
截至 2026 年 3 月,Gemini API 的文本模型价格区间大致是:每百万输入 Token 0.10 美元到 2.00 美元,每百万输出 Token 0.40 美元到 12.00 美元。其中,Gemini 2.5 Flash-Lite 仍然是最便宜的稳定文本模型;如果你必须留在 Gemini 3 系列里,Gemini 3.1 Flash-Lite Preview 是当前最便宜的一档;而 Gemini 3.1 Pro Preview 则是当前高端文本能力的付费路线。需要特别注意的是,Pro 档模型在提示词超过 200K Token 之后会进入更高计费区间,这往往才是预算失控的真正原因。
把这页当成一份预算决策页来看:你需要先知道该把哪一档模型放进报价表、什么时候 200K 上下文阈值会改变成本曲线,以及哪些附加计费项会把实际账单推离首页那串好看的数字。这里会只保留 Gemini Developer API 这一条线,不混 Vertex、Gemini App 订阅或 Workspace 费用,并把 Batch、缓存、Grounding、音频输入和长上下文阈值这些真正会改预算的因素拆开讲清楚。
要点速览
- 最便宜的稳定文本模型:Gemini 2.5 Flash-Lite,每百万输入 Token 0.10 美元、输出 0.40 美元。
- 最便宜的 Gemini 3 文本路线:Gemini 3.1 Flash-Lite Preview,每百万输入 0.25 美元,输出 1.50 美元。
- 当前高端文本路线:Gemini 3.1 Pro Preview,在提示词不超过 200K 时,每百万输入 2.00 美元、输出 12.00 美元;超过 200K 后会上涨到 4.00 / 18.00 美元。
- 大多数生产应用的稳妥默认选择:Gemini 2.5 Flash,价格仍然明显低于 Pro,但能力比 Flash-Lite 更均衡。
- 最快的降本手段:Batch 模式。官方价格页上,主要文本模型的 Batch 价格通常约等于标准价格的 50%。
- 最常见的误判:只记住基础输入/输出价格,却忽略了长上下文阈值、音频输入、缓存计费、缓存存储费、Grounding 费用和失败请求对配额的影响。
2026 年 3 月 Gemini API Token 定价表

官方的 Gemini Developer API pricing 页面 当然是最权威的来源,但如果你只是想快速比较当前几条主流文本模型路线,它其实不够直观。下面这张表把大多数开发者当前真正会比较的模型放在一起。
| 模型 | 标准输入价格 | 标准输出价格 | Batch 输入价格 | Batch 输出价格 | 说明 |
|---|---|---|---|---|---|
| Gemini 3.1 Pro Preview | 200K 以内每百万 2.00 美元,超过 200K 为 4.00 美元 | 200K 以内 12.00 美元,超过 200K 为 18.00 美元 | 200K 以内 1.00 美元,超过 200K 为 2.00 美元 | 200K 以内 6.00 美元,超过 200K 为 9.00 美元 | 付费专用,当前高端文本路线 |
| Gemini 3 Flash Preview | 文本 / 图片 / 视频每百万 0.50 美元;音频 1.00 美元 | 3.00 美元 | 文本 / 图片 / 视频 0.25 美元;音频 0.50 美元 | 1.50 美元 | Gemini 3 快速路线,可用免费层 |
| Gemini 3.1 Flash-Lite Preview | 文本 / 图片 / 视频每百万 0.25 美元;音频 0.50 美元 | 1.50 美元 | 文本 / 图片 / 视频 0.125 美元;音频 0.25 美元 | 0.75 美元 | 当前最便宜的 Gemini 3 文本路线 |
| Gemini 2.5 Pro | 200K 以内 1.25 美元,超过 200K 为 2.50 美元 | 200K 以内 10.00 美元,超过 200K 为 15.00 美元 | 200K 以内 0.625 美元,超过 200K 为 1.25 美元 | 200K 以内 5.00 美元,超过 200K 为 7.50 美元 | 比 3.1 Pro 便宜的高推理替代 |
| Gemini 2.5 Flash | 文本 / 图片 / 视频每百万 0.30 美元;音频 1.00 美元 | 2.50 美元 | 文本 / 图片 / 视频 0.15 美元;音频 0.50 美元 | 1.25 美元 | 稳定、均衡、适合大多数生产应用 |
| Gemini 2.5 Flash-Lite | 文本 / 图片 / 视频每百万 0.10 美元;音频 0.30 美元 | 0.40 美元 | 文本 / 图片 / 视频 0.05 美元;音频 0.15 美元 | 0.20 美元 | 当前最便宜的稳定路线 |
先说两个最关键的判断。
第一,Google 现在的产品线并不是“最新的一定最便宜”或者“3 系列一定全面替代 2.5 系列”的结构。如果你追求最低稳定文本成本,Gemini 2.5 Flash-Lite 仍然最便宜;如果你必须留在 Gemini 3 家族里,Gemini 3.1 Flash-Lite Preview 才是预算档。很多第三方页面会把“Gemini 3”写成一个统一的价格带,这会掩盖真正的选择差异。
第二,老页面里仍然经常出现 Gemini 3 Pro Preview。但从 Google 当前的 models 页面 来看,它已经在 2026 年 3 月 9 日 下线,官方明确要求迁移到 Gemini 3.1 Pro Preview。如果你看到某篇文章还把 Gemini 3 Pro Preview 当作现役高端模型来比较,那么它的其它价格信息也很可能已经过时。
该为哪种 Gemini 模型做预算
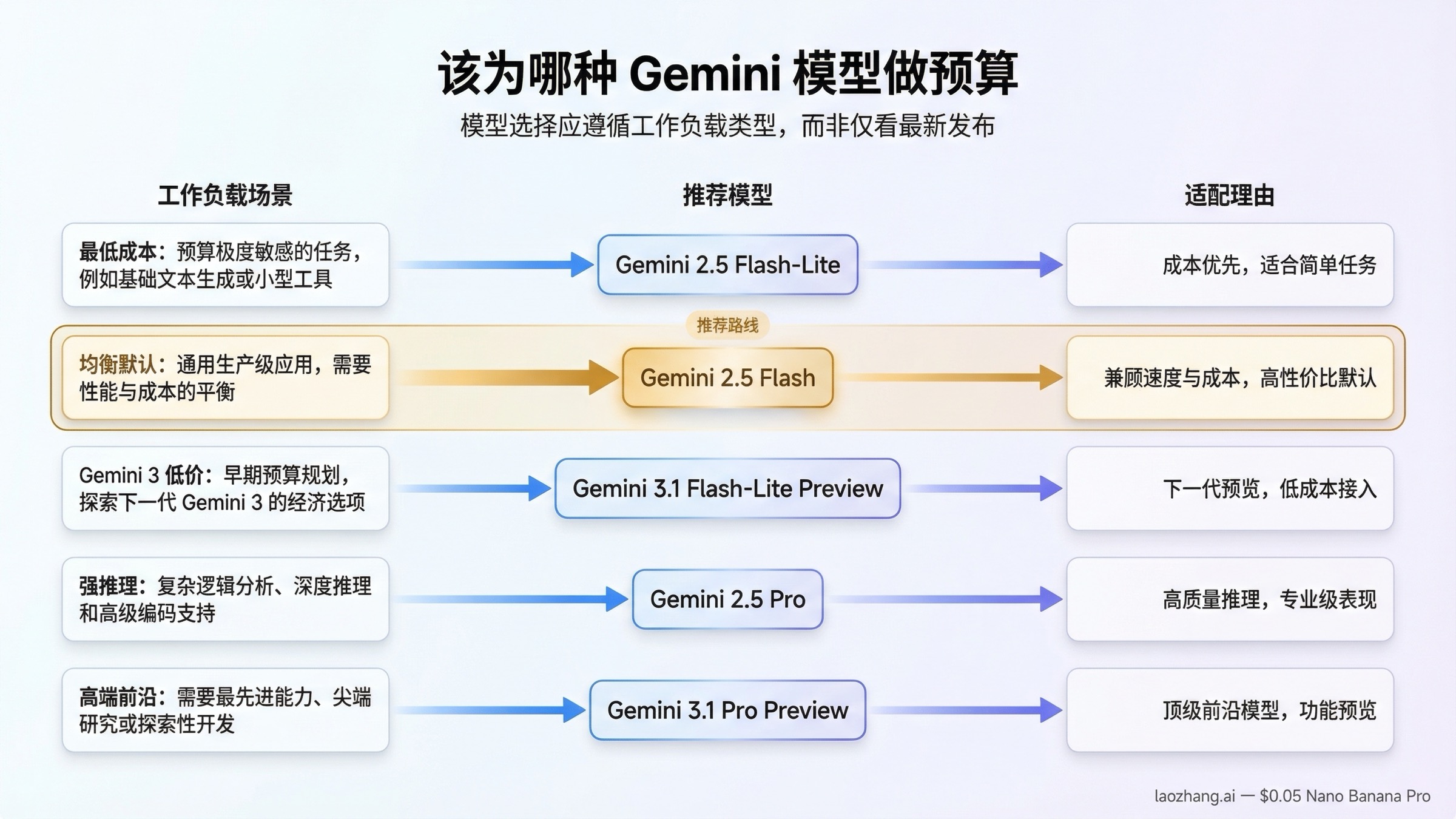
真正有用的问题并不是“哪个模型最强”,而是“哪条模型路线对我的工作负载最划算”。如果只盯着排行榜或模型新旧顺序,预算判断几乎一定会偏。
如果你的首要目标就是压低成本,Gemini 2.5 Flash-Lite 仍然是最干净的答案。它的价格足够低,非常适合分类、抽取、轻量翻译、基础路由、简单客服、批量文本处理这类任务。很多场景并不需要更高阶的推理能力,真正需要的是稳定吞吐和更低单次成本,这时 Flash-Lite 的优势非常明显。
如果你需要一条更稳妥的生产默认路线,Gemini 2.5 Flash 依然是当前最值得优先预算的一档。它比 Flash-Lite 贵一些,但远不到 Pro 的水平;而在内部 Copilot、FAQ 机器人、文档问答、基础 Agent 流程、轻量代码辅助等场景里,它通常已经足够。对于大多数还在探索产品形态的团队来说,2.5 Flash 仍然是最均衡的出发点。
如果你的组织明确希望使用 Gemini 3 家族,但又不想直接支付 Pro 的高价,那么 Gemini 3.1 Flash-Lite Preview 是当前的预算路线。它并不比 2.5 Flash-Lite 便宜,但它提供了 Gemini 3 家族中的低成本入口。这个选择更适合那些在产品规划、版本兼容或内部采购层面上,确实需要“留在 3 系列”的团队。
真正昂贵的选择,是 Gemini 2.5 Pro 和 Gemini 3.1 Pro Preview 之间的取舍。Gemini 2.5 Pro 的价格已经不低,但与 3.1 Pro 相比仍然更克制。如果你的任务是高强度代码生成、复杂长文综合、复杂 Agent 规划,2.5 Pro 往往已经能覆盖很多需求;只有在你明确确认 3.1 Pro 的推理收益能换来业务价值时,才值得承受更高的 Token 成本。
换句话说,当前 Gemini 定价不是单一阶梯,而是几条不同定位的路线并行存在:
- 最低成本:Gemini 2.5 Flash-Lite
- 稳定均衡:Gemini 2.5 Flash
- Gemini 3 预算路线:Gemini 3.1 Flash-Lite Preview
- 较强推理、但仍要看成本:Gemini 2.5 Pro
- 高端前沿路线:Gemini 3.1 Pro Preview
很多页面没有把这个判断明确说出来,于是用户只能自己对照一堆表格。更有用的做法,是先把路线说清楚,再去看精确数字,这样预算表才不会一开始就混进不属于同一条账单的费用。
如果你还处在试用期,别把 AI Studio 里的免费尝试直接当作生产成本预估。Google 的 billing FAQ 说得很明确:AI Studio 本身可以免费使用,但一旦你把付费 API key 关联到付费功能,相关使用就会进入付费逻辑。换句话说,AI Studio 的体验不能直接等价于“生产环境仍然免费”。
你的 Gemini 账单到底包含什么
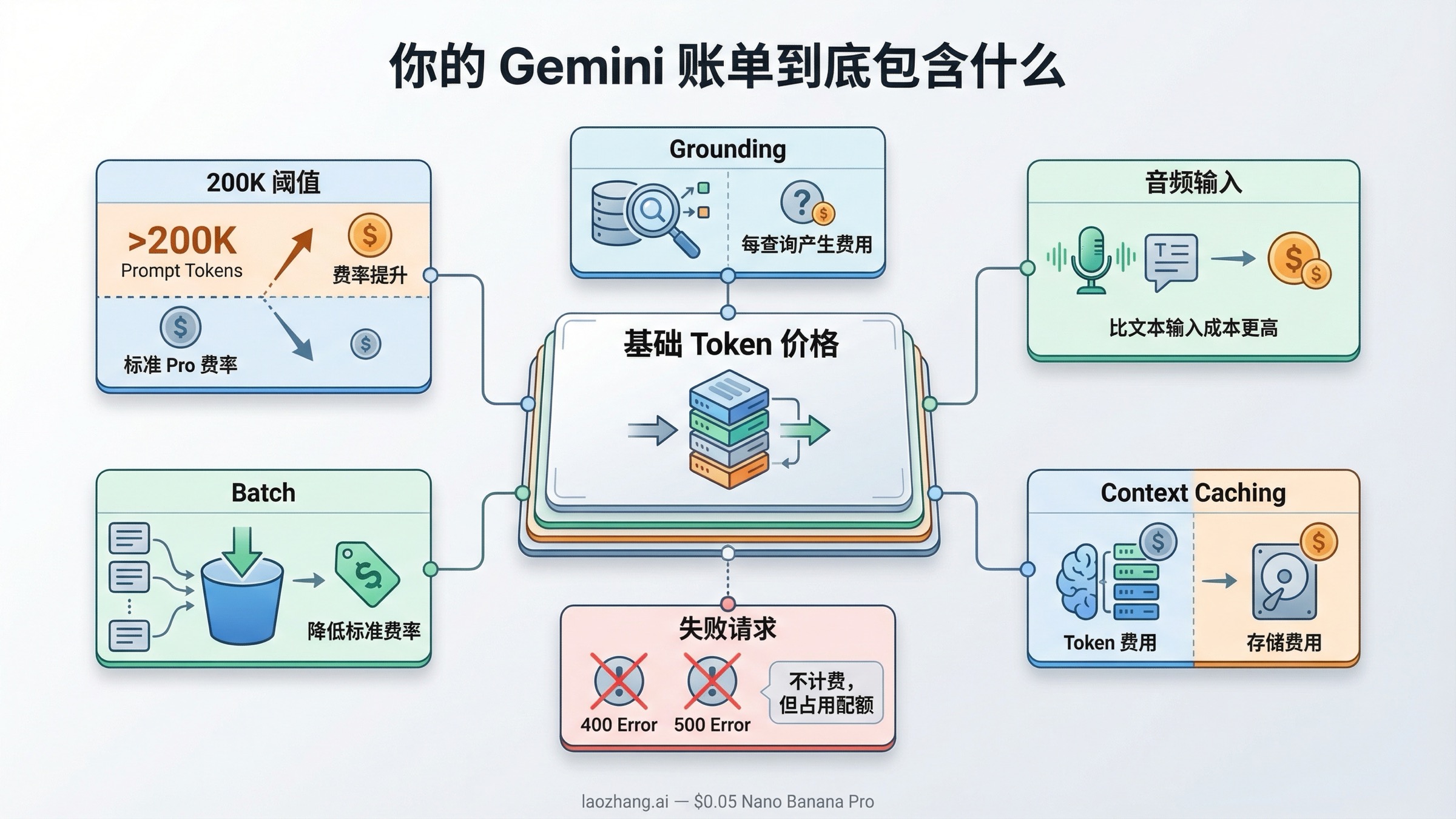
很多“Gemini 定价指南”停在价格表就结束了,但真正让预算失真的地方在计费机制本身。Google 的 billing 页面 明确写到,Gemini API 的计费基础包括 输入 Token 数量、输出 Token 数量、缓存 Token 数量 和 缓存存储时长。也就是说,你最终支付的并不只是“我发了多少字,模型回了多少字”。
理解 Token 本身也很重要。根据官方的 token 说明,对 Gemini 来说,一个 Token 大约相当于 4 个字符,100 个 Token 大约相当于 60 到 80 个英文单词。这当然不是精确计费公式,但足够帮助你建立直觉:一个短小提示词通常不会贵,真正容易让账单膨胀的是重复附带的大段系统提示、冗长上下文、工具调用痕迹,以及长文档检索结果。
更容易被忽略的是,不同类型的输入并不总是同价。某些模型上,音频输入价格高于文本输入。而在 Pro 档模型上,当单次请求的提示词超过 200K Token 之后,价格会跳到更高档位。如果你又同时用了缓存、Grounding 或多模态输入,那么“基础价格”很快就不再等于“真实账单”。
下面这张表,是大多数团队真正需要记住的“账单修正项”:
| 计费修正项 | 会发生什么 | 为什么重要 |
|---|---|---|
| Pro 模型超过 200K 提示词 | Gemini 3.1 Pro Preview 从 2.00 / 12.00 涨到 4.00 / 18.00;Gemini 2.5 Pro 从 1.25 / 10.00 涨到 2.50 / 15.00 | 长上下文任务可能比你记忆中的价格贵很多 |
| 音频输入 | Flash 和 Flash-Lite 系列通常对音频输入收更高费用 | 语音场景容易被低估预算 |
| Batch 模式 | 主要文本模型的标准价格大多能降到约一半 | 异步任务最直接的降本杠杆 |
| Context Caching | 会收缓存 Token 费用和缓存存储费 | 缓存能省钱,但不是“免费记忆” |
| Grounding | 搜索或地图 Grounding 会产生额外查询费用 | 你的账单不再只是 Token 账单 |
| 失败请求 | 400/500 请求本身不计费,但仍会消耗配额 | 出错风暴不会直接加钱,但会降低可用吞吐 |
其中最值得强调的有两个。
Batch 模式 是最容易被忽略、却往往最有效的降本方式。如果你的任务不要求实时返回,比如离线评估、批量改写、定时报告、夜间回填,那么你应该优先用 Batch 价格做预算,而不是先假设所有请求都走标准价格。很多团队花大量时间在 Prompt 微调、模型迁移或缓存设计上,但真正立刻能省下来的,往往只是把工作流改成异步批处理。
Context Caching 也是误解最多的功能之一。它确实能减少重复上下文的重复成本,但它不是“把大段 Prompt 存起来就免费”。Google 同时会对缓存 Token 和存储时长计费,因此你应该把它理解成一个成本优化工具,而不是一块免费内存。只有在你确实会频繁重用相同上下文前缀时,它才会带来很明显的收益。如果你想看更偏工程实现的拆解,可以继续看站内的 Gemini API 免费额度 2026 指南 作为配额层面的补充。
Gemini 定价为什么会突然变贵
很多人会有一种感觉:明明记得某个模型每百万 Token 很便宜,但一上线到真实工作负载,账单马上就和脑海里的数字不一样。这个落差通常来自三个地方。
第一,是 200K Prompt 阈值。只要你在 Pro 档模型上处理长文档、大型代码上下文、RAG 拼接结果或者冗长多轮对话,就很容易跨过这个界限。一旦跨过去,输入和输出价格都不再按低档计费。也正因为这样,很多听起来“应该上 Pro”的任务,最后从成本角度看,反而更适合放在 Flash 系列上,再用更好的检索与压缩策略来补足质量。
第二,是 免费层错觉。用户常常把“AI Studio 里可以试”与“API 调用本身仍然免费”混为一谈。事实上,不同模型的免费层可用性并不一样,而一旦你切换到付费项目,生产计费逻辑就会接管。把试用体验当成长期预算,是当前 Gemini 价格判断里最常见的错误之一。
第三,是 Grounding 与配额的交织。价格只是成本的一面,吞吐和可用性是另一面。Google 的 rate limits 页面 明确说明,限制是按项目而不是按 API key 生效,而且不同模型、不同 tier 的限制并不相同。一旦你真正进入生产环境,你需要考虑的不再只是“哪一行最便宜”,而是“哪一条路线能以我需要的吞吐稳定运行”。如果你的瓶颈已经变成 429,那么继续比较几毛钱的 Token 价格意义并不大。
也就是说,真正拉开成本差距的,往往不是模型价格表里的细小差别,而是模型选择、上下文长度、Batch 模式、缓存策略,以及是否过度堆叠提示词。理解这一点,比记住几组数字更重要。
Gemini Developer API、Vertex AI 和 AI Studio 的定价区别
这类定价问题之所以容易混乱,还有一个原因:很多页面会把 Gemini Developer API、Vertex AI 和 AI Studio 当成同一个东西来讨论。
但对开发者来说,这三者并不是一个计费面。
- Gemini Developer API:这是这里要先看的核心计费面,适用于直接按官方 Gemini API 页面来估算调用成本的开发者。
- Vertex AI:这是 Google Cloud 企业栈里的 Gemini 接入方式,价格逻辑大体相关,但会更明确地展示优先级、企业级吞吐、Flex / Batch 等企业部署维度。
- AI Studio:这是试验与调试界面,不应该被直接视为生产定价模型。
当前很多第三方页面为了“看起来更全面”,会把这三种接口面再加上 Gemini App 订阅、Workspace、Code Assist 等产品一起写进一篇长文。结果就是文章很长,但对“Gemini API Token 定价是多少”这个问题的帮助反而更弱。
更实用的判断规则是:
- 你在按 Gemini Developer API 定价页 计算直连调用成本,就看 Developer API 价格。
- 你实际上是走 Google Cloud 企业架构,就参考 Vertex AI pricing。
- 你只是拿 AI Studio 做实验,就不要把它直接当作长期生产预算。
在 2026 年 3 月这个时间点上,Vertex AI 和 Gemini Developer API 的主要模型价格逻辑大体是一致的,但 Vertex 更容易让人误把优先级或企业级部署价格和普通 Developer API 价格混在一起。如果第三方页面没有明确说明自己引用的是哪一个价格面,就不要轻信它给出的结论。
常见工作负载的月度成本估算
真正让价格变得有用的方法,是把它代入常见工作负载,而不是只盯着“每百万 Token 多少钱”。
场景一:小型客服机器人,使用 Gemini 2.5 Flash
假设你一个月处理 3000 万输入 Token 和 1000 万输出 Token。按 Gemini 2.5 Flash 的标准价格计算:
- 输入:30 × 0.30 = 9.00 美元
- 输出:10 × 2.50 = 25.00 美元
- 月度估算总价:34.00 美元
这就是为什么 2.5 Flash 依然是当前很强的默认选择。它没有便宜到只适合玩具项目,也没有贵到让生产试验难以承受。
场景二:高吞吐抽取或路由服务,使用 Gemini 2.5 Flash-Lite
假设你一个月处理 2 亿输入 Token 和 4000 万输出 Token:
- 输入:200 × 0.10 = 20.00 美元
- 输出:40 × 0.40 = 16.00 美元
- 月度估算总价:36.00 美元
这个例子很能说明问题:如果你的应用输出量也不少,输出价格的差异同样重要。Flash-Lite 之所以在很多高吞吐任务里有吸引力,不只是因为输入便宜,也因为输出非常便宜。
场景三:高强度代码或综合推理任务,使用 Gemini 3.1 Pro Preview
假设你一个月处理 2000 万输入 Token 和 400 万输出 Token,并且单次请求都控制在 200K 以内:
- 输入:20 × 2.00 = 40.00 美元
- 输出:4 × 12.00 = 48.00 美元
- 月度估算总价:88.00 美元
如果你把同样的工作负载放到 Gemini 2.5 Pro:
- 输入:20 × 1.25 = 25.00 美元
- 输出:4 × 10.00 = 40.00 美元
- 月度估算总价:65.00 美元
也就是说,3.1 Pro 的高端溢价是实打实存在的,并不是一个可以忽略的小差价。对于还在产品验证期的团队来说,这个差价是否值得,一定要靠效果验证,而不是仅凭“最新模型更强”来假设。
场景四:异步回填任务,使用 Batch 模式
如果还是场景一,但把请求改成 Batch 模式:
- 输入:30 × 0.15 = 4.50 美元
- 输出:10 × 1.25 = 12.50 美元
- 月度估算总价:17.00 美元
这比标准模式几乎直接减半。很多团队会把优化精力放在迁移供应商、压缩 Prompt 或复杂缓存策略上,但从“立刻省钱”的角度看,先判断任务能不能异步化,通常更有效。
如果你当前还主要关心免费测试和额度问题,继续看站内的 Gemini API 免费额度 2026 指南 会更有帮助。如果只压缩成一句预算判断,就是:
Gemini API Token 定价真正要回答的不是“价格是多少”,而是“我该走哪条模型路线,以及哪些计费修正项会改变最终数字”。 一旦这个问题想清楚了,Google 当前这套看起来复杂的定价体系就会好理解得多。