
The landscape of AI development changed dramatically when OpenAI released their latest GPT-4o pricing structure in 2025. As developers building production applications with large language models, understanding the nuances of API pricing isn't just about managing costs—it's about architecting systems that deliver value while maintaining financial sustainability.
Current GPT-4o API Pricing Structure

OpenAI's GPT-4o API operates on a token-based pricing model that has become the industry standard. The current pricing stands at $5.00 per million input tokens and $20.00 per million output tokens for standard API calls. This represents a significant evolution from earlier pricing models, reflecting both the increased capabilities of the model and OpenAI's commitment to making advanced AI more accessible to developers.
Understanding token economics is crucial for any developer working with the GPT-4o API. A token roughly corresponds to 4 characters in English text, though this varies significantly across languages. For practical purposes, 1,000 tokens translate to approximately 750 words. This means processing a typical 2,000-word document would consume roughly 2,667 tokens, costing about $0.013 for input processing.
The asymmetric pricing between input and output tokens reflects the computational complexity of generation versus comprehension. While the model processes input tokens relatively efficiently, generating coherent, contextually appropriate output requires significantly more computational resources. This 4:1 ratio between output and input pricing has profound implications for application design.
Usage Tiers and Rate Limits
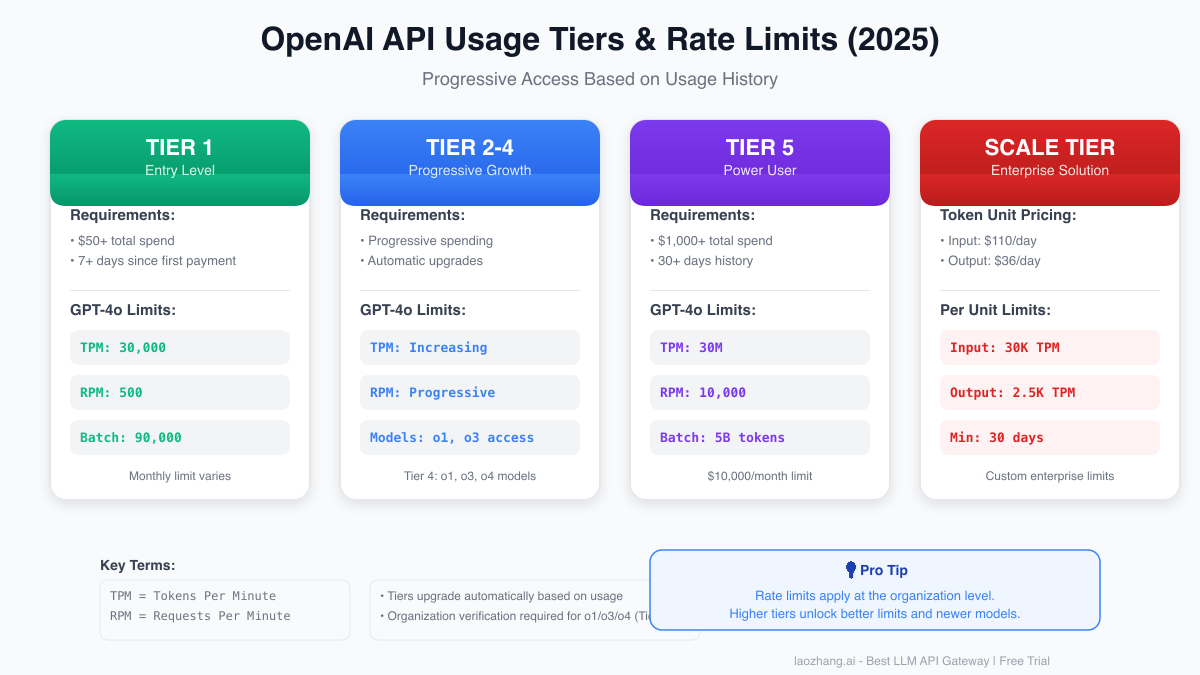
OpenAI's tiered system provides a progressive pathway for developers to scale their applications. Starting with Tier 1, which requires a minimum of $50 in total spend and 7 days since first payment, developers gain access to 30,000 tokens per minute (TPM) and 500 requests per minute (RPM) for GPT-4o. This entry-level tier provides sufficient capacity for prototype development and small-scale applications.
The progression through tiers happens automatically based on usage and payment history. Tier 2 through Tier 4 offer incrementally higher limits, with each tier unlocking additional capabilities. Notably, Tier 4 grants access to newer models like o1 and o3, positioning serious developers at the forefront of AI capabilities. The tier system isn't just about rate limits—it's OpenAI's way of building trust relationships with developers while managing infrastructure demands.
Tier 5 represents a significant leap in capabilities, requiring $1,000 in total spend and 30 days of payment history. At this level, developers enjoy 30 million TPM and 10,000 RPM, essentially removing rate limiting as a concern for most applications. The monthly spending limit of $10,000 at Tier 5 accommodates substantial production workloads while maintaining reasonable guardrails.
Scale Tier and Enterprise Solutions
For applications requiring consistent, high-volume access, OpenAI introduced the Scale Tier—a paradigm shift in API pricing. Rather than paying per token, Scale Tier customers purchase token units at fixed daily rates: $110 per input unit and $36 per output unit. Each input unit provides 30,000 TPM capacity, while output units deliver 2,500 TPM.
The Scale Tier requires a 30-day commitment and suits organizations processing millions of tokens daily. Consider a news aggregation service processing 50 million input tokens and generating 10 million output tokens daily. Under standard pricing, this would cost $250 for input and $200 for output daily. With Scale Tier, purchasing appropriate units could reduce costs while guaranteeing consistent performance.
This pricing model particularly benefits applications with predictable, high-volume workloads. Financial analysis platforms, content generation services, and enterprise automation tools find the Scale Tier's predictable costs and guaranteed capacity essential for reliable operations. The commitment requirement ensures OpenAI can allocate dedicated resources while providing customers with enterprise-grade reliability.
Batch API Economics
The Batch API represents one of the most underutilized cost optimization opportunities in the OpenAI ecosystem. Offering a 50% discount on both input and output tokens, the Batch API processes requests within a 24-hour window, making it ideal for non-time-sensitive workloads. At $2.50 per million input tokens and $10.00 per million output tokens, batch processing transforms the economics of large-scale AI applications.
Document processing pipelines exemplify the Batch API's value proposition. Consider a legal tech startup analyzing thousands of contracts daily. By aggregating document analysis requests and submitting them through the Batch API, they reduce processing costs by half while maintaining quality. The 24-hour turnaround fits naturally into overnight processing workflows, turning a potential limitation into an operational advantage.
Implementation requires thoughtful architecture. Successful batch processing systems implement request queuing, progress tracking, and result handling mechanisms. Here's a practical example of a document processing system leveraging batch economics:
pythonimport asyncio from datetime import datetime import json class BatchDocumentProcessor: def __init__(self, api_client): self.api_client = api_client self.batch_queue = [] self.results_cache = {} async def add_document(self, doc_id, content): """Queue document for batch processing""" self.batch_queue.append({ 'custom_id': doc_id, 'method': 'POST', 'url': '/v1/chat/completions', 'body': { 'model': 'gpt-4o', 'messages': [{ 'role': 'system', 'content': 'Analyze the following document and extract key information.' }, { 'role': 'user', 'content': content }] } }) # Trigger batch when queue reaches threshold if len(self.batch_queue) >= 100: await self.process_batch() async def process_batch(self): """Submit queued documents for batch processing""" if not self.batch_queue: return # Create batch file batch_file = await self.api_client.files.create( file=json.dumps(self.batch_queue), purpose='batch' ) # Submit batch batch = await self.api_client.batches.create( input_file_id=batch_file.id, endpoint='/v1/chat/completions', completion_window='24h' ) self.batch_queue.clear() return batch.id
Real-World Implementation Patterns
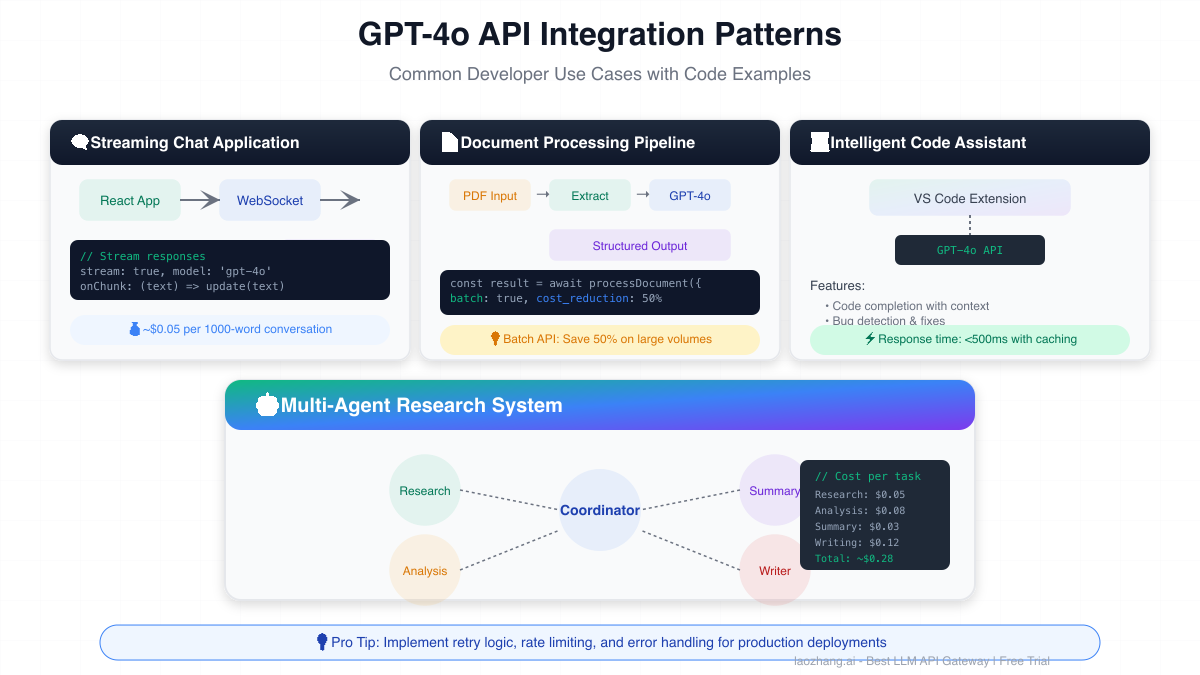
Streaming chat applications represent the most common GPT-4o API use case. Modern implementations leverage server-sent events (SSE) or WebSocket connections to deliver real-time responses. The streaming approach not only improves user experience but also enables graceful handling of long responses and timeout scenarios.
A production-ready streaming implementation addresses several critical concerns. Token counting ensures requests stay within model limits while response caching reduces redundant API calls. Here's a robust streaming chat implementation:
javascriptclass StreamingChatClient { constructor(apiKey) { this.apiKey = apiKey; this.conversationCache = new Map(); } async streamChat(messages, onChunk) { const cacheKey = this.generateCacheKey(messages); // Check cache first if (this.conversationCache.has(cacheKey)) { return this.conversationCache.get(cacheKey); } const response = await fetch('https://api.openai.com/v1/chat/completions', { method: 'POST', headers: { 'Authorization': `Bearer ${this.apiKey}`, 'Content-Type': 'application/json' }, body: JSON.stringify({ model: 'gpt-4o', messages: messages, stream: true, temperature: 0.7, max_tokens: 1000 }) }); const reader = response.body.getReader(); const decoder = new TextDecoder(); let fullResponse = ''; while (true) { const { done, value } = await reader.read(); if (done) break; const chunk = decoder.decode(value); const lines = chunk.split('\n').filter(line => line.trim()); for (const line of lines) { if (line.startsWith('data: ')) { const data = line.slice(6); if (data === '[DONE]') continue; try { const parsed = JSON.parse(data); const content = parsed.choices[0]?.delta?.content || ''; fullResponse += content; onChunk(content); } catch (e) { console.error('Parse error:', e); } } } } // Cache the complete response this.conversationCache.set(cacheKey, fullResponse); return fullResponse; } generateCacheKey(messages) { return JSON.stringify(messages); } }
Multi-agent systems represent an advanced implementation pattern gaining traction among sophisticated developers. By orchestrating multiple specialized agents, applications can tackle complex tasks more efficiently than monolithic approaches. Each agent optimizes for specific subtasks, leveraging appropriate models and parameters.
Cost Optimization Strategies
Effective cost management begins with comprehensive monitoring. Implementing request-level tracking provides visibility into usage patterns and identifies optimization opportunities. Successful applications implement multiple layers of cost control, from prompt optimization to intelligent caching strategies.
Prompt engineering directly impacts costs. Concise, well-structured prompts reduce input tokens while improving output quality. System prompts should be refined iteratively, balancing comprehensive instructions with token efficiency. Consider this optimization example:
pythonverbose_prompt = """ You are an AI assistant that helps users with their questions. Please provide helpful, accurate, and detailed responses to user queries. Make sure to be polite and professional in your communication. If you don't know something, admit it rather than making up information. Always strive to give the most useful answer possible. """ # Optimized prompt (50 tokens) optimized_prompt = """ You are a helpful AI assistant. Provide accurate, concise responses. If uncertain, acknowledge limitations. Maintain professional tone. """ # Saves 100 tokens per request without sacrificing quality
Response caching dramatically reduces costs for applications with repeated queries. Implementing semantic similarity matching allows caching beyond exact matches, increasing cache hit rates. Production systems often achieve 30-40% cost reduction through intelligent caching strategies.
The choice between GPT-4o and GPT-4o-mini depends on task complexity. GPT-4o-mini, priced at $0.15 per million input tokens and $0.60 per million output tokens, handles many tasks adequately at 3% of GPT-4o's cost. Implementing dynamic model selection based on query complexity optimizes the cost-quality tradeoff.
Competitor Analysis and Market Position
OpenAI's pricing positions GPT-4o competitively within the enterprise LLM market. Anthropic's Claude 3 Opus, at $15/$75 per million tokens, offers superior context windows but at premium pricing. Google's Gemini Pro provides lower costs but with varying performance characteristics across different task types.
The market dynamics reveal interesting patterns. While raw token prices matter, the total cost of ownership includes factors like reliability, latency, and feature completeness. OpenAI's extensive ecosystem, comprehensive documentation, and proven scale often justify the pricing for production applications.
For developers seeking flexibility across multiple providers, API gateway solutions like laozhang.ai provide unified interfaces while optimizing costs. These platforms aggregate multiple LLM providers, enabling dynamic routing based on cost, performance, and availability requirements. The ability to seamlessly switch between providers or distribute load across multiple APIs becomes increasingly valuable as applications scale.
Business Value and ROI Calculations
Quantifying the return on investment for GPT-4o implementations requires looking beyond direct API costs. Customer service automation provides a clear example. A support ticket typically costs $5-15 to resolve manually. GPT-4o can handle routine inquiries at $0.05-0.10 per ticket, representing a 50-100x cost reduction.
Content generation workflows show similar economics. A marketing team producing blog content might spend $200-500 per article through traditional channels. GPT-4o-assisted workflows reduce this to $10-20 in API costs plus human review time, accelerating production while maintaining quality standards.
The compound effects multiply these savings. Faster content production enables more frequent publishing, improving SEO performance and audience engagement. Automated customer service frees human agents for high-value interactions, increasing customer satisfaction and retention. These second-order effects often exceed direct cost savings.
Production Deployment Considerations
Deploying GPT-4o in production requires robust infrastructure design. Rate limiting protects against usage spikes while retry logic handles transient failures. Implementing circuit breakers prevents cascade failures when API availability issues occur.
Security considerations demand careful attention. API keys require secure storage and rotation procedures. Request and response logging must balance debugging needs with privacy requirements. Many organizations implement proxy layers to centralize security controls and audit logging.
Here's a production-ready API client with comprehensive error handling:
pythonimport time import logging from typing import Optional, Dict, Any import backoff from dataclasses import dataclass @dataclass class APIResponse: success: bool data: Optional[Dict[Any, Any]] = None error: Optional[str] = None retry_after: Optional[int] = None class ProductionGPT4Client: def __init__(self, api_key: str, max_retries: int = 3): self.api_key = api_key self.max_retries = max_retries self.logger = logging.getLogger(__name__) @backoff.on_exception( backoff.expo, Exception, max_tries=3, max_time=300 ) async def complete(self, messages: list, **kwargs) -> APIResponse: """Production-ready completion with comprehensive error handling""" try: response = await self._make_request(messages, **kwargs) if response.status_code == 200: return APIResponse(success=True, data=response.json()) elif response.status_code == 429: # Rate limit - extract retry after retry_after = int(response.headers.get('Retry-After', 60)) self.logger.warning(f"Rate limited, retry after {retry_after}s") return APIResponse( success=False, error="Rate limited", retry_after=retry_after ) elif response.status_code >= 500: # Server error - should retry self.logger.error(f"Server error: {response.status_code}") raise Exception(f"Server error: {response.status_code}") else: # Client error - should not retry return APIResponse( success=False, error=f"Client error: {response.status_code}" ) except Exception as e: self.logger.error(f"Request failed: {str(e)}") return APIResponse(success=False, error=str(e))
Future Outlook and Strategic Planning
The trajectory of API pricing suggests continued optimization as competition intensifies and infrastructure scales. OpenAI's introduction of specialized models and tiered pricing indicates a future where developers can precisely match model capabilities to use case requirements.
Planning for future developments requires architectural flexibility. Applications should abstract LLM interactions, enabling model switching as new options emerge. Cost monitoring and optimization should be built into application architecture from the start, not added as an afterthought.
For organizations building AI-first applications, platforms like laozhang.ai offer strategic advantages. By providing unified access to multiple LLM providers, implementing intelligent routing, and offering usage analytics, these API gateways future-proof applications against vendor lock-in while optimizing costs. The free trial available at laozhang.ai enables developers to experiment with multi-provider strategies without initial investment.
Conclusion
OpenAI's GPT-4o API pricing in 2025 represents a maturation of the AI development ecosystem. The combination of tiered access, batch processing options, and enterprise Scale Tier provides options for every development scenario. Success requires more than understanding pricing—it demands thoughtful architecture, careful optimization, and strategic platform choices.
As AI capabilities expand and costs continue to optimize, the developers who thrive will be those who master not just the technology but the economics of AI deployment. Whether building a simple chatbot or a complex multi-agent system, understanding GPT-4o API pricing forms the foundation for sustainable, scalable AI applications.
The journey from prototype to production involves countless decisions about architecture, optimization, and platform selection. By leveraging the strategies outlined in this guide and considering flexible solutions like API gateways, developers can build applications that deliver exceptional value while maintaining cost efficiency. The future of AI development is bright for those who approach it with both technical excellence and economic wisdom.