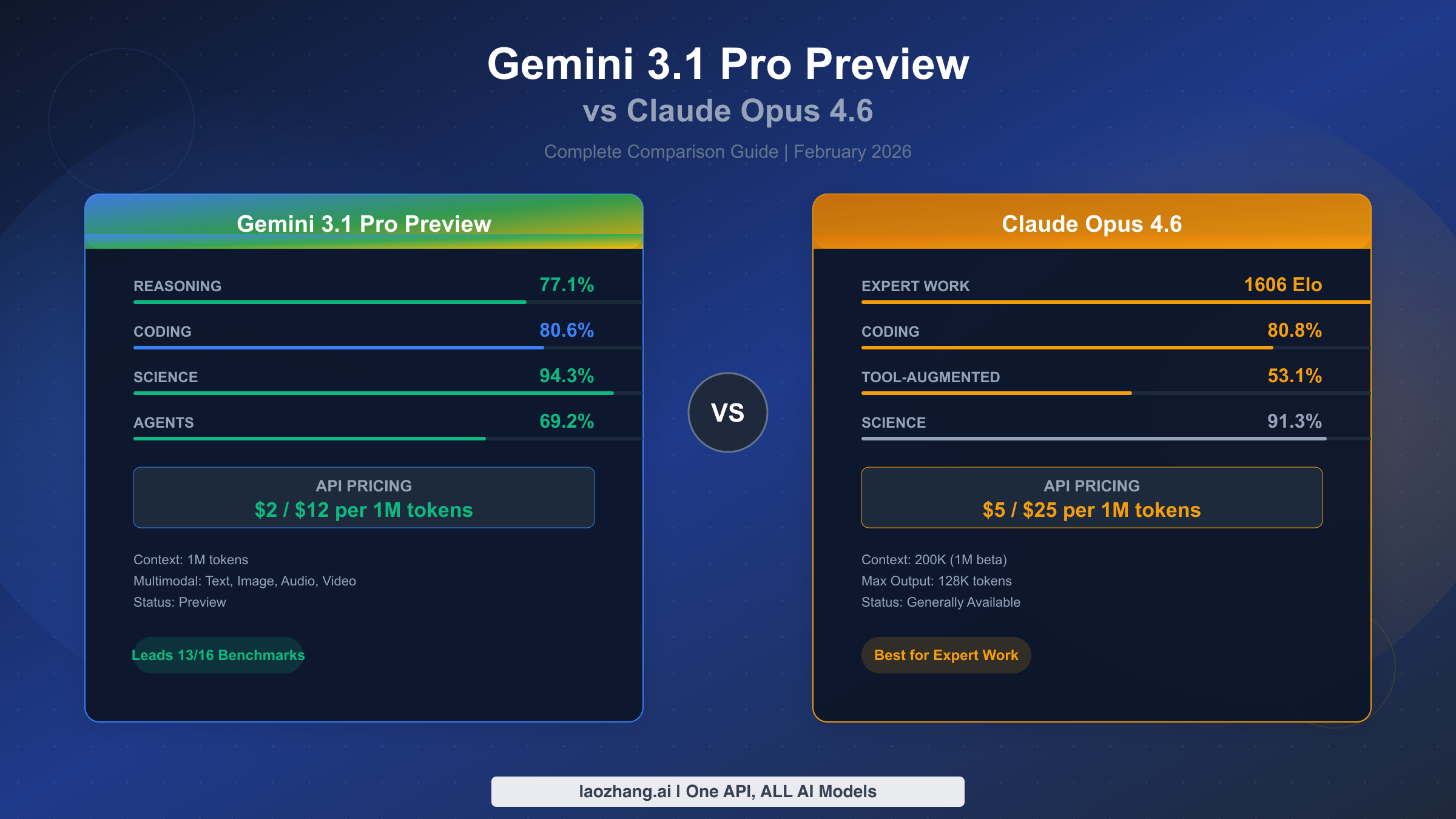
Google just dropped Gemini 3.1 Pro Preview on February 19, 2026, claiming it leads 13 out of 16 major benchmarks while costing roughly half of what Anthropic charges for Claude Opus 4.6. But benchmark dominance does not automatically translate to being the better choice for your project. Claude Opus 4.6, released two weeks earlier on February 5, still commands a significant lead in expert-level knowledge work and tool-augmented reasoning — areas that matter enormously for production applications. This guide cuts through the marketing noise to help you understand what these numbers actually mean and which model deserves your API budget.
TL;DR
Gemini 3.1 Pro Preview wins on raw benchmark numbers and price-to-performance ratio. Claude Opus 4.6 wins on expert knowledge work, coding polish, and tool-assisted reasoning. Here is the quick breakdown before we dive deep:
| Category | Winner | Why |
|---|---|---|
| Abstract Reasoning | Gemini 3.1 Pro | 77.1% vs 68.8% on ARC-AGI-2 |
| Expert Knowledge Work | Claude Opus 4.6 | 1606 vs 1317 Elo on GDPval-AA |
| Coding | Tie (slight Claude edge) | 80.8% vs 80.6% SWE-Bench |
| Tool-Augmented Reasoning | Claude Opus 4.6 | 53.1% vs 51.4% HLE with tools |
| Multimodal | Gemini 3.1 Pro | Native audio + video support |
| Context Window | Gemini 3.1 Pro | 1M native vs 200K (1M beta) |
| Pricing | Gemini 3.1 Pro | $2/$12 vs $5/$25 per MTok |
| Max Output | Claude Opus 4.6 | 128K vs 64K tokens |
| Production Readiness | Claude Opus 4.6 | GA vs Preview status |
Bottom line: Choose Gemini 3.1 Pro for budget-conscious projects, long-document processing, and multimodal tasks. Choose Claude Opus 4.6 for expert-level work, complex coding projects, and production deployments where stability matters.
Benchmark Comparison — What the Numbers Actually Mean

When Google announced that Gemini 3.1 Pro leads on 13 of 16 benchmarks, the natural reaction is to declare it the outright winner. But that interpretation misses a critical nuance: not all benchmarks matter equally for real-world applications, and the benchmarks where Claude Opus 4.6 wins happen to be the ones that correlate most strongly with production value. Understanding what each benchmark actually measures helps you determine which advantage matters for your specific workflow.
Reasoning: Where Gemini Shines Brightest
The ARC-AGI-2 benchmark evaluates a model's ability to solve entirely novel logic patterns — problems it has never seen during training. Gemini 3.1 Pro scored 77.1% here, compared to Claude Opus 4.6's 68.8%, representing an 8.3 percentage point gap (Google blog, February 19, 2026). This is genuinely impressive, especially considering Gemini 3 Pro scored only 31.1% on the same test, meaning Google more than doubled their model's abstract reasoning capability in a single update.
What this means in practice is that Gemini 3.1 Pro excels at problems requiring creative pattern matching — things like debugging unusual edge cases, identifying non-obvious data relationships, or solving optimization problems where the solution path is not immediately apparent. If your application involves complex analytical reasoning where the model needs to figure out novel approaches rather than apply known patterns, Gemini has a meaningful advantage.
The Humanity's Last Exam (HLE) benchmark tells a more nuanced story. Without access to external tools, Gemini leads 44.4% to 40.0%. But once tools are introduced, Claude Opus 4.6 pulls ahead at 53.1% versus Gemini's 51.4% (Artificial Analysis, February 2026). This reversal is significant because most production AI applications involve tool use — API calls, database queries, code execution, web searches. A model that performs better with tools is arguably more valuable in real deployments than one that performs better in isolation.
Coding: The Closest Battle
The coding benchmarks reveal the tightest competition between these two models. On SWE-Bench Verified, which evaluates a model's ability to resolve real GitHub issues by writing actual code patches, the scores are nearly identical: Gemini at 80.6% and Claude at 80.8% (Google announcement and Claude Opus 4.6 also outperforms GPT-5.3 in several benchmarks, February 2026). That 0.2 percentage point difference is statistically insignificant.
However, the story shifts when you look at Arena Coding leaderboards, where human evaluators rate model outputs in blind comparisons. Claude Opus 4.6 consistently ranks number one in human-preference coding evaluations, suggesting that while both models can solve the same problems, Claude produces code that developers actually prefer to work with — cleaner architecture, better documentation, and more maintainable patterns. Meanwhile, Gemini 3.1 Pro dominates the MCP Atlas benchmark at 69.2% versus Claude's 59.5%, indicating stronger performance in multi-step coding workflows that span multiple files and require coordinating changes across a codebase.
Expert Knowledge Work: Claude's Decisive Advantage
The GDPval-AA benchmark evaluates economically valuable knowledge work across finance, legal, and other professional domains. Here, Claude Opus 4.6 achieves 1606 Elo points while Gemini 3.1 Pro scores 1317 — a 289 Elo point gap that represents a substantial quality difference (Artificial Analysis, February 2026). To put this in perspective, a 289 Elo gap in chess would be the difference between a strong club player and a titled expert. In practical terms, this means Claude Opus 4.6 produces noticeably better output for tasks like financial analysis, legal document review, medical report interpretation, and strategic business analysis. If your application serves professional users who need expert-grade output quality, this is the most important benchmark to consider.
Pricing Breakdown — The Real Cost of Each Model

Pricing is where Gemini 3.1 Pro presents its strongest value proposition, offering comparable or superior performance at significantly lower cost. However, the pricing structure has nuances that affect total cost depending on how you use each model. All pricing below is verified from official sources as of February 20, 2026.
Per-token pricing comparison:
| Metric | Gemini 3.1 Pro Preview | Claude Opus 4.6 | Difference |
|---|---|---|---|
| Input (standard) | $2.00/1M tokens | $5.00/1M tokens | Gemini 2.5x cheaper |
| Output | $12.00/1M tokens | $25.00/1M tokens | Gemini 2.1x cheaper |
| Input (long context) | $4.00/1M (>200K) | Long-context pricing applies | Varies |
| Batch input | $1.00/1M tokens | Not available | Gemini only |
| Context caching | $0.20/1M tokens | Available with caching | Gemini cheaper |
Sources: Google AI pricing page, February 20, 2026; Anthropic official documentation, February 20, 2026.
The real-world cost impact depends on your usage volume. For a typical application processing 100 million tokens per month with a 3:1 input-to-output ratio, Gemini 3.1 Pro costs approximately $450 compared to Claude Opus 4.6 at roughly $1,000 — a savings of $550 per month or 55% less. At enterprise scale with 1 billion tokens monthly, Gemini saves approximately $5,500 per month. These savings compound significantly over time, and the availability of batch processing at 50% discount makes Gemini even more attractive for non-latency-sensitive workloads.
For developers working with both models, platforms like laozhang.ai provide unified API access to both Gemini and Claude models through a single endpoint, which simplifies integration and can offer additional cost optimizations compared to managing separate API accounts with Google and Anthropic. You can find a detailed breakdown of Gemini 3 API pricing and quotas in our dedicated guide.
It is worth noting that cost-per-token is only half the equation. Claude Opus 4.6 supports 128K output tokens — double Gemini's 64K limit — which means fewer API calls for tasks requiring long-form generation. If your workflow involves generating lengthy reports, complete code files, or extensive analyses, Claude's higher output ceiling can reduce the number of calls needed, partially offsetting its per-token price premium. For a deeper look at Claude Opus pricing structure, we have covered the full breakdown including batch discounts.
Context Window, Multimodal, and Technical Specs
The technical specifications beyond benchmarks reveal meaningful architectural differences that affect how you build applications with each model. These are not just numbers on a spec sheet — they determine what kinds of tasks each model can handle natively versus requiring workarounds.
Context Window: A Real Architectural Advantage
Gemini 3.1 Pro supports a native 1 million token context window, which translates to approximately 1,500 pages of text, an entire mid-size codebase, or several full-length novels processed simultaneously. Claude Opus 4.6 offers 200K tokens by default with a 1 million token beta available through a special header flag (Anthropic documentation, February 2026). While both models technically reach 1M tokens, Gemini's native support means more predictable performance and pricing at that scale.
The practical difference matters most for tasks involving large document sets. Consider a legal team analyzing a 500-page contract alongside 200 pages of precedent cases and regulatory guidance — that is well within Gemini's native context but requires careful management with Claude's standard 200K window. Similarly, developers analyzing entire codebases benefit from being able to load complete project structures without chunking, which avoids the information loss that comes with splitting context across multiple calls.
That said, Claude's 1M beta is actively available and works well in practice. The key differences are pricing (Anthropic applies long-context pricing above 200K tokens) and the fact that it requires opt-in via a beta header, suggesting it is still being refined. For most applications under 200K tokens — which covers the vast majority of use cases — both models perform comparably.
Multimodal Capabilities: Gemini's Unique Strength
Gemini 3.1 Pro is natively multimodal, processing text, images, audio, and video inputs within a single model architecture. Claude Opus 4.6 accepts text and images but cannot process audio or video content. This distinction matters if your application involves analyzing meeting recordings, processing podcast transcripts with audio context, understanding video content, or any workflow where information comes in non-text formats. Gemini handles these natively without requiring separate transcription or processing steps, which reduces both complexity and cost.
Output Limits and Speed
Claude Opus 4.6 supports up to 128K output tokens — double Gemini's 64K limit. This is a significant advantage for generative tasks where the model needs to produce lengthy, detailed output in a single call. Writing complete technical specifications, generating full documentation sets, or producing long-form content all benefit from Claude's higher output ceiling.
| Spec | Gemini 3.1 Pro Preview | Claude Opus 4.6 |
|---|---|---|
| Context window | 1M tokens (native) | 200K (1M beta) |
| Max output | 64K tokens | 128K tokens |
| Input modalities | Text, image, audio, video | Text, image |
| Output speed | ~107 tokens/sec | Moderate |
| Free tier | Not available | Not available |
| Status | Preview | Generally Available |
Which Model Should You Choose? A Decision Framework
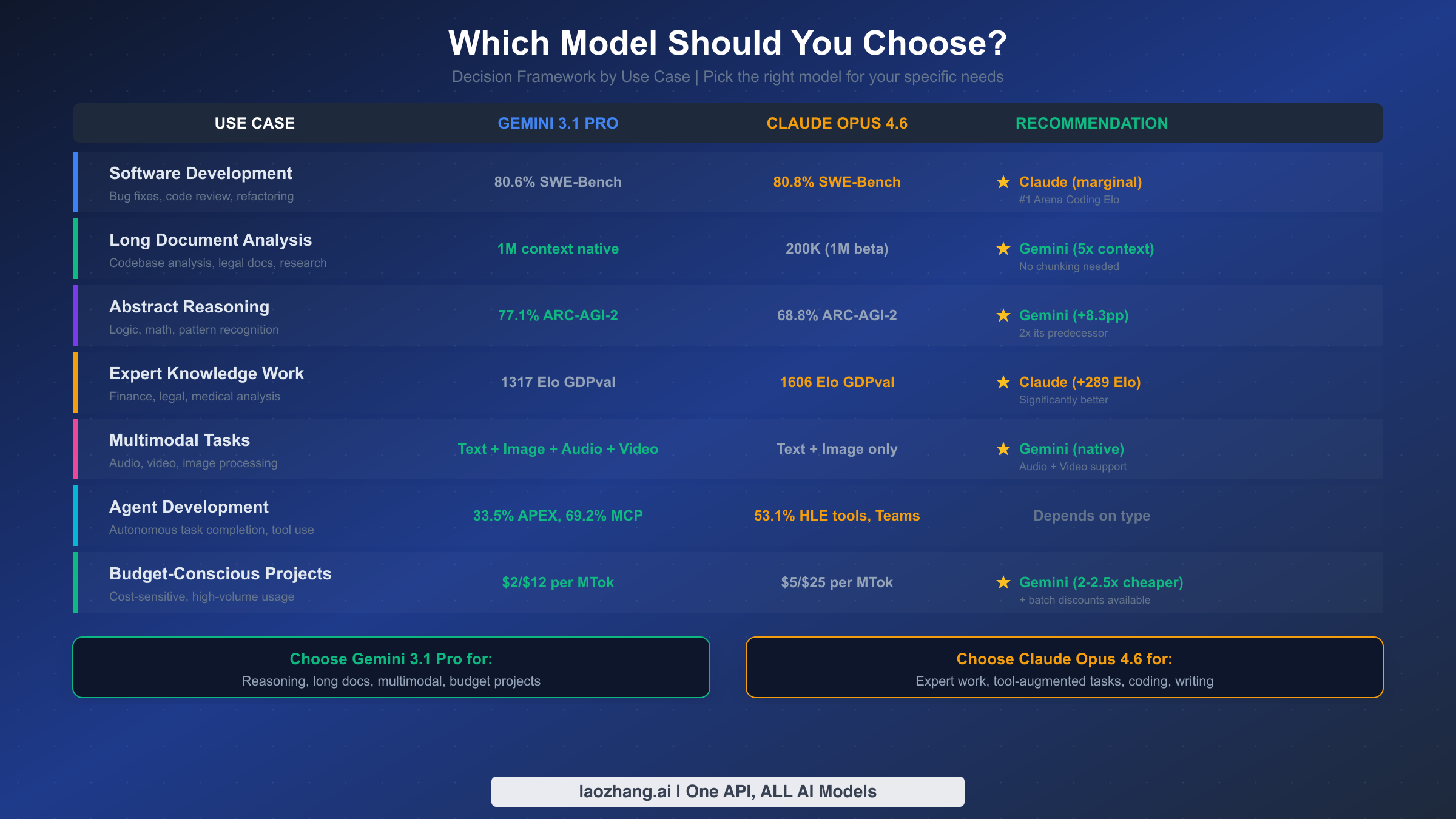
Rather than declaring one model universally "better," the most valuable approach is matching each model's strengths to your specific requirements. Both Gemini 3.1 Pro and Claude Opus 4.6 represent frontier-level intelligence, but they excel in different dimensions that map directly to different workflows. After analyzing the complete benchmark data and technical specifications, here is the decision framework that should guide your choice.
Choose Gemini 3.1 Pro Preview if your primary needs include:
Long document processing is central to your workflow. The native 1M token context window eliminates the need for document chunking, retrieval-augmented generation fallbacks, or multi-call strategies that lose context. If you regularly process legal documents, research papers, entire codebases, or lengthy datasets, Gemini's context advantage is genuine and meaningful. You can load an entire 50,000-line codebase and ask questions about cross-file dependencies without worrying about which chunks to include.
Budget efficiency matters to your project. At $2/$12 per million tokens compared to Claude's $5/$25, Gemini delivers comparable overall performance at roughly 55% less cost. For high-volume applications, startups operating on limited runway, or teams evaluating multiple models during development, the cost savings are substantial. The additional 50% batch processing discount makes offline workloads even more affordable.
Multimodal capabilities are required. If your application needs to process audio recordings, analyze video content, or handle mixed-media inputs, Gemini is currently the only frontier model offering native support for all four modalities. There is no need for separate transcription services or preprocessing pipelines — the model handles everything directly.
Abstract reasoning is a core requirement. For applications involving complex pattern matching, mathematical reasoning, or novel problem-solving where the model encounters scenarios unlike its training data, Gemini's 77.1% on ARC-AGI-2 represents a meaningful 8.3 percentage point advantage over Claude.
Choose Claude Opus 4.6 if your primary needs include:
Expert-level knowledge work quality is non-negotiable. If your application serves professionals in finance, law, medicine, or other expert domains, Claude's 289 Elo point advantage on GDPval-AA translates directly to better output quality. The difference between 1317 and 1606 Elo is the difference between "adequate" and "expert" grade output for professional analysis tasks. This matters when your users are domain experts who will notice quality shortcomings.
Tool-augmented workflows are central to your architecture. Claude Opus 4.6's advantage in HLE with tools (53.1% vs 51.4%) and its "agent teams" feature — where multiple agents split tasks and coordinate in parallel — make it the stronger choice for agentic applications. Anthropic has invested heavily in making Claude reliable for sustained, multi-step tool use, and this shows in practice.
Long-form content generation is frequent. Claude's 128K maximum output — double Gemini's 64K — means fewer API calls for tasks that produce lengthy results. Generating complete technical documentation, writing detailed reports, or producing full-length articles benefits from being able to complete the entire output in a single call without artificial truncation.
Production stability is critical. Claude Opus 4.6 is generally available, while Gemini 3.1 Pro is in Preview. For production applications where API stability, consistent behavior, and predictable performance are requirements, Claude's GA status provides stronger guarantees.
Preview vs GA — What It Means for Production Readiness
The distinction between Gemini 3.1 Pro's "Preview" status and Claude Opus 4.6's general availability is more than semantic — it has practical implications for production deployments that many comparison articles overlook entirely.
Google explicitly states that Gemini 3.1 Pro is being released in Preview to "validate these updates and continue to make further advancements in areas such as ambitious agentic workflows before they make it generally available soon" (Google blog, February 19, 2026). This language signals several things: the model API may experience changes to behavior, pricing, or rate limits before reaching GA. Applications built on the Preview API should account for the possibility of breaking changes, even if historically Google has been reasonably conservative about such disruptions.
For production systems with paying users, building on a Preview API introduces risk. If Gemini adjusts its response characteristics during the transition to GA, your application behavior could change without notice. This is not a reason to avoid Gemini entirely — many teams successfully run Preview models in production — but it does mean implementing version pinning, output validation, and fallback strategies as standard practice rather than optional precautions.
Claude Opus 4.6, released as a generally available model on February 5, 2026, provides the stability guarantees that come with GA status. Anthropic's model versioning system uses snapshot dates (e.g., claude-opus-4-6) to ensure consistent behavior, and deprecated models receive advance notice before retirement. For enterprises with compliance requirements, regulated industries, or applications where output consistency is legally relevant, this stability matters.
The typical Google preview-to-GA timeline for major model releases runs 4 to 8 weeks based on historical patterns. Gemini 3.1 Pro will likely reach GA by late March or early April 2026. For teams comfortable with Preview status and eager to leverage the performance advantages, the risk is manageable. For teams that need production guarantees today, Claude Opus 4.6 is the safer choice until Gemini reaches GA.
How to Access Both Models via API
Both models are available through their respective official APIs, major cloud platforms, and third-party providers. The setup process differs between providers, but the core integration patterns are similar.
Gemini 3.1 Pro Preview is accessible through Google AI Studio, the Gemini API, Vertex AI, and developer tools including Gemini CLI and Android Studio. The model ID is gemini-3.1-pro-preview in most API contexts. It is also available in GitHub Copilot as of February 19, 2026, making it immediately accessible to millions of developers without separate API setup. For developers exploring alternatives, our guide to the best alternatives for accessing the Gemini API covers additional options.
Claude Opus 4.6 is available through the Claude API (model ID: claude-opus-4-6), AWS Bedrock (anthropic.claude-opus-4-6-v1), Google Cloud Vertex AI, and Microsoft Azure Foundry. The model supports the standard Anthropic Messages API format with streaming, tool use, and vision capabilities.
For teams that want to use both models — which is increasingly common as organizations pick the best model per task — platforms like laozhang.ai provide unified API access with a single endpoint. This approach eliminates the need to manage separate authentication, billing, and SDK integrations for Google and Anthropic, letting you route requests to whichever model suits each specific task. The platform supports OpenAI-compatible API format, making it straightforward to switch between models with a simple model parameter change.
Quick integration example using the OpenAI-compatible format:
pythonimport openai client = openai.OpenAI( base_url="https://api.laozhang.ai/v1", api_key="your-api-key" ) response = client.chat.completions.create( model="gemini-3.1-pro-preview", messages=[{"role": "user", "content": "Analyze this dataset pattern..."}] ) # Use Claude Opus 4.6 for expert analysis response = client.chat.completions.create( model="claude-opus-4-6", messages=[{"role": "user", "content": "Review this legal contract..."}] )
Final Verdict and Recommendations
The competition between Gemini 3.1 Pro Preview and Claude Opus 4.6 reflects a broader truth about the current AI landscape: no single model dominates across every dimension. Google's engineering achievement with Gemini 3.1 Pro is remarkable — more than doubling reasoning performance while maintaining the same pricing is a rare combination of speed and value improvement. Anthropic's Claude Opus 4.6, meanwhile, has solidified its position as the model that professionals trust for expert-grade output and reliable tool-augmented workflows.
For most developers and teams, the best strategy in February 2026 is not choosing one model exclusively but building systems that can leverage both. Use Gemini 3.1 Pro for tasks where its advantages are clear: long-document processing, multimodal inputs, high-volume workloads, and abstract reasoning challenges. Use Claude Opus 4.6 where quality at the expert level matters most: professional analysis, complex coding with nuanced requirements, and agentic workflows that require sophisticated tool coordination.
The pricing gap makes this dual-model approach even more attractive. By routing budget-sensitive, high-volume tasks to Gemini and reserving Claude for tasks where its quality premium justifies the cost, teams can optimize both performance and spending. This is not a compromise — it is the genuinely optimal strategy when two frontier models excel at complementary tasks.
If you must choose one model today: pick Gemini 3.1 Pro if budget and multimodal capability drive your decision, or pick Claude Opus 4.6 if expert output quality and production stability are your priorities. Both are excellent choices — the question is which kind of excellence matters more for your specific project.
Frequently Asked Questions
Is Gemini 3.1 Pro Preview better than Claude Opus 4.6?
It depends on the task. Gemini leads on 13 of 16 benchmarks including reasoning (77.1% vs 68.8% ARC-AGI-2) and costs 2-2.5x less. However, Claude Opus 4.6 significantly outperforms Gemini on expert knowledge work (1606 vs 1317 Elo) and tool-augmented reasoning. Neither model is universally better — the right choice depends on your use case.
How much cheaper is Gemini 3.1 Pro compared to Claude Opus 4.6?
Gemini 3.1 Pro costs $2/$12 per million input/output tokens compared to Claude's $5/$25 (Google AI and Anthropic official pricing, February 2026). This makes Gemini roughly 2.5x cheaper on input and 2.1x cheaper on output. For a workload of 100M tokens per month, Gemini saves approximately $550 per month.
Can Gemini 3.1 Pro process audio and video?
Yes. Gemini 3.1 Pro is natively multimodal, supporting text, image, audio, and video inputs. Claude Opus 4.6 currently supports text and image inputs only. This makes Gemini the better choice for applications that need to analyze meeting recordings, video content, or audio data.
Is Gemini 3.1 Pro Preview safe to use in production?
Gemini 3.1 Pro is in Preview status, which means the API may change before reaching general availability. Many teams use Preview models in production successfully, but you should implement version pinning and fallback strategies. GA is expected within 4-8 weeks based on historical Google timelines.
Which model is better for coding?
Both models score nearly identically on SWE-Bench Verified (80.6% vs 80.8%). Claude Opus 4.6 ranks #1 on Arena Coding leaderboards for human-preference evaluations, suggesting it produces code that developers prefer. Gemini 3.1 Pro leads on MCP Atlas (69.2% vs 59.5%) for multi-step coding workflows. For most coding tasks, either model will perform excellently.