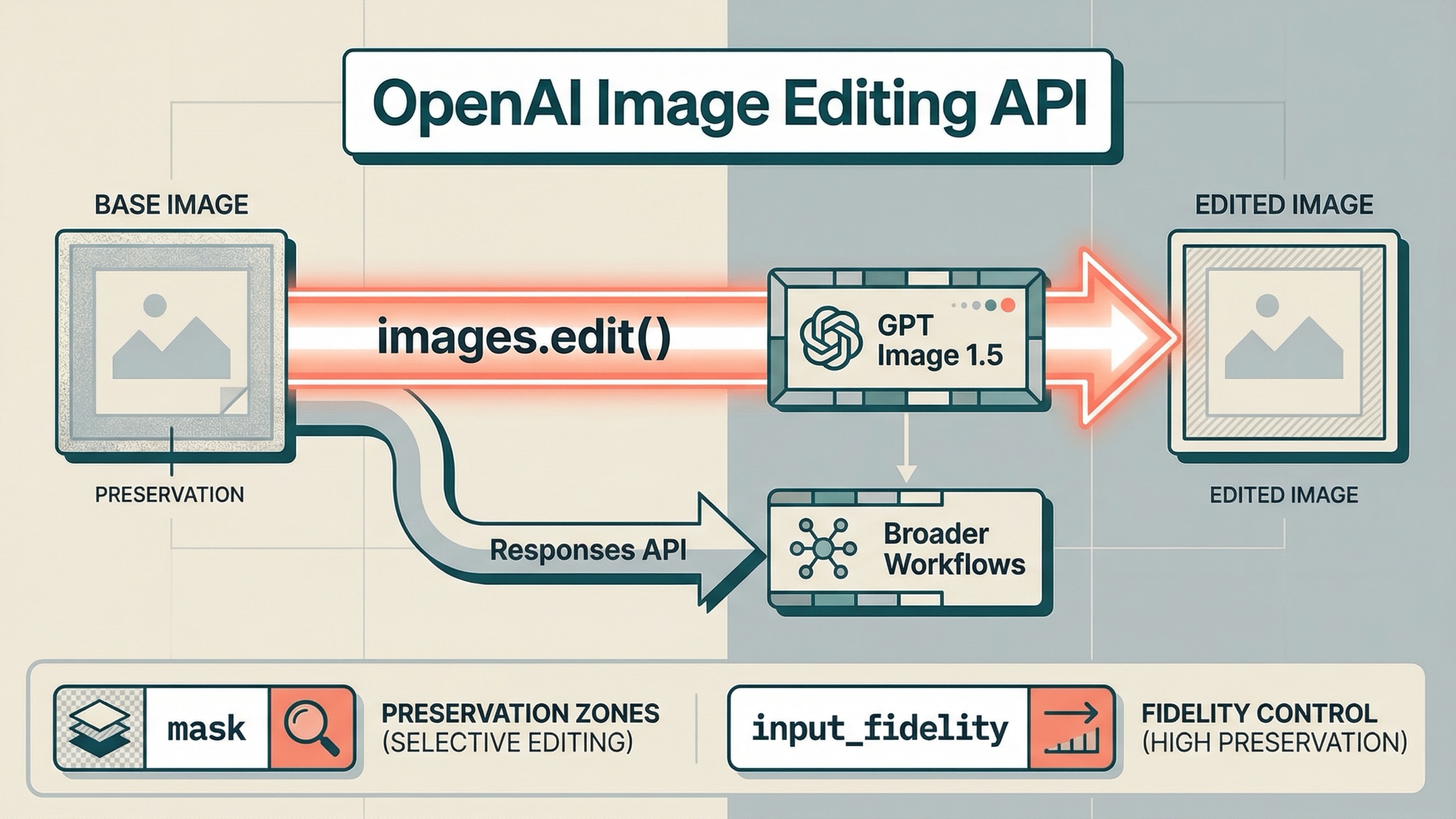
If you want to edit images with the OpenAI API on March 23, 2026, start with the direct Images API and gpt-image-1.5. For most edit-first jobs, that means client.images.edit() in the SDK or POST /v1/images/edits over raw HTTP. Use the Responses API only when image editing is one step inside a larger conversation, agent, or multi-turn workflow.
That default matters because OpenAI's current image docs are still split across several pages. The main image generation guide now shows gpt-image-1.5 in direct edit examples. The current GPT Image 1.5 model page labels it the latest image generation model. But the broader Images and vision guide still says the latest model is gpt-image-1. If you skim one page and stop, it is easy to copy a valid-looking edit flow that is strategically stale.
The second trap is more expensive than the first one. A lot of developers hear "image editing API" and expect Photoshop-style local patching. OpenAI's current docs are more careful than that. They say your prompt should describe the full desired final image, not only the erased area. Community threads also show why that warning matters: teams still get frustrated when a masked GPT Image edit behaves like a broader semantic rewrite instead of a strict masked pixel replacement. This article is here to keep you out of that loop.
TL;DR
- Start with
images.edit()andgpt-image-1.5for direct OpenAI image editing API work. - Use masks when you need to steer where the model should focus, but do not assume the mask guarantees a local pixel-only patch.
- Use
input_fidelity="high"when preserving faces, logos, layout, or branded visuals matters more than speed or cost. - Use Responses only when the edit belongs inside a broader multimodal or agent workflow.
Start here: the current direct OpenAI image editing API path
For a normal edit workflow, the shortest safe mental model is:
- send one or more input images
- describe the final result you want
- set preservation controls only when they matter
- decode the returned base64 image and save it
The current direct JavaScript pattern looks like this:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1.5", image: [fs.createReadStream("room.jpg")], prompt: "Replace the empty wall art with a framed abstract poster. Preserve the room layout, lighting, shadows, and all furniture. Do not change the camera angle.", input_fidelity: "high", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; const imageBuffer = Buffer.from(imageBase64, "base64"); fs.writeFileSync("room-edited.jpg", imageBuffer);
The matching Python version is just as direct:
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.edit( model="gpt-image-1.5", image=[open("room.jpg", "rb")], prompt=( "Replace the empty wall art with a framed abstract poster. " "Preserve the room layout, lighting, shadows, and all furniture. " "Do not change the camera angle." ), input_fidelity="high", size="1024x1024", quality="medium", output_format="jpeg", output_compression=80, ) image_base64 = result.data[0].b64_json image_bytes = base64.b64decode(image_base64) with open("room-edited.jpg", "wb") as f: f.write(image_bytes)
If you need the raw HTTP shape, the important detail is that image edits are multipart form data, not JSON:
bashcurl https://api.openai.com/v1/images/edits \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "image[]=@room.jpg" \ -F 'prompt=Replace the empty wall art with a framed abstract poster. Preserve the room layout, lighting, shadows, and all furniture. Do not change the camera angle.' \ -F "input_fidelity=high" \ -F "size=1024x1024" \ -F "quality=medium"
That is the best starting point because it keeps the workflow obvious. You pick the current edit-capable model, provide the source image, describe the final result, and get back base64 image data. You are not asking a general reasoning model to decide whether it should edit or generate. You are not managing conversation state. You are just doing the edit.
If your real question is broader than editing, read the larger OpenAI Image API tutorial. This page stays narrower on purpose.
Images API vs Responses when you need edits
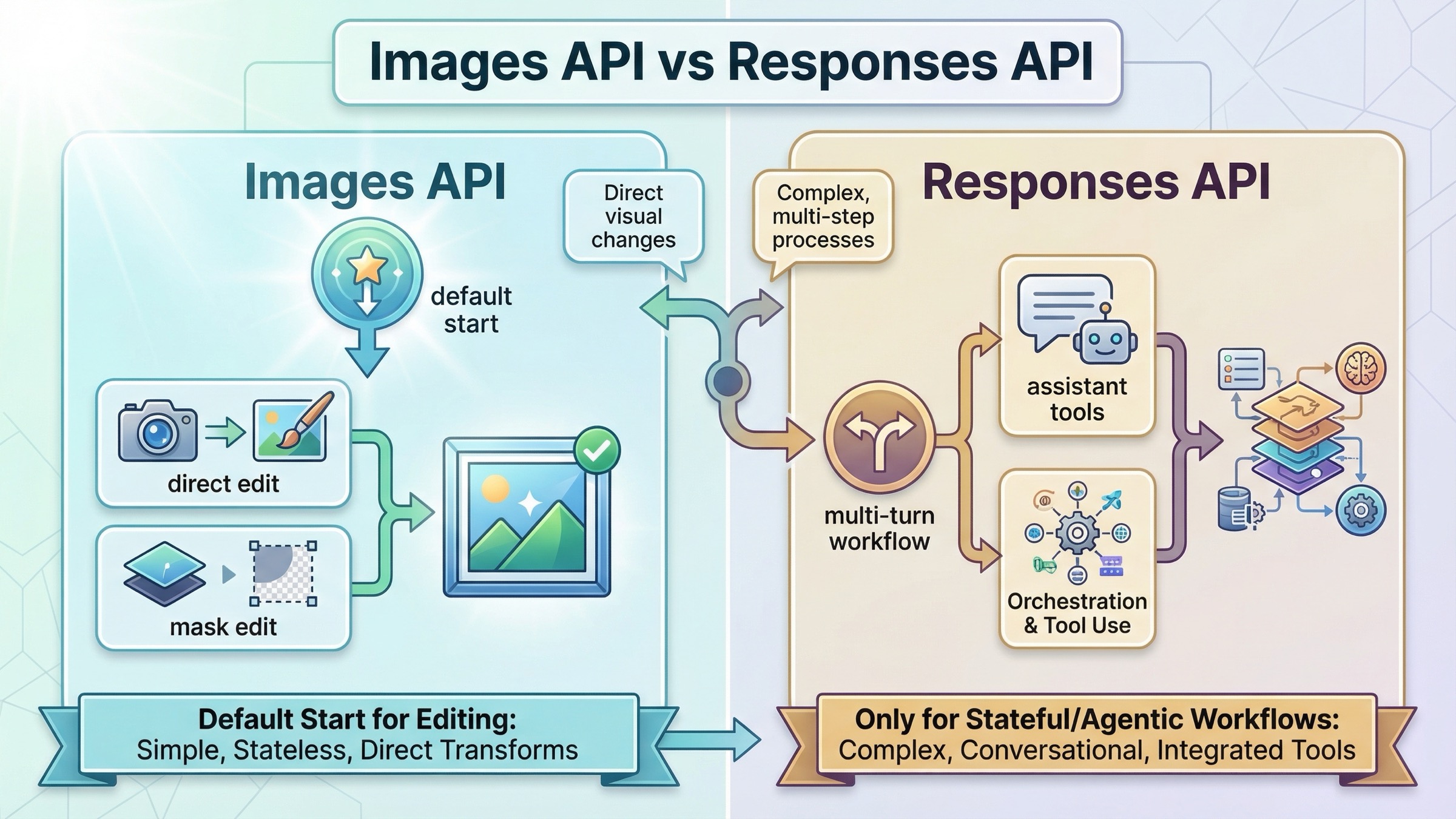
This is the route choice most page-one results still leave fuzzy.
| Situation | Better default | Why |
|---|---|---|
| Edit one or more source images and save the output file | Images API | It is the shortest direct edit path and keeps the request contract easy to debug |
| Insert or replace an element while preserving a face, logo, or product shot | Images API | Direct edit flow plus input_fidelity=high is the cleanest preservation-first setup |
| Use a mask to steer where the edit should focus | Images API | Mask inputs, multipart upload, and direct output handling are already first-class here |
| Continue editing inside a multi-turn conversation using previous response IDs or image-generation call IDs | Responses API | Conversation state and iterative tool use are easier to manage there |
| Build an assistant that may reason, call tools, inspect inputs, and sometimes edit an image | Responses API | Image editing becomes one tool inside a larger workflow rather than the whole product surface |
The important rule is simple: do not start with Responses just because it looks newer. The current tool guide is clear that Responses is for broader hosted image-generation flows. It even notes that GPT Image models are not valid top-level model values in the Responses API. You use a text-capable model such as gpt-5, then let the hosted image_generation tool perform the edit or generation step.
That makes Responses powerful, but it also makes it easier to choose the wrong abstraction. If your product needs one direct edit endpoint today, use the direct Images API first. If the product later grows into multi-turn editing, conversation memory, or other tool calls, that is when Responses becomes the better route.
Choose the right edit mode before you touch the prompt
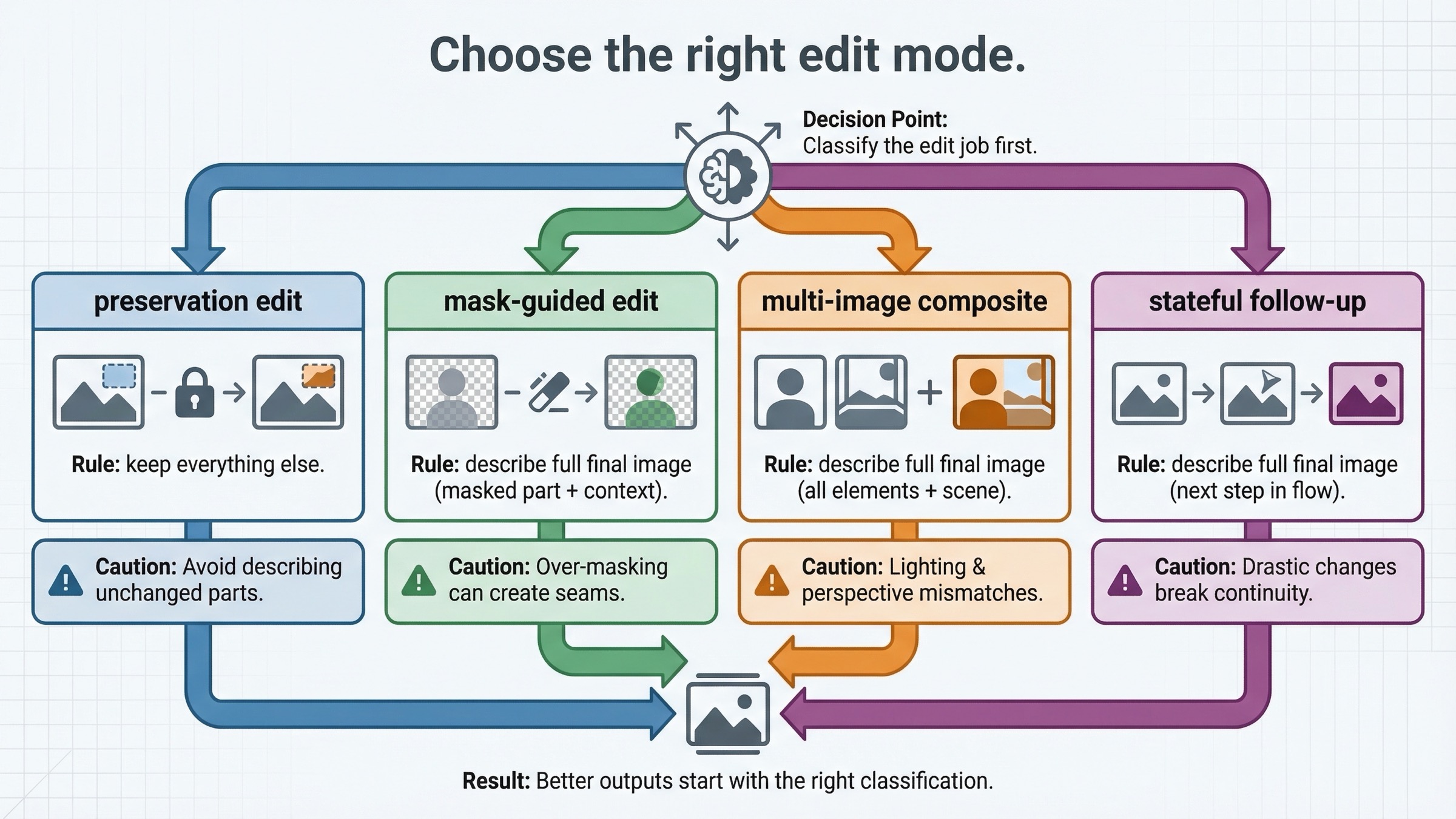
Most weak tutorials treat "image editing" like one operation. It is not. The prompt only gets clearer once you decide what kind of edit you are actually asking the model to perform.
The first type is a preservation-heavy single-image edit. This is the right choice when you already have the scene you want and only need a controlled change: swap clothing, add a sign, update wall art, remove one distracting element, restyle an object, or change the mood while keeping composition. In these jobs, preservation matters more than raw creativity, so input_fidelity="high" is often worth it.
The second type is a mask-guided edit. Here you are not only telling the model what to change, but also where to focus. That helps, but it does not turn GPT Image into a deterministic local patch tool. The mask is a steering device, not a guarantee that only those pixels will be touched in the strictest possible sense.
The third type is a multi-image reference or compositing edit. OpenAI's current guide and cookbook both show that you can pass more than one image and ask the model to insert, blend, or carry over features from one into another. This is how you build workflows like:
- place the logo from image two onto the shirt in image one
- bring the dog from image two into the scene from image one
- keep the same product, but re-stage it in a new environment
The fourth type is iterative follow-up editing. This is where Responses becomes more attractive. If the first edit is close but not done, and you want the model to continue from the prior output inside a conversation, the Responses path is cleaner than manually rebuilding everything around one-off direct edit calls.
The reason to make this distinction early is that each mode wants a different prompt style. A preservation-heavy single-image edit wants explicit "keep everything else" language. A mask edit wants the full final-image description plus location guidance. A multi-image composite wants clear source attribution: what to take from which input, what to preserve from the base image, and what must remain unchanged.
How masks and input_fidelity really behave

This is the part most readers are actually searching for, even when they do not phrase it that way.
OpenAI's current image generation guide says the image and mask must be the same format and size, the payload must stay under 50 MB, and the mask needs an alpha channel. It also gives the most important instruction on the page: describe the full desired final image, not just the erased area.
That one line changes how you should think about the API. It means the model is not only filling a hole. It is interpreting the source image, the mask, and your prompt together to produce a coherent final result.
This is also why community complaints do not come from nowhere. One OpenAI Developer Community thread from April 27, 2025 says masked edits felt like they regenerated the whole image. Replies later quoted OpenAI Support calling precise inpainting a known limitation for gpt-image-1 at that time. Even if GPT Image 1.5 is clearly stronger than GPT Image 1 on preservation-heavy edits, the operational lesson is still valid: test masked workflows like a semantic edit system, not like deterministic layer surgery.
input_fidelity="high" helps when the edit has to preserve style and features more carefully. OpenAI uses it in the direct guide for logo placement, and Microsoft's current Azure OpenAI edit guide explains the same idea in practical terms: high input fidelity makes the model work harder to preserve features, especially facial ones, during subtle edits. That is why it belongs in workflows like:
- changing a product background while keeping the product untouched
- updating a person’s clothing while preserving facial identity
- placing a branded logo on an object or garment
- making a small scene adjustment without losing camera angle or composition
The tradeoff is not mysterious. Higher preservation effort usually means more cost and more caution. If the task does not need strict preservation, you do not gain much by forcing high fidelity everywhere.
The better habit is this:
- start with one simple direct edit
- add
input_fidelity=highonly when preservation matters - use a mask when location guidance matters
- keep the prompt focused on the final image, the preserved elements, and the one or two things that should change
If the first result is close but not perfect, do not immediately jump to a giant prompt. Iterate with one narrower follow-up change instead.
Preservation-heavy edits work better in small steps
The current GPT Image 1.5 prompting guide is useful here because it behaves less like a parameter dump and more like production advice. Across translation, compositing, style preservation, and scene changes, the pattern is consistent: the strongest edits come from explicit constraints plus small iterative changes.
That is also how you should structure prompts in real products.
Bad edit prompt:
textMake this look better, more modern, cleaner, more premium, maybe add some flowers, maybe change the colors, and make it suitable for a landing page.
Better preservation-first edit prompt:
textReplace only the poster on the wall with a framed abstract print. Preserve the room layout, furniture, lighting, floor shadows, and camera angle. Do not move or redesign any other object. Photorealistic interior photography.
Better compositing prompt:
textPlace the logo from image 2 onto the front of the tote bag in image 1. Match the bag's fabric texture and lighting. Keep the model, pose, background, and camera framing unchanged.
Better follow-up prompt:
textKeep the edited image exactly the same, but make the poster slightly larger and reduce glare on the frame. Do not change anything else.
That last line matters. The more valuable the original image is, the more you should think like an operator protecting state rather than a prompt writer chasing style.
This is also why the December 16, 2025 OpenAI release post matters. OpenAI positioned GPT Image 1.5 as stronger than GPT Image 1 for edits that preserve branded logos, key visuals, and facial consistency. That does not mean every preservation-heavy prompt will behave perfectly. It means the model is now good enough that your prompt discipline and edit sequencing matter more than they did in the older GPT Image 1 launch period.
If you need the broader model-routing decision after this, the best follow-up is our OpenAI image generation API models guide.
Troubleshooting: the common failures page one still leaves to forum threads
The first failure is using the wrong API surface first. If you only need to edit an image, do not start by wiring a Responses workflow with a top-level gpt-image-1.5 model field. That is the wrong contract. Direct Images API first, Responses later if the product actually needs it.
The second failure is trusting the wrong official page for freshness. As checked on March 23, 2026, the GPT Image 1.5 model page says GPT Image 1.5 is the latest image generation model, while the broader Images and vision guide still says gpt-image-1 is the latest. If your article or internal docs rely on the wrong page, your team can look stale even when the code still works.
The third failure is sending JSON to the raw edit endpoint. Direct image edits are multipart form data. If you are debugging with curl or your own HTTP client, that detail is not optional.
The fourth failure is treating the mask like a hard promise instead of a guidance tool. If your workflow absolutely depends on tiny local patches with zero collateral changes, test that assumption early. Do not promise product behavior based only on the word "mask" in the docs.
The fifth failure is writing prompts that describe only the changed object. OpenAI's guide says to describe the full desired image. If you only say "add a beach ball," the model has too much freedom about what else can move or restyle.
The sixth failure is assuming access and syntax are the same problem. GPT Image 1.5 still has current tier limits, and the model page still shows Free not supported. If the request fails before it returns a usable image, confirm access before you spend an hour rewriting your prompt. If that turns out to be your real blocker, the better follow-up is our OpenAI image generation API verification guide.
The seventh failure is forcing too much change into one request. If the task is preservation-heavy, large compound prompts make it harder to understand whether the model failed on composition, preservation, prompt wording, or the mask itself. One edit, then one follow-up correction, is still the cleaner production habit.
FAQ
Should I use gpt-image-1 or gpt-image-1.5 for edits right now?
For new direct edit work, use gpt-image-1.5. On March 23, 2026, OpenAI's current GPT Image 1.5 model page labels it the latest image generation model, while older official pages still mention gpt-image-1. Keep gpt-image-1 only when you are maintaining or comparing an older workflow.
Why did my mask edit change more than the masked area?
Because GPT Image edits are guided semantic rewrites, not guaranteed pixel-only local patches. OpenAI's current guide says the prompt should describe the full desired image, and community threads show that users still see broader rerenders when they expected hard-boundary inpainting.
Do I need input_fidelity=high for every edit?
No. Use it when preserving faces, logos, product geometry, camera angle, or other important visual identity matters more than speed or cost. Skip it when the task is more generative and you do not care if the model restyles more aggressively.
When should I move from Images API to Responses?
Move to Responses when the edit is part of a multi-turn conversation, an assistant workflow, or a broader tool-using product. Stay on the direct Images API when the image edit itself is the feature you are trying to ship.
Final recommendation
The clean current rule is this: if you want to edit images with the OpenAI API today, start with images.edit() plus gpt-image-1.5, not with a broader Responses workflow. Use masks to guide where the model should focus, but write prompts as if you are specifying the full final image. Add input_fidelity=high when preservation is the job, not by default in every request.
That framing is what page one still misses. The winning answer is not "OpenAI can edit images." The winning answer is "here is the direct edit path, here is when to use the alternate route, and here is what the mask does not guarantee."
If you want the broader API surface after this page, read the full OpenAI Image API tutorial. If you want working generation examples next, go to our OpenAI image generation API example page.