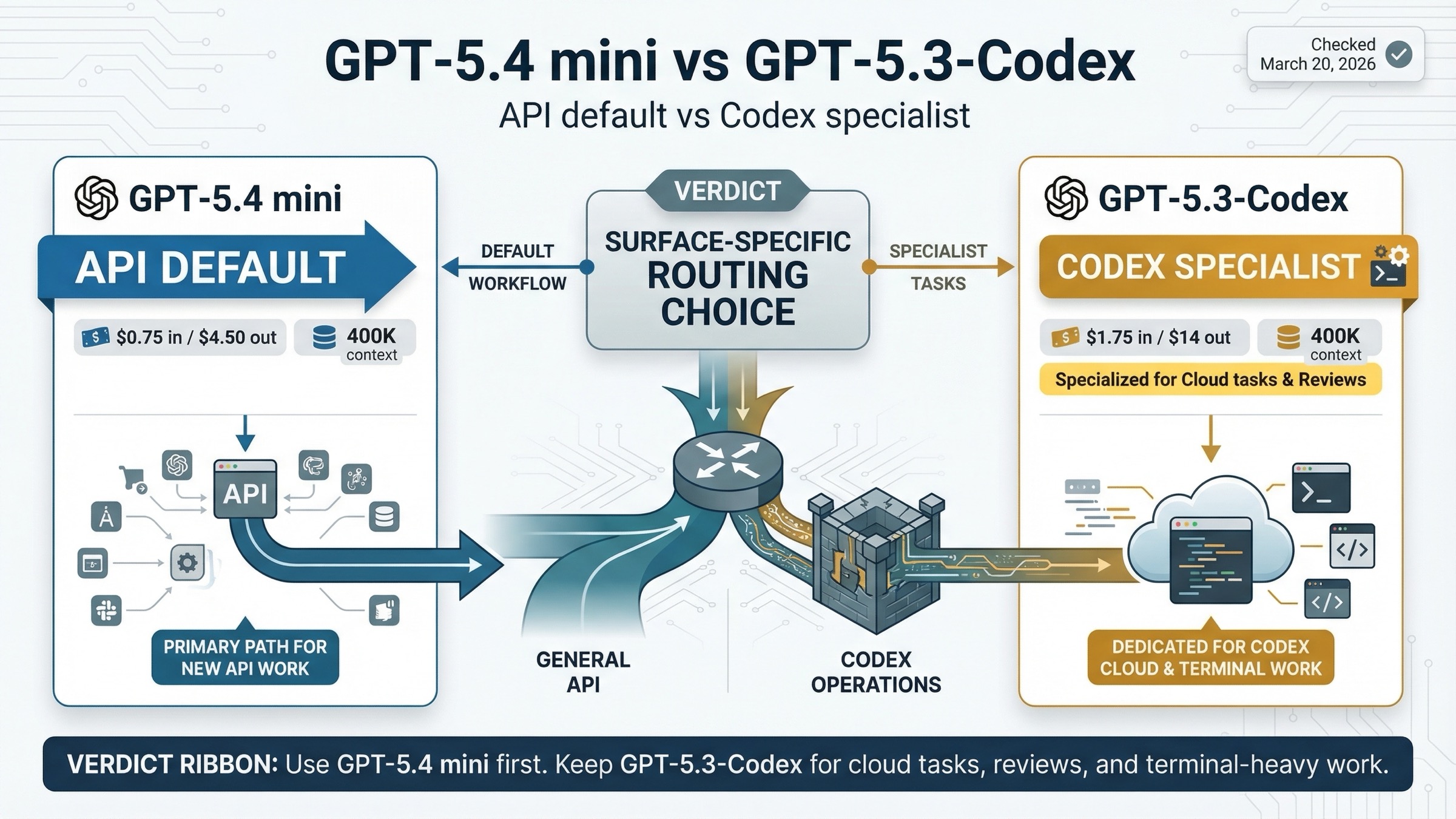
Используйте GPT-5.4 mini для новой работы в API и subagents. Оставляйте GPT-5.3-Codex для более тяжелого specialist coding внутри Codex, когда code review, terminal work и более глубокое coding behavior важнее price efficiency small-model класса.
Сравнение становится понятным только после разделения surfaces. В API GPT-5.4 mini - более дешевый и более новый default для многих high-volume coding workflows. В Codex-style environments GPT-5.3-Codex все еще держит более сильную specialist coding posture.
Краткое содержание
Если вам нужен самый короткий ответ, используйте такое правило: для новых API-потоков и subagents начинайте с GPT-5.4 mini; для Codex cloud tasks, code reviews и terminal-heavy coding держите GPT-5.3-Codex.
| Модель | Лучший сценарий | Главная причина выбрать | Главная причина не выбирать |
|---|---|---|---|
| GPT-5.4 mini | Новые API coding workers, дешёвые subagents, screenshot-heavy workers, локальная рутина в Codex | Дешевле в API, шире поддержка инструментов, текущая рекомендуемая mini-линия | Слабее specialist coding-бенчмарки и нет current support для Codex cloud tasks и reviews |
| GPT-5.3-Codex | Terminal-heavy разработка, specialist coding runs, Codex cloud tasks и code reviews | Сильнее профиль на SWE-Bench Pro и особенно на Terminal-Bench, плюс полный Codex product slot | Намного дороже в API и уже не small-model default |
Практическое правило можно сжать до четырёх строк:
- Для новых API coding-потоков сначала тестируйте GPT-5.4 mini.
- Для cloud tasks и GitHub code reviews в Codex сохраняйте GPT-5.3-Codex.
- Для terminal-first engineering GPT-5.3-Codex всё ещё выглядит сильнее.
- Не принимайте решение по названиям в ChatGPT picker, если ваш реальный вопрос про API или Codex.
В чём реальная разница между GPT-5.4 mini и GPT-5.3-Codex
Самая частая ошибка здесь - думать, что GPT-5.4 mini это просто «младшая и более дешёвая» версия работы, которую раньше делал GPT-5.3-Codex. Это не совсем так.
По текущим official model pages у моделей много общих верхнеуровневых параметров:
- 400K context window
- 128K max output
- knowledge cutoff: 31 августа 2025
- поддержка text и image input
Из-за этого при беглом чтении карточек кажется, что модели почти одинаковы. Но в реальности выбор определяется не статикой спецификаций, а ролью внутри продукта.
В текущем Using GPT-5.4 guide OpenAI рекомендует gpt-5.4-mini для high-volume coding, computer use и agent workflows с сильным reasoning. Это новая default-позиция для маленькой coding-oriented модели.
На странице GPT-5.3-Codex, напротив, модель описывается как the most capable agentic coding model to date и явно привязывается к Codex or similar environments. То есть это более узкая, более specialist роль.
Удобнее всего держать в голове такую таблицу:
| Вопрос | Лучше подходит |
|---|---|
| Нужен текущий default для API coding и subagents? | GPT-5.4 mini |
| Нужен более глубокий specialist coding lane? | GPT-5.3-Codex |
| Нужны cloud tasks и code reviews в Codex? | GPT-5.3-Codex |
| Нужна дешёвая локальная рутина в Codex или дешёвый API default? | GPT-5.4 mini |
Поэтому пытаться назначить одного «абсолютного победителя» здесь просто неверно. Рекомендация меняется в зависимости от того, принимаете ли вы API decision или Codex product decision.
Какие бенчмарки здесь действительно важны

OpenAI не публикует одну общую таблицу, где обе модели стоят в одном benchmark grid. Но официальных launch posts уже достаточно, чтобы понять разделение ролей.
Из официального поста от 17 марта 2026 GPT-5.4 mini and nano для GPT-5.4 mini:
- 54.4% SWE-Bench Pro
- 60.0% Terminal-Bench 2.0
- 72.1% OSWorld-Verified
Из официального поста от 5 февраля 2026 GPT-5.3-Codex для GPT-5.3-Codex:
- 56.8% SWE-Bench Pro
- 77.3% Terminal-Bench 2.0
- 64.7% OSWorld-Verified
Рядом это читается так:
| Бенчмарк | GPT-5.4 mini | GPT-5.3-Codex | Какой вывод важен |
|---|---|---|---|
| SWE-Bench Pro | 54.4% | 56.8% | GPT-5.3-Codex всё ещё сильнее в specialist coding |
| Terminal-Bench 2.0 | 60.0% | 77.3% | GPT-5.3-Codex заметно лучше для terminal-heavy инженерной работы |
| OSWorld-Verified | 72.1% | 64.7% | GPT-5.4 mini лучше подходит для screenshot-grounded и computer-use-like задач |
Это и есть ключевая мысль: победитель зависит от формы работы.
Если ваш реальный workload - это shell operations, repo-local debugging, build tooling, test loops и CLI automation, то преимущество GPT-5.3-Codex не косметическое. Terminal-Bench gap здесь слишком большой, чтобы его игнорировать.
Если же ваш workflow больше похож на:
- интерпретацию скриншотов,
- более широкий tool use,
- дешёвых worker-агентов внутри более крупного planner,
- hybrid coding-plus-computer-use задачи,
то GPT-5.4 mini начинает выглядеть сильнее. Его OSWorld score - важный сигнал того, куда OpenAI двигает всю GPT-5.4 family.
Итоговый вывод по benchmark layer такой:
- GPT-5.3-Codex выигрывает specialist coding lane
- GPT-5.4 mini выигрывает более современную и дешёвую mini-lane с лучшей пригодностью к computer use
Если вы вообще сомневаетесь, нужен ли вам один из этих small-моделей, или сразу стоит смотреть на более широкий flagship, полезно открыть нашу статью GPT-5.4 vs GPT-5.3-Codex.
Цена в API, инструменты и лимиты
Цена - это место, где рекомендация в пользу GPT-5.4 mini становится не тонкой, а очень практической.
На проверенных 20 марта 2026 official model pages:
| Параметр | GPT-5.4 mini | GPT-5.3-Codex |
|---|---|---|
| Input price | $0.75 / 1M tokens | $1.75 / 1M tokens |
| Cached input | $0.075 / 1M tokens | $0.175 / 1M tokens |
| Output price | $4.50 / 1M tokens | $14.00 / 1M tokens |
| Context window | 400K | 400K |
| Max output | 128K | 128K |
| Knowledge cutoff | Aug 31, 2025 | Aug 31, 2025 |
То есть в API GPT-5.3-Codex вовсе не бюджетная опция. Наоборот, GPT-5.4 mini радикально дешевле:
- меньше чем вдвое дешевле по input,
- меньше чем вдвое дешевле по cached input,
- меньше чем втрое дешевле по output.
Для нового API pipeline это почти автоматически меняет default recommendation.
Tool posture тоже склоняет чашу весов к GPT-5.4 mini. На текущей странице GPT-5.4 mini указаны:
- web search
- file search
- image generation
- code interpreter
- hosted shell
- apply patch
- skills
- computer use
- MCP
- tool search
У GPT-5.3-Codex акцент намного уже: structured outputs, function calling и привязка к specialist coding environments.
Даже rate limits не вытягивают GPT-5.3-Codex в роль очевидного API default. По текущим published limits:
| Tier | GPT-5.4 mini TPM | GPT-5.3-Codex TPM |
|---|---|---|
| Tier 1 | 500,000 | 500,000 |
| Tier 2 | 2,000,000 | 1,000,000 |
| Tier 3 | 4,000,000 | 2,000,000 |
| Tier 4 | 10,000,000 | 4,000,000 |
| Tier 5 | 180,000,000 | 40,000,000 |
Поэтому если вопрос звучит как «какую модель маленького класса тестировать первой в API», то ответ довольно прямой: по умолчанию начинайте с GPT-5.4 mini, а к GPT-5.3-Codex переходите только там, где specialist coding profile действительно важнее цены и tool breadth.
Если вам нужна соседняя развилка внутри mini-линейки OpenAI, можно затем посмотреть GPT-5.4 mini vs GPT-5 mini.
Почему Codex меняет вывод
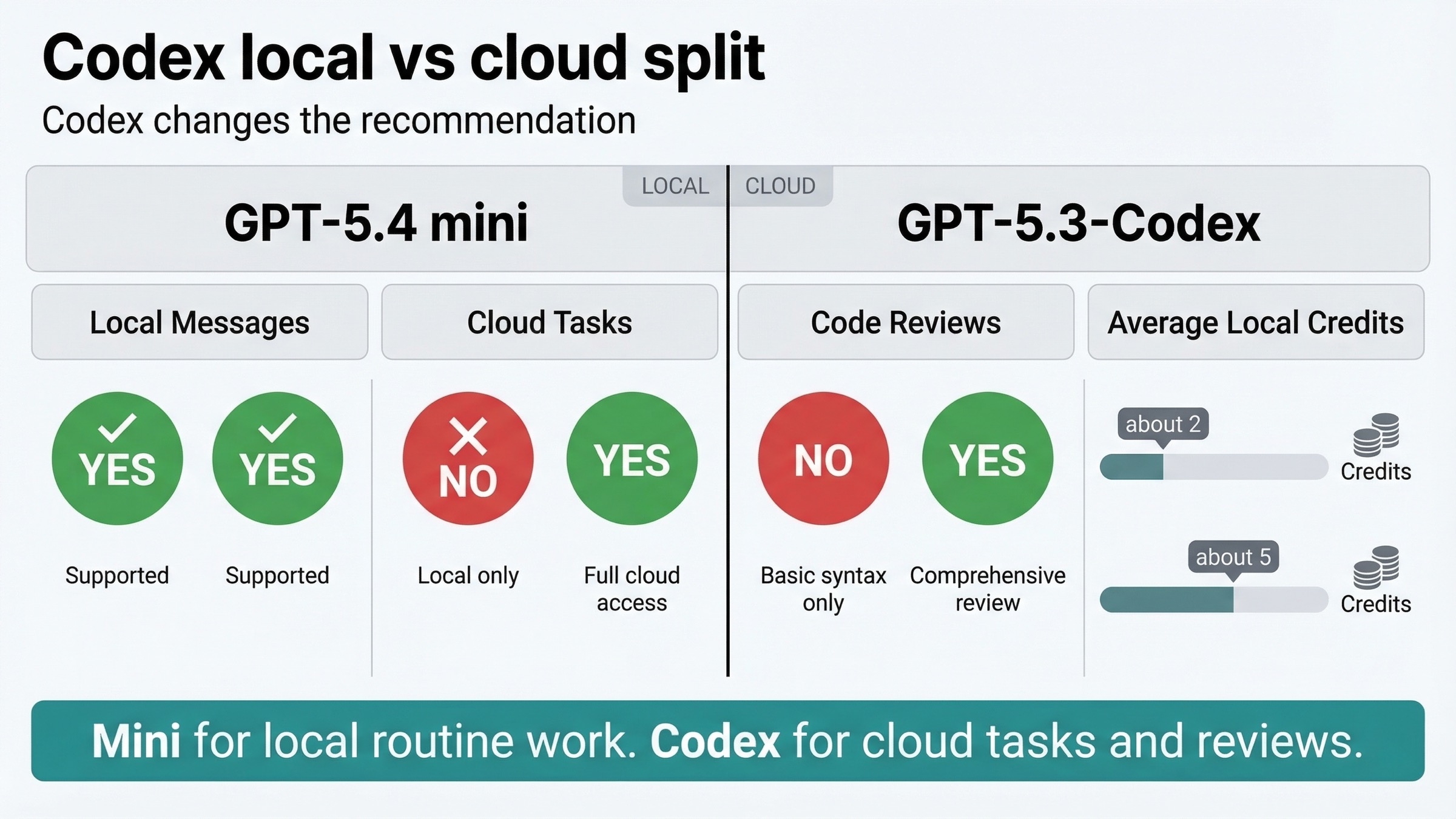
Именно этот слой чаще всего теряется в текущих comparison pages.
Внутри Codex GPT-5.4 mini не является полным replacement для GPT-5.3-Codex.
Текущая страница Codex pricing говорит:
- GPT-5.4 mini даёт до 3.3x higher local-message limits
- средняя локальная задача на GPT-5.4 mini стоит около 2 credits
- средняя локальная задача на GPT-5.3-Codex стоит около 5 credits
Это делает GPT-5.4 mini очень привлекательным для:
- routine local coding tasks,
- дешёвых локальных правок,
- быстрого file read/edit work,
- high-volume supporting work в Codex app, CLI, IDE extension или web.
Но на той же странице есть решающее ограничение:
| Возможность Codex | GPT-5.4 mini | GPT-5.3-Codex |
|---|---|---|
| Local messages | Yes | Yes |
| Cloud tasks | No | Yes |
| Code reviews | No | Yes |
Это самый важный продуктовый факт во всей статье.
Если ваш Codex workflow опирается на cloud tasks или GitHub code reviews, GPT-5.4 mini сегодня не заменяет GPT-5.3-Codex полностью.
Поэтому в Codex правильная рекомендация распадается на две:
- локальная рутина в Codex: GPT-5.4 mini
- облачные задачи и reviews в Codex: GPT-5.3-Codex
Именно из-за этого в марте 2026 в сообществе было много путаницы: люди наблюдали изменение доступности моделей в разных интерфейсах и тарифах, но эти discussion threads не меняют более устойчивого product fact. GPT-5.4 mini и GPT-5.3-Codex сейчас занимают разные рабочие места внутри Codex.
Какую модель брать под конкретный workflow
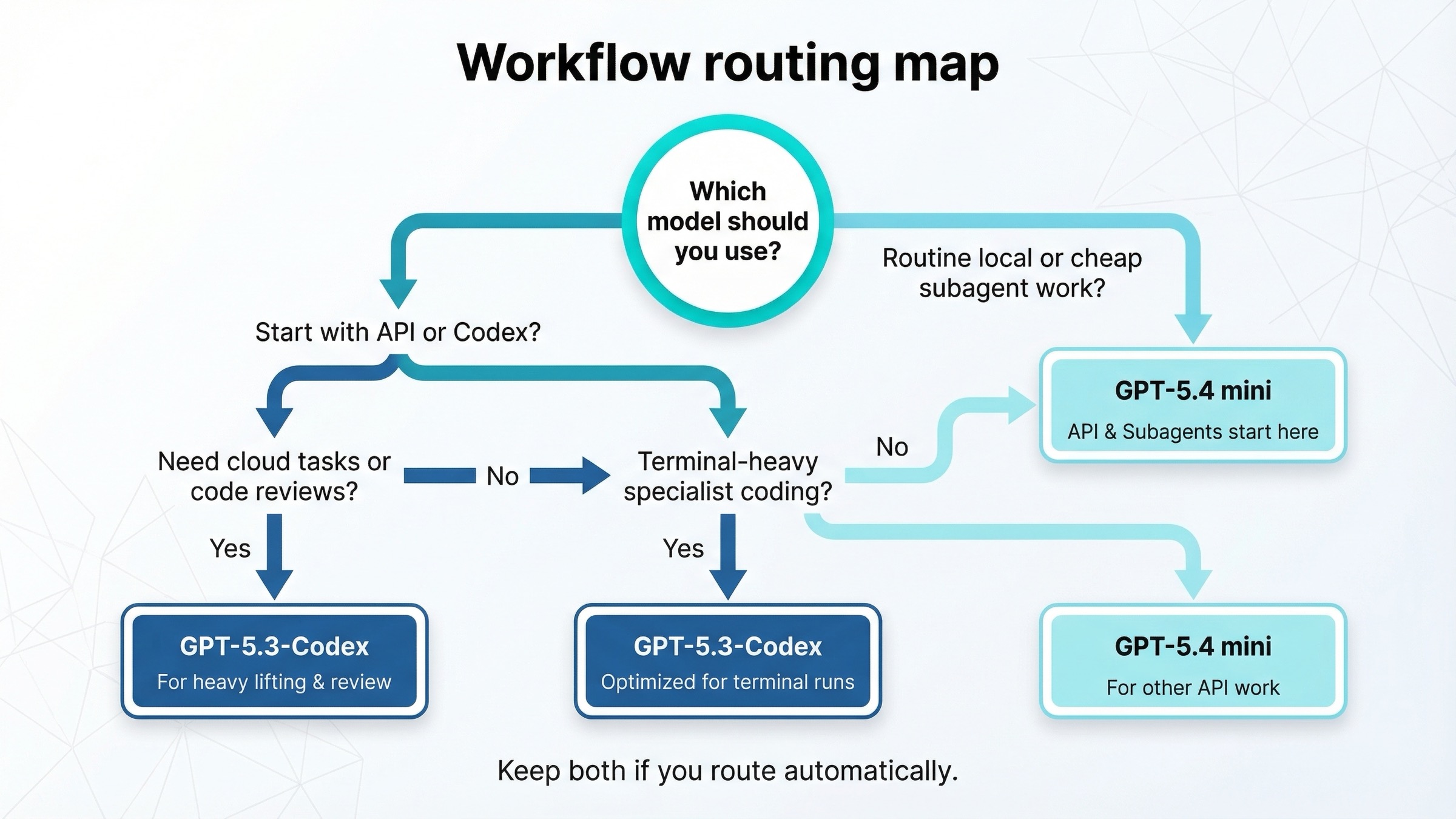
Ниже - сжатая routing table, которую реально можно использовать в продакшне:
| Workflow | GPT-5.4 mini | GPT-5.3-Codex | Почему |
|---|---|---|---|
| Новый API default для coding workers | Yes | Rarely | GPT-5.4 mini дешевле, новее и шире по tools |
| Дешёвые subagents под большим planner | Yes | Rarely | Это ровно та роль, которую OpenAI сейчас отводит mini |
| Screenshot-heavy или computer-use-like worker | Yes | Sometimes | OSWorld и tool posture сильнее у GPT-5.4 mini |
| Terminal-heavy engineering | Sometimes | Yes | У GPT-5.3-Codex слишком большой перевес в Terminal-Bench |
| Локальная рутина в Codex | Yes | Sometimes | GPT-5.4 mini растягивает local quotas заметно дальше |
| Codex cloud tasks | No | Yes | Только GPT-5.3-Codex закрывает эту поверхность |
| Codex GitHub code reviews | No | Yes | Здесь слот всё ещё у GPT-5.3-Codex |
| Один specialist model для тяжёлых coding loops | Sometimes | Yes | GPT-5.3-Codex остаётся более specialist choice |
Для обычной API-команды вывод простой: начните с GPT-5.4 mini и маршрутизируйте в GPT-5.3-Codex только задачи, которые действительно выглядят specialist coding или terminal-heavy.
Для power users в Codex хороший ответ часто вообще не «или-или», а оба:
- GPT-5.4 mini для дешёвой локальной рутины
- GPT-5.3-Codex для cloud tasks, code reviews и более тяжёлого coding lane
Это лучше, чем пытаться протащить все задания через одну модель просто потому, что она либо новее, либо specialist.
Когда GPT-5.3-Codex всё ещё имеет смысл
Слишком много страниц выдают упрощённую формулу «GPT-5.4 mini новее, значит используйте только его». Это быстрее написать, но хуже для принятия решений.
GPT-5.3-Codex остаётся логичным выбором как минимум в четырёх ситуациях.
Во-первых, terminal-heavy work. Если ваш реальный день выглядит как shell loops, отладка в репозитории, сборка, тестовые циклы и CLI-инструменты, у GPT-5.3-Codex по-прежнему самый сильный evidence profile.
Во-вторых, Codex cloud workflows. Это самый чистый аргумент. Нужны cloud tasks - держите GPT-5.3-Codex.
В-третьих, Codex code reviews. Для команд, где GitHub review flow - часть ключевого процесса, этот пункт не факультативен.
В-четвёртых, fallback routing. Некоторые команды вообще не должны искать одного вечного победителя. Гораздо полезнее такое правило:
- mini first для дешёвой текущей работы,
- Codex second для specialist coding и Codex cloud surfaces.
Это здоровее, чем по инерции держать старый specialist model в роли universal default.
Если вам нужен ещё один ориентир по coding-моделям OpenAI, полезно посмотреть наш разбор GPT-5.3 Codex против Claude Opus 4.6.
FAQ
GPT-5.4 mini лучше GPT-5.3-Codex для coding в целом?
Не во всех coding-бенчмарках. GPT-5.3-Codex всё ещё сильнее на SWE-Bench Pro и намного сильнее на Terminal-Bench 2.0. Но GPT-5.4 mini значительно дешевле в API, находится в текущей recommended mini-линии и лучше выглядит для screenshot-heavy и computer-use-adjacent задач.
Почему default recommendation всё равно за GPT-5.4 mini, если GPT-5.3-Codex сильнее в coding benchmarks?
Потому что default recommendation строится не по одной строке таблицы, а по общей operating picture: цена, tool support, rate limits, product direction и тот факт, что многие современные coding systems - это уже не чистые terminal agents, а гибридные tool-and-agent systems.
Заменяет ли GPT-5.4 mini GPT-5.3-Codex внутри Codex?
Нет, не полностью. GPT-5.4 mini отлично подходит для локальной рутины, но по текущему Codex pricing page у него нет cloud tasks и code reviews. На этих направлениях GPT-5.3-Codex по-прежнему обязателен.
С какой модели новой команде начинать тесты?
Для API - с GPT-5.4 mini. Для Codex-heavy команд - с двухполосной схемы: GPT-5.4 mini для локальной рутины и GPT-5.3-Codex для cloud tasks, reviews и тяжёлого terminal-first coding.
Финальная рекомендация
Если вам нужна одна фраза для команды, используйте такую: GPT-5.4 mini - правильный default для новых API и subagent workflows, но GPT-5.3-Codex всё ещё нужно держать там, где работа terminal-heavy или зависит от Codex cloud tasks и reviews.
Этот вывод сильнее, чем банальная схема «новее против старее», потому что он соответствует фактической продуктовой реальности марта 2026:
- GPT-5.4 mini дешевле и привлекательнее в API
- GPT-5.3-Codex удерживает более сильный specialist coding profile
- поведение Codex делает модели не взаимозаменяемыми
Зрелая архитектура здесь - не в том, чтобы стереть одну модель другой, а в том, чтобы дисциплинированно дать каждой модели её правильную полосу.