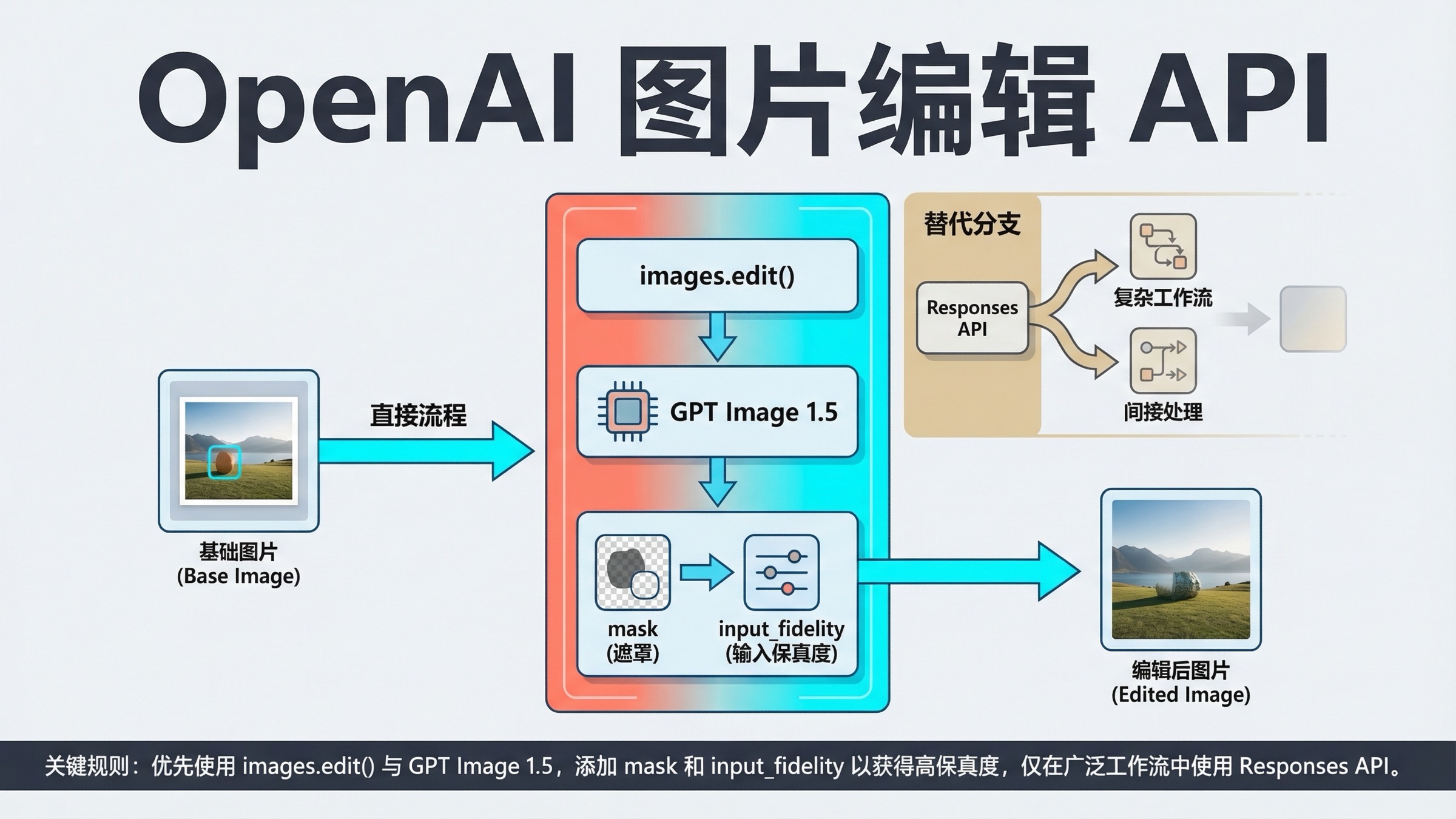
如果你今天要用 OpenAI API 编辑图片,截至 2026 年 3 月 23 日,最稳的默认路线仍然是直接走 Images API 和 gpt-image-1.5。对大多数“先编辑、再保存结果”的场景来说,就是在 SDK 里调用 client.images.edit(),或者直接打 POST /v1/images/edits。只有当图片编辑只是更大对话、助手或 agent 工作流里的一个步骤时,才应该切到 Responses API。
这一步之所以重要,是因为 OpenAI 目前关于图片编辑的说明仍然分散在多页文档里。主 image generation guide 已经在直接编辑示例里使用 gpt-image-1.5;当前 GPT Image 1.5 模型页 也把它标成最新的 image generation model;但更广的 Images and vision guide 里仍然保留着“最新模型是 gpt-image-1”的旧表述。你只看其中一页,很容易抄到“代码还能跑,但思路已经旧了”的路线。
第二个坑比第一个更贵。很多团队一看到“image editing API”,脑中自动联想到 Photoshop 式的局部补丁。但 OpenAI 当前文档写得更谨慎。它明确要求你描述最终整张图长什么样,而不是只写被擦掉的那一块。社区讨论也反复说明了这一点:不少人仍然会遇到 masked edit 更像“语义级重写”,而不是严格只改掩码内像素的情况。本文就是帮你先把这个预期摆正,免得在错误的心智模型上继续调 prompt。
要点速览
- 直接做 OpenAI 图片编辑,默认先用
images.edit()+gpt-image-1.5。 - mask 的作用是帮助模型知道“重点改哪里”,但不要把它理解成严格的局部像素补丁承诺。
- 当你更关心人脸、logo、构图或品牌视觉保留时,再加
input_fidelity="high"。 - 只有当图片编辑属于更大的多模态或 agent 工作流时,才改走 Responses。
先记住当前默认路线:直接编辑优先
对一个常规图片编辑流程,最短也最安全的心智模型是:
- 传入一张或多张输入图
- 写清楚你想要的最终结果
- 只在真的需要时补 preservation 控制
- 解码返回的 base64 图片并保存
当前最直接的 JavaScript 写法是:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1.5", image: [fs.createReadStream("room.jpg")], prompt: "Replace the empty wall art with a framed abstract poster. Preserve the room layout, lighting, shadows, and all furniture. Do not change the camera angle.", input_fidelity: "high", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; const imageBuffer = Buffer.from(imageBase64, "base64"); fs.writeFileSync("room-edited.jpg", imageBuffer);
Python 版本同样直接:
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.edit( model="gpt-image-1.5", image=[open("room.jpg", "rb")], prompt=( "Replace the empty wall art with a framed abstract poster. " "Preserve the room layout, lighting, shadows, and all furniture. " "Do not change the camera angle." ), input_fidelity="high", size="1024x1024", quality="medium", output_format="jpeg", output_compression=80, ) image_base64 = result.data[0].b64_json image_bytes = base64.b64decode(image_base64) with open("room-edited.jpg", "wb") as f: f.write(image_bytes)
如果你需要 raw HTTP 形态,最关键的点是:image edit 用的是 multipart form data,不是 JSON。
bashcurl https://api.openai.com/v1/images/edits \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "image[]=@room.jpg" \ -F 'prompt=Replace the empty wall art with a framed abstract poster. Preserve the room layout, lighting, shadows, and all furniture. Do not change the camera angle.' \ -F "input_fidelity=high" \ -F "size=1024x1024" \ -F "quality=medium"
这条路线最好用,因为它把事情讲得很清楚:你选一个当前可用的编辑模型,传输入图,描述最终图,拿回 base64 数据。你没有把“是否编辑”这一步交给更泛化的 reasoning workflow,也不需要一上来就管理会话状态。
如果你真正想找的是更广义的图片 API 路线,而不只是编辑,可以接着看中文的 OpenAI Image API 教程。这篇文章故意把范围收窄,只回答“图片编辑 API 现在怎么走”。
Images API 和 Responses:什么时候该切换
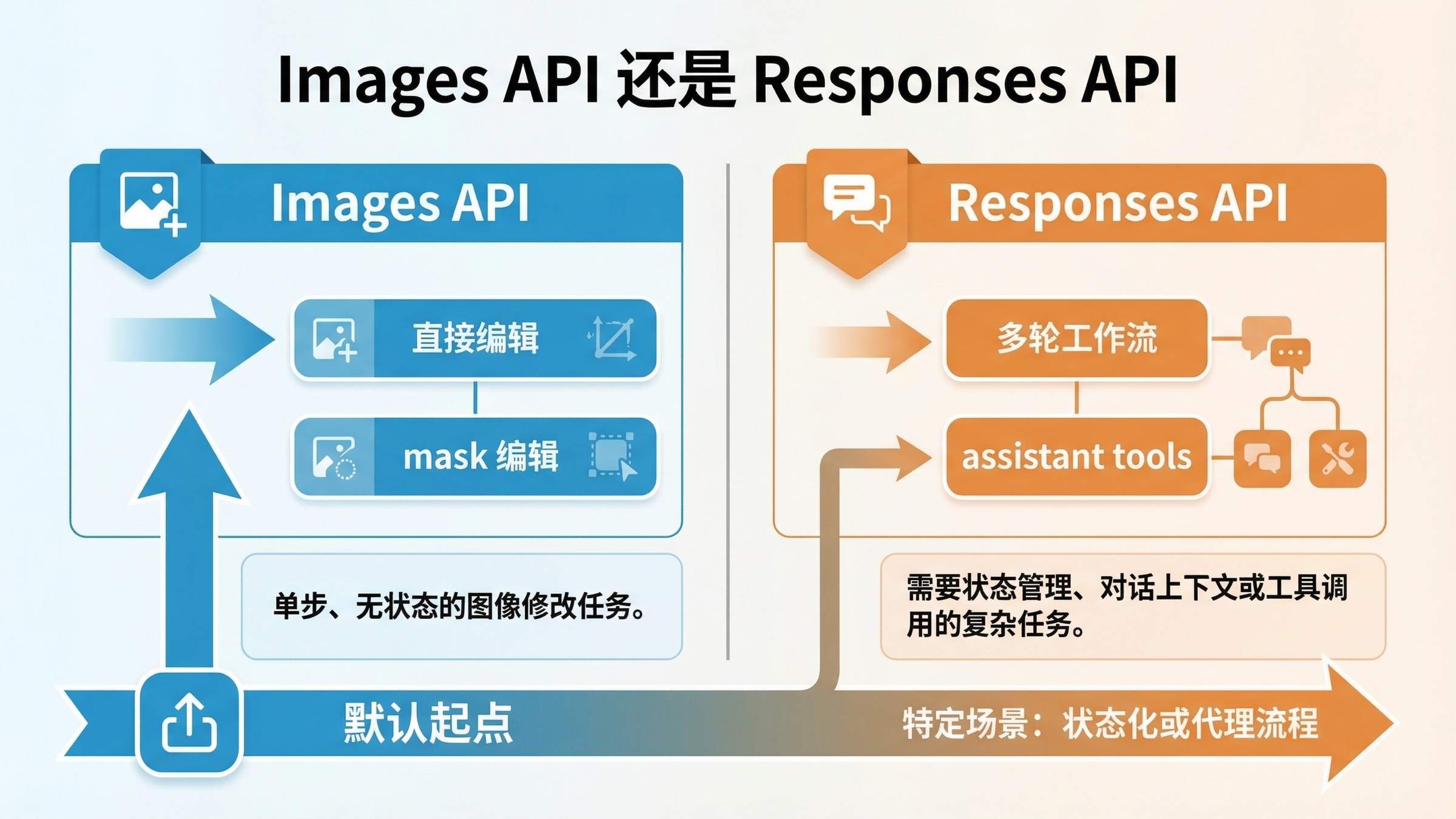
这一点正是 page one 里最常被讲糊涂的地方。
| 场景 | 更好的默认路线 | 为什么 |
|---|---|---|
| 编辑一张或多张输入图,然后把结果文件保存下来 | Images API | 路径最短,请求契约也最容易排查 |
| 在保留人脸、logo、商品图的前提下插入或替换元素 | Images API | 直接编辑再配合 input_fidelity=high 是最清楚的保留型方案 |
| 使用 mask 指定模型重点修改的区域 | Images API | mask、multipart 上传和输出处理都已经是一等公民 |
| 在同一段多轮对话里继续基于上一张图追改 | Responses API | 会话状态和连续工具调用在这里更自然 |
| 做一个可能需要推理、调用工具、看图再编辑的 assistant | Responses API | 图片编辑只是更大产品流程中的一个 tool |
最重要的一句规则其实很简单:不要只因为 Responses 看起来更新,就一开始走它。 当前 tool guide 已经写得很清楚,Responses 适合托管式的更大图片工作流,而且 GPT Image 模型不能作为 Responses 顶层 model。你要放的是像 gpt-5 这样的文本主模型,再由 image_generation 工具去执行图片编辑或出图。
这让 Responses 很强,但也更容易让人选错抽象层。如果你的产品今天只需要一个“上传图片并返回编辑结果”的接口,先把直接 Images API 跑顺。如果以后产品真的发展成多轮会话、对话记忆或多工具编排,再切到 Responses 才合理。
写 prompt 前,先判断你属于哪种编辑任务
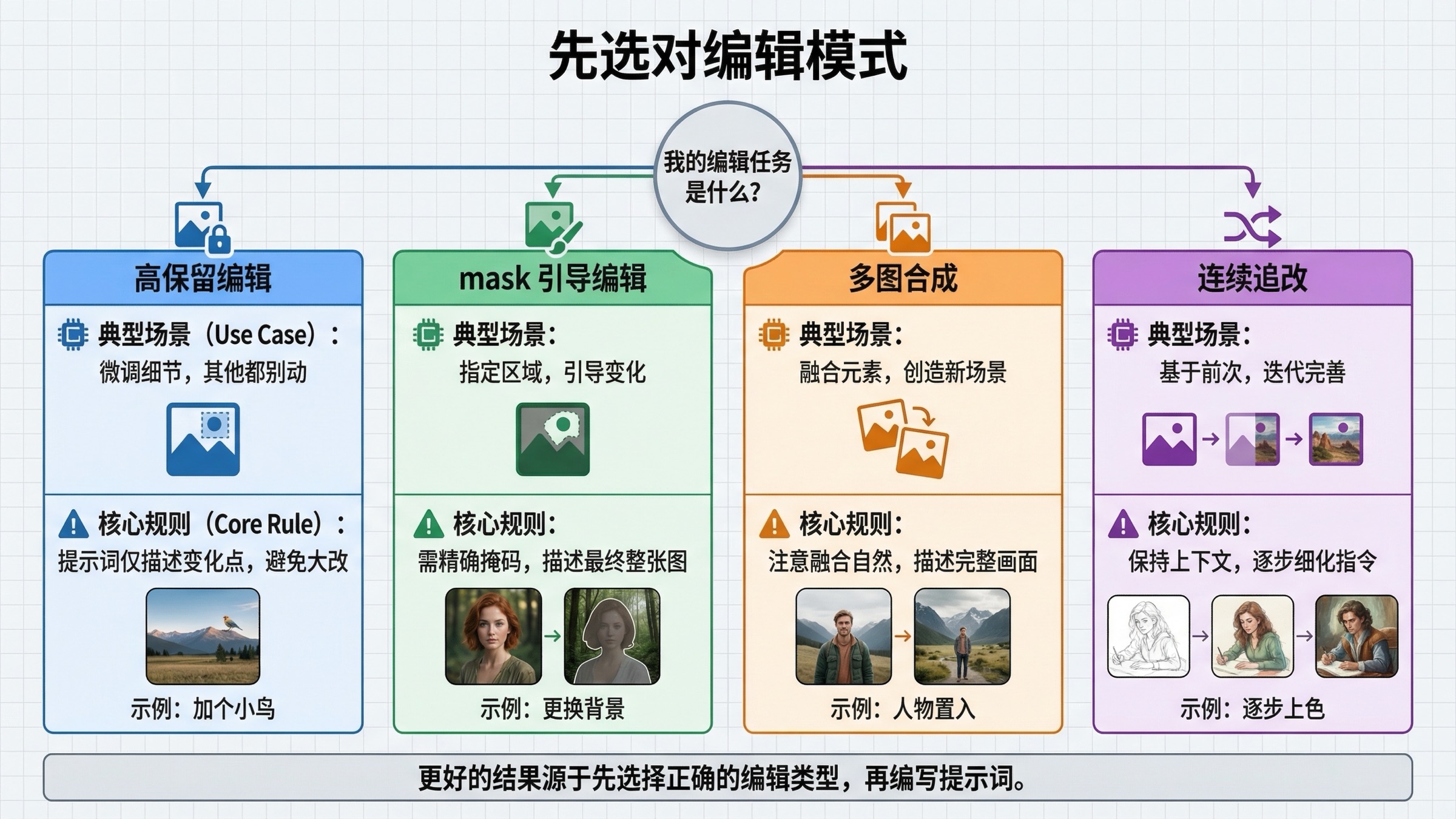
很多弱教程把“image editing”当成一个动作,其实不是。你先分清自己在做哪一类编辑,prompt 才会越写越清楚,而不是越写越长。
第一类是高保留单图编辑。你已经有想要的场景,只需要做一个受控改动,比如换衣服、加招牌、改墙上挂画、删掉一个干扰物、改某个物体风格,或者在不改构图的前提下变换氛围。这类任务里,保留比创造更重要,所以 input_fidelity="high" 往往值得加。
第二类是 mask-guided edit。也就是你不仅告诉模型“改什么”,还告诉它“重点看哪里”。这会有帮助,但不会把 GPT Image 变成一个完全确定性的局部补丁工具。mask 更像方向引导,而不是“除了这里别动任何像素”的绝对保证。
第三类是多图参考或合成编辑。OpenAI 当前指南和 cookbook 都展示了:你可以一次传多张图,让模型把一张图里的元素带到另一张图里。常见任务包括:
- 把图二里的 logo 放到图一的衣服上
- 把图二里的狗带到图一的场景里
- 保留同一个商品,只是换拍摄环境
第四类是连续追改。如果第一轮结果已经接近,但你想在一次多轮会话里继续让模型沿着上一个结果细修,那么 Responses 的吸引力就会更强。因为这时你关心的是连续上下文,而不是一次独立 edit call。
为什么要一开始就区分这四类?因为它们需要的 prompt 风格并不一样。高保留编辑更需要“其他都别动”的约束;mask 编辑更需要“最终整张图应该长什么样”的描述;多图合成更需要清楚说明“从哪张图拿什么、哪些东西必须保留”。
mask 和 input_fidelity 到底会怎么表现

这一节其实才是很多人在搜的真正问题,只是他们自己未必会这样下关键词。
OpenAI 当前 image generation guide 写得很明确:原图和 mask 必须同格式、同尺寸,总 payload 要控制在 50 MB 以内,而且 mask 需要 alpha channel。更重要的一句是:prompt 要描述最终整张图,而不是只写擦除区域。
这句话会直接改变你对 API 的理解方式。它意味着模型不是单纯地“补一个洞”,而是在综合理解原图、mask 和 prompt 之后,生成一张新的、语义上自洽的最终结果。
这也是为什么社区抱怨并不是空穴来风。OpenAI Developer Community 上 2025 年 4 月 27 日 的一个讨论就提到:masked edit 看起来像把整张图都重新生成了。后来回复里还引用了 OpenAI Support 对当时 gpt-image-1 的解释,说精确 inpainting 仍是已知限制。即便 GPT Image 1.5 在高保留编辑上已经明显强于 GPT Image 1,实操结论仍然不该变:把 masked workflow 当成语义编辑系统来测试,而不是拿它当严格像素边界手术刀。
input_fidelity="high" 的价值,则体现在需要更强保留时。OpenAI 在 direct guide 里把它放进 logo 放置示例里;微软当前 Azure OpenAI 的编辑指南也给出了类似解释:高 input fidelity 会让模型更努力地保留输入图特征,尤其是人脸等关键视觉身份。它特别适合这些场景:
- 换背景,但商品本体不能变
- 改人物服装,但脸部身份要保留
- 把品牌 logo 放到物体或服装上
- 做一个小幅场景修改,同时尽量不动镜头角度和构图
这个参数的取舍并不神秘。更高的保留努力,通常就意味着更高成本和更保守的编辑行为。如果任务本身不需要严格保留,你把 high fidelity 到处硬开,收益往往并不大。
更稳的习惯是:
- 先做一次最简单的 direct edit
- 只有当保留确实重要时再加
input_fidelity=high - 只有当位置引导确实重要时再加 mask
- prompt 聚焦在最终图、必须保留的元素,以及一两处真正要改的点
如果第一轮结果已经接近,不要立刻把 prompt 写成一大段愿望清单。先做一次更窄、更明确的 follow-up 修正,通常更容易得到可控结果。
高保留编辑更适合拆成小步
当前 GPT Image 1.5 prompting guide 的价值在于,它不像参数速查表,而更像 production advice。无论是翻译、合成、风格保持还是场景变化,其中反复出现的模式都是:明确约束 + 小步迭代 比一开始堆满需求更稳。
这也应该成为你在产品里组织 prompt 的方式。
坏 prompt:
textMake this look better, more modern, cleaner, more premium, maybe add some flowers, maybe change the colors, and make it suitable for a landing page.
更好的保留型 prompt:
textReplace only the poster on the wall with a framed abstract print. Preserve the room layout, furniture, lighting, floor shadows, and camera angle. Do not move or redesign any other object. Photorealistic interior photography.
更好的合成 prompt:
textPlace the logo from image 2 onto the front of the tote bag in image 1. Match the bag's fabric texture and lighting. Keep the model, pose, background, and camera framing unchanged.
更好的 follow-up prompt:
textKeep the edited image exactly the same, but make the poster slightly larger and reduce glare on the frame. Do not change anything else.
最后一句尤其重要。原图越有业务价值,你越应该像在“保护状态”的操作员,而不是一个无限追求风格化效果的 prompt writer。
这也是为什么 OpenAI 2025 年 12 月 16 日 的发布文章值得注意。OpenAI 把 GPT Image 1.5 定位为比 GPT Image 1 更适合保留品牌 logo、关键视觉和人脸一致性的模型。这并不意味着所有高保留编辑都会完美,而是意味着:现在很多结果好坏,更多取决于你的 prompt discipline 和 edit sequencing,而不是模型本身有没有最基础的能力。
如果你看完这里,接下来想确认的是“更大范围内该选哪个 image model”,最自然的下一篇是中文的 OpenAI image generation API models 指南。
排错:page one 仍然经常漏掉的几个失败点
第一个失败点,是一开始就选错 API surface。如果你只是想编辑图片,不要上来就把 Responses workflow 搭起来,更不要在 Responses 顶层 model 字段里直接写 gpt-image-1.5。那不是正确契约。先用 direct Images API,把 Responses 留给真正需要多轮或多工具编排的时候。
第二个失败点,是信错了官方页面的新鲜度。截至 2026 年 3 月 23 日,GPT Image 1.5 模型页明确说它是最新 image generation model,但更广的 Images and vision guide 仍保留着 gpt-image-1 是 latest 的旧表述。如果你的内部文档或博客引用错了页面,即使代码还能跑,策略判断也会显得过时。
第三个失败点,是向 raw edit endpoint 发 JSON。直接图片编辑走的是 multipart form data。你用 curl 或自建 HTTP client 时,这个细节不是“可选最佳实践”,而是请求是否成立的前提。
第四个失败点,是把 mask 当成强承诺,而不是引导工具。如果你的产品绝对依赖“小范围精准修补且周边零副作用”,那就应该尽早用真实样本验证这个假设,而不是看到文档里有 mask 就默认它一定满足。
第五个失败点,是prompt 只写被修改的那个对象。OpenAI 当前指南明确要求描述最终整张图。如果你只写“加一个 beach ball”,模型对其他部分其实拥有过大的自由度。
第六个失败点,是把 access 问题和语法问题混为一谈。GPT Image 1.5 仍然有当前 tier 限制,模型页也明确写着 Free not supported。如果请求在返回可用图片之前就失败,先确认 access,而不是先改 prompt。如果你怀疑这才是你的根因,下一篇更适合看的是中文的 OpenAI image generation API verification 指南。
第七个失败点,是试图在一个请求里塞进太多变化。对高保留任务来说,超长复合 prompt 会让你更难判断问题到底出在构图、保留、措辞,还是 mask 本身。一次改一件事,再做一次小修正,仍然是更好的生产习惯。
FAQ
现在做图片编辑,应该用 gpt-image-1 还是 gpt-image-1.5?
如果是新的直接编辑工作流,先用 gpt-image-1.5。截至 2026 年 3 月 23 日,OpenAI 当前 GPT Image 1.5 模型页把它标为最新 image generation model;只有更老的官方页面还在继续提 gpt-image-1。gpt-image-1 更适合旧工作流维护或对比迁移。
为什么我的 mask edit 改动比掩码范围更大?
因为 GPT Image 编辑更接近“被 mask 引导的语义重写”,而不是严格像素级局部修补。OpenAI 当前指南要求描述最终整张图,社区讨论也不断说明:当用户期待硬边界 inpainting 时,实际结果经常会比预想改动更广。
每次编辑都需要 input_fidelity=high 吗?
不需要。只有在你特别在意人脸、logo、商品几何、镜头角度或其他关键视觉身份时,才值得加。若任务本身更偏生成式、也不介意模型做更大幅度重写,就没必要默认全开。
什么时候该从 Images API 切到 Responses?
当图片编辑已经变成多轮对话、assistant workflow 或更大工具链中的一环时,再切到 Responses。只要图片编辑本身就是你要交付的功能,继续留在直接 Images API 上通常更合理。
最终建议
今天最干净的规则就是:如果你要用 OpenAI API 做图片编辑,先从 images.edit() + gpt-image-1.5 开始,而不是从更宽的 Responses workflow 开始。mask 用来告诉模型“重点看哪里”,但 prompt 仍然要按“描述最终整张图”的思路来写。只有当保留是任务核心时,再补 input_fidelity=high,不要把它变成所有请求的默认模板。
这也是当前 page one 仍然普遍没讲清的地方。真正高价值的答案不是“OpenAI 可以编辑图片”,而是“直接编辑该走哪条路、什么时候切换备用路线,以及 mask 到底不能保证什么”。
如果你看完后想把范围放大到整个 API 路线,可以继续读完整的 OpenAI Image API 教程。如果你下一步更需要的是可运行的出图示例,可以接着看中文的 OpenAI image generation API example。