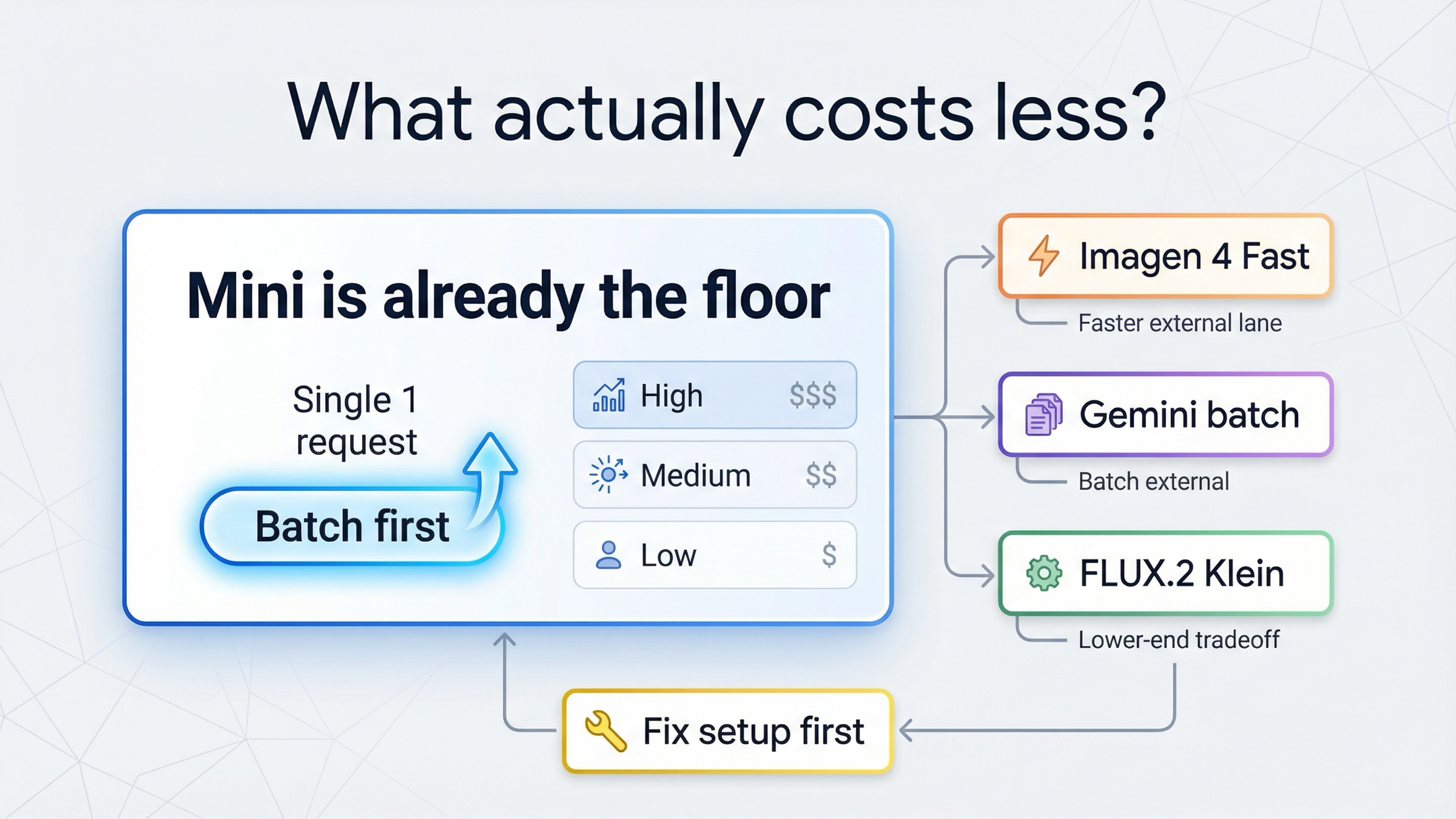
As checked on March 29, 2026, there is no clean mainstream hosted API that beats gpt-image-1-mini across its current low and medium price rows. OpenAI's current gpt-image-1-mini model page still lists mini at \$0.005, \$0.011, and \$0.036 for square 1024x1024 low, medium, and high outputs, and that one fact already changes the article most ranking pages would write. If price is the whole problem, the first cheaper move is usually to keep mini and test Batch, not to switch models.
That is exactly where the live SERP is still weak. Broad pricing grids can tell you that Imagen 4 Fast costs 0.02, that gemini-2.5-flash-image batch costs 0.0195, and that FLUX.2 Klein starts around 0.014 to 0.015. What they usually do not tell you is whether those rows are cheaper than mini overall, cheaper than mini high only, or cheaper only because they change the job, the quality target, or the shelf life of the route.
There is also a second trap in this keyword. Some gpt-image-1-mini cheaper alternative searches are not model-selection problems at all. They are really Batch-versus-live-routing questions, or verification and tier-state frustrations that make the workflow feel more expensive than it actually is. If your real issue is quality, typography, or editing rather than price, the better next read is GPT Image 1 Mini alternative. This page stays on the price-first question.
TL;DR
If you only need the routing answer, use this table first.
| If your real goal is... | Cheapest credible move | Current price anchor | Why it works | Main caveat |
|---|---|---|---|---|
| keep the lowest current official OpenAI image lane | Stay on gpt-image-1-mini | \$0.005 / \$0.011 / \$0.036 | Mini is already the current cost-efficient OpenAI branch | You keep mini's quality ceiling |
| lower cost without changing models for asynchronous work | Stay on mini and test Batch | OpenAI says Batch saves 50% on inputs and outputs | The first cheaper move may be workflow, not vendor | OpenAI does not publish a separate mini batch per-image card, and Batch is asynchronous |
| beat mini high, not mini low or medium, with a simple Google-hosted lane | Imagen 4 Fast | \$0.02 per image | It undercuts mini high and stays easy to understand | It is still more expensive than mini low and medium, and Google lists a June 24, 2026 shutdown date |
| beat mini high with Google's lowest current image row | gemini-2.5-flash-image batch | \$0.0195 per image | It is Google's lowest current published image row | It is still more expensive than mini low and medium, and Google lists an October 2, 2026 shutdown date |
| use a lower-end external high-volume lane | FLUX.2 Klein | from \$0.014 to \$0.015 | It can undercut mini high in some lower-end workloads | Pricing is megapixel-based and the route is not a like-for-like GPT Image replacement |
| fix access, verification, or route pain that only feels expensive | Stay with OpenAI and fix setup | no model switch required | A vendor switch does not solve tier or verification state | You still have to debug the route before judging the model economics |
The practical rule is simple. Cheaper than mini high is not the same as cheaper than mini overall. If you blur those together, you end up switching away from the floor without a real reason.
Why mini is already the current floor

The most important part of this article is not a comparison row. It is understanding what mini is supposed to be.
OpenAI's current models catalog still frames the family cleanly: GPT Image 1.5 is the state-of-the-art image generation model, GPT Image 1 is the previous generation model, and gpt-image-1-mini is the cost-efficient branch. That means mini is not an accidental budget leftover. It is the current official answer for teams that want lower image cost inside OpenAI.
The mini model page makes the price split explicit. On square 1024x1024 output, mini currently lists \$0.005 low, \$0.011 medium, and \$0.036 high. Those three rows are why the cheaper-alternative keyword is awkward. A lot of broad pricing pages compare one competitor number against one OpenAI number as if mini were a single price. It is not. The row you are actually buying matters.
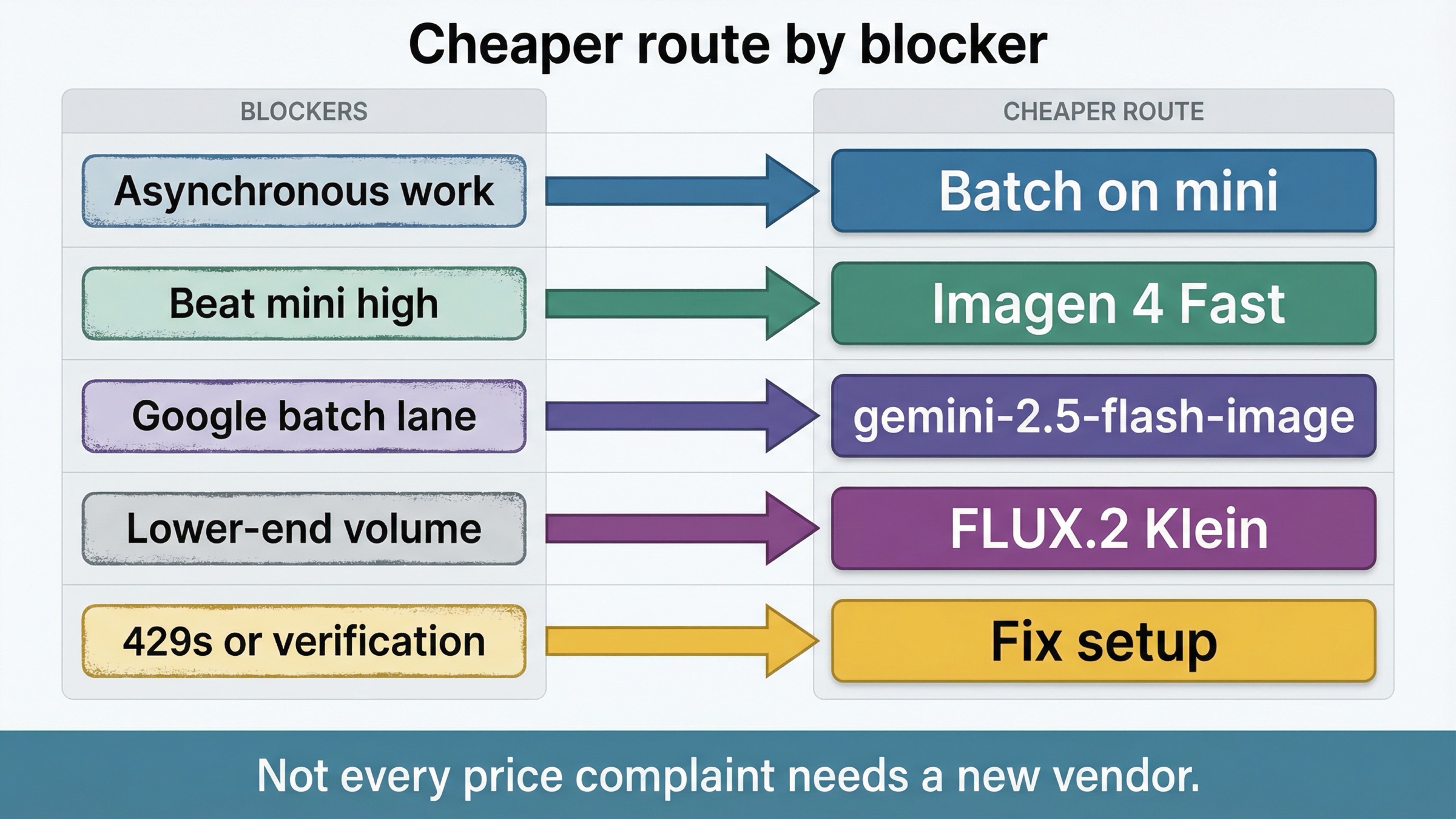
That is also why some supposedly cheaper alternatives are not really alternatives to mini at all. Imagen 4 Fast at 0.02 and gemini-2.5-flash-image batch at 0.0195 are cheaper than mini high, but not cheaper than mini low or mini medium. If your workload already lives on mini low or medium, those Google rows are not the price win they first appear to be.
The same logic is why Batch belongs near the top of the article. OpenAI's current API pricing page says the Batch API saves 50% on inputs and outputs for asynchronous work over 24 hours. The mini model page also exposes Batch as a supported endpoint family. OpenAI does not publish a separate mini-specific batch per-image card, so you should treat this as a workflow optimization rather than a fixed new sticker price. But the routing consequence is still real: if your workload is queueable, the first cheaper experiment is often mini plus Batch, not a new provider.
This is also where older OpenAI routes stop looking attractive. OpenAI's current image-generation guide says DALL-E 2 and DALL-E 3 stop supporting requests on May 12, 2026. That alone keeps the cheaper-alternative page from drifting into legacy answers just because one old card still looks inexpensive on the surface. A cheaper row that is already on the way out is not a strong default.
If you want the raw mini ladder without the market routing, GPT Image 1 Mini pricing is the better companion read. If your question is broader than mini and you really mean "cheaper than OpenAI's image stack overall," OpenAI image generation API cheaper alternative is the better market-wide page.
The current price picture becomes clearer when you separate universal wins from narrow wins:
| Route | Current published price surface | What it really beats | Main caveat |
|---|---|---|---|
| Mini live | \$0.005 / \$0.011 / \$0.036 | baseline floor inside OpenAI | Same quality ceiling you already know |
| Mini + Batch | 50% off inputs and outputs | potentially the cheapest version of the same workflow if asynchronous | No separate mini batch image card is published |
| Imagen 4 Fast | \$0.02 per image | mini high | June 24, 2026 shutdown date |
gemini-2.5-flash-image batch | \$0.0195 per image | mini high | October 2, 2026 shutdown date |
| FLUX.2 Klein 4B / 9B | from \$0.014 / \$0.015 | some lower-end mini-high comparisons | Megapixel pricing and a different quality target |
That table is the article. Everything else only explains when each row is honest.
When Google's cheaper rows are real
Google matters here, but only if you stay disciplined about what problem it is solving.
The clearest Google-hosted generation lane is Imagen 4 Fast at \$0.02 per image on Google's current Gemini Developer API pricing page. That is a useful answer when your current comparison point is mini high, not mini low or medium, and when you want a simple hosted generation product rather than a queue or workflow tweak inside OpenAI.
The catch is important enough that it has to stay in the same paragraph as the price. Google's current deprecations page lists imagen-4.0-fast-generate-001 with a June 24, 2026 shutdown date. That does not make Imagen 4 Fast unusable today. It does mean it is a short-horizon cheaper lane, not a forever default you can stop thinking about.
gemini-2.5-flash-image batch is even trickier. Google's pricing page currently shows \$0.0195 per image on batch pricing and \$0.039 per image on standard pricing. That makes batch the cheaper-looking row, and it is one of the few current mainstream numbers that can edge under mini high. But Google's deprecations page also lists October 2, 2026 as the shutdown date for gemini-2.5-flash-image. In other words, the cheaper row is real, but its clock is real too.
This is why weaker pages still fail the reader. They show Google's low row and stop there. The honest answer is narrower:
- use Imagen 4 Fast if you want a simple Google-hosted generation lane that is cheaper than mini high today
- use
gemini-2.5-flash-imagebatch only if a shorter-horizon Google batch lane is acceptable - do not describe either one as universally cheaper than mini
That last sentence is the whole trust test. If your current work already fits mini low or medium, Google is not giving you a cleaner price win. It is giving you a different platform, a different lifecycle, and a lower price only against one mini row.
The other reason to keep this section narrow is duplication. If you really need Google because the workflow itself is changing, not just the price row, this page is not the best place to flatten that into one sentence. The keyword here is cheaper-than-mini, not every possible reason to move to Google.
When BFL is cheaper only because the job changes
Black Forest Labs belongs in the article for a different reason.
The current BFL pricing page gives you one genuinely lower starting lane: FLUX.2 [klein] 4B from 0.014 and FLUX.2 [klein] 9B from 0.015 with megapixel-based pricing. That means Klein can sit below mini high and sometimes near the line where a reader starts asking whether external price now matters more than staying on the OpenAI stack.
But the reason BFL matters is not "here is a clean cheaper clone of mini." It is that Klein is a lower-end high-volume lane with a different product posture. BFL explicitly frames it around real-time, high-volume or balanced quality-speed use cases. That is a real route, but it is not the same promise as the GPT Image family.
This distinction is exactly what the live SERP keeps flattening away. Cheap does not always mean the same job, only at a lower number. Sometimes it means:
- lower-end quality expectations
- different output-size economics
- different operating assumptions
- a lane built for volume rather than for keeping OpenAI-style behavior
That is why I would keep the BFL recommendation narrow. Use FLUX.2 Klein when you are deliberately choosing a cheaper external volume lane, not when you want a one-to-one mini replacement.
The same BFL pricing page also helps by showing what does not belong on this page. FLUX.1 Kontext [pro] is 0.04 per image. That is not cheaper than mini high. It may still be the right model in an edit-heavy workflow, but that is a different question and belongs on the broader GPT Image 1 Mini alternative page, not on a cheaper-alternative page.
That contrast is useful because it keeps the article honest. BFL has cheaper-looking lanes, but the only price-first one here is Klein. If you need edit-heavy control, the answer has already moved from cheaper to better-fit.
When the real problem is setup, not price
One reason cheaper-alternative queries can look stronger than they really are is that access pain feels like price pain.
OpenAI's current organization-verification help page says verification unlocks image-generation capabilities, does not require spending thresholds, may take up to 30 minutes to update, and often resolves lingering access issues after you generate a new API key. That is not pricing advice, but it is crucial routing advice. If your issue is verification or route state, a vendor switch is solving the wrong problem.
The current OpenAI community thread on gpt-image-1 rate-limit errors makes the same point from the user side. People reported 429 or free-tier-style failures before any image generation actually happened, even after adding credits or verifying. The thread then drifted into payment-state, tier, support, and key-regeneration troubleshooting. That is not a cheaper-model conversation. It is a setup conversation that happens to feel expensive because nothing useful is shipping yet.
This section matters because the current SERP does not separate these states cleanly:
- model is too expensive for the job
- workflow is too expensive because you are not batching
- account or verification state is blocking access
Only the first one really demands a cheaper model. The second one might demand a cheaper workflow. The third one demands troubleshooting.
If your actual complaint sounds like "I am paying too much for keepable images," keep reading this page. If it sounds like "I still cannot get the route working cleanly," the better next step is OpenAI image API tutorial, not a provider migration.
How I would test the cheaper route in one afternoon
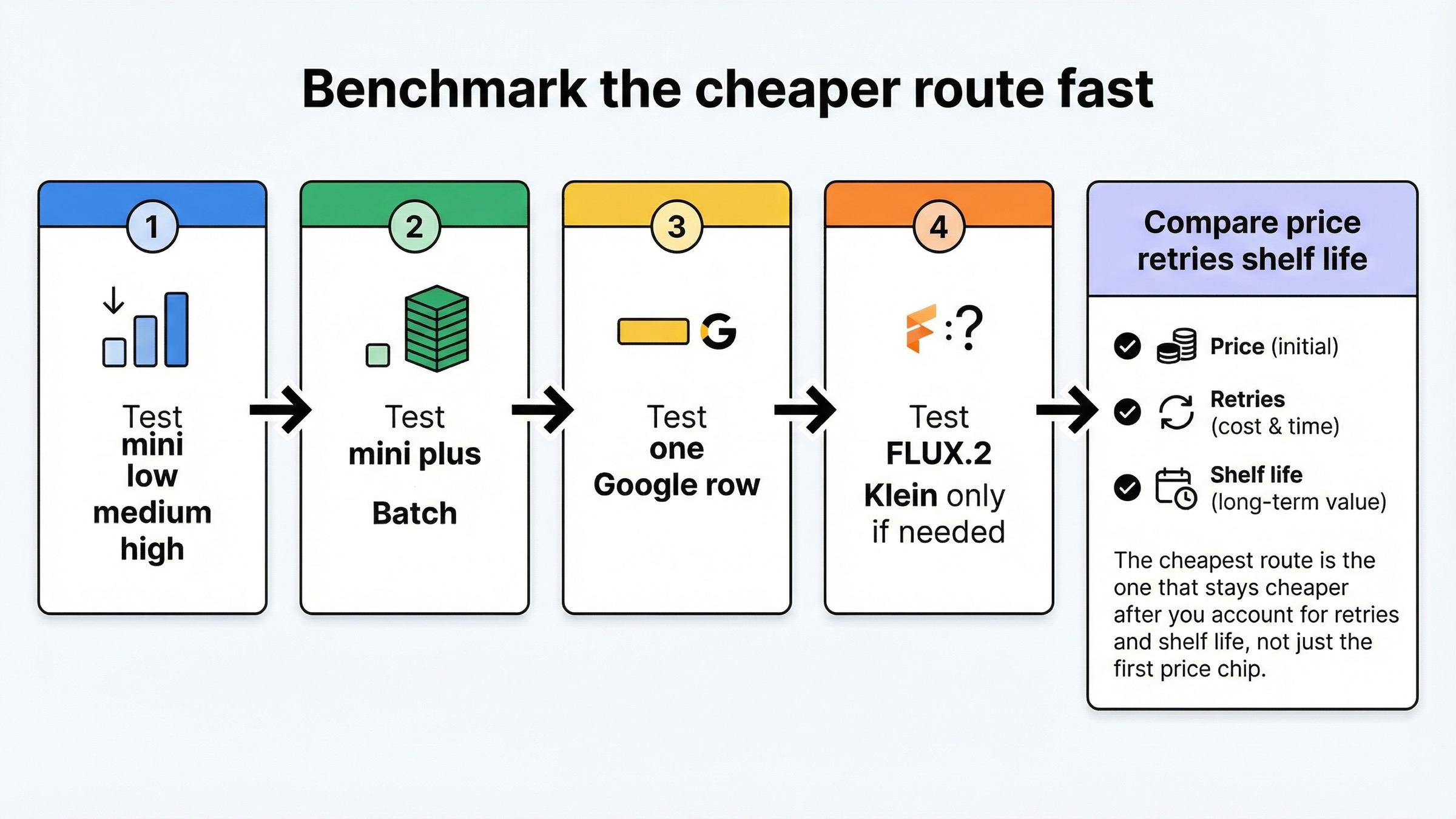
Do not pick this from one row. Pick it from one controlled afternoon.
- Run the same prompt set on mini low, medium, and high. The keyword is impossible to answer honestly if you never check which mini row you are actually comparing against.
- If the workload can wait, run mini through Batch. That is the first cheaper workflow route because it keeps the same model family and removes half the price on inputs and outputs at the platform layer.
- Run Imagen 4 Fast only if you are honestly comparing against mini high and want a simple Google-hosted generation lane.
- Run
gemini-2.5-flash-imagebatch only if the route is short-horizon enough that the October 2, 2026 shutdown date does not break your plan. - Run FLUX.2 Klein only if you are genuinely willing to buy a lower-end external volume lane rather than a like-for-like mini replacement.
Then compare three things, not one:
- price per usable image
- retry count to get something you would keep
- whether the route is still safe enough to build around after you account for shutdown dates and workflow shape
That last line is the one the current pricing guides usually skip. The cheapest row is not the whole answer. The cheaper route is the one that stays cheaper after you account for queue shape, quality expectation, and shelf life.
FAQ
Is anything actually cheaper than gpt-image-1-mini overall?
Not as a clean current mainstream hosted swap. The only rows that clearly undercut mini today either beat mini high only, depend on Batch, or change the job enough that you are no longer buying the same kind of route.
What is the cheapest way to keep using mini?
Start by checking whether mini low or mini medium is already enough, then test Batch if the workload can run asynchronously. That is usually the first honest cheaper move because it keeps the same model family instead of forcing a migration before you know the cheaper requirement is real.
Should I switch to Google just because the sticker price looks lower?
Only if you are honestly comparing against mini high and you are comfortable with the route's lifecycle caveat. Imagen 4 Fast and gemini-2.5-flash-image batch can look cheaper in that narrower comparison, but neither is cheaper than mini low or medium, and both have 2026 shutdown dates listed in Google's current docs.
Bottom line
The best gpt-image-1-mini cheaper alternative is usually not another mainstream hosted image model.
If price is the whole problem, keep mini and test Batch first. If you are only trying to beat mini high, Imagen 4 Fast and gemini-2.5-flash-image batch are real current rows, but both carry 2026 shutdown caveats and neither is cheaper than mini low or medium. If you want a lower-end external volume lane, FLUX.2 Klein is the cleanest BFL option, but it is still a job change, not a universal mini replacement. And if the pain is verification or access state, fix setup before you call this a pricing problem.
That is the honest answer the current SERP still hides. Mini is already the floor. The real work is deciding whether you need to optimize it, outgrow it, or stop misdiagnosing a setup issue as a model-pricing issue.