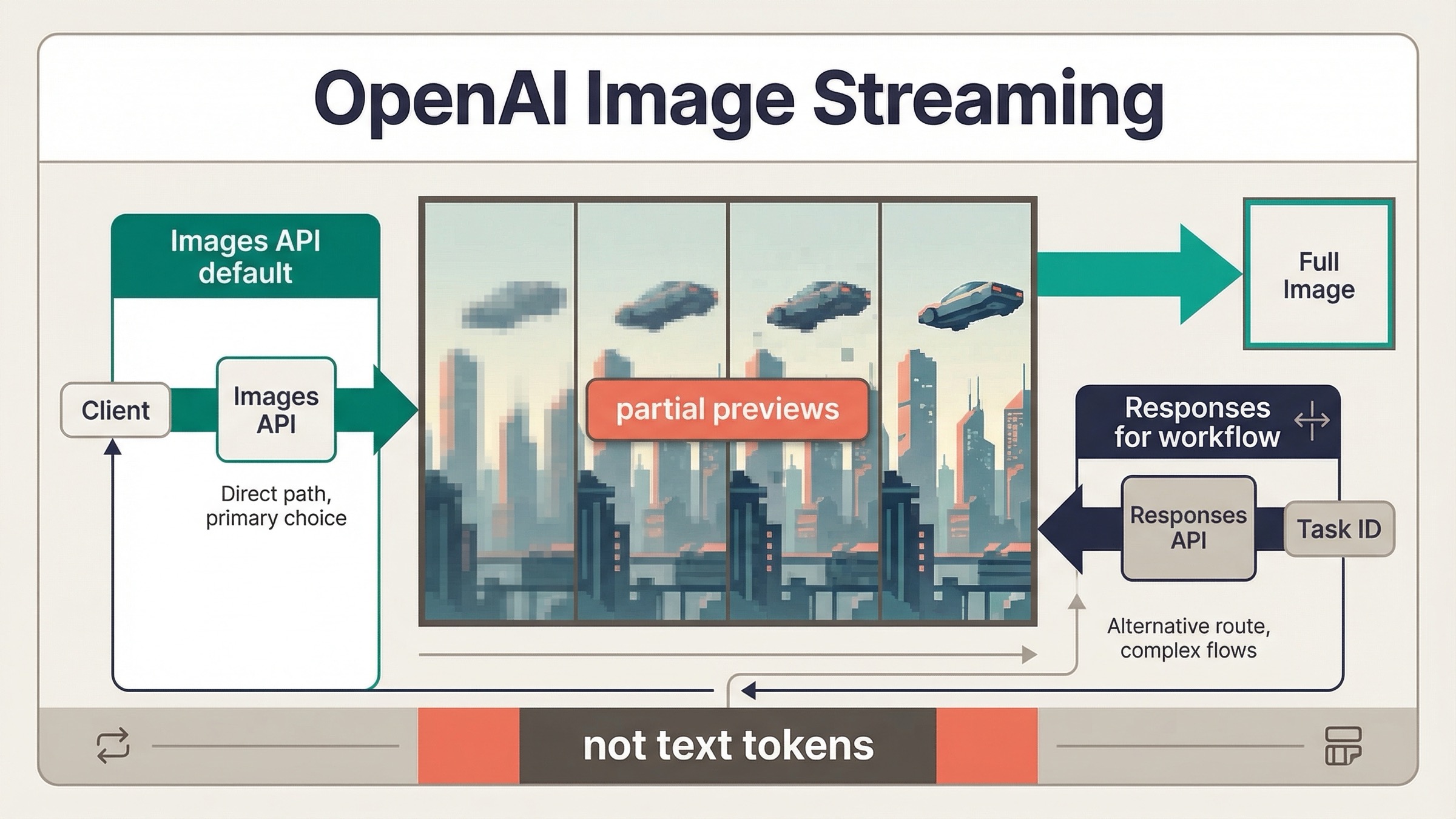
По состоянию на 23 марта 2026 года OpenAI image generation действительно поддерживает streaming, но текущая механика не похожа на text-style token streaming. Сегодня OpenAI документирует streamed partial-image previews, которые приходят, пока финальная картинка еще генерируется. Это важно не как терминологическая мелочь, а как практическое ограничение: от него зависит, что можно обещать в UI и какой API surface стоит подключать первым.
Если вы делаете прямую image feature, самый безопасный текущий дефолт простой: начинайте с Images API и стримьте preview images из client.images.generate(). Если генерация картинки у вас только один tool внутри более широкого assistant или multimodal workflow, тогда уже разумнее брать Responses API и hosted image_generation tool. Большинство слабых страниц смешивают эти два маршрута в один, и именно поэтому keyword до сих пор кажется запутаннее, чем должен быть.
Отдельная проблема в том, что official pages OpenAI описывают streaming не на одном уровне. Текущий image generation guide прямо показывает streaming и для Responses API, и для Images API. При этом текущая страница GPT Image 1.5 все еще пишет Streaming: Not supported в таблице model-card features. Если открыть эти страницы в неправильном порядке, создается впечатление, будто docs спорят сами с собой. Эта статья нужна именно для того, чтобы снять это противоречие до того, как вы начнете дебажить не ту проблему.
Кратко
- Да, OpenAI image generation сейчас умеет streaming, но поток состоит из partial-image previews, а не из text tokens.
- Сначала используйте Images API, если сама генерация картинки и есть продуктовая функция.
- Переходите к Responses API только тогда, когда изображение - один tool внутри более крупного assistant или multimodal flow.
- На разных поверхностях разные event names:
image_generation.partial_imageдля Images API иresponse.image_generation_call.partial_imageдля Responses API. - Не рассчитывайте, что всегда получите все previews, которые запросили. Текущий guide пишет, что
partial_imagesможет быть от0до3, а быстрые generations иногда возвращают меньше previews, чем вы попросили.
С чего начать: что сегодня на самом деле значит OpenAI image streaming
Главная ошибка вокруг этого keyword-а - автоматически переносить mental model из text generation. Когда разработчик спрашивает, "умеет ли OpenAI image generation streaming", обычно он имеет в виду один из двух вопросов:
- могу ли я показать пользователю progressive visual feedback до появления финальной картинки
- ведет ли себя image model как text model, которая отдает маленькие token-sized chunks до завершения ответа
Текущий ответ OpenAI звучит так: на первый вопрос - да, на второй - нет. Актуальный image generation guide говорит, что и Responses API, и Image API поддерживают streaming image generation, а затем раскрывает это через partial images, а не через text-like tokens. Там же прямо сказано, что partial_images можно задать от 0 до 3, и что previews может прийти меньше, если финальная картинка дорисовалась слишком быстро.
Отсюда и правильное продуктовое ожидание. Это не контракт в духе "я получаю стабильный поток маленьких шагов рендера, пока не проявится последний пиксель". Это контракт в духе "я могу запросить небольшое число preview images, показать их в процессе generation, а потом перейти на обычный path финального asset-а". Для UX это все равно очень полезно, особенно если вы хотите, чтобы image generation ощущалась менее черным ящиком, но контракт у этого поведения уже и уже, чем многие ожидают по слову streaming.
Именно поэтому первый архитектурный выбор так важен. Если вашему продукту нужен только prompt, несколько preview frames и финальная картинка, прямой Images API держит mental model чистой. Если же вам нужен conversation state, tool orchestration или image generation как этап внутри более широкого agent workflow, тогда у Responses API уже есть смысл. Обе ветки поддержаны текущими docs. Ошибка - считать их одинаково хорошим стартом для любой задачи.
Images API vs Responses API: как выбрать правильную streaming surface
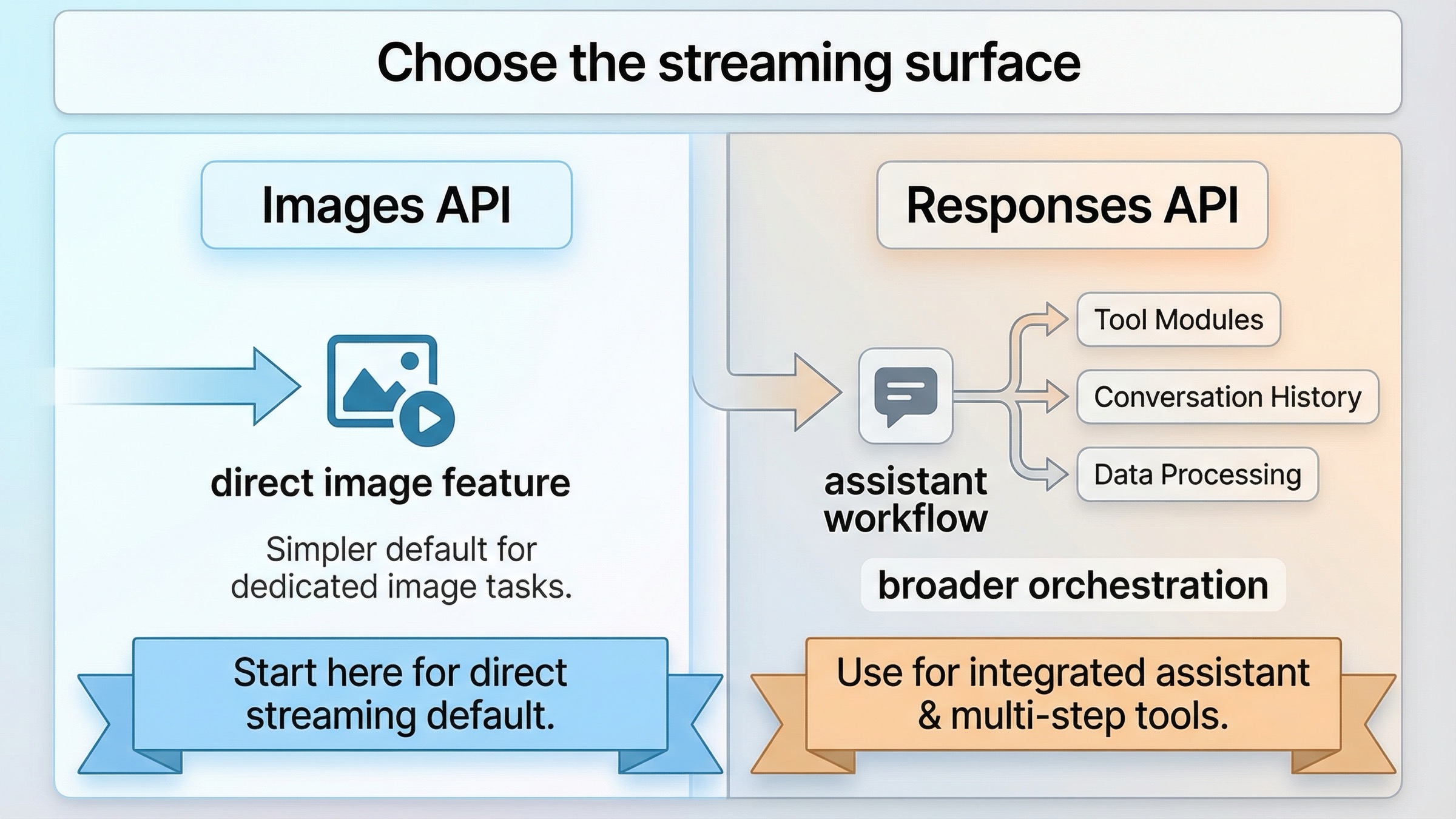
Этот keyword резко упрощается, как только вы перестаете спрашивать "какой endpoint новее" и начинаете спрашивать "какой surface соответствует продукту, который я делаю сейчас".
| Ситуация | Лучший дефолт | Почему |
|---|---|---|
| Вы делаете прямую image feature и хотите previews плюс финальную картинку | Images API | Самая чистая форма request-а, явный выбор image model и простой event loop для image-only path |
| Генерация изображения встроена в более широкий assistant или multimodal flow | Responses API | Картинка становится одним tool внутри большего reasoning или conversation workflow |
| Нужен самый быстрый proof, что streaming вообще работает в вашем аккаунте | Images API | Меньше moving parts, меньше route choices и не нужно сразу разруливать top-level orchestration |
| Mainline model должна править prompt или координировать другие tools вокруг image output | Responses API | Hosted image_generation tool лучше встраивается туда, где image не единственный output |
| Вы впервые разбираете путаницу в docs | Сначала Images API, потом Responses при необходимости | Так вы убираете целый уровень неопределенности еще до дебага event handling и orchestration |
Практическое правило прямое. Если генерация изображения сама по себе и есть feature, стартуйте с direct route. Используйте Images API, убедитесь, что partial previews приходят, и только потом добавляйте Responses layer, если продукт действительно в ней нуждается. Если генерация изображения - один tool среди нескольких, тогда уже начинайте с Responses, потому что именно surrounding workflow и является сутью системы.
Текущий images and vision guide как раз поддерживает этот split. Там сказано, что разработчики могут генерировать и редактировать картинки через Image API или Responses API, а пример для Responses использует mainline model вроде gpt-4.1-mini вместе с hosted image_generation tool. Это хороший сигнал о том, как OpenAI видит Responses path: mainline model orchestrates, а image generation - только один из инструментов внутри более широкого flow.
Самый быстрый working stream через Images API
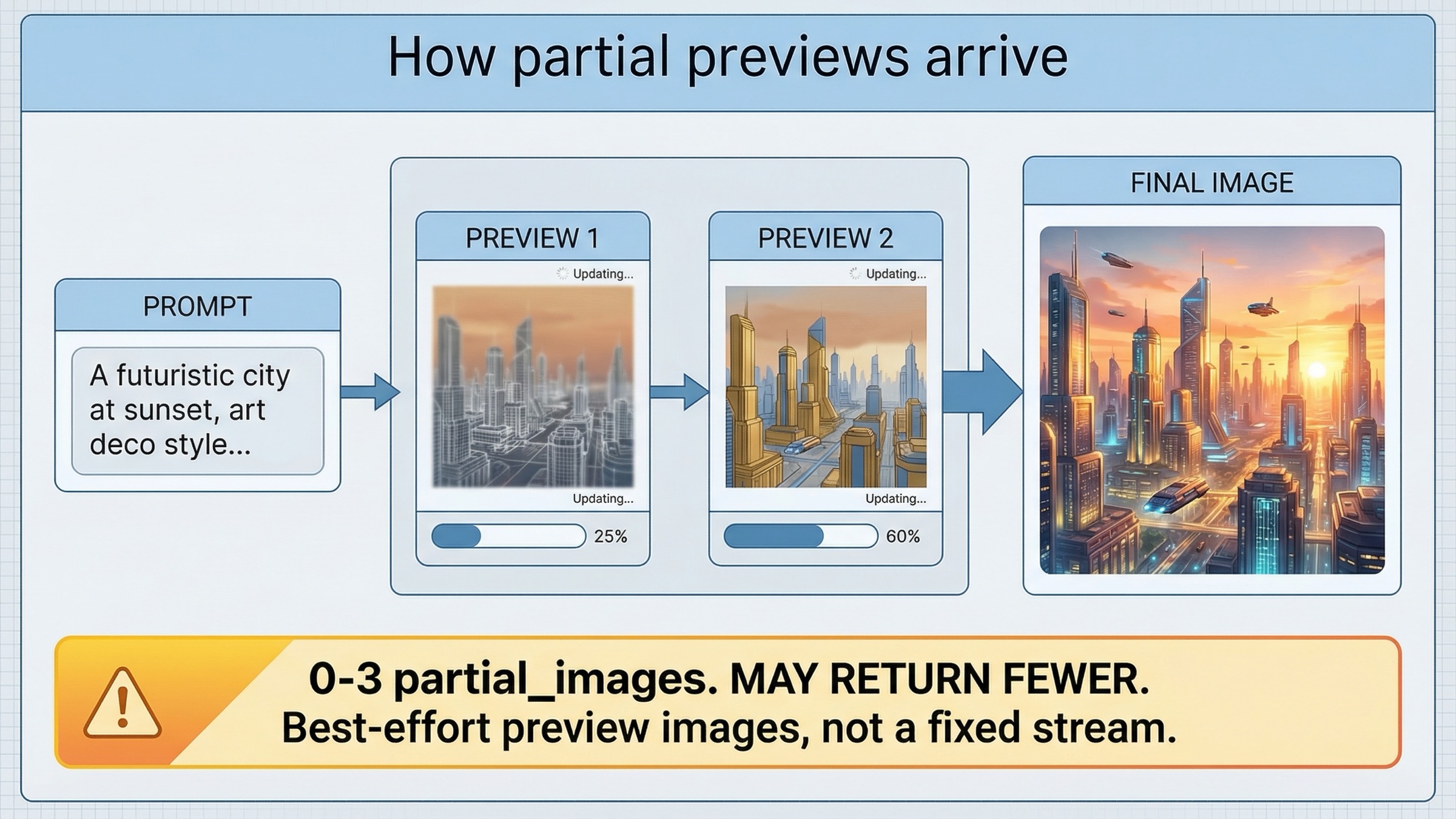
Если ваша задача - быстро доказать, что streaming path вообще работает, Images API остается лучшей стартовой точкой. Текущий guide показывает direct pattern с gpt-image-1.5, stream: true и partial_images: 2. Именно этот маршрут я бы дал разработчику, которому нужен самый быстрый и честный success path.
В JavaScript:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const stream = await client.images.generate({ model: "gpt-image-1.5", prompt: "Create a clean editorial illustration of a camera drone hovering over a bright city skyline at sunrise", stream: true, partial_images: 2, }); for await (const event of stream) { if (event.type === "image_generation.partial_image") { const index = event.partial_image_index; const imageBytes = Buffer.from(event.b64_json, "base64"); fs.writeFileSync(`preview-${index}.png`, imageBytes); } }
В Python:
pythonfrom openai import OpenAI import base64 client = OpenAI() stream = client.images.generate( model="gpt-image-1.5", prompt="Create a clean editorial illustration of a camera drone hovering over a bright city skyline at sunrise", stream=True, partial_images=2, ) for event in stream: if event.type == "image_generation.partial_image": index = event.partial_image_index image_bytes = base64.b64decode(event.b64_json) with open(f"preview-{index}.png", "wb") as f: f.write(image_bytes)
Это правильный первый тест по трем причинам.
Во-первых, он доказывает максимально простой route. Вы явно выбираете текущую image model, явно просите небольшое число previews и явно слушаете один image-specific event type. Именно этого и хочется, когда вопрос звучит как "работает ли streaming для моей image feature", а не как "как мне оркестрировать целого agent-а".
Во-вторых, у вас получается более чистое дерево дебага. Если preview не пришел, можно проверять account access, выбор model и event handling, не гадая, не скрыта ли проблема внутри более крупного Responses workflow. Текущая страница GPT Image 1.5 все еще пишет Free not supported, а rate limits для image use начинаются с Tier 1 и 100,000 TPM / 5 IPM, так что перед обвинением SDK имеет смысл сначала снять access assumptions.
В-третьих, этот путь с самого начала задает честное ожидание для UI. Guide говорит, что можно запросить 0-3 partial images, но может прийти меньше preview, чем вы попросили, если final image соберется слишком быстро. Это preview signal, а не гарантированный frame contract. Если ваш продукт умеет с этим жить, прямой Images API route чаще всего уже достаточен.
Если команде нужен более широкий direct-generation handbook, после этой статьи логично дать им наш OpenAI image API tutorial. Он остается лучшей стартовой страницей для direct generation и edits, когда вопрос уже не сводится именно к streamed previews.
Когда Responses API действительно лучше для streaming
Responses path сам по себе не ошибочный. Он просто чаще всего не лучший первый дефолт для этого keyword-а, если workflow по-настоящему не требует его.
Текущий image generation guide показывает streamed Responses generation примерно так:
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const stream = await client.responses.create({ model: "gpt-5", input: "Create a transparent sticker-style icon of a paper airplane for a travel app", stream: true, tools: [{ type: "image_generation", partial_images: 2 }], }); for await (const event of stream) { if (event.type === "response.image_generation_call.partial_image") { const index = event.partial_image_index; const imageBytes = Buffer.from(event.partial_image_b64, "base64"); fs.writeFileSync(`preview-${index}.png`, imageBytes); } }
Этот путь оправдан, когда image - не единственное, что вас интересует. Типичные примеры такие:
- multimodal assistant, который иногда возвращает text, а иногда images
- workflow, в котором mainline model должна сама решить, когда запускать image generation
- система, где mainline model полезно переписывает prompt или координирует другие tools вокруг image output
Текущий guide прямо показывает и этот дополнительный слой. В Responses API mainline model может пересмотреть prompt для image generation call, а после завершения можно посмотреть поле revised_prompt. Это полезно, когда ценность продукта лежит именно в orchestration, а не в минимальном direct route.
Но здесь разработчиков все еще ловит одно правило: не пытайтесь относиться к Responses path так, будто туда надо положить gpt-image-1.5 в top-level model только потому, что финальный output - картинка. Текущая документация описывает Responses image generation как связку mainline model вроде gpt-4.1 или gpt-5 плюс hosted image_generation tool. Если навязать этой surface неправильную mental model, вы будете дебажить route problem так, будто это streaming problem.
Поэтому правильная рекомендация не звучит как "Responses современнее, значит используйте его везде". Правильная рекомендация звучит так: Responses лучше там, где orchestration и есть feature. Images API лучше там, где feature - сама image generation.
Почему docs выглядят противоречиво
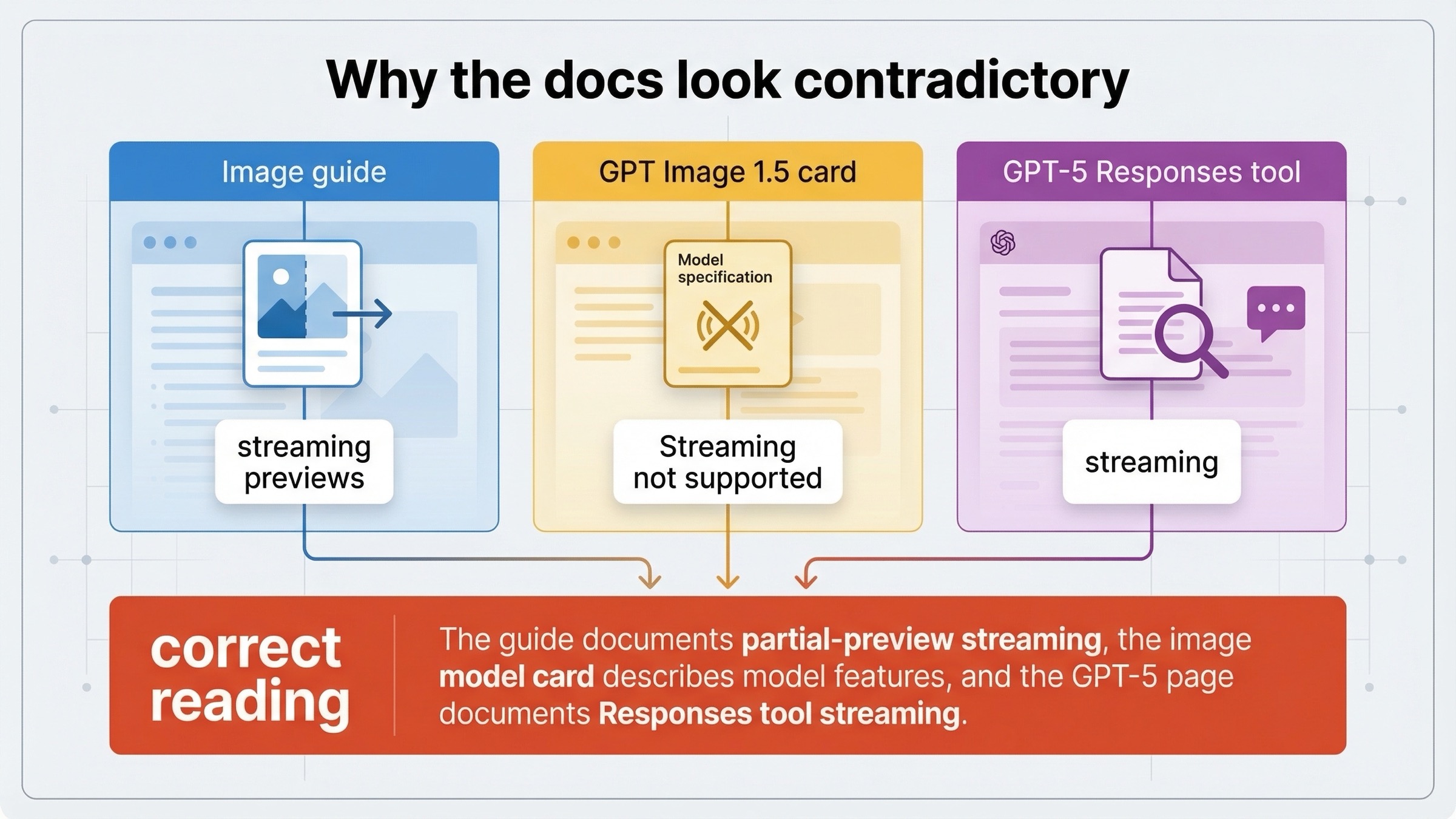
Именно этот блок большинство ranking pages до сих пор аккуратно обходит, хотя именно из-за него keyword вообще существует.
Текущий image generation guide говорит, что и Responses API, и Image API поддерживают streaming image generation. Дальше он показывает concrete event loops для обеих поверхностей и явно объясняет поддержку через partial-image previews.
Текущая страница GPT Image 1.5, однако, все еще пишет Streaming: Not supported в feature table.
А текущая страница GPT-5 уже говорит, что streaming is supported, и отдельно указывает, что image_generation tool поддерживается в Responses API.
Самый чистый способ примирить эти страницы такой:
- image guide описывает поведение на уровне API surface для streamed partial-image delivery
- страница GPT-5 описывает поведение mainline model плюс tool support внутри Responses
- карточка GPT Image не обещает generic text-like streaming от самой image model
Именно такое чтение лучше всего совпадает с примерами, которые OpenAI реально публикует. Если ваш вопрос звучит как "может ли мое приложение получать preview images, пока generation еще не завершилась", ответ - да. Если вопрос звучит как "ведет ли себя image model как text model, стримя token chunks", ответ - нет, текущий image guide описывает не это.
Это же объясняет, почему старые tutorials до сих пор звучат иначе. В launch post про API image model от 23 апреля 2025 года OpenAI представила gpt-image-1 на Images API и написала, что Responses support "coming soon". Если вы собрали mental model в ту эпоху, у вас почти наверняка остался Images-first взгляд на стек и более узкое понимание streaming support. Текущие docs уже ушли дальше, но старые формулировки с других поверхностей никуда автоматически не исчезли.
Типичные implementation mistakes, которые зря тратят время
Чаще всего проблемы на этом keyword-е не про алгоритмы. Это route mistakes, naming mistakes и expectation mistakes.
1. Перепутать event name для выбранной surface
На прямом Images API current guide слушает image_generation.partial_image. На Responses API guide слушает response.image_generation_call.partial_image. Это не взаимозаменяемые имена. Можно скопировать правильную идею, но не тот event name, а затем решить, что route broken, хотя проблема в event handler-е.
2. Стартовать с Responses, когда продукту нужна просто прямая image feature
Это самая частая архитектурная ошибка. Если все, что вам нужно, это prompt, несколько preview images и финальный asset, Images API дает более чистый first success. Старт с Responses добавляет лишний abstraction layer раньше, чем вы вообще доказали, что простейший stream работает.
3. Считать partial_images гарантией по кадрам
Текущий guide говорит, что partial_images можно задать от 0 до 3, но previews может прийти меньше, если финальная картинка соберется быстрее. Относитесь к previews как к best-effort progress UX, а не как к обещанию вернуть фиксированное число progressive frames.
4. Читать model card и guide как если бы они описывали один и тот же слой
Это не так. Guide описывает текущую streamed partial-image delivery на уровне API surface. Model card описывает features image model в более широкой catalog table. Если склеить эти два уровня в одно значение, вы либо занизите текущую поддержку, либо завысите то, что эта поддержка реально гарантирует.
5. Дебажить код раньше, чем вы проверили access assumptions
Текущая страница GPT Image 1.5 все еще пишет, что Free tier для image use не поддерживается, а launch post по-прежнему предупреждает, что части разработчиков может понадобиться organization verification. Если ваш первый streamed test вообще ничего не возвращает, не считайте event loop единственным подозреваемым. Сначала проверьте, может ли account и organization реально пользоваться выбранной image model.
6. Тащить в 2026 год старые assumptions из эпохи gpt-image-1
Для new work current anchor - это gpt-image-1.5, а не исходная launch-era mental model вокруг gpt-image-1. Если вам одновременно нужно сравнить broader image routes, дальше лучше перейти к нашему гайду по текущим OpenAI image models, а уже потом продолжать тюнинг streaming path.
FAQ
Можно ли заставить API всегда вернуть ровно две preview frames?
Нет. Текущий image generation guide говорит, что partial_images можно задать от 0 до 3, но при быстрой generation вы можете получить меньше previews, чем запросили. Относитесь к partial images как к best-effort preview signals, а не как к гарантированному числу кадров.
Нужно ли для этого сразу смотреть в сторону Realtime API?
Не как к дефолтному ответу на этот keyword. Текущий image generation guide документирует streamed partial-image previews на Images API и Responses API. Именно этот documented path и стоит брать первым, пока OpenAI не опубликует более прямой image-preview pattern для Realtime.
Какую model лучше ставить в request?
Для прямого Images API route начинайте с gpt-image-1.5. Для Responses route следуйте current docs pattern: ставьте в top-level model mainline model вроде gpt-4.1 или gpt-5, а затем подключайте hosted image_generation tool.
Финальная рекомендация
Если с этой страницы нужно унести только одно правило, пусть оно будет таким: streaming в OpenAI image generation сейчас означает streaming partial-image previews, а Images API остается самым безопасным дефолтом, пока image generation не стала лишь одним tool внутри более широкого Responses workflow.
Это полезнее, чем просто ответить "да", потому что сразу подсказывает следующий шаг. Сначала запустите один direct streamed request в Images API на gpt-image-1.5. Убедитесь, что ваш UI честно обрабатывает best-effort preview images. И только после этого поднимайтесь на Responses API, где дополнительная orchestration действительно стоит дополнительной сложности.
Если после решения streaming-вопроса вам нужен более широкий route map, переходите к нашему OpenAI image API tutorial для direct generation и edits или к нашему гайду по OpenAI image editing API, если следующая задача - preserve-heavy edits, а не progressive previews.