
Выбирайте Gemini 3 Flash, когда вам нужна более сильная Gemini 3-series lane для coding, agent workflows и Computer Use. Выбирайте Gemini 3.1 Flash-Lite, когда задача настолько high-volume, latency-sensitive и cost-sensitive, что побеждает более дешевая lane.
Реальное решение здесь не в абстрактном benchmark rank. Вопрос в том, должен ли ваш fast model тянуть premium coding и agent work, или ему в основном достаточно быть дешевым, быстрым и достаточным на масштабе.
Краткое содержание
- Выбирайте Gemini 3 Flash, если вам нужна более сильная premium fast lane для coding, сложных агентов и Computer Use.
- Выбирайте Gemini 3.1 Flash-Lite, если вам нужна дешевая high-volume lane для перевода, extraction, routing и других массовых задач.
- Держите обе модели, если у вас смешанный production stack с дорогими и дешевыми типами трафика.
Базовое сравнение сейчас выглядит так:
| Параметр | Gemini 3.1 Flash-Lite | Gemini 3 Flash | Что это значит |
|---|---|---|---|
| Статус | Preview | Preview | Ни одна из моделей не является Stable-по-умолчанию |
| Дата запуска | 2026-03-03 | 2025-12-17 | Flash-Lite новее, но не обязательно "выше классом" |
| Model ID | gemini-3.1-flash-lite-preview | gemini-3-flash-preview | Нужна явная маршрутизация |
| Standard input | бесплатно, затем $0.25 / 1M | бесплатно, затем $0.50 / 1M | Flash-Lite вдвое дешевле |
| Standard output | бесплатно, затем $1.50 / 1M | бесплатно, затем $3.00 / 1M | Здесь тоже почти 2x |
| Batch price | бесплатно, затем $0.125 / $0.75 | без free batch, затем $0.25 / $1.50 | Для большого async-потока Flash-Lite выгоднее |
| Context window | 1,048,576 tokens | 1,048,576 tokens | Это не различающий фактор |
| Max output | 65,536 tokens | 65,536 tokens | Тоже нет |
| Computer Use | Нет | Да | Это одна из главных реальных разниц |
| Grounding | Есть, но без free-tier grounding | Есть, но без free-tier grounding | Бесплатного преимущества по grounding здесь нет |
| Лучший fit | Дешевый массовый трафик | Более сильная fast lane | Ключевая разница именно в lane, а не в названии |
Почему эту пару так легко понять неправильно
По названию может показаться, что Flash-Lite это просто "дешевый Flash". Официальное позиционирование рисует более четкое разделение.
Google описывает Gemini 3 Flash как более сильную fast model для multimodal understanding, advanced reasoning и agentic coding. А Gemini 3.1 Flash-Lite подается как наиболее cost-efficient модель для высокочастотных легких задач, translation, extraction и routing.
То есть вопрос на самом деле не в том, "кто новее", а в том, какая lane вам нужна:
- более сильная premium fast lane
- более дешевая high-volume lane
Цена, free tier, grounding и batch throughput
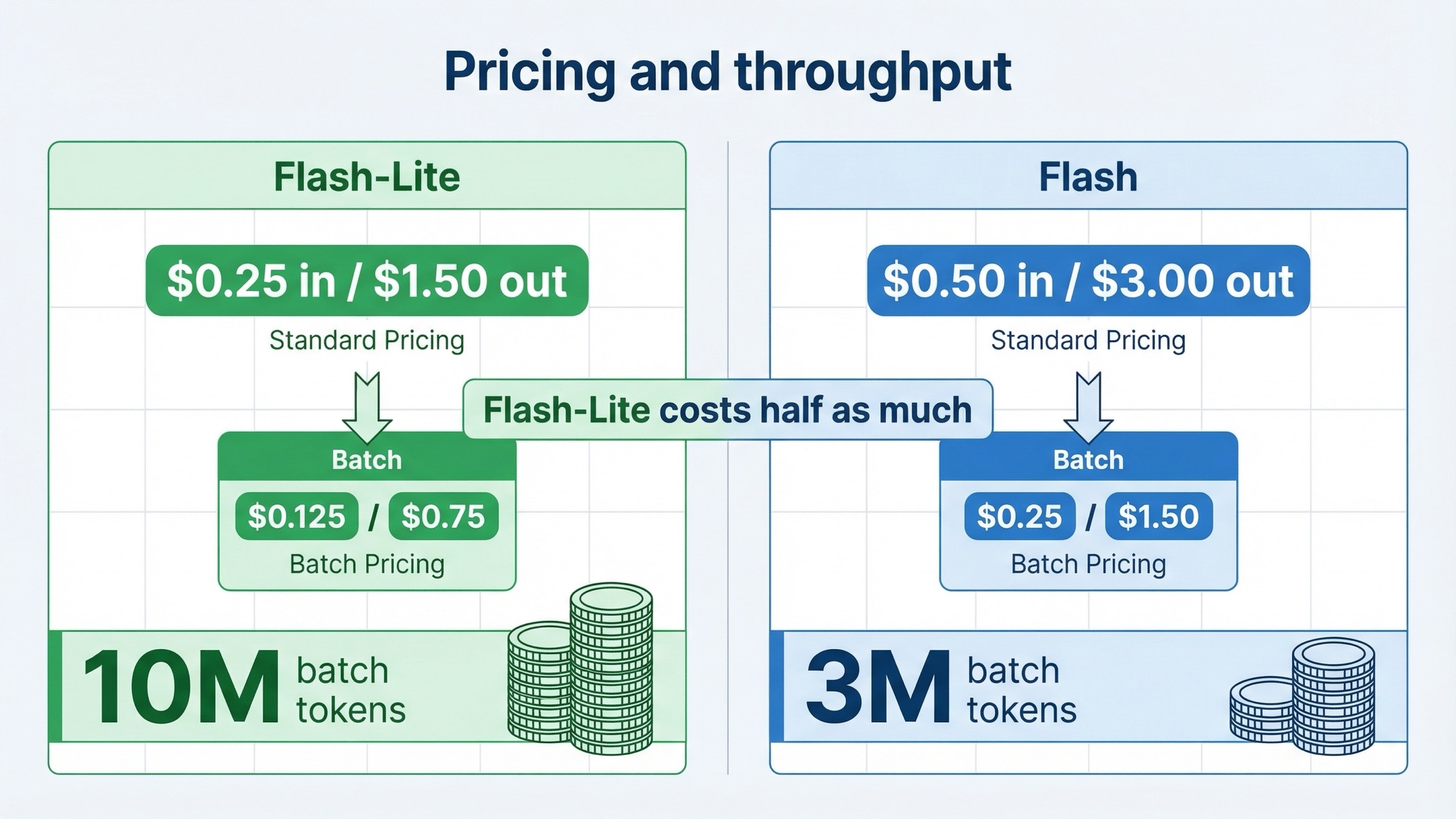
Самая чистая официальная разница здесь это цена.
Согласно pricing page:
- Gemini 3.1 Flash-Lite Preview:
\$0.25input и\$1.50output за 1M tokens - Gemini 3 Flash Preview:
\$0.50input и\$3.00output за 1M tokens
Иными словами, Gemini 3 Flash стоит примерно в 2 раза дороже.
Если ваш workload в основном состоит из:
- перевода
- структурированного extraction
- классификации
- routing
- массовых summary-задач
- больших async-пайплайнов
то уже одной этой разницы достаточно, чтобы склониться в сторону Flash-Lite.
Batch подтверждает тот же вывод:
- Gemini 3.1 Flash-Lite Batch:
\$0.125input,\$0.75output - Gemini 3 Flash Batch:
\$0.25input,\$1.50output
Кроме того, на странице rate limits в таблице Tier 1 Batch API указано:
- Gemini 3.1 Flash-Lite Preview:
10,000,000enqueued batch tokens - Gemini 3 Flash Preview:
3,000,000enqueued batch tokens
Для массового async-трафика это очень практическая разница.
С grounding тоже важно не упрощать. Обе model page указывают Search grounding и Maps grounding как поддерживаемые возможности, но pricing page показывает, что ни у одной модели нет free-tier grounding. В paid usage обе получают 5,000 бесплатных prompts в месяц перед отдельным billing за grounding. Значит, бесплатного преимущества тут нет ни у одной стороны.
Разница в возможностях важнее, чем разница в названии

На уровне headline specs модели очень похожи:
- text output
- text / image / video / audio / PDF input
1,048,576input tokens65,536output tokens- Batch, Function Calling, Structured Outputs, Code Execution, Caching
Если смотреть только на этот список, легко решить, что فرق лишь в цене. Но настоящий разлом проходит через workflow.
Gemini 3 Flash поддерживает Computer Use. Gemini 3.1 Flash-Lite не поддерживает.
Если вы строите UI-агентов, browser automation или более тяжелый tool-use сценарий, это уже не косметическая разница.
Второй слой различия это позиционирование. 3 Flash у Google это lane для более сильного coding и reasoning. 3.1 Flash-Lite это lane для translation, extraction, routing и других легких массовых задач.
Именно поэтому Flash-Lite не стоит воспринимать как слепую замену 3 Flash. Намного точнее воспринимать его как bulk-traffic lane в семействе Gemini 3.
Что официальные performance page подсказывают, а что не доказывают
У DeepMind есть сильные официальные страницы для обеих моделей:
Но это не одна общая страница head-to-head для данной пары. Более того, в model card для 3.1 Flash-Lite есть оговорка, что использованы обновленные evaluation-методики, и результаты нельзя механически сравнивать с более ранними Gemini model cards.
Тем не менее направленность считывается достаточно четко:
- Gemini 3 Flash имеет более сильный официальный capability-story
- Gemini 3.1 Flash-Lite имеет более сильный cost-efficiency-story
То есть вопрос не в том, "кто побеждает везде", а в том, стоит ли вам платить за premium lane.
Для каких workload какая модель подходит лучше
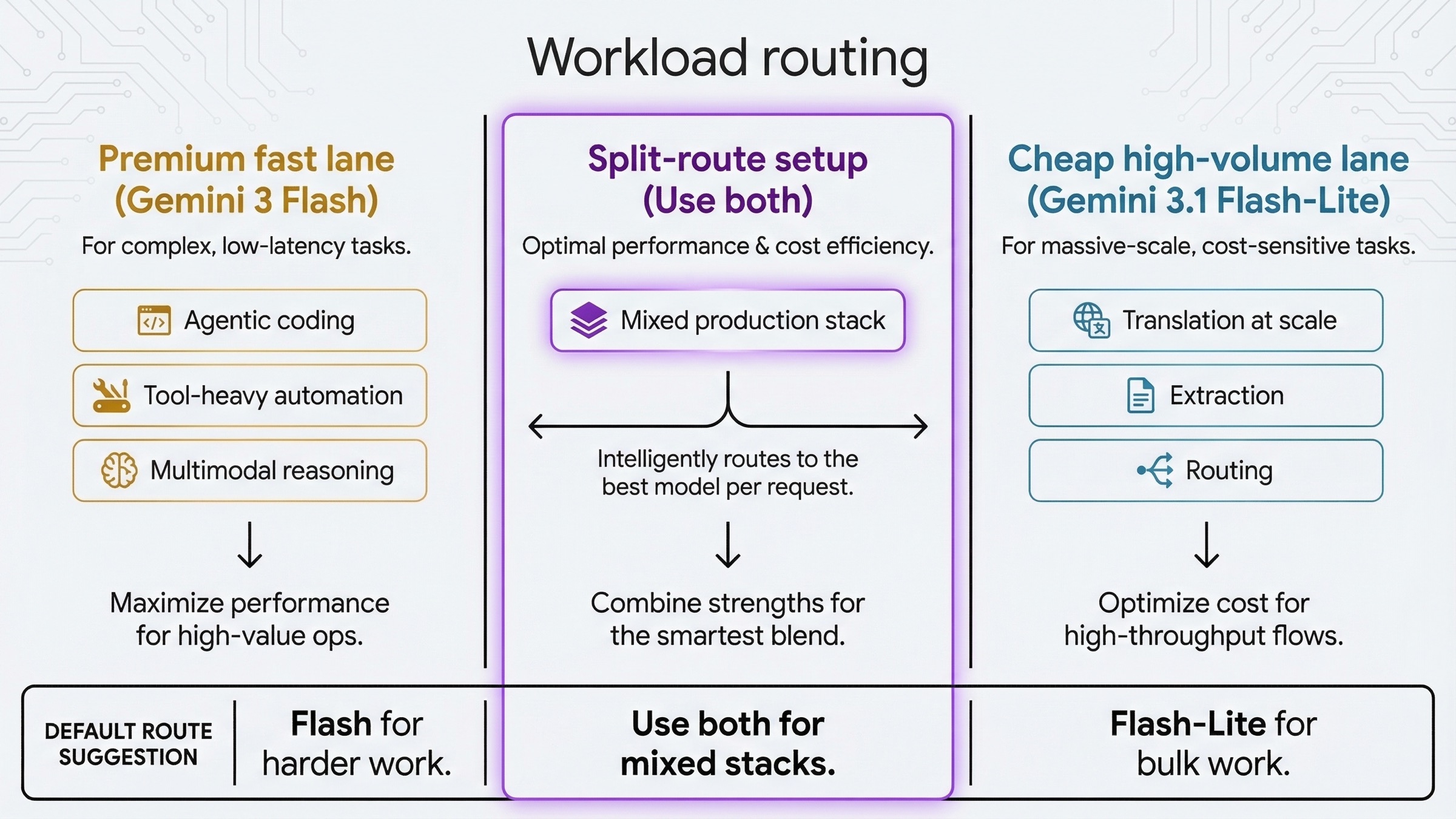
| Workload | Что брать первым | Почему |
|---|---|---|
| agentic coding | Gemini 3 Flash | Более сильная capability lane |
| tool-heavy automation | Gemini 3 Flash | Computer Use решает |
| сложный multimodal reasoning | Gemini 3 Flash | Это premium fast lane |
| перевод в масштабе | Gemini 3.1 Flash-Lite | Дешевле и естественнее по fit |
| structured extraction | Gemini 3.1 Flash-Lite | Здесь cost и throughput важнее |
| слой classification / routing | Gemini 3.1 Flash-Lite | Один из самых естественных use case |
| большой async batch | Gemini 3.1 Flash-Lite | Лучше цена и batch-ceiling |
| смешанный production stack | Обе | Дорогие задачи отдельно, bulk-трафик отдельно |
Как внедрять без лишнего сожаления
Наиболее здравый ответ здесь не "перевести все на одну модель".
- Отдать Flash-Lite дешевую lane
Перевод, extraction, tagging, routing и другой bulk traffic логично отдавать gemini-3.1-flash-lite-preview.
- Оставить 3 Flash для premium lane
Coding, сложный reasoning, Computer Use и тяжелые agent workflow логично оставлять на gemini-3-flash-preview.
- Смотреть не только на средние цифры, но и на поломки
Поскольку обе модели Preview, важно проверять не только среднюю latency, но и:
- стабильность structured outputs
- надежность tool calling
- drift на длинном контексте
- стоимость успешной задачи, а не просто стоимость token
Если вам нужна операционная страховка, полезно также посмотреть наш гайд по Gemini API troubleshooting.
Что стоит проверить до того, как сделать одну из моделей маршрутом по умолчанию
Самая частая ошибка в такой паре моделей это слишком быстро превратить официальный benchmark или красивую ценовую разницу в решение о полной миграции. На практике лучше сначала прогнать короткий, но жесткий production-чеклист.
Во-первых, посмотрите на стабильность structured outputs. Если ваш downstream ждет JSON, schema или предсказуемые аргументы функций, текстовой "общей адекватности" недостаточно. Важно, сколько раз модель ломает формат, сколько раз теряет поля и как часто вам приходится перезапрашивать ответ.
Во-вторых, смотрите на реальную надежность tool calling, а не только на наличие галочки "Function Calling". Две модели могут одинаково поддерживать функцию на бумаге, но вести себя по-разному на длинных промптах, сложных схемах и частичных ошибках.
В-третьих, не путайте одинаковый headline context window с одинаковым качеством длинного контекста. Даже если обе модели заявляют один и тот же потолок input tokens, это не гарантирует одинаковую точность на длинных документах, многошаговом анализе и retrieval-подобных сценариях.
В-четвертых, считайте стоимость успешной задачи, а не только стоимость token. Более дешевая модель может оказаться дороже, если она требует больше повторов, постобработки или fallback-веток. Для реального выбора важнее cost per successful task.
В-пятых, рассматривайте split-route как базовый вариант, а не как компромисс на крайний случай. Именно для этой пары моделей очень естественно разделить трафик так: Gemini 3 Flash для premium-task и Gemini 3.1 Flash-Lite для bulk-task.
Такой чеклист не усложняет решение. Наоборот, он убирает маркетинговую дымку и переводит разговор из уровня "какая модель круче" в уровень "какой тип нагрузки куда разумнее направлять".
Почему API-команды и пользователи Gemini app принимают не одно и то же решение
Это важное уточнение, которого почти всегда не хватает в SERP. API-команда обычно выбирает между cost per task, batch throughput, tool calling и качеством routing. Пользователь Gemini app чаще думает о другом: какой вариант виден в интерфейсе, какой тариф его открывает, насколько часто модель доступна и насколько понятны повседневные ограничения.
Для API-команды Gemini 3.1 Flash-Lite может быть отличным default-слоем для дешевых массовых задач даже в том случае, если никто в компании никогда не открывает Gemini app. Для app-пользователя сама логика выбора может быть почти обратной: его интересует не столько batch ceiling, сколько реальное наличие модели, стабильность поведения и удобство конкретного сценария.
Именно поэтому не стоит читать этот материал как "какая модель вообще лучше". Это статья про API-routing и production lane selection. Если ваш реальный вопрос больше про интерфейс приложения, подписку или видимость модели в продукте Google, часть этого сравнения будет полезной только косвенно.
Кому что выбирать в первую неделю
Если вы маленькая команда и вам нужен один дешевый production default для перевода, extraction, тегирования и простых automation-задач, начинать разумнее с Gemini 3.1 Flash-Lite. У него понятнее экономическая логика для массового трафика, и именно в такой роли он выглядит наиболее естественно.
Если вы строите agent workflow с tool use, code generation и более тяжелым reasoning, то первый кандидат обычно Gemini 3 Flash. Здесь цена выше, но и риск испортить качество в критическом маршруте тоже выше, поэтому premium lane часто окупается не benchmark-цифрой, а меньшим количеством operational surprises.
Если же вы уже знаете, что у вас будет две совсем разные категории трафика, не тратьте неделю на поиск "единственной правильной модели". Намного практичнее сразу заложить split-route: Flash для дорогих задач с высоким риском ошибки и Flash-Lite для всего, где решает throughput. Именно такой старт обычно лучше масштабируется, чем поздняя болезненная миграция.
И еще один практический момент: в первую неделю полезно заранее договориться, какая метрика вообще считается победой. Для Flash это часто доля задач, которые доходят до правильного tool-use или кода без ручного ремонта. Для Flash-Lite чаще важны cost per successful job, latency на массовом потоке и устойчивость простого structured extraction. Без такого разделения команды слишком часто сравнивают модели по разным целям и получают спор вместо решения.
FAQ
Gemini 3 Flash лучше, чем Gemini 3.1 Flash-Lite?
Если под "лучше" вы имеете в виду capability, agentic coding и Computer Use, то да. Если вы имеете в виду cost-efficiency, то нет.
Gemini 3.1 Flash-Lite это просто дешевый Gemini 3 Flash?
Нет. Точнее считать его отдельной high-volume lane внутри семейства Gemini 3.
У обеих моделей есть free tier?
Для standard usage да. Но batch, caching и grounding устроены не полностью одинаково.
Обе модели поддерживают grounding?
Да, но у обеих нет free-tier grounding.
Что лучше для coding?
Gemini 3 Flash.
Что лучше для перевода, extraction и routing?
Gemini 3.1 Flash-Lite.
Стоит ли полностью заменить 3 Flash на Flash-Lite?
Нет. Разумнее перевести на Flash-Lite только дешевую lane, а premium-задачи оставить на 3 Flash.