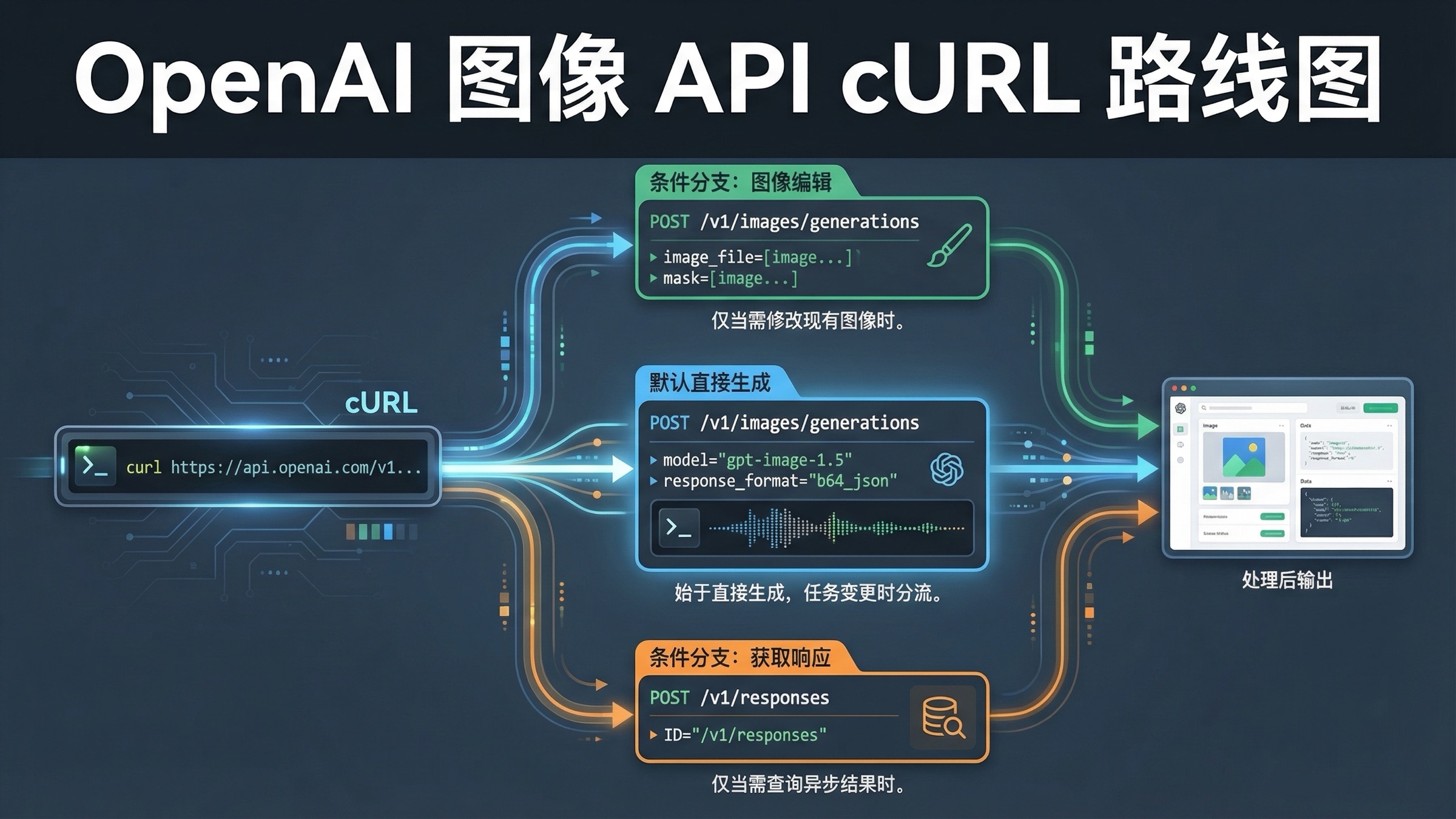
如果你现在就想找一条 OpenAI 图像生成 API cURL 命令,最稳的默认路线仍然是 POST /v1/images/generations。先发一条最简单的直接出图请求,把返回的 JSON 存下来,再把 .data[0].b64_json 解码成文件。这是目前最安全、最容易排错的起点。
真正会改变路线的情况只有两个。第一,你已经有输入图片,想在原图基础上做修改,这时才切到 POST /v1/images/edits 并改成 multipart 表单。第二,图片生成只是更大多模态工作流中的一个工具,这时才切到 POST /v1/responses 并用 image_generation tool。除此之外,大多数复杂化都只是把第一条命令变得更难 debug。
这个关键词之所以一直让人觉得“文档看了还是乱”,不是因为 cURL 本身复杂,而是因为 OpenAI 把答案拆在了不同页面里。主 图像生成指南 负责讲路线和常见参数,Images API 参考 负责讲原始端点和返回结构,Responses image_generation 工具指南 负责讲更大的工具工作流。到了 2026 年 3 月 24 日,官方指南里甚至还保留了一个走 https://api.openai.com/v1/images 的 GPT Image cURL 片段,而 API 参考页写的却是 /images/generations 和 /images/edits。这篇文章就是要把这些碎片重新拼成一条能直接落地的原始 HTTP 工作流。
要点速览
- 第一条最该先跑通的命令是
POST /v1/images/generations,模型默认用gpt-image-1.5。 - GPT 图像模型默认返回的是
b64_json,不是托管图片 URL。 - 只有在你已经有输入图片时,才切到
POST /v1/images/edits。 - 只有当图片生成属于更大工具工作流时,才切到
POST /v1/responses。
先用 POST /v1/images/generations 跑通单张出图
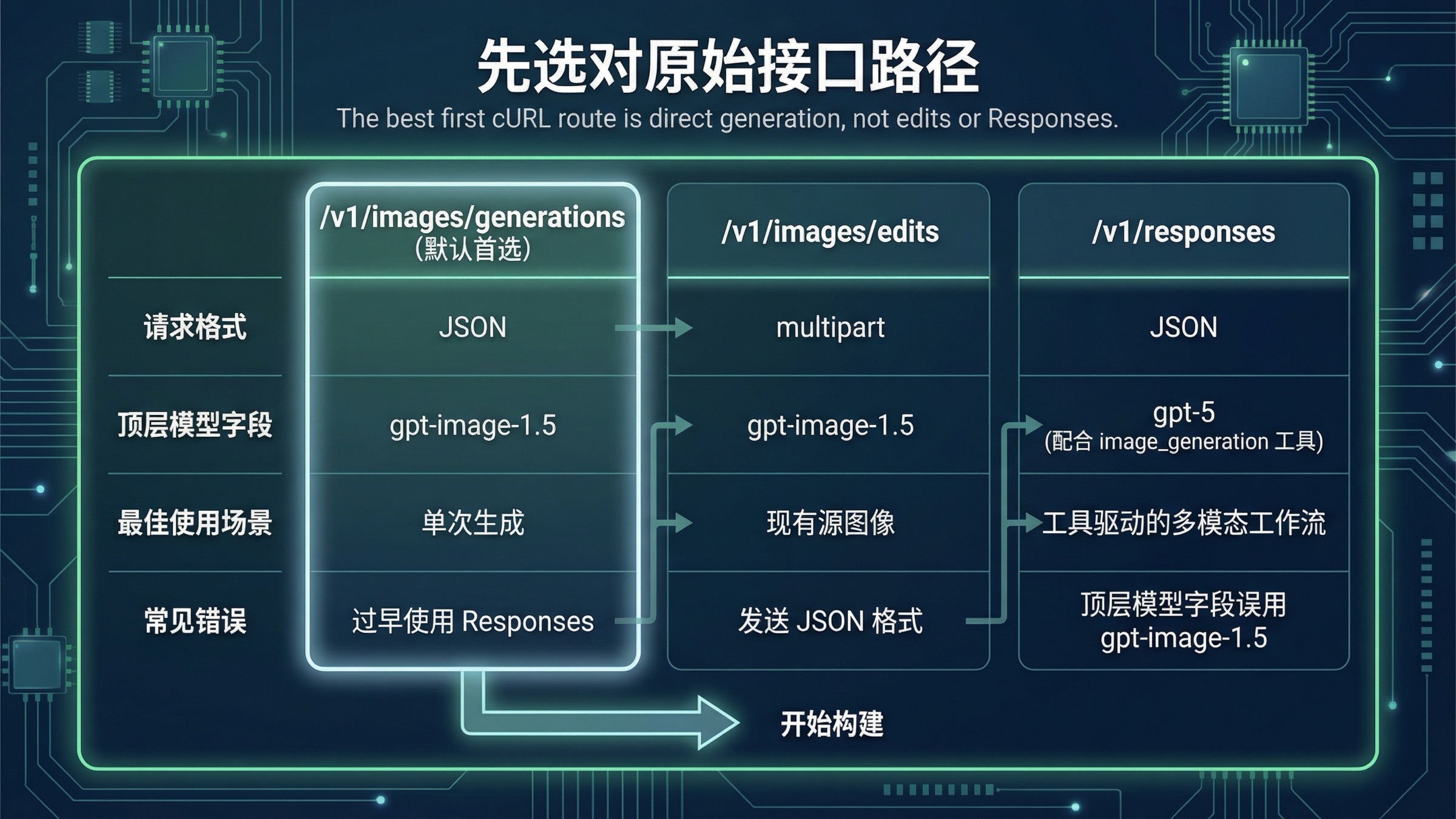
如果你的真实任务是“从终端或后端脚本里发一个 prompt,拿回一张图片”,那当前最该先用的仍然是直接 Images API。官方 Images API 参考 把原始生成端点写成 POST /images/generations,对应的完整 URL 就是 https://api.openai.com/v1/images/generations。
这条路线之所以值得当默认起点,是因为它把第一轮成功闭环压到最小:
- 发送 JSON
- 收到 JSON
- 提取 base64
- 保存成图片文件
它也和当前模型路线一致。官方 All models 页面已经把 GPT Image 1.5 列成当前 state-of-the-art 图像模型,同时列出了 chatgpt-image-latest、gpt-image-1 和 gpt-image-1-mini。所以新写一份 cURL 示例时,默认值应该是 gpt-image-1.5,而不是 GPT Image 1,更不是 DALL-E 时代留下来的旧 mental model。
最安全的第一条命令就是下面这样:
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Create a clean editorial illustration of a robot camera operator in a bright studio", "size": "1024x1024", "quality": "medium" }' > response.json
这里故意保持“无聊”是对的。官方指南明确说过,正方形图片通常最快,而 1024x1024 仍然是默认尺寸。你的第一条请求不应该同时证明透明背景、横版构图、流式 partial image、压缩导出和复杂 editing 都没问题。第一条请求只需要证明 5 件事:
- 账户能访问这个模型
- 端点没写错
- payload 形状没写错
- 响应结构是你预期的
- 你真的能把结果落成文件
多数读者真正需要的路线表,其实可以压缩成下面这一张:
| 场景 | 最适合的原始路径 | model 字段怎么放 | 为什么这是默认路线 |
|---|---|---|---|
| 纯文本 prompt 直接出一张图 | POST /v1/images/generations | 直接用 gpt-image-1.5 | 路径最短、排错最简单 |
| 已经有输入图,要在原图基础上改 | POST /v1/images/edits | 仍然用 gpt-image-1.5 | 仍然属于直接 Images API,只是请求体从 JSON 变成 multipart |
| 图片生成只是更大工作流里的一个工具 | POST /v1/responses | 顶层用 gpt-5 这类主模型 | 只有在 tool orchestration 才真有必要 |
这个表之所以重要,是因为 page one 上很多“example”“tutorial”“endpoint”文章都会把 3 条路线糊成 1 件事来讲。结果就是读者看完以后仍然不知道第一条命令到底该从哪里起步。
还有一个预算层面的补充值得提早说清楚。如果你真正关心的是成本,而不是旗舰默认路线,那么同一份模型目录里还有 gpt-image-1-mini 这条更便宜的 lane。它不会改变端点路径,但会改变你应该先 benchmark 哪个模型。如果你下一步更关心这件事,可以继续看 OpenAI 图像生成 API 模型选择指南。
返回结果到底是什么,以及怎样安全解码
对 cURL 用户来说,最大的坑其实不是 POST 本身,而是“POST 成功以后怎么办”。
官方 Images API 参考 里对 Image 对象的说明非常关键:它列出了 b64_json、revised_prompt 和 url,并额外说明 对 GPT 图像模型来说,默认返回的是 b64_json,而不是给你一个可直接下载的托管 URL。这也是为什么一篇真正有用的 cURL 文章不能只给请求体,不给落盘步骤。
最稳的操作习惯,是先把原始响应存下来:
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Create a clean editorial illustration of a robot camera operator in a bright studio", "size": "1024x1024", "quality": "medium" }' > response.json jq '.data[0] | {has_b64_json: has("b64_json"), revised_prompt, url}' response.json
这一步看起来多余,其实很值。它能先证明响应结构没问题,再决定你要不要把数据流直接导去 base64。很多“命令能返回 200 但文件打不开”的问题,都是因为请求成功了、解码却写错了。
如果你在 Linux 或者支持 GNU base64 的环境里,最短解码命令通常是:
bashjq -r '.data[0].b64_json' response.json | base64 --decode > openai-image.png
如果你在 macOS 上,通常要换成 -D:
bashjq -r '.data[0].b64_json' response.json | base64 -D > openai-image.png
如果你想要一条跨系统更稳的命令,最简单的方法反而是把 decode 这一步交给 Python:
bashjq -r '.data[0].b64_json' response.json \ | python -c 'import sys, base64; sys.stdout.buffer.write(base64.b64decode(sys.stdin.read()))' \ > openai-image.png
这正是这类关键词最容易被 page one 忽略的价值点。很多 cURL 文章会把请求直接 pipe 到 jq,然后默认 base64 --decode 在所有系统上都能跑通,最后让读者在“HTTP 200 但是图片文件不可用”这一层自己踩坑。
还有一个值得提前拆开的误区。很多旧教程默认用 .data[0].url 这个心智模型去理解返回值,这是 DALL-E 时代留下来的残影。对当前 GPT 图像模型,默认 happy path 已经是 base64 payload,所以如果你的脚本还在等 .data[0].url,你 debug 的根本就不是现在这一代接口。
官方文档里另一个容易绕晕人的点,也发生在这里:主指南里当前还保留了一条走 /v1/images 的 GPT Image cURL 片段,而参考页把原始契约写成了 /images/generations。对于写 cURL 的读者来说,最稳的建议仍然应该是:以参考页的端点命名作为原始契约,再把指南当成路线解释和参数说明。
如果你还想看一篇更泛化、同时覆盖 JavaScript、Python 和 cURL 的页面,可以继续读 OpenAI 图像生成 API 示例。但这个页面故意更窄,因为它要解决的是“原始 HTTP 怎么稳定落地”,不是“再给你一页看起来很全的 SDK 教程”。
已有输入图时再切到 multipart POST /v1/images/edits
如果你已经有产品图、品牌素材或参考图,就不要继续把 generation 路线硬解释成 editing 教程。正确做法不是换平台,而是继续留在直接 Images API,只是切到 edit 分支。
官方 Images API 参考 把编辑端点写成 POST /images/edits,主 图像生成指南 里也给了当前可用的 multipart cURL 示例,用 repeated image[] 字段上传输入图。
原始形状大致就是下面这样:
bashcurl -s -D >(grep -i x-request-id >&2) \ -o >(jq -r '.data[0].b64_json' | base64 --decode > edited-image.png) \ -X POST "https://api.openai.com/v1/images/edits" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "image[]=@product-shot.png" \ -F "image[]=@logo.png" \ -F 'prompt=Place the logo on the product box as if it were printed on the packaging.'
这里最值得读者立刻记住的一条规则是:生成请求走 JSON,编辑请求走 multipart 表单。很多 400 级别错误都不是参数本身写错,而是你还在沿用 Content-Type: application/json 这套思路去发送应该用 -F 的编辑请求。
第二个分支点是 fidelity。官方指南明确写了,如果你用的是 gpt-image-1.5,前 5 张输入图可以通过 input_fidelity=high 获得更强的保真度。这在你真的关心 logo、构图、人物细节的时候很有价值,而不是一个应该默认加上的“高级参数”。
放到原始 cURL 里,大致会变成这样:
bashcurl -s \ -X POST "https://api.openai.com/v1/images/edits" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "image[]=@woman.jpg" \ -F "image[]=@logo.png" \ -F "input_fidelity=high" \ -F 'prompt=Add the logo to the woman'\''s jacket as if stitched into the fabric.' \ > edit-response.json
这里也最容易暴露一个 page-one 常见误导:很多“更高级的图像 workflow”文章会顺手把读者推去 Responses,仿佛 editing 一复杂就该换 API surface。这个结论是错的。Editing 仍然是直接 Images API 的一等场景。只有当整个工作流开始依赖更大的 tool orchestration 时,Routes 才需要改变。
如果你真正需要的是更完整的 edit 细节,而不是单纯弄清楚 cURL 路由,那下一篇更合适的是 OpenAI 图像编辑 API 指南。
只有当图片生成属于更大流程时才切到 /v1/responses
官方 Responses image_generation 工具指南 解决的是另外一个问题:当图片生成只是整个模型交互中的一个 tool 时,应该怎么做。
这里最重要的规则不是“Responses 更新”,而是字段层级变了。
该指南写得很清楚:GPT 图像模型不能作为 Responses API 顶层 model 字段的值。当你走 /v1/responses 时,顶层 model 应该是 gpt-4.1 或 gpt-5 这类主模型,而 image_generation tool 在背后调用 GPT Image 模型。
原始 cURL 形状如下:
bashcurl https://api.openai.com/v1/responses \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-5", "input": "Generate a transparent sticker-style icon of a paper airplane for a travel app", "tools": [ { "type": "image_generation", "background": "transparent", "quality": "high" } ] }' > responses-output.json jq -r '.output[] | select(.type=="image_generation_call") | .result' responses-output.json \ | python -c 'import sys, base64; sys.stdout.buffer.write(base64.b64decode(sys.stdin.read()))' \ > plane.png
这条路线只在下面这些场景里更合适:
- 同一个请求可能同时产出文本和图片
- 模型需要决定什么时候调用图片生成工具
- 图片生成只是更大 assistant / agent workflow 中的一个动作
而它在下面这些场景里通常只是徒增复杂度:
- 你只是想验证一条 prompt-to-image 命令
- 你还没搞清楚账户是否有权限访问图片模型
- 你还在排查端点、模型名或落盘问题
最实用的规则其实就一句话:不要因为 Responses 看起来更先进,就拿它当第一条 cURL 示例。 只有当 orchestration 本身才是真正的工作内容时,它才是更好的抽象层。
如果你后面还想看一篇更完整的路线教程,可以继续读 OpenAI 图像 API 教程。但对这个关键词来说,保持 Responses 分支“只在确实需要时才出现”,反而才是最有帮助的写法。
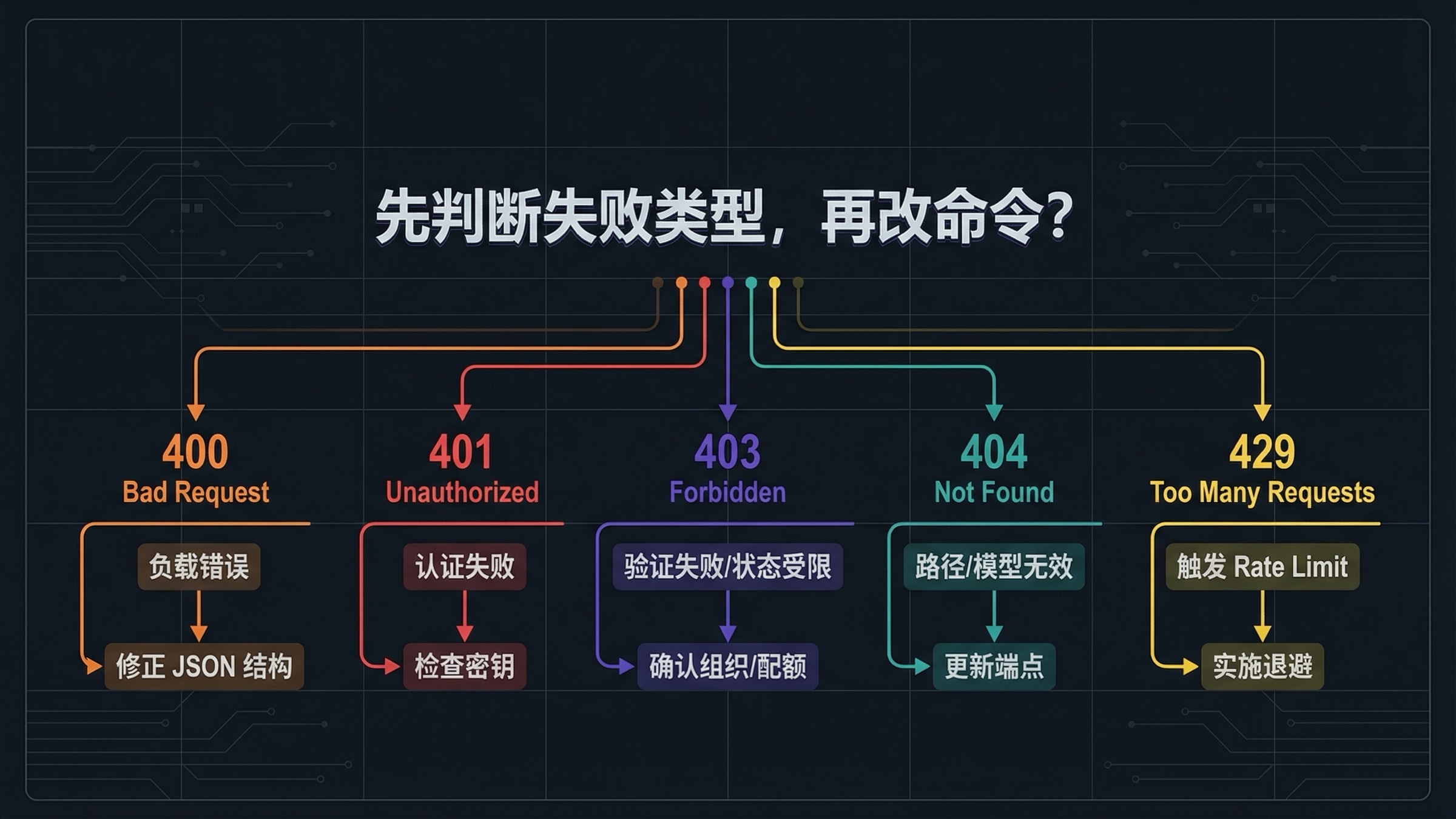
故障排查:哪些 cURL 错误是 payload 问题,哪些是 access 问题
这一节是大多数 page-one 结果最容易写弱的地方。
当一条 cURL 示例失败时,你真正该先问的问题不是“我还要改哪个参数”,而是“这属于哪一类失败?” 因为 payload 写错、key 写错、组织验证没完成、模型假设过时、账户速率限制触发,这几类问题的修法完全不一样。
先用下面这张表判断:
| 你看到的现象 | 通常意味着什么 | 最该先检查什么 |
|---|---|---|
400 Bad Request | JSON 结构不对、Content-Type 不对,或者你把 edit 请求当成 JSON 发了 | 先确认端点和请求体形状,到底该用 -d 还是 -F |
401 Unauthorized | key 无效、缺失,或者请求头没带对 | 先检查 OPENAI_API_KEY、shell 展开、项目级 key 是否正确 |
403 且带 verification / image access 提示 | 这更像账户状态问题,不是 payload 问题 | 先检查组织验证、当前 org、传播延迟和新 key |
404 或 model not found | 路径写错、模型名过时,或你复制了 rollout 早期示例 | 先重查端点路径、模型名和官方当前文档 |
429 或限流提示 | 这是 tier 或速率限制,不是命令格式问题 | 先检查速率上限、账户 tier,以及是否该降请求频率 |
403 这条尤其容易误导人,因为它经常看起来像是代码问题,但实际上是账户状态问题。官方 API Organization Verification 说明里写得很清楚:组织验证可以解锁 API 里的图像生成功能;如果验证后仍然看到 not verified 之类的提示,应当等待最多 30 分钟、生成新的 API key、刷新会话,并确认当前切到的就是正确组织。
另一个重要的 access 线索来自官方 API Model Availability by Usage Tier and Verification Status 页面。它写明 gpt-image-1 和 gpt-image-1-mini 对 tier 1 到 tier 5 开放,但部分访问仍然受组织验证影响。所以当你遇到 403 或 429 时,不要先把所有注意力都放在 JSON 上。
404 分支则是另一种时间错位问题。OpenAI 自己的 GPT-Image-1.5 rollout 讨论串 记录过 2025 年 12 月 16 日前后 rollout 时的 model does not exist 情况。这解释了为什么现在搜索里仍然会出现一些旧答案,但它不应该成为你今天默认判断 404 的第一解释。今天更合理的顺序仍然是:先查路径,再查模型名,再查你是不是复制了旧教程。
还有一种经常被忽略的失败根本不是 HTTP 错误:请求返回 200,但最终生成的图片文件为空或打不开。 这类问题经常不是 API 本身,而是解码步骤写错了。最好的办法仍然是:先把 response.json 保留下来,再检查 .data[0].b64_json 是否真的存在。
还有一个很实用的操作习惯,官方 edit 示例里其实已经暗示了:能打印 request ID 时就尽量打印出来。对排查 support 问题或者组织状态问题很有帮助:
bashcurl -s -D >(grep -i x-request-id >&2) \ -o response.json \ https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Create a clean editorial illustration of a robot camera operator in a bright studio", "size": "1024x1024", "quality": "medium" }'
这条命令本身不会修好你的错误,但它会让下一步排查更短,不至于只剩下一句“我这条 cURL 就是不 work”。
如果你已经确定问题更像组织验证,而不是 payload 形状,那更该继续读的是 OpenAI 图像生成 API 验证问题排查。
第一条请求跑通之后再去改的参数
当前官方指南和参考页里,最值得在“第一条请求跑通之后”再去动的参数主要有这些:
size:1024x1024、1024x1536、1536x1024或autoquality:low、medium、high或autobackground:transparent、opaque或autooutput_format:png、webp或jpeg
这里真正重要的不是参数本身,而是顺序。大多数 raw HTTP 工作流一开始不该先调 prompt,而应该先把“路由通、账户通、解码通、文件能落地”这四件事做实。否则你很难知道自己到底是在 debug 权限问题、请求体问题,还是图片质量问题。
对大多数单张直接生成请求来说,安全默认值仍然是:
size先保持1024x1024quality先保持medium- 如果不是明确需要透明背景,就先不要引入
background - 文件格式的优化等第一条请求跑通后再做
如果你真的需要透明背景,再把请求写得更明确:
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Draw a transparent sticker-style icon of a paper airplane for a travel app", "size": "1024x1024", "quality": "high", "background": "transparent", "output_format": "png" }' > transparent-response.json
如果你更在意文件更小、传输更快,那么等路线稳定后,再去试 jpeg 或 webp。如果你关心 streaming 和 partial_images,官方指南里也有这条能力,但它显然不应该成为这个关键词的第一屏答案。那是“优化第二步”,不是“跑通第一步”。
这也是这篇文章想帮读者省下时间的地方。很多人会先去调 prompt,其实顺序经常反了。更稳的顺序应该是:
- 先证明端点能通
- 再证明响应能解码
- 再证明你选的是正确路线
- 最后才去调
quality、size、background和 prompt
如果你下一步更关心的是成本,而不是原始 HTTP 命令本身,那可以继续看 OpenAI 图像生成 API 定价。
最终建议
如果你只想记住一句最短规则,那就是:先用 POST /v1/images/generations,先解码 b64_json,只有在你已经有输入图时才切到 POST /v1/images/edits,只有在图片生成属于更大工具工作流时才切到 POST /v1/responses。
这条规则之所以比当前大多数搜索结果更有用,不是因为它更“全”,而是因为它把真正会决定成败的那几步放在了一起:路线、模型、返回结构、解码、排错顺序。对这个关键词来说,这比再给你一页宽泛的 SDK 教程更能直接帮你把东西跑起来。