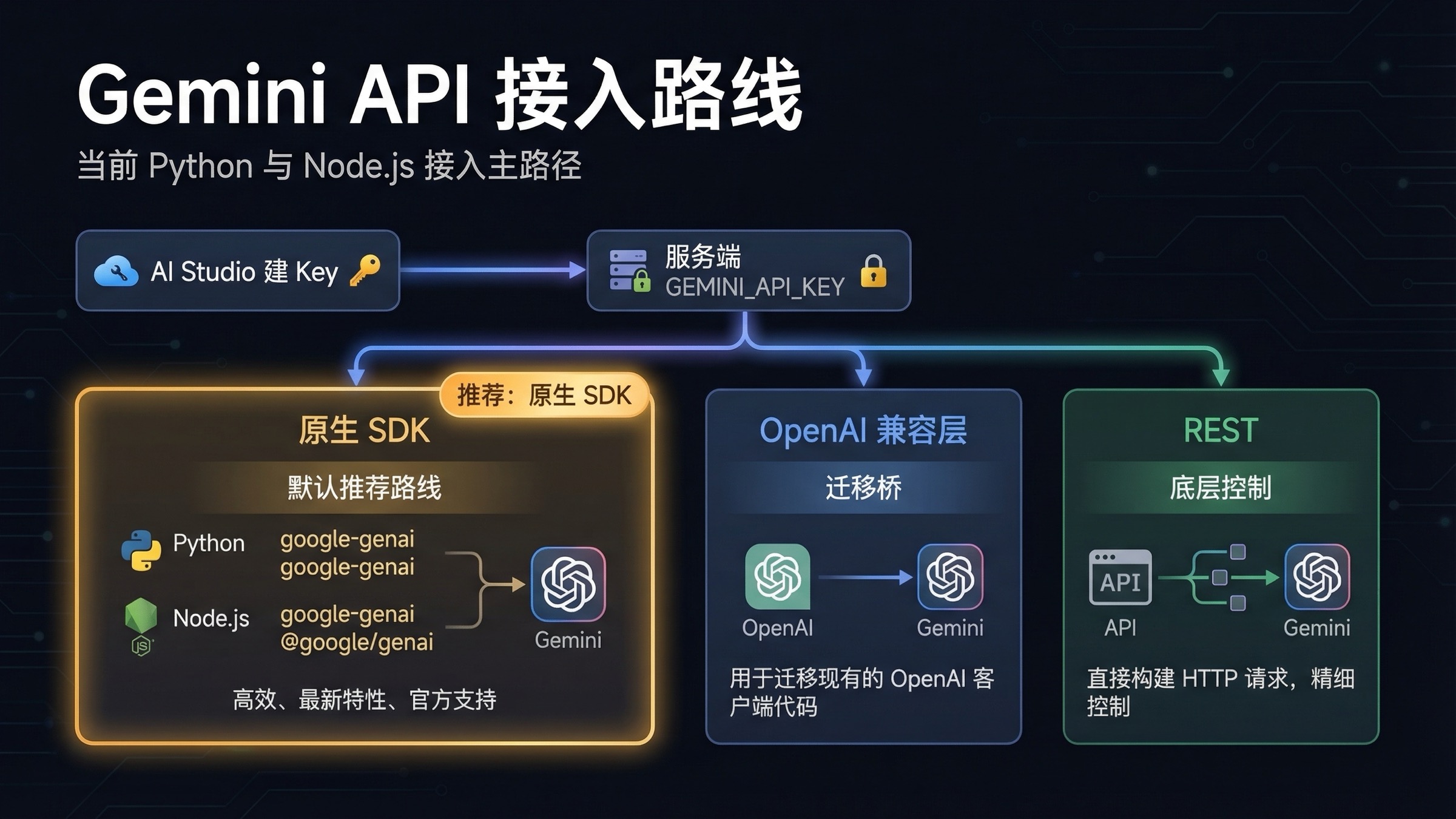
如果你现在要开始一个新的 Gemini API 集成,默认路线就是先用原生 Google GenAI SDK,把 GEMINI_API_KEY 放在服务端,再先跑通一个最小可用请求,确认基础链路没问题之后再加 streaming、tools 或 files。只有在你已经有一套 OpenAI 风格的现有代码、确实需要快速迁移时,OpenAI 兼容层才应该排到前面。因为 Google 当前的 quickstart、migration guide 和 example repo,已经全面转向 google-genai(Python)与 @google/genai(JavaScript)。
第一天最重要的,不是再看一遍泛泛的 hello world,而是把实现路径走对。先把原生 SDK、密钥边界和首个请求跑通;然后按顺序补 streaming、structured output、tool calling、Files API,以及 billing 和 rate limits。这样你就不会在一开始就被旧包名、旧模型 ID 或错误的生产边界拖进返工。
当前官方示例中仍然大量使用 gemini-3-flash-preview 这样的 preview 模型字符串,所以这里的示例也沿用这一官方当前写法。但更稳妥的生产规则并不是“永远跟着 preview 跑”。Google 的 models 页面明确写着:如果有合适的 stable 模型,多数生产应用更适合使用明确的 stable model ID。也就是说,你可以先用这里的例子跑通,再根据自己业务把模型切到像 gemini-2.5-flash 这样的稳定版本。
要点速览
- 新项目默认用
google-genai和@google/genai。这是 Google 当前主推的 Google GenAI SDK 路线,migration guide 也明确建议从旧 Gemini 库迁移过来。 - API Key 在 Google AI Studio 创建,放进
GEMINI_API_KEY,并通过服务端、后端 worker、API route 或 server action 调用,而不是直接放在浏览器里。 - 第一步先让一个原生 SDK 请求成功。第二步学流式输出。第三步再根据业务需要加结构化输出或函数调用。这个顺序最稳。
- 如果你已经有一套 OpenAI 风格客户端,OpenAI 兼容层 是最快的迁移桥梁;但如果你真正需要 Gemini 的原生能力,比如 Files API 或更完整的 tool flow,长期还是原生 SDK 更合适。
- 请求总大小超过 100 MB 时,或 PDF 超过 50 MB 时,应该切到 Files API。官方说明还写明:上传文件保存 48 小时、每个项目最多 20 GB、单文件最多 2 GB。
- Billing 和 quota 不能等到出问题才看。Google 的 billing 页面 明确写到:400 和 500 错误不会计费,但仍然会消耗 quota;而 rate limits 页面 也说明限制与 tier 相关,需要在 AI Studio 里查看当前值。
| 路线 | 最适合谁 | 优点 | 主要代价 |
|---|---|---|---|
| 原生 Google GenAI SDK | 新的 Python / Node.js 应用 | 包名和文档都是当前官方主路径,直接支持 streaming、structured output、files、tools 等能力 | 需要接受 Gemini 原生客户端结构,而不是继续套 OpenAI 抽象 |
| OpenAI 兼容层 | 已有 OpenAI 风格代码库 | 改 base URL、API key 和 model name 就能快速验证 | 功能上限更低,Gemini 原生特性会出现抽象损耗 |
| 直接 REST | 自定义语言、极端依赖控制、底层调试 | 自己掌控请求细节,无 SDK 负担 | 样板代码更多,复杂能力要自己管理 |
如果你当前缺的是 key 创建步骤,可以直接看站内的 Gemini API Key 指南 作为英文 fallback;如果你更关心成本,可以接着看中文本地化的 Gemini API Token Pricing 指南;如果你已经碰到 429、400、500 或更广义的接入异常,下一步应看 Gemini API 错误排查指南。
正确的 Gemini API 首次集成路径

正确的起点不是 IDE,而是 AI Studio。Gemini API 当前的 key 管理方式,是在 Google AI Studio 里创建和维护 key,并且 key 归属于 Google Cloud project,而不是像某些开发者以为的那样,是一个“完全独立”的凭证。对新用户来说,AI Studio 往往会自动给你建一个默认 project 和默认 key,这确实能让你很快跑通第一条请求,但也意味着你应该更早思考 project、billing 与团队权限边界。
在真正开始写代码之前,你只要先把一条原则记牢:**把 GEMINI_API_KEY 放在服务端。**如果你在写后端服务,就把 key 配进环境变量;如果你在写 Web 应用,就通过 API route、server route、edge backend 或其他后端执行面去调用 Gemini。不要把永久 key 直接塞进浏览器端 JS,也不要把“让用户自己在前端贴 key”当成默认安全策略。对于真正要上线的应用,这几乎总是错误的起点。
当前官方 quickstart 的安装方式就是下面这样:
bashpip install -U google-genai npm install @google/genai
然后设置环境变量:
bashexport GEMINI_API_KEY="your_real_key_here"
这之后,第一条请求一定要尽量朴素。不要一开始就上 function calling、grounding、multimodal files。第一条请求的目标只有一个:确认 key、运行时、网络路径和基础客户端都没问题。
pythonfrom google import genai client = genai.Client() response = client.models.generate_content( model="gemini-3-flash-preview", contents="Explain the purpose of an API integration tutorial in one sentence." ) print(response.text)
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({}); const response = await ai.models.generateContent({ model: "gemini-3-flash-preview", contents: "Explain the purpose of an API integration tutorial in one sentence.", }); console.log(response.text);
这一步最重要的不是 prompt,而是客户端结构。新 SDK 已经把 models、chats、files 等服务都放进统一 client 里。Google 的 migration guide 之所以值得读,不是因为它会给你更多功能,而是因为它告诉你:很多旧教程之所以让人越看越乱,正是因为它们教的已经不是 Google 当前主推的客户端结构了。
2026 仍然不过时的 Python 集成示例
Python 现在依然是 Gemini 最顺手的接入路径之一。基础请求已经很短,但第一个真正值得学的升级不是“更多 prompt 技巧”,而是 streaming。Google 的 text-generation guide 里就给了 generate_content_stream 的当前写法,这对于 CLI 工具、后台作业回传、聊天 UI 或任何要降低感知延迟的场景都很有价值。
pythonfrom google import genai client = genai.Client() stream = client.models.generate_content_stream( model="gemini-3-flash-preview", contents="Write three short tips for migrating from a legacy LLM SDK." ) for chunk in stream: print(chunk.text, end="")
这一步的意义在于,它让你的应用第一次从“能跑”走向“像产品”。很多弱教程只会停在一次性返回完整结果的 generate_content,但真实应用更常见的需求其实是:尽快把部分结果交给用户、减轻长响应等待感、让 UI 先动起来。Streaming 就是最自然的下一个能力。
第二个很值得尽早掌握的模式,是 structured output。Google 的 structured outputs 页面明确支持 JSON Schema,而 Python 路线还能直接配合 Pydantic。只要你的 Gemini 输出要被另一个系统消费,而不是只给人眼看,结构化输出就比“在 prompt 里说请返回 JSON”靠谱得多。
pythonfrom google import genai from google.genai import types from pydantic import BaseModel class IntegrationTicket(BaseModel): language: str task: str priority: str client = genai.Client() response = client.models.generate_content( model="gemini-3-flash-preview", contents="Python app, needs JSON output, shipping next week.", config=types.GenerateContentConfig( response_mime_type="application/json", response_schema=IntegrationTicket, ), ) print(response.text)
一旦你把 schema 交给模型,prompt 的重心就不再是“拜托你别乱格式化”,而是“把真正的信息抽出来”。这就是生产型集成与 demo 型集成最重要的差别之一。
Python 在 function calling 上也有额外优势。Google 的 function-calling guide 说明,Python SDK 可以直接把带 type hints 和 docstring 的 Python 函数作为 tool 使用,并自动管理 declaration、调用执行和响应回传。这对于内部工具、自动化工作流或较轻量的 agent 场景来说,非常省时间。
pythonfrom google import genai from google.genai import types def get_current_temperature(location: str) -> dict: """Gets the current temperature for a given location.""" return {"temperature": 25, "unit": "Celsius"} client = genai.Client() response = client.models.generate_content( model="gemini-3-flash-preview", contents="What's the temperature in Boston?", config=types.GenerateContentConfig(tools=[get_current_temperature]), ) print(response.text)
不过这个便利性更适合“Python 自己就是执行中心”的场景。如果你后面还要做跨语言工具编排、统一审计或服务边界拆分,那么 Python 的自动便利层未必就是长期最优解。它很适合快速推进,但不一定适合所有系统架构。
JavaScript 与 Node.js 集成示例
Node.js 路线在客户端结构上与 Python 很接近,但它最容易踩坑的地方是运行边界。因为很多 JavaScript 开发者在做 Web 产品,很容易一开始就把 key、SDK 和页面逻辑写在一起。当前的 @google/genai 包本身没有问题,真正要强调的是:它应该运行在 Node、API route、server action、edge backend 或其他服务端执行面,而不是直接暴露在公开前端。
第一条 JavaScript 请求应保持尽量简单:
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({}); const response = await ai.models.generateContent({ model: "gemini-3-flash-preview", contents: "Give me a one-line summary of why current SDK names matter.", }); console.log(response.text);
第二步同样建议先学 streaming:
javascriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({}); const stream = await ai.models.generateContentStream({ model: "gemini-3-flash-preview", contents: "List three practical steps for hardening an API integration.", }); for await (const chunk of stream) { process.stdout.write(chunk.text ?? ""); }
对于 Next.js、Express、Nest 或其他 Node 后端来说,这一步非常关键。因为一旦流式输出跑通,你就能一边保持服务端 key 边界,一边把响应 chunk 持续转发给前端,用户感受会比“等整段结果生成完再一次性返回”好很多。
JavaScript 也支持 structured output 与 function calling,只是它的使用体验更偏“显式配置”,不像 Python 那样更偏自动便利。官方文档在 JS 里用的是 Zod、functionCallingConfig 之类更明确的写法。如果你的团队本身就是 TypeScript 后端栈,这种显式控制反而是优点,因为它更容易和现有类型系统、请求 schema 与服务边界一起工作。
另外,别等费用失控之后才去看 token。Google 的 token guide 给了 count tokens 和 usage metadata 的当前路线,这比靠字符数拍脑袋靠谱得多。尤其在 JavaScript 产品里,prompt 常常会随着功能增长越来越长,越早量化,后面越不容易出账单惊喜。
什么时候该用 OpenAI 兼容层

OpenAI 兼容层不是噱头,而是真正有用的过渡工具。Google 的官方兼容层文档已经把路径写得很清楚:把 base URL 换成 Gemini 的兼容层地址、换 API key、换 model name,就能用现有 OpenAI 风格客户端快速验证 Gemini 是否适合你的场景。如果你的团队已经有一套围绕 OpenAI messages 结构构建起来的服务,这是最快的落地办法。
pythonfrom openai import OpenAI client = OpenAI( api_key="YOUR_GEMINI_API_KEY", base_url="https://generativelanguage.googleapis.com/v1beta/openai/", ) response = client.chat.completions.create( model="gemini-3-flash-preview", messages=[{"role": "user", "content": "Explain why compatibility layers are useful."}], ) print(response.choices[0].message.content)
兼容层之所以吸引人,主要有两个原因。第一,它让已有系统能很快加上 Gemini,而不用马上改掉整个客户端抽象。第二,它对 provider 对比、BYOK 或统一 provider gateway 场景很友好。只要“尽快验证”和“尽量少改代码”是当前最高优先级,兼容层就是正确选择。
但它不应该被误解成“永远最佳”。Google 自己的 partner integration guide 已经把 trade-off 说得很明白:如果你真正需要 Gemini 的原生能力,比如 Files API、更完整的 tools、或者更贴近 Gemini 架构的能力暴露,OpenAI 兼容层就会逐渐变成一种抽象损耗。越往后走,你越可能为“兼容”付出额外映射成本。
最实用的决策规则其实很简单:如果你是在现有 OpenAI 风格代码库里快速验证 Gemini,先上兼容层;如果你是在做新的 Gemini 项目,优先直接走原生 SDK。这样你的系统更接近 Gemini 的真实能力面,也能避免未来为了追原生功能又做一次迁移。
Hello World 之后最值得先学的生产能力
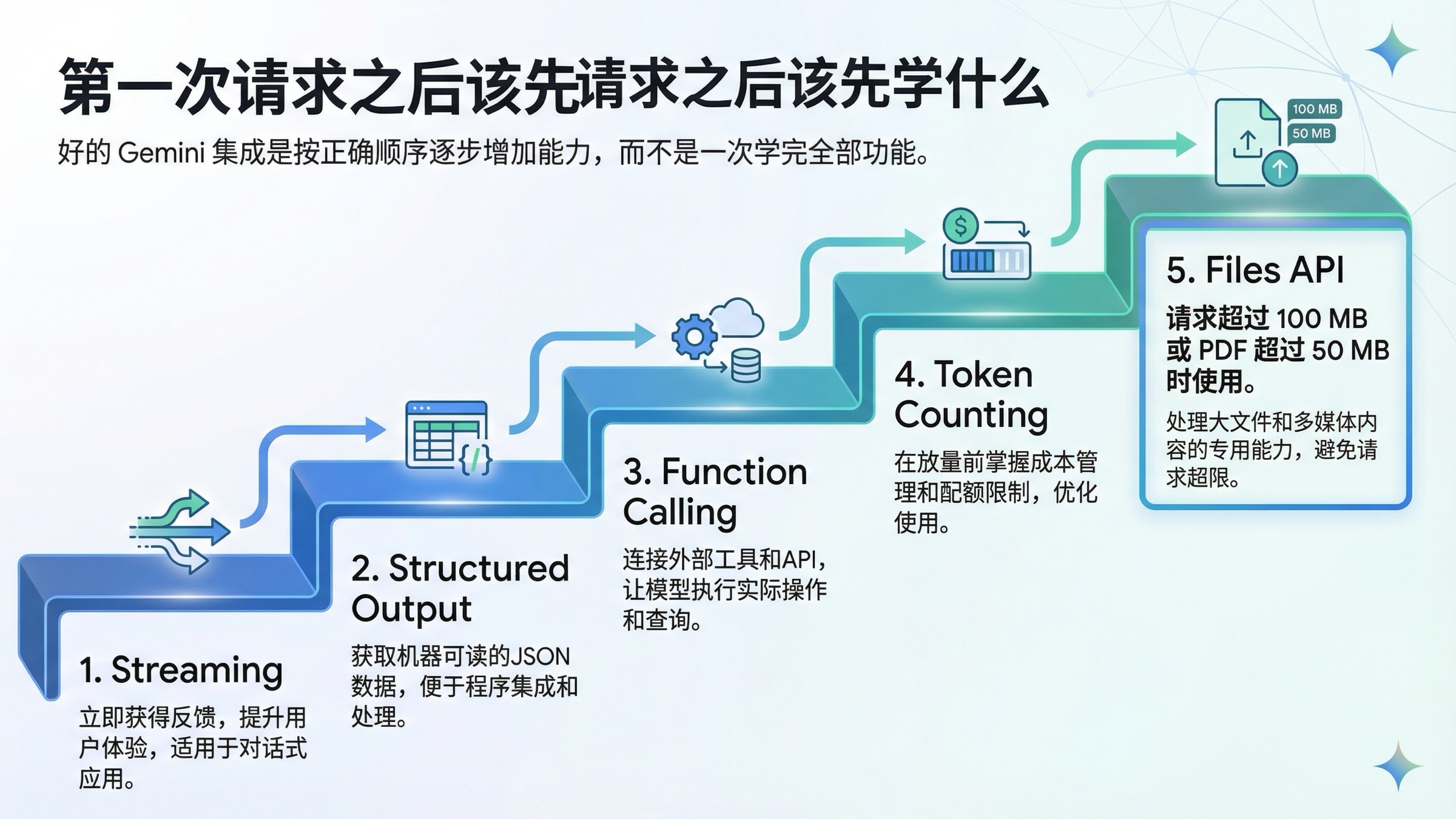
第一次请求成功之后,最容易犯的错误,就是开始“把所有功能都学一遍”。真正更好的路线不是“学完整个 Gemini 能力树”,而是先学那些最早会改变真实产品行为的能力。对大多数开发者来说,这个顺序通常是:streaming、structured output、function calling、token counting,最后是 Files API。
Streaming 改变的是响应体验。Structured output 改变的是下游自动化可靠性。Function calling 让模型能和你的代码、工具或外部 API 连起来。Token counting 让你在规模上来之前有成本感知。Files API 则是在请求变大、真正进入文档、音频、图片、视频等多模态输入时必须掌握的能力。
Google 的 Files API 文档还给出了很关键的实际阈值:总请求大小超过 100 MB 时要走 Files API;PDF 超过 50 MB 时也应切换。它还写明文件默认保存 48 小时、每项目 20 GB、单文件 2 GB。这些都不是“冷知识”,而是你在做文档处理、音频理解或较大多模态请求时必须提前知道的系统约束。
javascriptimport { GoogleGenAI, createPartFromUri, createUserContent, } from "@google/genai"; const ai = new GoogleGenAI({}); const myfile = await ai.files.upload({ file: "path/to/sample.mp3", config: { mimeType: "audio/mpeg" }, }); const response = await ai.models.generateContent({ model: "gemini-3-flash-preview", contents: createUserContent([ createPartFromUri(myfile.uri, myfile.mimeType), "Describe this audio clip", ]), }); console.log(response.text);
要特别强调的是:Files API 的正确使用场景,是“真的需要它时再上”,而不是“既然官方支持,那我所有请求都改成上传文件”。小文本请求依然应保持简单。之所以建议早点理解 Files API,是因为一旦你真的遇到大文档、大音频或较大多模态输入,request size、保留时长、删除策略这些约束就不再是可以事后补课的知识。
| 能力 | 什么时候先学 | 为什么重要 | 官方锚点 |
|---|---|---|---|
| Streaming | 第一条请求成功后立刻学 | 提升交互体验与感知速度 | Text generation |
| Structured Output | 需要把结果交给别的系统消费时 | 比“请返回 JSON”稳定得多 | Structured outputs |
| Function Calling | 模型要触发应用逻辑或调用工具时 | 让 agent-like 工作流更可控 | Function calling |
| Token Counting | 准备上生产流量之前 | 及早量化 prompt 增长与成本 | Token counting |
| Files API | 请求总大小超过 100 MB,或 PDF 超过 50 MB 时 | 支撑真正的大型多模态输入 | Files API |
这个顺序本身,就是很多教程没有给出的价值。太浅的文章只会停在 text prompt;太散的文章则会一次性把所有能力列出来,却不告诉你先学哪个。真正适合生产落地的路径,是先把第一条请求跑稳,再按照最能改变实际结果的顺序往上加。
常见问题排查与 Gemini 集成错误
最常见的错误,其实是从错误的教程开始。如果你看到文章里还把 google-generativeai 或 @google/generative-ai 当成“当前默认路线”,先不要照抄,先对照 Google 的 migration guide 看一眼。旧代码不一定完全不能用,但它已经不是 2026 年最干净的起点了。
第二个常见错误,是把 preview model 当成稳定契约。Google 的 models 页面明确说明,preview 模型可以用于生产,但通常限制更紧、退场风险更高。这不等于你不能用 preview,而是说你必须清楚自己为什么用它,并且有能力在之后切到 stable model。对很多不需要追最新能力的业务来说,stable 仍然是更稳的默认值。
第三个常见错误,是误解 billing 与 quota。Google 的 billing 页面写得很明确:input tokens、output tokens、cached token count 和 cached token storage duration 都会影响计费;而 400 与 500 虽然不收费,但依然消耗 quota。很多团队一看到“failed requests are not billed”,就以为失败没有任何代价。实际上不是。你只是没被收费,但容量仍然被消耗了。
这也是为什么 429 不能只靠“加 retry”来理解。Google 的 rate limits 页面说明,限制与 tier 绑定,要在 AI Studio 里看当前可用值;而社区讨论还进一步暴露了另一个现实:开发者即便没有打满肉眼可见的 RPM,也可能碰到 batch enqueued tokens、project 级别配置或 preview capacity 相关问题。所以真正遇到 429 时,先确认自己撞到的是哪一层限制,而不是机械地把 backoff 写得更长。
第四个错误,是在第一周把 Gemini 所有能力都学完。你并不需要在 day one 同时掌握 streaming、tools、files、caches、chat history 和复杂 orchestration。你真正需要的是:一条成功请求、一个清晰的服务端密钥边界,以及一个与当前产品场景最匹配的下一能力。大多数团队只要守住这个顺序,落地速度反而会更快。
如果你现在已经处在报错阶段,而不是教程选择阶段,那就不要继续猜。继续看中文的 Gemini API 错误排查指南 才是更高价值的下一步;如果你主要担心成本与 token 结构,则接着看 Gemini API Token Pricing 指南。如果只压缩成一句实现建议,就是:先走原生、密钥留在服务端、尽早测 token、按顺序学能力。