
Платить за Gemini 3.1 Pro Preview стоит тогда, когда workload действительно сложный, tool-sensitive и engineering-heavy. Для high-volume, latency-sensitive и cost-sensitive задач, которым не нужен reasoning уровня Pro, default должен быть Gemini 3.1 Flash-Lite.
Прежде всего это routing-решение. Pro - не просто ярлык 'лучше benchmark', а Flash-Lite - не просто дешевая копия. Они созданы для разных production lanes, поэтому правильный ответ зависит от того, какая lane нужна именно вам.
Краткое содержание
Если нужен только практический ответ, используйте такое правило:
- Gemini 3.1 Pro Preview берите для сложных агентных сценариев, software engineering и чувствительных к качеству tool-heavy задач.
- Gemini 3.1 Flash-Lite держите как дешевую полосу по умолчанию для перевода, извлечения, классификации, легких агентов и массовых очередей.
- Если нагрузка смешанная, не выбирайте одну модель на все. Делайте split-routing.
Официальная картина на 20 марта 2026 года выглядит так:
| Параметр | Gemini 3.1 Pro Preview | Gemini 3.1 Flash-Lite | Что это значит |
|---|---|---|---|
| Текущий статус | Preview | Preview | Ни одна из моделей не является безусловным GA-дефолтом |
| Бесплатный уровень | Нет | Есть | Flash-Lite удобнее для тестов и недорогих экспериментов |
| Стандартная цена входа | $2.00 / 1M tokens | $0.25 / 1M tokens | Pro дороже в 8 раз по input |
| Стандартная цена выхода | $12.00 / 1M tokens | $1.50 / 1M tokens | По output разница тоже 8x |
| Batch-цена | $1.00 in / $6.00 out | Бесплатный слой, затем $0.125 in / $0.75 out | Flash-Lite лучше для дешевой асинхронной нагрузки |
| Входной лимит | 1,048,576 tokens | 1,048,576 tokens | Размер контекста не решает выбор |
| Максимальный output | 65,536 tokens | 65,536 tokens | Лимит вывода тоже не отличает модели |
| Публичный Tier 1 Batch ceiling | 5,000,000 tokens | 10,000,000 tokens | Flash-Lite лучше для больших очередей |
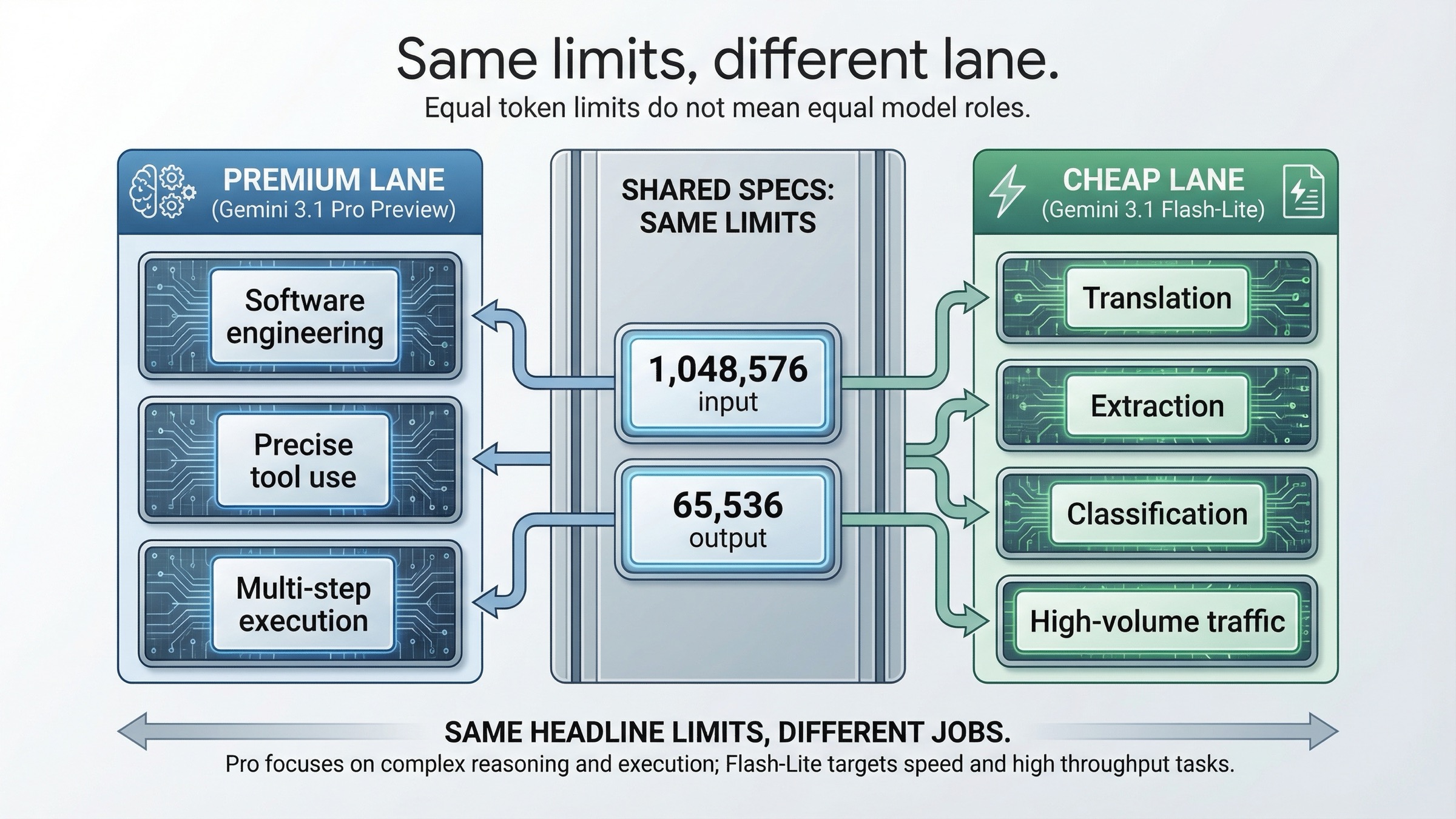
| Лучший сценарий | Сложные агенты, software engineering, точные tool flows | Перевод, извлечение, классификация, легкие агенты, массовый трафик | Это и есть реальное разделение ролей |
Этот вывод основан на официальных страницах pricing, Gemini 3.1 Pro Preview, Gemini 3.1 Flash-Lite Preview, публичной странице rate limits и карточках DeepMind: Gemini 3.1 Pro и Gemini 3.1 Flash-Lite.
Почему это не спор про размер контекста, а спор про маршрутизацию
Самая частая ошибка в этой теме звучит так: раз Pro дороже и сильнее, значит надо переводить туда весь трафик. Обратная ошибка: раз Flash-Lite это "lite", значит это просто урезанная версия Pro. Текущая документация Google не подтверждает ни одну из этих крайностей.
Сначала про то, что совпадает. Обе официальные модельные страницы указывают 1,048,576 input tokens и 65,536 output tokens. То есть вы не покупаете у Pro больший контекст и не покупаете более длинный ответ. Именно поэтому сравнение нельзя сводить к "у кого выше лимит".
Настоящая разница начинается там, где приходится отвечать на вопрос: за что вы платите более высокую цену и чего лишаетесь, если берете более дешевую модель.
Страница Gemini 3.1 Pro Preview говорит о лучшем thinking, лучшей token efficiency, лучшей factual consistency, более сильном software engineering behavior, точном использовании инструментов и надежном многошаговом выполнении. Это язык премиальной полосы. Он нужен там, где ошибки дорого обходятся.
Страница Gemini 3.1 Flash-Lite Preview использует совсем другой словарь: высокая частота вызовов, простые задачи извлечения, перевод, классификация, низкая задержка, high-volume agentic tasks. Это не "тот же Pro, но чуть слабее". Это другая оптимизация.
Поэтому полезнее задавать такие вопросы:
- Какие запросы действительно требуют более сильного reasoning и более надежного tool behavior?
- Какие запросы по своей природе относятся к дешевой полосе и не должны оплачивать Pro?
- Нагрузка у вас однородная или разумнее держать Flash-Lite по умолчанию и поднимать только самые трудные кейсы на Pro?
Если смотреть на пару через эту призму, дальнейшая картина становится намного проще.
Цена, Batch-экономика и публичная реальность лимитов на 20 марта 2026 года

Цена здесь важнее любых рекламных формулировок, потому что именно она определяет, какую модель имеет смысл держать дефолтом.
На текущей странице pricing Gemini 3.1 Pro Preview не имеет free tier. Для запросов до 200k prompt tokens Google указывает $2.00 за 1M входных токенов и $12.00 за 1M выходных. Для промптов выше 200k цена растет до $4.00 input и $18.00 output. Batch-режим снижает тариф примерно вдвое, но даже тогда это $1.00 input и $6.00 output.
У Flash-Lite экономика совершенно другая. У модели есть бесплатный уровень, а платный тариф равен всего $0.25 input и $1.50 output. В Batch-режиме еще дешевле: $0.125 input и $0.75 output.
Это означает очень важную вещь: стандартная цена Pro выше ровно в 8 раз как по input, так и по output. Поэтому Pro должен реально окупать себя качеством. Если повышение качества лишь косметическое, платить за него бессмысленно. Но если более сильный первый ответ сокращает дорогое ручное ревью, уменьшает число неверных tool calls и спасает многошаговые workflow от каскадных провалов, тогда высокая цена может быстро оправдаться.
Публичная картина по лимитам показывает ту же логику. Текущая страница rate limits уже не дает единой статической таблицы RPM и TPM для всех моделей и отправляет смотреть активные значения в AI Studio. Поэтому не стоит писать статьи так, будто есть один "вечный" публичный RPM-ответ. Но одна полезная цифра там все же есть: Tier 1 Batch enqueued token limits.
Сейчас публично указано:
- Gemini 3.1 Pro Preview: 5,000,000
- Gemini 3.1 Flash-Lite: 10,000,000
Для реальных production-систем это очень важно, потому что большая часть нагрузки часто живет не в чат-интерфейсе, а в фоне:
- пакетный перевод
- извлечение из документов
- массовая классификация и маркировка
- summary-конвейеры
- асинхронная маршрутизация
Именно для такого трафика Flash-Lite оказывается не только дешевле, но и удобнее по публичной очереди.
По grounding тоже не стоит ждать "скрытого бонуса" у Pro. На странице pricing обе модели имеют 5,000 бесплатных grounding prompts в месяц в paid usage, после чего Search и Maps тарифицируются по $14 за 1,000 queries. То есть текущая официальная картина не говорит, что Pro выигрывает на инструментальной экономике.
Если собрать все вместе, вывод получается очень прямой: если задача относится к дешевой полосе, держать ее на Pro по умолчанию почти всегда неверно.
Когда Gemini 3.1 Pro Preview действительно оправдывает свою цену
Было бы ошибкой сделать из этой статьи вывод "дешевая модель всегда выгоднее". Есть заметный класс задач, где Pro действительно окупает себя.
Официальная страница Gemini 3.1 Pro Preview прямо акцентирует software engineering, precise tool use и reliable multi-step execution. Карточка Gemini 3.1 Pro, опубликованная 19 февраля 2026 года, усиливает это позиционирование и показывает более сильный верхний уровень по сложным тестам вроде Humanity's Last Exam, GPQA Diamond, Terminal-Bench 2.0, SWE-Bench Verified и APEX-Agents.
Да, такие бенчмарки нельзя механически переносить на любой production-стек. Но направленность сигнала здесь очень полезна. Pro нужен там, где качество ответа действительно меняет экономику:
- многошаговые агентные планы
- сложные tool-heavy coding flows
- сценарии, где одна плохая tool decision тянет за собой длинную цепочку ошибок
- сложные reasoning-задачи, где дешевые повторы все равно обходятся дорого
- engineering-сценарии, где более сильный первый черновик экономит реальное время разработчиков
Есть и практический workflow-сигнал: в документации Pro отдельно существует линия gemini-3.1-pro-preview-customtools для смешанных bash и custom-tool сценариев. Это не означает, что все агенты обязаны работать на Pro, но показывает, куда Google сам помещает более тяжелые инструментальные кейсы.
Даже сообщество двигается в ту же сторону. Пост на Reddit "I had to switch to 3.1 Pro Preview Custom Tools for my Agent" не является официальной спецификацией, но хорошо показывает тип запроса, стоящий за этим сравнением: люди пытаются решить реальные проблемы агентных workflow, а не спорят о маркетинговых лозунгах.
Поэтому правильная формулировка для Pro такая:
Используйте Pro тогда, когда стоимость плохого ответа заметно выше стоимости токенов.
Если это не так, Pro чаще всего не должен быть моделью по умолчанию.
Почему Gemini 3.1 Flash-Lite должна оставаться дешевой полосой по умолчанию
Flash-Lite часто недооценивают просто потому, что многие сравнения моделей автоматически ставят "более сильную" модель в роль дефолта. Но текущие официальные страницы Google описывают Flash-Lite иначе: как экономичный рабочий инструмент для задач, которые нужно делать много и дешево.
Страница Gemini 3.1 Flash-Lite Preview и карточка Gemini 3.1 Flash-Lite указывают практически на один и тот же набор задач:
- перевод
- классификация
- простое извлечение
- низкая задержка
- высокочастотные вызовы
- большие асинхронные очереди
- легкие агентные пайплайны
А это огромная часть реального production-трафика.
Если ваш стек в основном работает с понятными входами и ограниченными по форме выходами, Flash-Lite не просто "дешевле". Во многих случаях это и есть правильная модель, потому что вы не платите за потолок Pro там, где он не нужен. Для извлечения, маркировки, типового перевода, простых summary-pipeline и route-by-template сценариев Pro часто оказывается не "лучше", а просто "слишком дорог".
Бесплатный уровень усиливает этот вывод. Для многих команд free tier — это не про экономию на игрушках, а про сохранение дешевой инженерной полосы для:
- проверки шаблонов промптов
- smoke tests на preprod
- тестирования логики маршрутизации
- регрессионных прогонов на малом объеме
С инженерной точки зрения это очень удобно. Дешевая модель с бесплатным уровнем позволяет держать систему здоровой и недорогой; платный премиальный уровень логично выделять только под те запросы, где ROI доказан.
Поэтому Flash-Lite правильнее понимать не как "план Б", а как дефолтную дешевую рабочую полосу для соответствующего класса задач.
Полная замена, сохранение дефолта или split-routing?
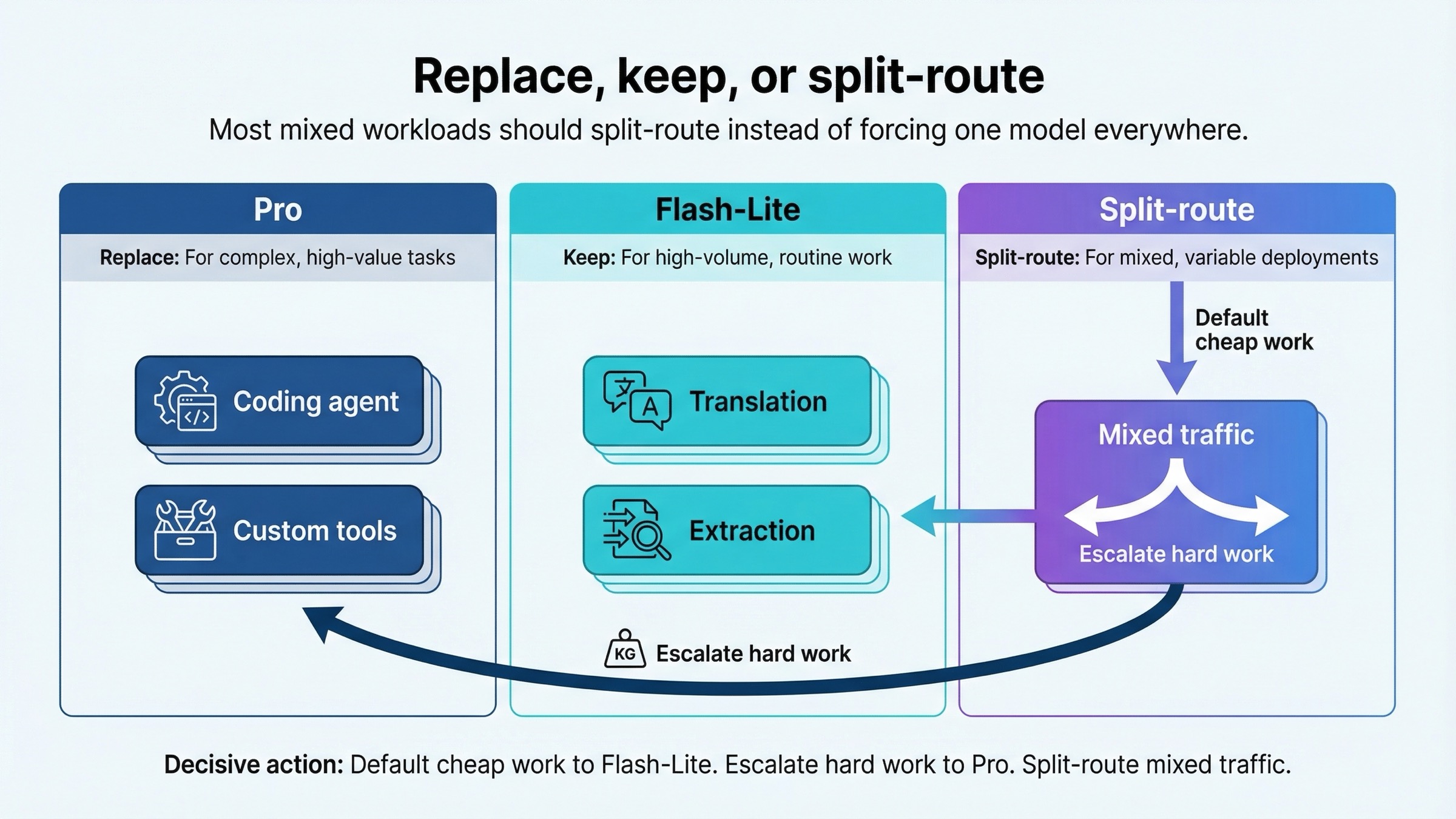
Для большинства серьезных команд разумный ответ — не крайность, а разделение ролей.
Если вы переводите весь трафик на Pro, почти наверняка переплачиваете за рутинную работу. Если все отправляете на Flash-Lite, рискуете потерять качество именно там, где ошибки обходятся дороже всего. Поэтому для смешанной нагрузки наиболее здравый вариант — split-routing.
Практическая схема выглядит так:
| Нагрузка | Более разумный дефолт | Почему |
|---|---|---|
| Tool-heavy coding agent | Gemini 3.1 Pro Preview | Здесь важнее software engineering и надежное многошаговое выполнение |
| Custom tools orchestration | Gemini 3.1 Pro Preview | У Pro сильнее сигнал по инструментальным workflow |
| Массовый перевод | Gemini 3.1 Flash-Lite | Дешевле и лучше для объема |
| Структурированное извлечение и маркировка | Gemini 3.1 Flash-Lite | Типичная дешевая полоса, где Pro редко окупается |
| Большие асинхронные очереди | Gemini 3.1 Flash-Lite | Ниже Batch-цена и выше публичный queue ceiling |
| Смешанный production-трафик | Split-route | Flash-Lite как default, Pro как escalation lane |
На практике это обычно означает три шага:
- Новый массовый трафик сначала запускайте на Flash-Lite.
- Pro тестируйте только на тяжелых сегментах: сложный coding, многошаговые задачи, трудные tool flows.
- Если качество Pro реально экономит деньги, только тогда выделяйте под эти запросы отдельную премиальную полосу.
Это намного полезнее, чем расплывчатая формула "Pro для качества, Lite для цены". Нормальное правило маршрутизации звучит так:
По умолчанию отправляйте дешевую рутинную работу в Flash-Lite. Сложную дорогую работу эскалируйте в Pro. Смешанный трафик разделяйте.
Если вам нужен соседний разбор роли Flash-Lite по отношению к более сильной быстрой модели, посмотрите Gemini 3.1 Flash-Lite vs Gemini 3 Flash. Если хотите понять, как Pro соотносится с более стабильной премиальной моделью прошлого поколения, читайте Gemini 3.1 Pro vs Gemini 2.5 Pro.
FAQ
Gemini 3.1 Pro Preview всегда лучше, чем Gemini 3.1 Flash-Lite?
Только для действительно сложных задач. Для массовых дешевых workload Flash-Lite часто является более правильной моделью по умолчанию.
Какая модель дешевле?
Flash-Lite. По состоянию на 20 марта 2026 года стандартный тариф Pro — $2.00 input / $12.00 output, а у Flash-Lite — $0.25 input / $1.50 output. Разница 8x в обе стороны.
У них одинаковые лимиты токенов?
Да. Официальные страницы обеих моделей сейчас указывают 1,048,576 input tokens и 65,536 output tokens. Поэтому сравнение нельзя сводить к размеру окна.
Что выбрать для coding agents?
Если агент сложный, опирается на инструменты и дорог в ручной проверке, начинайте с Pro. Если сценарий легкий и типовой, можно сначала ставить Flash-Lite в baseline.
Что выбрать для перевода и извлечения на масштабе?
Flash-Lite. И официальное позиционирование, и цена, и Batch-экономика, и queue ceiling говорят в его пользу.