По состоянию на 29 марта 2026 года safest default для OpenAI mask edits остается простым: начинайте с прямого images.edit() на gpt-image-1.5, отправляйте same-size alpha mask и пишите prompt как описание всей финальной картинки, а не только пустой области. Это быстрее приводит к рабочему результату, чем ранний переход к Responses или попытка дебажить все через старую DALL·E-era mental model.
Этот query до сих пор кажется запутаннее, чем должен, потому что текущий ответ у OpenAI разложен по нескольким страницам. В image generation guide собраны mechanical mask rules, в секции input fidelity объясняется preservation side, а в tool options для Responses уже живет развилка с action=auto|generate|edit. Если читать только одну из этих страниц, легко унести половину ответа и начать с неправильного abstraction layer.
Самое важное предупреждение OpenAI уже пишет прямо: GPT Image masking остается prompt-based guidance и не гарантирует строгую pixel-locked локальную замену. Именно отсюда и рождается classic complaint про whole-image rewrite. Mask здесь управляет фокусом, а не превращает модель в механический layer editor.
Краткое содержание
- Для one-shot mask edits сначала используйте direct
client.images.edit()илиPOST /v1/images/edits. - Прежде чем трогать prompt, проверьте сам mask: same format, same dimensions, less than
50 MB, реальный alpha channel. - Prompt нужно писать как описание всей финальной картинки, а не только того, что вы хотите вставить в дырку.
input_fidelity="high"нужен не всегда; это отдельный control для preservation, особенно для faces, logos и product details.- Правильная mental model здесь такая: constrained semantic rewrite, а не deterministic local surgery.
Начните с текущего mask-first маршрута OpenAI
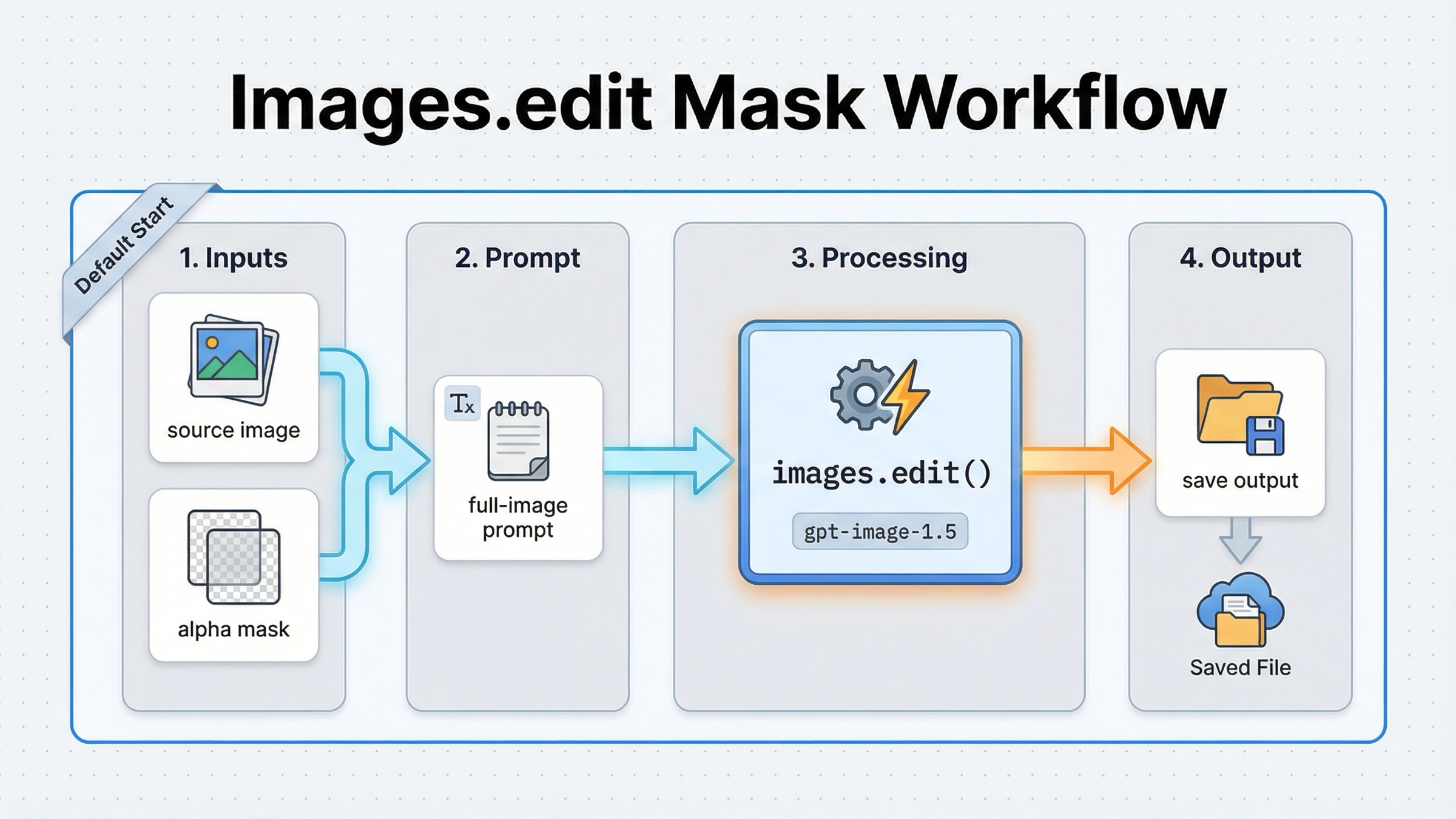
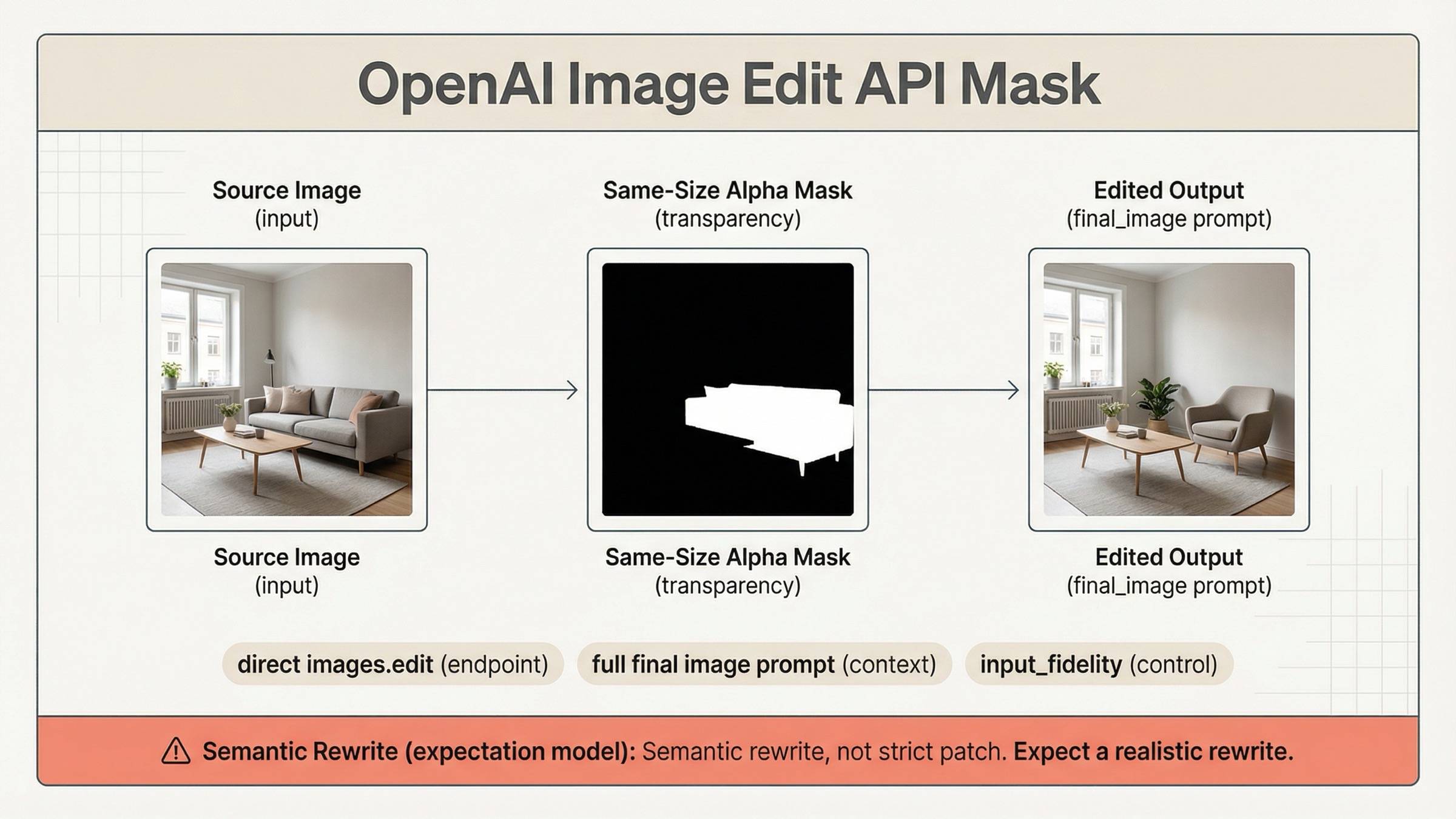
Если ваш job звучит как «у меня уже есть картинка, нужно изменить конкретную область», нет причин сразу тащить сюда conversation wrapper. Current OpenAI docs по-прежнему показывают самый надежный старт как прямой Images API: base image, mask, final-image prompt, base64 output, сохранение файла.
Текущий JavaScript path выглядит так:
jsimport fs from "fs"; import OpenAI, { toFile } from "openai"; const client = new OpenAI(); const result = await client.images.edit({ model: "gpt-image-1.5", image: await toFile(fs.createReadStream("sunlit_lounge.png"), null, { type: "image/png", }), mask: await toFile(fs.createReadStream("mask.png"), null, { type: "image/png", }), prompt: "A sunlit indoor lounge area with a pool containing a flamingo. Preserve the room, lighting, reflections, and camera angle.", input_fidelity: "high", size: "1024x1024", quality: "medium", }); const imageBase64 = result.data[0].b64_json; const imageBytes = Buffer.from(imageBase64, "base64"); fs.writeFileSync("lounge.png", imageBytes);
Python не сложнее:
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.edit( model="gpt-image-1.5", image=open("sunlit_lounge.png", "rb"), mask=open("mask.png", "rb"), prompt=( "A sunlit indoor lounge area with a pool containing a flamingo. " "Preserve the room, lighting, reflections, and camera angle." ), input_fidelity="high", size="1024x1024", quality="medium", ) image_base64 = result.data[0].b64_json image_bytes = base64.b64decode(image_base64) with open("lounge.png", "wb") as f: f.write(image_bytes)
Если вам нужен raw HTTP contract, current multipart route все еще выглядит так:
bashcurl -s -X POST "https://api.openai.com/v1/images/edits" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "mask=@mask.png" \ -F "image[]=@sunlit_lounge.png" \ -F 'prompt=A sunlit indoor lounge area with a pool containing a flamingo'
Почему это лучший первый шаг? Потому что он оставляет минимум moving parts. Вы сразу видите, где проблема: в project state, model access, mask validity, prompt scope или output handling. Как только вы на первом же тесте оборачиваете edit в Responses, assistant logic и extra tool state, failure surface растет быстрее, чем польза.
Есть и еще одна current nuance. /v1/images/edits уже не завязан только на local multipart uploads. Текущий endpoint contract позволяет и JSON requests с images плюс optional mask через image_url или file_id. То есть даже если assets уже лежат в uploaded form, direct Images API все равно может оставаться самой короткой surface.
Сначала соберите mask, который API действительно примет
Самый дорогой wasted hour по этому keyword выглядит так: команда думает, что надо переписывать prompt, хотя mask изначально mechanical invalid. OpenAI current mask requirements довольно короткие, но все они жесткие:
- base image и mask должны быть одного формата
- у них должны быть одинаковые pixel dimensions
- payload должен быть меньше
50 MB - mask обязан содержать alpha channel
Именно четвертый пункт чаще всего ломает ожидания. Люди сохраняют черно-белую картинку и считают, что этого достаточно, хотя инструмент вывел просто opaque bitmap без alpha. Не случайно OpenAI отдельно показывает пример, как programmatically превратить black-and-white image в RGBA mask и записать grayscale values в alpha channel.
Но здесь есть еще одна важная развилка. Mechanical validity не равна strict behavioral obedience. Документация одновременно говорит две вещи: transparent area — это replace region, и GPT Image masking остается prompt-based, не обязуясь идеально следовать форме mask. Эти утверждения не противоречат друг другу. Они вместе описывают текущую operational truth: mask ограничивает смысловую область edit, но не превращает весь процесс в pixel-perfect patching.
Практический preflight checklist выглядит так:
- заранее выровняйте base image и mask по одной финальной размерности
- сохраняйте mask как настоящий RGBA PNG, а не «похожую» grayscale картинку
- убедитесь, что меняемая область именно прозрачная, а не просто белая на opaque layer
- держите masked area настолько узкой, насколько это позволяет job
Если вы используете несколько input images, не пропустите еще одно current правило: mask применяется к первой input image. Это значит, что первая картинка должна быть базовой сценой, а не случайным reference asset из списка.
Пишите prompt про финальную картинку целиком, а не только про «дырку»
Самая полезная sentence в current OpenAI docs для этого query не про endpoint, а про prompt method: describe the full new image, not only the erased area. Если ее пропустить, mask может быть идеальным, а результат все равно покажется неправильным.
Это меняет весь способ thinking about prompts. Модель здесь не «заполняет пустое место» механически. Она строит новую coherent final image, в которой mask лишь подсказывает, где изменение особенно важно. Поэтому prompt должен одновременно делать три работы:
- назвать, что именно нужно изменить
- назвать, что должно остаться без изменений
- описать финальное состояние сцены так, чтобы edit не начал дрейфовать
Плохой prompt:
textPut a flamingo in the pool.
Намного лучший:
textA sunlit indoor lounge area with a pool containing a flamingo. Preserve the pink room walls, the pool tile pattern, the reflections, the furniture, and the camera angle. Do not redesign the rest of the room.
Если edit касается label, logo, packaging или product hero image, preservation list должна быть еще жестче:
textReplace only the blank label area on the bottle with a clean gold logo. Preserve the bottle shape, cap, glass reflections, lighting, shadows, background, and camera framing. Do not change any other packaging detail.
Именно тут current GPT Image 1.5 prompting guide полезнее многих thin tutorials. Его главный смысл не в том, чтобы заставить вас писать максимально длинный prompt, а в том, чтобы явно разделять change list и preserve list, а затем итеративно двигаться малыми исправлениями. Большой всеобъемлющий prompt часто дает модели больше свободы заново интерпретировать сцену, а не меньше.
Если output уже близок к цели, не начинайте следующую попытку с нуля. Обычно фраза вроде «keep everything the same, but enlarge the logo slightly» устойчивее, чем полный rewrite предыдущего prompt.
Когда input_fidelity=high действительно меняет результат
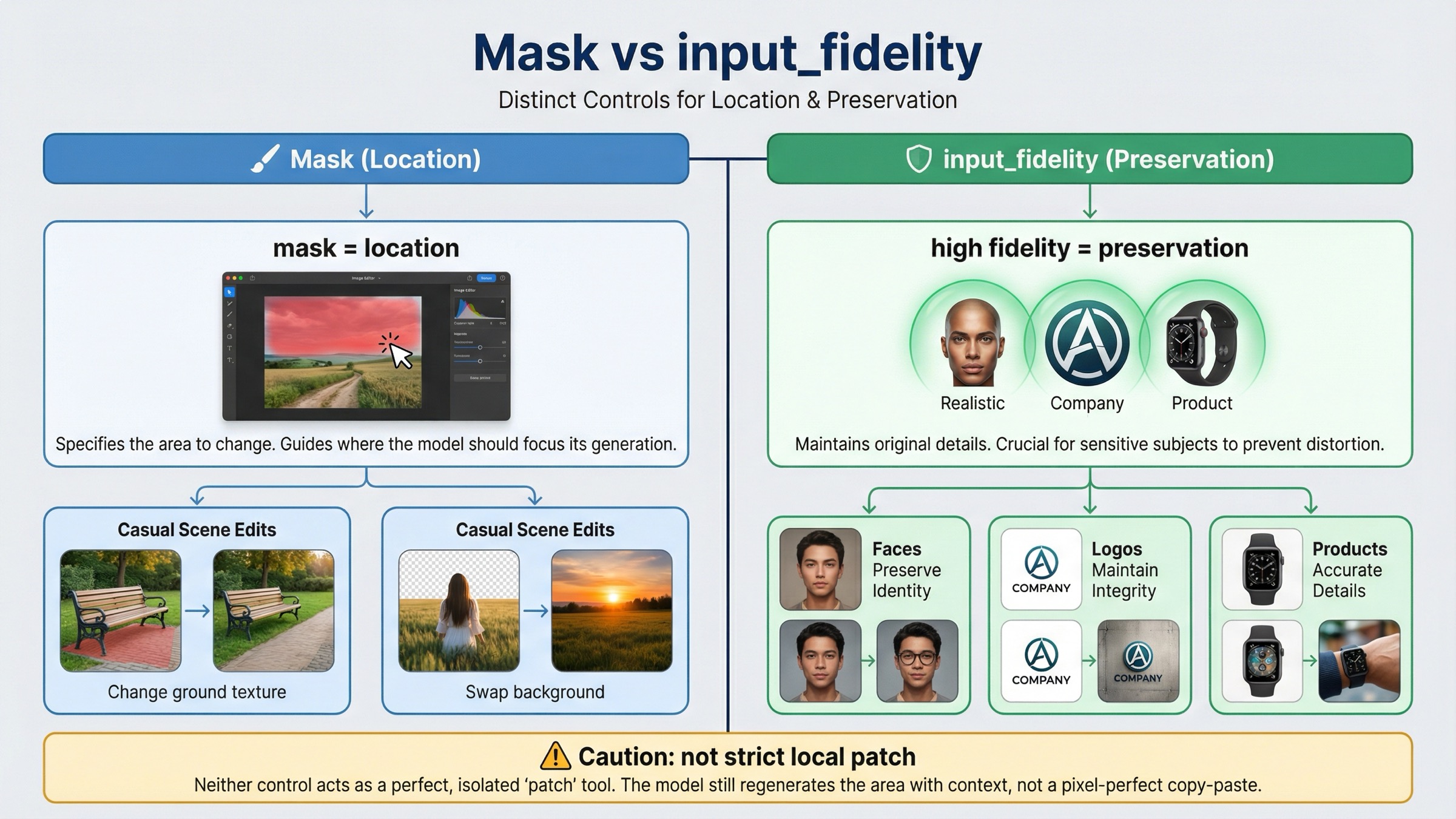
Mask и input_fidelity отвечают за разные вещи. Mask управляет location, а input_fidelity — preservation pressure на детали входных изображений. Если смешать эти две задачи, команда начнет обвинять mask в тех сбоях, которые на самом деле были caused by weak preservation.
Current input fidelity section OpenAI формулирует это прямо: high особенно полезен для faces и logos; у gpt-image-1 и gpt-image-1-mini richer preservation идет прежде всего по первому input image; у gpt-image-1.5 более высокий уровень preservation распространяется на первые 5 input images. По умолчанию input_fidelity остается low.
Самый полезный operational split выглядит так:
| Ситуация | Достаточно ли обычно одного mask | Стоит ли добавлять input_fidelity="high" | Почему |
|---|---|---|---|
| Простая замена объекта в casual scene | Чаще да | Обычно нет | Основная задача — location, а не дорогой detail preservation |
| Edit рядом с face | Не всегда | Чаще да | Face drift слишком дорог, docs явно называют такие случаи preservation-sensitive |
| Logo на упаковке, одежде или signage | Редко | Да | Mask задает позицию, но fidelity помогает удержать узнаваемость branding |
| Product hero shot с важной геометрией и reflections | Редко | Да | Здесь важнее сохранить object identity, чем выиграть немного latency |
| Ожидание strict local patch без spillover | Нет | Даже high не гарантирует этого | Fidelity помогает удерживать детали, но не превращает GPT Image в deterministic layer surgery |
Отсюда и главный practical вывод: если mask вроде бы корректный, но drift возникает на face, logo или product detail, скорее всего это preservation problem, а не mask problem. Конечно, high дороже по image input tokens, поэтому включать его по умолчанию на every tiny edit не стоит. Но если цена drift выше, чем extra token cost, этот параметр почти всегда важнее очередной магической перестановки слов в prompt.
Если нужен более широкий model-routing context, полезно дочитать OpenAI image generation API models. Но для exact mask query достаточно помнить одно: mask = где менять, input_fidelity = насколько жестко удерживать детали.
Почему masked edits все равно переписывают больше, чем вы ожидали
Docs на самом деле честнее большинства third-party pages. В current mask section OpenAI говорит, что GPT Image использует mask как guidance и может не следовать его shape с полной точностью. Это и есть official translation той самой community complaint, которую разработчики продолжают заново открывать для себя.
На OpenAI Developer Community похожие жалобы живут как минимум с 27 апреля 2025 года: valid mask может все равно ощущаться так, будто он запустил более широкий scene rewrite. Это не означает, что endpoint broken. Это означает, что underlying edit behavior остается semantic and prompt-led, а не полностью deterministic local inpainting engine.
Обычно за overreach отвечают четыре фактора:
- prompt описывает только добавляемый объект, а остальная final scene остается underspecified
- edit затрагивает faces, logos, reflections, packaging или layout-sensitive areas без
input_fidelity="high" - masked area достаточно велика, чтобы модели пришлось переосмыслить соседний контекст
- команда все еще ожидает от GPT Image behavior, ближе к старым inpainting tools
Поэтому лучший fix здесь не «перестать использовать mask», а изменить expectation model:
- делайте edit smaller, если можете
- явно перечисляйте preserved parts
- включайте high fidelity только там, где drift действительно дорог
- если нужен очень локальный control, готовьте crop / segmentation до запроса, а не после
Если business rule звучит как «измените только эти пиксели и буквально ничего больше», этот query уже не про тонкую настройку prompt. Он про границу между current model behavior и вашим product requirement. Именно эту границу важно протестировать рано.
Images API vs Responses для mask-heavy workflow
Responses бывает полезен, но многие переходят к нему слишком рано. Current image generation guide и tool options page дают довольно ясный split: когда gpt-image-1.5 или chatgpt-image-latest используются внутри Responses, можно настроить action (auto, generate, edit), и OpenAI рекомендует оставлять auto, если нет жесткой необходимости forcing behavior.
Из этого следует удобное правило. Direct Images API остается default, когда workflow выглядит так:
- взять одну картинку
- применить один mask
- сохранить один output
- при необходимости повторить с более узким prompt
Responses начинает выигрывать, когда edit — это только один шаг внутри larger assistant chain, когда нужна multi-turn context, или когда продукт уже живет вокруг stored files, reusable state и broader multimodal orchestration.
Есть и practical nuance, которая усиливает прямой route. Теперь /v1/images/edits умеет не только multipart uploads, но и JSON с image_url / file_id. Значит, аргумент «нам уже все равно пришлось загружать файлы, поэтому давайте сразу в Responses» уже не так силен.
Если вы сейчас решаете более общий route question, дальше полезно открыть OpenAI Image API tutorial. Но для exact mask-heavy query default ответ остается тем же: берите самую короткую surface, которая чисто решает прямой edit.
Troubleshooting: почему mask все еще ломается или задевает лишнее
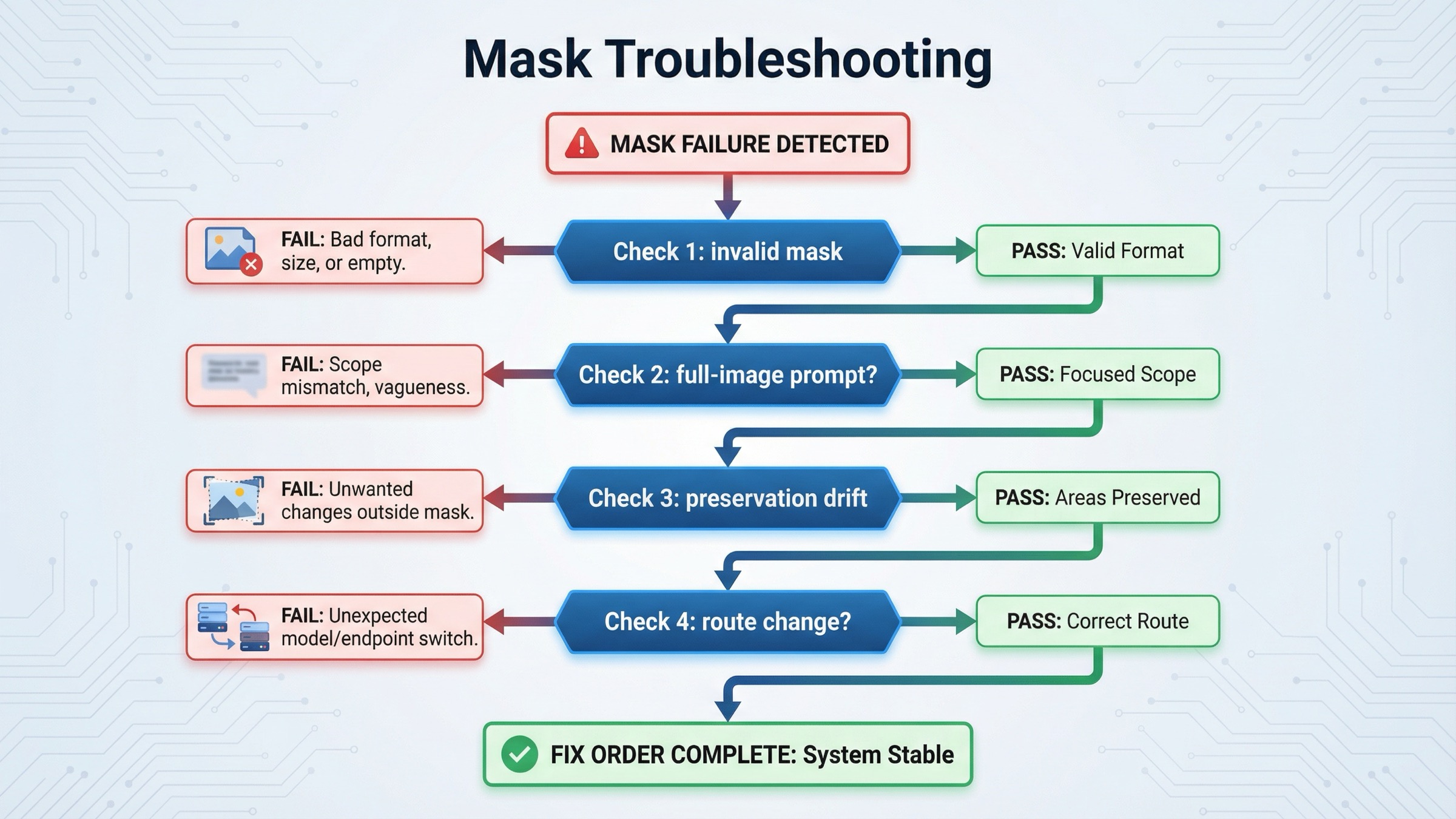
Самый экономный порядок диагностики выглядит так:
-
API отклоняет mask или ведет себя так, будто mask не распознан.
Сначала проверяйте format, dimensions, payload size и alpha. Пока эта механика не пройдена, дальше копать бессмысленно. -
Модель меняет примерно правильную область, но вся сцена выглядит иначе.
Обычно это значит, что prompt слишком узко описал change и слишком слабо описал preserved scene. Перепишите его как full final-image description и добавьте explicit preserve list. -
Изменение выходит за пределы mask.
Для GPT Image это не аномалия. Попробуйте сузить mask, уменьшить объем изменений за одну попытку и сделать preservation wording конкретнее. -
Faces, logos или branded objects все равно дрейфуют.
Это чаще preservation problem, а не mask problem. Включитеinput_fidelity="high"и явно напишите, какие identity или branding details нельзя менять. -
Нужна серия итераций и stored asset references.
Вот здесь уже логично думать о Responses или JSON/v1/images/editsсfile_id. Но не раньше. -
Требуется настоящая pixel-local reliability.
Проверьте это требование как product constraint. Если оно жестче, чем current GPT Image masking behavior, реальный fix будет в crop/segmentation/preprocessing, а не в еще одном magic prompt.
Именно поэтому dedicated mask guide все еще выигрывает у среднего page-one result. Большинство страниц объясняют одну часть задачи, но не дают один цельный triage flow от mechanical validity до route choice.
FAQ
Если область в mask прозрачная, это значит, что изменятся только эти точные пиксели?
Нет. Current docs прямо говорят, что transparent area — replace region, но GPT Image masking остается prompt-based и не обязан следовать shape mask с полной точностью. Здесь лучше думать про constrained rewrite, а не про strict local surgery.
Стоит ли для mask edits по умолчанию идти в Responses, а не в images.edit()?
Нет. Для one-shot mask edits сначала используйте direct Images API. К Responses переходите, когда edit живет внутри larger multi-turn или multimodal workflow.
Mask вроде правильный, почему тогда drift происходит у logo или лица?
Потому что mask управляет location, а не силой preservation. Это как раз тот случай, где нужен input_fidelity="high" плюс prompt, который явно перечисляет must-keep identity или branding details.
Финальная рекомендация
Current default для OpenAI mask edits остается очень практичным: запускайте gpt-image-1.5 через direct Images API, делайте mask mechanical valid, пишите prompt как описание всей финальной картинки и добавляйте input_fidelity="high" только там, где preservation действительно важнее экономии. Эта связка решает больше реальных failures, чем ранний переход к более тяжелому framework.
Если результат все равно переписывает больше сцены, чем нужно, не предполагайте автоматически, что mask upload broken. Сначала проверьте, не строже ли ваш product expectation, чем current GPT Image masking behavior. Чаще именно в этом и лежит настоящая развилка. Для более широкого edit route дальше полезен OpenAI image editing API guide, а для access и capability checks перед rollout — OpenAI image generation API verification guide.