
В феврале 2026 года произошёл беспрецедентный выпуск передовых ИИ-моделей буквально за несколько недель, и пространство сравнений уже заполнено устаревшими ценами и поверхностными таблицами бенчмарков. После проверки каждого показателя непосредственно на официальных страницах можно с уверенностью сказать: единого победителя среди Gemini 3.1 Pro, Claude Opus 4.6 и GPT-5.3-Codex не существует. Каждая модель доминирует в своей области: Gemini лидирует в научных рассуждениях и эффективности затрат при $2 за миллион входных токенов, Opus превосходит всех в агентном программировании благодаря уникальной архитектуре Agent Teams, а Codex обеспечивает непревзойдённую скорость автономного выполнения задач через изолированную среду. Далее следует наиболее тщательно проверенное сравнение, доступное на март 2026 года.
Краткое содержание
Прежде чем углубляться в детали, ознакомьтесь с основным сравнением по параметрам, которые наиболее важны для разработчиков, принимающих решения о продакшен-инфраструктуре прямо сейчас. Каждая цена в этой таблице была проверена непосредственно на официальных страницах с помощью автоматизации браузера 2 марта 2026 года, и мы обнаружили, что несколько конкурирующих статей приводят некорректные данные о ценах, особенно для Opus 4.6. Это критически важно, потому что разработчики, принимающие инфраструктурные решения на основе неверных цен, могут легко ошибиться на тысячи долларов в месяц, что приведёт либо к напрасной трате ресурсов, либо к непредвиденному перерасходу, вынуждающему менять модель посреди проекта.
| Характеристика | Gemini 3.1 Pro | Claude Opus 4.6 | GPT-5.3-Codex |
|---|---|---|---|
| Дата выпуска | 19 фев 2026 | 5 фев 2026 | Фев 2026 |
| Цена за вход | $2/MTok | $5/MTok | Нет в API |
| Цена за выход | $12/MTok | $25/MTok | Нет в API |
| Окно контекста | 1M (GA) | 200K / 1M (бета) | 400K |
| Макс. выход | 64K | 128K | 128K |
| Лучший бенчмарк | ARC-AGI-2: 77,1% | SWE-Bench: 80,8% | Terminal-Bench: 77,3% |
| Сильная сторона | Исследования, наука, длинный контекст | Сложный код, агенты | Автономное выполнение |
| Доступ через API | Стандартный API | Стандартный API | Только продукты Codex |
Самый важный вывод заключается в том, что GPT-5.3-Codex не имеет отдельной цены на API на странице OpenAI. Модель доступна исключительно через приложение Codex, CLI, расширения для IDE и GitHub Copilot, что фундаментально отличает её от двух других моделей по способу интеграции в рабочий процесс. Если вам нужен прямой вызов API с потокенной оплатой, ваш реальный выбор сводится к Gemini 3.1 Pro и Claude Opus 4.6, и решение зависит от того, что важнее: экономическая эффективность и широта рассуждений или глубина агентного программирования и надёжность. Мы подробно рассматриваем каждый из этих аспектов ниже, начиная с результатов бенчмарков, определяющих конкурентную территорию каждой модели, затем переходя к реальности ценообразования, которую большинство статей описывает неверно, и завершая практической системой принятия решений, которая сопоставит ваш конкретный рабочий процесс с правильным выбором модели.
Бенчмарки лицом к лицу — кто побеждает и в чём
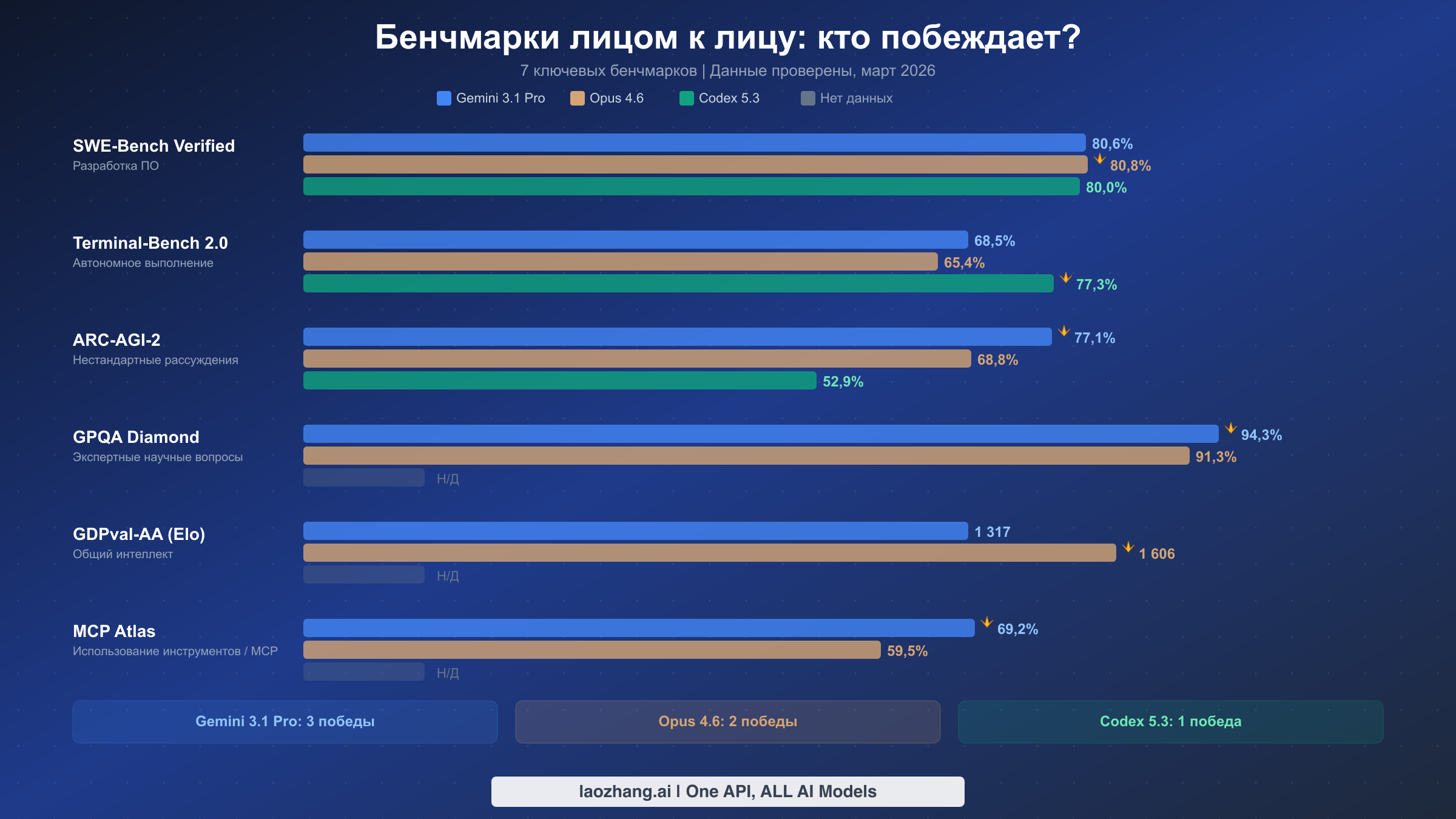
Ландшафт бенчмарков для этих трёх моделей выявляет закономерность, которая опровергает упрощённый нарратив «одна модель для всего». Каждая модель заняла свою отчётливую территорию, и понимание сильных сторон каждой требует не просто взгляда на числа, а осознания того, что именно измеряют эти бенчмарки.
SWE-Bench Verified, золотой стандарт оценки разработки ПО, демонстрирует невероятно плотную гонку. Opus 4.6 вырывается вперёд с показателем 80,8%, за ним следуют Gemini 3.1 Pro с 80,6% и Codex 5.3 с 80,0%. Разница здесь находится в пределах дисперсии для большинства практических задач, что означает: все три модели примерно равноценны в решении реальных задач на GitHub. Это примечательно, потому что ещё полгода назад существовал явный разрыв между лидирующей моделью и остальными. Для более глубокого погружения в сравнение Opus и Codex именно по задачам программирования ознакомьтесь с нашим подробным сравнением Opus 4.6 и GPT-5.3.
Terminal-Bench 2.0 рассказывает совершенно другую историю — именно здесь Codex 5.3 по-настоящему блистает с результатом 77,3%, значительно опережая Gemini (68,5%) и Opus (65,4%). Этот бенчмарк измеряет способность к автономному выполнению, то есть умение модели работать с терминалом, запускать команды, отлаживать сбои и завершать многоэтапные задачи без вмешательства человека. Лидерство Codex здесь логично, учитывая, что модель была специально разработана для изолированных сред выполнения, где она может свободно запускать код, проверять результаты и итеративно улучшать решения. Это бенчмарк, который наиболее важен, если ваш сценарий использования предполагает передачу целых задач ИИ-агенту с ожиданием готового результата.
ARC-AGI-2 измеряет способность к нестандартным рассуждениям, и Gemini 3.1 Pro доминирует с 77,1% по сравнению с 68,8% у Opus и 52,9% у Codex. Это самый большой разрыв между любыми двумя моделями по любому бенчмарку, и он отражает инвестиции Google в возможности рассуждений через архитектуру Mixture-of-Experts. Бенчмарк ARC-AGI-2 специально тестирует способность решать задачи, которые модель никогда раньше не видела, что делает его показателем общего интеллекта, а не сопоставления с паттернами из обучающих данных.
GPQA Diamond, который тестирует ответы на научные вопросы экспертного уровня, показывает Gemini 3.1 Pro на уровне 94,3% против 91,3% у Opus 4.6. У Codex 5.3 нет опубликованного результата по этому бенчмарку. Разрыв в три процентных пункта здесь значим, потому что вопросы GPQA Diamond спроектированы как сложные даже для экспертов с докторской степенью. Если ваш рабочий процесс включает научные исследования, медицинские рассуждения или сложные аналитические задачи, Gemini имеет измеримое преимущество.
GDPval-AA, измеряемый в рейтинге Elo, показывает лидерство Opus 4.6 с 1606 по сравнению с 1317 у Gemini. Этот бенчмарк оценивает общее следование инструкциям и когерентность в диалоге — область, где подход Anthropic к обучению Constitutional AI приносит дивиденды. Разрыв в 289 пунктов Elo существенен и говорит о том, что Opus выдаёт более стабильно качественные, нюансированные ответы в разговорных сценариях. Для целенаправленного сравнения этих двух моделей ознакомьтесь с нашим детальным анализом Gemini 3.1 Pro и Opus 4.6.
Отдельно стоит упомянуть MCP Atlas, который измеряет эффективность использования моделями внешних инструментов через Model Context Protocol. Gemini 3.1 Pro набирает 69,2% по сравнению с 59,5% у Opus 4.6, у Codex 5.3 результат не опубликован. Это особенно актуально для разработчиков, создающих агентные приложения, где модель должна оркестрировать вызовы к базам данных, API и файловым системам. Лидерство Gemini здесь указывает на то, что его архитектура MoE маршрутизирует запросы, связанные с использованием инструментов, к специализированным экспертам, которые более эффективно обрабатывают схемы API и генерацию параметров.
Итог таков: ни одна модель не побеждает во всех бенчмарках. Gemini 3.1 Pro лидирует в рассуждениях и науке (3 победы в бенчмарках, включая ключевые ARC-AGI-2 и MCP Atlas), Opus 4.6 лидирует в качестве кода и общем интеллекте (2 победы в SWE-Bench и GDPval-AA), а Codex 5.3 доминирует в автономном выполнении (1 победа в Terminal-Bench, но с решающим отрывом в 12 пунктов). Ваш выбор должен определяться тем, какая категория бенчмарков наиболее точно соответствует вашей реальной рабочей нагрузке, и для большинства команд это означает честную оценку того, где находится ваше узкое место — в качестве рассуждений, корректности кода или автоматизации выполнения.
Реальные цены — сколько на самом деле стоят эти модели в 2026 году
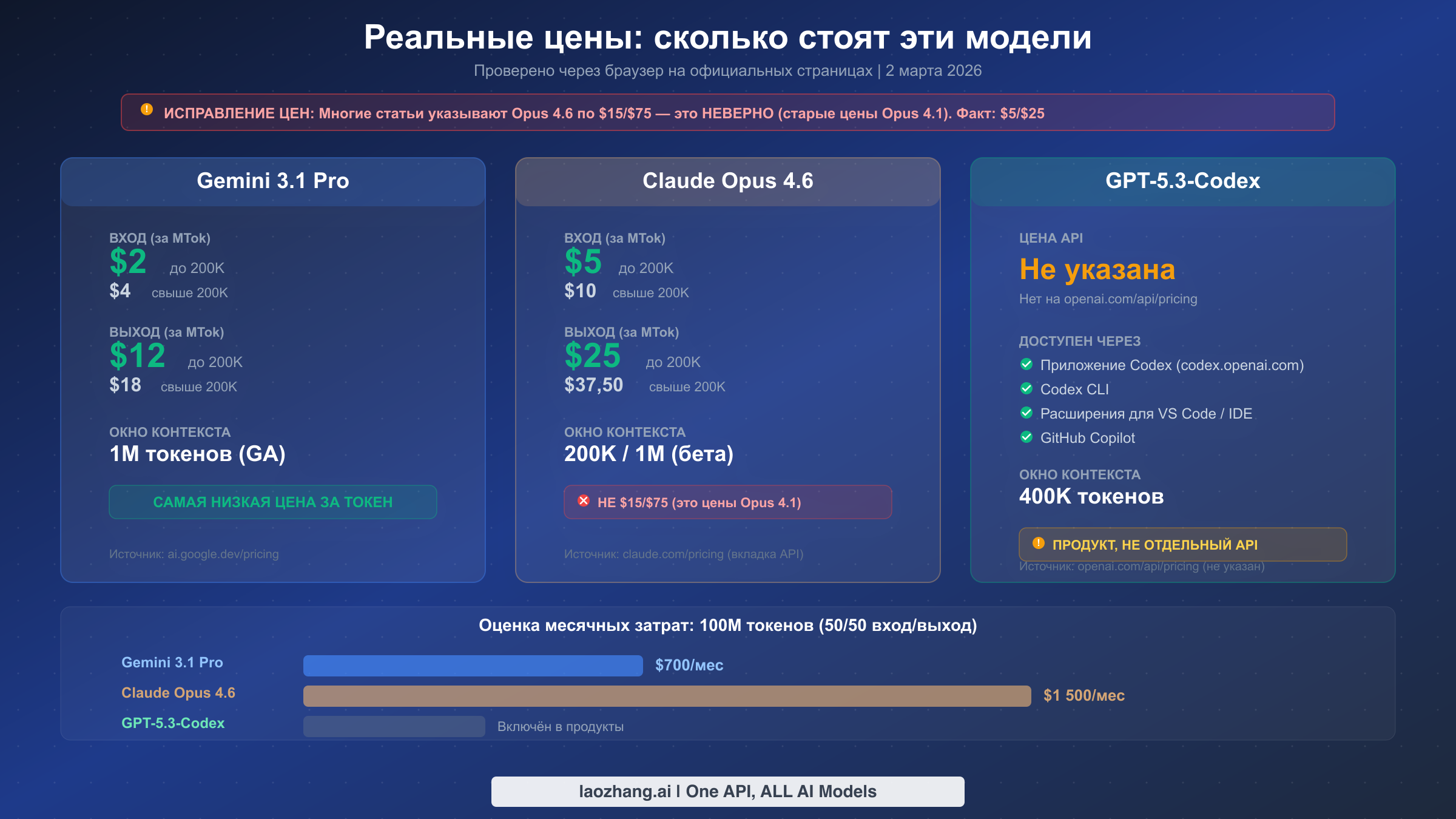
Именно в ценообразовании мы обнаружили наибольшее количество опасной дезинформации в существующих сравнительных статьях. Множество статей из топа выдачи указывают цену Claude Opus 4.6 как $15 за миллион входных токенов и $75 за миллион выходных токенов. Это неверно. Это цены предыдущего поколения Opus 4.1 и 4.0. Реальная цена Opus 4.6, проверенная непосредственно на claude.com/pricing 2 марта 2026 года, составляет $5 за миллион входных токенов и $25 за миллион выходных токенов для промптов до 200K контекста. Для более длинных промптов, превышающих 200K токенов, цена увеличивается до $10 за вход и $37,50 за выход на миллион токенов.
Gemini 3.1 Pro предлагает наиболее конкурентоспособную цену за токен среди всех передовых моделей, доступных через стандартный API. При стоимости $2 за миллион входных токенов и $12 за миллион выходных токенов (проверено на ai.google.dev/pricing 2 марта 2026 года) он на 60% дешевле Opus 4.6 на входе и на 52% дешевле на выходе. Для промптов, превышающих 200K токенов, цена Gemini удваивается до $4 за вход и $18 за выход, что всё равно существенно дешевле расширенных тарифов Opus. Если вы выполняете высоконагруженные задачи инференса и стоимость является приоритетом, это ценовое преимущество быстро накапливается. Подробности о тарифных планах и скидках Gemini смотрите в нашей статье о ценах API Gemini на 2026 год.
GPT-5.3-Codex представляет совершенно иную модель ценообразования, потому что он вообще не появляется на странице цен API OpenAI. Мы проверили это, перейдя на openai.com/api/pricing 2 марта 2026 года, и обнаружили, что GPT-5.2 указан по цене $1,75/$14 за миллион токенов, но GPT-5.3-Codex отсутствовал. Это означает, что вы не можете вызывать его через стандартную конечную точку API с потокенной оплатой. Вместо этого вы получаете доступ через продукты Codex: веб-приложение по адресу codex.openai.com, Codex CLI, расширения для IDE или GitHub Copilot. Стоимость включена в вашу существующую подписку на OpenAI или GitHub, а не тарифицируется за токены, что затрудняет прямое сравнение затрат с двумя другими моделями.
Совокупная стоимость владения: три реальных сценария
Чтобы сделать ценообразование практичным, рассмотрим три сценария использования с оценкой месячных затрат:
Сценарий 1: Индивидуальный разработчик (10M токенов/месяц, соотношение вход/выход 60/40). Для разработчика, использующего ИИ-помощника для кодирования на протяжении всего рабочего дня, Gemini 3.1 Pro обойдётся примерно в $60 в месяц, тогда как Opus 4.6 — примерно в $130. Codex 5.3 фактически включён в подписку ChatGPT Pro за $200/месяц или корпоративную подписку GitHub Copilot, что делает его выгодным только если вы уже платите за эти сервисы.
Сценарий 2: Конвейер ревью кода для малой команды (100M токенов/месяц, соотношение вход/выход 70/30). Команда из 5-10 разработчиков, запускающих автоматизированное ревью кода, потратит примерно $500 в месяц на Gemini 3.1 Pro против примерно $1100 на Opus 4.6. При таком масштабе ценовой разрыв становится значимым, и командам следует серьёзно оценить, оправдывают ли улучшения качества кода Opus 2,2-кратную ценовую наценку. Для команд, уже использующих сервисы агрегации API, такие как laozhang.ai, единый биллинг по нескольким моделям может упростить управление затратами при сохранении конкурентных тарифов.
Сценарий 3: Корпоративный агентный конвейер (1B токенов/месяц, соотношение 50/50). В корпоративном масштабе Gemini 3.1 Pro обходится примерно в $7000 в месяц, тогда как Opus 4.6 — примерно в $15 000. Однако Anthropic предлагает значительные скидки на пакетную обработку (50%) и скидки на кэширование промптов, которые могут существенно сократить этот разрыв. Для полного разбора тарифов Claude смотрите наш полный гид по ценам Claude API.
Решение по ценообразованию в конечном итоге зависит от того, оправдывает ли разница в качестве между моделями ценовую надбавку для вашего конкретного сценария использования. Для задач с интенсивными рассуждениями Gemini предлагает лучшее соотношение цена-качество. Для сложных задач программирования, где разница в качестве транслируется в меньшее количество багов и меньше доработок, наценка Opus может окупиться.
Как получить доступ к каждой модели — API, CLI и не только
Один из наиболее неверно понимаемых аспектов этого тройного сравнения — как вы фактически получаете доступ к каждой модели. В то время как Gemini 3.1 Pro и Claude Opus 4.6 следуют привычному паттерну «получи API-ключ и делай HTTP-запросы», GPT-5.3-Codex полностью отходит от этой модели, и понимание этого различия критически важно перед тем, как привязать свою команду к конкретному рабочему процессу.
Gemini 3.1 Pro доступен через Google AI Studio и платформу Vertex AI. Вы генерируете API-ключ на ai.google.dev, и вызовы следуют стандартному REST-паттерну с идентификатором модели gemini-3.1-pro-preview. Google также предоставляет клиентские библиотеки для Python, JavaScript, Go и других языков. В настоящее время модель имеет статус «Preview», что означает, что Google может вносить ломающие изменения до GA, но на практике API стабилен с момента запуска. Заметным преимуществом является бесплатный тариф Gemini с щедрыми лимитами запросов, что делает модель доступной для экспериментов без привязки кредитной карты.
Claude Opus 4.6 доступен через API Anthropic с идентификатором модели claude-opus-4-6. Для доступа требуется API-ключ с console.anthropic.com. Anthropic предоставляет официальные SDK для Python и TypeScript, и API следует чистому, хорошо документированному формату. Opus 4.6 уже имеет статус Generally Available (GA), что означает стабильность API и готовность к продакшену. Модель также доступна через Claude.ai, Claude Code (CLI-инструмент Anthropic) и различные интеграции с IDE. Для агентных сценариев Opus 4.6 поддерживает функцию Agent Teams через Claude Code, позволяя порождать субагентов, работающих параллельно над сложными задачами.
GPT-5.3-Codex требует принципиально другого подхода. На API OpenAI отсутствует конечная точка gpt-5.3-codex. Вместо этого вы получаете доступ через четыре канала: веб-приложение Codex по адресу codex.openai.com, где вы назначаете задачи, которые модель выполняет асинхронно в изолированных средах; Codex CLI, интегрируемый в ваш рабочий процесс в терминале; расширения для IDE для VS Code и JetBrains; и GitHub Copilot, где модель Codex обеспечивает работу ИИ-помощника. Этот продуктовый подход означает, что Codex превосходно справляется с полным выполнением задач (написать функцию, исправить баг, создать PR), а не с потоковой генерацией токенов. Если ваш рабочий процесс уже строится вокруг GitHub и вам нужен ИИ, способный автономно завершать пулл-реквесты, Codex создан именно для этого. Но если вам нужно встраивать вызовы модели в собственные приложения с потокенным контролем, Codex — не тот выбор.
Практические последствия этих различных паттернов доступа значительны для архитектурных решений. Если вы создаёте продукт, которому нужно программно вызывать ИИ-модели с тонким контролем над использованием токенов, параметрами модели и потоковой передачей ответов, то ваши варианты — Gemini 3.1 Pro и Claude Opus 4.6. Если вам нужен ИИ, который работает скорее как младший разработчик, принимающий описания задач и возвращающий готовую работу, Codex 5.3 спроектирован именно для этого. Многие продвинутые команды используют оба подхода: модели на базе API для интерактивных пользовательских функций и Codex для фоновых задач автоматизации, таких как генерация тестов и обновление документации.
Для команд, которым нужна гибкость работы с несколькими моделями, платформы агрегации API могут упростить мультимодельные рабочие процессы. Такой сервис, как laozhang.ai, предоставляет единую конечную точку API, поддерживающую модели Gemini и Claude, что позволяет командам маршрутизировать запросы к оптимальной модели без управления множеством API-ключей и систем биллинга. Это особенно ценно в текущий период быстрых релизов моделей, когда оптимальная модель для определённого типа задач может меняться от квартала к кварталу, и вам нужна гибкость для переключения без переписывания интеграционного кода.
Под капотом — почему каждая модель превосходит в своей области

Понимание архитектуры объясняет «почему» за результатами бенчмарков, и именно здесь большинство сравнительных статей терпят неудачу. Они сообщают, какие баллы набирает каждая модель, но не объясняют, почему она набирает именно столько. Архитектурные различия между этими тремя моделями — не просто академические курьёзы; они напрямую предсказывают, с какими нагрузками каждая модель справится лучше всего.
Архитектура Mixture-of-Experts (MoE) Gemini 3.1 Pro — ключ как к его превосходству в рассуждениях, так и к экономической эффективности. Вместо активации всей нейронной сети для каждого запроса MoE избирательно маршрутизирует каждый вход к небольшому количеству специализированных «экспертных» подсетей. Представьте это как команду специалистов, где для каждой задачи привлекаются только релевантные. Именно поэтому Gemini может поддерживать огромное общее количество параметров (обеспечивая высокую производительность на разнообразных задачах), сохраняя низкую стоимость инференса (потому что для каждого запроса активируется лишь часть параметров). Дизайн MoE особенно выгоден для научных и математических рассуждений, потому что модель может маршрутизировать сложные аналитические запросы к экспертам, специально обученным в этих доменах. Это также объясняет, почему Gemini предлагает самое большое окно контекста в продакшене — 1 миллион токенов в General Availability: эффективная маршрутизация экспертов делает обработку длинного контекста вычислительно осуществимой в масштабе.
Плотная трансформерная архитектура Claude Opus 4.6 с Constitutional AI представляет иную философию. Вместо маршрутизации к специалистам каждый параметр участвует в каждом вычислении, что обеспечивает более последовательные и нюансированные результаты ценой более высокой стоимости инференса. Прорывная инновация в Opus 4.6 — цикл GVR (Generate-Verify-Reflect) для задач программирования: модель генерирует код, выполняет проверки и затем анализирует результаты перед итерацией — процесс, который имитирует работу опытных разработчиков. Этот самокорректирующийся цикл объясняет, почему Opus лидирует в SWE-Bench и производит меньше багов на практике. Архитектура Agent Teams расширяет эту концепцию, позволяя Opus порождать субагентов, работающих над разными частями задачи одновременно, что, по данным Anthropic, привело к обнаружению более 500 zero-day уязвимостей в крупных проектах с открытым исходным кодом. Поведенческая характеристика Opus, подтверждённая отзывами разработчиков из JetBrains и Databricks, заключается в том, что модель задаёт уточняющие вопросы перед реализацией, что приводит к решениям, более точно соответствующим замыслу разработчика.
Оптимизированный вариант GPT-5 в GPT-5.3-Codex создан специально для скорости и автономного выполнения. Его определяют две инновации: во-первых, режим Spark, достигающий 1000+ токенов в секунду, что делает его примерно на 25% быстрее GPT-5.2 и существенно быстрее как Gemini, так и Opus в чистой скорости генерации. Во-вторых, модель работы в изолированной среде, где Codex функционирует в обособленных облачных окружениях с полным доступом к git, командам терминала и фреймворкам тестирования. Именно поэтому Codex доминирует в Terminal-Bench: он не просто генерирует код, который должен работать — он реально запускает код, наблюдает за выходом, отлаживает сбои и итерирует до тех пор, пока задача не пройдёт все тесты. Поведенческий паттерн здесь противоположен Opus: Codex сначала реализует, а вопросы задаёт потом, быстро прототипируя решения и итерируя по результатам ошибок, а не планируя заранее. Более подробное сравнение GPT-5.3 Codex и Opus 4.6 в практических сценариях программирования мы рассмотрели в отдельной статье.
Различия в методологиях обучения не менее важны. Подход Google к Gemini включает нативное обучение на нескольких модальностях данных — тексте, коде, изображениях, аудио и видео — с самого начала, а не дообучение текстовой модели для работы с другими модальностями. Это нативное мультимодальное обучение объясняет, почему Gemini более естественно обрабатывает входные данные смешанных модальностей, например, одновременное понимание скриншота UI и текстового описания желаемых изменений. Обучение Anthropic для Opus делает акцент на Constitutional AI, где модель учится оценивать и улучшать собственные результаты в соответствии с набором принципов, формируя то осторожное, самокорректирующееся поведение, которое разработчики замечают на практике. Обучение OpenAI для Codex было сфокусировано именно на выполнении кода и использовании инструментов, с обширным обучением с подкреплением на основе обратной связи от человека по качеству генерации кода и автономному завершению задач.
Эти архитектурные и обучающие различия создают чёткие импликации для выбора модели. Если вам нужно наибольшее количество обработанных токенов на доллар с сильными рассуждениями по модальностям, оптимальна Gemini на базе MoE. Если вам нужна наивысшее качество генерации кода с тщательным планированием и самокоррекцией, выбор за Opus на плотном трансформере. Если вам нужно максимально быстрое автономное завершение задач с возможностью запуска, тестирования и итерации без участия человека, побеждает подход Codex с приоритетом выполнения.
Какую модель выбрать — система принятия решений для разработчика
Вместо того чтобы предлагать обобщённый ответ «зависит от ситуации», представляем конкретную систему принятия решений на основе пяти типов разработчиков, соответствующих распространённым реальным сценариям. Определите, какой тип наиболее точно описывает ваш рабочий процесс, и рекомендация по модели станет очевидной.
Тип 1: Самостоятельный фулстек-разработчик, создающий SaaS-продукт, которому нужна модель, способная справляться с разнообразными задачами от фронтенд-компонентов на React до проектирования бэкенд-API и запросов к базам данных, а стоимость критична, потому что каждый рубль идёт из личных сбережений или небольшого посевного раунда. Рекомендация — Gemini 3.1 Pro в качестве основной модели. Широта рассуждений благодаря архитектуре MoE хорошо справляется с разнообразными фулстек-задачами, контекстное окно в 1M токенов позволяет загружать целые кодовые базы для контекста, а цена $2/MTok за вход означает управляемый ежемесячный счёт. Используйте Opus 4.6 избирательно для сложных архитектурных решений или запутанных сессий отладки, где дополнительное качество стоит наценки.
Тип 2: Бэкенд-инженер по инфраструктуре, работающий с распределёнными системами, микросервисами и DevOps-пайплайнами, которому нужна глубокая техническая точность и тщательный анализ, а не скорость. Рекомендация — Claude Opus 4.6. Цикл GVR ловит тонкие баги конкурентности и пограничные случаи, которые другие модели пропускают, поведенческий паттерн «сначала спрашивает» идеально подходит для инфраструктурной работы, где ошибка может вызвать сбой в продакшене, а функция Agent Teams трансформирует задачи рефакторинга, затрагивающие несколько сервисов одновременно. Ценовая наценка в 2,5 раза по сравнению с Gemini окупается, когда один баг в продакшене обходится компании в тысячи долларов на реагирование на инцидент.
Тип 3: Инженерный менеджер, руководящий командой из 10+ разработчиков, которому нужен ИИ для автономной обработки рутинных задач — ревью PR, исправления багов, генерации тестов — освобождая инженеров для творческой работы. Рекомендация — GPT-5.3-Codex через GitHub Copilot или Codex CLI. Модель работы в изолированной среде позволяет назначать задачи и получать готовые PR, результат 77,3% в Terminal-Bench отражает реальную способность автономного завершения задач, а продуктовое ценообразование предсказуемо независимо от объёма потребления токенов. Ограничение заключается в том, что Codex сильнее всего внутри экосистемы GitHub; если ваша команда использует GitLab или Bitbucket, история интеграции слабее.
Тип 4: ИИ-исследователь или дата-сайентист, работающий над нестандартными задачами, требующими научного рассуждения, математических доказательств или анализа больших наборов данных, которому нужны сильнейшие способности к рассуждению независимо от функций, специфичных для программирования. Рекомендация — Gemini 3.1 Pro, однозначно. Результат 77,1% в ARC-AGI-2 (на 24 пункта впереди ближайшего конкурента) и 94,3% в GPQA Diamond делают его очевидным выбором для исследовательской работы. Контекстное окно GA в 1M токенов также уникально ценно для анализа больших статей, наборов данных или результатов экспериментов в одном промпте.
Тип 5: Корпоративный архитектор, оценивающий модели для развёртывания по всей организации в различных командах, которому нужна надёжность, безопасность и гибкость больше, чем любая отдельная способность. Рекомендация — мультимодельная стратегия. Используйте Gemini 3.1 Pro как модель по умолчанию для общих запросов и экономической эффективности, Opus 4.6 для сложного программирования и задач, чувствительных к безопасности, где обучение Constitutional AI обеспечивает дополнительные гарантии безопасности, и Codex 5.3 через GitHub Copilot для продуктивности разработчиков. Этот подход также обеспечивает естественную диверсификацию поставщиков, защищая от сбоев, изменений цен или объявлений об устаревании от любого отдельного провайдера. Предприятие, работающее исключительно на одном провайдере моделей, несёт концентрационный риск, который всё труднее оправдать, учитывая, насколько просто интегрировать несколько моделей через стандартизированные паттерны API. Именно этот подход мы подробнее рассматриваем в следующем разделе.
Построение мультимодельной стратегии для продакшена
Наиболее продвинутые инженерные команды в 2026 году не выбирают одну модель. Они строят маршрутизирующие архитектуры, которые направляют каждый запрос к оптимальной модели на основе типа задачи, требуемого уровня качества и бюджетных ограничений. Этот подход позволяет извлечь лучшее из всех трёх моделей, интеллектуально управляя затратами.
Основной паттерн — маршрутизатор моделей, который классифицирует входящие запросы и маршрутизирует их соответственно. На высоком уровне логика маршрутизации выглядит так: запросы с интенсивными рассуждениями (исследования, анализ, научные вопросы) направляются к Gemini 3.1 Pro за его превосходную производительность в ARC-AGI-2 и GPQA Diamond при минимальной стоимости; сложные задачи программирования (рефакторинг, архитектура, аудит безопасности) направляются к Opus 4.6 за его лидирующее качество в SWE-Bench и самокорректирующийся цикл GVR; задачи автономного выполнения (создание PR, генерация тестов, рутинное исправление багов) направляются к Codex 5.3 через его продуктовые интеграции за его доминирующие показатели в Terminal-Bench.
Практическая реализация обычно включает три уровня. Первый — уровень классификации, определяющий тип задачи по запросу пользователя или контексту приложения. Второй — уровень маршрутизации, сопоставляющий типы задач с моделями на основе настраиваемых правил. Третий — уровень резервирования, обрабатывающий недоступность модели, ограничения частоты запросов или непредвиденные ошибки путём маршрутизации к альтернативной модели. Многие команды реализуют это через сервисы агрегации API, которые абстрагируют отдельные API моделей в единую конечную точку, делая логику маршрутизации чище, а биллинг — консолидированным.
Оптимизация затрат в мультимодельной установке выходит за рамки простого выбора самой дешёвой модели. Кэширование контекста Gemini может снизить затраты до 75% для повторных промптов с общими префиксами. Anthropic предлагает 50% скидку на пакетные API-запросы для Opus, что идеально подходит для офлайн-пайплайнов ревью кода. А продуктовое ценообразование Codex означает, что его стоимость фиксирована независимо от объёма использования, что делает его наиболее предсказуемым вариантом для бюджетирования.
Ключевой метрикой для оценки мультимодельной стратегии является не производительность отдельной модели, а совокупное качество-на-доллар по всему набору запросов. Хорошо настроенный маршрутизатор может достичь 90%+ качества по сравнению с постоянным использованием лучшей модели для каждого типа задач, при этом снижая затраты на 40-60% по сравнению с использованием единой премиальной модели для всего. Инвестиции в инженерию маршрутизатора быстро окупаются в масштабе: даже простой маршрутизатор на основе правил, направляющий запросы рассуждений к Gemini и задачи программирования к Opus, может сократить затраты на 30% по сравнению с использованием Opus для всего, сохраняя эквивалентное или лучшее качество на задачах рассуждений.
Команды, не готовые строить собственную инфраструктуру маршрутизации, могут достичь аналогичных результатов через платформы агрегации API, которые берут на себя выбор модели и логику резервирования. Ключевое понимание заключается в том, что привязка к одной модели — это самый большой риск в текущем ландшафте. При наличии трёх сильных вариантов от трёх разных провайдеров сохранение гибкости для перенаправления трафика между моделями по мере развития возможностей и изменения цен ценнее, чем выжимание последнего процента производительности из любой отдельной модели.
FAQ — ответы на частые вопросы
Какая модель лучше всего подходит для программирования в марте 2026?
Это зависит от вашего рабочего процесса. Для ревью кода и сложного рефакторинга лидирует Claude Opus 4.6 с 80,8% в SWE-Bench и самокорректирующимся циклом GVR. Для автономного выполнения задач, когда модель самостоятельно пишет, тестирует и коммитит код, доминирует GPT-5.3-Codex с 77,3% в Terminal-Bench. Для общего программирования с учётом бюджета Gemini 3.1 Pro с 80,6% в SWE-Bench и $2/MTok за вход предлагает лучшее соотношение цена-качество. Все три модели находятся в пределах 1 процентного пункта по SWE-Bench, поэтому практическая разница определяется типом нужной помощи в программировании и вашим предпочтительным рабочим процессом.
Действительно ли Opus 4.6 стоит $5/$25 за миллион токенов? Многие статьи указывают $15/$75.
Да, $5/$25 — корректная цена. Мы проверили это непосредственно на claude.com/pricing, кликнув на вкладку API 2 марта 2026 года. Цена $15/$75, указываемая многими сравнительными статьями, относится к моделям предыдущего поколения Claude Opus 4.1 и 4.0. Anthropic значительно снизила цены на Opus с релизом 4.6, что делает его намного более конкурентоспособным для продакшен-использования.
Можно ли вызывать GPT-5.3-Codex через API как GPT-4o или GPT-5.2?
Нет. По состоянию на 2 марта 2026 года GPT-5.3-Codex не отображается на странице цен API OpenAI и не имеет отдельной конечной точки модели. Вы получаете доступ через веб-приложение Codex (codex.openai.com), Codex CLI, расширения для IDE или GitHub Copilot. Если вам нужен стандартный API с потокенной оплатой от OpenAI, последний вариант — GPT-5.2 по цене $1,75/$14 за миллион токенов, но ему не хватает возможностей автономного выполнения, которые делают Codex особенным.
У какой модели самое большое контекстное окно?
Gemini 3.1 Pro предлагает самое большое контекстное окно — 1 миллион токенов в General Availability, что означает стабильность и готовность к продакшену на этой длине. Claude Opus 4.6 поддерживает 200K токенов по умолчанию с бета-доступом к 1M токенам по запросу. GPT-5.3-Codex поддерживает 400K токенов. Если обработка очень длинных документов является центральной частью вашего сценария использования, Gemini имеет явное преимущество с контекстным окном 1M в GA.
Какая модель наиболее безопасна для корпоративного использования?
Claude Opus 4.6 был разработан с применением Constitutional AI и обширного обучения безопасности, что делает его особенно подходящим для корпоративных сред со строгими требованиями к соответствию нормативам. Anthropic публикует подробные карточки моделей и имеет надёжную историю по оценкам безопасности. Gemini 3.1 Pro интегрируется с существующей корпоративной инфраструктурой безопасности Google через Vertex AI, что означает такие же средства контроля доступа, ведение журнала аудита и сертификаты соответствия, которым предприятия уже доверяют для своих рабочих нагрузок в Google Cloud. Codex 5.3 работает в изолированных средах, ограничивающих возможности непредвиденных побочных эффектов, а его продуктовый подход означает, что модель не может получить доступ к системам за пределами того, что вы явно предоставили. Все три провайдера предлагают корпоративные соглашения, соответствие SOC 2 и договоры обработки данных, поэтому решение о безопасности должно основываться на вашей конкретной нормативной базе, а не на общей рекомендации.
Как скидки на пакетную обработку влияют на сравнение стоимости?
Пакетная обработка существенно меняет экономику для пользователей с высоким объёмом. Anthropic предлагает 50% скидку на пакетные API-запросы для Opus 4.6, что снижает эффективную цену за вход до $2,50 за миллион токенов — почти совпадает со стандартной ценой Gemini в $2. Google предлагает кэширование контекста для Gemini, которое может снизить затраты до 75% для промптов с общими префиксами, что крайне ценно для пайплайнов ревью кода, где системный промпт и контекст репозитория остаются неизменными. Ценообразование Codex от OpenAI уже включено в продуктовые подписки, поэтому дополнительных скидок на пакеты нет, но эффективная стоимость за токен может быть очень низкой для активных пользователей. Ключевой вывод: опубликованные цены за токен — это отправная точка, а не конечная стоимость. Команды, обрабатывающие более 100 миллионов токенов в месяц, должны вести переговоры напрямую с провайдерами и учитывать кэширование, пакетную обработку и скидки за гарантированный объём.
Будут ли эти модели скоро заменены? Стоит ли подождать?
Темп выпуска моделей в начале 2026 года был экстраординарным, и естественно беспокоиться о создании решений на модели, которая может устареть через несколько месяцев. Однако все три эти модели представляют значительные архитектурные достижения (а не просто увеличение масштаба) по сравнению с предшественниками, что указывает на то, что они останутся конкурентоспособными дольше, чем типичные поколения моделей. Архитектура MoE Gemini, Agent Teams Opus и изолированное выполнение Codex — это новые возможности, а не инкрементальные улучшения. Прагматичный подход — строить приложения с абстракцией модели, чтобы замена модели требовала лишь изменения конфигурации, и выбирать лучшую доступную модель сегодня, а не ждать неопределённого будущего релиза. Мультимодельная стратегия, описанная в этой статье, изначально обеспечивает эту гибкость.