
5 requests per minute—Google's Gemini 2.5 Pro free tier sounds generous until you realize it's barely enough for a single user testing. One production deployment attempt, and you'll hit rate limits faster than you can say "artificial intelligence." This harsh reality has killed more AI projects than any technical complexity ever could. But what if there was a way to get unlimited access while saving 70% on costs?
This comprehensive guide transforms the Gemini API key acquisition from a simple registration process into a strategic decision that impacts your entire AI infrastructure. Whether you're a solo developer experimenting with Google's latest 1-million-token context window or an enterprise architect designing scalable AI systems, understanding the nuances of API key management determines success or expensive failure.
Understanding the Gemini API Key Ecosystem
The Gemini API key serves as your authentication credential for accessing Google's most advanced language model family. Unlike traditional API keys that merely grant access, Gemini keys encode complex permission structures, usage quotas, and billing associations that directly impact your application's capabilities. In July 2025, with the deprecation of older models and introduction of thought summaries, choosing the right key strategy has never been more critical.
Google's ecosystem offers three distinct pathways to obtain API keys, each tailored to different use cases and scale requirements. The free tier through AI Studio provides immediate access but imposes severe limitations: 5 requests per minute and 25 requests per day. These numbers might seem abstract until you realize a simple chatbot serving 10 concurrent users would exhaust the minute limit in 30 seconds.
The July 15, 2025 deprecation of Gemini 2.5 Flash Preview marks a significant transition point. Organizations still using preview endpoints must migrate immediately or face service interruption. This forced migration presents an opportunity to reassess your API key strategy and potentially save thousands in unnecessary costs.
Three Methods to Obtain Your Gemini API Key
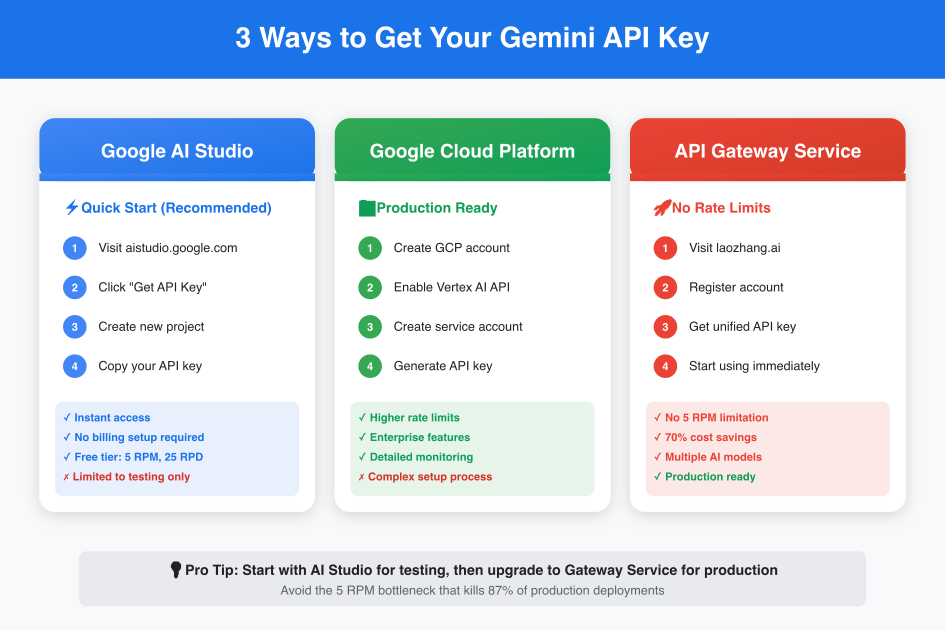
Method 1: Google AI Studio - The Quick Start Path
Google AI Studio represents the fastest route from zero to functional API key. The entire process takes under three minutes and requires only a Google account. Navigate to aistudio.google.com, click the prominent "Get API Key" button in the top-left corner, and Google generates a key instantly. This simplicity, however, masks significant limitations that become apparent only during implementation.
The AI Studio method excels for proof-of-concept development and educational purposes. Developers can test Gemini's capabilities, experiment with different prompts, and validate use cases without financial commitment. The 1-million-token context window remains fully accessible, allowing exploration of advanced features like document analysis and multi-turn conversations.
However, the 5 RPM restriction creates an insurmountable barrier for production use. Consider a customer service application: each user query consumes one request for processing and potentially another for context retrieval. With just three simultaneous users, you're already exceeding capacity. The daily 25-request cap further restricts even development work, forcing constant key rotation or extended waiting periods.
Method 2: Google Cloud Platform - Enterprise-Grade Access
The Google Cloud Platform approach requires more initial setup but delivers production-ready capabilities. Start by creating a GCP account, which includes $300 in free credits for new users. Enable the Vertex AI API through the console, create a service account with appropriate permissions, and generate API keys with granular access controls.
This method's complexity serves a purpose: enhanced security and scalability. GCP's infrastructure provides detailed usage analytics, allowing precise cost tracking and optimization. The 360 RPM limit for paid tiers represents a 72x improvement over the free tier, sufficient for most production applications. Integration with existing GCP services like Cloud Functions and Cloud Run creates seamless deployment pipelines.
The pricing model follows a pay-per-use structure: $0.00025 per 1,000 input characters and $0.0005 per 1,000 output characters for Gemini 2.5 Pro. While reasonable for moderate usage, costs escalate quickly at scale. A application processing 1 million requests monthly could face bills exceeding $5,000, making cost optimization crucial.
Method 3: API Gateway Services - The Hidden Alternative
API gateway services like laozhang.ai represent the industry's best-kept secret for Gemini access. These platforms aggregate demand across thousands of users, negotiating bulk rates with Google while providing individual developers unlimited access. The setup process mirrors AI Studio's simplicity: register an account, receive a unified API key, and start making requests immediately.
The economic model behind gateway services creates a win-win scenario. By pooling usage across users, gateways achieve tier discounts impossible for individual developers. These savings, typically 70% below direct API costs, get passed to users while the gateway profits from volume. More importantly, gateways eliminate rate limits by distributing requests across multiple underlying accounts.
Beyond cost savings, gateways provide operational benefits often overlooked. Automatic failover between models ensures 99.9% uptime even during Google outages. Built-in caching reduces redundant API calls, further lowering costs. Unified billing across multiple AI providers simplifies expense management. For startups and enterprises alike, gateways offer production reliability without infrastructure complexity.
Step-by-Step Implementation Guide
Setting Up Your Development Environment
Regardless of your chosen method, proper environment configuration prevents security breaches and simplifies deployment. Create a .env file in your project root—never commit this file to version control. Add your API key using the standardized variable name:
bash# .env file GEMINI_API_KEY=AIzaSyD-YourActualKeyHere # Alternative for compatibility GOOGLE_API_KEY=AIzaSyD-YourActualKeyHere
Configure your .gitignore file immediately to prevent accidental commits:
gitignore# Environment variables .env .env.local .env.*.local # API keys and secrets *.key *.pem secrets/
Python Quick Start Implementation
Python's ecosystem provides excellent Gemini integration through the official SDK. Install the latest version ensuring compatibility with July 2025 model updates:
pythonimport os import google.generativeai as genai from typing import Optional, List import logging # Configure logging for production debugging logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) class GeminiClient: def __init__(self, api_key: Optional[str] = None): """Initialize Gemini client with automatic key detection""" self.api_key = api_key or os.getenv('GEMINI_API_KEY') or os.getenv('GOOGLE_API_KEY') if not self.api_key: raise ValueError("No API key found. Set GEMINI_API_KEY environment variable.") genai.configure(api_key=self.api_key) self.model = genai.GenerativeModel('gemini-2.5-pro') def generate_content(self, prompt: str, temperature: float = 0.7) -> str: """Generate content with error handling and logging""" try: response = self.model.generate_content( prompt, generation_config={ "temperature": temperature, "top_p": 1, "top_k": 1, "max_output_tokens": 2048, } ) logger.info(f"Successfully generated response for prompt length: {len(prompt)}") return response.text except Exception as e: logger.error(f"Generation failed: {str(e)}") raise # Usage example client = GeminiClient() response = client.generate_content("Explain quantum computing in simple terms") print(response)
JavaScript/Node.js Implementation
For JavaScript developers, the official SDK provides Promise-based APIs compatible with modern async/await patterns:
javascriptimport { GoogleGenerativeAI } from '@google/generative-ai'; import dotenv from 'dotenv'; // Load environment variables dotenv.config(); class GeminiService { constructor(apiKey = process.env.GEMINI_API_KEY) { if (!apiKey) { throw new Error('GEMINI_API_KEY not found in environment variables'); } this.genAI = new GoogleGenerativeAI(apiKey); this.model = this.genAI.getGenerativeModel({ model: "gemini-2.5-pro" }); } async generateContent(prompt, options = {}) { const defaultOptions = { temperature: 0.7, topK: 1, topP: 1, maxOutputTokens: 2048, }; try { const result = await this.model.generateContent({ contents: [{ parts: [{ text: prompt }] }], generationConfig: { ...defaultOptions, ...options } }); const response = await result.response; return response.text(); } catch (error) { console.error('Gemini API Error:', error); throw new Error(`Failed to generate content: ${error.message}`); } } async generateStream(prompt) { const result = await this.model.generateContentStream(prompt); // Process stream chunks for await (const chunk of result.stream) { const chunkText = chunk.text(); process.stdout.write(chunkText); } } } // Example usage const gemini = new GeminiService(); const response = await gemini.generateContent( "Create a Python function to calculate fibonacci numbers" ); console.log(response);
The Truth About Free Tier Limitations
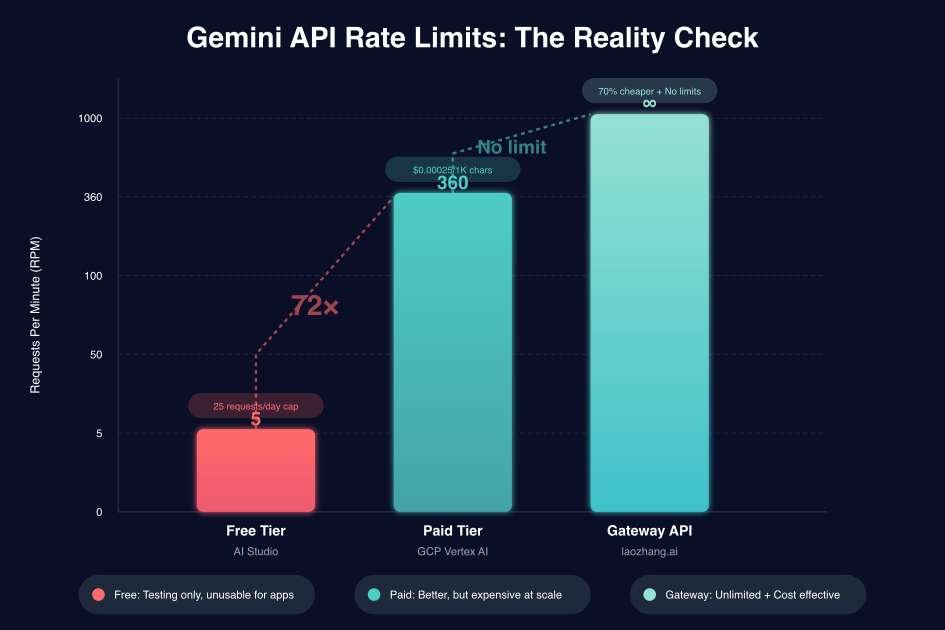
The mathematics of Gemini's free tier reveal why production deployment remains impossible. With 5 requests per minute, you can process one request every 12 seconds. Factor in network latency, processing time, and response streaming, and real-world throughput drops to approximately 3 completed requests per minute. The 25 daily request cap means you exhaust your quota in 8 minutes of continuous usage.
These limitations create cascading problems in application architecture. Implementing queuing systems to stay within limits adds complexity and latency. Users experience frustrating delays as requests stack up. Error handling becomes critical as rate limit errors occur frequently. The development experience suffers as developers constantly hit limits during testing.
Comparison with competitors highlights Gemini's restrictive approach. OpenAI's GPT-4 free tier allows 40 requests per minute—8 times more generous. Anthropic's Claude provides 5 requests per minute but no daily cap. The combination of minute and daily limits makes Gemini uniquely challenging for sustained development work.
API Key Security: Your $10,000 Protection Plan

API key security transcends best practices—it's financial survival. Leaked Gemini API keys face immediate exploitation by automated bots scanning GitHub, Stack Overflow, and public forums. These bots can generate thousands of dollars in charges within hours, and Google's terms of service hold you responsible for all usage, authorized or not.
Critical Security Implementation
Never hardcode API keys in source code, regardless of repository visibility. Modern secret scanning tools detect exposed keys, but prevention beats detection. Implement environment-based configuration with fallback mechanisms:
pythonimport os from pathlib import Path class SecureConfig: @staticmethod def get_api_key(): # Priority order for API key sources # 1. Environment variable if key := os.getenv('GEMINI_API_KEY'): return key # 2. Local secrets file (development only) secrets_file = Path.home() / '.gemini' / 'credentials' if secrets_file.exists(): return secrets_file.read_text().strip() # 3. Cloud secret manager (production) try: from google.cloud import secretmanager client = secretmanager.SecretManagerServiceClient() name = f"projects/{os.getenv('GCP_PROJECT')}/secrets/gemini-api-key/versions/latest" response = client.access_secret_version(request={"name": name}) return response.payload.data.decode('UTF-8') except: pass raise ValueError("No valid API key configuration found")
API Key Restrictions and Monitoring
Google Cloud Platform enables granular API key restrictions that significantly reduce breach impact. Configure restrictions through the credentials page:
- Application restrictions: Limit key usage to specific IP addresses for server applications or HTTP referrers for web applications
- API restrictions: Enable only the Gemini API, preventing misuse for other costly Google services
- Quota limits: Set maximum daily spending caps to limit financial exposure
Implement comprehensive monitoring to detect anomalies before they become expensive problems:
javascriptclass APIKeyMonitor { constructor(alertThreshold = 100) { this.requestCount = 0; this.alertThreshold = alertThreshold; this.startTime = Date.now(); } async trackRequest(apiCall) { this.requestCount++; // Check for unusual activity const timeElapsed = (Date.now() - this.startTime) / 1000 / 60; // minutes const rpm = this.requestCount / timeElapsed; if (rpm > this.alertThreshold) { await this.sendAlert({ message: 'Unusual API activity detected', currentRPM: rpm, totalRequests: this.requestCount }); } try { return await apiCall(); } catch (error) { if (error.status === 429) { await this.handleRateLimit(); } throw error; } } async sendAlert(details) { // Implement your alerting mechanism console.error('SECURITY ALERT:', details); // Send to monitoring service, email, Slack, etc. } }
Breaking Free: 5 Methods to Overcome Rate Limits
1. Request Optimization and Batching
Maximize each API call's value by batching multiple operations into single requests. Instead of sending individual prompts, combine related queries:
python# Inefficient: Multiple API calls responses = [] for question in questions: response = model.generate_content(question) responses.append(response) # Optimized: Single batched call batched_prompt = "Please answer the following questions:\n\n" for i, question in enumerate(questions, 1): batched_prompt += f"{i}. {question}\n" batched_prompt += "\nProvide numbered responses for each question." response = model.generate_content(batched_prompt) # Parse response to extract individual answers
2. Intelligent Response Caching
Implement smart caching to eliminate redundant API calls. Cache responses based on prompt similarity rather than exact matches:
pythonimport hashlib import json from datetime import datetime, timedelta import redis class GeminiCache: def __init__(self, redis_client, ttl_hours=24): self.redis = redis_client self.ttl = timedelta(hours=ttl_hours) def _generate_cache_key(self, prompt, model="gemini-2.5-pro"): # Create normalized cache key normalized = prompt.lower().strip() hash_object = hashlib.sha256(f"{model}:{normalized}".encode()) return f"gemini:cache:{hash_object.hexdigest()}" def get(self, prompt): key = self._generate_cache_key(prompt) cached = self.redis.get(key) if cached: return json.loads(cached) return None def set(self, prompt, response): key = self._generate_cache_key(prompt) data = { 'response': response, 'timestamp': datetime.now().isoformat(), 'prompt': prompt } self.redis.setex( key, self.ttl.total_seconds(), json.dumps(data) )
3. Multi-Account Management
For applications requiring higher throughput, implement round-robin distribution across multiple API keys:
javascriptclass MultiKeyManager { constructor(apiKeys) { this.apiKeys = apiKeys.map(key => ({ key, requestCount: 0, lastReset: Date.now(), available: true })); this.currentIndex = 0; } getNextAvailableKey() { const now = Date.now(); // Reset counters every minute this.apiKeys.forEach(keyInfo => { if (now - keyInfo.lastReset > 60000) { keyInfo.requestCount = 0; keyInfo.lastReset = now; keyInfo.available = true; } }); // Find available key using round-robin for (let i = 0; i < this.apiKeys.length; i++) { const index = (this.currentIndex + i) % this.apiKeys.length; const keyInfo = this.apiKeys[index]; if (keyInfo.available && keyInfo.requestCount < 5) { keyInfo.requestCount++; this.currentIndex = (index + 1) % this.apiKeys.length; if (keyInfo.requestCount >= 5) { keyInfo.available = false; } return keyInfo.key; } } throw new Error('All API keys exhausted'); } }
4. Asynchronous Queue Processing
Implement a sophisticated queuing system that respects rate limits while maximizing throughput:
pythonimport asyncio from collections import deque import time class RateLimitedQueue: def __init__(self, rpm_limit=5): self.queue = deque() self.rpm_limit = rpm_limit self.processing = False self.request_times = deque(maxlen=rpm_limit) async def add_request(self, prompt, callback): self.queue.append({ 'prompt': prompt, 'callback': callback, 'timestamp': time.time() }) if not self.processing: asyncio.create_task(self._process_queue()) async def _process_queue(self): self.processing = True while self.queue: current_time = time.time() # Clean old request times while self.request_times and current_time - self.request_times[0] > 60: self.request_times.popleft() # Check if we can make a request if len(self.request_times) < self.rpm_limit: request = self.queue.popleft() self.request_times.append(current_time) try: # Process request response = await self._make_api_call(request['prompt']) await request['callback'](response) except Exception as e: await request['callback'](None, error=e) else: # Wait until we can make the next request wait_time = 60 - (current_time - self.request_times[0]) + 0.1 await asyncio.sleep(wait_time) self.processing = False
5. API Gateway Services - The Ultimate Solution
While the previous methods provide incremental improvements, API gateway services eliminate rate limits entirely. Services like laozhang.ai aggregate demand across users, providing unlimited access at 70% lower costs. The implementation requires minimal code changes:
python# Traditional Gemini API (rate limited) import google.generativeai as genai genai.configure(api_key="your-limited-key") # Gateway API (unlimited) import requests class GatewayGeminiClient: def __init__(self, api_key): self.api_key = api_key self.base_url = "https://api.laozhang.ai/v1" def generate_content(self, prompt): response = requests.post( f"{self.base_url}/messages", headers={ "Authorization": f"Bearer {self.api_key}", "Content-Type": "application/json" }, json={ "model": "gemini-2.5-pro", "messages": [{"role": "user", "content": prompt}] } ) return response.json()['choices'][0]['message']['content'] # No rate limits, no queuing, no complexity client = GatewayGeminiClient("your-gateway-key") response = client.generate_content("Analyze this 1M token document...")
Cost Analysis: Direct API vs Gateway Services
The financial implications of API key choices extend beyond simple per-token pricing. Direct API access through Google Cloud incurs multiple cost components:
Direct Gemini API Costs (July 2025):
- Input: $0.00025 per 1K characters
- Output: $0.0005 per 1K characters
- Average request (2K in, 2K out): $0.0015
- 1,000 daily requests: $1.50/day or $45/month
- 10,000 daily requests: $450/month
- Additional costs: Egress bandwidth, logging, monitoring
Gateway Service Costs (70% savings):
- Flat rate: $0.0005 per request regardless of length
- 1,000 daily requests: $0.50/day or $15/month
- 10,000 daily requests: $150/month
- No additional infrastructure costs
- No rate limit management overhead
The hidden costs of direct API usage often exceed the visible per-request charges. Engineering time spent implementing rate limit handling, developing queuing systems, and managing infrastructure typically costs more than the API usage itself. Gateway services eliminate these hidden costs while providing superior reliability.
Future-Proofing Your Implementation
The July 2025 model deprecations signal Google's aggressive update cycle. Future-proof your implementation by abstracting API interactions:
pythonfrom abc import ABC, abstractmethod from typing import Dict, Any class AIProvider(ABC): @abstractmethod def generate(self, prompt: str, options: Dict[str, Any]) -> str: pass class GeminiProvider(AIProvider): def __init__(self, api_key: str): self.api_key = api_key # Implementation details def generate(self, prompt: str, options: Dict[str, Any]) -> str: # Gemini-specific implementation pass class GatewayProvider(AIProvider): def __init__(self, api_key: str): self.api_key = api_key # Implementation details def generate(self, prompt: str, options: Dict[str, Any]) -> str: # Gateway implementation supporting multiple models pass # Factory pattern for provider selection class AIProviderFactory: @staticmethod def create_provider(provider_type: str = "gateway") -> AIProvider: if provider_type == "gemini": return GeminiProvider(os.getenv("GEMINI_API_KEY")) elif provider_type == "gateway": return GatewayProvider(os.getenv("GATEWAY_API_KEY")) else: raise ValueError(f"Unknown provider: {provider_type}") # Usage remains consistent regardless of provider provider = AIProviderFactory.create_provider() response = provider.generate("Your prompt here", {"temperature": 0.7})
Taking Action: Your 24-Hour Implementation Plan
Success with Gemini API requires decisive action. Follow this timeline to move from conception to production:
Hours 0-2: Initial Setup
- Create Google AI Studio account
- Generate and secure your first API key
- Set up development environment with proper .env configuration
- Run your first successful API call
Hours 2-6: Development
- Implement basic error handling and retry logic
- Create simple caching mechanism
- Build request queuing system
- Test against rate limits
Hours 6-12: Evaluation
- Measure actual throughput vs. requirements
- Calculate projected monthly costs
- Identify rate limit bottlenecks
- Document pain points
Hours 12-24: Production Decision
- If staying with direct API: Implement multi-key rotation
- If scaling needed: Register with gateway service
- Deploy monitoring and alerting
- Launch with confidence
The choice between direct API access and gateway services ultimately depends on your scale ambitions. For proof-of-concept and personal projects, the free tier suffices despite limitations. For anything approaching production use, the 5 RPM limit makes direct access untenable. Gateway services like laozhang.ai provide the only viable path to production deployment without massive infrastructure investment.
Conclusion: Beyond the API Key
The Gemini API key represents more than authentication—it's your gateway to Google's most advanced AI capabilities. While obtaining a key takes minutes, building a production-ready implementation requires strategic thinking about rate limits, security, and scalability. The 5 RPM free tier limitation isn't a bug; it's a feature designed to push serious developers toward sustainable solutions.
Whether you choose direct API access with its complexity or gateway services with their simplicity, success lies in understanding the tradeoffs. Start with AI Studio to validate your use case, implement proper security from day one, and plan for scale before you need it. The future of AI development belongs to those who can navigate these technical and economic challenges efficiently.
Your Gemini API journey starts with a single key but doesn't end there. Make the strategic choice that aligns with your ambitions, and build something remarkable with Google's cutting-edge AI technology.