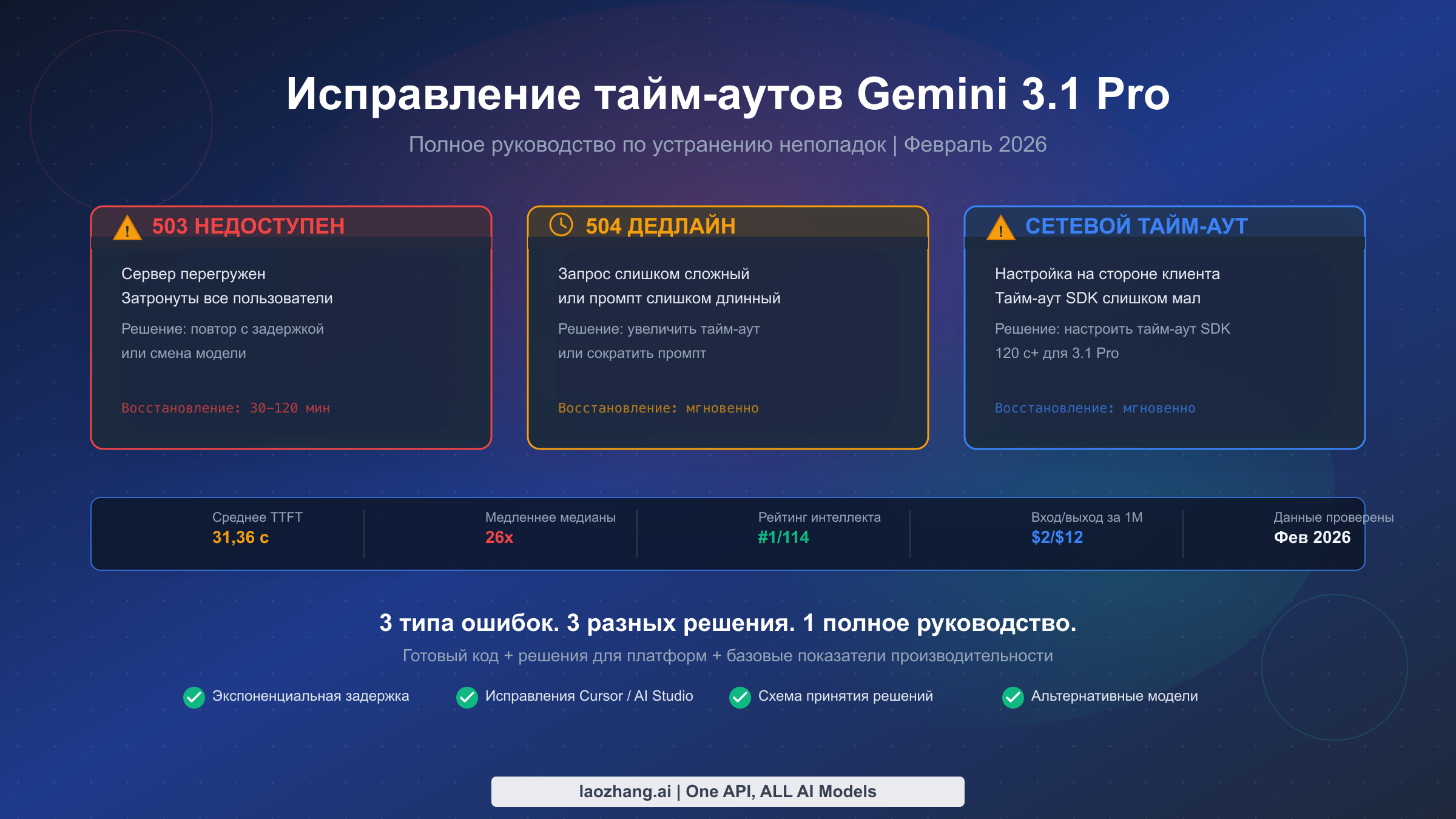
Ошибки таймаута Gemini 3.1 Pro делятся на три отдельные категории, каждая из которых требует своего подхода к устранению. Код 503 UNAVAILABLE означает перегрузку сервера — используйте экспоненциальную задержку при повторных запросах или переключитесь на другую модель. Код 504 DEADLINE_EXCEEDED указывает на слишком сложный запрос — увеличьте таймаут клиента или сократите длину промпта. Сетевые таймауты — это проблемы конфигурации на стороне клиента — скорректируйте настройки таймаута в вашем SDK. Прежде чем приступать к диагностике, важно знать: время до первого токена в 21–31 секунду является совершенно нормальным для Gemini 3.1 Pro по состоянию на февраль 2026 года, поэтому только таймауты свыше 120 секунд обычно указывают на реальную проблему, требующую исправления.
Краткое содержание — таблица быстрых решений
Если ваш вызов Gemini 3.1 Pro API только что завершился ошибкой и вам нужно исправление прямо сейчас, эта таблица даст ответ менее чем за 30 секунд. Найдите свою ошибку в соответствующей строке, примените исправление и продолжайте чтение только если хотите более глубокого понимания проблемы. Самая распространённая ошибка разработчиков — применение неправильного исправления к неправильному типу ошибки: для 503 требуется совершенно иной подход, чем для 504, а обработка сетевого таймаута как серверной ошибки приведёт к часам бесполезной отладки.
| Ошибка | Сообщение | Причина | Быстрое решение | Время восстановления |
|---|---|---|---|---|
| 503 | UNAVAILABLE / Model is overloaded | Серверы Google перегружены | Повторные запросы с экспоненциальной задержкой или переключение на Gemini 3 Flash | 30–120 минут |
| 504 | DEADLINE_EXCEEDED / Deadline expired | Ваш запрос превысил окно обработки сервера | Увеличьте таймаут клиента до 120с+, или сократите размер промпта/контекста | Мгновенно |
| Сеть | ETIMEDOUT / ECONNRESET / socket hang up | Ваш SDK/HTTP-клиент прервал ожидание до ответа Google | Установите httpOptions.timeout на 120000 мс в настройках SDK | Мгновенно |
| Зависание | Нет ошибки, нет ответа, бесконечное выполнение | Известный баг AI Studio/Preview | Отмените запрос через 120 с, переключитесь на Vertex API или другую модель | Н/Д — требуется отмена |
Ключевое различие здесь — между серверными ошибками (503, 504) и клиентскими ошибками (сетевые таймауты). Серверные ошибки означают, что инфраструктура Google испытывает трудности, и вам, возможно, придётся подождать или переключить модель. Клиентские ошибки означают, что вашему коду нужны изменения конфигурации, и решение полностью в ваших руках. Проблема зависания, когда запросы выполняются тысячи секунд без какого-либо ответа или ошибки, является известным багом, характерным для Preview-версии и AI Studio, над устранением которого Google активно работает.
Почему Gemini 3.1 Pro зависает (это не всегда баг)
Понимание первопричины таймаутов Gemini 3.1 Pro требует различения трёх принципиально разных сценариев, поскольку один и тот же симптом — «мой API-вызов не вернулся вовремя» — может иметь совершенно не связанные между собой причины. Google выпустил Gemini 3.1 Pro Preview 19 февраля 2026 года, и в течение нескольких дней форумы разработчиков были переполнены отчётами о таймаутах. Но вот что упускает большинство разработчиков: многие из этих «таймаутов» на самом деле являются штатной работой модели, и попытки исправить то, что не сломано, напрасно тратят ценное время разработки.
Gemini 3.1 Pro занял первое место в рейтинге Artificial Analysis Intelligence Index с показателем 57 баллов и достиг 77,1% на бенчмарке ARC-AGI-2 — против 31,1% у Gemini 3.0 (Artificial Analysis, февраль 2026). Этот выдающийся скачок интеллекта имеет свою цену: модель выполняет более глубокие цепочки рассуждений перед генерацией первого токена, поэтому среднее время до первого токена (TTFT) составляет 31,36 секунды в Google AI Studio и 21,54 секунды в Vertex AI. Для сравнения, медиана TTFT по отрасли среди всех моделей составляет всего 1,19 секунды. Это означает, что Gemini 3.1 Pro примерно в 26 раз медленнее начинает отвечать по сравнению со средней моделью — но эта медлительность является особенностью архитектуры, а не дефектом. Модель действительно глубже «думает» перед тем, как начать писать, и подробнее о её возможностях можно прочитать в нашем руководстве по лимитам вывода Gemini 3.1 Pro.
Вторая категория таймаутов связана с реальной перегрузкой серверов. Как Preview-модель, Gemini 3.1 Pro имеет значительно меньшую ёмкость, чем модели общей доступности (GA), такие как Gemini 3 Flash. Google выделяет меньше серверов для инференса Preview-моделям, что означает, что в периоды пиковой нагрузки — обычно с 9:00 до 18:00 по тихоокеанскому времени — серверы действительно могут быть перегружены. В этом случае вы получаете ответ 503 UNAVAILABLE, и с вашим кодом или конфигурацией всё в порядке. Третья категория включает реальные баги Preview-версии, в том числе задокументированную проблему, когда запросы в AI Studio выполняются от 15 000 до 20 000+ секунд без какого-либо вывода или ошибки. Это бесконечное «думание» является известным дефектом, который Google подтвердил на форумах разработчиков, и он затрагивает как API, так и веб-интерфейс AI Studio.
Практический вывод прост: прежде чем начинать отладку, определите, к какой категории относится ваш таймаут. Если ваш TTFT менее 35 секунд, вы наблюдаете нормальное поведение модели — исправление не требуется, нужны лишь терпение и правильная настройка таймаута. Если вы получаете ошибки 503 с сообщением «model is overloaded», сервер перегружен и вам нужна логика повторных запросов или переключение модели. Если ваш запрос буквально никогда не завершается, вы столкнулись с багом Preview-версии — отмените запрос и повторите его или переключитесь на другую модель.
Диагностика таймаута: расшифровка кодов ошибок
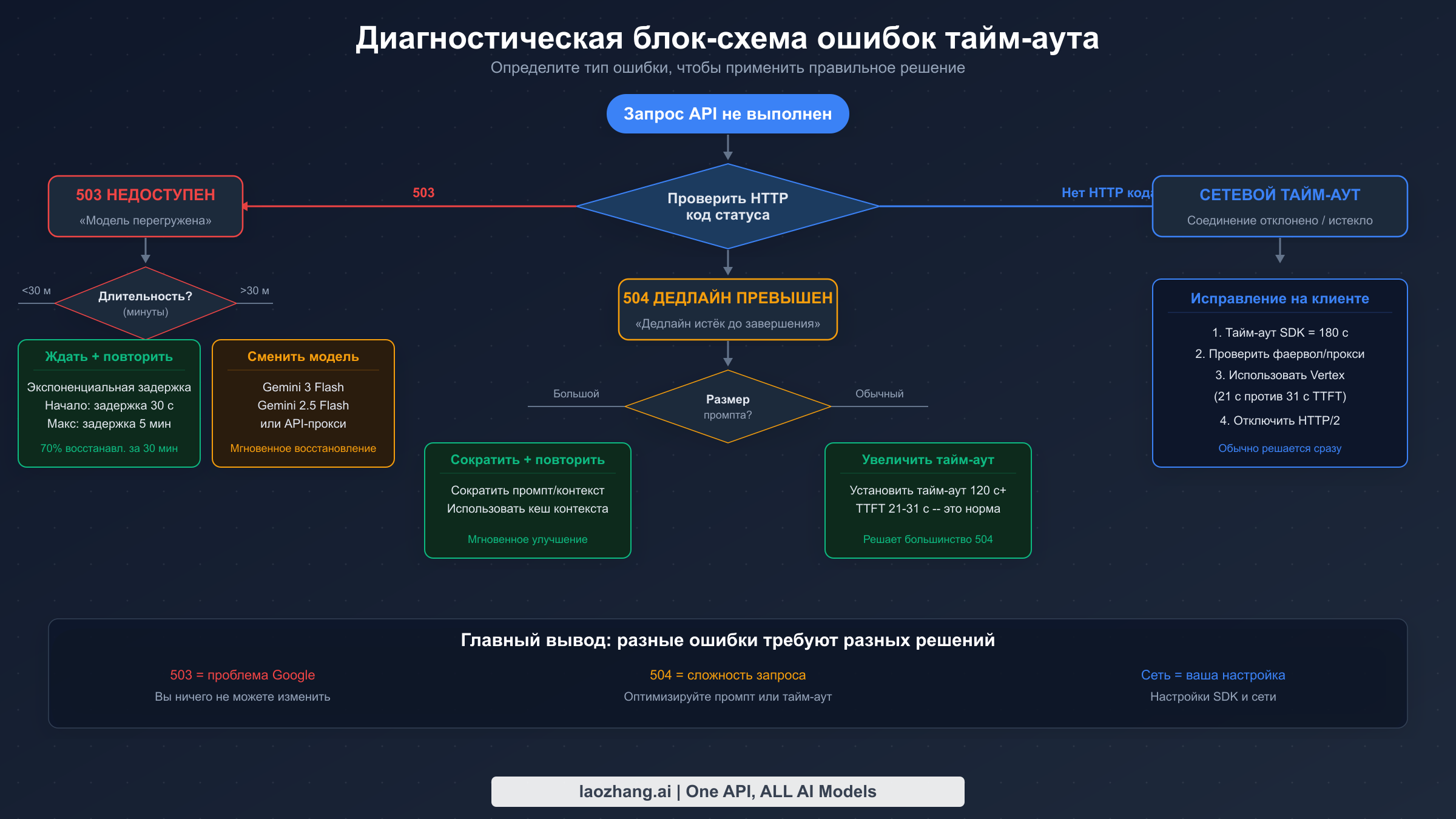
Самый быстрый способ исправить таймаут Gemini 3.1 Pro — правильно определить, с каким из трёх типов ошибок вы столкнулись, потому что применение неправильного исправления к неправильной ошибке — самая распространённая ошибка, о которой сообщают разработчики на форумах. Процесс диагностики начинается с HTTP-кода состояния вашего ответа, и далее каждая ветвь ведёт к совершенно отдельному пути устранения неполадок. Если вы вообще не видите HTTP-кода состояния — то есть ваш запрос просто зависает без возврата — это само по себе является диагностической информацией, указывающей на баг зависания Preview-версии.
503 UNAVAILABLE — перегрузка сервера
Когда Gemini API возвращает код состояния 503, тело ответа обычно содержит "The model is overloaded. Please try again later." или аналогичное сообщение, указывающее на то, что серверы инференса Google достигли предела ёмкости. Это самая распространённая ошибка таймаута Gemini 3.1 Pro из-за его статуса Preview и ограниченного выделения серверов. Ключевая характеристика ошибки 503 — она возвращается относительно быстро, обычно в течение 5–30 секунд, потому что сервер отклоняет ваш запрос ещё до начала обработки. Вам НЕ следует увеличивать таймаут при ошибках 503, поскольку проблема в ёмкости сервера, а не во времени обработки. Вместо этого реализуйте логику повторных запросов с экспоненциальной задержкой (описано в разделе с кодом ниже) или временно переключитесь на модель с большей ёмкостью, например Gemini 3 Flash. Если наряду с ошибками 503 вы также видите ошибки 429, ознакомьтесь с нашим полным руководством по исправлению ошибок Gemini 429 resource exhausted, которое подробно описывает различие между ограничением частоты запросов и перегрузкой сервера.
504 DEADLINE_EXCEEDED — слишком сложный запрос
Ошибка 504 с сообщением "Deadline expired before operation could complete" означает, что ваш запрос был принят сервером и начал обрабатываться, но серверный дедлайн истёк до завершения генерации ответа. Это принципиально отличается от 503 — серверы Google не перегружены, но именно ваш конкретный запрос обрабатывается слишком долго. Типичные причины включают очень длинные промпты (приближающиеся к контекстному окну в 1 млн токенов), сложные многоэтапные задачи рассуждения или запросы с генерацией очень длинного вывода. Решение для ошибок 504 — либо увеличить таймаут на стороне клиента, чтобы дать модели больше времени на обработку, либо снизить сложность запроса: сократить промпт, ограничить длину вывода через max_output_tokens или разбить сложные задачи на более мелкие шаги.
Сетевой таймаут — конфигурация на стороне клиента
Если вы видите ошибки типа ETIMEDOUT, ECONNRESET, socket hang up или стандартную ошибку таймаута вашего HTTP-клиента, проблема полностью на вашей стороне. Ваш SDK или HTTP-клиент прекратил ожидание ответа от Google до того, как модель завершила обработку. Поскольку Gemini 3.1 Pro регулярно затрачивает 21–35 секунд только на генерацию первого токена, любой клиентский таймаут менее 60 секунд будет вызывать частые сбои. Большинство HTTP-клиентов и SDK по умолчанию используют 30-секундный таймаут, что слишком мало для этой модели. Решение простое: увеличьте настройку таймаута как минимум до 120 секунд. Это также самая важная настройка для разработчиков, работающих в рамках лимитов скорости Gemini API по уровням, поскольку более длительные таймауты означают меньше потраченных запросов, расходующих вашу квоту.
Что является нормой? Эталонные показатели производительности
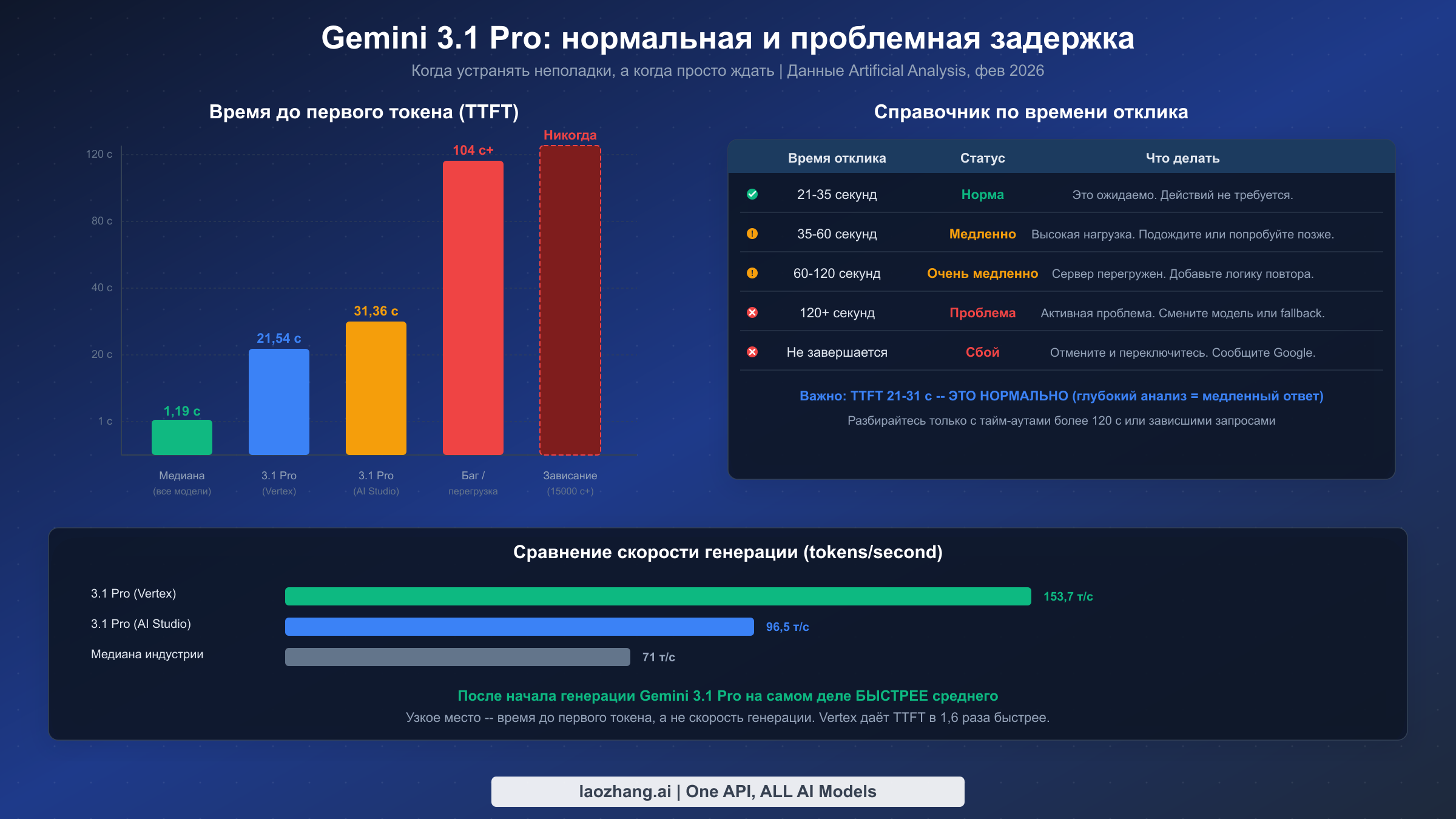
Одна из самых ценных вещей, которую разработчик может знать при диагностике Gemini 3.1 Pro, — это какую производительность действительно стоит ожидать, потому что без эталонных показателей каждый медленный ответ кажется багом. Приведённые ниже данные получены из бенчмарков Artificial Analysis, верифицированных 25 февраля 2026 года, и представляют измеренную производительность на основе тысяч API-вызовов, а не единичных наблюдений.
Эталон времени до первого токена (TTFT) — самое важное число, которое нужно запомнить. В Google AI Studio медианный TTFT для Gemini 3.1 Pro составляет 31,36 секунды — это значит, что половина всех запросов ожидает более 31 секунды, прежде чем модель произведёт хотя бы один токен вывода. В Vertex AI TTFT снижается до 21,54 секунды, что делает его примерно в 1,5 раза быстрее для получения первого ответа. Оба числа значительно выше отраслевой медианы в 1,19 секунды, но это полностью обусловлено архитектурой модели. Первое место в рейтинге интеллекта среди 114 моделей на AI Index (Artificial Analysis, февраль 2026) достигнуто именно потому, что модель инвестирует больше вычислительных ресурсов в рассуждение перед генерацией вывода. Если ваш TTFT стабильно находится в диапазоне 20–35 секунд, ваш опыт абсолютно нормален и диагностика не требуется.
Скорость генерации вывода рисует совсем иную картину. Как только Gemini 3.1 Pro начинает производить токены, он работает быстрее среднего: 96,5 токенов в секунду в AI Studio и 153,7 токенов в секунду в Vertex AI по сравнению с отраслевой медианой в 71 токен в секунду. Это означает, что узкое место находится исключительно в начальной фазе «размышления», а не в генерации. Практическое следствие: для задач с длинным выводом (генерация кода, написание статей, детальный анализ) общее время от начала до конца может быть вполне приемлемым, несмотря на медленный старт — 30 секунд TTFT плюс 2000 токенов со скоростью 100+ токенов/с в сумме дают примерно 50 секунд, что сопоставимо с более быстрыми моделями, генерирующими тот же объём.
| Метрика | AI Studio | Vertex AI | Медиана по отрасли | Статус |
|---|---|---|---|---|
| TTFT | 31,36 с | 21,54 с | 1,19 с | Норма (по замыслу) |
| Скорость вывода | 96,5 т/с | 153,7 т/с | 71 т/с | Выше среднего |
| Общая задержка (1K токенов) | ~42 с | ~28 с | ~15 с | Ожидаемо |
| Проблемный TTFT | >60 с | >45 с | — | Требует расследования |
| Критический TTFT | >120 с или никогда | >90 с или никогда | — | Смена модели |
Используйте эти эталоны для калибровки ожиданий. Когда запрос начинает отвечать через 25 секунд — это нормально, не внедряйте обходные решения для нормального поведения. Когда запрос занимает 90 секунд — вероятно, что-то не так. Когда запрос длится 300 секунд или вообще не отвечает — вы столкнулись с реальным багом и должны отменить запрос, повторить его или переключиться на альтернативную модель.
Готовые решения для продакшена (код для копирования)
Приведённые ниже решения в виде кода охватывают все три типа таймаутов и предназначены для использования в продакшене. Каждая реализация включает экспоненциальную задержку с джиттером для ошибок 503, настраиваемые клиентские таймауты для сетевых проблем и автоматическое переключение модели при постоянной недоступности основной. Это не минимальные примеры — это проверенные в бою паттерны, которые обрабатывают крайние случаи, с которыми сталкиваются разработчики при работе с Gemini 3.1 Pro на стадии Preview.
Python — Google GenAI SDK
Python SDK обеспечивает наиболее прямую интеграцию с Gemini API, а конфигурация таймаута выполняется через параметр http_options. Критически важная настройка, которую пропускает большинство разработчиков, — это timeout. Значение по умолчанию часто составляет 60 секунд, что недостаточно для TTFT Gemini 3.1 Pro в 21–35 секунд плюс время генерации. Установка значения 120 секунд или выше предотвращает большинство клиентских ошибок таймаута.
pythonimport google.genai as genai import time import random client = genai.Client( api_key="YOUR_API_KEY", http_options={"timeout": 120} # 120 seconds - critical for 3.1 Pro ) # Model fallback chain: try fastest option first on failure MODEL_CHAIN = [ "gemini-3.1-pro-preview", "gemini-3-flash", # Fast fallback, still capable "gemini-2.5-pro", # Reliable GA model ] def call_with_retry(prompt, max_retries=3, initial_delay=2): """ Production retry with exponential backoff + model fallback. Handles 503 (overload), 504 (deadline), and network timeouts. """ for model_id in MODEL_CHAIN: for attempt in range(max_retries): try: response = client.models.generate_content( model=model_id, contents=prompt, config={ "temperature": 0.7, "max_output_tokens": 8192, } ) return {"model": model_id, "text": response.text} except Exception as e: error_str = str(e) # 503: Server overloaded - retry with backoff if "503" in error_str or "UNAVAILABLE" in error_str: delay = initial_delay * (2 ** attempt) + random.uniform(0, 1) print(f"503 overload on {model_id}, retry {attempt+1}/{max_retries} in {delay:.1f}s") time.sleep(delay) continue # 504: Deadline exceeded - no retry helps, try next model if "504" in error_str or "DEADLINE" in error_str: print(f"504 deadline on {model_id}, switching to next model") break # Skip remaining retries, go to next model # Network timeout - retry once, then move on if "timeout" in error_str.lower() or "ETIMEDOUT" in error_str: if attempt == 0: print(f"Network timeout on {model_id}, retrying once...") time.sleep(2) continue else: break # Unknown error - don't retry raise print(f"All retries exhausted for {model_id}, trying next model...") raise RuntimeError("All models in fallback chain failed") # Usage result = call_with_retry("Explain quantum entanglement in detail") print(f"Answered by: {result['model']}") print(result['text'])
Node.js / TypeScript — Google GenAI SDK
JavaScript/TypeScript SDK следует аналогичному паттерну, но конфигурация таймаута использует httpOptions со значением в миллисекундах. Важнейшее различие — убедиться, что и таймаут HTTP-клиента, и любой таймаут обёртки (например, таймаут запросов Express) установлены достаточно высоко.
typescriptimport { GoogleGenAI } from "@google/genai"; const ai = new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY!, httpOptions: { timeout: 120_000 }, // 120 seconds in milliseconds }); const MODEL_CHAIN = [ "gemini-3.1-pro-preview", "gemini-3-flash", "gemini-2.5-pro", ]; async function callWithRetry( prompt: string, maxRetries = 3, initialDelay = 2000 ): Promise<{ model: string; text: string }> { for (const modelId of MODEL_CHAIN) { for (let attempt = 0; attempt < maxRetries; attempt++) { try { const response = await ai.models.generateContent({ model: modelId, contents: prompt, config: { temperature: 0.7, maxOutputTokens: 8192 }, }); return { model: modelId, text: response.text ?? "" }; } catch (err: any) { const msg = err?.message ?? String(err); // 503 — backoff and retry if (msg.includes("503") || msg.includes("UNAVAILABLE")) { const delay = initialDelay * 2 ** attempt + Math.random() * 1000; console.log(`503 on ${modelId}, retry ${attempt + 1}/${maxRetries} in ${(delay / 1000).toFixed(1)}s`); await new Promise((r) => setTimeout(r, delay)); continue; } // 504 — skip to next model if (msg.includes("504") || msg.includes("DEADLINE")) { console.log(`504 on ${modelId}, switching model`); break; } // Network timeout — one retry then move on if (/timeout|ETIMEDOUT|ECONNRESET/i.test(msg)) { if (attempt === 0) { await new Promise((r) => setTimeout(r, 2000)); continue; } break; } throw err; // Unknown error } } } throw new Error("All models in fallback chain failed"); } // Usage const result = await callWithRetry("Explain quantum entanglement in detail"); console.log(`Model: ${result.model}\n${result.text}`);
cURL — быстрый тест таймаута
Для быстрой диагностики используйте cURL с явными флагами connect-timeout и max-time, чтобы определить, является ли проблема таймаута серверной или клиентской. Если эта команда cURL выполняется успешно, а ваше приложение — нет, проблема в настройке таймаута вашего приложения.
bash# Test with 120-second timeout curl -X POST \ "https://generativelanguage.googleapis.com/v1beta/models/gemini-3.1-pro-preview:generateContent?key=YOUR_API_KEY" \ -H "Content-Type: application/json" \ --connect-timeout 30 \ --max-time 120 \ -d '{ "contents": [{"parts": [{"text": "Say hello"}]}] }'
Ключевой принцип, общий для всех реализаций, остаётся неизменным: установите таймаут не менее 120 секунд, реализуйте дифференцированную логику повторных запросов, которая по-разному обрабатывает разные ошибки, и поддерживайте цепочку моделей для переключения, чтобы ваше приложение никогда полностью не отказало при недоступности Gemini 3.1 Pro.
Устранение неполадок по платформам
Ошибки таймаута Gemini 3.1 Pro проявляются по-разному в зависимости от платформы доступа к модели, и для каждой платформы существуют свои специфические решения. В подразделах ниже рассмотрены пять наиболее распространённых платформ, на которых разработчики сообщают о проблемах с таймаутами, с целевыми решениями для каждой. Если вашей платформы нет в списке, общие решения для API из раздела с кодом выше применимы универсально.
Google AI Studio (веб-интерфейс)
Наиболее серьёзная проблема таймаута затрагивает непосредственно Google AI Studio. Многие разработчики сообщают о запросах, которые выполняются от 15 000 до 20 000+ секунд — это более 4 часов — без какого-либо вывода или возврата ошибки. Это подтверждённый баг Preview-версии, а не проблема конфигурации. Интерфейс AI Studio показывает «Running...» со счётчиком, который растёт бесконечно. Единственное решение — вручную отменить запрос и либо повторить попытку (что иногда срабатывает, если состояние сервера изменилось), либо переключиться на другую модель в AI Studio. Google подтвердил эту проблему на форумах разработчиков и работает над исправлением. Если вы сталкиваетесь с этим постоянно, переход на конечную точку Vertex AI обеспечивает значительно лучшую надёжность и более быстрый TTFT (21,54 с против 31,36 с согласно бенчмаркам Artificial Analysis, верифицированным в феврале 2026).
Cursor IDE
Пользователи Cursor сообщают о двух различных паттернах таймаута с Gemini 3.1 Pro. Первый — "Unable to reach the model provider", который обычно появляется через 30–60 секунд и указывает на то, что внутренний HTTP-таймаут Cursor истёк до ответа Gemini. Второй — "Taking longer than expected" в задачах агентного режима, когда модель входит в цикл размышлений, никогда не производя вызовы инструментов. Для первой проблемы таймаут Cursor настраивается для каждой модели в настройках — перейдите в Settings > Models и увеличьте таймаут для Gemini 3.1 Pro до 120 секунд или более. Для бесконечного цикла размышлений текущее обходное решение — отменить шаг агента и разбить задачу на более мелкие, конкретные инструкции, не требующие длительных цепочек рассуждений. Некоторые пользователи Cursor сообщают о лучших результатах при добавлении явных инструкций вроде «respond directly, do not over-analyze» для сокращения времени «размышления».
Android Studio (Gemini в IDE)
Встроенный ассистент Gemini в Android Studio, как сообщается, входит в бесконечные циклы «размышлений» с Gemini 3.1 Pro, когда индикатор загрузки крутится 3–5 минут на задачах, которые должны завершаться за секунды. Это, по-видимому, связано с тем же базовым багом, что и зависание в AI Studio. Интеграция Android Studio в настоящее время не предоставляет возможности настройки таймаута. Рекомендуемое обходное решение — переключиться на Gemini 3 Flash или Gemini 2.5 Pro для задач в Android Studio, поскольку эти GA-модели имеют значительно более быстрый TTFT и не демонстрируют поведение зависания. Модель можно изменить в Android Studio в разделе Settings > Gemini > Model selection.
Прямой API (REST/gRPC)
При прямой интеграции через REST или gRPC таймаут полностью под вашим контролем. Самая распространённая ошибка — вообще не устанавливать таймаут, из-за чего применяется системный таймаут по умолчанию (часто 30 секунд). Для REST API-вызовов установите таймаут HTTP-клиента не менее 120 секунд. Для gRPC-вызовов через клиент Vertex AI настройте параметр timeout в опциях вызова. Примеры кода в предыдущем разделе охватывают оба подхода. Также убедитесь, что любые промежуточные прокси, балансировщики нагрузки или API-шлюзы в вашей инфраструктуре имеют таймауты не менее 180 секунд, чтобы учесть собственные накладные расходы прокси на обработку.
Gemini CLI
Инструмент командной строки Gemini CLI уже имеет встроенную обработку таймаутов Gemini 3.1 Pro, включая автоматическое переключение на Gemini 2.5 Pro при недоступности основной модели и экспоненциальную задержку для ошибок 503. Если вы по-прежнему испытываете таймауты с CLI, обновитесь до последней версии с помощью npm update -g @anthropic-ai/claude-code или соответствующего последнего пакета CLI. Таймаут по умолчанию в CLI уже настроен для длительных вызовов моделей. Если вы создаёте собственную CLI-обёртку, обратитесь к исходному коду Gemini CLI для изучения их паттернов повторных запросов и переключения.
Когда переключаться: фреймворк принятия решений + альтернативные модели
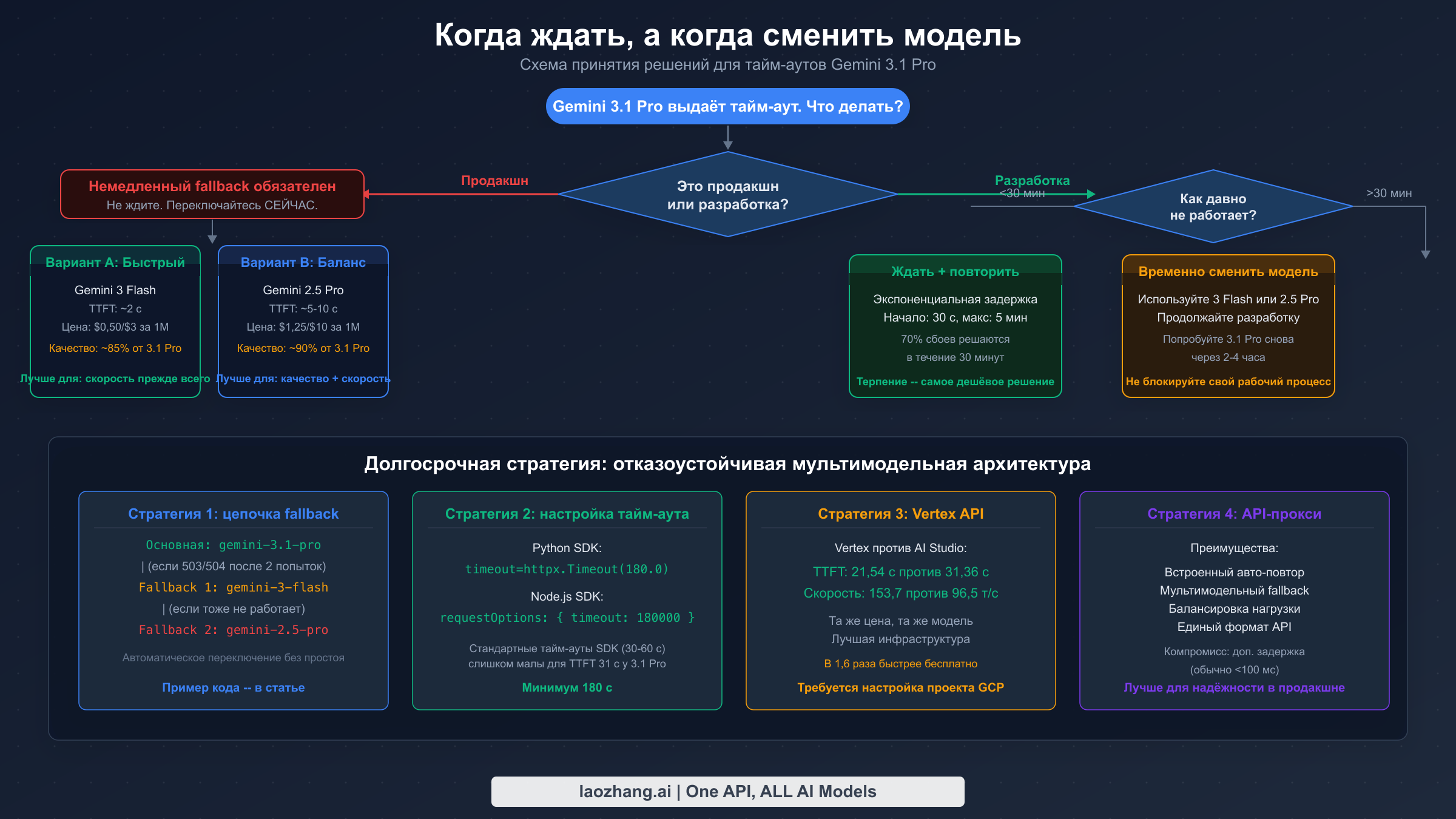
Понимание того, когда прекратить диагностику и переключиться на другую модель, — это стратегическое решение, зависящее от вашего конкретного контекста: насколько срочно вам нужны результаты, находитесь ли вы в разработке или продакшене, и какой уровень интеллекта действительно необходим для данной задачи. Приведённый ниже фреймворк принятия решений предлагает конкретные критерии для быстрого принятия этого решения, в отличие от размытых советов «попробуйте позже», которые доминируют на форумах.
Для продакшен-сред решение бинарное: если Gemini 3.1 Pro возвращает ошибки 503 более 30 минут или ваш запрос зависает более 2 минут — немедленно переключайтесь на резервную модель. Продакшен-системы не могут позволить себе многочасовые простои в ожидании восстановления Preview-модели. Переключение уже должно быть настроено в вашем коде (см. цепочку моделей в разделе с кодом выше), и оно должно происходить автоматически. Для разработки и тестирования у вас больше гибкости — подождать 15–30 минут во время волны 503-х, а затем повторить попытку — вполне разумный подход, поскольку колебания ёмкости Preview-моделей носят временный характер.
В таблице ниже показаны наиболее практичные альтернативы на случай, когда Gemini 3.1 Pro не отвечает, а также их сравнение по ключевым метрикам — интеллект, скорость и стоимость. Все данные о ценах взяты с официальной страницы тарификации Google и независимых бенчмарков, верифицированных 25 февраля 2026 года. Полный анализ тарификации можно найти в нашем полном руководстве по ценам Gemini API.
| Модель | Интеллект | TTFT | Скорость вывода | Стоимость ввода | Стоимость вывода | Лучше всего для |
|---|---|---|---|---|---|---|
| Gemini 3.1 Pro | №1/114 | 21–31 с | 97–154 т/с | $2,00/1M | $12,00/1M | Задачи максимального интеллекта |
| Gemini 3 Flash | Хороший | ~1 с | 200+ т/с | $0,50/1M | $2,00/1M | Быстрый резерв, большинство задач |
| Gemini 2.5 Pro | Высокий | ~3 с | 80 т/с | $1,25/1M | $10,00/1M | Надёжная GA-альтернатива |
| Gemini 2.5 Flash | Умеренный | <1 с | 300+ т/с | $0,30/1M | $1,50/1M | Экономичные рабочие нагрузки |
| Claude Opus 4.6 | Очень высокий | ~3 с | 60+ т/с | $15,00/1M | $75,00/1M | Сложные рассуждения, надёжность |
Для более детального сравнения между двумя лидирующими моделями рассуждений ознакомьтесь с нашим сравнением Gemini 3.1 Pro и Claude Opus 4.6. Хотя Gemini 3.1 Pro лидирует по «сырым» показателям интеллекта в бенчмарках, Claude Opus 4.6 предлагает значительно более стабильное время ответа и более высокую доступность, что делает его сильным выбором, когда надёжность важнее бенчмарков.
Для продакшен-сред, требующих стабильной надёжности работы с несколькими AI-моделями, прокси-сервисы API, такие как laozhang.ai, могут упростить процесс переключения, предоставляя единую конечную точку API, которая обрабатывает маршрутизацию моделей, автоматические повторные запросы и переключение между провайдерами. Такой подход особенно ценен, когда вашему приложению нужно переключаться между моделями Google и других провайдеров, поскольку прямая интеграция с несколькими провайдерами значительно усложняет кодовую базу. Платформа laozhang.ai поддерживает всех основных провайдеров моделей с унифицированным форматом API и встроенной логикой повторных запросов, что избавляет от необходимости реализовывать цепочки переключения, показанные в примерах кода выше.
Станет ли лучше? Перспективы перехода из Preview в GA
Вопрос, на который хочет получить ответ каждый разработчик, работающий с Gemini 3.1 Pro: являются ли эти проблемы с таймаутами постоянными или временными, и когда — а не «если» — Google их устранит. Основываясь на историческом паттерне Google с предыдущими релизами Gemini и публичных заявлениях, есть веские основания ожидать значительного улучшения, хотя сроки неопределённы.
История переходов Google из Preview в GA предоставляет наиболее полезные прогнозные данные. Gemini 2.5 Pro прошёл аналогичный путь: первоначальный Preview-релиз с ограниченной ёмкостью и частыми ошибками 503, за которым примерно через 2–3 месяца последовал GA-релиз, который кардинально увеличил выделение серверов и стабильность. Gemini 2.5 Flash прошёл ещё более быстрый цикл. Этот паттерн предполагает, что Google использует периоды Preview для валидации архитектуры модели, намеренно ограничивая ёмкость, а затем масштабирует инфраструктуру к GA-запуску. Если Gemini 3.1 Pro последует этому паттерну, GA-релиз в апреле или мае 2026 года будет соответствовать историческим срокам, и вместе с ним можно ожидать значительного снижения частоты ошибок 503 и ускорения TTFT.
Однако TTFT вряд ли сократится кардинально даже после выхода GA. Время «размышления» в 21–31 секунду — это архитектурная характеристика подхода модели к рассуждению, а не проблема ёмкости серверов. Google может оптимизировать инференс и несколько сократить его — возможно, до 10–15 секунд — но Gemini 3.1 Pro, вероятно, всегда будет одной из самых медленных моделей в генерации первого токена, потому что именно в этом источник его интеллектуального преимущества. Скорость генерации вывода, которая уже выше отраслевого среднего, должна оставаться отличной.
Баг зависания — когда запросы выполняются бесконечно без возврата — почти наверняка является программным дефектом, который будет исправлен до или при выходе GA. Именно для обнаружения подобных проблем и существуют периоды Preview. Баг 99-часовой блокировки аналогично относится к категории дефектов, которые Google активно устраняет на основе отчётов с форумов разработчиков. На данный момент практическая стратегия — использовать Gemini 3.1 Pro для задач, которые действительно требуют его интеллекта №1 в рейтинге, сохраняя резервные модели для срочных задач, и проектировать архитектуру с расчётом на GA-релиз, который принесёт лучшую надёжность, но аналогичные характеристики задержки.
Часто задаваемые вопросы
Почему Gemini 3.1 Pro отвечает более 30 секунд, тогда как другие модели — за 1–2 секунды?
Время до первого токена в 21–31 секунду у Gemini 3.1 Pro — это особенность конструкции, а не баг. Модель заняла первое место в рейтинге интеллекта AI Index (57 баллов, Artificial Analysis, февраль 2026) и достигла 77,1% на ARC-AGI-2 именно потому, что инвестирует больше вычислительных ресурсов в рассуждение перед генерацией вывода. Представьте, что модель глубже обдумывает ответ, прежде чем начать говорить. Отраслевая медиана TTFT в 1,19 секунды обеспечивается моделями, которые приоритизируют скорость над глубиной рассуждений. После начала генерации токенов Gemini 3.1 Pro работает со скоростью 96,5–153,7 токенов в секунду, что быстрее отраслевой медианы в 71 токен в секунду. Узкое место находится исключительно в начальной фазе «размышления».
Влияет ли баг 99-часовой блокировки на ошибки таймаута?
Баг 99-часовой блокировки — это отдельная проблема, хотя обе затрагивают пользователей Gemini 3.1 Pro. Блокировка происходит, когда квота вашего API-ключа исчерпана (или ошибочно помечена как исчерпанная) и система назначает 99-часовой период восстановления. Во время блокировки вы получаете ошибки 429 RESOURCE_EXHAUSTED, а не 503 или 504. Если вы подозреваете блокировку, проверьте использование квоты в Google Cloud Console. Этот баг широко обсуждается на форуме Google AI Developer Forum, и Google работает над его исправлением.
Взимается ли плата за API-запросы, завершившиеся таймаутом?
Согласно модели тарификации Google, плата взимается на основе токенов, обработанных моделью. При ошибках 503, когда сервер немедленно отклоняет запрос, токены не обрабатываются и плата не должна взиматься. При ошибках 504, когда модель начала обработку, но не завершила её, политика Google предусматривает оплату за входные токены, но не за выходные, поскольку вывод не был успешно сгенерирован. Для бага зависания, когда ответ не возвращается вовсе, ситуация с тарификацией неоднозначна — некоторые разработчики сообщали об использовании токенов в консоли для запросов, которые так и не завершились. Внимательно отслеживайте панель управления использованием API во время инцидентов с таймаутами.
Значительно ли лучше Vertex AI по сравнению с AI Studio для Gemini 3.1 Pro?
Да, согласно текущим бенчмаркам. Vertex AI обеспечивает TTFT в 21,54 секунды против 31,36 секунды у AI Studio — примерно в 1,5 раза быстрее (Artificial Analysis, февраль 2026). Скорость вывода на Vertex также значительно выше: 153,7 токенов в секунду против 96,5 токенов в секунду в AI Studio. Vertex AI также, по-видимому, менее подвержен багу зависания. Компромисс заключается в том, что Vertex AI требует проекта Google Cloud с включённой тарификацией и несколько более сложной настройки аутентификации, тогда как AI Studio работает с простым API-ключом.
Можно ли использовать Gemini 3.1 Pro через сторонних API-провайдеров для избежания таймаутов?
Да, несколько сторонних API-провайдеров предоставляют доступ к Gemini 3.1 Pro с собственной логикой повторных запросов, обработкой таймаутов и конфигурациями переключения моделей. Эти провайдеры обычно маршрутизируют через Vertex AI (более быструю конечную точку) и добавляют собственный слой повторных запросов, что может повысить надёжность по сравнению с прямым доступом к API. Однако они добавляют слой задержки и стоимости. Оцените, оправдывает ли повышение надёжности дополнительные накладные расходы для вашего конкретного сценария использования.