問題は博士レベルの分野専門家にとっても難しいように設計されているからです。ワークフローに科学研究、医学的推論、または複雑な分析タスクが含まれる場合、Geminiには測定可能な優位性があります。
GDPval-AAはEloレーティングで測定され、Opus 4.6が1,606でGeminiの1,317をリードしています。このベンチマークは、一般的な指示への追従と対話における一貫性を評価するものであり、AnthropicのConstitutional AIトレーニングアプローチが効果を発揮する分野です。289ポイントのElo差は大きく、Opusが会話的な場面でより一貫して高品質で繊細な回答を生成することを示しています。この2つのモデルの直接比較については、Gemini 3.1 Pro vs Opus 4.6の比較分析をご覧ください。
追加で言及する価値のあるベンチマークとしてMCP Atlasがあります。これは、Model Context Protocolを通じてモデルが外部ツールをどれだけ効果的に使用できるかを測定します。Gemini 3.1 Proは69.2%、Opus 4.6は59.5%のスコアを記録し、Codex 5.3はスコアを報告していません。これは、モデルがデータベース、API、ファイルシステムへの呼び出しをオーケストレーションする必要があるエージェントアプリケーションを構築する開発者にとって特に重要です。GeminiのリードはそのMoEアーキテクチャがAPIスキーマの理解とパラメータ生成をより効果的に処理する専門エキスパートにツール使用クエリをルーティングすることを示唆しています。
結論として、すべてのベンチマークで勝つモデルはありません。Gemini 3.1 Proは推論と科学でリード(重要なARC-AGI-2とMCP Atlasを含む3つのベンチマーク勝利)、Opus 4.6はコーディング品質と汎用知能でリード(SWE-BenchとGDPval-AAの2勝)、Codex 5.3は自律実行を支配(Terminal-Benchの1勝ですが12ポイントという決定的なマージン)しています。選択は、どのベンチマークカテゴリが実際のワークロードに最も近いかに基づくべきであり、ほとんどのチームにとってそれは、ボトルネックが推論品質、コードの正確性、または実行の自動化のどれにあるかを正直に評価することを意味します。
実際の料金 - 2026年にこれらのモデルが本当にかかるコスト
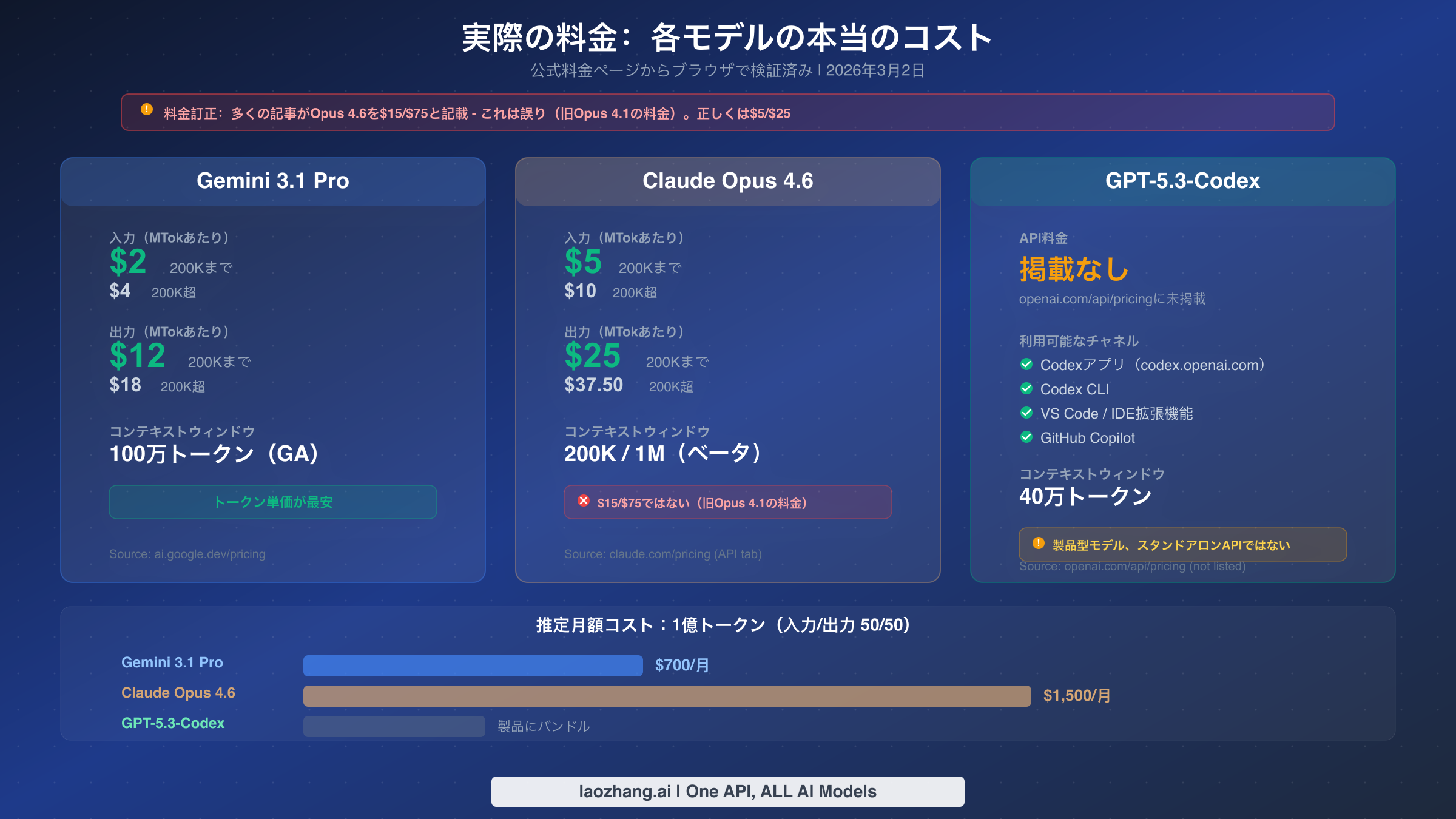
料金は、既存の比較記事の中で最も危険な誤情報が見つかった分野です。上位にランクインする複数の記事が、Claude Opus 4.6の料金を入力100万トークンあたり15ドル、出力100万トークンあたり75ドルと引用しています。これは間違いです。それらはOpus 4.1および4.0のレガシー価格です。2026年3月2日にclaude.com/pricingから直接検証した実際のOpus 4.6の料金は、200Kコンテキストまでのプロンプトに対して入力100万トークンあたり5ドル、出力100万トークンあたり25ドルです。200Kトークンを超えるロングプロンプトの場合、料金は入力10ドル、出力37.50ドル(100万トークンあたり)に上がります。
Gemini 3.1 Proは、現在標準APIを通じて利用可能なフロンティアモデルの中で最も競争力のあるトークン単価を提供しています。入力100万トークンあたり2ドル、出力100万トークンあたり12ドル(2026年3月2日にai.google.dev/pricingから検証済み)であり、Opus 4.6と比較して入力で60%、出力で52%安くなっています。200Kトークンを超えるプロンプトの場合、Geminiの料金は入力4ドル、出力18ドルに倍増しますが、それでもOpusの拡張コンテキスト料金よりも大幅に安いままです。大量の推論ワークロードを実行しており、コストが主要な関心事である場合、この価格優位性は急速に積み上がります。Geminiの料金ティアと割引の詳細については、2026年Gemini API料金の詳細をご覧ください。
GPT-5.3-Codexは、OpenAIのAPI料金ページにまったく掲載されていないため、まったく異なる料金モデルを提示しています。2026年3月2日にopenai.com/api/pricingにアクセスして確認したところ、GPT-5.2は100万トークンあたり$1.75/$14で掲載されていましたが、GPT-5.3-Codexは存在しませんでした。つまり、トークン単位の課金による標準APIエンドポイントで呼び出すことはできません。代わりに、codex.openai.comのWebアプリ、Codex CLI、IDE拡張機能、またはGitHub CopilotといったCodex製品を通じてアクセスします。コストはトークン単位ではなく、既存のOpenAIまたはGitHubサブスクリプションにバンドルされるため、他の2つのモデルとの直接的なコスト比較は困難です。
総所有コスト:3つの実際のシナリオ
料金を実用的に理解するために、推定月額コストを含む3つの使用シナリオを考えてみましょう。
シナリオ1:個人開発者(月1,000万トークン、入力/出力比60/40)。一日中AIコーディングアシスタントを使用する開発者の場合、Gemini 3.1 Proは月約60ドル、Opus 4.6は月約130ドルかかります。Codex 5.3は月額200ドルのChatGPT Proまたはエンタープライズ向けGitHub Copilotサブスクリプションに事実上含まれているため、すでにこれらのサービスの料金を支払っている場合にのみコスト効率が高くなります。
シナリオ2:小規模チームのコードレビューパイプライン(月1億トークン、入力/出力比70/30)。5〜10人の開発者からなるチームが自動化コードレビューを実行する場合、Gemini 3.1 Proで月約500ドル、Opus 4.6で月約1,100ドルとなります。この規模では料金差が大きくなり、Opusのコーディング品質の向上が2.2倍のコストプレミアムに見合うかどうかを真剣に検討する必要があります。すでにlaozhang.aiのようなAPI集約サービスを利用しているチームであれば、競争力のある料金を維持しながら複数モデルにわたる統一的な課金管理が可能です。
シナリオ3:エンタープライズ向けエージェントパイプライン(月10億トークン、入力/出力比50/50)。エンタープライズ規模では、Gemini 3.1 Proが月約7,000ドル、Opus 4.6が月約15,000ドルとなります。ただし、Anthropicはバッチ処理の大幅な割引(50%オフ)とプロンプトキャッシュの割引を提供しており、この差を大幅に縮められます。Claudeの料金ティアの包括的な内訳については、Claude API料金の完全ガイドをご覧ください。
料金の判断は、最終的にはモデル間の品質差が特定のユースケースにおけるコストプレミアムを正当化するかどうかにかかっています。推論中心のワークロードにはGeminiが最も優れた価値を提供します。品質の違いがバグの減少とやり直しの減少につながる複雑なコーディングタスクについては、Opusのプレミアムが元を取れる可能性があります。
各モデルのアクセス方法 - API、CLI、そしてその先
この3者比較で最も誤解されている側面の1つは、各モデルに実際にどのようにアクセスするかということです。Gemini 3.1 ProとClaude Opus 4.6はおなじみの「APIキーを取得してHTTPリクエストを送信する」パターンに従いますが、GPT-5.3-Codexはこのモデルから完全に脱却しており、チームを特定のワークフローにコミットする前にこの違いを理解することが不可欠です。
Gemini 3.1 Proは、GoogleのAI StudioとVertex AIプラットフォームを通じてアクセス可能です。ai.google.devでAPIキーを生成し、モデルID gemini-3.1-pro-preview で標準RESTパターンに従って呼び出します。GoogleはPython、JavaScript、Goなどのクライアントライブラリも提供しています。モデルは現在「プレビュー」ステータスであり、GA前にGoogleが破壊的変更を加える可能性がありますが、実際にはAPIはリリース以来安定しています。注目すべき利点として、Geminiは寛大なレート制限付きの無料ティアを提供しており、クレジットカードなしで実験が可能です。
Claude Opus 4.6は、Anthropicの API を通じてモデルID claude-opus-4-6 で利用可能です。アクセスにはconsole.anthropic.comからのAPIキーが必要です。AnthropicはPythonとTypeScript用の公式SDKを提供しており、APIはクリーンで十分にドキュメント化されたフォーマットに従っています。Opus 4.6はすでにGA(Generally Available)であり、APIは安定してプロダクション対応です。モデルはClaude.ai、Claude Code(AnthropicのCLIツール)、およびさまざまなIDE統合を通じてもアクセス可能です。エージェント型ユースケースでは、Opus 4.6はClaude Codeを通じてAgent Teams機能をサポートしており、複雑なタスクに並行して取り組むサブエージェントを生成できます。
GPT-5.3-Codexには根本的に異なるアプローチが必要です。OpenAIのAPIに gpt-5.3-codex モデルエンドポイントは存在しません。代わりに、4つのチャネルでアクセスします。codex.openai.comのCodex Webアプリケーションでは、サンドボックス環境でモデルが非同期に作業するタスクを割り当てます。Codex CLIはターミナルワークフローに統合されます。VS CodeとJetBrains用のIDE拡張機能があります。そしてGitHub Copilotでは、Codexモデルがコーディングアシスタントを支えています。このプロダクト指向のアプローチにより、Codexはトークンごとのストリーミング応答ではなく、完全なタスク実行(機能の作成、バグの修正、PRの作成)に優れています。ワークフローがすでにGitHubを中心としており、PRを自律的に完了できるAIが欲しい場合、Codexはまさにそのために作られています。ただし、トークン単位の制御でモデル呼び出しをカスタムアプリケーションに組み込む必要がある場合、Codexは適切な選択ではありません。
これらの異なるアクセスパターンの実際的な影響は、アーキテクチャの意思決定にとって重要です。トークン使用量、モデルパラメータ、レスポンスストリーミングをきめ細かく制御しながらAIモデルをプログラム的に呼び出す製品を構築している場合、Gemini 3.1 ProとClaude Opus 4.6が選択肢となります。タスクの説明を受け取って完了した成果物を返すジュニア開発者のように動作するAIが欲しい場合、Codex 5.3はまさにそのユースケース向けに設計されています。多くの洗練されたチームは両方のパターンを使用しています。リアルタイムのユーザー向け機能にはAPIベースのモデルを使用し、テスト生成やドキュメント更新などのバックグラウンド自動化タスクにはCodexを使用しています。
複数のモデルにわたる柔軟性が必要なチームには、API集約プラットフォームがマルチモデルワークフローを簡素化できます。laozhang.aiのようなサービスは、GeminiとClaudeの両モデルをサポートする統一APIエンドポイントを提供し、複数のAPIキーや課金システムを管理することなく、最適なモデルにリクエストをルーティングできます。これは現在のように急速なモデルリリースが続く時期に特に有用で、特定のタスクタイプに最適なモデルが四半期ごとに変わる可能性があり、統合コードを書き直すことなく切り替える柔軟性が求められるからです。
アーキテクチャの内側 - 各モデルが特定分野で優れる理由

アーキテクチャを理解することで、ベンチマーク数値の背後にある「なぜ」を説明でき、ここが多くの比較記事の不十分な点です。各モデルが何点を取ったかは伝えても、なぜそのスコアになるのかは説明しません。これら3つのモデルのアーキテクチャの違いは単なる学術的な好奇心ではなく、各モデルがどのワークロードを最もうまく処理するかを直接予測するものです。
Gemini 3.1 ProのMixture-of-Experts(MoE)アーキテクチャは、推論における優位性とコスト効率の両方の鍵です。すべてのクエリに対してニューラルネットワーク全体をアクティブ化するのではなく、MoEは各入力を少数の専門化された「エキスパート」サブネットワークに選択的にルーティングします。関連する専門家だけが各タスクに取り組む専門家チームのようなものと考えてください。これが、Geminiが大規模な総パラメータ数を維持しながら(多様なタスクでの強力なパフォーマンスを可能にする)、推論コストを低く保てる理由です(クエリごとにパラメータの一部しかアクティブ化されないため)。MoE設計は特に科学的・数学的推論に有利です。モデルがそれらの分野に特化してトレーニングされたエキスパートに複雑な分析クエリをルーティングできるからです。また、Geminiが100万トークンのGA対応コンテキストウィンドウを提供できる理由も説明しています。効率的なエキスパートルーティングにより、ロングコンテキスト処理が大規模で計算上実現可能になるのです。
Claude Opus 4.6のDense TransformerアーキテクチャとConstitutional AIは、異なる哲学を表しています。専門家にルーティングするのではなく、すべてのパラメータがすべての計算に参加するため、より一貫性のある繊細な出力を生成しますが、推論コストは高くなります。Opus 4.6の画期的なイノベーションは、コーディングタスク向けのGVR(Generate-Verify-Reflect)ループです。モデルがコードを生成し、検証チェックを実行し、結果について振り返ってから反復するプロセスで、経験豊富な開発者の作業方法を反映しています。この自己修正ループが、OpusがSWE-Benchでリードし、実務でバグが少ない理由です。Agent Teamsアーキテクチャはこれをさらに拡張し、Opusが問題の異なる部分に同時に取り組むサブエージェントを生成できるようにします。Anthropicの報告によると、これにより主要なオープンソースプロジェクト全体で500件以上のゼロデイ脆弱性が発見されました。JetBrainsやDatabricksのエンジニアからの開発者証言で確認されたOpusの行動特性は、実装前に明確化の質問をすることであり、開発者の意図により正確にマッチしたソリューションを生み出します。
GPT-5.3-Codexの最適化GPT-5バリアントは、速度と自律実行のために特化して構築されています。2つのイノベーションがそれを定義します。まず、1,000+トークン/秒を達成するSparkモードで、GPT-5.2より約25%高速で、生の生成速度ではGeminiやOpusのいずれよりも大幅に高速です。次に、Codexがgit、ターミナルコマンド、テストフレームワークにフルアクセスできる分離されたクラウド環境で動作するサンドボックス実行モデルです。これがCodexがTerminal-Benchを支配する理由です。動作するはずのコードを生成するだけでなく、実際にコードを実行し、出力を観察し、失敗をデバッグし、タスクがすべてのテストに合格するまで反復します。ここでの行動パターンはOpusとは正反対です。Codexは先に実装して後から質問し、事前に広範な計画を立てるのではなく、ソリューションを迅速にプロトタイプして失敗に基づいて反復します。GPT-5.3 CodexとOpus 4.6が実際にどう比較されるかのより詳細な比較については、専用の記事で具体的なコーディングシナリオを探っています。
トレーニング手法の違いも同様に重要です。Geminiに対するGoogleのアプローチは、テキストモデルを後から他のモダリティに対応するようにファインチューニングするのではなく、テキスト、コード、画像、音声、動画を含む複数のデータモダリティにわたってネイティブにトレーニングすることです。このネイティブなマルチモーダルトレーニングが、UIのスクリーンショットと変更内容のテキスト説明を組み合わせるような混合モダリティ入力をGeminiがより自然に処理する理由です。Opusに対するAnthropicのトレーニングはConstitutional AIを重視し、モデルが一連の原則に照らして自身の出力を評価・改善することを学習し、開発者が実際に気づく慎重で自己修正的な行動を生み出します。Codexに対するOpenAIのトレーニングは、コード実行とツール使用に特に焦点を当て、コード生成品質と自律タスク完了に関する人間のフィードバックからの広範な強化学習を行いました。
これらのアーキテクチャとトレーニングの違いは、モデル選択に明確な示唆を生み出します。モダリティを問わず強力な推論で1ドルあたり最も多くのトークンを処理する必要がある場合、MoEベースのGeminiが最適です。慎重な計画と自己修正を備えた最高品質のコード生成が必要な場合、Dense TransformerベースのOpusが選択です。実行、テスト、独立した反復能力を備えた最速の自律タスク完了が必要な場合、Codexの実行優先アプローチが勝ちます。
どのモデルを選ぶべきか - 開発者のための判断フレームワーク
一般的な「場合による」という回答ではなく、一般的な実世界のシナリオにマッピングされる5つの開発者ペルソナに基づく具体的な判断フレームワークを提供します。あなたのワークフローに最も近いペルソナを特定すれば、モデルの推奨が導かれます。
ペルソナ1:ソロのフルスタック開発者。SaaS製品を構築しており、フロントエンドのReactコンポーネントからバックエンドAPIの設計、データベースクエリまで多様なタスクを処理できるモデルが必要で、すべてのコストが個人の貯蓄やシードラウンドから出るためコストが重要です。ここでの推奨はGemini 3.1 Proをプライマリモデルとすることです。MoEアーキテクチャからの推論の幅広さが多様なフルスタックタスクをうまく処理し、1Mコンテキストウィンドウによりコードベース全体をコンテキストとしてロードでき、入力$2/MTokの料金で月額コストが管理可能な範囲に収まります。複雑なアーキテクチャの決定やトリッキーなデバッグセッションなど、追加の品質が価値のある場面ではOpus 4.6を選択的に使用してください。
ペルソナ2:バックエンドインフラエンジニア。分散システム、マイクロサービス、DevOpsパイプラインに取り組んでおり、速度よりも深い技術的正確性と慎重な分析が必要です。推奨はClaude Opus 4.6です。GVRループが他のモデルが見逃す微妙な並行性バグやエッジケースを検出し、「先に質問する」行動パターンは、間違えると障害を引き起こすインフラ作業に最適であり、Agent Teams機能は複数のサービスに同時に影響するリファクタリングタスクにとって変革的です。Geminiに対する2.5倍のコストプレミアムは、単一のプロダクションバグがインシデント対応に数千ドルのコストをかける場合には元が取れます。
ペルソナ3:エンジニアリングマネージャー。10人以上の開発者を監督しており、PRレビュー、バグ修正、テスト生成などのルーティンタスクを自律的に処理し、人間のエンジニアを創造的な仕事に解放できるAIが必要です。推奨はGPT-5.3-Codex(GitHub CopilotまたはCodex CLI経由)です。サンドボックス実行モデルにより、タスクを割り当てて完了したPRを受け取ることができ、77.3%のTerminal-Benchスコアは実際の自律タスク完了能力を反映しており、プロダクトベースの料金はトークン消費量に関係なく予測可能です。制限として、CodexはGitHubエコシステム内で最も強力であり、チームがGitLabやBitbucketを使用している場合、統合のストーリーは弱くなります。
ペルソナ4:AI研究者またはデータサイエンティスト。科学的推論、数学的証明、または大規模データセットの分析を必要とする新規の問題に取り組んでおり、コーディング固有の機能に関係なく最も強力な推論能力が必要です。推奨は明確にGemini 3.1 Proです。77.1%のARC-AGI-2スコア(最も近い競合より24ポイント先行)と94.3%のGPQA Diamondパフォーマンスにより、研究作業の明確な選択肢です。1MトークンのGAコンテキストウィンドウも、単一のプロンプトで大規模な論文、データセット、実験結果を分析するのに独自の価値を持ちます。
ペルソナ5:エンタープライズアーキテクト。多様なチームにわたる組織全体への展開を評価するモデルを評価しており、単一の能力よりも信頼性、安全性、柔軟性が必要です。推奨はマルチモデル戦略です。一般的なクエリとコスト効率にはGemini 3.1 Proをデフォルトモデルとして使用し、Constitutional AIトレーニングが追加の安全保証を提供する複雑なコーディングとセキュリティに敏感なタスクにはOpus 4.6を使用し、開発者の生産性にはGitHub Copilotを通じてCodex 5.3を使用します。このアプローチは自然なベンダー分散も提供し、いずれか1つのプロバイダーからのサービス停止、価格変更、廃止発表に対する保護となります。単一のモデルプロバイダーに完全に依存するエンタープライズは、標準化されたAPIパターンを通じて複数のモデルを統合することがこれほど容易になった今、ますます正当化できない集中リスクを抱えることになります。
プロダクション向けマルチモデル戦略の構築
2026年で最も洗練されたエンジニアリングチームは、単一のモデルを選んではいません。タスクの種類、求められる品質レベル、コスト制約に基づいて、各リクエストを最適なモデルにルーティングするアーキテクチャを構築しています。このアプローチは、コストをインテリジェントに管理しながら3つすべてのモデルの最良の部分を取り込みます。
コアパターンは、着信リクエストを分類して適切にルーティングするモデルルーターです。大まかに言えば、ルーティングロジックは次のようになります。推論中心のクエリ(研究、分析、科学的質問)はGemini 3.1 Proにルーティングし(ARC-AGI-2とGPQA Diamondでの優れたパフォーマンスを最低コストで活用)、複雑なコーディングタスク(リファクタリング、アーキテクチャ、セキュリティ監査)はOpus 4.6にルーティングし(SWE-Benchリーディングの品質とGVR自己修正ループを活用)、自律実行タスク(PR作成、テスト生成、ルーティンバグ修正)はCodex 5.3にルーティングします(Terminal-Benchを支配する能力を活用)。
実際の実装には通常、3つのレイヤーが含まれます。第1に、ユーザーのリクエストやアプリケーションコンテキストからタスクの種類を判定する分類レイヤー。第2に、設定可能なルールに基づいてタスクタイプをモデルにマッピングするルーティングレイヤー。第3に、モデルの利用不可、レート制限、予期しないエラーを処理し、代替モデルにルーティングするフォールバックレイヤーです。多くのチームはこれをAPI集約サービスを通じて実装し、個々のモデルAPIを単一のエンドポイントに抽象化して、ルーティングロジックをクリーンに保ち、課金を統合しています。
マルチモデル構成でのコスト最適化は、単に最も安いモデルを選ぶことだけではありません。Geminiのコンテキストキャッシュは、共有プレフィックスを持つ繰り返しプロンプトのコストを最大75%削減できます。AnthropicはOpusのバッチAPIリクエストに50%の割引を提供しており、オフラインコードレビューパイプラインに最適です。そしてCodexのプロダクトベースの料金は使用量に関係なく固定されているため、予算管理に最も予測可能な選択肢です。
マルチモデル戦略を評価するための重要な指標は、個々のモデルのパフォーマンスではなく、リクエストミックス全体にわたる品質あたりのコストの集計です。適切にチューニングされたルーターは、各タスクタイプに常に最適なモデルを使用した場合の品質の90%以上を達成しながら、すべてに単一のプレミアムモデルを使用する場合と比較してコストを40〜60%削減できます。ルーターの構築へのエンジニアリング投資は、大規模では迅速に回収されます。推論クエリをGeminiに、コーディングクエリをOpusに送信するシンプルなルールベースのルーターでさえ、すべてにOpusを使用する場合と比較してコストを30%削減でき、推論タスクでは同等以上の品質を維持します。
カスタムルーティングインフラを構築する準備ができていないチームは、モデル選択とフォールバックロジックを処理するAPI集約プラットフォームを通じて同様の結果を達成できます。重要な洞察は、現在の状況ではモデルロックインが最大のリスクであるということです。3つの異なるプロバイダーからの3つの強力な選択肢がある中で、能力の進化や料金の変更に応じてモデル間でトラフィックをシフトする柔軟性を維持することは、単一のモデルから最後の数パーセントのパフォーマンスを絞り出すことよりも価値があります。
FAQ - よくある質問
2026年3月時点でコーディングに最適なモデルはどれですか?
コーディングのワークフローによって異なります。コードレビューと複雑なリファクタリングには、Claude Opus 4.6がSWE-Benchの80.8%とGVR自己修正ループでリードしています。モデルが独立してコードを書き、テストし、コミットする自律タスク実行には、GPT-5.3-CodexがTerminal-Benchの77.3%で支配的です。コスト感度のある一般的なコーディングには、Gemini 3.1 ProがSWE-Bench 80.6%と入力$2/MTokで最も優れた価値を提供します。3つのモデルすべてがSWE-Benchで1パーセントポイント以内にあるため、実際の違いは必要なコーディング支援の種類と好みのワークフローに帰結します。
Opus 4.6は本当に$5/$25(100万トークンあたり)ですか?多くの記事が$15/$75と書いています。
はい、$5/$25が正しい料金です。2026年3月2日にclaude.com/pricingのAPIタブをクリックして直接確認しました。多くの比較記事が引用している$15/$75の料金は、前世代のClaude Opus 4.1および4.0モデルのものです。Anthropicは4.6リリースでOpusの料金を大幅に引き下げ、プロダクション利用でより競争力のある価格になりました。
GPT-5.3-CodexをGPT-4oやGPT-5.2のようにAPI経由で呼び出せますか?
いいえ。2026年3月2日時点で、GPT-5.3-CodexはOpenAIのAPI料金ページに掲載されておらず、スタンドアロンのモデルエンドポイントもありません。Codex Webアプリ(codex.openai.com)、Codex CLI、IDE拡張機能、またはGitHub Copilotを通じてアクセスします。OpenAIからトークン単位の課金付き標準APIが必要な場合、GPT-5.2(100万トークンあたり$1.75/$14)が最新の選択肢ですが、Codexを特別にする自律実行機能は持っていません。
最大のコンテキストウィンドウを持つモデルはどれですか?
Gemini 3.1 ProがGA(Generally Available)で100万トークンの最大コンテキストウィンドウを提供しており、その長さで安定してプロダクション対応です。Claude Opus 4.6はデフォルトで200Kトークンをサポートし、リクエストにより1Mトークンのベータが利用可能です。GPT-5.3-Codexは400Kトークンをサポートしています。非常に長いドキュメントの処理がユースケースの中心である場合、Geminiの1M GAコンテキストウィンドウには明確な優位性があります。
エンタープライズ利用で最も安全なモデルはどれですか?
Claude Opus 4.6は、Constitutional AIと広範な安全性トレーニングにより設計されており、厳格なコンプライアンス要件を持つエンタープライズ環境に特に適しています。Anthropicは詳細なモデルカードを公開し、安全性評価において強い実績を持っています。Gemini 3.1 ProはVertex AIを通じてGoogleの既存のエンタープライズセキュリティインフラストラクチャと統合されるため、エンタープライズがすでにGoogle Cloudワークロードで信頼しているのと同じアクセス制御、監査ログ、コンプライアンス認証が得られます。Codex 5.3はサンドボックス環境で動作し、意図しない副作用を引き起こす能力を制限し、プロダクトベースのアプローチにより、明示的に付与した範囲を超えてシステムにアクセスすることはできません。3つのプロバイダーすべてがエンタープライズ契約、SOC 2コンプライアンス、データ処理契約を提供しているため、安全性の決定は一般的な推奨ではなく、特定のコンプライアンスフレームワークに基づいて行うべきです。
バッチ処理の割引はコスト比較にどう影響しますか?
バッチ処理は、大量ユーザーのコスト計算を大きく変えます。Anthropicは Opus 4.6のバッチAPIリクエストに50%割引を提供しており、実効入力価格は100万トークンあたり2.50ドルに下がり、Geminiの標準価格2ドルにほぼ匹敵します。Googleは Gemini向けにコンテキストキャッシュを提供し、共有プレフィックスを持つプロンプトのコストを最大75%削減できます。これはシステムプロンプトとリポジトリコンテキストが多くのリクエストにわたって一定であるコードレビューパイプラインに非常に有用です。OpenAIのCodex料金はすでにプロダクトサブスクリプションにバンドルされているため、追加のバッチ割引はありませんが、ヘビーユーザーにとっての実効トークン単価は非常に低くなり得ます。重要なポイントは、公表されたトークン単価は出発点であり、最終コストではないということです。月に1億トークン以上を処理するチームは、プロバイダーと直接交渉し、キャッシュ、バッチ処理、コミットメント使用割引を考慮に入れるべきです。
これらのモデルはすぐに後継モデルに取って代わられますか?待つべきでしょうか?
2026年初頭のモデルリリースのペースは並外れており、数か月で時代遅れになるかもしれないモデルの上に構築することを心配するのは当然です。しかし、これら3つのモデルはすべて、前世代に対する重要なアーキテクチャの進歩(単なるスケールの増加ではなく)を表しており、典型的なモデル世代よりも長く競争力を維持することを示唆しています。GeminiのMoEアーキテクチャ、OpusのAgent Teams、Codexのサンドボックス実行はすべて、段階的な改善ではなく新しい能力です。実用的なアプローチは、モデルの交換が設定変更のみで済むようにモデルの抽象化を組み込んでアプリケーションを構築し、不確実な将来のリリースを待つのではなく、今日利用可能な最適なモデルを選択することです。この記事で概説したマルチモデル戦略は、本質的にこの柔軟性を提供します。