
Elegir el proveedor de API de IA adecuado ya no es solo una decisión técnica. Con el lanzamiento de GPT-5.4 de OpenAI a $2.50 por millón de tokens de entrada, Gemini 3.1 Pro de Google ofreciendo inteligencia comparable a $2.00, y Claude Opus 4.6 de Anthropic con un precio premium de $5.00 por su profundidad de razonamiento, los precios por token solo cuentan parte de la historia. Lo que realmente determina tu factura mensual es una combinación de la elección del modelo, las características de la carga de trabajo y las estrategias de optimización que la mayoría de las guías comparativas ignoran por completo. Esta guía proporciona los datos de precios verificados más recientes a marzo de 2026, calcula los costos mensuales reales para tres escenarios empresariales y ofrece un manual concreto para reducir tu gasto en API entre un 60-80%.
Resumen rápido
Google Gemini ofrece el rango de precios más amplio, desde $0.10/MTok (Flash-Lite) hasta $2.00/MTok (3.1 Pro), convirtiéndolo en la plataforma con mayor flexibilidad de costos y un generoso nivel gratuito. GPT-5.4 de OpenAI se sitúa en $2.50/$15.00 con el ecosistema más maduro y precios de entrada en caché aproximadamente diez veces más baratos. Claude cobra precios premium (Sonnet 4.6 a $3.00/$15.00, Opus 4.6 a $5.00/$25.00) pero ofrece una calidad de razonamiento superior y descuentos del 90% en aciertos de caché. Para la mayoría de las cargas de trabajo en producción, combinar la clasificación por modelos con el procesamiento por lotes y el almacenamiento en caché de prompts reduce los costos entre un 60-80%, independientemente del proveedor que elijas.
Desglose Completo de Precios de API (Marzo 2026)
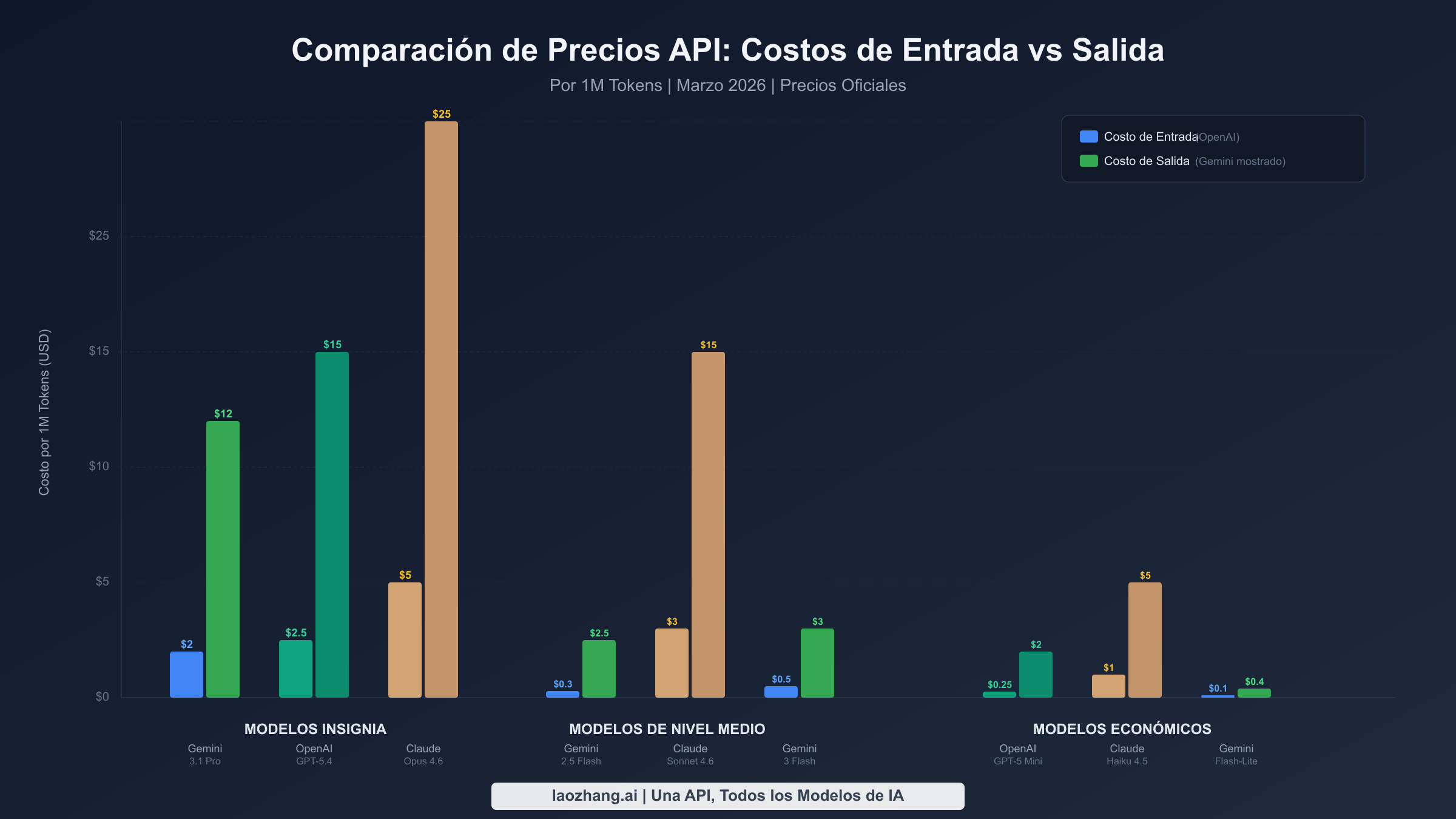
Comprender el panorama completo de precios requiere mirar más allá de los modelos insignia. Cada proveedor ofrece una línea escalonada diseñada para diferentes relaciones calidad-costo, y la diferencia entre sus modelos más baratos y más caros a menudo supera las 50 veces. Los siguientes datos fueron verificados contra las páginas oficiales de precios el 17 de marzo de 2026, con las fuentes indicadas para cada dato.
Google Gemini tiene la gama más amplia de modelos a puntos de precio notablemente diferentes. El recientemente lanzado Gemini 3.1 Pro Preview cobra $2.00 por millón de tokens de entrada y $12.00 por millón de tokens de salida para prompts de menos de 200,000 tokens, aumentando a $4.00 y $18.00 para contextos más largos (ai.google.dev, marzo 2026). En el extremo económico, Gemini 2.5 Flash-Lite ofrece rendimiento de nivel de producción a solo $0.10 de entrada y $0.40 de salida por millón de tokens, lo que lo hace aproximadamente 20 veces más barato que el modelo insignia. Gemini 3 Flash Preview se sitúa en el medio a $0.50/$3.00, ofreciendo fuertes capacidades de razonamiento a una fracción del precio del Pro. Quizás lo más importante es que Gemini proporciona un nivel gratuito genuinamente útil que cubre la mayoría de los modelos, convirtiéndolo en el único proveedor importante donde puedes prototipar y ejecutar aplicaciones a pequeña escala a costo cero. Para los desarrolladores que exploran toda la gama de opciones de precios de la API de Gemini, la estructura escalonada significa que casi siempre hay un modelo que se adapta a cualquier restricción presupuestaria.
| Modelo | Entrada ($/1M) | Salida ($/1M) | Entrada Lotes | Salida Lotes | Contexto |
|---|---|---|---|---|---|
| Gemini 3.1 Pro | $2.00 / $4.00 | $12.00 / $18.00 | $1.00 / $2.00 | $6.00 / $9.00 | 1M |
| Gemini 3 Flash | $0.50 | $3.00 | $0.25 | $1.50 | 1M |
| Gemini 2.5 Pro | $1.25 / $2.50 | $10.00 / $15.00 | $0.625 / $1.25 | $5.00 / $7.50 | 1M |
| Gemini 2.5 Flash | $0.30 | $2.50 | $0.15 | $1.25 | 1M |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | $0.05 | $0.20 | 1M |
OpenAI posiciona GPT-5.4 como su modelo insignia actual a $2.50 por millón de tokens de entrada y $15.00 por millón de tokens de salida para uso de contexto estándar. Una innovación significativa en precios es la división entre contexto corto y largo: los prompts que superan los 272,000 tokens en GPT-5.4 incurren en precios de entrada 2x y salida 1.5x ($5.00/$22.50), lo que impacta materialmente los costos para cargas de trabajo de RAG y análisis de documentos. GPT-5 Mini sigue siendo la opción económica preferida a $0.25/$2.00, ofreciendo calidad de nivel GPT-4 a una fracción del costo. El precio de entrada en caché de OpenAI es su mayor ventaja de costos, reduciendo frecuentemente los costos de entrada en aproximadamente un 90% para prompts de sistema repetitivos, y la API por lotes proporciona un descuento fijo del 50% para todo el procesamiento no en tiempo real.
| Modelo | Entrada ($/1M) | Salida ($/1M) | Entrada en Caché | Descuento Lotes | Contexto |
|---|---|---|---|---|---|
| GPT-5.4 (corto) | $2.50 | $15.00 | $0.25 | 50% | 1.05M |
| GPT-5.4 (largo >272K) | $5.00 | $22.50 | $0.50 | 50% | 1.05M |
| GPT-5 | $1.25 | $10.00 | $0.125 | 50% | 128K |
| GPT-5 Mini | $0.25 | $2.00 | $0.025 | 50% | 128K |
Anthropic Claude ocupa el nivel premium, con sus precios reflejando el énfasis de la plataforma en la profundidad de razonamiento y la seguridad. Claude Opus 4.6, el modelo insignia, cuesta $5.00 de entrada y $25.00 de salida por millón de tokens, convirtiéndolo en la opción más cara entre los tres proveedores pero consistentemente mejor posicionado en las pruebas de referencia de razonamiento. Claude Sonnet 4.6 a $3.00/$15.00 ofrece un punto medio convincente con fuertes capacidades de codificación y análisis, mientras que Haiku 4.5 a $1.00/$5.00 proporciona el punto de entrada. El almacenamiento en caché de prompts de Claude ofrece ahorros significativos, con aciertos de caché a solo el 10% del costo estándar de entrada. Como hemos cubierto en nuestro desglose de precios de la API de Claude, el principal factor de costo es la naturaleza pesada en salida de las respuestas detalladas de Claude.
| Modelo | Entrada ($/1M) | Salida ($/1M) | Acierto Caché | Escritura Caché | Contexto |
|---|---|---|---|---|---|
| Opus 4.6 | $5.00 | $25.00 | $0.50 | $6.25 | 200K |
| Sonnet 4.6 (≤200K) | $3.00 | $15.00 | $0.30 | $3.75 | 200K-1M |
| Haiku 4.5 | $1.00 | $5.00 | $0.10 | $1.25 | 200K |
Escenarios de Costos Mensuales en el Mundo Real

Los precios por token solo cobran sentido cuando se traducen en facturas mensuales reales. Los siguientes escenarios asumen 1,000 tokens por solicitud con una proporción de entrada/salida de 75/25, lo que representa una carga de trabajo conversacional o analítica típica. Estos cálculos utilizan precios estándar sin descuentos de optimización, proporcionando una línea base que puede reducirse drásticamente mediante las estrategias cubiertas más adelante en esta guía.
Nivel Inicial (10,000 solicitudes por mes) representa desarrolladores individuales, proyectos secundarios y prototipos en etapa temprana. A esta escala, Gemini 2.5 Flash-Lite cuesta aproximadamente $1.75 por mes, y el nivel gratuito en realidad lo cubre por completo. OpenAI GPT-5 Mini cuesta alrededor de $6.88, mientras que Claude Haiku 4.5 llega a aproximadamente $20.00. Las diferencias de costo a esta escala son relativamente menores en términos absolutos, lo que significa que debes priorizar la calidad del modelo y la experiencia del desarrollador sobre el precio bruto. Si tu proyecto está comenzando, el nivel gratuito de Gemini es un punto de entrada inigualable, y siempre puedes escalar a modelos de pago a medida que crecen tus requisitos sin cambiar de proveedor.
Nivel de Crecimiento (100,000 solicitudes por mes) es donde las decisiones de precios comienzan a importar significativamente. Una aplicación en producción que procesa 100K solicitudes mensuales con un modelo insignia revela diferencias de costo significativas. Gemini 2.5 Pro cuesta aproximadamente $344 por mes, GPT-5.4 alrededor de $563 y Claude Sonnet 4.6 alcanza los $600. Estas cifras asumen precios estándar, pero la realidad es que la mayoría de las aplicaciones en producción deberían estar usando procesamiento por lotes y almacenamiento en caché, lo que puede reducir estos números aproximadamente a la mitad. En este nivel, la elección entre proveedores a menudo se reduce a si necesitas el equilibrio de costo y calidad de Gemini, la madurez del ecosistema de OpenAI o la profundidad de razonamiento de Claude para tu caso de uso específico.
Nivel Empresarial (1,000,000 solicitudes por mes) magnifica cada diferencia de precio en miles de dólares. Ejecutar un millón de solicitudes a través de Gemini 2.5 Flash cuesta aproximadamente $850, GPT-5 llega a alrededor de $3,438 y Claude Opus 4.6 alcanza los $10,000 por mes a tarifas estándar. A esta escala, la clasificación por modelos se vuelve esencial. Un sistema bien diseñado que enruta el 70% de las consultas simples a Flash-Lite ($175), el 25% a un modelo de nivel medio ($860) y el 5% a un modelo premium ($500) podría manejar la misma carga de trabajo por aproximadamente $1,535 en total, representando una reducción del 55-85% dependiendo del modelo premium elegido.
Costos Ocultos Que Cambian la Ecuación
Los precios por token mostrados en las páginas oficiales de precios cuentan una historia incompleta. Varios multiplicadores de costos permanecen enterrados en la documentación o solo se hacen evidentes después de un uso significativo, y no tenerlos en cuenta puede llevar a excesos presupuestarios del 30-100%. Comprender estos costos ocultos es fundamental para una planificación financiera precisa.
Los tokens de razonamiento representan el mayor costo oculto individual para las cargas de trabajo intensivas en razonamiento. Tanto Gemini 2.5 Pro como Claude Sonnet 4.6 generan tokens de razonamiento internos que cuentan hacia el precio de salida pero no aparecen en la respuesta final. Una solicitud que produce una respuesta visible de 500 tokens podría en realidad consumir 2,000-5,000 tokens de salida cuando se incluye el razonamiento, multiplicando efectivamente tus costos de salida por 4-10x para tareas de razonamiento complejas. Las páginas de precios de Gemini declaran explícitamente que los precios de salida incluyen tokens de razonamiento, y la función de razonamiento extendido de Claude funciona de manera similar. Al presupuestar para aplicaciones que dependen en gran medida del razonamiento, como la generación de código, el análisis matemático o la planificación de múltiples pasos, siempre multiplica tu volumen estimado de salida por al menos 3x para tener en cuenta la sobrecarga de razonamiento.
Las primas por contexto largo se aplican tanto a Gemini como a OpenAI cuando tus prompts superan umbrales específicos. Gemini 2.5 Pro y 3.1 Pro cobran 2x de entrada y 1.5x de salida cuando los prompts superan los 200,000 tokens. OpenAI GPT-5.4 aplica un multiplicador similar de 2x/1.5x más allá de 272,000 tokens. Para aplicaciones de RAG y flujos de trabajo de análisis de documentos que procesan regularmente contextos largos, esto puede duplicar tus costos efectivos por token. Claude, por el contrario, mantiene precios fijos independientemente de la longitud del contexto hasta su ventana estándar de 200K, convirtiéndolo en la opción más predecible para cargas de trabajo de contexto largo.
Las tarifas de búsqueda fundamentada agregan otra capa de costo para los usuarios de Gemini. Los modelos Gemini 3.x cobran $14 por cada 1,000 consultas de búsqueda cuando utilizan la fundamentación con Google Search (después de los primeros 5,000 prompts mensuales gratuitos). Para aplicaciones que fundamentan cada respuesta en resultados de búsqueda web, esto agrega $14 por mil solicitudes además de los costos de tokens. OpenAI y Claude actualmente no ofrecen fundamentación de búsqueda integrada a nivel de API, por lo que este costo es exclusivo de Gemini pero también representa una capacidad que los otros proveedores no pueden igualar.
¿Qué Proveedor Gana para Tu Caso de Uso?

En lugar de declarar un único ganador, la elección óptima depende completamente de las características de tu carga de trabajo. Cada proveedor ha establecido ventajas claras en dominios específicos, y las siguientes recomendaciones se basan tanto en el análisis de precios como en observaciones de rendimiento del mundo real en implementaciones de producción.
Chatbots orientados al cliente y automatización de soporte priorizan la velocidad, la eficiencia de costos y una calidad adecuada para interacciones conversacionales. Gemini 2.5 Flash-Lite a $0.10/$0.40 por millón de tokens ofrece la mejor economía para aplicaciones conversacionales de alto volumen, especialmente cuando se combina con el nivel gratuito para desarrollo y pruebas. Para aplicaciones que requieren respuestas de mayor calidad, Gemini 2.5 Flash a $0.30/$2.50 proporciona un excelente razonamiento a un precio aún asequible. La disponibilidad del nivel gratuito significa que puedes validar la arquitectura de tu chatbot antes de comprometer cualquier presupuesto.
Aplicaciones de RAG y bases de conocimiento exigen recuperación precisa, resúmenes fieles y típicamente implican el procesamiento de contextos largos de documentos. Gemini 2.5 Pro a $1.25/$10.00 ofrece la mejor combinación de ventana de contexto de 1M tokens y precios razonables para prompts de longitud estándar, aunque la prima de 2x más allá de 200K tokens debe tenerse en cuenta en las proyecciones de costos. Claude Sonnet 4.6 destaca en fidelidad y seguimiento de instrucciones en tareas de RAG pero cuesta más a $3.00/$15.00. Para implementaciones de RAG sensibles al presupuesto, enrutar las consultas con recuperación aumentada a Gemini y reservar Claude para la síntesis de los contextos recuperados más complejos crea un enfoque híbrido efectivo.
Generación de código y herramientas de desarrollo se benefician más de las fuertes capacidades de razonamiento y seguimiento de instrucciones. La comparación entre Claude Opus 4.6 y GPT-5 ha demostrado que Claude lidera consistentemente en las pruebas de referencia de calidad de generación de código. Claude Sonnet 4.6 a $3.00/$15.00 proporciona el punto óptimo de capacidad de codificación y costo, convirtiéndolo en la opción más popular entre las empresas de herramientas para desarrolladores. Si el presupuesto es la principal restricción, Gemini 3 Flash Preview a $0.50/$3.00 ofrece una generación de código sorprendentemente fuerte por una sexta parte del precio.
Flujos de trabajo agénticos y razonamiento de múltiples pasos requieren modelos que puedan mantener el contexto, planificar efectivamente y usar herramientas de manera fiable a lo largo de cadenas de interacción extendidas. Claude Opus 4.6, a pesar de su precio premium de $5.00/$25.00, sigue siendo el estándar de oro para aplicaciones agénticas debido a sus superiores capacidades de seguimiento de instrucciones y planificación. La sobrecarga de tokens de razonamiento hace que las cargas de trabajo agénticas sean particularmente costosas, pero para flujos de trabajo automatizados de misión crítica, la prima de costo se justifica por tasas de finalización de tareas significativamente más altas.
Procesamiento por lotes y análisis offline siempre deben aprovechar las API por lotes para obtener la reducción directa del 50% en costos. Los precios por lotes de Gemini reducen Gemini 2.5 Flash a $0.15/$1.25, haciendo que el procesamiento de documentos a gran escala sea notablemente asequible. La API por lotes de OpenAI aplica el mismo descuento del 50% en todos los modelos con resultados entregados en 24 horas.
Estrategias de Optimización de Costos Que Realmente Funcionan
Pasar de comprender los precios a reducir activamente los costos requiere implementar estrategias específicas. Los siguientes enfoques están clasificados por impacto y dificultad de implementación, con cálculos concretos que muestran los ahorros esperados.
La clasificación por modelos ofrece los mayores ahorros inmediatos para la mayoría de las aplicaciones y solo requiere cambios en la lógica de enrutamiento. El principio es simple: enrutar las solicitudes al modelo más barato capaz de manejar cada tarea específica. Un sistema de clasificación bien diseñado envía el 70% de las consultas sencillas a modelos económicos (Flash-Lite a $0.10/$0.40 o GPT-5 Mini a $0.25/$2.00), el 25% de las tareas de complejidad moderada a modelos de nivel medio (Gemini 2.5 Flash a $0.30/$2.50 o Claude Sonnet a $3.00/$15.00) y solo el 5% de las tareas de razonamiento genuinamente complejas a modelos premium (Opus a $5.00/$25.00 o GPT-5.4 a $2.50/$15.00). Para una carga de trabajo de 100K solicitudes que costaría $600 solo con Claude Sonnet, la clasificación reduce la factura a aproximadamente $160, un ahorro del 73%.
El procesamiento por lotes de la API proporciona un descuento garantizado del 50% tanto en tokens de entrada como de salida para cualquier solicitud que no requiera respuestas en tiempo real. Los tres proveedores ahora ofrecen procesamiento por lotes: Gemini muestra explícitamente precios por lotes en cada modelo, OpenAI proporciona un descuento fijo del 50% con un SLA de 24 horas, y Claude ofrece capacidades similares de procesamiento por lotes. Para pipelines de procesamiento de datos, análisis de contenido y tareas de generación programadas, prácticamente no hay razón para no usar precios por lotes. Si el 40% de tu carga de trabajo puede tolerar procesamiento diferido, la API por lotes por sí sola reduce tu factura total en un 20%.
El almacenamiento en caché de prompts transforma la economía de las aplicaciones con prompts de sistema repetitivos. El sistema de almacenamiento en caché de Claude reduce los costos de entrada de aciertos de caché a solo el 10% del precio estándar, mientras que el almacenamiento en caché de contexto de Gemini ofrece reducciones similares con precios adicionales basados en almacenamiento. Si tu aplicación utiliza un prompt de sistema de 4,000 tokens en todas las solicitudes, almacenar en caché ese prompt ahorra aproximadamente el 90% en esos tokens de entrada. Para una aplicación de 100K solicitudes, esto se traduce en aproximadamente $300-500 en ahorros mensuales dependiendo del modelo.
Las plataformas de agregación de API como laozhang.ai ofrecen una solución pragmática para equipos que quieren usar múltiples proveedores sin gestionar claves de API separadas, cuentas de facturación y código de integración. Estas plataformas proporcionan un único punto de acceso API compatible con OpenAI que enruta solicitudes a cualquier modelo de Gemini, OpenAI o Claude, con precios competitivos que a menudo igualan o mejoran las tarifas directas del proveedor. Más allá de los precios, el beneficio operativo es significativo: una sola clave API te da acceso instantáneo a todos los modelos, y puedes cambiar entre proveedores sin cambios en el código. Para equipos que evalúan múltiples modelos o ejecutan arquitecturas híbridas, la reducción de la sobrecarga de integración y la flexibilidad de proveedores típicamente justifican el enfoque de agregación.
Tomando Tu Decisión: Próximos Pasos Prácticos
El volumen de datos de precios y estrategias de optimización puede resultar abrumador, pero el marco de decisión es realmente sencillo cuando te enfocas en tus principales restricciones.
Si el costo es tu principal restricción, comienza con Gemini. El nivel gratuito te permite validar tu aplicación sin ningún gasto, y la progresión desde Flash-Lite ($0.10/$0.40) pasando por Flash ($0.30/$2.50) hasta Pro ($1.25/$10.00) proporciona rutas de actualización naturales a medida que crecen tus requisitos de calidad. Gemini también ofrece los precios por lotes más agresivos, llevando modelos ya asequibles a costos por token notablemente bajos.
Si la calidad y el razonamiento son primordiales, invierte en Claude. Sonnet 4.6 ofrece la mejor relación calidad-costo para aplicaciones que exigen resultados precisos, matizados y bien razonados. El sistema de almacenamiento en caché de prompts hace que las interacciones repetidas sean significativamente más baratas, y el contexto extendido de 1M en beta abre posibilidades para el análisis de documentos largos que otros proveedores no pueden igualar a niveles de calidad similares. La suscripción Pro de $20 al mes también incluye un uso generoso para prototipos.
Si el ecosistema y las herramientas son lo más importante, OpenAI sigue siendo la opción más segura. El soporte de integración de terceros más amplio, el ecosistema de SDK más maduro y la comunidad más grande de desarrolladores significan una velocidad de desarrollo más rápida. Los precios de entrada en caché (10x más baratos) y la API por lotes (50% de descuento) proporcionan fuertes palancas de optimización de costos, y el precio de GPT-5.4 a $2.50/$15.00 es competitivo con el modelo insignia de Gemini.
Para equipos que construyen aplicaciones de producción que requieren flexibilidad, explorar una plataforma de agregación de API como laozhang.ai proporciona la capacidad de probar los tres proveedores a través de un único punto de integración. Con precios que igualan las tarifas directas del proveedor y capacidades de cambio instantáneo de modelo, elimina el riesgo de dependencia del proveedor que conlleva comprometerse con un solo proveedor desde el principio. Puedes comenzar en docs.laozhang.ai con créditos desde solo $5.
Preguntas Frecuentes
¿Cuál es la API de IA más barata en 2026?
Google Gemini 2.5 Flash-Lite a $0.10 de entrada y $0.40 de salida por millón de tokens es la API de producción más barata de un proveedor importante a marzo de 2026. Cuando se combina con la API por lotes (50% de descuento), baja a $0.05/$0.20, y el nivel gratuito cubre el uso a pequeña escala a costo cero. GPT-5 Mini de OpenAI a $0.25/$2.00 es la opción más barata de OpenAI, mientras que Claude Haiku 4.5 a $1.00/$5.00 es el modelo más asequible de Anthropic.
¿Cuánto cuesta ejecutar 100,000 solicitudes de API al mes?
Los costos mensuales para 100K solicitudes (asumiendo 1,000 tokens cada una, proporción de entrada/salida 75/25) varían desde aproximadamente $18 con Gemini Flash-Lite hasta $1,000 con Claude Opus 4.6. Las opciones de nivel medio más populares cuestan $344 (Gemini 2.5 Pro), $563 (GPT-5.4) y $600 (Claude Sonnet 4.6). Aplicar optimizaciones de API por lotes y almacenamiento en caché típicamente reduce estos valores entre un 40-60%.
¿Afectan los tokens de razonamiento a los costos de la API?
Sí, significativamente. Tanto Gemini 2.5 Pro como los modelos de Claude generan tokens de razonamiento internos que se facturan a tarifas de tokens de salida pero no aparecen en la respuesta visible. Para tareas intensivas en razonamiento, los tokens de razonamiento pueden multiplicar tus costos efectivos de salida por 3-10x. Siempre monitorea el consumo real de tokens a través del panel de uso de tu proveedor en lugar de estimar basándote solo en la longitud de la respuesta.
¿Vale la pena cambiar de OpenAI a Gemini para ahorrar dinero?
Para cargas de trabajo sensibles al costo, cambiar a Gemini puede reducir los costos de API entre un 30-70% dependiendo de tu uso actual del modelo. La contrapartida es que la calidad del modelo de Gemini, aunque mejora rápidamente, puede diferir de la de OpenAI para casos de uso específicos. Un enfoque práctico es enrutar las operaciones masivas sensibles al costo hacia Gemini mientras mantienes los flujos críticos de calidad en tu proveedor actual. Las plataformas de agregación de API hacen que este enfoque híbrido sea sencillo de implementar.
¿Cómo puedo reducir mis costos de API de IA en un 50% o más?
Tres estrategias combinadas típicamente logran una reducción de costos del 60-80%: (1) La clasificación por modelos enruta el 70% de las solicitudes a modelos económicos, ahorrando un 40-60%. (2) El procesamiento por lotes de la API proporciona un descuento fijo del 50% para cargas de trabajo no en tiempo real. (3) El almacenamiento en caché de prompts reduce los costos de entrada repetitivos en un 75-90%. Comienza con la clasificación por modelos ya que no requiere cambios en la API, solo lógica de enrutamiento.