На 19 марта 2026 года Gemini 3.1 Pro действительно сильнее на верхнем уровне качества, но Gemini 2.5 Pro для многих продакшен-команд остается более выгодным дефолтом. Это не противоречие, если посмотреть на официальные страницы Google в связке: 3.1 Pro -- более новый Preview-модельный уровень для сложных задач, а 2.5 Pro -- GA-модель с более низкой ценой и доступным free tier в Gemini Developer API. В этом материале мы переводим сырые спецификации в практичное решение: где стоит эскалировать на 3.1 Pro, а где рациональнее оставаться на 2.5 Pro.
Это значит, что главный вопрос звучит не "кто победил в бенчмарках", а "нужно ли полностью заменить 2.5 Pro, или лучше держать его базовой моделью и отправлять на 3.1 только самые трудные запросы". Большинство страниц в выдаче не дают четкого ответа: они либо пересказывают таблицы, либо повторяют маркетинговые тезисы. Здесь подход обратный: сначала решение, потом факты, которые его обосновывают.
Краткое содержание
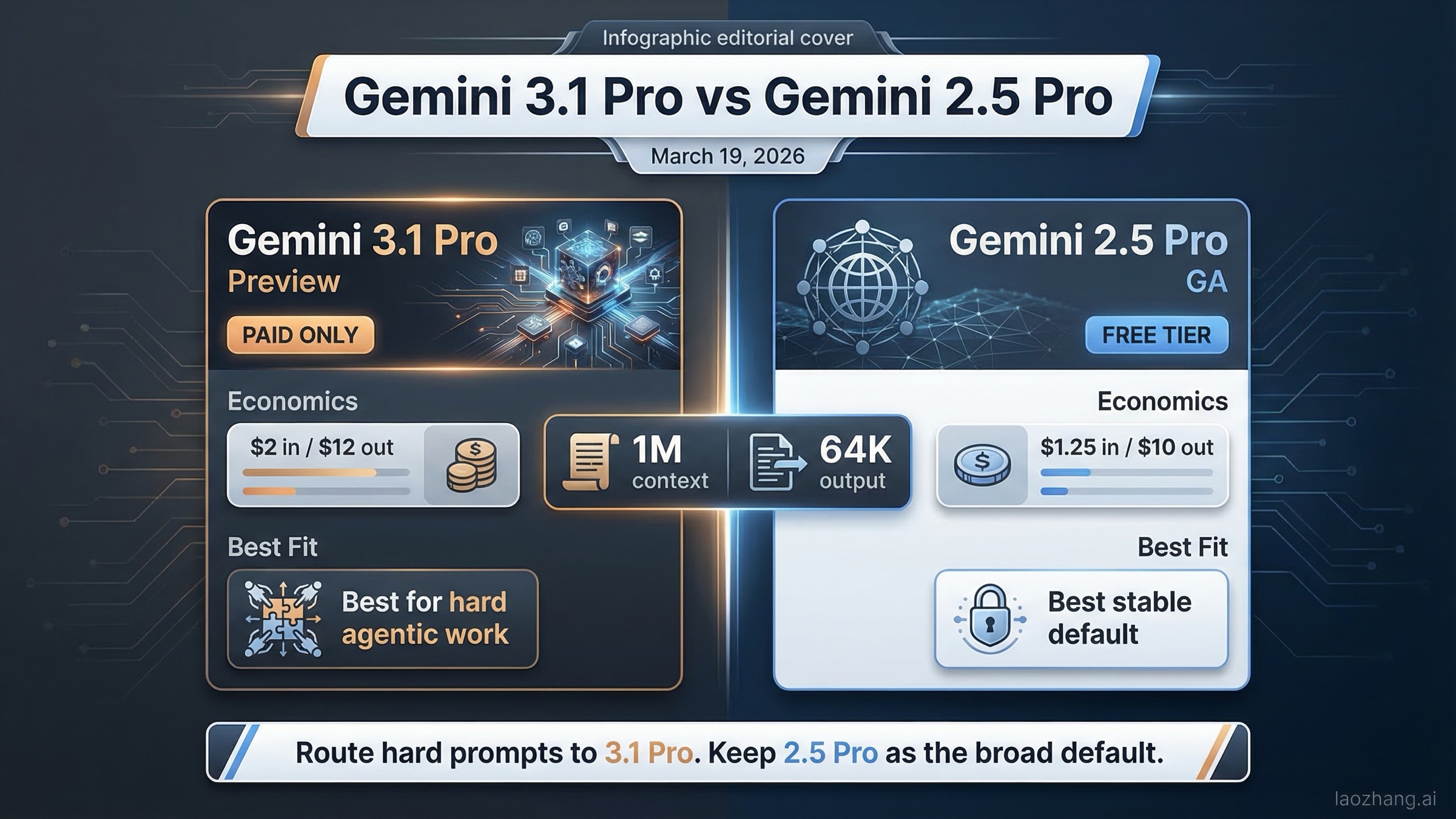
Если нужен короткий ответ: Gemini 3.1 Pro выбирают там, где узкое место -- сложное рассуждение, агентный кодинг и рабочие цепочки с большим числом инструментальных вызовов, а выгода от качества важнее рисков Preview и отсутствия бесплатного уровня. Gemini 2.5 Pro выбирают как стабильный GA-дефолт для массового трафика, более дешевого токенного бюджета и безопасного тестового контура.
Официальная картина на 19 марта 2026 года выглядит так:
| Параметр | Gemini 3.1 Pro | Gemini 2.5 Pro | Практический вывод |
|---|---|---|---|
| Текущий статус | Preview | GA (общедоступен) | 3.1 новее, но не всегда лучший дефолт для продакшена |
| Model ID | gemini-3.1-pro-preview | gemini-2.5-pro | Для миграции нужен явный роутинг, а не слепая замена |
| Бесплатный уровень | Нет | Да | 2.5 Pro удобнее для тестов, staging и низкорисковых экспериментов |
| Стандартная цена входа | $2.00 / 1M токенов до 200k | $1.25 / 1M токенов до 200k | Вход у 3.1 дороже на 60% |
| Стандартная цена выхода | $12.00 / 1M токенов до 200k | $10.00 / 1M токенов до 200k | Выход у 3.1 дороже на 20% |
| Цена для длинных промптов | $4.00 in / $18.00 out выше 200k | $2.50 in / $15.00 out выше 200k | Разрыв по цене сохраняется и на больших запросах |
| Контекстное окно | 1M токенов | 1M токенов | 3.1 не дает преимущества по headline-контексту |
| Макс. вывод | 64K токенов | 64K токенов | По потолку вывода 3.1 тоже не выигрывает |
| Лучший сценарий | Сложное агентное рассуждение, продвинутая разработка, frontier-задачи | Стабильный продакшен-дефолт, чувствительная к стоимости нагрузка, тесты на бесплатном уровне | 3.1 лучше использовать как премиальный маршрут, а не единственный путь |
Эти строки основаны на официальных источниках: Gemini Developer API pricing, Gemini API models, Vertex AI model catalog, Gemini 3.1 Pro model card и официальная PDF model card Gemini 2.5 Pro. Ключевой вывод: Google предлагает выбор не по лимитам 1M/64K (они одинаковые), а по качеству модели, цене и зрелости продукта.
Поэтому практичная рекомендация простая:
- Используйте Gemini 3.1 Pro там, где задача реально сложна и выигрыш в рассуждении снижает стоимость человеческой проверки.
- Оставляйте Gemini 2.5 Pro дефолтом для повседневного кодинга, широкого продакшен-трафика и сценариев, где важны GA-стабильность и free tier.
- Если у вас есть маршрутизация, не выбирайте "или-или": базовый поток на 2.5 Pro, сложные запросы -- эскалация на 3.1 Pro.
Именно из-за этого команды часто путаются: новая модель звучит как универсальный апгрейд, но официальные страницы по цене и статусу говорят другое. Gemini 3.1 Pro разумнее рассматривать как premium lane, а не как автоматическую замену всего контура.
Что на самом деле изменилось при переходе с 2.5 Pro на 3.1 Pro
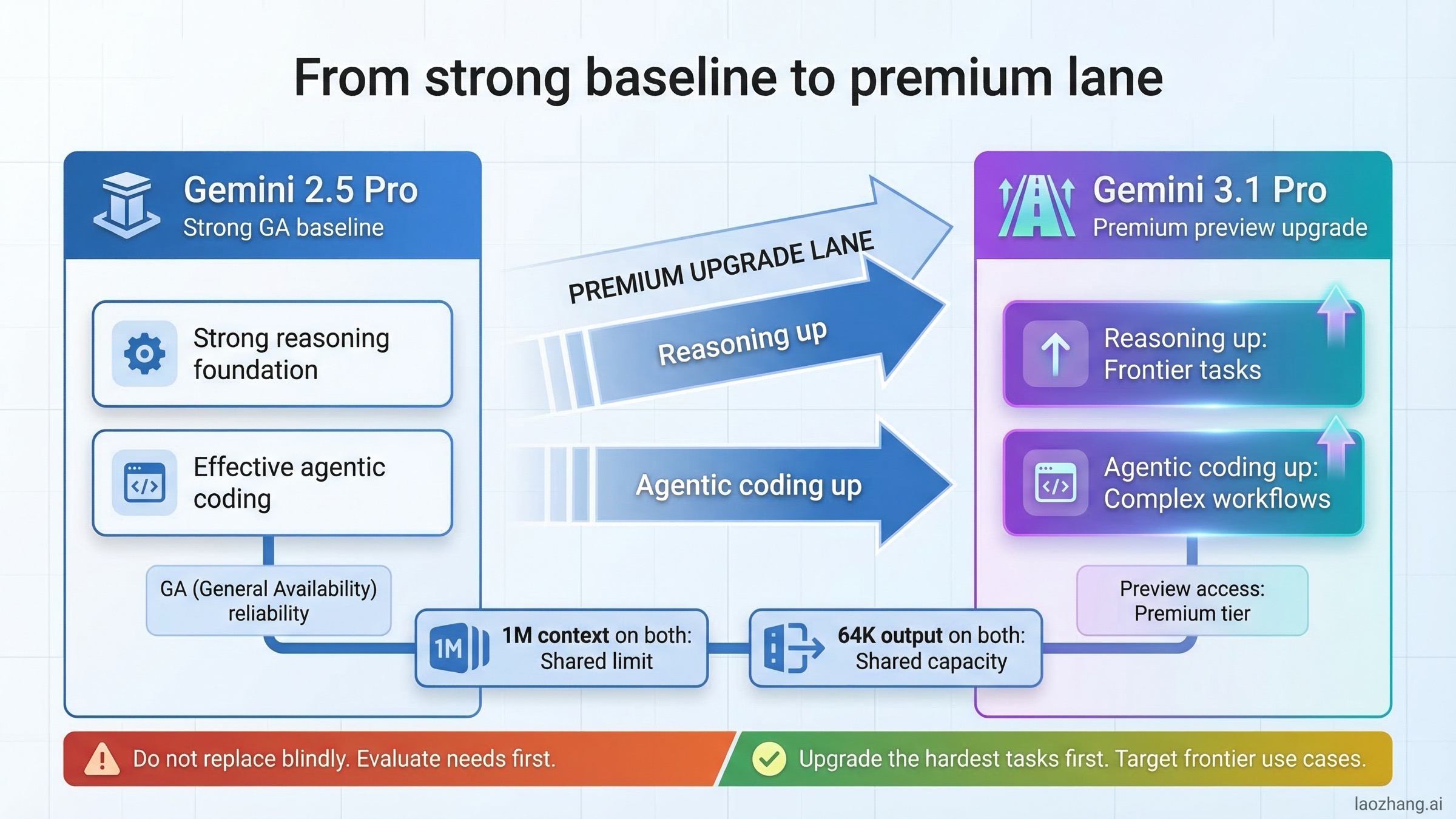
Самая частая ошибка в этом сравнении -- думать, что переход с 2.5 Pro на 3.1 Pro в основном про более длинный контекст, более высокий output ceiling или "просто быстрее". Это неверная рамка. Главный сдвиг -- в позиционировании линейки Google.
На текущей странице Vertex AI models Gemini 3.1 Pro указан в секции Preview и описан как последний reasoning-first уровень, оптимизированный для сложных агентных workflow и кодинга. На той же странице Gemini 2.5 Pro находится в секции GA как high-capability модель для сложного рассуждения и кодинга. Это ключевая подсказка: 3.1 -- фронтирный шаг вперед, 2.5 -- стабильный стандарт.
Model card Gemini 3.1 Pro усиливает эту логику. Документ опубликован 19 февраля 2026 года и на момент публикации называет 3.1 Pro самой продвинутой моделью Google для сложных задач. Там же подтверждены 1M контекста, 64K вывода и широкий список поверхностей: Gemini app, Vertex AI, AI Studio, Gemini API, Google Antigravity и NotebookLM.
Но model card Gemini 2.5 Pro, обновленная 27 июня 2025 года, показывает, почему 2.5 Pro не так просто "списать". В ней явно указан статус generally available и те же лимиты 1M/64K. То есть при переходе на 3.1 многие команды покупают не "больше места", а "более сильный мозг" за более высокую цену.
Это особенно заметно, если посмотреть на последнее крупное публичное позиционирование 2.5 Pro до релиза 3.1. В посте Google от 6 мая 2025 года -- "Build rich, interactive web apps with an updated Gemini 2.5 Pro" -- акцент сделан на улучшенном кодинге и web-app генерации, плюс отмечено лидерство в WebDev Arena. Поэтому 3.1 сравнивают не с "слабой старой моделью", а с уже сильной рабочей базой.
Рабочая ментальная модель для всего сравнения такая:
- Gemini 2.5 Pro -- не "устаревшая слабая версия".
- Gemini 3.1 Pro -- не "то же самое, только автоматически лучше для всех".
- Реальный выбор: premium Preview lane против стабильной GA lane.
С этой рамкой весь набор сигналов по продукту и цене начинает выглядеть логично.
Цены, бесплатный уровень и статус модели на 19 марта 2026 года

Именно цены превращают дискуссию "какая модель лучше" в реальное инженерное решение. Многие сравнительные статьи прячут это за общими бенчмарками, но официальная страница Gemini Developer API pricing дает очень прямой ответ на 19 марта 2026 года.
Для Gemini 3.1 Pro Preview указано:
- Free tier отсутствует
\$2.00за 1M входных токенов при промптах до 200k\$12.00за 1M выходных токенов при промптах до 200k\$4.00вход /\$18.00выход при промптах выше 200k- Batch-тарифы примерно вдвое ниже стандартных
Для Gemini 2.5 Pro указано:
- Free tier доступен
\$1.25за 1M входных токенов при промптах до 200k\$10.00за 1M выходных токенов при промптах до 200k\$2.50вход /\$15.00выход при промптах выше 200k- Batch-тарифы примерно вдвое ниже стандартных
Практически это значит:
- Вход: 3.1 Pro дороже на 60%.
- Выход: 3.1 Pro дороже на 20%.
- Тестовый контур: у 3.1 нет бесплатного входа.
Для продакшена этот разрыв может окупаться, если 3.1 заметно снижает ретраи, плохие первые ответы и объем ручной доработки. Но для рутинного кодинга, массового трафика и staging free-tier-потеря обычно ощущается быстрее, чем "красивые" цифры в benchmark-слайдах.
Простой расчет делает это еще понятнее. Если конвейер за месяц использует 50M входных и 10M выходных токенов (в основном до 200k), то:
- Gemini 2.5 Pro:
50 x \$1.25 = \$62.50(вход) +10 x \$10 = \$100(выход) =\$162.50 - Gemini 3.1 Pro:
50 x \$2.00 = \$100(вход) +10 x \$12 = \$120(выход) =\$220
Разница около 35% в этом сценарии, и это до учета ценности free tier у 2.5.
Статус модели по зрелости не менее важен, чем цены. И Gemini API models, и Vertex AI catalog подтверждают одну и ту же структуру: 3.1 Pro -- Preview, 2.5 Pro -- GA. Preview не значит "нельзя запускать", но значит "выше риск изменений поведения и ожиданий по эксплуатации".
Именно поэтому правильный вопрос в продакшене -- не "потянем ли мы 3.1 по бюджету", а "достаточно ли нам нужен 3.1, чтобы платить premium за Preview, если 2.5 уже закрывает основной workload". Для части сложных задач ответ "да", для широкого потока часто "пока нет".
Почему API-команды и пользователи Gemini App принимают разные решения
Одна из причин путаницы в выдаче -- в одном запросе смешиваются две разные аудитории. Одни решают, какую API-модель вызывать в продакшене. Другие пытаются понять, что именно доступно в Gemini App в рамках подписки. Это пересекающиеся, но не одинаковые решения.
Текущая выдача Google это отражает. Для API-аудитории главные источники: Gemini Developer API pricing, Gemini API models, Vertex AI models и model cards. Для app-аудитории Google подмешивает справочные страницы вроде Gemini Apps limits and upgrades, потому что там вопрос чаще звучит как "вижу ли я эту модель в интерфейсе и на каком плане".
Если вы API-команда, выбор между 3.1 и 2.5 -- это про пять вещей:
- качество на самых трудных задачах
- токенную цену
- наличие free tier
- операционную зрелость
- инфраструктурную экономику (кэш, batch, grounding)
Если вы пользователь Gemini App, выбор обычно уже:
- доступна ли модель в вашем тарифе
- какие лимиты применения внутри интерфейса
- заметна ли разница качества в ваших задачах
Именно поэтому API-экономика здесь сложнее, чем шаблон "новая модель чуть дороже".
На текущей pricing-странице у Gemini 3.1 Pro Preview выше не только базовый токенный тариф, но и сопутствующие расходы. Для промптов до 200k:
- context caching у 3.1 Pro Preview:
\$0.20за 1M токенов - context caching у 2.5 Pro:
\$0.125за 1M токенов - storage у обоих:
\$4.50 / 1,000,000 токенов в час
Выше 200k разрыв также сохраняется:
- 3.1 Pro Preview caching:
\$0.40 - 2.5 Pro caching:
\$0.25
То есть premium у 3.1 проявляется не только в строке input/output, но и в инфраструктурных компонентах, если у вас длинные системные промпты, тяжелый retrieval и переиспользуемый контекст.
Batch -- еще один пример. В верхней части pricing-страницы сказано про Batch API с 50% экономией. В фактических таблицах для обеих моделей это примерно соблюдается. До 200k:
- 3.1 Pro Preview batch:
\$1.00input и\$6.00output - 2.5 Pro batch:
\$0.625input и\$5.00output
Даже с batch 3.1 остается более дорогим маршрутом. Если трафик асинхронный и cost-sensitive, batch снижает стоимость обоих путей, но не убирает разницу.
Grounding тоже влияет на выбор, особенно если используете Google Search и Maps. Здесь важно читать формулировки аккуратно: у 3.1 Pro Preview указано 5,000 prompts/month free для grounding Search/Maps и затем \$14 / 1,000 search queries. У 2.5 Pro -- 1,500 RPD free и затем \$35 / 1,000 grounded prompts для Search и \$25 / 1,000 grounded prompts для Maps. Формально это не идеальное apples-to-apples, потому что единицы тарификации различаются, но практический вывод один: выбор модели одновременно становится выбором инструментарного чека.
Именно поэтому free tier недооценивают. Для многих команд это не "экономия для хобби", а рабочий контур:
- staging-прогоны
- эксперименты с шаблонами промптов
- регрессионные проверки low-risk
- smoke-тесты изменений роутинга
У 2.5 Pro этот контур есть. У 3.1 Pro Preview его нет.
Поэтому зрелые команды обычно не делают шаг "3.1 лучше -- переносим все". Они делают шаг "2.5 остается базовым контуром проверки, а 3.1 -- премиальным маршрутом для действительно сложных запросов".
Справочные страницы в выдаче усиливают этот вывод с другой стороны: многие пользователи ищут не benchmark, а ясность по surface доступа. В app-сценарии вопрос про тариф и доступность. В API-сценарии -- про экономику и эксплуатацию.
Эти вопросы частично пересекаются, но их нельзя смешивать. App-пользователь может выбирать "новее = лучше", потому что маржинальная стоимость скрыта в подписке. API-команда так работать не может: ей нужны прогнозируемость, управляемая стоимость и понятный fallback.
Поэтому статья снова и снова возвращается к роутингу:
- Для app-пользователя часто достаточно ответа "какую кнопку нажать".
- Для API-команды критично "какая модель несет массовый поток, а какая -- дорогие edge-cases".
Именно в API-чтении это сравнение раскрывается правильно.
Бенчмарки: где 3.1 действительно сильнее, а где сравнение менее чистое
Разделы про бенчмарки в AI-сравнениях часто звучат слишком уверенно. Здесь это особенно опасно, потому что официальные model card для Gemini 3.1 Pro и Gemini 2.5 Pro не являются одной единой same-date таблицей, где 3.1 напрямую сопоставлен с 2.5 по всем метрикам. Цифры полезны, но интерпретировать их нужно аккуратно.
Направление по двум официальным model card выглядит так:
| Бенчмарк | Официальное значение Gemini 3.1 Pro | Официальное значение Gemini 2.5 Pro | Безопасная интерпретация |
|---|---|---|---|
| Humanity's Last Exam | 44.4% | 21.6% | Сильный сигнал, что 3.1 поднимает frontier-рассуждение Google |
| GPQA Diamond | 94.3% | 86.4% | 3.1 выглядит заметно сильнее в научном рассуждении |
| SWE-Bench Verified | 80.6% | 59.6% | Направленно в пользу 3.1, но это не единый same-date стенд |
| Terminal-Bench 2.0 | 68.5% | Не указан в 2.5 GA card | 3.1 явно позиционируется под более сильный agentic coding |
| APEX-Agents | 33.5% | Не указан в 2.5 GA card | Еще один сигнал в пользу long-horizon агентных задач |
| Контекст / вывод | 1M / 64K | 1M / 64K | По headline-лимитам преимущества 3.1 нет |
Самая корректная трактовка: Gemini 3.1 Pro действительно усиливает frontier-level reasoning и агентный контур, но не стоит делать вид, что каждая строка двух разных model card -- идеальная лабораторная head-to-head проверка.
Даже с этим ограничением паттерн очевиден. 3.1 Pro чаще нужен там, где:
- задача многошаговая и tool-heavy
- качество цепочки рассуждения реально меняет исход
- агентный кодинг важнее рутинного autocomplete
- цена ошибки в человеко-часах высока
2.5 Pro остается сильным там, где:
- задачи сложные, но не frontier-экстремальные
- нагрузка массовая и повторяемая
- бюджет чувствителен к стоимости токенов
- важна широкая операционная устойчивость
Именно поэтому бенчмарки должны менять роутинг, а не подталкивать к тотальной замене. Если самые сложные 5% задач определяют бизнес-ценность, premium 3.1 может легко окупаться. Если же 95% потока -- это стабильный рутинный workload, цена и зрелость 2.5 Pro часто оказываются важнее.
Есть еще один важный момент: обе модели уже дают 1M контекста и 64K вывода. Значит, в выборе вы покупаете не "больше лимитов", а "более сильное мышление для определенных классов задач". Поэтому сегментация workload здесь критична.
Задержка, длинный контекст и надежность в продакшене
Официальные документы хорошо показывают capability-уровень, но не снимают главный операционный вопрос: насколько предсказуемо ведет себя новая модель под реальной нагрузкой.
Здесь выдача становится особенно показательной. Рядом с официальными страницами Google выводит и пользовательский friction-контент, например тред на Google AI Developers Forum: "Gemini 3 significantly worse thant 2.5 Pro at long context. Temperature likely to blame". Это не каноничная спецификация платформы и не источник для жестких фактов, но это важный сигнал: часть пользователей сравнивает модели не по релизному нарративу, а по стабильности на сложных и длинных промптах.
Это важно, потому что обе model card дают одинаковые 1M/64K лимиты. На бумаге -- паритет. На практике равные потолки не гарантируют равный UX. В продакшене решают вопросы:
- какая модель предсказуемее на вашем реальном prompt mix
- где меньше дорогих неудачных first-pass ответов
- где проще fallback и оркестрация
- где premium действительно окупается снижением ретраев и правок
Для многих команд 2.5 Pro остается более ровным вариантом: GA-статус плюс более низкая цена. Preview не означает "нестабильно всегда", но это достаточная причина не назначать 3.1 универсальным дефолтом до собственных измерений.
Также полезно разделить capability-риск и product-риск. По capability 3.1 чаще выигрывает на сложных задачах рассуждения и агентности. По product-критериям 2.5 часто выигрывает для широкого деплоя, потому что:
- это GA, а не Preview
- есть free tier
- ниже стоимость
- команда уже знает его поведение
Поэтому практично почти всегда работает progressive routing, а не blanket replacement: 2.5 несет массовый lane, 3.1 забирает действительно сложные запросы. Если метрики на 3.1 стабильно лучше -- увеличиваете долю. Если нет -- вы не ломаете весь контур ради "самой новой" метки.
Если вы уже глубоко работаете с Google-стеком, посмотрите смежные материалы по эксплуатации: лимит вывода Gemini 3.1 Pro, таймауты Gemini 3.1 Pro и диагностика ошибок Gemini API. На практике именно эти operational-детали чаще всего определяют production-ready статус.
Какую модель выбрать для кодинга, агентов, исследований и контроля затрат
Самый полезный способ читать это сравнение -- перестать искать "общего победителя" и привязать выбор к конкретным workload.
| Тип нагрузки | Лучший дефолт | Почему |
|---|---|---|
| Повседневный coding-assistance | Gemini 2.5 Pro | Дешевле, GA, и достаточно силен для массового кода |
| Сложный agentic coding | Gemini 3.1 Pro | Официальное позиционирование и benchmark-наратив указывают на более сильный агентный контур |
| Исследовательская аналитика | Gemini 3.1 Pro | Более сильные frontier-сигналы упрощают обоснование premium |
| Long-context анализ в масштабе | Сначала Gemini 2.5 Pro, затем выборочная эскалация на 3.1 | Лимиты 1M одинаковые, но 2.5 дешевле и безопаснее как default lane |
| Эксперименты на free tier | Gemini 2.5 Pro | У 3.1 Pro free tier отсутствует |
| Массовый продакшен-трафик | Gemini 2.5 Pro | GA-зрелость и низкая цена снижают операционное трение |
| Premium fallback lane | Gemini 3.1 Pro | Лучшее применение новой модели, когда не каждый запрос требует premium-уровня |
Для индивидуальных разработчиков и маленьких команд обычно достаточно простой схемы: старт на 2.5 Pro, выделенный маршрут на 3.1 для hardest-cases и никакой лишней сложности, пока premium lane не начал явно окупаться.
Для больших инженерных команд это уже архитектурный вопрос. Если у вас есть routing-layer, 3.1 Pro логично использовать как high-intelligence lane, а 2.5 оставить bulk lane. В такой системе худшее решение обычно не "оставить старую модель", а "послать весь трафик в дорогой Preview без дискриминации задач".
Для исследовательских и оценочных команд 3.1 Pro может получать более высокий приоритет. Его official model card дает более сильный frontier-сигнал, и в задачах сложного синтеза или длинных агентных цепочек premium чаще оправдан. Но цену все равно нельзя игнорировать.
Для cost-sensitive продакшена 2.5 Pro все еще трудно превзойти: GA + free tier + более низкий токенный тариф дают лучшую экономику для широкого потока. Если у вас нет измеренного бизнес-выигрыша от 3.1, дефолт на 2.5 остается рациональным.
В этом контексте уместен и multi-model gateway. Если реальная проблема -- не выбор "одной модели", а управляемый роутинг между поколениями в едином кодовом контуре, платформа типа laozhang.ai может быть полезна как слой маршрутизации, fallback и биллинга. Это не рекламный тезис, а инженерная реальность: в продакшене выбор модели почти всегда превращается в задачу orchestration.
Что протестировать, прежде чем повышать долю 3.1 Pro
Самая частая ошибка после прочтения таких сравнений -- прогнать пару впечатляющих промптов на 3.1 Pro, увидеть "умнее" и сразу менять дефолт везде. Это недостаточно строгий процесс. Здесь есть реальные trade-off по цене и зрелости, поэтому тестировать нужно как оператор, а не как любопытный пользователь.
Начните с разбиения workload по смысловым корзинам:
| Корзина оценки | Примеры | Какой вопрос вы реально проверяете |
|---|---|---|
| Рутинный код и правки | refactor, мелкие тесты, простые багфиксы | Дает ли 3.1 выгоду, оправдывающую premium в массовой работе? |
| Сложный agentic coding | многошаговые изменения репозитория, tool-heavy repair loop | Снижает ли 3.1 долю first-pass провалов и ручной ревью? |
| Long-context анализ | длинные документы, большие транскрипты, multi-file reasoning | Сохраняет ли 3.1 преимущество на "тяжелых" промптах? |
| Grounded research / tool use | search-backed ответы, оркестрация инструментов | Окупает ли выгода допрасходы на tool-side экономику? |
| Cost-sensitive bulk traffic | большой поток рутинных запросов | Есть ли причина уводить дефолт с 2.5? |
Если тестировать только одну корзину, решение почти наверняка будет ошибочным. 3.1 может быть очень сильным в hard-agentic сегменте и одновременно быть плохим кандидатом на default lane для массового трафика.
Второе правило: измеряйте принятый результат, а не "кто красивее ответил". Ключевая метрика -- "стоимость приемлемого результата после ретраев, правок и ревью", а не только токены.
Обычно это требует минимум таких полей:
- first-pass acceptance rate
- минуты ручной доработки
- retry rate
- p95 latency
- token cost
- caching cost (где применимо)
- grounding cost (где применимо)
- fallback rate
Без этих чисел вы не узнаете, где модель реально дешевле в бизнес-смысле. Дорогая модель может выиграть, если сокращает ручную доработку. И наоборот -- более "умная" модель может проиграть, если эффект проявляется только на узком хвосте трафика.
Именно здесь команды впервые видят разницу между "benchmark winner" и "default winner".
Чтобы тест был корректным, держите условия стабильными:
- Заморозьте prompt-template на время теста.
- Используйте один и тот же набор инструментов для обеих моделей.
- Держите сопоставимые настройки temperature/reasoning там, где API это позволяет.
- Тестируйте на production-like запросах, а не на демонстрационных toy-задачах.
- Не усредняйте все подряд: разделяйте легкие и сложные кейсы.
Пятый пункт критичен: смешанное среднее скрывает выигрыш hard-сегмента или, наоборот, искусственно завышает ценность модели за счет hero-cases.
Третье правило: тестируйте операционное поведение, а не только correctness. Когда у обеих моделей уже есть 1M/64K, разница часто проявляется в эксплуатационных деталях:
- сколько запросов требуют дополнительного ретрая
- насколько стабильно держится tool orchestration в длинных цепочках
- сохраняется ли связность long-context ответов
- насколько удобно постобрабатывать структуру ответа
- насколько предсказуемо поведение модели от недели к неделе
Именно здесь важен Preview-статус. Preview может быть production-годным, но переводить его в broad default lane разумно только при более строгом пороге допуска.
Рациональный promotion-test для 3.1 Pro обычно выглядит так:
- Соберите репрезентативный набор запросов за последние 2-4 недели.
- Разметьте каждый запрос по типу задачи и бизнес-критичности.
- Прогоните одинаковый набор на Gemini 2.5 Pro и Gemini 3.1 Pro.
- Оцените результаты в blinded review, где это возможно.
- Считайте качество вместе с latency и retry-поведением.
- Сравните cost per accepted answer, а не только cost per token.
- Держите тест достаточно долго, чтобы увидеть стабильность, а не launch-эффект.
Если объем позволяет, не останавливайтесь на offline-тесте. Делайте controlled live experiment:
- 2.5 Pro остается дефолтом
- узкий срез hardest-запросов уходит в 3.1 Pro
- сравниваете бизнес-метрики именно на этом срезе
- расширяете долю только при устойчивом результате
Это полностью соответствует продуктовой реальности: 2.5 -- broad lane, 3.1 -- premium lane, которая должна доказать свою долю.
Четвертое правило: проверяйте tool-side экономику, а не только текстовые ответы. Если система завязана на длинные промпты, кэш, batch и grounding, решение по апгрейду -- это и инфраструктурное решение:
- остается ли 3.1 экономически разумным с более дорогим caching
- сохраняет ли batch приемлемую маржу
- выдерживает ли grounded-workflow бюджет при вашем объеме
- не замедляет ли отсутствие free tier скорость экспериментов
Пятое правило: задайте promotion-gate до анализа результатов. Иначе команда почти всегда подгоняет критерии под желаемый исход. Пример жесткого gate:
- 3.1 должен дать значимый выигрыш на hard-task корзине
- рост latency должен укладываться в SLO
- cost per accepted answer должен оставаться в заранее принятом premium-диапазоне
- Preview-поведение должно быть стабильным в многодневном/многонедельном окне
- bulk-трафик либо остается на 2.5, либо получает измеримую бизнес-причину для миграции
Если 3.1 проходит gate -- масштабируете там, где он выиграл. Если нет -- оставляете его в specialty lane. Это не провал, а корректный результат теста.
Практический паттерн, который обычно работает лучше всего:
- классифицируйте запросы на low / medium / high difficulty
- держите
gemini-2.5-proдля low и большей части medium - отправляйте high difficulty / high review cost в
gemini-3.1-pro-preview - еженедельно мониторьте hard bucket и ежемесячно пересматривайте правила
Так вы получаете большую часть upside новой модели без насильственного перевода всего трафика на дорогой Preview.
Короткая формула для этого раздела: сравнивайте премиальный маршрут с бюджетом на исправления, а не с любопытством команды. 3.1 Pro заслуживает статус дефолта только если улучшает дорогую часть рабочего процесса настолько, что перекрывает премию по цене и риску зрелости.
Стратегия миграции: заменить, разделить роутинг или остаться на 2.5 Pro
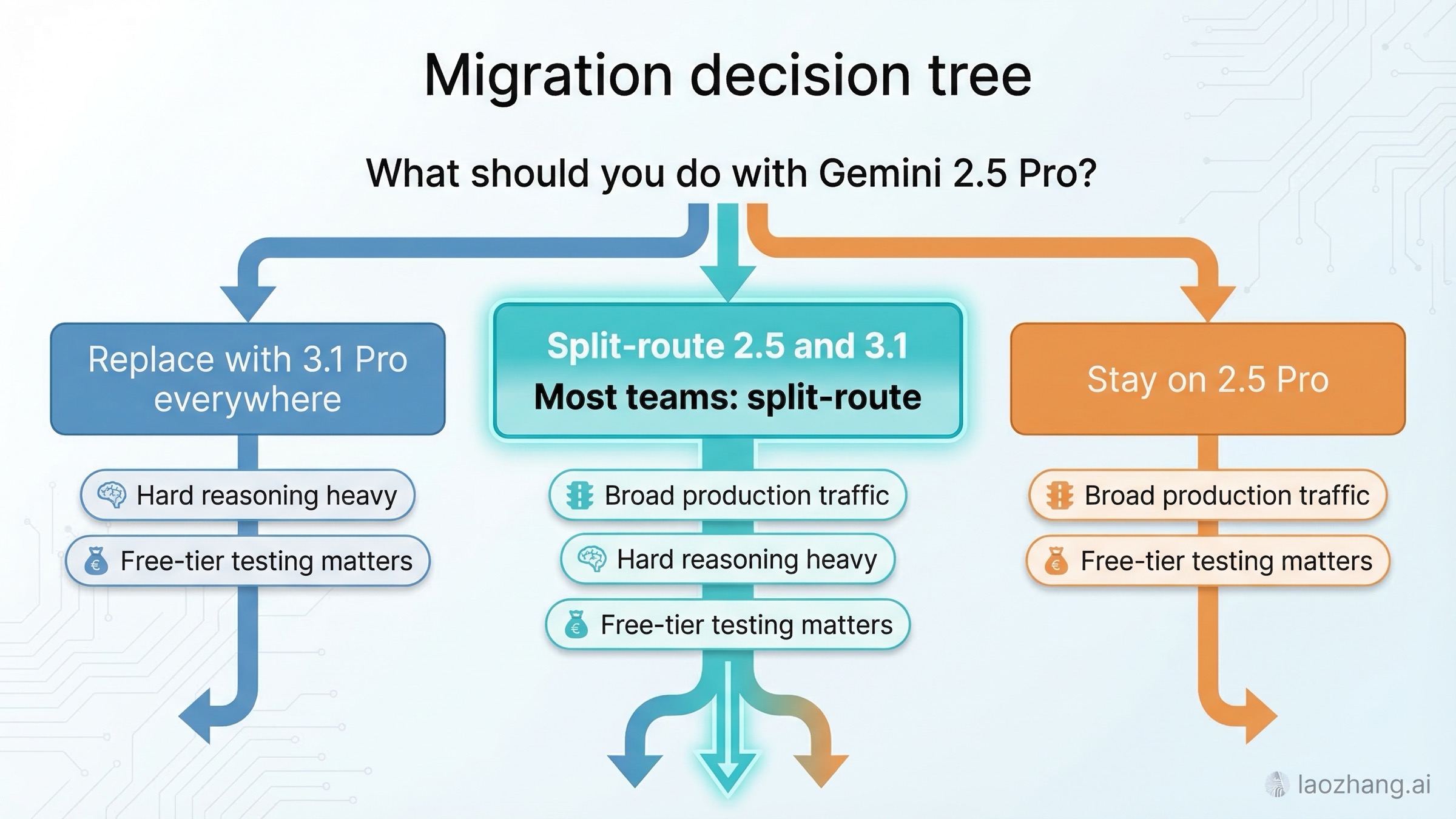
Для большинства команд существует три практичных шаблона миграции.
Шаблон 1: полностью заменить 2.5 Pro на 3.1 Pro. Это оправдано только если ваша нагрузка действительно сосредоточена в сложном reasoning/agentic сегменте и команда готова держать Preview как дефолт. Это самый агрессивный путь и самый рискованный без строгого измерения качества, latency и стоимости.
Шаблон 2: split-routing между 2.5 и 3.1. Для большинства это лучший вариант. 2.5 Pro остается default lane. 3.1 Pro получает запросы, где выполняется хотя бы одно условие:
- Запрос высокостоит по риску, а цена человеческой проверки велика.
- First-pass failure rate на 2.5 уже бьет по throughput.
- Задача явно многошаговая и агентная, а не single-shot.
- Дополнительная сила рассуждения важнее экономии токенов.
Простая политика роутинга часто уже достаточна:
tsfunction chooseGeminiModel(task: { requiresAgenticCoding: boolean; reasoningDifficulty: "low" | "medium" | "high"; costSensitive: boolean; needsFreeTierFallback: boolean; }) { if (task.needsFreeTierFallback || task.costSensitive) { return "gemini-2.5-pro"; } if (task.requiresAgenticCoding || task.reasoningDifficulty === "high") { return "gemini-3.1-pro-preview"; } return "gemini-2.5-pro"; }
Шаблон 3: пока остаться на 2.5 Pro. Это не "страх нового", а рациональный выбор, если текущего качества уже достаточно, free-tier контур критичен, а premium 3.1 пока не дает измеримого бизнес-эффекта.
Чистый migration-checklist:
- Сравните обе модели на собственных production-like промптах.
- Считайте качество вместе с ценой человеческой доработки.
- Держите 2.5 Pro в fallback до подтверждения стабильности 3.1 на боевой нагрузке.
- Не делайте вывод "3.1 лучше везде" только из model card.
- Масштабируйте 3.1 только там, где выигрыш подтвержден и оправдывает цену/риск.
В этом и суть: Gemini 3.1 Pro продвигают в дефолт по данным, а не по факту более нового имени.
FAQ
Gemini 3.1 Pro лучше, чем Gemini 2.5 Pro?
Да, если речь о top-end reasoning и агентных задачах: это поддержано текущим позиционированием Google и model card Gemini 3.1 Pro. Нет, если понимать "лучше во всем". Gemini 2.5 Pro остается дешевле, имеет GA-статус и free tier, поэтому часто выигрывает как дефолт.
Дает ли Gemini 3.1 Pro больше контекста или больший output limit?
Нет. На 19 марта 2026 года официальная документация для обеих моделей указывает 1M контекста и 64K вывода. Ключевые различия -- качество, цена и статус зрелости.
Gemini 3.1 Pro заметно дороже?
Да. На официальной странице Gemini Developer API pricing у 3.1 Pro -- \$2.00 input и \$12.00 output за 1M токенов до 200k. У 2.5 Pro -- \$1.25 input и \$10.00 output в том же диапазоне, плюс доступен free tier.
Стоит ли переводить весь трафик с Gemini 2.5 Pro на Gemini 3.1 Pro?
Обычно нет. Базовый паттерн -- оставить 2.5 Pro для широкого потока и эскалировать на 3.1 только hardest-cases. Полная замена оправдана, когда измеренный выигрыш в качестве стабильно окупает premium и Preview-риск.
Можно ли считать benchmark-цифры полностью apples-to-apples?
Нет. Это официальные данные, но они не из одного единого same-date head-to-head документа. Используйте их как направляющий сигнал и комбинируйте с ценой, статусом и workload-fit.
Одинаково ли важно это сравнение для Gemini App и Gemini API?
Не совсем. Для app-пользователей важнее доступ по подписке и лимиты в интерфейсе. Для API-команд важнее free tier, токенная экономика, batch/grounding и стратегия роутинга. Поэтому здесь фокус на production API-решении.
Итог
Если вам нужен максимально сильный текущий Gemini для hardest reasoning и agentic workflow, выбирайте Gemini 3.1 Pro. Если нужен лучший дефолт для стабильного и ценочувствительного продакшена, выбирайте Gemini 2.5 Pro. Если есть роутинг -- используйте обе модели и распределяйте трафик по сложности задачи.