Claude Code 的速率限制分为两种完全不同的类型,混淆它们是开发者在错误方向上浪费时间的头号原因。无论你看到的是 Pro 计划上模糊的"使用限制已达上限"提示,还是来自 API 的精确 HTTP 429 错误,本指南都将帮助你准确定位瓶颈所在,采取正确的解决方案,并养成防止限制中断工作流的好习惯。
要点速览
Claude Code 执行两套独立的限制系统:订阅配额(Pro 和 Max 计划上的 5 小时滚动窗口,与 Claude.ai 共享)和 API 速率限制(基于消费层级的每分钟 RPM/ITPM/OTPM 上限)。订阅限制最快的修复方法是等待 5 小时重置或升级到 Max。API 限制的解决方案包括实现指数退避、使用 prompt caching 将有效 token 消耗降低最多 80%,或者通过第三方 API 服务(如 laozhang.ai)路由请求——按 token 计费且无每分钟上限。
Claude Code 为什么会触发速率限制?(两套独立系统)
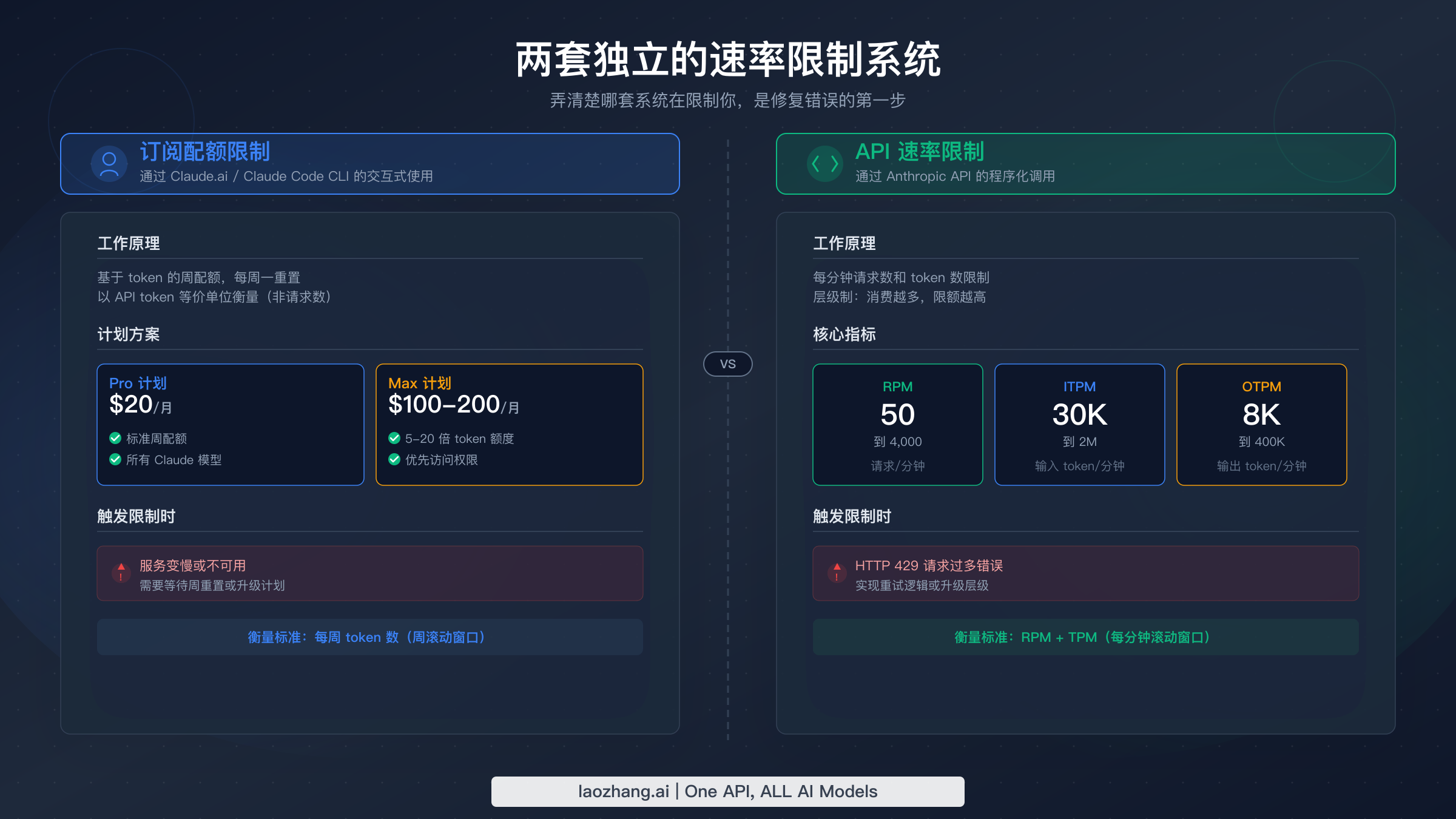
理解 Claude Code 速率限制最关键的一点是:存在两套完全独立的系统控制着你的使用量。网上大多数排查指南把这两套系统混为一谈,导致开发者陷入无效的排查路径,白白浪费宝贵的编码时间。搞清楚哪套系统在限制你,直接决定了解决方案是五秒钟还是五分钟的事。
系统一 — 订阅配额 适用于通过付费计划使用 Claude Code 的情况(Pro 每月 $20,Max 5x 每月 $100,Max 20x 每月 $200,数据来源于 Anthropic 定价页面,2026 年 3 月验证)。这些配额通过 5 小时滚动窗口衡量你的总使用量,且在 Claude.ai 聊天和 Claude Code 之间共享。当订阅配额耗尽时,Claude Code 会显示"usage limit reached"或"you've reached your limit for now"之类的软提示,而不是标准的 HTTP 错误码。这里有个关键细节:越重的模型消耗配额越快——对于相同长度的对话,Opus 4.6 消耗的资源大约是 Sonnet 4.6 的五倍。这解释了为什么默认使用 Opus 的 Max 计划用户会出乎意料地快速触发限制。
系统二 — API 速率限制 在你(或代你运行的工具)直接调用 Anthropic Messages API 时生效。这些限制以每分钟请求数(RPM)、每分钟输入 token 数(ITPM)和每分钟输出 token 数(OTPM)来衡量。它们与你的 API 组织消费层级挂钩,而非订阅计划,超限时会返回标准的 HTTP 429 响应码和 retry-after 头。API 使用 token 桶算法(详见 Anthropic 速率限制文档,2026 年 3 月验证),这意味着容量是持续补充的,而非在固定时间点重置。
这两套系统独立运行。你的 API 速率限制可能完全充裕,但订阅配额已经耗尽,反之亦然。一个刚从 Pro 升级到 Max 5x 的开发者可能发现订阅限制消失了,却碰上了 API 层级的 ITPM 上限——因为 Claude Code 的多轮对话会将系统提示、文件内容和工具调用 token 打包到每个请求中。如果你想了解 Claude Code 免费版在这套体系中的定位,免费计划在两个维度上的限制都更紧。
订阅速率限制 — Pro、Max 5x 和 Max 20x 配额详解
订阅限制是大多数 Claude Code 用户最先遇到的,因为每个付费计划都包含 Claude Code 访问权限,且配额在所有 Claude 产品之间共享。2025 年 8 月 28 日 Anthropic 引入周配额时——这一变化被 TechCrunch 等媒体广泛报道——开发者社区的工作模式发生了显著转变,不再能像之前那样无节制地依赖 Claude Code 进行长时间编码。
下表汇总了个人用户当前的订阅层级(数据来源于 claude.com/pricing 及第三方报告,2026 年 3 月验证):
| 计划 | 月费 | 约消息数 / 5 小时 | 可用模型 | 自动降级阈值 |
|---|---|---|---|---|
| Free | $0 | 非常有限(随需求波动) | Sonnet, Haiku | 无 |
| Pro | $20(年付 $17/月) | 约 45 条消息 | Sonnet 4.6 | 无 |
| Max 5x | $100 | 约 225 条消息(5 倍 Pro) | Sonnet 4.6, Opus 4.6 | Opus 在 20% 用量时降级为 Sonnet |
| Max 20x | $200 | 约 900 条消息(20 倍 Pro) | Sonnet 4.6, Opus 4.6 | Opus 在 50% 用量时降级为 Sonnet |
有几个关键细节直接影响这些限制的实际体验。首先,"消息"指标是近似值,因为每次交互的 token 占用量差异极大——取决于你的代码库上下文大小、拉入对话的文件数量,以及 Claude Code 是否执行了文件读取或 bash 命令等工具调用。一个关于单个文件的简单问题可能只消耗一个"消息单位",而一个涉及数十个文件的复杂重构任务可能在一次交互中消耗相当于十条或更多消息的资源。
其次,Max 计划的自动降级行为既是福音也是困扰。当你的 Opus 使用量达到阈值(Max 5x 为 20%,Max 20x 为 50%)时,Claude Code 会自动切换到 Sonnet。这可以为较轻量的工作保留剩余配额,但当模型推理质量在会话中间明显下降时,体验会非常突兀。你可以用 /model 命令强制切换回去,但这样会更快地耗尽剩余配额。
第三点经常让用户措手不及:你的订阅配额在 Claude.ai 网页聊天和 Claude Code 之间共享。如果你上午花了很长时间在 Claude.ai 界面进行对话,下午的 Claude Code 配额就会相应减少。那些既做研究(通过聊天)又做开发(通过 Claude Code)的团队成员往往会以惨痛的方式发现这一点。
2026 年 1 月的争议值得仔细分析,因为它揭示了订阅限制如何在技术上按设计运行的同时让人感觉不可预测。Anthropic 在 2025 年 12 月 25 日至 31 日的假日促销期间将使用限制翻倍后,许多用户反映在 1 月 1 日正常配额恢复时感觉限制大约收紧了 60%。Anthropic 澄清说限制只是恢复到标准基线,但这种对比让正常限制显得格外紧缩——这一现象在 Reddit、Hacker News 和 Discord 的开发者社区中引发了广泛讨论。
情况因 2026 年 2 月的一个 Hacker News 帖子而更加复杂化,该帖子报告了速率限制在没有对应使用量的情况下被触发的案例。虽然 Anthropic 表示未能发现 token 消耗的 bug,但社区记录了多个场景——Claude Code 的后台操作,如自动对话索引、上下文窗口管理和工具调用开销,消耗了用户未明确授权的 token。这凸显了 Claude Code 的一个重要特性:与你能控制每个 token 的简单 API 调用不同,Claude Code 的智能体行为意味着工具本身会通过系统提示、文件读取和内部推理步骤产生大量 token 开销,这些都会计入你的配额消耗,却不会作为可见的"消息"出现在终端中。
理解这种隐性 token 消耗是有效管理订阅限制的关键。单次 Claude Code 交互在终端中看起来只是一次对话,实际上可能涉及多个内部 API 调用——读取文件、执行命令、搜索代码库——每一个都在消耗你的配额。这就是为什么 Pro 用户"每 5 小时约 45 条消息"的指标会让人感觉严重失准:一个复杂的编码任务可能在用户看来只是一次交互,却消耗了相当于 15 条"消息"的 token。
API 速率限制 — 按层级划分的 RPM、ITPM 和 OTPM

API 速率限制管控的是对 Anthropic Messages API 的直接调用,按照累计充值金额分为四个层级。与订阅配额不同,这些限制有精确定义,并返回你的代码可以程序化处理的结构化错误响应。更详细的层级分解可参阅 Claude API 配额层级与限制完整指南。
以下是最常用模型的当前各层级 API 速率限制(数据来源于 platform.claude.com/docs/en/api/rate-limits,2026 年 3 月验证):
| 模型 | Tier 1(RPM / ITPM / OTPM) | Tier 2 | Tier 3 | Tier 4 |
|---|---|---|---|---|
| Sonnet 4.x | 50 / 30K / 8K | 1,000 / 450K / 90K | 2,000 / 800K / 160K | 4,000 / 2M / 400K |
| Opus 4.x | 50 / 30K / 8K | 1,000 / 450K / 90K | 2,000 / 800K / 160K | 4,000 / 2M / 400K |
| Haiku 4.5 | 50 / 50K / 10K | 1,000 / 450K / 90K | 2,000 / 1M / 200K | 4,000 / 4M / 800K |
升级层级需要累计充值:Tier 1 为 $5,Tier 2 为 $40,Tier 3 为 $200,Tier 4 为 $400。每个层级还有月度消费上限——分别为 $100、$500、$1,000 和 $200,000——作为额外的安全护栏。
Anthropic 速率限制中最强大但最少被理解的特性之一是缓存感知 ITPM。对于大多数当前模型,缓存的输入 token 不计入你的 ITPM 速率限制。这意味着如果你通过有效使用 prompt caching 实现了 80% 的缓存命中率,实际上可以处理五倍于名义 token 限制的吞吐量。以 Tier 4 的 ITPM 限制 2,000,000 为例,优化缓存后的有效吞吐量可达每分钟 10,000,000 个输入 token。更详细的实现指南请参阅 Claude API prompt caching 指南。
token 桶算法值得特别关注,因为它影响突发行为。与每分钟简单重置的计数器不同,token 桶以稳定速率持续补充至最大限制。这意味着 60 RPM 的速率可能被强制执行为大约每秒 1 个请求——超过这个瞬时速率的短时突发可能触发 429 错误,即使你在完整一分钟内的平均使用量低于限制。在循环中快速连续发送请求的开发者特别容易遇到这种情况。
速率限制在组织级别生效,而非按 API 密钥。如果你的组织有多个项目或团队成员共享同一 API 账户,他们的请求都从同一个池中扣减。这就是为什么 429 错误有时会在你的单个应用看似只发出少量请求时出现——其他团队成员的工作负载可能在消耗共享容量。对于团队而言,Anthropic 提供了工作空间级别的限制配置:组织管理员可以将总容量的一部分分配给每个工作空间,防止任何单个项目垄断整个组织的速率限制预算。例如,如果你的组织在 Sonnet 上有 Tier 3 的 800,000 ITPM 限制,你可以将 500,000 分配给生产工作空间、300,000 分配给开发环境,确保开发实验不会饿死生产系统。
这些 API 限制对 Claude Code 使用的实际影响在很大程度上取决于配置方式。当 Claude Code 通过你的订阅运行(Pro 和 Max 计划的默认模式)时,它使用 Anthropic 的内部基础设施和你的订阅配额——而非你的 API 层级限制。但当你配置 Claude Code 使用自己的 API 密钥(通过环境变量或 --api-key 参数)时,它就会切换为使用 API 层级限制而非订阅配额。这个区别对高级用户至关重要:如果你有一个 Tier 4 API 账户(月度消费上限 $200,000),配置 Claude Code 使用你的 API 密钥可以获得远超 Max 20x 订阅计划的吞吐量,代价是按 token 付费而非固定月费。
另外值得注意的是,Anthropic 最近为 Opus 4.6 推出了 fast mode,它有独立于标准 Opus 限制的专用速率限制。如果你正在使用 fast mode 的研究预览版,可能会遇到与标准 Opus 分配不同的速率限制错误。fast mode 的响应头使用 anthropic-fast-* 前缀而非标准的 anthropic-ratelimit-* 前缀,因此如果你同时使用 fast mode 和标准推理,监控代码需要检查两组头信息。
如何判断你触发了哪种速率限制
正确诊断是哪套速率限制系统在限制你,是采取正确修复措施的关键第一步。两者的症状差异足够明显,只要你知道该看什么,通常几秒钟内就能锁定原因。
订阅限制的特征相对非正式。Claude Code 会在终端中显示"Usage limit reached"或"You've run out of messages for now — please wait"之类的消息。没有 HTTP 状态码,因为限制是在应用层面、API 调用发起之前就被拦截的。Claude.ai 网页界面可能还会显示一个倒计时器,指示你的 5 小时窗口何时重置——这个计时器同样适用于 Claude Code,因为配额是共享的。
API 速率限制的特征是精确且机器可读的。你会收到一个 HTTP 429 响应,JSON 错误体会指明超出了哪种限制(请求数、输入 token 还是输出 token)。响应包含 retry-after 头,精确告诉你需要等待多少秒。此外,每个成功的 API 响应都包含一组速率限制头,让你可以实时监控剩余容量:
pythonimport anthropic client = anthropic.Anthropic() try: response = client.messages.create( model="claude-sonnet-4-6-20250514", max_tokens=1024, messages=[{"role": "user", "content": "Hello"}] ) # 从响应头检查剩余容量 print(f"剩余请求数: {response.headers.get('anthropic-ratelimit-requests-remaining')}") print(f"剩余输入 token: {response.headers.get('anthropic-ratelimit-input-tokens-remaining')}") print(f"剩余输出 token: {response.headers.get('anthropic-ratelimit-output-tokens-remaining')}") print(f"重置时间: {response.headers.get('anthropic-ratelimit-requests-reset')}") except anthropic.RateLimitError as e: print(f"被限流了!等待: {e.response.headers.get('retry-after')} 秒") print(f"错误详情: {e.message}")
还有第三种较少见但值得了解的情况:加速限制。即使你在名义的 RPM 和 TPM 上限之内,Anthropic API 也会对使用量的急剧飙升施加加速限制。如果你的组织流量在短时间内大幅跳增——例如在几分钟内从零请求增长到数百——你可能在达到公布的速率限制之前就收到 429 错误。解决方案是逐步增加流量,而不是突发大量请求。这种行为对于在构建流程开始时同时启动多个 Claude Code 实例的 CI/CD 管道尤为相关。
如果你不确定触发的是订阅限制还是 API 限制,按以下三个信号依次检查。第一,看错误格式——如果是 Claude Code 终端中的对话式消息而非结构化的 HTTP 错误,那就是订阅限制。第二,检查 Claude.ai 网页界面——如果那里也显示使用限制提示,说明订阅配额已耗尽。第三,检查 API 响应头——如果显示剩余 token 或请求数为零,说明触发了 API 速率限制。关于 429 错误的更多排查模式,我们的 Claude API 429 速率限制错误修复指南涵盖了更多边缘情况。
8 种经过验证的"速率限制已达上限"修复方案
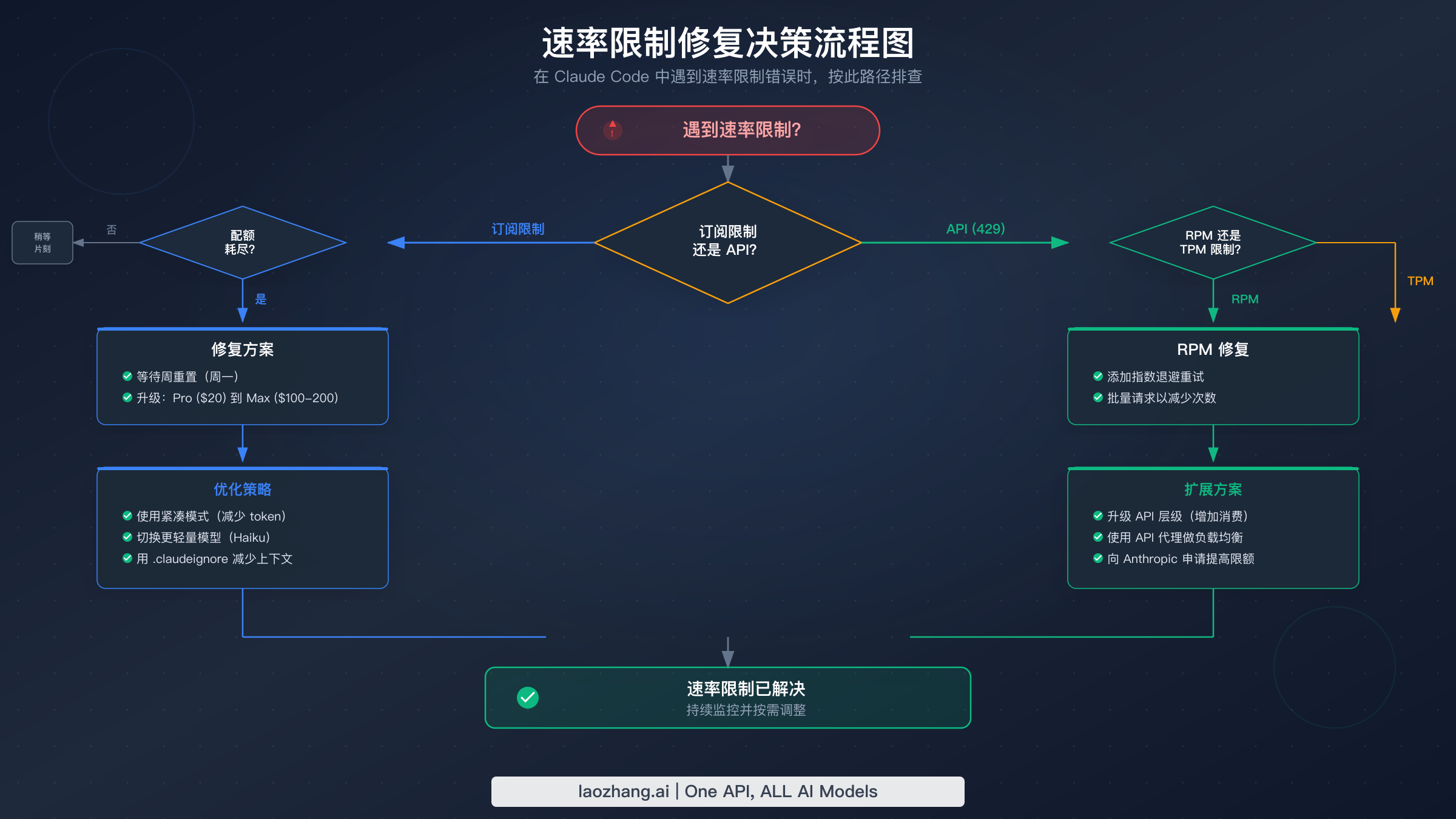
触发速率限制后,正确的修复方案取决于哪套系统触发了它,以及你恢复工作的紧迫程度。以下八种策略按从最快的临时缓解到最可持续的长期方案排列。
方案 1:等待滚动窗口重置。 对于订阅限制,5 小时滚动窗口意味着你的容量会随着旧的使用量过期而逐步恢复。你不需要等满五小时——即使 30 到 60 分钟的不活跃通常也能释放足够的配额进行几次交互。对于 API 速率限制,token 桶持续补充,因此只需等待 retry-after 头中指定的秒数通常就够了。
方案 2:切换到更轻量的模型。 如果你正在使用 Opus 4.6 并触发了订阅限制,用 /model 命令切换到 Sonnet 4.6 可以立即让你从相同的剩余配额中获得约五倍的交互次数。Sonnet 能够高效处理绝大多数编码任务,对于文件编辑、测试编写和代码导航等常规操作,质量差异可以忽略不计。将 Opus 保留给真正需要更深层推理的任务,如复杂的架构决策或隐蔽的 bug 排查。
方案 3:减少对话上下文大小。 Claude Code 会将系统提示、对话历史、文件内容和工具调用 token 打包到每个请求中。使用 /clear 开始新对话或关闭重新打开 Claude Code 可以消除累积的历史 token,减少每个请求的体积。有策略地选择让 Claude Code 读取哪些文件——当你只需要特定文件时,避免加载整个目录。
方案 4:为 API 限制实现指数退避。 对于程序化的 API 访问,带抖动的指数退避是行业标准方法。以下是一个生产级实现:
pythonimport time import random import anthropic def call_with_backoff(client, max_retries=5, **kwargs): """使用指数退避调用 Anthropic API,处理速率限制错误。""" for attempt in range(max_retries): try: return client.messages.create(**kwargs) except anthropic.RateLimitError as e: retry_after = int(e.response.headers.get("retry-after", 2 ** attempt)) wait_time = retry_after + random.uniform(0, 1) print(f"被限流,等待 {wait_time:.1f} 秒(第 {attempt + 1}/{max_retries} 次重试)") time.sleep(wait_time) raise Exception(f"重试 {max_retries} 次后仍然失败") client = anthropic.Anthropic() response = call_with_backoff( client, model="claude-sonnet-4-6-20250514", max_tokens=2048, messages=[{"role": "user", "content": "分析这段代码中的 bug..."}] )
方案 5:启用并优化 prompt caching。 由于缓存的输入 token 在大多数当前 Claude 模型上不计入 ITPM 限制,有效的缓存可以将你的有效吞吐量提升五倍甚至更多。将系统指令、大型上下文文档和工具定义放在消息的开头,并设置缓存控制断点。在 Claude Console 的 Usage 页面监控缓存命中率,目标是 70% 或更高。
方案 6:将请求分散到多个模型端点。 因为 API 速率限制对每个模型类别分别计算,你可以同时使用 Sonnet 和 Haiku 各自的限制额度。将代码格式化、文档生成和基础补全等简单任务路由到 Haiku 4.5,将更复杂的推理任务保留给 Sonnet 4.6。这在不升级层级的情况下有效地将总吞吐量翻倍甚至三倍。
方案 7:升级你的计划或 API 层级。 如果你持续触发限制,升级可能是最具性价比的解决方案。从 Pro($20/月)升级到 Max 5x($100/月)可以获得五倍的订阅配额和 Opus 访问权限。在 API 方面,从 Tier 1 升级到 Tier 2 只需 $40 的累计充值,却能解锁 20 倍的 RPM 提升(50 到 1,000)和 15 倍的 Sonnet ITPM 提升(30K 到 450K)。
方案 8:通过第三方 API 服务路由。 对于经常触发订阅限制且希望获得 API 级灵活性而无需管理层级升级的开发者,第三方 API 路由服务提供了一条替代路径。laozhang.ai 等服务通过 OpenAI 兼容的端点提供 Claude 模型访问,按消耗的 token 计费且没有每分钟速率上限。这种方式完全绕过了订阅配额,因为你发出的是直接 API 调用而非使用 Claude Code 订阅,而且路由服务会在多个 API 密钥之间进行负载均衡以避免单组织限制。
使用第三方 API 路由绕过订阅限制
当订阅配额成为持续性瓶颈时,配置 Claude Code 使用第三方 API 端点可以从根本上改变你的体验。你不再面对在密集编码会话中耗尽的固定月度配额,而是只为实际消耗的 token 付费——这意味着你的有效限制是预算而非任意的使用上限。
核心思路很简单:Claude Code 可以被配置为向任何实现了 Anthropic Messages API 格式的端点发送 API 请求。像 laozhang.ai 这样的第三方路由服务接收这些请求,转发到 Anthropic 的基础设施(或等效的模型提供商),并按 token 计费,费率与直接 API 定价相当。由于这些服务通常维护着跨多个组织的 API 密钥池,制约单个开发者的单组织速率限制被分散到了更大的容量池中。
以下是如何配置 Claude Code 使用替代 API 端点,并在路由服务不可用时自动回退到官方 API:
pythonimport os import anthropic # 备选:直接 Anthropic API(受层级速率限制) ENDPOINTS = [ { "base_url": "https://api.laozhang.ai/v1", "api_key": os.environ.get("LAOZHANG_API_KEY"), "name": "laozhang.ai 路由" }, { "base_url": "https://api.anthropic.com", "api_key": os.environ.get("ANTHROPIC_API_KEY"), "name": "Anthropic 直连" } ] def create_message_with_fallback(messages, model="claude-sonnet-4-6-20250514", max_tokens=4096): """依次尝试每个端点,遇到速率限制错误时自动切换。""" for endpoint in ENDPOINTS: if not endpoint["api_key"]: continue try: client = anthropic.Anthropic( base_url=endpoint["base_url"], api_key=endpoint["api_key"] ) response = client.messages.create( model=model, max_tokens=max_tokens, messages=messages ) print(f"通过 {endpoint['name']} 成功") return response except anthropic.RateLimitError: print(f"在 {endpoint['name']} 被限流,尝试下一个...") continue except Exception as e: print(f"{endpoint['name']} 出错: {e},尝试下一个...") continue raise Exception("所有端点均已耗尽")
对于 Claude Code CLI,你可以在启动会话前设置环境变量 ANTHROPIC_BASE_URL 指向你的路由服务。这会将 Claude Code 的所有 API 调用重定向到替代端点,无需修改任何配置文件。权衡之处在于成本透明度——你需要手动监控每个 token 的支出,而非依赖可预测的月度订阅上限。
这种方案最适合使用模式不可预测的开发者:有些天你几乎不碰 Claude Code,另一些天你可能花八小时进行密集的结对编程。按 token 付费的模式让成本与实际消耗对齐,而不是被迫选择一个在清闲日浪费钱、在忙碌日被限流的层级。
在评估第三方路由服务时,有几个重要因素需要考虑。首先,验证该服务是否支持你需要的特定 Claude 模型——一些路由提供商只提供 Sonnet,而其他的提供包括 Opus 和 Haiku 在内的完整模型阵容。其次,了解延迟影响——通过中间商路由会增加少量网络开销,通常为每个请求 50-200ms,这对 Claude Code 的交互式工作流可以忽略不计,但对延迟敏感的批量处理需要了解。第三,检查该服务是否支持流式响应,这是 Claude Code 实时输出显示所依赖的。第四,仔细评估定价——虽然按 token 的成本可能与直接 API 定价相当,一些服务会加价或收取最低月费。最好的路由服务提供透明的按 token 定价,与 Anthropic 官方费率接近,同时提供池化速率限制和跨多个 API 组织的自动故障转移。
对于考虑大规模采用这种方案的团队,值得进行为期一周的对比:跟踪你当前计划的实际 token 消耗量,计算同样的使用量通过路由服务的成本,并比较金钱成本和不触发速率限制带来的生产力提升。许多团队发现 token 成本与订阅费相当,但消除速率限制中断带来的可衡量生产力改善足以证明切换的合理性。
高频 Claude Code 用户的预防策略
处理速率限制最有效的方式是从一开始就不要触发它们。以下策略来源于对数千次 Claude Code 会话的模式观察以及 Claude Code 文档中的官方建议。
策略 1:构建最小化上下文膨胀的对话结构。 Claude Code 的每次交互都会携带累积的对话历史,这意味着 token 消耗随每次交流增长。频繁开始新对话,而不是进行马拉松式的长会话。需要在长任务中保持上下文时,使用 /compact 命令来总结和压缩对话历史。明确指定 Claude Code 应该读取哪些文件——当你只需要三个特定文件时,避免使用"查看整个 src 目录"这样的宽泛命令。
策略 2:有策略地使用模型路由。 不是每个任务都需要最强大的模型。建立一个心理分类系统:用 Haiku 做快速文件查找、格式化和简单编辑;用 Sonnet 做标准编码任务、调试和测试生成;只有在复杂的架构推理、隐蔽的 bug 或 Sonnet 持续犯错的任务上才用 Opus。在 Max 计划上,关注你的 Opus 消耗量,在自动降级阈值触发之前主动切换到 Sonnet,因为主动切换让你控制时机,而自动降级可能发生在工作流的关键节点。
策略 3:批量处理相关操作。 不要发送五个单独请求来编辑五个文件,而是在一个提示中描述所有五个编辑。Claude Code 高效处理多文件操作,每个批次只计入你订阅配额中的一次交互而非五次。同样,审查代码时,在一个提示中提出所有问题,而不是逐个发送。这种方法还能产生更好的结果,因为 Claude 可以考虑你问题之间的关联性,而非孤立回答。
策略 4:主动监控使用量。 对于 API 使用,检查每个响应的速率限制头,了解在触发限制之前还剩多少容量。对于订阅配额,Claude.ai 界面显示当前使用水平。一些开发者构建了简单的仪表板来跟踪 API 消耗模式,并在使用量达到层级限制的 70% 时发送告警,给他们留出在中断发生前调整工作流的时间。Claude Console Usage 页面提供的图表展示了每小时最大 token 速率和速率限制上限的对比,这对理解消耗模式非常有价值。
策略 5:在基础设施层面实施 prompt caching。 如果你在 Claude API 之上构建应用,让 prompt caching 成为架构级别的核心关注点,而非事后想法。将静态内容(系统提示、工具定义、大型参考文档)放在每个请求的开头,并设置适当的缓存断点。80% 的缓存命中率可以使有效 ITPM 容量提升五倍,相当于免费升级两个完整层级。实现高缓存命中率的关键在于请求结构的一致性——如果系统提示和工具定义在各请求间完全相同,它们就能完美缓存。即使前缀内容的微小变化也可能使缓存失效,因此标准化你的提示模板并有策略地使用缓存断点。
策略 6:在非高峰时段安排重型工作负载。 虽然 Anthropic 没有正式公布按时段划分的使用数据,但社区观察一致报告在北美非高峰时段(大约太平洋时间凌晨 2 点到上午 8 点)速率限制感觉更宽松。这很可能是因为平台整体负载较低时 token 桶补充更快,竞争同一基础设施容量的请求更少。如果你有不需要实时交互的批量工作——如生成文档、对 Claude 运行大型测试套件或处理代码审查——将这些任务安排在非高峰时段可以减少速率限制中断的频率。
策略 7:为非交互式工作负载使用 Batch API。 对于不需要即时响应的任务,Message Batches API 提供了一条专用路径,拥有独立于实时 API 的速率限制。批处理请求在 Tier 1 最多可排队 100,000 个项目(Tier 4 为 500,000),且批处理的成本比标准 API 定价低 50%。这使其非常适合代码库级别的文档生成、大规模代码审查或数据提取等批量操作——你可以一次性提交所有请求,稍后收集结果。批处理队列限制足够大,大多数开发者永远不会触及,实际上为异步工作提供了无限吞吐量。
常见问题解答
为什么 Max 计划只显示 16% 使用量就触发了速率限制?
Claude 界面显示的使用百分比衡量的是整体配额消耗,但速率限制也可能由更短时间窗口内的突发模式触发。如果你在短时间内连续发送一组复杂请求,即使 5 小时总配额还有大量余额,也可能超出每分钟吞吐限制。此外,Opus 4.6 每次交互消耗的资源约为 Sonnet 4.6 的五倍,因此 Max 5x 配额的 16% 如果全部用在 Opus 上,代表的 token 交换量比百分比显示的要大得多。使用量仪表的百分比计算方式也存在常见误解——它反映的是考虑了模型复杂度的加权平均值,这意味着十次 Opus 对话可能显示 16%,而消耗的原始算力等于八十次 Sonnet 对话。
订阅限制和 API 限制有什么区别?
订阅限制是 Claude Pro 或 Max 计划的一部分,在 5 小时滚动窗口内生效,在 Claude.ai 和 Claude Code 之间共享,并产生对话式的"usage limit reached"消息。API 速率限制与你组织的消费层级挂钩(累计充值 $5 到 $400+),以每分钟 RPM/ITPM/OTPM 衡量,返回带结构化头的 HTTP 429,且仅适用于直接 API 调用。两套系统完全独立——你可以耗尽一个而另一个仍有充足容量。可以把订阅限制想象成有访客上限的月度健身房会员,而 API 限制是按次收费但有入场速度限制的设施。
清除对话历史有助于缓解速率限制吗?
对未来的请求有帮助——用 /clear 清除历史可以减少后续交互的 token 体积,因为每次 API 调用中打包的上下文更少了。但它不会追溯恢复已经消耗的配额。之前对话中使用的 token 已经计入了你的限制。清除历史是一种预防策略而非追溯修复。话虽如此,影响可以很显著:一个有 50 次来回交流的对话可能在每个后续请求中携带 100,000+ 个 token 的历史。清除这些历史重新开始可以将每个请求的 token 消耗减少 80% 或更多,这直接转化为更慢的配额耗尽速度。
我可以使用不同的 API 端点来避免限制吗?
可以。将 ANTHROPIC_BASE_URL 设置为第三方路由服务会将 Claude Code 的 API 调用重定向到具有不同速率限制策略的替代端点。laozhang.ai 等服务跨多个 API 组织池化容量,有效提供比单个 Tier 1 或 Tier 2 账户更高的每分钟吞吐量。代价是按消耗的 token 付费而非固定月度配额。这种方案对使用量日间波动极大的开发者特别有价值——有些天零使用,其他天十二小时马拉松会话——因为按 token 付费的模式让成本与实际消耗对齐,而不需要为高峰日预留订阅余量。
速率限制重置需要多长时间?
对于订阅配额,5 小时滚动窗口意味着容量会随着旧交互过期而逐步恢复——你不需要等满五小时。实际上,大多数用户发现 30 到 60 分钟的不活跃就能释放足够的配额进行多次交互,而且更轻量的模型恢复配额更快,因为它们消耗的更少。对于 API 速率限制,token 桶持续补充。429 响应上的 retry-after 头精确告诉你需要等待多少秒,通常在 1 到 60 秒之间,取决于你超限的程度。加速限制(由突然的使用量飙升触发)可能需要更长的几分钟冷却期。
有没有办法在触发限制之前检查当前使用量?
对于 API 使用,检查每个成功请求的响应头——anthropic-ratelimit-requests-remaining、anthropic-ratelimit-input-tokens-remaining 和 anthropic-ratelimit-output-tokens-remaining 精确告诉你还剩多少容量。Claude Console 的 Usage 页面提供历史图表,展示你的峰值消耗速率和速率限制上限的对比,有助于你理解模式并规划容量需求。对于订阅配额,Claude.ai 网页界面显示使用量指示器,不过更新频率不如 API 头。一些开发者构建了轻量级监控脚本,在每次 API 调用后记录这些头的值,创建一个当剩余容量降至限制的 20% 以下时发出告警的预警系统。