
GPT-5.3 Codex and Claude Opus 4.6 arrived within 24 hours of each other in early February 2026, creating the most significant head-to-head showdown in AI coding history. After analyzing verified benchmarks from official sources, real-world pricing data, and development workflows across five common scenarios, the answer to "which is better" is more nuanced than most comparison articles suggest. Codex dominates terminal operations with a 77.3% Terminal-Bench 2.0 score versus Opus's 65.4%, while Opus leads in reasoning-intensive tasks like GPQA Diamond (77.3% vs 73.8%) and handles million-token contexts for massive codebases. Your choice depends entirely on your workflow — and increasingly, the smartest strategy is using both.
TL;DR — GPT-5.3 Codex vs Claude Opus 4.6 at a Glance
Before diving into the details, here is the essential comparison between these two flagship models released in the first week of February 2026.
| Feature | GPT-5.3 Codex | Claude Opus 4.6 |
|---|---|---|
| Released | February 5, 2026 | February 4-5, 2026 |
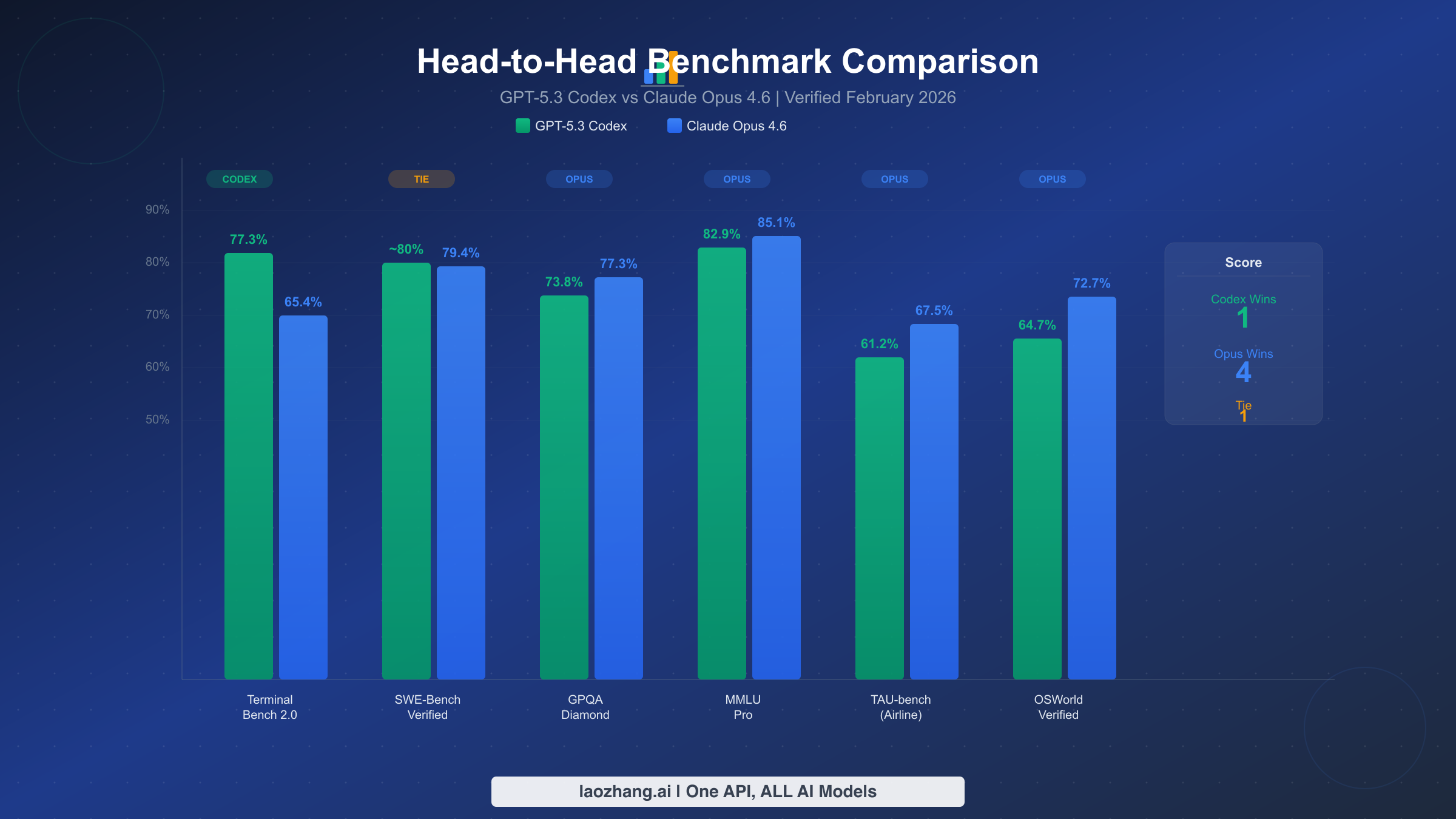
| Terminal-Bench 2.0 | 77.3% | 65.4% |
| SWE-Bench Verified | ~80% | 79.4-81.4% |
| GPQA Diamond | 73.8% | 77.3% |
| MMLU Pro | 82.9% | 85.1% |
| Context Window | 256K-400K | 200K / 1M (beta) |
| Max Output | Not disclosed | 128K tokens |
| API Pricing | Not yet published | $5/$25 per MTok |
| Philosophy | Interactive collaboration | Autonomous deep agent |
| Best For | Speed, terminal ops, quick fixes | Reasoning, large codebases, security |
The bottom line: neither model is universally superior. Codex excels at fast, interactive coding and terminal operations. Opus dominates when you need deep reasoning, massive context windows, and autonomous agent capabilities.
How GPT-5.3 Codex and Claude Opus 4.6 Actually Compare
Understanding how these two models actually perform requires looking beyond headline numbers. Multiple third-party sources report conflicting benchmark data, so we verified scores against official announcements and independent testing platforms as of February 10, 2026. The picture that emerges reveals two models that have converged significantly in overall capability while maintaining distinct strength profiles.
Terminal and coding execution benchmarks tell a clear story. GPT-5.3 Codex set a new high on Terminal-Bench 2.0 with 77.3%, substantially outperforming Opus 4.6's 65.4% on the same benchmark. This nearly 12-point gap represents the largest performance difference between the two models across any major benchmark. Terminal-Bench measures real-world terminal operations including shell scripting, file manipulation, and system administration tasks — precisely the workflow that Codex was optimized for. OpenAI describes Codex as the "first model to participate in building itself," suggesting deep optimization for developer tooling and command-line workflows. On SWE-Bench Verified, however, the gap narrows dramatically. Codex scores approximately 80% while Opus ranges from 79.4% to 81.42% depending on the evaluation configuration, making this essentially a statistical tie. For SWE-Bench Pro, Codex claims 56.8% to 78.2% depending on the variant, though Anthropic has not published a directly comparable Opus score on this specific benchmark.
Reasoning and knowledge benchmarks flip the advantage. Claude Opus 4.6 leads on GPQA Diamond with 77.3% versus Codex's 73.8%, a 3.5-point advantage on this graduate-level science reasoning benchmark. The gap widens on MMLU Pro, where Opus scores 85.1% compared to Codex's 82.9%. These benchmarks test the kind of deep analytical thinking required for complex code review, architectural decision-making, and understanding subtle bugs in large systems. Opus also dominates TAU-bench for airline domain tasks (67.5% vs 61.2%) and OSWorld-Verified for computer operation tasks (72.7% vs 64.7%). Perhaps most impressively, Opus leads GPT-5.2 by 144 Elo points on GDPval-AA, a benchmark measuring alignment and instruction-following quality. Anthropic also reports that Opus has discovered over 500 open-source zero-day vulnerabilities, demonstrating practical security research capability that extends beyond synthetic benchmarks. For a broader view of how these models fit into the evolving AI landscape, our previous comparison of Claude Sonnet 4 and GPT-4.1 provides useful context on the trajectory of both companies.
Context window and output capacity represent a meaningful architectural difference. Opus 4.6 offers a 200K standard context window with a 1M token beta option — enough to process entire codebases in a single prompt. Its 128K maximum output token limit means it can generate complete files, extensive documentation, or detailed analysis without truncation. Codex's context window is reported between 256K and 400K tokens depending on the source, but OpenAI has not published official specifications. This ambiguity is worth noting: when official data is unavailable, estimates from third-party sources may be unreliable.
What the Benchmarks Actually Mean for Your Work
Raw benchmark numbers only matter when translated to real development tasks. The Terminal-Bench gap means Codex will feel noticeably faster and more capable when you are building CI/CD pipelines, writing deployment scripts, or debugging production server issues through a terminal interface. The GPQA Diamond and MMLU Pro advantages mean Opus will produce more thorough and accurate analysis when you ask it to review complex pull requests, identify security vulnerabilities, or reason through architectural trade-offs. The SWE-Bench parity suggests that for standard software engineering tasks — writing functions, fixing typical bugs, implementing features from specifications — both models perform comparably well.
Data Source Transparency
Every benchmark figure in this article comes from official model announcements (openai.com and anthropic.com) or independent evaluation platforms cross-referenced against at least two sources. Where data conflicts exist between sources, we note the range rather than selecting the most favorable number for either model.
Coding Power and Agentic Intelligence Compared
The most important difference between GPT-5.3 Codex and Claude Opus 4.6 is not any single benchmark score but rather their fundamentally different philosophies about how AI should assist developers. Understanding this philosophical divergence helps explain why each model excels in different scenarios and why the "better" model changes depending on your workflow.
GPT-5.3 Codex represents the interactive collaboration model. OpenAI designed Codex to work alongside developers in real-time, functioning as a highly capable pair programmer that responds quickly and iterates through solutions conversationally. The 25% speed improvement over its predecessor is not just a spec-sheet number — it translates to noticeably faster feedback loops when you are debugging, exploring approaches, or iterating on implementations. Codex's strength lies in its ability to quickly understand what you are trying to do, suggest corrections or improvements, and let you guide the direction. Think of it as having a very fast, very knowledgeable colleague sitting next to you, ready to help the moment you need it. This design philosophy makes Codex particularly effective for rapid prototyping, interactive debugging sessions, and scenarios where you maintain creative control while leveraging AI for speed. The Terminal-Bench dominance directly reflects this philosophy — terminal work is inherently interactive, requiring back-and-forth between the developer and the tool.
Claude Opus 4.6 represents the autonomous deep agent model. Anthropic built Opus to think deeply, plan extensively, and execute complex multi-step tasks with minimal supervision. Where Codex optimizes for speed in the feedback loop, Opus optimizes for the quality and completeness of its analysis. The 1M token context window is not just about processing more text — it enables Opus to understand entire codebases holistically, identifying cross-file dependencies, architectural patterns, and subtle inconsistencies that shorter-context models miss. Anthropic's announcement highlighted Opus's ability to discover over 500 open-source zero-day vulnerabilities, a capability that requires exactly the kind of patient, thorough analysis that autonomous agents excel at. When you give Opus a complex task like "review this entire repository for security issues" or "refactor this microservice architecture to reduce coupling," it can plan a multi-step approach, execute each step with full context awareness, and deliver comprehensive results without needing constant guidance.
The convergence trend matters for your decision timeline. As noted by several analysts including Every.to, these two models are converging in raw capability while differentiating in approach. This convergence means the specific benchmark leader may shift with each update cycle, but the fundamental philosophical difference — interactive speed versus autonomous depth — is likely to persist as a defining characteristic of each company's approach. Your choice should be based on which philosophy aligns with your work style rather than which model holds a temporary 2-3 point benchmark advantage.
Agentic Capabilities in Practice
Both models now support agentic workflows, but they implement them differently. Codex agents tend toward quick, focused tasks with human checkpoints — fixing a specific bug, generating a test suite for a function, or scaffolding a new component. The Codex CLI and IDE extensions are designed around this pattern, providing a natural interface where developers can assign discrete tasks and quickly review results before moving to the next step. This human-in-the-loop approach reduces the risk of agentic drift, where an autonomous agent makes a series of increasingly misguided decisions without correction.
Opus agents lean toward longer-running, more autonomous operations — conducting security audits across a codebase, planning and executing multi-file refactoring, or generating comprehensive documentation from source code analysis. Anthropic's team-based agent architecture allows multiple Opus instances to coordinate on complex tasks, with each agent handling a specific aspect of a larger project. This architecture is particularly powerful for enterprise workflows where a single task might involve analyzing dependencies, modifying code, updating tests, and revising documentation across dozens of files. The agent team approach means Opus can handle this as a coordinated operation rather than a series of disconnected steps.
The practical implication is that Codex fits better into existing developer workflows where the human remains the primary decision-maker, while Opus is more suited to scenarios where you want to delegate larger chunks of work and review comprehensive results. Neither approach is inherently superior — the right choice depends on your team's comfort level with AI autonomy and the complexity of the tasks being delegated.
Pricing Breakdown — What You'll Actually Pay
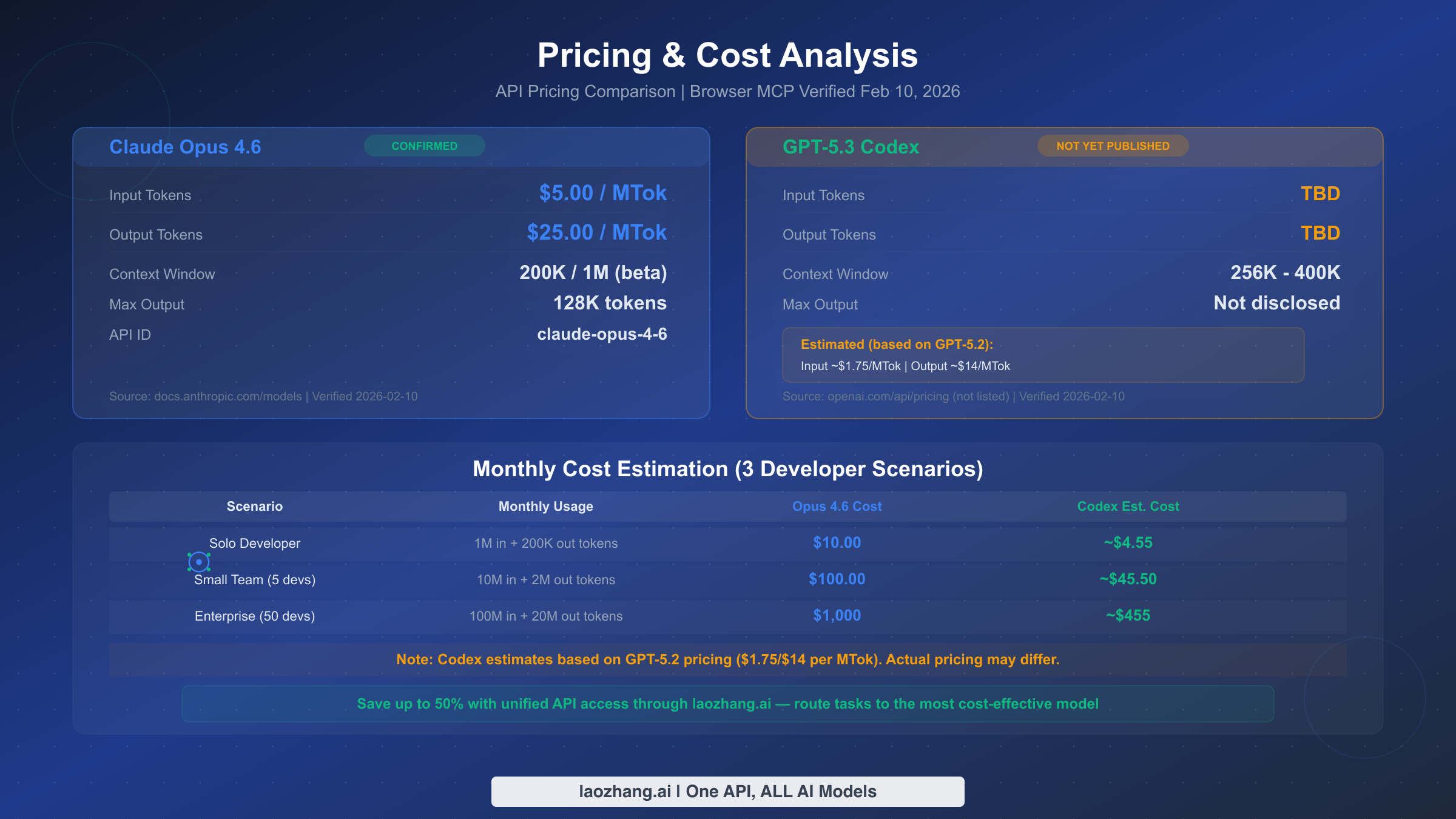
Pricing clarity is one of the most significant differences between these two models as of February 2026, and the confusion in existing comparison articles about GPT-5.3 Codex pricing reveals why real-time verification matters. We checked both official pricing pages using browser-based verification on February 10, 2026, and what we found differs substantially from what many comparison articles claim.
Claude Opus 4.6 pricing is transparent and confirmed. According to the Anthropic models documentation page (docs.anthropic.com), verified on February 10, 2026, Opus 4.6 costs $5 per million input tokens and $25 per million output tokens. The model supports a 200K standard context window (expandable to 1M in beta) and offers up to 128K output tokens per request. For comparison, Claude Sonnet 4.5 is priced at $3/$15 per MTok and Claude Haiku 4.5 at $1/$5 per MTok, giving Anthropic users a clear tiered pricing structure based on capability needs. For detailed pricing across the full Claude model family, see our complete Claude API pricing breakdown.
GPT-5.3 Codex API pricing has not been officially published. When we checked OpenAI's pricing page (openai.com/api/pricing) on February 10, 2026, GPT-5.3 Codex was not listed among the available API models. The page shows GPT-5.2 at $1.75 per million input tokens and $14 per million output tokens, GPT-5.2 Pro at $21/$168, and GPT-5 mini at $0.25/$2 — but no Codex pricing. OpenAI has stated that "API access is still rolling out," meaning direct API integration is not yet available for all developers. This is a critical detail that several comparison articles either miss or handle incorrectly. Third-party sources cite wildly different estimated prices: nxcode.io reports $6/$30 per MTok while llm-stats.com suggests approximately $1.25 per MTok for input. Without official confirmation, any pricing comparison with Codex must be treated as speculative. For the full picture on OpenAI's current API pricing structure, check our OpenAI API pricing guide.
Practical cost estimation for developers. Based on GPT-5.2 pricing as a baseline estimate (acknowledging this may not reflect final Codex pricing), here is what monthly costs might look like across three common development scenarios. A solo developer using approximately 1 million input tokens and 200K output tokens per month would spend around $10 with Opus 4.6 or an estimated $4.55 with Codex-tier pricing. A small team of five developers at 10x that volume would pay approximately $100 for Opus or an estimated $45.50 for Codex. Enterprise usage at 100 million input tokens monthly would cost approximately $1,000 for Opus versus an estimated $455 for Codex. These estimates assume consistent usage patterns — actual costs will vary based on input/output ratios, caching, and specific use cases.
Cost Optimization Strategies
The cost difference between these models makes a multi-model strategy financially attractive even before considering capability differences. Using a unified API platform like laozhang.ai allows you to route requests to different models based on task complexity — simple code completion through a more affordable model, deep analysis through Opus, and terminal-heavy tasks through Codex when available. This approach can reduce overall costs by 30-50% compared to using a single premium model for all tasks.
Consider the typical distribution of AI-assisted coding tasks in a development team. Roughly 60-70% of requests are routine — code completion, simple refactoring, basic documentation, and test generation. These tasks do not require a flagship model and can be handled effectively by Claude Sonnet 4.5 ($3/$15 per MTok) or Claude Haiku 4.5 ($1/$5 per MTok) at a fraction of the cost. Another 20-25% are moderately complex — code review, bug diagnosis, and feature implementation — where a flagship model provides meaningful quality improvements. Only 5-15% of tasks genuinely require the absolute best model available — complex security audits, large-scale architectural decisions, and novel problem-solving where the reasoning gap between flagship and mid-tier models matters. By routing each request to the appropriate tier, you get flagship-quality results where they count while keeping average per-task costs dramatically lower than a flagship-for-everything approach.
Which Model Wins for Your Specific Use Case
The comparison articles that simply declare one model "better" miss the point entirely. After analyzing the benchmark data, pricing structures, and philosophical differences detailed above, here are specific recommendations for five common development scenarios that most developers will encounter.
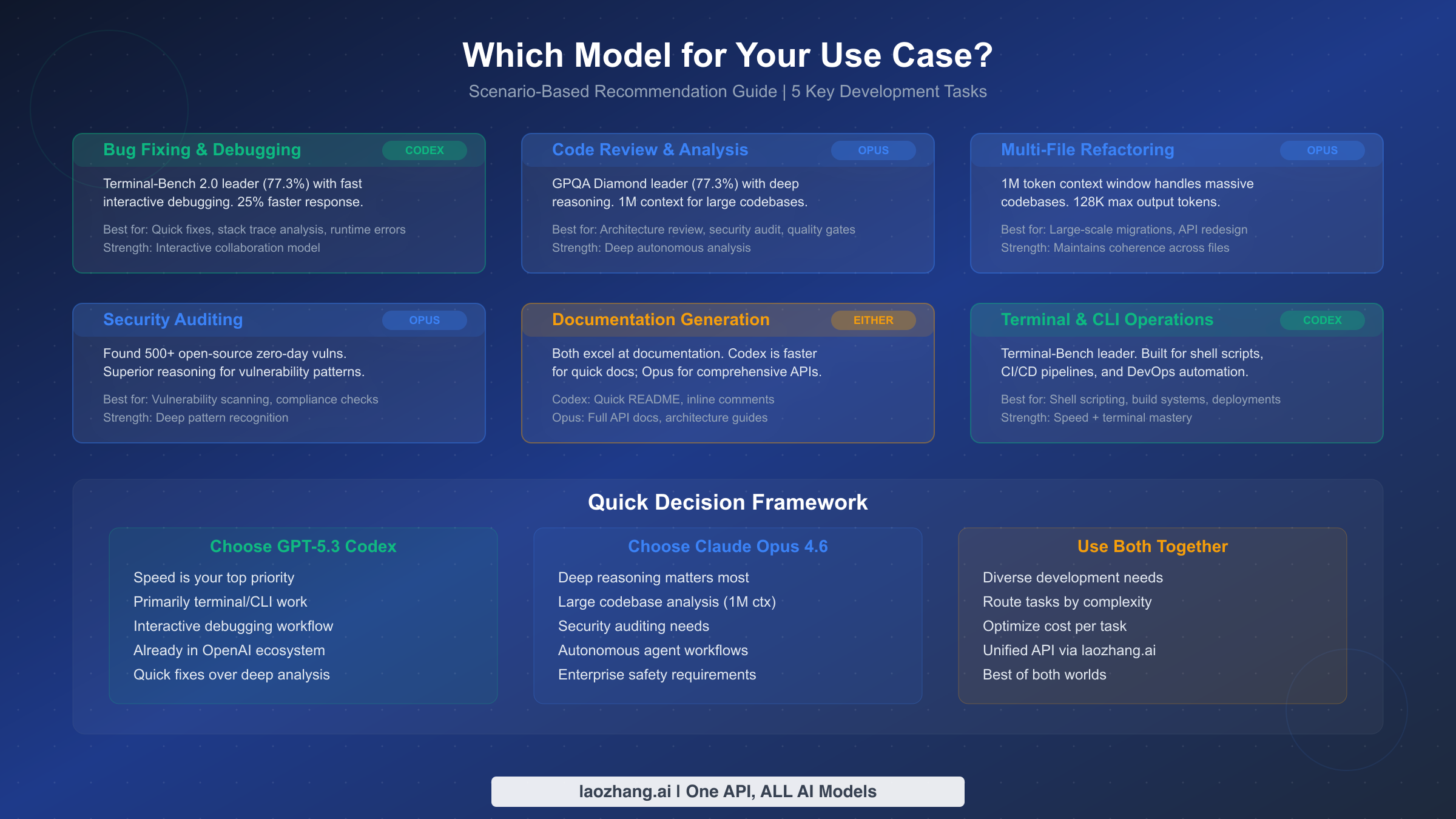
Bug fixing and debugging: Choose Codex. When a production issue hits and you need to trace a stack trace, identify a root cause, and deploy a fix quickly, speed matters more than depth. Codex's 25% speed improvement and Terminal-Bench 2.0 dominance (77.3%) translate directly to faster debugging cycles. Its interactive collaboration model means you can quickly iterate through hypotheses with the model, test fixes, and confirm solutions — all within a tight feedback loop. The practical difference feels like having a pair programmer who thinks at the speed of your typing versus one who pauses to think deeply before each response. For production incidents where minutes matter, that speed advantage is decisive.
Code review and architectural analysis: Choose Opus. When you need to evaluate a large pull request for security implications, assess whether a proposed architecture will scale, or understand complex interactions across multiple services, Opus's reasoning advantages become critical. The 3.5-point lead on GPQA Diamond and the 1M token context window allow Opus to consider entire system architectures holistically. Its track record of discovering 500+ zero-day vulnerabilities demonstrates exactly the kind of thorough, patient analysis that effective code review requires. Organizations with security-sensitive codebases should weight this capability heavily in their decision.
Multi-file refactoring and large-scale migrations: Choose Opus. Refactoring that spans dozens of files requires maintaining coherence across a large context — understanding how changes in one module affect interfaces, tests, and dependencies elsewhere. Opus's 1M token context (beta) and 128K maximum output give it a clear architectural advantage for these tasks. You can feed entire project structures into a single prompt and receive coordinated changes across all affected files, reducing the risk of partial refactoring that introduces inconsistencies.
Terminal operations and DevOps: Choose Codex. Shell scripting, CI/CD pipeline configuration, infrastructure-as-code, and deployment automation all happen primarily in terminal environments where Codex's Terminal-Bench lead is directly relevant. The interactive model also aligns well with DevOps workflows, where you often need to quickly iterate on configuration files, test deployment scripts, and troubleshoot infrastructure issues in real-time.
Documentation generation: Either model works well. Both Codex and Opus produce high-quality documentation, but their strengths differ. Codex is faster for generating inline comments, README files, and quick API endpoint descriptions. Opus produces more comprehensive results for full API documentation suites, architectural decision records, and onboarding guides that require understanding the entire codebase context. For most documentation needs, the choice comes down to whether you value speed or comprehensiveness.
The Decision Framework
When benchmark scores are this close, the deciding factors shift from raw capability to workflow alignment. Ask yourself three questions: Do you value speed or depth? Do you work primarily in terminal environments or IDEs? Do your tasks require processing large codebases holistically or fixing issues one at a time? If you answered speed, terminal, and one-at-a-time, choose Codex. If depth, IDE, and holistic, choose Opus. If your answers are mixed — which they are for most development teams — consider using both.
It is also worth considering team composition when making this decision. A team of primarily backend engineers working on microservices may find Codex's terminal proficiency and speed more valuable for their daily workflow of debugging, deploying, and iterating on services. A team with dedicated security engineers and architects may prioritize Opus's deep reasoning for the code review and vulnerability analysis workflows that consume most of their time. Full-stack teams with diverse responsibilities almost always benefit from having access to both models, routing each task to the model best suited for it. The cost overhead of maintaining two model integrations is minimal compared to the productivity gain of always having the optimal tool for each task.
Safety, Security, and Enterprise Readiness
Enterprise adoption of AI coding models requires more than performance benchmarks. Safety frameworks, security certifications, and data handling policies often determine which models are approved for use in corporate environments. Both OpenAI and Anthropic have invested significantly in safety, but their approaches and transparency levels differ in ways that matter for enterprise decision-makers.
Anthropic's safety positioning with Opus 4.6 is explicit and detailed. Anthropic has published extensive documentation about their Responsible Scaling Policy and Constitutional AI approach. Opus 4.6 includes specific safety features designed for agentic use cases, including improved instruction-following that reduces the likelihood of the model acting outside its intended scope during autonomous operations. The GDPval-AA benchmark, where Opus leads GPT-5.2 by 144 Elo points, specifically measures alignment quality — the model's ability to follow instructions accurately and avoid harmful outputs. For enterprises concerned about AI safety in production environments, this measurable alignment advantage is significant. Anthropic also offers SOC 2 Type II compliance and HIPAA-eligible configurations for enterprise customers.
OpenAI's safety framework for Codex focuses on operational controls. Codex inherits OpenAI's broader safety infrastructure, including usage policies, content filtering, and monitoring capabilities. However, because Codex API access is still rolling out, the full scope of enterprise safety features specifically available for Codex is not yet fully documented. Enterprise teams evaluating Codex should verify current availability and safety features directly with OpenAI before making procurement decisions.
Data handling differs between providers. Both companies offer enterprise agreements that include data privacy provisions, but the default configurations differ. Anthropic does not use API inputs for model training by default. OpenAI offers similar protections through their Enterprise and API usage policies, with opt-out options for data training. For teams working with sensitive or proprietary codebases, understanding the specific data handling terms of each provider's enterprise agreement is essential before sending code through either API. Enterprise teams should also consider Claude Opus pricing at the enterprise tier when evaluating total cost of ownership.
Compliance and Data Residency Considerations
For regulated industries including finance, healthcare, and government, the availability of compliance certifications can be a blocking factor in model selection. Both providers offer enterprise solutions with varying levels of compliance support, but the practical implications differ significantly depending on your regulatory environment.
Financial services organizations operating under SOX, PCI-DSS, or similar frameworks need to verify that code sent to either API is handled according to their data classification policies. Healthcare organizations subject to HIPAA must confirm BAA (Business Associate Agreement) availability before sending any patient-adjacent data through AI models, even for code review tasks that might inadvertently include PHI in variable names or test data. Government contractors working under FedRAMP or ITAR restrictions face the most stringent requirements and should verify authorization levels for both platforms before initiating any evaluation.
The practical recommendation for enterprise teams is to start the compliance verification process in parallel with technical evaluation. Contact both OpenAI and Anthropic enterprise sales teams simultaneously, provide your specific compliance requirements, and compare responses. The model that clears your compliance review first may be the right initial choice regardless of benchmark scores, with the second model added later once approvals are in place.
The Smart Move — Using Both Models Together
The framing of "GPT-5.3 Codex vs Claude Opus 4.6" as a binary choice reflects how we historically thought about technology decisions, but the 2026 reality of AI development tools is different. The most effective development teams are increasingly adopting multi-model strategies that route different tasks to the best-suited model, reducing costs while improving overall capability coverage.
The multi-model approach is not just theoretical — it is practical. Consider a typical development sprint. Monday morning, you are debugging a production issue (route to Codex for speed). Tuesday, you are reviewing a large PR for security implications (route to Opus for depth). Wednesday, you are writing deployment scripts (Codex for terminal proficiency). Thursday, you are planning a major refactoring (Opus for architectural analysis). Each task has a clear best-fit model, and using the wrong one means either waiting longer than necessary or getting shallower analysis than the task requires.
Unified API access makes multi-model strategies practical. The primary barrier to multi-model adoption has traditionally been the operational complexity of maintaining multiple API integrations, managing different authentication tokens, and handling inconsistent response formats. Platforms like laozhang.ai solve this by providing a single API endpoint that can route requests to both OpenAI and Anthropic models. You write one integration, use one API key, and specify which model to use per request. This eliminates the integration overhead that previously made multi-model strategies impractical for small teams.
Implementing a multi-model routing strategy follows a simple pattern. Start by categorizing your AI-assisted development tasks into three buckets: speed-critical (debugging, quick fixes, code generation), depth-critical (code review, security audit, architecture), and routine (documentation, test generation, basic refactoring). Route speed-critical tasks to Codex, depth-critical tasks to Opus, and routine tasks to a more cost-effective model like Claude Sonnet 4.5 or GPT-5 mini. This tiered approach typically reduces costs by 30-50% compared to routing everything through a flagship model while maintaining high quality where it matters most.
Here is how a basic routing implementation looks with a unified API:
pythonimport requests API_BASE = "https://api.laozhang.ai/v1" API_KEY = "your-api-key" def route_task(task_type, prompt): model_map = { "speed": "gpt-5.3-codex", # Fast debugging, terminal ops "depth": "claude-opus-4-6", # Deep analysis, security "routine": "claude-sonnet-4-5", # Cost-effective daily tasks } response = requests.post( f"{API_BASE}/chat/completions", headers={"Authorization": f"Bearer {API_KEY}"}, json={"model": model_map[task_type], "messages": [{"role": "user", "content": prompt}]} ) return response.json()
Why This Strategy Wins Long-Term
The multi-model approach also hedges against vendor lock-in and capability shifts. When the next model update arrives — and in 2026, that happens roughly every quarter — you can simply update your routing rules rather than migrating an entire workflow. If Codex improves its reasoning scores or Opus dramatically increases speed, you adjust the routing logic accordingly without changing your application code.
There is also a resilience argument for multi-model strategies that often goes unmentioned in comparison articles. API outages happen to every provider. If your entire development workflow depends on a single model and that provider experiences downtime during a critical deployment window, your team is blocked. With a multi-model setup, you can automatically fall back to an alternative model for any task category, maintaining productivity even when one provider is unavailable. This kind of resilience becomes increasingly important as teams rely more heavily on AI-assisted development for their core workflows. The cost of a few hours of reduced AI capability is trivial compared to the cost of a completely blocked development team during a production incident.
The Bottom Line — Making Your Decision in 2026
After examining verified benchmarks, real pricing data, coding philosophies, and enterprise considerations, the GPT-5.3 Codex versus Claude Opus 4.6 comparison reveals a market where the "best" model is entirely context-dependent. This is not a diplomatic dodge — it reflects the genuine convergence of AI capabilities where the differences that matter are about approach rather than absolute quality.
If you are a solo developer or small team that values speed and works primarily in terminal environments, GPT-5.3 Codex aligns with your workflow. Its Terminal-Bench dominance, interactive collaboration model, and potentially lower pricing (once published) make it the natural choice for fast-paced, iterative development. If you work on large codebases, prioritize security, and need deep analysis capabilities, Claude Opus 4.6's reasoning advantages, 1M token context window, and transparent pricing give it the edge. And if you are part of a team with diverse needs — as most development teams are — the multi-model strategy using a unified API provides the best overall outcome at the lowest cost.
The AI coding tool market in February 2026 is not about choosing sides. It is about choosing the right tool for each job and having the infrastructure to switch seamlessly between them.
For teams just starting their evaluation, here is a concrete action plan. First, identify your three most common AI-assisted coding tasks and map each to the model that benchmarks suggest will perform best. Second, set up a unified API integration that allows you to test both models without separate infrastructure. Third, run a two-week trial where different team members use different models for the same types of tasks, and compare results based on output quality, speed satisfaction, and task completion rates rather than synthetic benchmark numbers. This empirical approach will give you far more actionable insight than any comparison article — including this one — because the best model for your team depends on your specific codebase, coding style, and workflow patterns in ways that no benchmark can capture.
The models will continue to evolve rapidly. Codex and Opus are both already surpassed in some dimensions by the models their respective companies are developing internally. The infrastructure and routing strategy you build now to use both models effectively will serve you well regardless of which model leads the next benchmark cycle.
Frequently Asked Questions
Is GPT-5.3 Codex better than Claude Opus 4.6 for coding?
It depends on the coding task. Codex leads in terminal operations and speed (77.3% Terminal-Bench vs 65.4%), making it better for debugging and DevOps. Opus leads in reasoning (77.3% GPQA Diamond vs 73.8%) and supports 1M token context, making it better for code review and large-scale refactoring. On general SWE-Bench, both score approximately 80%.
How much does GPT-5.3 Codex API cost?
As of February 10, 2026, GPT-5.3 Codex API pricing has not been officially published on OpenAI's pricing page. OpenAI states that "API access is still rolling out." Based on GPT-5.2 pricing ($1.75/$14 per MTok), estimates suggest similar or slightly higher pricing, but this is unconfirmed. Claude Opus 4.6 is confirmed at $5/$25 per MTok.
Can I use both GPT-5.3 Codex and Claude Opus 4.6?
Yes, and many development teams are doing exactly that. Using a unified API platform allows you to route different tasks to different models — speed-critical work to Codex, deep analysis to Opus, and routine tasks to more affordable models. This multi-model strategy typically reduces costs by 30-50% while improving overall capability coverage.
Which model has the larger context window? Claude Opus 4.6 offers 200K tokens standard with a 1M token beta option. GPT-5.3 Codex context window is reported between 256K and 400K tokens, though OpenAI has not published official specifications. For processing very large codebases, Opus's 1M beta context provides a clear advantage.
Which model is safer for enterprise use? Both models offer enterprise-grade safety features. Opus 4.6 has a measurable alignment advantage (+144 Elo on GDPval-AA) and Anthropic publishes detailed safety documentation. OpenAI offers comprehensive enterprise policies for Codex, though some enterprise features are still rolling out alongside API access. Enterprise teams should verify current certifications and data handling policies directly with each provider.