
Start by checking whether you actually need to leave Gemini. If your workload already fits Gemini 2.5 Flash-Lite pricing and Gemini's multimodal surface, switching vendors may save less money than the SERP suggests.
The more useful question is which alternative is cheaper for your real workload and what you lose when you move. For pure text generation, some routes beat Gemini on price. For multimodal coverage, simpler vendor consolidation, or staying inside Google's current API surface, Gemini often remains the better default.
Key Takeaways
The short version is simple: stay on Gemini if you want the cheapest current stable Gemini lane or you need broad multimodal support; switch only when a text-first workload, quota pain, or a different vendor ecosystem matters more than staying inside Google.
| Option | Current price | When it is the cheapest sensible pick | Main tradeoff |
|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 input / $0.40 output | Cheapest current stable Gemini route for text, image, video, and Google-native tooling | Still subject to Google project quotas and billing behavior |
| Gemini 3.1 Flash-Lite Preview | $0.25 input / $1.50 output | Only if you specifically want the newer Gemini 3 preview lane at lower cost than Gemini 3 Flash | Newer, but not cheaper than 2.5 Flash-Lite |
| DeepSeek-V3.2 | $0.28 input / $0.42 output | Low-cost reasoning or text workloads where Google multimodality does not matter | Not actually cheaper than Gemini 2.5 Flash-Lite on output |
| Mistral Small 3.2 | $0.10 input / $0.30 output | Cheap hosted API with lower output cost than Gemini and a cleaner EU-hosted story | 128K context and a narrower product surface |
| Groq cheap text models | $0.05/$0.08 for Llama 3.1 8B, $0.075/$0.30 for GPT OSS 20B | Very cheap high-throughput text generation | Not a real drop-in replacement for Gemini's multimodal API |
| OpenAI GPT-5.4 nano | $0.20 input / $1.25 output | OpenAI flagship low-cost option when ecosystem compatibility matters more than raw price | Standard output is still materially pricier than Gemini, Mistral, and Groq |
| Claude Haiku 4.5 | $1 input / $5 output | Only when you want Anthropic behavior or tooling, not when you want the cheapest API | Nowhere near the cheap end of the market |
If you only need Google's own cheapest path, read our full Gemini API pricing guide. If your real problem is quota behavior rather than price, start with our Gemini API rate limit explainer.
Why “Cheap Gemini API” And “Gemini API Alternative” Are Not The Same Search
Most ranking pages treat these as the same question, but they are not. A developer searching for "cheap Gemini API" is often asking one of three things:
- What is the cheapest Gemini model I can use right now?
- Is there another provider that is cheaper than Gemini for my workload?
- Is Gemini's free or paid quota behavior unreliable enough that I should route some traffic elsewhere?
Those are different problems. The first is solved by Google's own pricing page. The second needs a cross-vendor price comparison. The third is about operations, not just token math.
This is why page one feels unsatisfying. Some results are consumer "Gemini alternatives" roundups comparing chat subscriptions. Some are vendor directories listing ten or fifteen APIs with shallow "best for" labels. Some are official Google docs that tell you the rates but not whether switching vendors is worth the engineering cost. None of those patterns cleanly answer the real developer decision.
The right way to think about the query is this: keep Gemini unless another provider is cheaper for your exact workload and still good enough at the features you actually use. That sounds obvious, but page one usually starts from the opposite assumption.
The Cheapest Current Gemini Options In March 2026
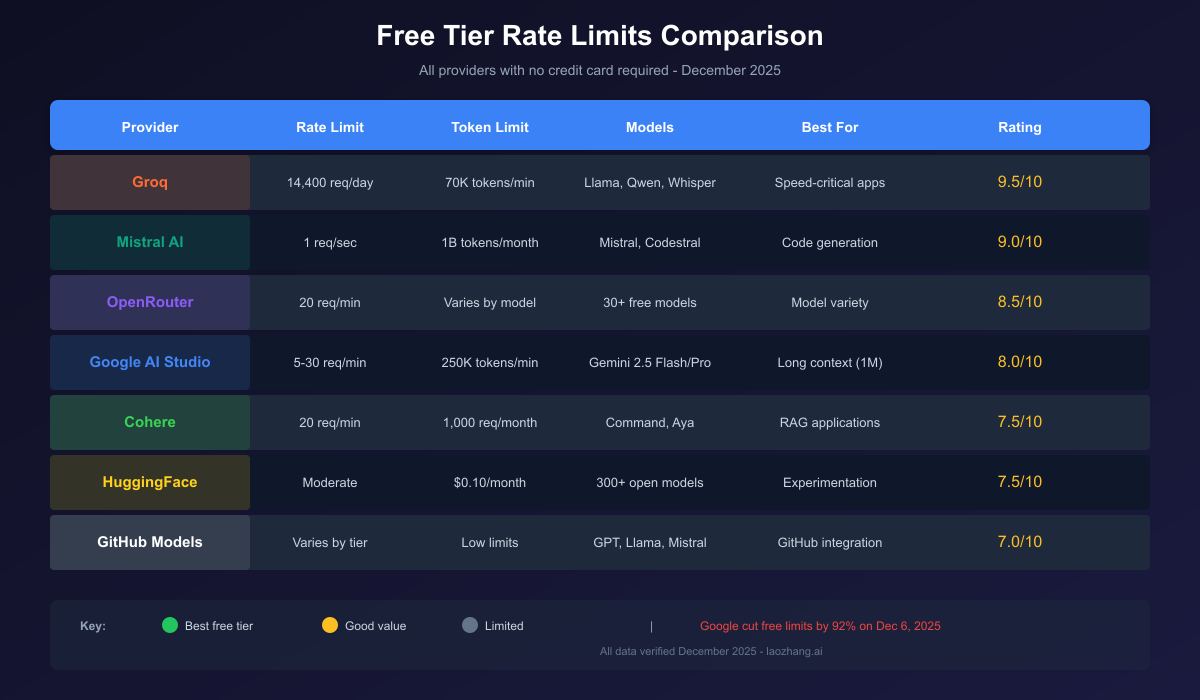
The cheapest current stable Gemini lane is Gemini 2.5 Flash-Lite. Google's official pricing page lists it at $0.10 input / $0.40 output per 1M tokens, with batch pricing at $0.05 / $0.20. That matters because many "cheap Gemini API" searches are really just trying to avoid accidentally paying Gemini 3 preview prices when a lighter stable model would already solve the job.
The newer preview lanes are not the cheap answer. Google lists Gemini 3.1 Flash-Lite Preview at $0.25 / $1.50, and Gemini 3 Flash Preview at $0.50 / $3.00. Those are legitimate model choices if you want the newer Gemini 3 family, but they are not budget substitutes for 2.5 Flash-Lite. In other words, "newer Gemini" and "cheaper Gemini" have diverged.
Google also still shows Gemini 2.0 Flash-Lite at $0.075 / $0.30, which is even cheaper on paper. But there is an important catch: the same pricing page says that model is deprecated and scheduled to shut down on June 1, 2026. That makes it a bad lead recommendation for anyone starting a new integration in late March 2026. Cheap and dying is not the same thing as cheap and safe.
Paid Gemini is also more flexible than some alternatives pages suggest. Google's pricing page says the paid tier adds higher rate limits, context caching, and Batch API access with a 50% cost reduction. That means the right cost comparison is not just list price versus list price. If your workload is asynchronous, repeated, or heavy on shared prompts, Google's own cost optimization tools can move Gemini closer to the cheapest route without changing vendors.
There is another underappreciated point here: Google already supports an OpenAI-compatible endpoint. The official compatibility guide says you can use OpenAI libraries by changing three lines of code and pointing the base URL to the Gemini endpoint. That reduces the migration argument for leaving Gemini purely because your codebase uses OpenAI SDKs today.
The Cost Mistakes That Make Gemini Look More Expensive Than It Is
The most common pricing mistake is comparing the wrong Gemini lane. If you compare Gemini 3 Flash Preview to Groq Llama 3.1 8B or Mistral Small 3.2, Gemini will obviously look expensive. But that is not a fair routing decision. Gemini 3 Flash Preview is Google's faster, more capable preview lane. The better cheap comparison is usually Gemini 2.5 Flash-Lite versus other budget models, and that picture is much tighter.
The second mistake is comparing multimodal pricing to text-only pricing as if they were interchangeable. Groq's cheap text models are excellent if you just need text generation, classification, or extraction. They are not solving the same problem as a Gemini route that may need image input, video input, search grounding, or one unified API surface. A cheaper text model is only a true savings if it does not force you to bolt on other vendors later.
The third mistake is ignoring batch and caching economics. Google's pricing page makes it explicit that the paid tier includes context caching and a Batch API that cuts cost by 50%. That matters most in production systems with repeated system prompts, long shared context, or asynchronous jobs. A provider that looks slightly cheaper on standard pricing can stop looking cheaper once Gemini's batch and caching tools enter the math.
The fourth mistake is treating quota pain as token-price pain. Many developers first search for "Gemini alternatives" after a 429 error, which makes them emotionally overweight nominal price and underweight operational behavior. But a quota problem is not proof that another provider is cheaper in production. It is proof that your current route may need billing activation, a different project setup, or partial traffic offload to another provider.
The fifth mistake is forgetting the migration tax. If leaving Gemini means rewriting SDK calls, changing observability, retraining prompts, or reworking multimodal assumptions, then a cheaper per-token price can still lead to a more expensive project. Google's OpenAI-compatible endpoint lowers that tax on the Gemini side, while a split-route architecture can lower it on the alternative side by moving only the cheapest text traffic first.
Which Alternatives Are Actually Cheaper Than Gemini
If your workload is mostly text and you do not care much about Gemini's broader multimodal surface, some alternatives really do beat Gemini 2.5 Flash-Lite. But the winners are narrower than most listicles imply.
| Provider or model | Current price | Cheaper than Gemini 2.5 Flash-Lite? | Best fit |
|---|---|---|---|
DeepSeek-V3.2 (deepseek-chat) | $0.28 input / $0.42 output | No on output, no on input | Cheap text and reasoning when you want DeepSeek specifically |
| Mistral Small 3.2 | $0.10 input / $0.30 output | Yes on output, tied on input | Low-cost hosted API with a cleaner EU story |
| OpenAI GPT-5.4 nano | $0.20 input / $1.25 output | No on output, no on input | OpenAI ecosystem convenience |
| Claude Haiku 4.5 | $1 input / $5 output | No | Premium alternative, not a cheap one |
| Groq Llama 3.1 8B | $0.05 input / $0.08 output | Yes | Very cheap, fast text-only or tool-light traffic |
| Groq GPT OSS 20B | $0.075 input / $0.30 output | Yes | Cheap higher-capability text routing |
DeepSeek-V3.2 is the provider many developers expect to dominate this comparison, but its official pricing shows a subtler picture. DeepSeek lists $0.28 per 1M input tokens on cache miss and $0.42 per 1M output tokens. That is much cheaper than Gemini 3 Flash Preview, but it is not cheaper than Gemini 2.5 Flash-Lite on output. DeepSeek is a serious budget alternative, just not the automatic "Gemini but cheaper" answer that some searchers assume.
Mistral Small 3.2 is more interesting for this keyword than it looks at first glance. Its official model page lists $0.10 input / $0.30 output with 128K context. That means it matches Gemini 2.5 Flash-Lite on input and beats it on output. If your workload is mostly classification, summarization, light generation, or structured text tasks, Mistral is one of the cleanest cheap alternatives available from an official hosted API.
OpenAI GPT-5.4 nano looks attractive if your team lives inside OpenAI tooling, but the pricing tradeoff is easy to miss. OpenAI's developer pricing page now lists $0.20 input, $0.02 cached input, and $1.25 output for standard pricing. That makes GPT-5.4 nano a workflow convenience play rather than a serious price leader against Gemini 2.5 Flash-Lite, Mistral Small 3.2, or Groq's cheap text models.
Claude Haiku 4.5 belongs in the comparison only to prevent a common mistake. Anthropic's official pricing puts it at $1 input / $5 output, which makes it a quality or platform choice, not a cheap alternative. If a page recommends Claude inside a "cheap Gemini API" article without saying that plainly, it is doing shopping-content theater rather than helping you cut cost.
Groq is where the most aggressive cheap text routing shows up. Groq's official models page lists Llama 3.1 8B at $0.05 / $0.08 and GPT OSS 20B at $0.075 / $0.30, both with 1K RPM on the developer plan. Those are impressive prices, especially if you care about raw text throughput. But you should read them correctly: Groq is a cheap text and inference-speed alternative, not a replacement for Gemini's full multimodal and grounding stack.
The pattern is consistent. If you only need cheap text, Gemini can be beaten. If you need one low-cost API that still covers text, image, video, and Google-native tools, Gemini 2.5 Flash-Lite remains hard to dislodge.
Cost Is Not The Only Reason People Leave Gemini
Price is only part of this search. A lot of "Gemini alternatives" demand is really quota frustration demand.
Google's official rate-limits page says quotas apply per project, not per API key, that requests per day reset at midnight Pacific, and that active limits are viewed in AI Studio rather than through a simple static public chart. The same page also says preview and experimental models have more restrictive rate limits and that actual capacity can vary. That is already enough to explain why developers sometimes feel like the cheap route is less predictable than the pricing table implies.
The community side makes the problem more obvious. In one Google AI Developers Forum thread, users describe new free-tier projects returning immediate 429 RESOURCE_EXHAUSTED errors even at very low request frequency. In another paid Tier 1 forum thread, users report paid projects still hitting free-tier quota metrics. Those threads are not official pricing documents, but they do explain why some developers stop treating this as a simple price comparison.
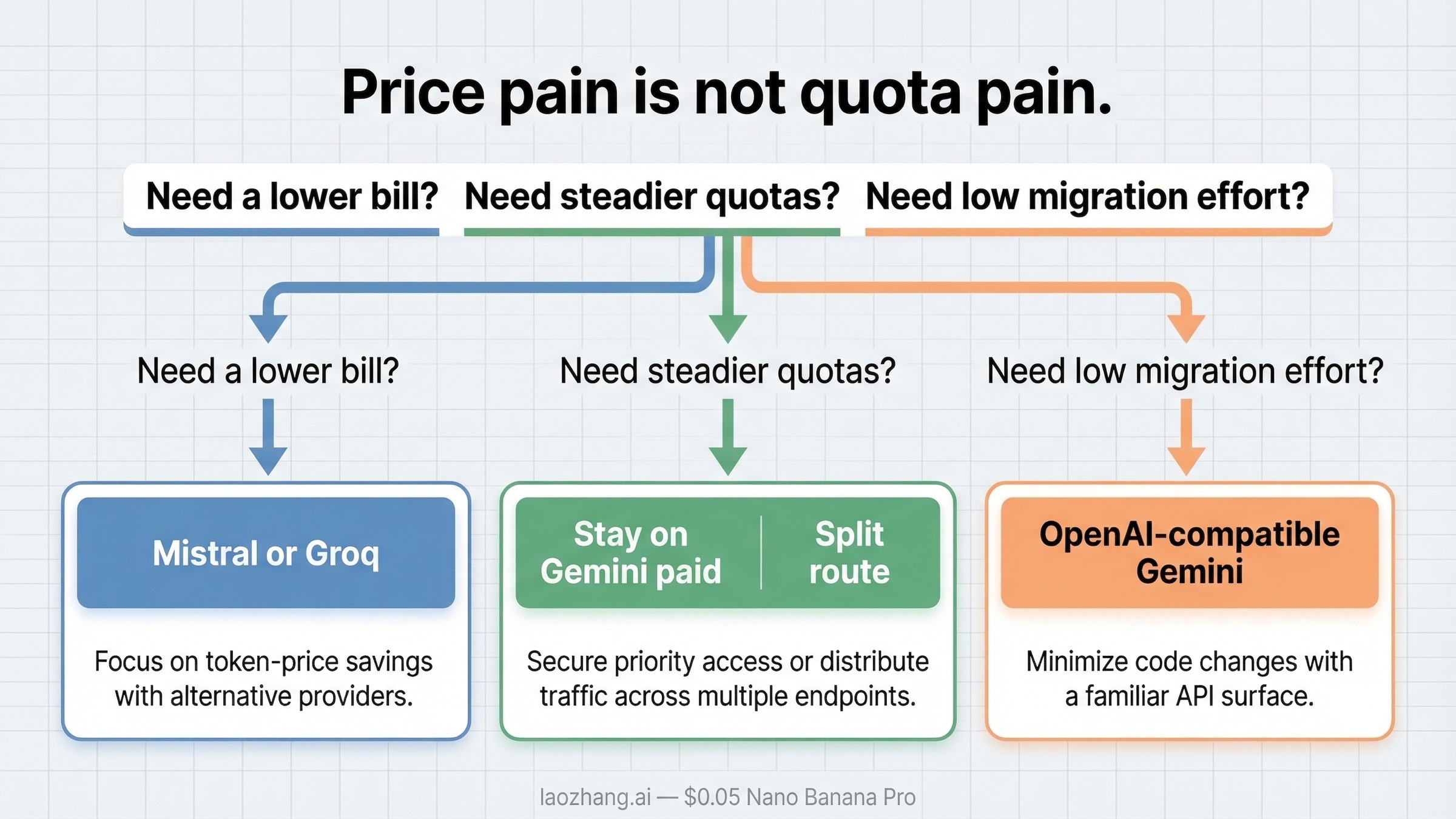
That operational layer changes the recommendation:
- If your real problem is nominal cost, compare token prices first.
- If your real problem is unpredictable quota behavior, compare quota stability and routing options before you compare pennies per million tokens.
- If your real problem is migration effort, remember that Gemini already supports an OpenAI-style API surface, so leaving Google is not the only way to keep OpenAI-library code patterns.
This is also why a "best alternative" list often feels wrong in practice. The best alternative for a batch-heavy, text-only pipeline is not the same as the best alternative for a multimodal app that occasionally gets 429 spikes on new projects.
If you are still trying to make Gemini cheaper before switching, look at Gemini context caching cost reduction and the current Gemini free quota situation. Those two guides usually matter more than another vendor directory when the real question is "can I keep this architecture and spend less?"
What To Use In Real Workloads
The most useful answer is not "here are five APIs." It is "here is what to route where."
If you want the cheapest current stable multimodal default, use Gemini 2.5 Flash-Lite. It is still the cleanest low-cost path when your app mixes text with image, audio, or video inputs and you want one vendor surface.
If you want the cheapest pure text generation path, use Groq-hosted low-cost text models or Mistral Small 3.2, depending on whether you care more about absolute token price or a more conventional hosted-model developer experience. Groq wins harder on raw text cost. Mistral feels more like a classic hosted API alternative.
If you want the cheapest text-plus-reasoning alternative that many teams already evaluate, check DeepSeek-V3.2, but do not assume it beats Gemini 2.5 Flash-Lite on every cost dimension. It does not. DeepSeek makes more sense when you prefer its model behavior or ecosystem, not when you are chasing the very lowest output price.
If you want to keep an OpenAI-style SDK workflow, do not assume the answer is OpenAI by default. Gemini's OpenAI compatibility layer means you can often keep the same calling style while staying on Gemini. OpenAI nano is reasonable when the ecosystem matters more than raw token price, but it is not the cheapest output path.
If your pain is mostly quota friction, the best move is often a split route. Keep Gemini for multimodal or Google-specific jobs, but send cheap text traffic to Mistral, Groq, or DeepSeek. That reduces the blast radius of Gemini quota issues without forcing a full platform exit.
If you want one broader cost framework across the big vendors, our Gemini vs OpenAI vs Claude cost guide goes deeper on how these routes compare once you add context length, batch pricing, and premium-model tradeoffs.
FAQ
What is the cheapest Gemini API right now?
As of March 21, 2026, the cheapest current stable Gemini API is Gemini 2.5 Flash-Lite at $0.10 input / $0.40 output per 1M tokens on the paid tier. Gemini 2.0 Flash-Lite is cheaper on paper, but it is deprecated and scheduled to shut down on June 1, 2026.
What is the cheapest Gemini API alternative for text-only workloads?
For raw text cost, Groq-hosted low-cost text models are the cheapest among the officially verified options in this article. Mistral Small 3.2 is the most balanced low-cost hosted alternative if you want something closer to a standard model API.
Is Gemini 3.1 Flash-Lite cheaper than Gemini 2.5 Flash-Lite?
No. Google's official pricing shows Gemini 3.1 Flash-Lite Preview at $0.25 / $1.50, while Gemini 2.5 Flash-Lite is $0.10 / $0.40. The newer preview lane is not the cheaper lane.
Do I need to leave Gemini to keep using OpenAI libraries?
No. Google says Gemini models are available through OpenAI libraries by changing the base URL and a few configuration lines. That means SDK compatibility alone is not a strong reason to switch vendors.
When should I switch away from Gemini even if the token price looks good?
Switch or split-route when your workload is mostly text, when you keep hitting quota or project-tier friction, or when a different hosted model better matches your operational needs. Do not switch just because "alternative" pages exist. Switch when another provider is cheaper and still fits the job.