
February 2026 delivered an unprecedented wave of frontier AI models within weeks of each other, and the comparison landscape is already filled with outdated pricing and superficial benchmark tables. After verifying every data point directly from official pricing pages, we can confidently say there is no single winner among Gemini 3.1 Pro, Claude Opus 4.6, and GPT-5.3-Codex. Each model dominates distinct domains: Gemini leads in scientific reasoning and cost efficiency at $2 per million input tokens, Opus excels in agentic coding with its unique Agent Teams architecture, and Codex delivers unmatched autonomous execution speed through its sandboxed environment. What follows is the most thoroughly verified comparison available as of March 2026.
TL;DR - Quick Comparison Summary
Before diving into the details, here is the essential comparison across the dimensions that matter most to developers making production decisions right now. Every pricing figure in this table was verified directly from official pricing pages using browser automation on March 2, 2026, and we discovered that several competing articles are citing incorrect pricing data, particularly for Opus 4.6. This matters because developers making infrastructure decisions based on wrong pricing numbers can easily over- or under-budget by thousands of dollars per month, leading to either wasted resources or unexpected cost overruns that force mid-project model switches.
| Feature | Gemini 3.1 Pro | Claude Opus 4.6 | GPT-5.3-Codex |
|---|---|---|---|
| Released | Feb 19, 2026 | Feb 5, 2026 | Feb 2026 |
| Input Price | $2/MTok | $5/MTok | Not on API |
| Output Price | $12/MTok | $25/MTok | Not on API |
| Context Window | 1M (GA) | 200K / 1M (beta) | 400K |
| Max Output | 64K | 128K | 128K |
| Best Benchmark | ARC-AGI-2: 77.1% | SWE-Bench: 80.8% | Terminal-Bench: 77.3% |
| Sweet Spot | Research, Science, Long Context | Complex Coding, Agents | Autonomous Execution |
| API Access | Standard API | Standard API | Codex products only |
The most critical takeaway is that GPT-5.3-Codex does not have standalone API pricing on OpenAI's pricing page. It is available exclusively through the Codex app, CLI, IDE extensions, and GitHub Copilot, making it fundamentally different from the other two models in terms of how you integrate it into your workflow. If you need a direct API call with per-token billing, your real choice is between Gemini 3.1 Pro and Claude Opus 4.6, and the decision comes down to whether you prioritize cost efficiency and reasoning breadth or agentic coding depth and reliability. We explore each of these dimensions in exhaustive detail below, starting with the benchmark numbers that define each model's competitive territory, then moving into the pricing reality that most articles get wrong, and finally arriving at a practical decision framework that maps your specific workflow to the right model choice.
Benchmark Head-to-Head - Who Wins What
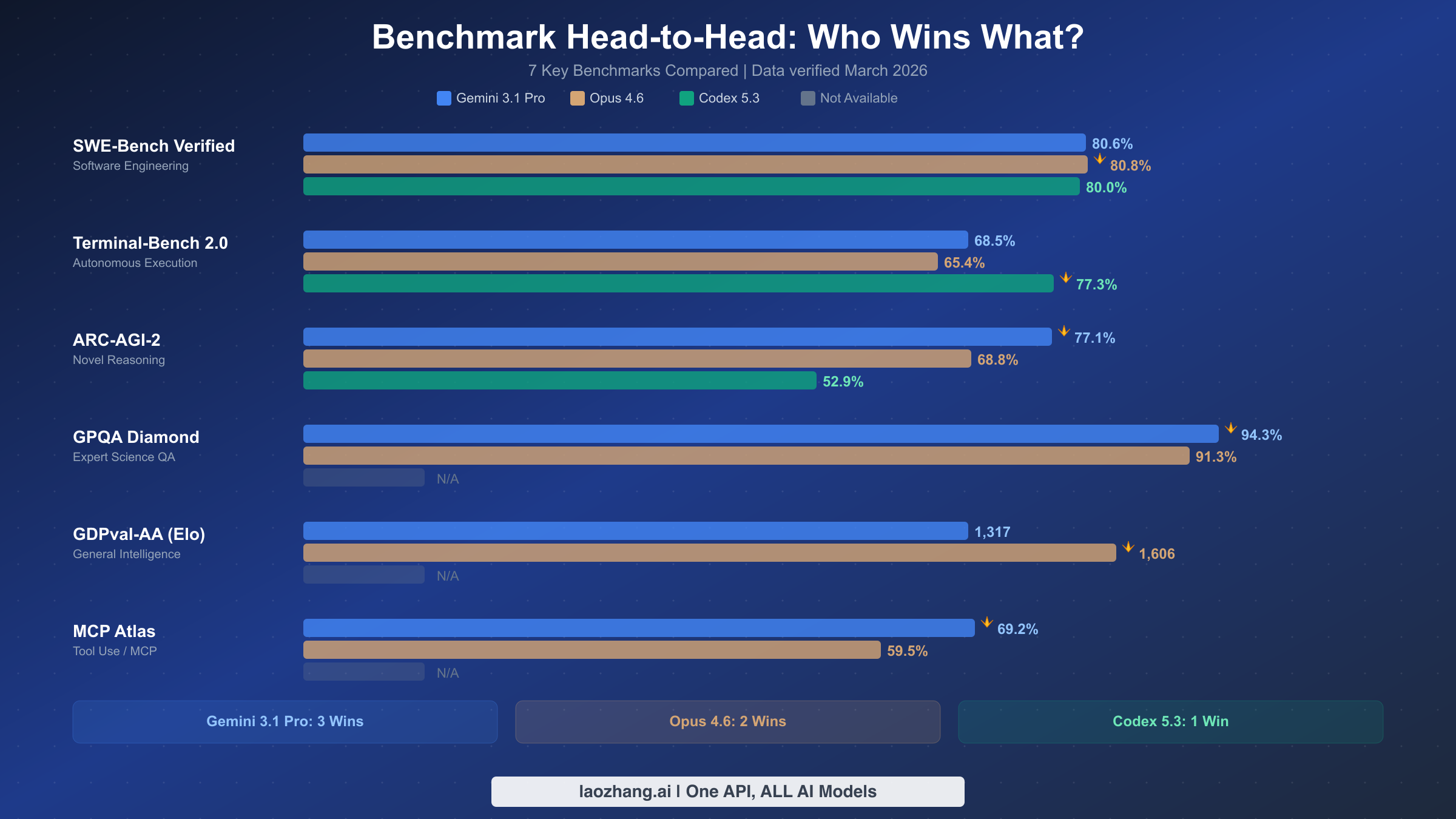
The benchmark landscape for these three models reveals a pattern that challenges the simplistic "one model to rule them all" narrative. Each model has carved out distinct territory, and understanding where each excels requires looking beyond raw numbers to what the benchmarks actually measure.
SWE-Bench Verified, the gold standard for software engineering evaluation, shows an incredibly tight race. Opus 4.6 edges ahead at 80.8%, followed by Gemini 3.1 Pro at 80.6% and Codex 5.3 at 80.0%. The differences here are within the margin of variance for most practical purposes, which means all three models are roughly equivalent at solving real-world GitHub issues. This is remarkable because it was not the case just six months ago, when there was a clear gap between the leading model and the rest. For a deeper dive into how Opus and Codex compare specifically on coding tasks, check out our detailed Opus 4.6 vs GPT-5.3 comparison.
Terminal-Bench 2.0 tells a very different story and is where Codex 5.3 truly shines with 77.3%, well ahead of Gemini's 68.5% and Opus's 65.4%. This benchmark measures autonomous execution capability, meaning the model's ability to operate a terminal, run commands, debug failures, and complete multi-step tasks without human intervention. Codex's lead here makes sense given that it was specifically designed around sandboxed execution environments where the model can freely run code, check outputs, and iterate on solutions. This is the benchmark that matters most if your use case involves handing off entire tasks to an AI agent and expecting completed work back.
ARC-AGI-2 measures novel reasoning ability, and Gemini 3.1 Pro dominates with 77.1% compared to Opus's 68.8% and Codex's 52.9%. This is the single largest gap between any two models in any benchmark, and it reflects Google's investment in reasoning capabilities through their Mixture-of-Experts architecture. The ARC-AGI-2 benchmark specifically tests the ability to solve problems the model has never seen before, making it a proxy for general intelligence rather than pattern matching against training data.
GPQA Diamond, which tests expert-level scientific question answering, shows Gemini 3.1 Pro at 94.3% versus Opus 4.6 at 91.3%. Codex 5.3 does not have a published score for this benchmark. The three-point gap here is meaningful because GPQA Diamond questions are designed to be challenging even for PhD-level domain experts. If your workflow involves scientific research, medical reasoning, or complex analytical tasks, Gemini has a measurable advantage.
GDPval-AA, measured in Elo rating, shows Opus 4.6 leading at 1,606 compared to Gemini's 1,317. This benchmark evaluates general instruction following and coherence in dialogue, an area where Anthropic's Constitutional AI training approach appears to pay dividends. The 289-point Elo gap is substantial and suggests that Opus produces more consistently high-quality, nuanced responses in conversational settings. For a focused comparison of how these two models stack up, see our Gemini 3.1 Pro vs Opus 4.6 head-to-head analysis.
One additional benchmark worth mentioning is MCP Atlas, which measures how effectively models use external tools through the Model Context Protocol. Gemini 3.1 Pro scores 69.2% compared to Opus 4.6's 59.5%, with Codex 5.3 not reporting a score. This is particularly relevant for developers building agentic applications where the model needs to orchestrate calls to databases, APIs, and file systems. Gemini's lead here suggests its MoE architecture routes tool-use queries to specialized experts that handle API schema understanding and parameter generation more effectively.
The bottom line is that no model wins across all benchmarks. Gemini 3.1 Pro leads in reasoning and science (3 benchmark wins including the crucial ARC-AGI-2 and MCP Atlas), Opus 4.6 leads in coding quality and general intelligence (2 wins on SWE-Bench and GDPval-AA), and Codex 5.3 dominates autonomous execution (1 win on Terminal-Bench, but a decisive 12-point margin). Your choice should be driven by which benchmark category aligns most closely with your actual workload, and for most teams, that means honestly assessing whether your bottleneck is reasoning quality, code correctness, or execution automation.
Real Pricing - What These Models Actually Cost in 2026
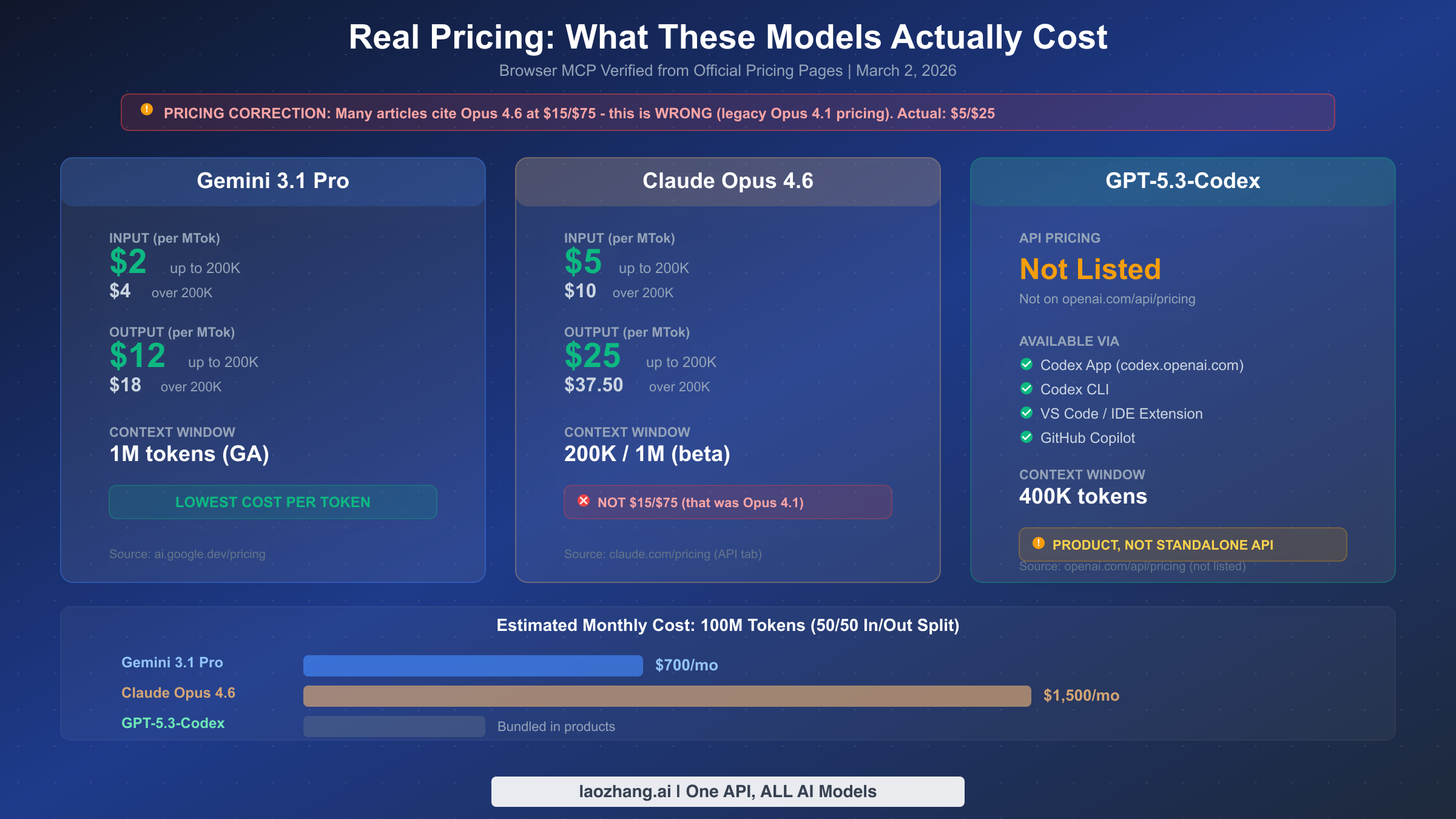
Pricing is where we found the most dangerous misinformation in existing comparison articles. Multiple top-ranking articles cite Claude Opus 4.6 pricing as $15 per million input tokens and $75 per million output tokens. This is wrong. Those are the legacy prices for Opus 4.1 and 4.0. The actual Opus 4.6 pricing, verified directly from claude.com/pricing on March 2, 2026, is $5 per million input tokens and $25 per million output tokens for prompts up to 200K context. For longer prompts exceeding 200K tokens, pricing increases to $10 input and $37.50 output per million tokens.
Gemini 3.1 Pro offers the most competitive per-token pricing of any frontier model currently available through a standard API. At $2 per million input tokens and $12 per million output tokens (verified from ai.google.dev/pricing on March 2, 2026), it is 60% cheaper than Opus 4.6 on input and 52% cheaper on output. For prompts exceeding 200K tokens, Gemini's pricing doubles to $4 input and $18 output, which is still substantially cheaper than Opus's extended context rates. If you are running high-volume inference workloads and cost is a primary concern, this pricing advantage compounds quickly. For complete details on Gemini pricing tiers and discounts, see our Gemini API pricing details for 2026.
GPT-5.3-Codex presents an entirely different pricing model because it does not appear on OpenAI's API pricing page at all. We verified this by navigating to openai.com/api/pricing on March 2, 2026 and found GPT-5.2 listed at $1.75/$14 per million tokens, but GPT-5.3-Codex was absent. This means you cannot call it via a standard API endpoint with per-token billing. Instead, you access it through Codex products: the web app at codex.openai.com, the Codex CLI, IDE extensions, or GitHub Copilot. The cost is bundled into your existing OpenAI or GitHub subscription rather than billed per token, which makes direct cost comparison with the other two models difficult.
Total Cost of Ownership: Three Real-World Scenarios
To make pricing practical, consider these three usage scenarios with estimated monthly costs:
Scenario 1: Individual Developer (10M tokens/month, 60/40 input/output split). For a developer using an AI coding assistant throughout their workday, Gemini 3.1 Pro would cost approximately $60 per month, while Opus 4.6 would cost approximately $130. Codex 5.3 is effectively included in a $200/month ChatGPT Pro or enterprise GitHub Copilot subscription, making it cost-effective only if you already pay for those services.
Scenario 2: Small Team Code Review Pipeline (100M tokens/month, 70/30 input/output split). A team of 5-10 developers running automated code review would spend approximately $500 per month on Gemini 3.1 Pro versus approximately $1,100 on Opus 4.6. At this scale, the pricing gap becomes meaningful, and teams should seriously consider whether the coding quality improvements of Opus justify a 2.2x cost premium. For teams already using API aggregation services like laozhang.ai, unified billing across multiple models can simplify cost management while maintaining competitive rates.
Scenario 3: Enterprise Agent Pipeline (1B tokens/month, 50/50 split). At enterprise scale, Gemini 3.1 Pro costs approximately $7,000 per month while Opus 4.6 runs approximately $15,000. However, Anthropic offers significant batch processing discounts (50% off) and prompt caching discounts that can narrow this gap considerably. For a comprehensive breakdown of Claude pricing tiers, see our complete Claude API pricing breakdown.
The pricing decision ultimately depends on whether the quality difference between models justifies the cost premium for your specific use case. For reasoning-heavy workloads, Gemini offers the best value. For complex coding tasks where quality differences translate to fewer bugs and less rework, Opus's premium may pay for itself.
How to Access Each Model - API, CLI, and Beyond
One of the most misunderstood aspects of this three-way comparison is how you actually access each model. While Gemini 3.1 Pro and Claude Opus 4.6 follow the familiar "get an API key and make HTTP requests" pattern, GPT-5.3-Codex breaks from this model entirely, and understanding this distinction is essential before committing your team to a particular workflow.
Gemini 3.1 Pro is accessible through Google's AI Studio and the Vertex AI platform. You generate an API key at ai.google.dev, and calls follow the standard REST pattern with the model ID gemini-3.1-pro-preview. Google also offers client libraries for Python, JavaScript, Go, and other languages. The model is currently in "Preview" status, meaning Google may make breaking changes before GA, but in practice the API has been stable since launch. One notable advantage is that Gemini offers a free tier with generous rate limits, making it accessible for experimentation without any credit card.
Claude Opus 4.6 is available through Anthropic's API with the model ID claude-opus-4-6. Access requires an API key from console.anthropic.com. Anthropic provides official SDKs for Python and TypeScript, and the API follows a clean, well-documented format. Opus 4.6 is already Generally Available (GA), meaning the API is stable and production-ready. The model is also accessible through Claude.ai, Claude Code (Anthropic's CLI tool), and various IDE integrations. For agentic use cases, Opus 4.6 supports the Agent Teams feature through Claude Code, allowing it to spawn sub-agents that work in parallel on complex tasks.
GPT-5.3-Codex requires a fundamentally different approach. There is no gpt-5.3-codex model endpoint on OpenAI's API. Instead, you access it through four channels: the Codex web application at codex.openai.com where you assign tasks that the model works on asynchronously in sandboxed environments; the Codex CLI which integrates into your terminal workflow; IDE extensions for VS Code and JetBrains; and GitHub Copilot where the Codex model powers the coding assistant. This product-oriented approach means Codex excels at complete task execution (write a feature, fix a bug, create a PR) rather than streaming token-by-token responses. If your workflow already centers on GitHub and you want an AI that can autonomously complete pull requests, Codex is purpose-built for that. But if you need to embed model calls into custom applications with per-token control, Codex is not the right choice.
The practical implication of these different access patterns is significant for architecture decisions. If you are building a product that needs to call AI models programmatically with fine-grained control over token usage, model parameters, and response streaming, then Gemini 3.1 Pro and Claude Opus 4.6 are your options. If you want an AI that operates more like a junior developer who takes task descriptions and returns completed work, Codex 5.3 is designed precisely for that use case. Many sophisticated teams use both patterns: API-based models for real-time user-facing features and Codex for background automation tasks like test generation and documentation updates.
For teams that need flexibility across multiple models, API aggregation platforms can simplify multi-model workflows. A service like laozhang.ai provides a unified API endpoint that supports both Gemini and Claude models, allowing teams to route requests to the optimal model without managing multiple API keys and billing systems. This is particularly valuable during the current period of rapid model releases, where the optimal model for a given task type can change quarter to quarter, and you want the flexibility to switch without rewriting integration code.
Under the Hood - Why Each Model Excels Where It Does

Understanding architecture explains the "why" behind the benchmark numbers, and this is where most comparison articles fall short. They tell you what each model scores but not why it scores that way. The architectural differences between these three models are not just academic curiosities; they directly predict which workloads each model will handle best.
Gemini 3.1 Pro's Mixture-of-Experts (MoE) architecture is the key to both its reasoning superiority and its cost efficiency. Instead of activating the entire neural network for every query, MoE selectively routes each input to a small number of specialized "expert" sub-networks. Think of it as having a team of specialists where only the relevant ones engage for each task. This is why Gemini can maintain a massive total parameter count (enabling strong performance on diverse tasks) while keeping inference costs low (because only a fraction of parameters are activated per query). The MoE design particularly benefits scientific and mathematical reasoning because the model can route complex analytical queries to experts specifically trained on those domains. It also explains why Gemini offers the largest production context window at 1 million tokens in General Availability: the efficient expert routing makes long-context processing computationally viable at scale.
Claude Opus 4.6's dense transformer architecture with Constitutional AI represents a different philosophy. Rather than routing to specialists, every parameter participates in every computation, which produces more consistent and nuanced outputs at the cost of higher inference expense. The breakthrough innovation in Opus 4.6 is the GVR (Generate-Verify-Reflect) loop for coding tasks: the model generates code, runs verification checks, and then reflects on the results before iterating, a process that mirrors how experienced developers work. This self-correcting loop is why Opus leads on SWE-Bench and produces fewer bugs in practice. The Agent Teams architecture extends this further by allowing Opus to spawn sub-agents that work on different parts of a problem simultaneously, something that Anthropic reports has led to 500+ zero-day vulnerability discoveries across major open-source projects. The behavioral signature of Opus, confirmed by developer testimonials from JetBrains and Databricks engineers, is that it asks clarifying questions before implementing, resulting in solutions that more accurately match the developer's intent.
GPT-5.3-Codex's optimized GPT-5 variant is purpose-built for speed and autonomous execution. Two innovations define it: first, the Spark mode that achieves 1,000+ tokens per second, making it roughly 25% faster than GPT-5.2 and substantially faster than either Gemini or Opus for raw generation speed. Second, the sandboxed execution model where Codex operates in isolated cloud environments with full access to git, terminal commands, and testing frameworks. This is why Codex dominates Terminal-Bench: it does not just generate code that should work, it actually runs the code, observes the output, debugs failures, and iterates until the task passes all tests. The behavioral pattern here is the opposite of Opus: Codex implements first and asks questions later, rapidly prototyping solutions and iterating on failures rather than planning extensively upfront. For a more detailed comparison of how GPT-5.3 Codex and Opus 4.6 compare in practice, we explored specific coding scenarios in our dedicated article.
The training methodology differences are equally important. Google's approach with Gemini involves training natively across multiple data modalities including text, code, images, audio, and video from the start, rather than fine-tuning a text model to handle other modalities afterward. This native multimodal training is why Gemini handles mixed-modality inputs more naturally, such as understanding a screenshot of a UI alongside a text description of the desired changes. Anthropic's training for Opus emphasizes Constitutional AI, where the model learns to evaluate and improve its own outputs against a set of principles, creating the careful, self-correcting behavior that developers notice in practice. OpenAI's training for Codex focused specifically on code execution and tool use, with extensive reinforcement learning from human feedback on code-generation quality and autonomous task completion.
These architectural and training differences create clear implications for model selection. If you need the most tokens processed per dollar with strong reasoning across modalities, MoE-based Gemini is optimal. If you need the highest-quality code generation with careful planning and self-correction, dense-transformer-based Opus is the choice. If you need the fastest autonomous task completion with the ability to run, test, and iterate independently, Codex's execution-first approach wins.
Which Model Should You Choose - A Developer's Decision Framework
Rather than offering a generic "it depends" answer, here is a concrete decision framework based on five developer personas that map to common real-world scenarios. Identify which persona matches your workflow most closely, and the model recommendation follows.
Persona 1: The Solo Full-Stack Developer building a SaaS product needs a model that can handle diverse tasks from frontend React components to backend API design to database queries, and cost matters because every dollar comes from personal savings or a small seed round. The recommendation here is Gemini 3.1 Pro as the primary model. The reasoning breadth from its MoE architecture handles diverse full-stack tasks well, the 1M context window allows loading entire codebases for context, and the $2/MTok input pricing means the monthly bill stays manageable. Use Opus 4.6 selectively for complex architectural decisions or tricky debugging sessions where the extra quality is worth the premium.
Persona 2: The Backend Infrastructure Engineer working on distributed systems, microservices, and DevOps pipelines needs deep technical accuracy and careful analysis over speed. The recommendation is Claude Opus 4.6. The GVR loop catches subtle concurrency bugs and edge cases that other models miss, the "asks first" behavioral pattern is ideal for infrastructure work where getting it wrong can cause outages, and the Agent Teams feature is transformative for refactoring tasks that touch multiple services simultaneously. The 2.5x cost premium over Gemini pays for itself when a single production bug costs your company thousands in incident response.
Persona 3: The Engineering Manager overseeing a team of 10+ developers wants an AI that can autonomously handle routine tasks like PR reviews, bug fixes, and test generation, freeing the human engineers for creative work. The recommendation is GPT-5.3-Codex through GitHub Copilot or the Codex CLI. The sandboxed execution model means you can assign tasks and receive completed PRs, the 77.3% Terminal-Bench score reflects real autonomous task completion ability, and the product-based pricing is predictable regardless of token consumption. The limitation is that Codex is strongest within the GitHub ecosystem; if your team uses GitLab or Bitbucket, the integration story is weaker.
Persona 4: The AI Researcher or Data Scientist working on novel problems that require scientific reasoning, mathematical proofs, or analyzing large datasets needs the strongest reasoning capabilities regardless of coding-specific features. The recommendation is Gemini 3.1 Pro, decisively. The 77.1% ARC-AGI-2 score (24 points ahead of the nearest competitor) and 94.3% GPQA Diamond performance make it the clear choice for research work. The 1M token GA context window is also uniquely valuable for analyzing large papers, datasets, or experimental results in a single prompt.
Persona 5: The Enterprise Architect evaluating models for organization-wide deployment across diverse teams needs reliability, safety, and flexibility more than any single capability. The recommendation is a multi-model strategy. Use Gemini 3.1 Pro as the default model for general queries and cost efficiency, Opus 4.6 for complex coding and security-sensitive tasks where its Constitutional AI training provides extra safety guarantees, and Codex 5.3 through GitHub Copilot for developer productivity. This approach also provides natural vendor diversification, protecting against service outages, pricing changes, or deprecation announcements from any single provider. An enterprise running exclusively on one model provider carries concentration risk that is increasingly unjustifiable given how easy it has become to integrate multiple models through standardized API patterns. This is the approach we explore in more depth in the next section.
Building a Multi-Model Strategy for Production
The most sophisticated engineering teams in 2026 are not choosing a single model. They are building routing architectures that direct each request to the optimal model based on the task type, required quality level, and cost constraints. This approach captures the best of all three models while managing costs intelligently.
The core pattern is a model router that classifies incoming requests and routes them accordingly. At a high level, the routing logic looks like this: reasoning-heavy queries (research, analysis, scientific questions) route to Gemini 3.1 Pro for its superior ARC-AGI-2 and GPQA Diamond performance at the lowest cost; complex coding tasks (refactoring, architecture, security audits) route to Opus 4.6 for its SWE-Bench-leading quality and GVR self-correction loop; autonomous execution tasks (PR creation, test generation, routine bug fixes) route to Codex 5.3 through its product integrations for its Terminal-Bench-dominating capability.
The practical implementation typically involves three layers. First, a classification layer that determines the task type from the user's request or the application context. Second, a routing layer that maps task types to models based on configurable rules. Third, a fallback layer that handles model unavailability, rate limits, or unexpected errors by routing to an alternative model. Many teams implement this through API aggregation services that abstract away the individual model APIs into a single endpoint, making the routing logic cleaner and the billing consolidated.
Cost optimization in a multi-model setup goes beyond just choosing the cheapest model. Gemini's context caching can reduce costs by up to 75% for repeated prompts with shared prefixes. Anthropic offers 50% discounts on batch API requests for Opus, which is ideal for offline code review pipelines. And Codex's product-based pricing means that its cost is fixed regardless of usage volume, making it the most predictable option for budgeting.
The key metric for evaluating a multi-model strategy is not the performance of any individual model but the aggregate quality-per-dollar across your entire request mix. A well-tuned router can achieve 90%+ of the quality of always using the best model for each task type while reducing costs by 40-60% compared to using a single premium model for everything. The engineering investment in building a router pays back quickly at scale: even a simple rule-based router that sends reasoning queries to Gemini and coding queries to Opus can cut costs by 30% compared to using Opus for everything, while maintaining equivalent or better quality on the reasoning tasks.
Teams that are not ready to build custom routing infrastructure can achieve similar results through API aggregation platforms that handle model selection and fallback logic. The key insight is that model lock-in is the biggest risk in the current landscape. With three strong options from three different providers, maintaining the flexibility to shift traffic between models as capabilities evolve and pricing changes is more valuable than squeezing the last percentage point of performance from any single model.
FAQ - Common Questions Answered
Which model is best for coding in March 2026?
It depends on your coding workflow. For code review and complex refactoring, Claude Opus 4.6 leads with 80.8% on SWE-Bench and its GVR self-correction loop. For autonomous task execution where the model writes, tests, and commits code independently, GPT-5.3-Codex dominates with 77.3% on Terminal-Bench. For general coding with cost sensitivity, Gemini 3.1 Pro at 80.6% SWE-Bench and $2/MTok input offers the best value. All three models are within 1 percentage point on SWE-Bench, so the practical difference comes down to the type of coding assistance you need and your preferred workflow.
Is Opus 4.6 really $5/$25 per million tokens? Many articles say $15/$75.
Yes, $5/$25 is correct. We verified this directly on claude.com/pricing by clicking the API tab on March 2, 2026. The $15/$75 pricing cited by many comparison articles refers to the previous generation Claude Opus 4.1 and 4.0 models. Anthropic significantly reduced Opus pricing with the 4.6 release, making it much more competitive for production use.
Can I call GPT-5.3-Codex via API like GPT-4o or GPT-5.2?
No. As of March 2, 2026, GPT-5.3-Codex does not appear on OpenAI's API pricing page and there is no standalone model endpoint. You access it through the Codex web app (codex.openai.com), Codex CLI, IDE extensions, or GitHub Copilot. If you need a standard API with per-token billing from OpenAI, GPT-5.2 at $1.75/$14 per million tokens is the latest option, but it lacks the autonomous execution capabilities that make Codex special.
Which model has the largest context window?
Gemini 3.1 Pro offers the largest context window at 1 million tokens in General Availability, meaning it is stable and production-ready at that length. Claude Opus 4.6 supports 200K tokens by default with a 1M token beta available on request. GPT-5.3-Codex supports 400K tokens. If processing extremely long documents is central to your use case, Gemini has a clear advantage with its 1M GA context window.
Which model is safest for enterprise use?
Claude Opus 4.6 was designed with Constitutional AI and extensive safety training that make it particularly suited for enterprise environments with strict compliance requirements. Anthropic publishes detailed model cards and has a strong track record on safety evaluations. Gemini 3.1 Pro integrates with Google's existing enterprise security infrastructure through Vertex AI, which means you get the same access controls, audit logging, and compliance certifications that enterprises already trust for their Google Cloud workloads. Codex 5.3 operates in sandboxed environments that limit its ability to cause unintended side effects, and its product-based approach means it cannot access systems beyond what you explicitly grant. All three providers offer enterprise agreements, SOC 2 compliance, and data processing agreements, so the safety decision should be based on your specific compliance framework rather than a blanket recommendation.
How do batch processing discounts affect the cost comparison?
Batch processing significantly changes the cost math for high-volume users. Anthropic offers a 50% discount on Opus 4.6 batch API requests, which brings the effective input price down to $2.50 per million tokens, nearly matching Gemini's standard pricing of $2. Google offers context caching for Gemini that can reduce costs by up to 75% for prompts with shared prefixes, which is extremely valuable for code review pipelines where the system prompt and repository context remain constant across many requests. OpenAI's Codex pricing is already bundled into product subscriptions so there is no additional batch discount, but the effective per-token cost can be very low for heavy users. The key takeaway is that published per-token rates are the starting point, not the final cost. Teams processing more than 100 million tokens per month should negotiate directly with providers and factor in caching, batching, and committed-use discounts.
Will these models be superseded soon? Should I wait?
The pace of model releases in early 2026 has been extraordinary, and it is natural to worry about building on a model that might be outdated in months. However, all three of these models represent significant architectural advances (not just scale increases) over their predecessors, suggesting they will remain competitive for longer than typical model generations. Gemini's MoE architecture, Opus's Agent Teams, and Codex's sandboxed execution are all novel capabilities rather than incremental improvements. The pragmatic approach is to build your applications with model abstraction, so that swapping models requires only a configuration change, and then choose the best available model today rather than waiting for an uncertain future release. The multi-model strategy outlined in this article inherently provides this flexibility.