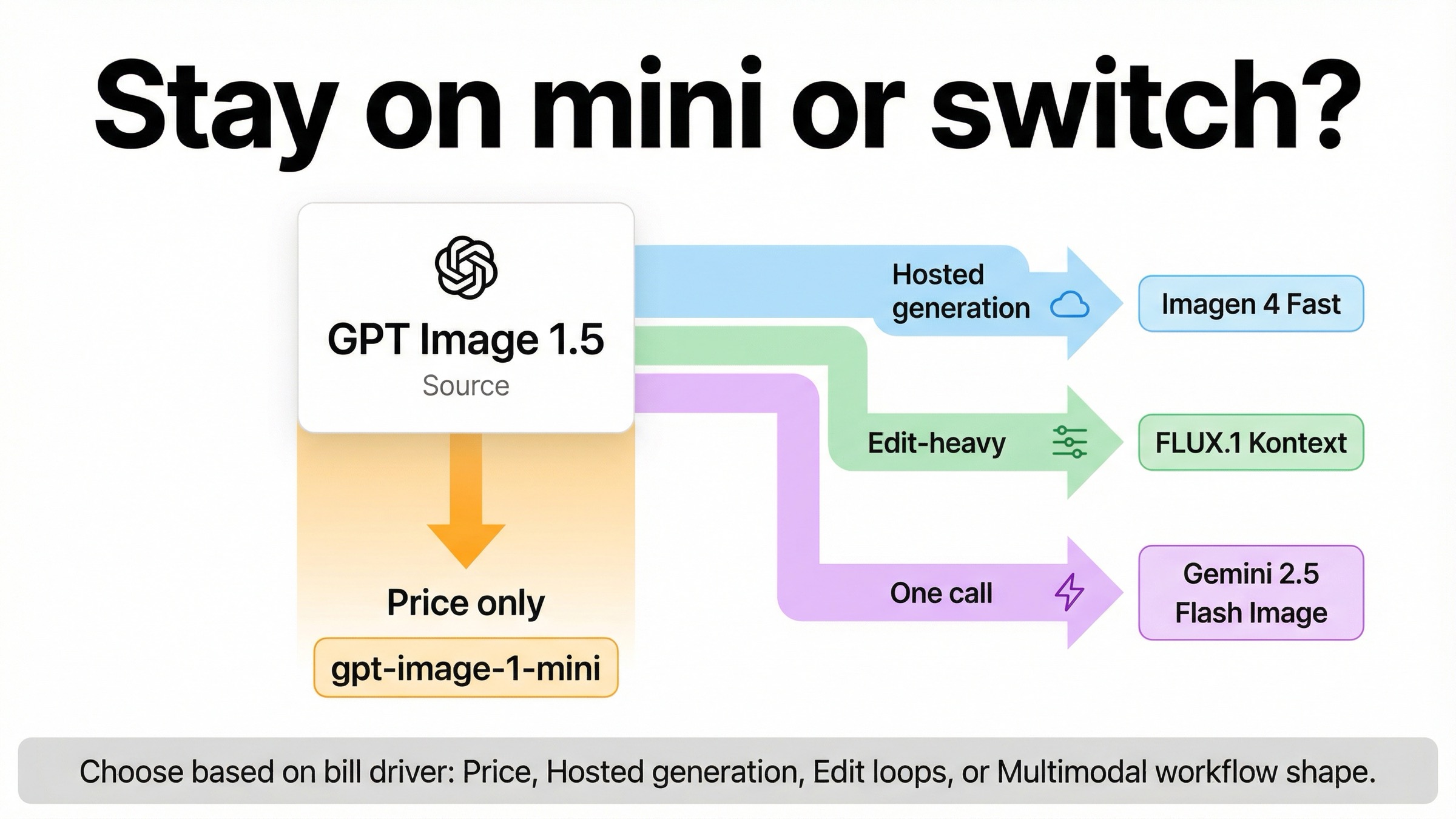
As checked on March 29, 2026, the best GPT Image 1.5 cheaper alternative depends on what you mean by cheaper. If price is the whole problem, the first move is usually OpenAI's own gpt-image-1-mini, which OpenAI currently lists at \$0.005, \$0.011, and \$0.036 for square low, medium, and high outputs. Switch outside OpenAI only when the workflow changes what "cheaper" means: use Imagen 4 Fast for a cheaper hosted generation lane, FLUX.1 Kontext for edit-heavy revision loops, and Gemini 2.5 Flash Image only when one multimodal call replaces multiple steps you would otherwise pay for separately.
That is the distinction most ranking pages still blur. Some pages are answering "cheaper than GPT Image 1.5 specifically." Others are answering "cheaper than OpenAI overall." Those are not the same question, because OpenAI already sells a much cheaper image lane, and that one fact changes the opening recommendation for a large share of buyers.
There is another hidden split worth naming early. Some "cheaper alternative" searches are not really price-routing questions at all. They are usage-tier, verification, or setup-friction problems that happen to feel expensive because the workflow never got far enough to prove whether GPT Image 1.5 was the wrong model in the first place. This page keeps those cases separate instead of treating every frustration like a migration trigger.
TL;DR

If you only need the routing answer, start here.
| If your real problem is... | Use this instead | Why it is the cheapest credible move | Main tradeoff |
|---|---|---|---|
| you only want a lower official price than GPT Image 1.5 | gpt-image-1-mini | OpenAI still lists it below GPT Image 1.5 on every square quality row | You give up the flagship lane's higher ceiling |
| you want a cheaper mainstream hosted generation lane than GPT Image 1.5 | Imagen 4 Fast | Google currently lists \$0.02 per image, which undercuts GPT Image 1.5 medium and high | It is a different provider stack and not cheaper than mini |
| retries, edits, and text fixes are what keep making GPT Image 1.5 expensive | FLUX.1 Kontext | It can lower effective cost by preserving more of the image you already like | Its posted \$0.04 row is not the lowest headline number |
| one interaction needs to reason in text and then return an image | Gemini 2.5 Flash Image | One multimodal call can replace multiple model steps and glue code | The price is token-based, and image output alone is not the cheapest row |
| the issue is 429s, verification, or access state rather than model fit | Stay with OpenAI and fix setup first | A provider switch does not solve a route or account-state problem | You still have to debug setup before judging model economics |
What actually costs less than GPT Image 1.5?

The cleanest way to answer this keyword is to separate price surfaces before talking about alternatives. OpenAI's current GPT Image 1.5 model page lists square 1024x1024 generation at \$0.009, \$0.034, and \$0.133 for low, medium, and high outputs. The current gpt-image-1-mini page lists \$0.005, \$0.011, and \$0.036 for the same square ladder. That already tells you something most "best alternatives" pages skip: if you only want a cheaper OpenAI image lane, OpenAI itself is still the first place to look.
External options matter, but they matter for narrower reasons. Google's current Vertex AI pricing page lists Imagen 4 Fast at \$0.02 per image, which makes it a real cheaper-than-GPT-Image-1.5 answer for many generation-first workloads. Black Forest Labs' current pricing page lists FLUX.1 Kontext [pro] at \$0.04 per image, which is not a clean headline-price win over GPT Image 1.5 medium at \$0.034, but can still be cheaper when revision count is the real cost center. Google's current Gemini 2.5 Flash Image model page says one generated image consumes 1290 tokens, and Vertex pricing lists image output at \$30 per 1M tokens, which implies roughly \$0.0387 of output-image cost per image before input tokens. That is an inference from official numbers, not a flat per-image card.
That is why this keyword needs a decision table instead of a generic leaderboard.
| Option | Current price surface | What it is cheaper than | Best fit | Why it is not the universal answer |
|---|---|---|---|---|
| GPT Image 1.5 | \$0.009 / \$0.034 / \$0.133 square low, medium, high | reference point only | flagship OpenAI image work | You are already paying the premium lane |
gpt-image-1-mini | \$0.005 / \$0.011 / \$0.036 square low, medium, high | cheaper than GPT Image 1.5 on all square rows | volume-heavy, low-stakes, or prototype work | It does not solve every quality or edit-fidelity complaint |
| Imagen 4 Fast | \$0.02 per image | cheaper than GPT Image 1.5 medium and high | cheaper hosted generation outside OpenAI | It is not cheaper than mini and does not solve multimodal workflow needs |
| FLUX.1 Kontext [pro] | \$0.04 per image | sometimes cheaper in practice, not by headline row | edit-heavy workflows with repeated revisions | Value comes from fewer retries, not the lowest posted price |
| Gemini 2.5 Flash Image | about \$0.0387 output-image cost before inputs | cheaper only when workflow compression matters | text-plus-image reasoning and rendering in one call | It is token-priced and harder to compare as pure image generation |
The short version is simple. Cheaper than GPT Image 1.5 is not the same as cheaper than OpenAI overall. If the reader means "what is the lowest-cost official move without leaving OpenAI," mini wins. If the reader means "what is a credible cheaper hosted lane than GPT Image 1.5 medium or high," Imagen 4 Fast is the clearest mainstream answer. FLUX and Gemini only become the right cheaper answer when the workflow itself is what makes GPT Image 1.5 feel expensive.
If your next question is pure OpenAI cost math rather than vendor choice, read GPT Image 1.5 API pricing and GPT Image 1.5 cost per image. Those pages go deeper on the official ladder. This article is about the switch rule.
Stay with gpt-image-1-mini when price is the whole problem
This is the most important section in the article because it is the one most alternatives pages still avoid. OpenAI's current image-generation guide explicitly says gpt-image-1-mini is the more cost-effective option when image quality is not the priority. That is not a throwaway positioning note. It is the official reason many teams should downshift before they migrate.
If your workload is high-volume ideation, internal mockups, disposable concept variants, or low-stakes generation where retries are acceptable, mini is usually the first thing to benchmark. It keeps you inside the same provider, avoids a stack change, and undercuts the mainstream hosted alternatives on raw entry price. On square outputs, mini starts at \$0.005 versus GPT Image 1.5 low at \$0.009, mini medium is \$0.011 versus \$0.034, and mini high is \$0.036 versus \$0.133. That is not a small discount. It is a different pricing lane.
The temptation to switch vendors too early usually comes from reading the wrong symptom. A team says "GPT Image 1.5 is too expensive," but what they really mean is "we started on the flagship lane before we knew whether this was flagship work." In that situation, a full migration is often false economy. The cheaper, lower-risk move is to keep the same API family and see whether the budget lane already satisfies the actual job.
That does not mean mini is secretly the answer to every cost complaint. If your real pain is brand preservation, better text rendering, higher-confidence edits, or client-facing outputs where the retry budget is low, the flagship premium may still be rational. But that is exactly why mini belongs at the top of this article. A trustworthy page has to tell the reader when not to leave.
If you want the broader case for staying inside OpenAI first, OpenAI image generation API cheaper alternative covers the wider market view, while GPT Image 1 Mini pricing goes deeper on the cost floor this article is using as its default control.
Use Imagen 4 Fast when you want a cheaper hosted generation lane
If you already know the problem is GPT Image 1.5 specifically, not OpenAI mini, then Imagen 4 Fast is the cleanest mainstream external answer.
Google's current Vertex AI pricing page lists Imagen 4 Fast at \$0.02 per image, and the current Imagen 4 documentation presents it as a dedicated image-generation lane with support for up to 4 output images per prompt. That matters because it means you are comparing one generation-first product against another, not forcing a chat-oriented multimodal model into an apples-to-apples image price fight.
This is the right route when the operator rule sounds like this: "I still want a hosted image-generation product, but GPT Image 1.5 medium and high are too expensive for my volume." In that case, Imagen 4 Fast gives you a simpler external switch story than FLUX or Gemini. The cost surface is easier to understand, the product shape is closer to the original job, and the savings versus GPT Image 1.5 medium or high are visible immediately.
It is still important not to oversell it. Imagen 4 Fast is not the cheapest option in the whole decision tree. It is not cheaper than mini, and it is not automatically the best answer for edit-heavy or multimodal work. Its strength is narrower and cleaner: a mainstream hosted generation lane with a current list price that beats GPT Image 1.5 medium and high without introducing token-heavy multimodal reasoning as part of the buying story.
That is why this article routes Imagen differently from Gemini. If the job is still mostly "generate images in the cloud, keep the billing simple, and pay less than GPT Image 1.5," Imagen 4 Fast is the clearest switch.
Use FLUX.1 Kontext when retries and edits are making GPT Image 1.5 expensive
Some teams are not overpaying because the first image costs too much. They are overpaying because the second, third, and fourth changes keep destroying what already worked.
That is the best case for FLUX.1 Kontext. Black Forest Labs' current Kontext overview positions the model around image editing, character consistency, text editing, and style transformation. That is a workflow promise, not a simple price-card promise. It is aimed at the part of image work where you are repeatedly telling the model to preserve the subject, keep the composition, replace the text, or make one local change without forcing a near-restart.
The posted price makes this point easy to miss. BFL's current pricing page lists FLUX.1 Kontext [pro] at \$0.04 per image, which means it is not a universal headline-price win over GPT Image 1.5. It is higher than GPT Image 1.5 medium at \$0.034, lower than GPT Image 1.5 high at \$0.133, and obviously higher than mini's cheapest rows. If you stop at that table, Kontext looks like a weak answer to a cheaper-alternative query.
That is the wrong reading. The real question is not "what does the first draft cost?" It is "how much do I pay for one image I can actually keep?" If your team keeps saying:
- keep the character, but change the scene
- keep the product shot, but fix the label text
- keep the layout, but make three campaign variants
- keep everything else, but swap this one visual element
then the cheaper model can be the one that preserves more of the current image rather than the one with the lowest first-row price. Kontext belongs in this article for that reason. It is an effective-cost alternative, not a blanket cheaper-per-image winner.
That is also why I would not recommend it as the default replacement for GPT Image 1.5. Use it when the money is leaking through revision pressure. If the workload is still mostly one-shot generation, mini or Imagen is usually the cleaner cost-down move.
Use Gemini 2.5 Flash Image only when one call must think and render
Google belongs in this article twice because it sells two genuinely different answers.
Imagen 4 Fast is the cheaper hosted generation lane. Gemini 2.5 Flash Image is the workflow alternative for teams that want one call to understand text, use images as context, continue the interaction, and then return an image. Those are different jobs, and this article has to keep them separate or the pricing advice becomes sloppy.
Google's current Gemini 2.5 Flash Image model page says the model accepts text and image inputs, returns text and image outputs, supports multi-turn image editing, and uses 1290 tokens per generated image. Combined with Vertex pricing at \$30 per 1M image-output tokens, that works out to about \$0.0387 of output-image cost per image before input tokens. That is why Gemini is not the cleanest answer if your only requirement is cheaper image generation. On image output alone, it is not beating mini, and it is not a clean headline win over GPT Image 1.5 medium either.
Where Gemini starts to make sense is when one multimodal call replaces multiple paid steps you are already stitching together. If the current workflow looks like "text model to reason, image model to render, then extra orchestration to keep the conversation coherent," Gemini can change the economics by collapsing those steps into one surface. In that case, cheaper is not about the image row alone. It is about the workflow bill.
This is the section where weaker roundup pages usually go wrong. They see a Google image model and treat it as just another one-shot generator. That misses the main reason to buy it. Gemini 2.5 Flash Image is the right alternative when you need the model to think and render together. If you do not need that, Imagen is the cleaner Google comparison and mini is still the cheaper OpenAI control.
When the real problem is setup, not price
This keyword family attracts a lot of frustrated searches that sound like cost problems but are actually access problems. OpenAI's current help article on API model availability by usage tier and verification status says gpt-image-1 and gpt-image-1-mini are available across tiers 1 through 5, with some access still subject to organization verification. That means a painful first experience with the API does not automatically prove that the model is overpriced or that another provider is the right next step.
This matters because setup friction changes how teams interpret cost. A 429, a verification block, or a route mistake can make every attempt feel expensive even before a serious benchmark happens. If that is the real situation, a provider switch may only replace one kind of debugging with another.
The trust-building rule here is simple. If the problem is account state, verification, tier access, or route confusion, solve that first. If the problem is the actual posted or effective cost of the workflow after setup is working, then use the routing logic from the sections above. Those are different failure modes, and the cheaper answer is different too.
This section also protects the article from over-claiming. Not every GPT Image 1.5 complaint should end in "switch vendors." Sometimes the honest answer is still "stay with OpenAI, fix the route, and then judge the economics on a clean test."
How I would test the switch in one afternoon
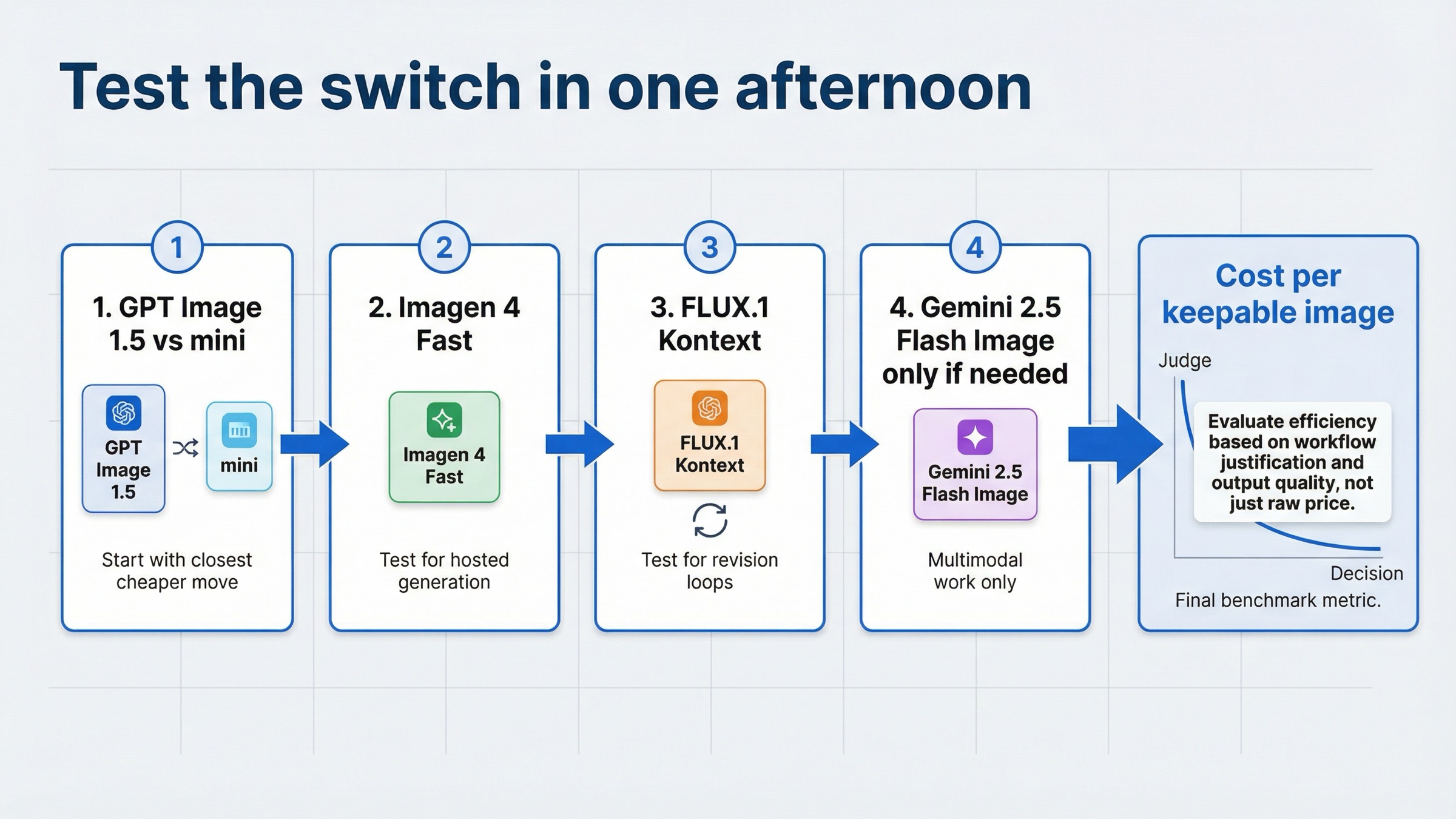
The cleanest way to avoid a bad migration is to benchmark the exact failure mode, not the brand names.
- Run the same prompt set on GPT Image 1.5 and
gpt-image-1-minifirst. If mini is already good enough, stop there. - Run one generation-first benchmark on Imagen 4 Fast. Use the same target outputs you currently generate on GPT Image 1.5 medium or high.
- Run one revision-loop benchmark on FLUX.1 Kontext. Use a task that requires preserving the image while changing text, layout detail, or one local element.
- Run one multimodal benchmark on Gemini 2.5 Flash Image only if the product genuinely needs text-plus-image behavior in one interaction.
- Compare cost by usable output, not by the first invoice line. The cheaper winner is the model that gets you to a keepable image with the least total operator effort and retry spend.
That sequence is intentionally narrow. Most weak comparison pages start with a broad market tour. The better test starts with the closest cheaper move, then escalates only when the workflow justifies it.
Bottom line
The best GPT Image 1.5 cheaper alternative is not one universal winner. It is the cheapest move that solves the reason GPT Image 1.5 feels expensive in your workflow.
If price is the whole problem, start with gpt-image-1-mini. If you want a cheaper mainstream hosted generation lane than GPT Image 1.5, use Imagen 4 Fast. If revisions and preservation are what keep driving the bill up, use FLUX.1 Kontext. If one call needs to think and render together, use Gemini 2.5 Flash Image. And if the pain is really access or verification, fix setup before treating this as a provider decision.