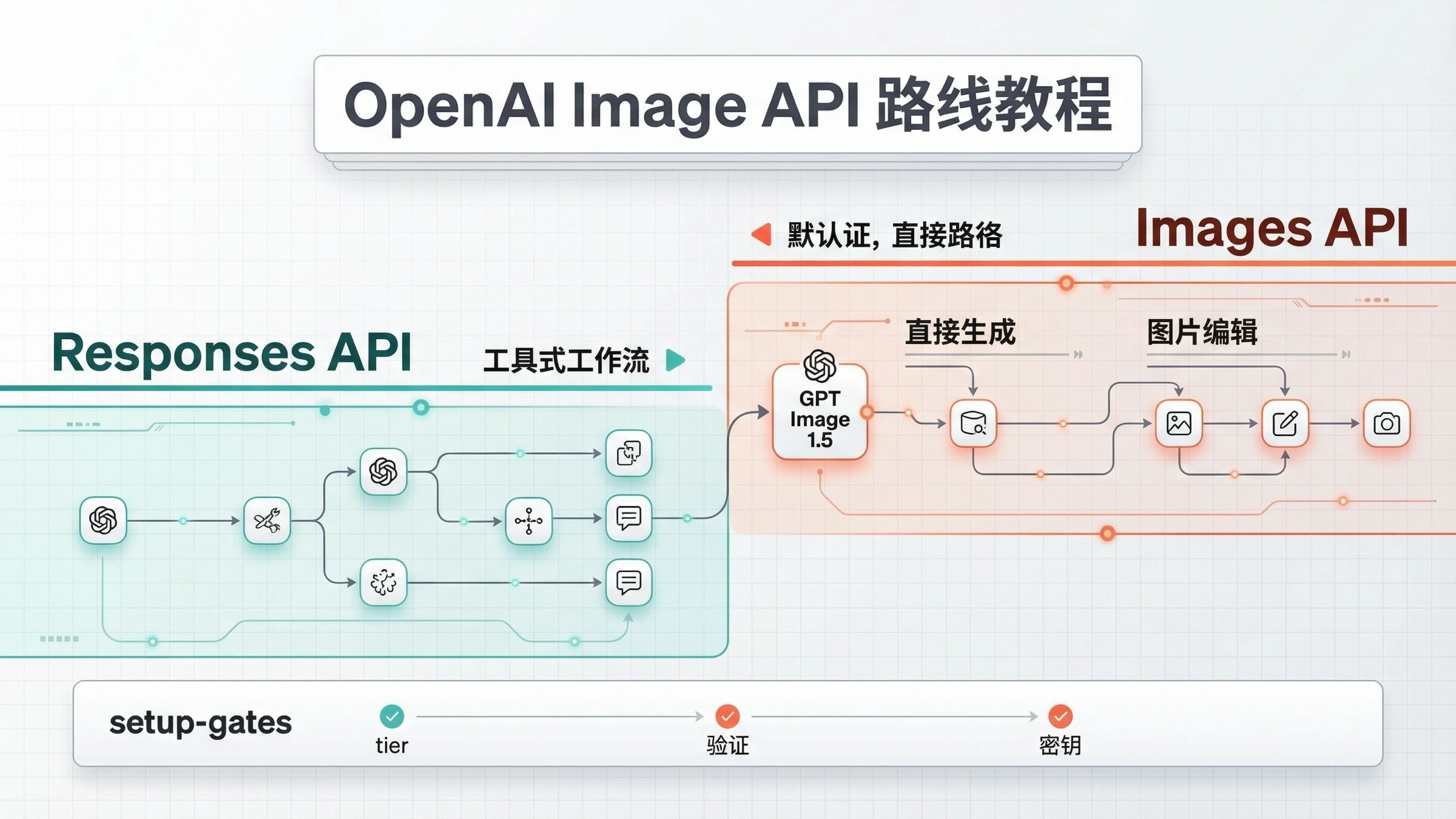
如果你现在要找一份 OpenAI 图像生成 API 示例,最稳的起点仍然是 Images API 加 gpt-image-1.5。截至 2026 年 3 月 23 日,这依旧是最适合直接出图请求的默认路线。只有当图片生成只是更大多模态工作流中的一个工具时,才应该切到 Responses API。
这个关键词之所以总让人觉得“文档看了还是乱”,不是因为 SDK 很难,而是因为答案被拆在了不同页面里。主 图像生成指南 讲直接生成和编辑;image_generation 工具指南 讲的是 responses.create() 里的工具式调用;Images API 参考 又负责说明原始端点。如果你只看其中一页,很容易把一段看起来没问题的代码放错地方。
最安全的顺序其实很简单:先跑通一条直接生成请求,把返回的 base64 图片保存到本地;确认这一步没问题之后,再去加编辑、透明背景、压缩或流式返回。如果你的产品后来确实需要会话、多工具编排或多模态推理,再切到 Responses API。
最快能跑通的 OpenAI 图像生成 API 示例
对于这个关键词,最好的起点就是直接 Images API。当前原始端点是 POST /v1/images/generations,当前最适合作为新示例默认模型的是 gpt-image-1.5。如果你只是想发一个请求生成一张图,不需要先把问题升级成工具编排或助手工作流。
最容易记住的心智模型是:
- 发送 prompt
- 收到 base64 图片数据
- 解码
- 保存到本地
JavaScript 最短可运行示例:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.generate({ model: "gpt-image-1.5", prompt: "Create a clean editorial illustration of a robot camera operator in a bright studio", size: "1024x1024", quality: "medium", }); const imageBase64 = result.data[0].b64_json; const imageBuffer = Buffer.from(imageBase64, "base64"); fs.writeFileSync("openai-image-example.png", imageBuffer);
Python 版本同样直接:
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.generate( model="gpt-image-1.5", prompt="Create a clean editorial illustration of a robot camera operator in a bright studio", size="1024x1024", quality="medium", ) image_base64 = result.data[0].b64_json image_bytes = base64.b64decode(image_base64) with open("openai-image-example.png", "wb") as f: f.write(image_bytes)
cURL 版本适合做后端排错或直接确认请求形状:
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Create a clean editorial illustration of a robot camera operator in a bright studio", "size": "1024x1024", "quality": "medium" }' \ | jq -r '.data[0].b64_json' \ | base64 --decode > openai-image-example.png
如果你的环境不支持 base64 --decode,请换成系统对应的参数。比如 macOS 上通常是 base64 -D。
这就是当前最值得放在第一屏的示例,因为它把直接出图这件事本身讲清楚了,而不是先把读者带去更复杂的工具编排。另一个多数旧教程会漏掉的细节是:GPT 图像模型默认返回的是 base64 图片数据,不是托管图片 URL。所以第一条好示例不应该只展示请求,还要展示如何把结果解码并真正落盘。
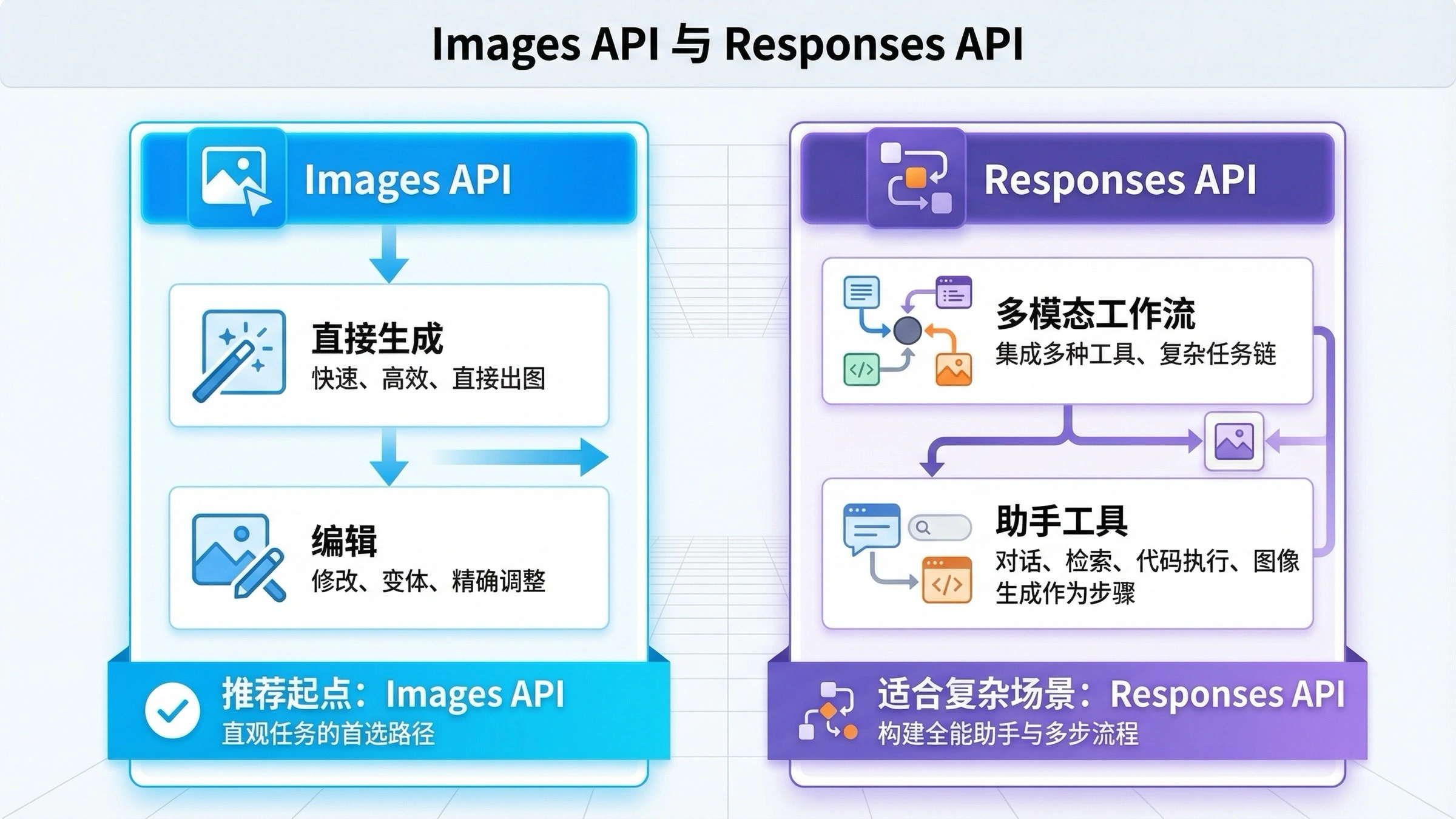
Images API 和 Responses image_generation 工具怎么选
如果你只是想生成或编辑一张图片,直接 Images API 更容易理解;如果你在做的是一个会同时处理文字、工具、图片甚至多轮上下文的系统,那 Responses 路线才更合理。
| 场景 | 更合适的默认路线 | 原因 |
|---|---|---|
| 只想发一个请求生成一张图并保存 | Images API | 路径最短,示例最清楚 |
| 需要编辑一张或多张输入图片 | Images API | 直接 edit 流程和 input_fidelity 都在这里 |
| 需要一个简单的后端出图端点 | Images API | 请求结构更直接,也更容易排错 |
| 图片生成只是更大助手工作流中的一个工具 | Responses API | 图片输出更适合作为工具挂在更大的会话流里 |
| 同一个请求里还要做其他推理步骤 | Responses API | 这种时候工具式调用更自然 |
这个关键词最该先讲清楚的一句话是:不要因为 Responses 看起来“更新”就默认从它开始。 只有当你的产品真的需要多模态编排时,它才是更好的抽象层。否则,你只是把第一条示例做复杂了。
还有一个特别常见的坑:在 Responses 路线里,model 字段应该放 gpt-5 这种主模型,而不是直接放 gpt-image-1.5。官方 工具指南 的意思很明确:image_generation 工具会在内部调用 GPT Image 模型,而顶层 model 仍然是负责推理和决定何时调用工具的模型。
这也决定了排错方式不一样。直接 Images API 出错时,你通常先查的是模型可用性、请求结构和文件解码;Responses 路线出错时,还要多看工具调用是否触发、输出如何解析,以及顶层模型和图像工具之间的关系。这也是为什么本文把简单示例固定在直接 Images API 上。
如果你想看更完整的路线拆解,而不是只想先跑通示例,可以继续读中文版 OpenAI Image API 教程。
写代码前先过一遍访问前提
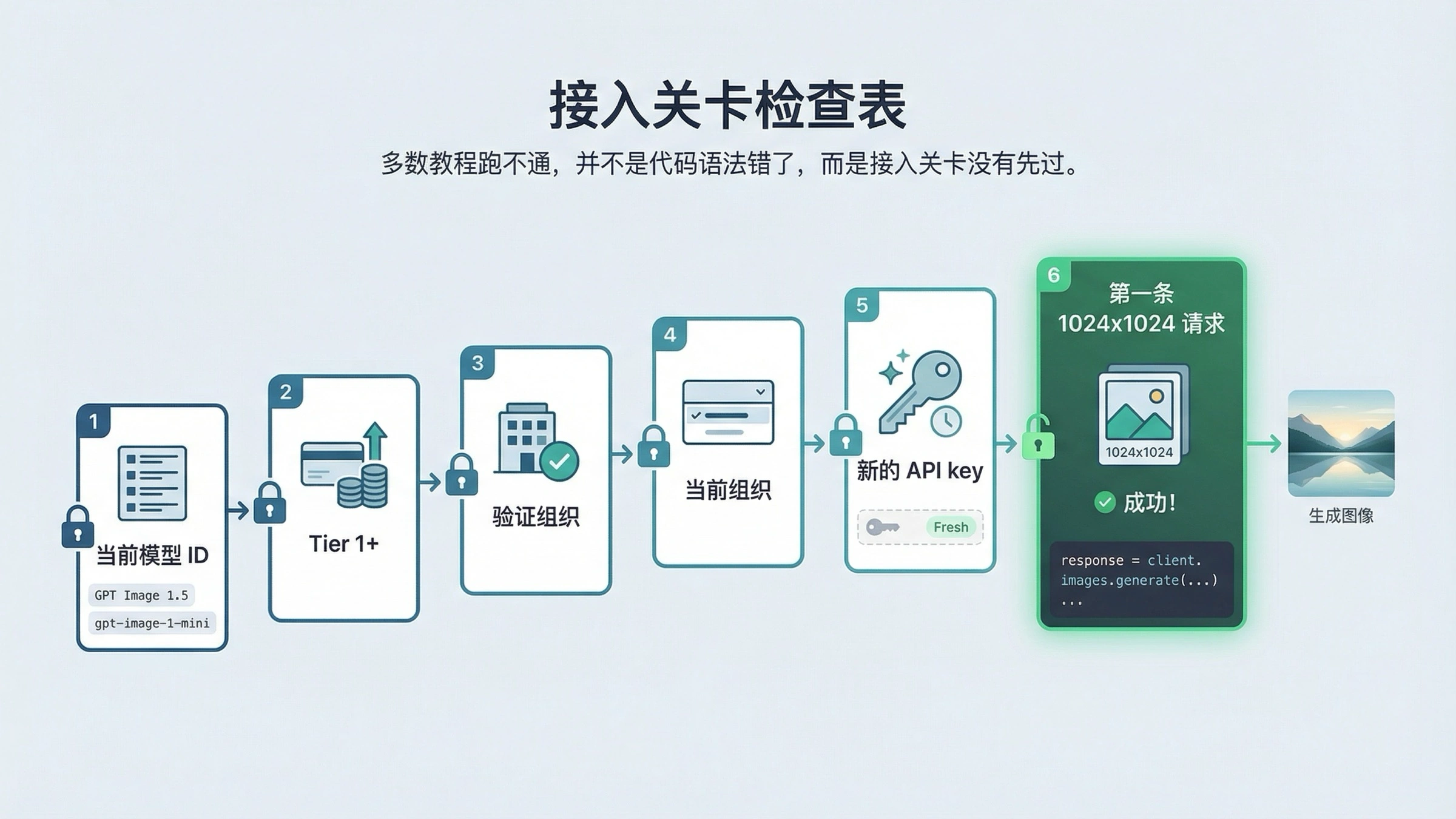
很多“这个示例坏了”的问题,真实原因并不是代码,而是访问条件。截至 2026 年 3 月 23 日,OpenAI 的 GPT Image 1.5 模型页明确写着 Free not supported,而且 Tier 1 从 100,000 TPM 和 5 IPM 起步。这意味着你的请求完全可能在代码还没发挥作用之前就被拦下。
另一个容易混淆的点是帮助中心的 API model availability by usage tier and verification status 页面写的是 gpt-image-1 和 gpt-image-1-mini 对 Tier 1 到 Tier 5 的 API 用户开放,部分访问仍受组织验证影响。所以,如果你复制了一段看起来没毛病的示例却依旧报访问错误,先看账户侧,而不是先重写代码。
最干净的检查顺序是:
- 先装当前 SDK。
- 确认环境变量里有
OPENAI_API_KEY。 - 确认账户在支持的 usage tier 上。
- 确认你当前切的是正确组织。
- 确认你用的是当前模型名。
- 最后才去调 prompt 或参数。
Node.js:
bashnpm install openai
Python:
bashpip install openai
如果你刚完成组织验证却还在看到 not verified 之类的错误,OpenAI 的 组织验证说明 建议是:最多等待 30 分钟,重新生成 API key,刷新会话,并确认当前组织正确。这不是边角料,而是很多读者真正会遇到的第一条故障分支。
真正重要的是排错顺序。很多人会先换 prompt、先换 SDK 版本、先怀疑接口是不是又变了,但在这个关键词下,最稳的运营式规则其实是:先查访问条件,再查请求结构,最后才查 prompt 质量。
不换 API,也能继续做编辑和输出控制
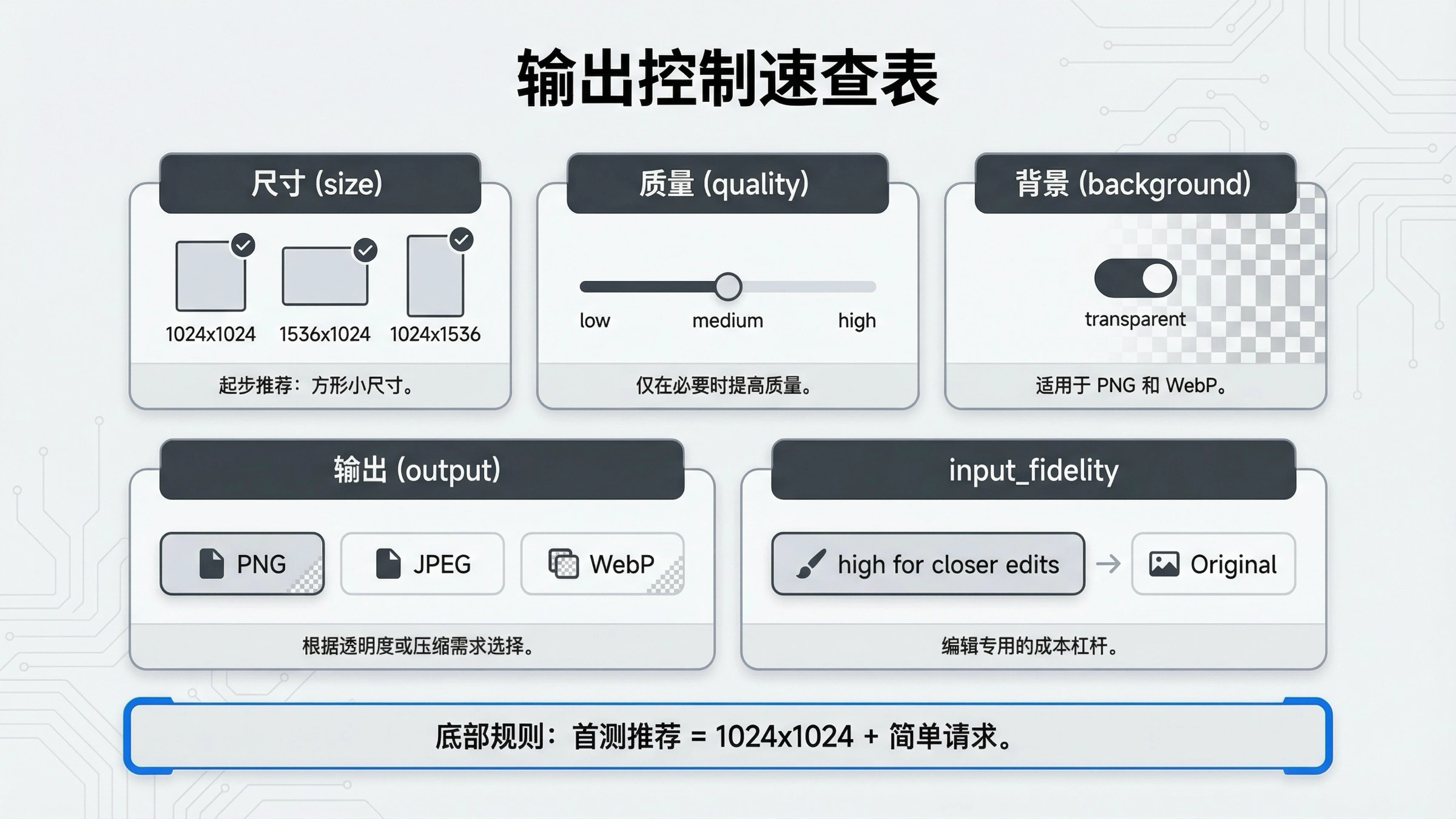
当基础示例跑通以后,最稳的做法不是立刻切到 Responses,而是继续留在同一条直接路线里,只加你眼下真的需要的功能。图像编辑、透明背景、输出格式切换,本来就都属于直接 Images API 的能力范围。
当前编辑示例可以这样写:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1.5", image: [ fs.createReadStream("product-photo.png"), fs.createReadStream("logo.png"), ], prompt: "Add the logo to the product box as if it were printed on the packaging.", input_fidelity: "high", }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync("product-with-logo.png", Buffer.from(imageBase64, "base64"));
这里的 input_fidelity: "high" 值得特别注意。官方指南的意思是:如果你很在意输入图片里的细节保留,这个参数会更稳,但它也会增加图片输入 token 成本。所以它应该在“源图细节很关键”时再开,而不是在第一条示例里盲目默认。
同一条直接 API 还支持这些输出控制:
size:第一条请求尽量先用1024x1024quality:首轮验证时medium很稳background:GPT 图像模型支持透明背景,适用于png和webpoutput_format:要更小文件或更快返回时可以用jpeg或webpoutput_compression:当你明确想控制 JPEG 或 WebP 压缩等级时使用
最实用的规则是:先让第一条请求足够“无聊”。方图、中等质量、单张输出,最有利于你确认访问、请求结构、解码和文件保存都没问题。等这一步稳定,再去加透明背景、高质量或多图编辑。
如果你还想先搞清楚成本,再决定是不是要把这条路线放进生产,可以继续看中文版 OpenAI 图像生成 API 定价指南。
什么时候才该切到 Responses
如果你的产品已经从“生成一张图”走到了“一个助手要做推理、调工具、收多模态输入、然后有时返回图片”,那 Responses 才是更合适的抽象层。
当前 JavaScript 示例可以这样写:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const response = await client.responses.create({ model: "gpt-5", input: "Generate a transparent sticker-style icon of a paper airplane for a travel app", tools: [ { type: "image_generation", background: "transparent", quality: "high", }, ], }); const imageBase64 = response.output .filter((item) => item.type === "image_generation_call") .map((item) => item.result)[0]; fs.writeFileSync("paper-airplane.png", Buffer.from(imageBase64, "base64"));
这段代码是正确的,但它解决的是另一类问题。它更适合“图片生成只是更大交互流程中的一个环节”,而不是“我只是想先跑通一个直接出图示例”。所以它不是不能用,而是不该作为这个关键词的默认第一步。
适合用 Responses 的情况:
- 同一个请求可能既返回文本也返回图片
- 图片生成只是更大助手工作流中的一个工具
- 你希望模型在会话里自己决定何时生成、何时继续
- 图像步骤要和其他工具并排存在,而不是单独成为一个端点
适合坚持用直接 Images API 的情况:
- 你要的是最短上手路径
- 你的后端接口只做一件图像相关的事
- 你正在排查生成或编辑链路
- 你想给团队一个最干净的最小示例
故障排查:多数旧教程会漏掉的分支
第一个错误,是沿用旧模型名。这个关键词下,搜索结果里仍然会混入 GPT Image 1 甚至 DALL-E 时代的旧内容。如果你今天写一篇新示例,默认起点应该是 gpt-image-1.5,而不是把旧命名继续放在第一屏。
第二个错误,是把 gpt-image-1.5 直接填进 Responses API 的 model 字段。工具指南说得很清楚:GPT Image 模型是在 image_generation 工具后面工作的,顶层 model 还是 gpt-5 这样的主模型。如果你忽略这个分层,代码会看起来“差一点就对了”,但结构上其实已经错位。
第三个错误,是把访问错误误判成代码错误。如果你返回的是 availability、permission 或 verification 相关错误,先去查 tier 和组织验证,不要一上来就改请求体。如果你要更完整地处理这条支线,可以直接看中文版 OpenAI 图像生成 API 验证指南。
第四个错误,是还在用 DALL-E 时代的输出预期。对于 GPT 图像模型,直接 Images API 默认返回的是 base64 图片数据,所以最短好示例一定要包含解码和保存,而不是只展示请求体。
第五个错误,是第一条请求就想解决所有需求。很多人还没跑通最小示例,就开始加纵向尺寸、透明背景、高质量、多图编辑,甚至助手编排。这是错误顺序。先证明直接路径能工作,再加下一个真正需要的功能。
还有一个实用分支是 SDK 和 cURL 的对照排错。如果 SDK 示例和 cURL 示例都以同样方式失败,问题通常不是你的应用代码,而是访问权限、模型命名或组织上下文。如果 cURL 可以成功而应用代码失败,那更像是环境变量、请求解析或文件写入的问题。
还有一个很值得保留的动作,是把第一条成功请求的 prompt、模型名、尺寸、质量参数和落盘后的图片一起保存成团队基线。后面无论你要加透明背景、改成长图,还是切到编辑接口,都先拿这条基线回归一次,通常会比盲目改参数更快定位问题。
FAQ
新示例应该用 gpt-image-1.5 还是 gpt-image-1?
如果你现在要写一份新的直接示例,就用 gpt-image-1.5。官方 GPT Image 1.5 模型页把它标成了最新图像生成模型。gpt-image-1 仍然有迁移参考价值,但不应该是新教程的默认主角。
为什么直接 Images API 返回的是 base64,不是图片 URL?
因为 GPT 图像模型默认返回的就是 base64 图片数据。这也是为什么好示例不能只展示请求,还要展示如何解码并落盘。很多旧教程的问题,就出在它们默认读者还活在 DALL-E 风格的 URL 输出预期里。
透明 PNG 或图像编辑一定要切到 Responses 吗?
不需要。直接 Images API 已经支持图像编辑、input_fidelity、透明背景,以及 output_format、output_compression 这类输出控制。只有当你真的需要更大的工具编排时,才应该改走 Responses。
最后建议
对于 openai image generation api example 这个关键词,最诚实的当前答案其实比很多页面写得更窄:先用 Images API,默认模型用 gpt-image-1.5,第一条请求保持小而简单,并把返回的 base64 图片真正保存到本地。这就是 2026 年 3 月 23 日 最快能跑通的默认路线。
只有当你的产品真的需要“图片只是更大工作流中的一个工具”时,才切到 Responses image_generation 路线。只要你把这个边界守住,今天这组文档里大多数容易踩的坑,其实都会在第一步之前就消失。