Столкнулись с ошибкой 429 RESOURCE_EXHAUSTED при генерации изображений через Gemini 3.1 Flash? Ошибка 429 в Gemini 3.1 Flash Image означает, что вы превысили один из четырёх лимитов: RPM (запросы в минуту), RPD (запросы в день), TPM (токены в минуту) или IPM (изображения в минуту). Исправить это можно немедленно: реализовать экспоненциальную задержку с рандомизацией, повысить тарифный уровень для увеличения лимитов до 6 раз, использовать Batch API с экономией 50% и отдельными квотами, распределить запросы между несколькими проектами или направить трафик через API-прокси для неограниченной пропускной способности. В этом руководстве вы узнаете, как точно определить, какой лимит сработал, и выбрать оптимальное решение для вашей ситуации.
Что такое ошибка 429 в Gemini 3.1 Flash Image

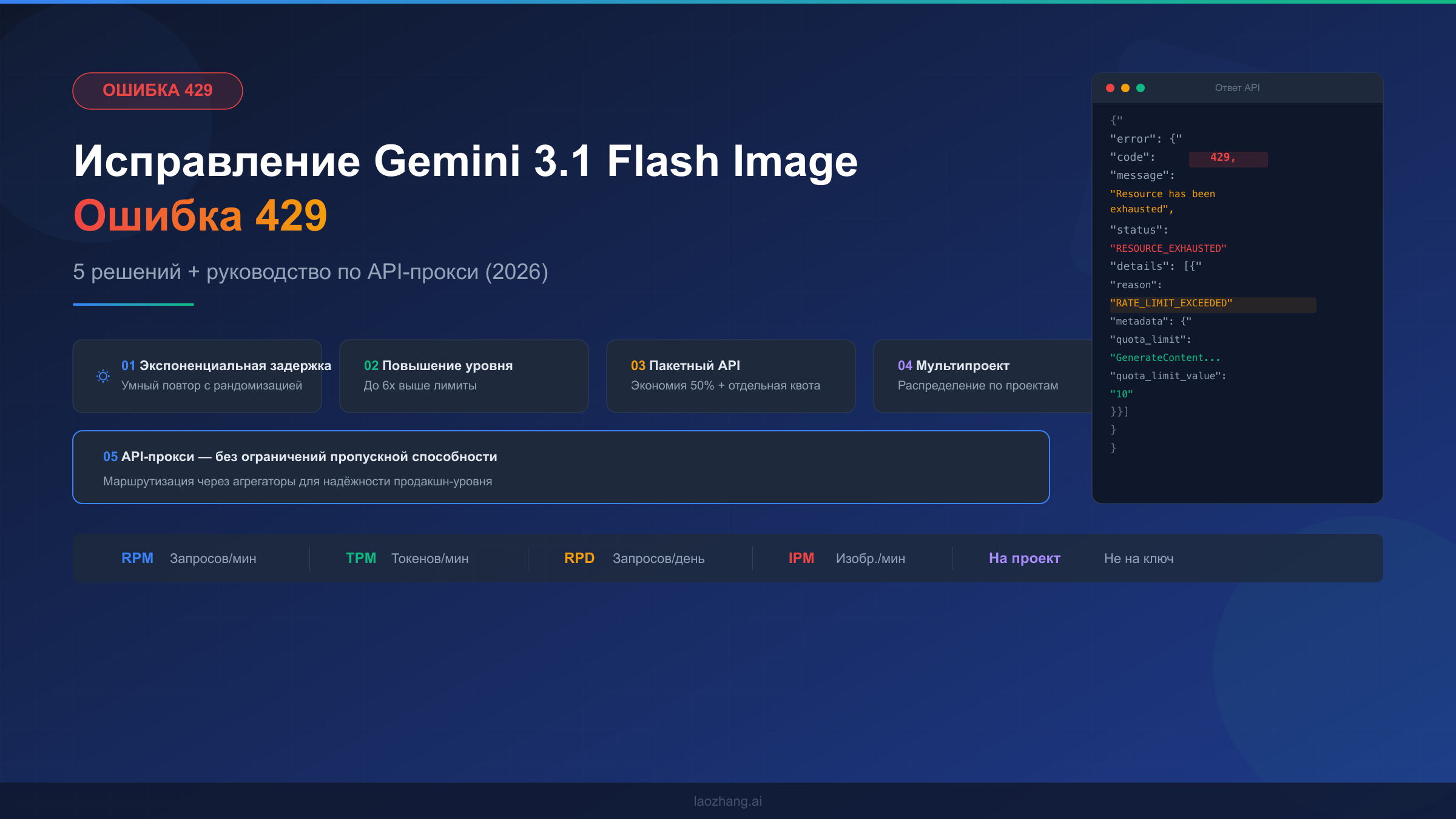
Когда ваш вызов API Gemini 3.1 Flash Image возвращает код статуса 429, тело ответа содержит критическую диагностическую информацию, которую большинство разработчиков упускают из виду. Прежде чем переходить к решениям, важно понять структуру ошибки — это поможет точно определить узкое место, а не применять общие исправления, которые могут не устранить вашу конкретную проблему. Код 429 — это способ Google сообщить, что ваш проект исчерпал выделенную квоту по определённому измерению, и в ответе фактически указано, по какому именно, если знать, куда смотреть.
Вот как выглядит реальный ответ при достижении лимита для модели Gemini 3.1 Flash Image Preview:
json{ "error": { "code": 429, "message": "Resource has been exhausted (e.g. check quota).", "status": "RESOURCE_EXHAUSTED", "details": [ { "@type": "type.googleapis.com/google.rpc.ErrorInfo", "reason": "RATE_LIMIT_EXCEEDED", "metadata": { "quota_limit": "GenerateContentRequestsPerMinutePerProjectPerRegion", "quota_limit_value": "10", "consumer": "projects/your-project-id", "quota_metric": "generativelanguage.googleapis.com/generate_content_requests" } } ] } }
Поле metadata.quota_limit — ключ к диагностике вашей проблемы. Оно точно указывает, какое из четырёх измерений лимитов вы исчерпали. Gemini API от Google применяет ограничения по четырём независимым измерениям — это означает, что вы можете быть далеко в пределах квоты RPM, но при этом превысить дневной лимит RPD. Понимание этих четырёх измерений критически важно, потому что исправление для нарушения RPM принципиально отличается от исправления для нарушения RPD.
Четыре измерения лимитов для Gemini 3.1 Flash Image Preview работают следующим образом. RPM (запросы в минуту) подсчитывает количество вызовов API за скользящее 60-секундное окно — это наиболее частый лимит, с которым сталкиваются разработчики при пиковых нагрузках. TPM (токены в минуту) отслеживает общее количество входных токенов за то же скользящее окно, что важно для генерации изображений, поскольку промпты с подробными описаниями потребляют значительно больше токенов, чем простые текстовые запросы. RPD (запросы в день) устанавливает жёсткий дневной лимит, который сбрасывается в полночь по тихоокеанскому времени — он особенно строг на бесплатном уровне, где Google сократил квоты на 92% в декабре 2025 года. Наконец, IPM (изображения в минуту) — измерение, уникальное для моделей генерации изображений вроде Gemini 3.1 Flash Image Preview, и это часто скрытое узкое место, которое разработчики не замечают, привыкнув думать только о RPM и TPM по опыту работы с текстовыми моделями.
Один критический факт, о котором многие разработчики не подозревают: лимиты в Gemini API применяются на уровне проекта, а не на уровне API-ключа. Это означает, что создание нескольких API-ключей в одном проекте Google Cloud не даёт абсолютно никаких преимуществ для обхода лимитов. Если у вас три ключа в одном проекте, все три используют один и тот же пул квот. Это различие становится важным, когда мы обсуждаем стратегию распределения по нескольким проектам в Решении 4.
Стоит также отметить разницу между ошибкой 429 и ошибкой 503, поскольку обе могут прервать ваш конвейер генерации изображений. Ошибка 429 означает, что вы исчерпали выделенную квоту и вам нужно либо подождать, либо увеличить лимиты. Ошибка 503 (Service Unavailable) указывает на временную проблему на стороне сервера Google — в этом случае обычно достаточно простого повтора запроса через короткий промежуток. Стратегии исправления существенно различаются, поэтому важно проверить код статуса перед применением решения.
Быстрая диагностика — какой лимит вы превысили?
Прежде чем применять какое-либо решение, необходимо точно определить, какое измерение лимита исчерпано. Если вы слепо реализуете экспоненциальную задержку, когда на самом деле достигли дневного лимита RPD, ваши повторные попытки будут безуспешны в течение часов до полуночи по тихоокеанскому времени. Такой диагностический подход сэкономит время на неправильном решении, и для определения первопричины потребуется менее минуты.
Начните с изучения поля quota_limit в ответе об ошибке. Значение напрямую соответствует одному из четырёх измерений, и у каждого есть свой строковый идентификатор. Когда вы видите GenerateContentRequestsPerMinutePerProjectPerRegion, вы достигли лимита RPM — обычно он восстанавливается за 60 секунд, если просто сделать паузу. Если поле показывает GenerateContentTokensPerMinutePerProjectPerRegion, ваш TPM исчерпан, то есть промпты потребляют слишком много токенов слишком быстро. Значение GenerateContentRequestsPerDayPerProjectPerRegion указывает на нарушение RPD — самое неприятное, потому что сброс произойдёт только в полночь по тихоокеанскому времени. А если вы встречаете GenerateContentImagesPerMinutePerProjectPerRegion, вы достигли лимита IPM для вывода изображений — ограничения, которое действует только для моделей генерации изображений.
Если ответ об ошибке не содержит подробный объект metadata (что случается с некоторыми старыми версиями SDK), можно использовать метод исключения. Проверьте частоту запросов за последние 60 секунд — если вы отправляли запросы пакетами, вероятно, дело в RPM или IPM. Если вы выполняли пакетное задание в течение дня, сверьте общее количество дневных запросов с лимитом RPD вашего уровня. Текущий уровень и связанные с ним лимиты можно проверить на странице квот Google AI Studio, где отображается использование в реальном времени и оставшаяся ёмкость по каждому измерению.
Следующий алгоритм принятия решений поможет быстро определить проблему и перейти к наиболее подходящему решению:
- Ошибка появилась при быстрой серии вызовов API (в течение секунд)? Вероятно, RPM или IPM. Примените Решение 1 (экспоненциальная задержка) для немедленного облегчения, затем рассмотрите Решение 2 (повышение уровня) для постоянного исправления.
- Ошибка появилась после продолжительного использования в течение дня? Вероятно, RPD. Подождите до полуночи по тихоокеанскому времени или примените Решение 2 (повышение уровня) для увеличения дневной квоты.
- Ошибка появилась при очень длинных или детальных промптах? Вероятно, TPM. Упростите промпты или примените Решение 1 для распределения запросов во времени.
- Вы на бесплатном уровне и быстро достигли лимита? Скорее всего, RPD (лимит RPD бесплатного уровня был сокращён на 92% в декабре 2025). Решение 2 (включение биллинга для Tier 1) — самый быстрый путь к постоянному исправлению.
Вы также можете проверить свой текущий уровень программно, просмотрев статус биллинга Google Cloud. Пользователи бесплатного уровня имеют самые строгие ограничения по всем четырём измерениям. Переход на Tier 1 требует лишь подключения платёжного аккаунта к проекту — повышение лимитов обычно вступает в силу в течение нескольких минут. Для подробной разбивки лимитов по уровням ознакомьтесь с нашим специальным руководством, в котором указаны точные квоты для каждого варианта модели.
Существует ещё один диагностический приём, полезный для разработчиков, которые хотят проактивно отслеживать потребление квот, а не реагировать постфактум. Google Cloud Console предоставляет страницу «Квоты и системные лимиты», где можно просматривать графики использования по каждому измерению в реальном времени. Перейдите в раздел IAM и администрирование вашего проекта, затем выберите «Квоты». Отфильтруйте по «generativelanguage.googleapis.com», чтобы увидеть все квоты Gemini API. Эти графики показывают закономерности использования во времени, что позволяет определить, постоянно ли вы упираетесь в конкретный лимит или это лишь периодические пики. Также можно настроить оповещения о квотах — уведомления при достижении 50%, 80% и 90% использования, что даёт раннее предупреждение до того, как приложение начнёт получать ошибки 429. Такой проактивный мониторинг особенно ценен для продакшн-систем, где ошибки лимитов напрямую влияют на пользовательский опыт.
Решение 1 — Экспоненциальная задержка с интеллектуальным повтором
Экспоненциальная задержка (exponential backoff) — первая линия защиты от ошибок 429, и она должна быть реализована в каждом продакшн-приложении, вызывающем Gemini API, независимо от других применяемых решений. Концепция проста: при получении ответа 429 следует подождать увеличивающееся время перед повторной попыткой. Однако наивная реализация, которая просто удваивает время ожидания, может создать проблему «стада» (thundering herd), когда несколько экземпляров повторяют запросы одновременно. Добавление случайной рандомизации (jitter) к интервалам задержки более равномерно распределяет попытки повтора и значительно снижает вероятность повторных столкновений на границе лимита.
Реализация на Python
Реализация на Python ниже использует SDK google-generativeai с пользовательской обёрткой повтора, которая интеллектуально обрабатывает различные типы лимитов. Для лимитов RPM используются более короткие начальные задержки, поскольку окно сбрасывается каждые 60 секунд. Для лимитов RPD стратегия переключается на значительно более длинные задержки или выбрасывает исключение, сигнализируя, что повтор бесполезен до дневного сброса.
pythonimport time import random import google.generativeai as genai genai.configure(api_key="YOUR_API_KEY") def generate_image_with_retry(prompt, max_retries=5, base_delay=1.0): """Generate image with exponential backoff and jitter.""" model = genai.GenerativeModel("gemini-3.1-flash-image-preview") for attempt in range(max_retries): try: response = model.generate_content( prompt, generation_config={"response_mime_type": "image/png"} ) return response except Exception as e: error_str = str(e) if "429" not in error_str and "RESOURCE_EXHAUSTED" not in error_str: raise # Non-rate-limit error, don't retry if "PerDay" in error_str: print("Daily limit reached. Retrying won't help until midnight PT.") raise # Exponential backoff with full jitter delay = base_delay * (2 ** attempt) + random.uniform(0, 1) delay = min(delay, 60) # Cap at 60 seconds print(f"Rate limited. Retry {attempt + 1}/{max_retries} in {delay:.1f}s") time.sleep(delay) raise Exception("Max retries exceeded")
Реализация на Node.js
Для приложений на Node.js реализация следует тому же шаблону, но использует синтаксис async/await и пакет @google/generative-ai. Расчёт рандомизации использует Math.random() для добавления случайности к интервалу задержки, предотвращая синхронизированные повторы на нескольких серверных экземплярах.
javascriptconst { GoogleGenerativeAI } = require("@google/generative-ai"); const genAI = new GoogleGenerativeAI("YOUR_API_KEY"); async function generateImageWithRetry(prompt, maxRetries = 5, baseDelay = 1000) { const model = genAI.getGenerativeModel({ model: "gemini-3.1-flash-image-preview" }); for (let attempt = 0; attempt < maxRetries; attempt++) { try { const result = await model.generateContent({ contents: [{ parts: [{ text: prompt }] }], generationConfig: { responseMimeType: "image/png" } }); return result; } catch (error) { const msg = error.message || ""; if (!msg.includes("429") && !msg.includes("RESOURCE_EXHAUSTED")) throw error; if (msg.includes("PerDay")) { throw new Error("Daily limit reached. Wait until midnight PT."); } const delay = Math.min(baseDelay * Math.pow(2, attempt) + Math.random() * 1000, 60000); console.log(`Rate limited. Retry ${attempt + 1}/${maxRetries} in ${(delay/1000).toFixed(1)}s`); await new Promise(resolve => setTimeout(resolve, delay)); } } throw new Error("Max retries exceeded"); }
Есть несколько нюансов, которые делают экспоненциальную задержку эффективной в продакшене. Во-первых, всегда устанавливайте максимальный предел задержки (60 секунд — разумный вариант для лимитов RPM), чтобы избежать чрезмерно долгого ожидания при устойчивом ограничении. Во-вторых, рассмотрите реализацию паттерна «автоматического выключателя» (circuit breaker) поверх логики повтора: если вы получили пять последовательных ошибок 429, временно прекратите все запросы на период охлаждения, а не продолжайте нагружать API. Это не только более уважительно к инфраструктуре Google, но и позволяет квоте быстрее восстановиться. В-третьих, логируйте каждое появление 429 с полными деталями ошибки, включая поле quota_limit — эти данные бесценны для понимания закономерностей использования и принятия решения о повышении уровня или переходе к более масштабируемому решению.
Хотя экспоненциальная задержка необходима, важно понимать её ограничения. Она хорошо справляется с временными пиками RPM, но не может решить структурные проблемы — например, стабильное превышение дневного лимита или потребность в устойчивой пропускной способности выше выделенной квоты. Думайте о ней как о страховочной сетке, а не о стратегии масштабирования. Если более 10-15% ваших запросов опираются на повторные попытки, пора обратить внимание на более фундаментальные решения, описанные далее.
Решение 2 — Повышение тарифного уровня API
Повышение тарифного уровня Google Cloud — самый прямой способ навсегда увеличить лимиты по всем четырём измерениям. Система уровней Google разработана для последовательного повышения квот по мере демонстрации легитимного использования через пороги расходов и возраст аккаунта. Для многих разработчиков простое включение биллинга (переход с бесплатного на Tier 1) обеспечивает немедленное и существенное увеличение доступной ёмкости, часто устраняя ошибки 429 без каких-либо изменений в коде.
Система уровней работает следующим образом (проверено по документации Google AI for Developers, 2026-03-09): бесплатный уровень доступен пользователям в подходящих странах и регионах, с наиболее строгими ограничениями, которые были ещё более ужесточены в декабре 2025 года. Tier 1 требует подключения платёжного аккаунта к проекту Google Cloud, и переход обычно вступает в силу в течение нескольких минут. Tier 2 требует общих расходов более $250 и не менее 30 дней с первого платежа. Tier 3 требует расходов свыше $1000 с тем же 30-дневным минимумом. Каждый уровень существенно увеличивает лимиты RPM, TPM, RPD и IPM — только Tier 1 часто обеспечивает увеличение в 3-6 раз по сравнению с бесплатным уровнем.
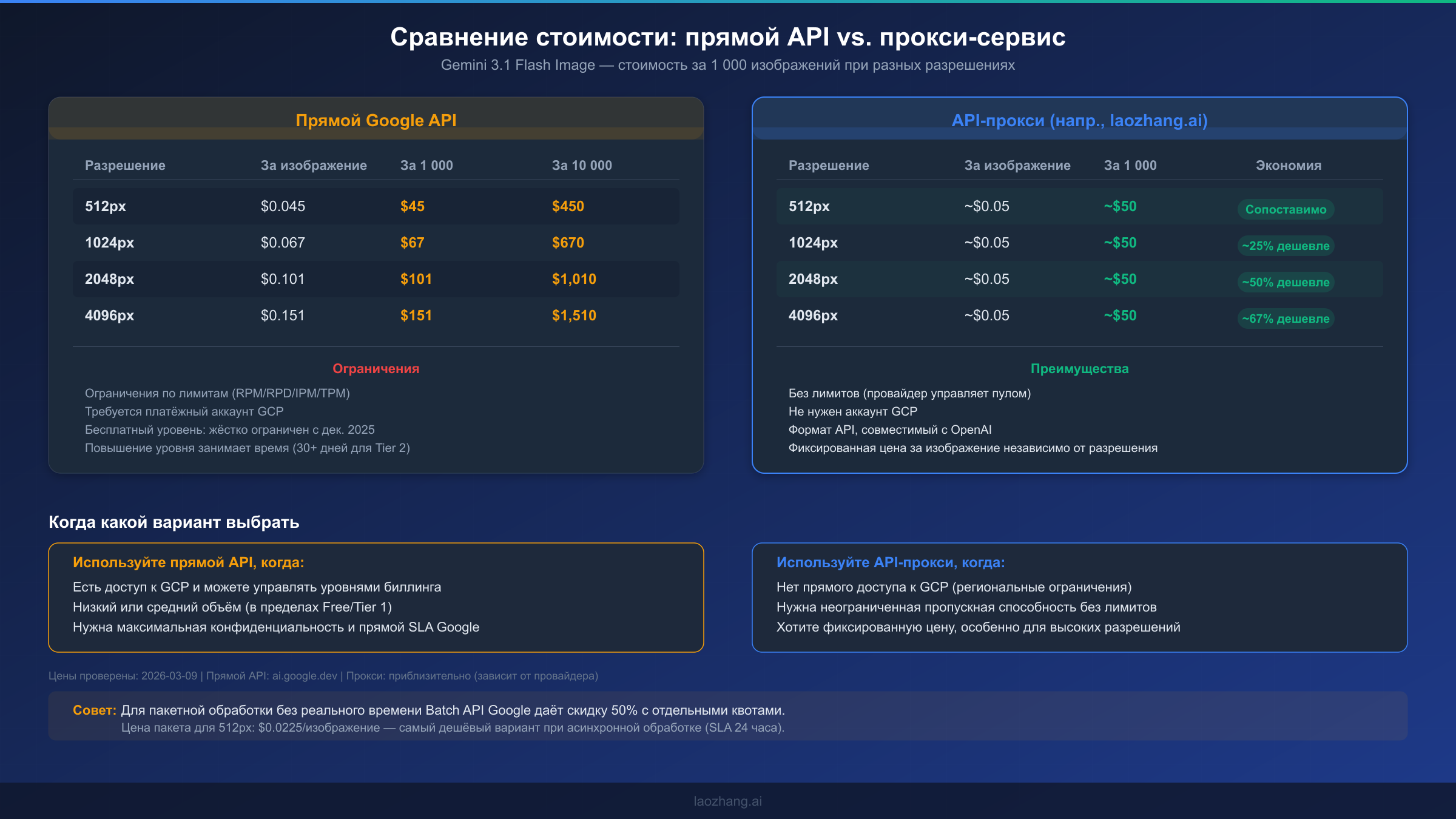
Вопрос стоимости при повышении уровня сильно зависит от паттерна использования. Если вы генерируете менее сотни изображений в день, бесплатного уровня может технически хватить вне пиковых периодов, но вы постоянно будете бороться с лимитами RPD. Включение биллинга не означает немедленных расходов — вы платите только за использование сверх бесплатной квоты. Ценообразование генерации изображений Gemini зависит от разрешения: $0,045 за изображение при 512px, $0,067 при 1024px, $0,101 при 2048px и $0,151 при 4096px (Google AI for Developers, проверено 2026-03-09). Для продакшн-приложения, генерирующего 500 изображений в день при разрешении 1024px, дневная стоимость составит около $33,50 — разумная инвестиция с учётом повышения надёжности.
Для повышения уровня перейдите в Google AI Studio или Google Cloud Console и включите биллинг для проекта. Процесс прост: создайте платёжный аккаунт, если его нет, привяжите к API-проекту, и повышение уровня распространится примерно через 10 минут. Для достижения Tier 2 и выше основное требование — накопительные расходы, которые происходят естественным образом при использовании API. Нет отдельного процесса подачи заявки или одобрения — только стабильное использование, которое пересекает пороги расходов.
Одно важное замечание по планированию: 30-дневный период ожидания для Tier 2 и Tier 3 означает, что ускорить процесс повышения невозможно. Если вы предвидите потребность в более высоких лимитах в ближайшем будущем, лучшая стратегия — включить биллинг заранее (даже при минимальном текущем использовании), чтобы запустить отсчёт времени. Тогда, когда ваше приложение масштабируется и потребуются лимиты Tier 2, временное требование уже будет выполнено.
Вот практический анализ соотношения стоимости и выгоды для различных сценариев использования. При генерации около 100 изображений в день при разрешении 1024px дневная стоимость на Tier 1 составит около $6,70, или примерно $200 в месяц. При 1000 изображениях в день — типичном пороге для продакшн SaaS-приложений — расходы составят около $67 в день или $2000 в месяц, что уверенно выведет вас на путь к соответствию Tier 2 в течение первого месяца. Для высоконагруженных операций с 10 000+ изображений в день затраты достигают $670 в день при разрешении 1024px, но при таком масштабе настоятельно рекомендуется рассмотреть Batch API (Решение 3) или API-прокси (Решение 5) для значительного снижения расходов. Ключевой вывод: стоимость за изображение остаётся постоянной на всех уровнях — меняется только потолок пропускной способности, а не цена генерации.
Решение 3 — Batch API для массовой генерации изображений
Batch API — это официально рекомендованный Google подход для массовой генерации изображений, при этом он остаётся удивительно малоиспользуемым, поскольку большинство конкурирующих руководств либо полностью его пропускают, либо упоминают вскользь. Batch API предоставляет два критических преимущества: он работает на полностью отдельной системе квот от API реального времени (то есть пакетные запросы не учитываются в ваших лимитах RPM/RPD/IPM), и он предлагает скидку 50% на все затраты генерации. Компромисс в том, что пакетные запросы обрабатываются асинхронно с SLA в 24 часа, поэтому это решение идеально подходит для рабочих процессов, где изображения не нужны мгновенно.
Квота Batch API измеряется в поставленных в очередь токенах, а не в запросах в минуту, и лимиты щедрые даже на нижних уровнях. Проекты Tier 1 могут ставить в очередь до 1 000 000 токенов пакетных запросов, Tier 2 открывает 250 000 000 токенов, а Tier 3 предоставляет 750 000 000 (страница лимитов Google AI for Developers, проверено 2026-03-09). Для контекста: типичный промпт для генерации изображения из 50-100 слов использует примерно 70-130 токенов, а значит, пакетная очередь Tier 1 может вместить приблизительно 7 700-14 300 запросов на генерацию изображений одновременно.
Реализация Batch API на Python
Вот полный рабочий пример, который создаёт пакетное задание, опрашивает статус выполнения и получает сгенерированные изображения:
pythonimport google.generativeai as genai import time genai.configure(api_key="YOUR_API_KEY") batch_requests = [] prompts = [ "A serene mountain landscape at sunset, photorealistic", "A futuristic city skyline with flying vehicles", "An underwater coral reef teeming with colorful fish" ] for i, prompt in enumerate(prompts): batch_requests.append({ "custom_id": f"img-{i}", "method": "POST", "url": "/v1beta/models/gemini-3.1-flash-image-preview:generateContent", "body": { "contents": [{"parts": [{"text": prompt}]}], "generationConfig": {"responseMimeType": "image/png"} } }) # Step 2: Submit batch job # Note: Use the REST API or batch-specific SDK methods # The exact SDK interface may vary — check current documentation import requests, json headers = {"Content-Type": "application/json"} api_url = "https://generativelanguage.googleapis.com/v1beta/batchJobs" response = requests.post( f"{api_url}?key=YOUR_API_KEY", headers=headers, json={"requests": batch_requests} ) job = response.json() job_name = job.get("name") print(f"Batch job created: {job_name}") # Step 3: Poll for completion while True: status_resp = requests.get(f"{api_url}/{job_name}?key=YOUR_API_KEY") status = status_resp.json() state = status.get("state", "UNKNOWN") print(f"Job state: {state}") if state in ("SUCCEEDED", "FAILED", "CANCELLED"): break time.sleep(30) # Check every 30 seconds # Step 4: Retrieve results if state == "SUCCEEDED": results = requests.get(f"{api_url}/{job_name}/results?key=YOUR_API_KEY") for result in results.json().get("responses", []): custom_id = result["custom_id"] # Process each generated image print(f"Image {custom_id} generated successfully")
При работе с Batch API есть несколько практических нюансов. SLA в 24 часа — это максимум; на практике большинство пакетных заданий завершаются значительно быстрее, часто за 1-4 часа в зависимости от глубины очереди и размера задания. Приложение следует проектировать с опросом статуса через разумные интервалы (каждые 30-60 секунд), а не с блокирующим ожиданием. Обработка ошибок в пакетном режиме отличается от вызовов реального времени: отдельные запросы внутри пакета могут завершаться с ошибками независимо, поэтому код обработки результатов должен проверять статус каждого ответа и реализовать логику повтора для неудачных элементов. Также учтите, что лимит токенов пакетной очереди считает все поставленные в очередь (ещё не завершённые) задания, поэтому не стоит отправлять больше работы, чем вы можете обработать за разумное время.
Batch API особенно эффективен в сценариях: генерация изображений товаров для электронной коммерции (обработка сотен описаний продуктов за ночь), конвейеры контент-маркетинга (массовое создание визуалов для социальных сетей) и создание наборов данных для обучения моделей машинного обучения. Любой рабочий процесс, где допустима задержка в минуты или часы — а не требуется мгновенный ответ — должен серьёзно рассмотреть Batch API как из-за экономии затрат, так и из-за иммунитета к лимитам реального времени, вызывающим ошибки 429. Для более широкого обзора оптимизации затрат смотрите наше руководство по решению проблем с лимитами Gemini.
Решение 4 — Распределение запросов между несколькими проектами
Поскольку лимиты Gemini API применяются на уровне проекта, а не на уровне API-ключа, вы можете эффективно умножить общую доступную квоту, распределяя запросы между несколькими проектами Google Cloud. Этот подход технически прост: создайте N проектов, сгенерируйте API-ключ для каждого и реализуйте стратегию циклического распределения (round-robin) в коде приложения. С тремя проектами вы фактически утраиваете лимиты RPM, RPD, IPM и TPM без повышения уровня или дополнительных расходов на проект.
Реализация требует поддержки пула API-ключей (по одному на проект) и циклического их использования для каждого запроса. Вот готовая к продакшену реализация, которая обрабатывает как распределение, так и переключение при достижении лимитов отдельных проектов:
pythonimport itertools import random class MultiProjectClient: def __init__(self, api_keys: list[str]): self.api_keys = api_keys self.key_cycle = itertools.cycle(api_keys) self.failed_keys = set() def generate_image(self, prompt, max_attempts=None): max_attempts = max_attempts or len(self.api_keys) * 2 for attempt in range(max_attempts): key = next(self.key_cycle) if key in self.failed_keys: continue try: genai.configure(api_key=key) model = genai.GenerativeModel("gemini-3.1-flash-image-preview") response = model.generate_content( prompt, generation_config={"response_mime_type": "image/png"} ) return response except Exception as e: if "429" in str(e): self.failed_keys.add(key) if len(self.failed_keys) >= len(self.api_keys): self.failed_keys.clear() # Reset and retry raise Exception("All projects rate limited") else: raise raise Exception("Max distribution attempts exceeded") # Usage client = MultiProjectClient([ "API_KEY_PROJECT_1", "API_KEY_PROJECT_2", "API_KEY_PROJECT_3" ]) result = client.generate_image("A beautiful sunset over the ocean")
Одно важное архитектурное соображение: убедитесь, что у каждого проекта Google Cloud включён собственный платёжный аккаунт (или по крайней мере биллинг разделяется через один платёжный аккаунт, привязанный к нескольким проектам). Это гарантирует, что каждый проект независимо получает лимиты своего уровня. Управление несколькими проектами осуществляется через переключатель проектов в Google Cloud Console, и практически нет ограничений на количество проектов одного аккаунта Google.
Относительно соответствия условиям использования: документация Google явно указывает, что «лимиты применяются на уровне проекта» и предоставляет инструменты управления квотами для каждого проекта, что неявно признаёт, что пользователи могут работать с несколькими проектами. Этот подход не нарушает никаких заявленных условий, если каждый проект является легитимным проектом Google Cloud с правильно настроенным биллингом. Однако есть практические соображения — необходимо управлять биллингом нескольких проектов, отдельно мониторить квоты и обрабатывать дополнительную сложность в конвейере развёртывания. Это решение лучше всего подходит для команд, которые уже работают в мультипроектной среде Google Cloud.
Решение 5 — API-прокси для неограниченной пропускной способности
Когда вашему приложению требуется устойчивая высокая пропускная способность, превышающая даже лимиты Tier 3, или когда у вас нет прямого доступа к Google Cloud Platform (что часто встречается у разработчиков в определённых регионах), сервис API-прокси предоставляет наиболее комплексное решение проблемы ошибок 429. API-прокси работают, поддерживая большие пулы учётных данных API на множестве проектов и уровней, прозрачно распределяя ваши запросы, чтобы избежать достижения лимитов любого отдельного проекта. С точки зрения вашего приложения вы делаете вызовы API к единой конечной точке и никогда не видите ошибки 429, потому что прокси берёт на себя всё управление лимитами.
При оценке сервисов API-прокси для генерации изображений Gemini важны несколько критериев. Во-первых, проверьте, поддерживает ли прокси конкретную модель, которая вам нужна — не все сервисы поддерживают gemini-3.1-flash-image-preview или его возможности вывода изображений. Во-вторых, уточните структуру ценообразования: одни прокси взимают плату за запрос, другие за токен, а некоторые используют фиксированную цену за изображение. В-третьих, оцените совместимость API — лучшие прокси предлагают формат API, совместимый с OpenAI, что означает возможность переключения путём замены только базового URL и API-ключа в существующем коде без переписывания логики. Наконец, учтите гарантии надёжности: SLA по времени безотказной работы, географическую задержку и оперативность поддержки.
Для разработчиков, ищущих прокси-решение, сервисы вроде laozhang.ai предлагают генерацию изображений Gemini примерно по $0,05 за изображение с фиксированной ценой независимо от разрешения — что представляет значительную экономию при высоких разрешениях, где прямое ценообразование Google варьируется от $0,101 до $0,151. Платформа агрегирует несколько моделей и провайдеров, управляет лимитами внутренне и не требует аккаунта GCP. Вы можете протестировать его непосредственно на площадке генерации изображений перед принятием решения.
Процесс интеграции с большинством API-прокси удивительно прост, поскольку они предоставляют конечные точки, совместимые с OpenAI. Во многих случаях переключение с прямого доступа к Google API на прокси требует изменения всего двух значений конфигурации — базового URL и API-ключа. Существующая логика форматирования промптов, обработки ошибок и парсинга ответов обычно работает без изменений. Вот минимальный пример, показывающий различие интеграции с прокси от прямого API:
python# Direct Google API import google.generativeai as genai genai.configure(api_key="GOOGLE_API_KEY") model = genai.GenerativeModel("gemini-3.1-flash-image-preview") # Via API Proxy (OpenAI-compatible format) from openai import OpenAI client = OpenAI( api_key="PROXY_API_KEY", base_url="https://api.laozhang.ai/v1" ) response = client.chat.completions.create( model="gemini-3.1-flash-image-preview", messages=[{"role": "user", "content": "A sunset over mountains"}] )
Для определения того, подходит ли API-прокси вашему случаю, рассмотрите следующую систему принятия решений. Используйте прямой Google API, когда у вас есть надёжный доступ к GCP, объём трафика укладывается в лимиты вашего уровня и требуется максимальная конфиденциальность данных с прямым SLA от Google. Используйте API-прокси, когда вы находитесь в регионе с ограниченным доступом к GCP, потребности в пропускной способности превышают возможности повышения уровня, хотите упрощённый биллинг без управления проектами GCP или создаёте прототип и хотите избежать настройки GCP. Для самых доступных вариантов Gemini Flash Image API у разных провайдеров наш обзор сравнений охватывает текущую картину рынка.
Выбор решения — сравнение + FAQ
Правильное решение зависит от вашей конкретной ситуации: насколько срочно нужно исправить ошибку, бюджетные ограничения, техническая инфраструктура и долгосрочные требования к пропускной способности. Большинство продакшн-развёртываний выигрывают от комбинации нескольких решений — например, реализация экспоненциальной задержки (Решение 1) как базовой страховочной сетки с одновременным повышением до Tier 1 или Tier 2 (Решение 2) для устойчивой ёмкости.
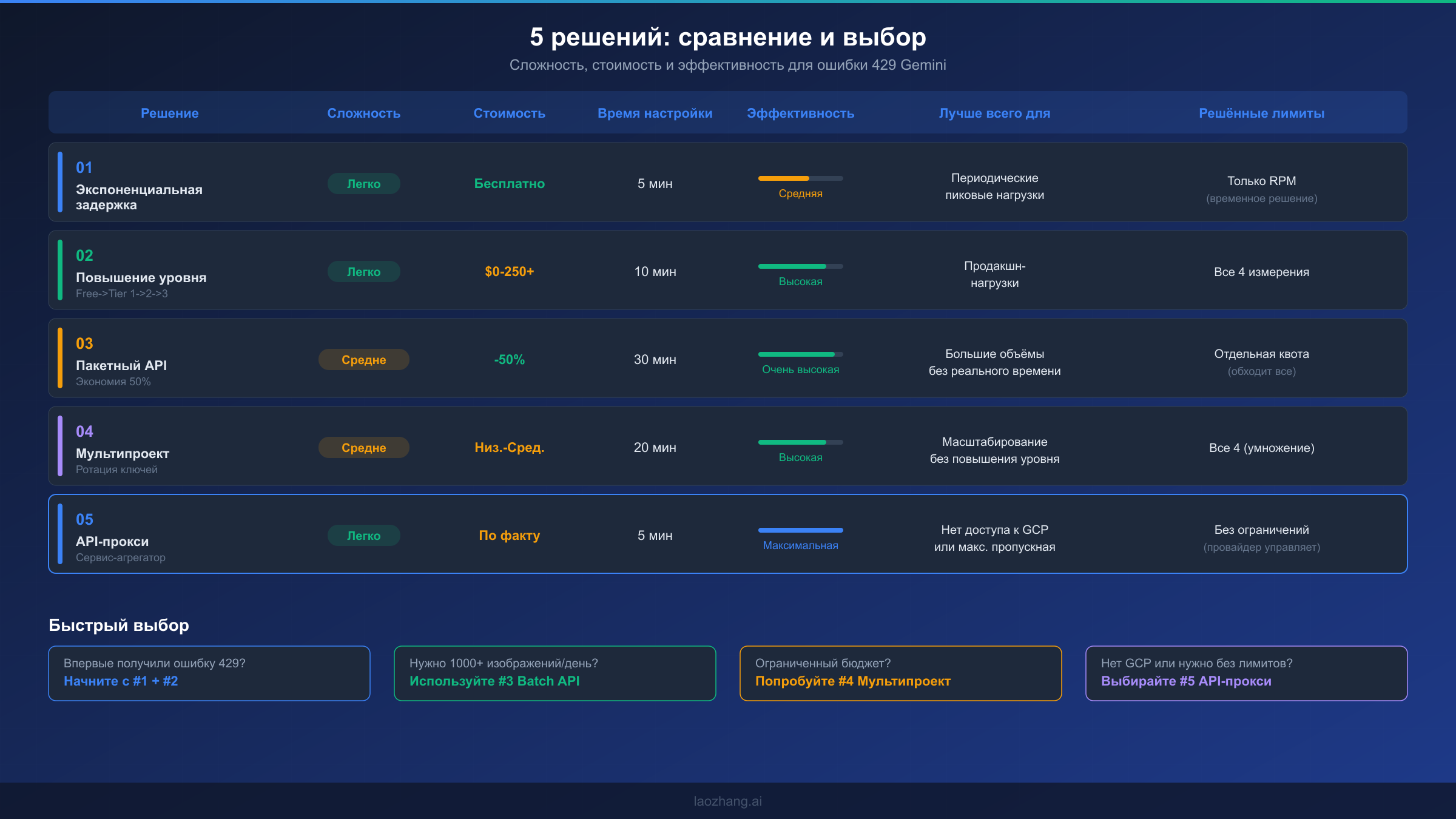
Вот краткое сравнение пяти решений по наиболее важным факторам принятия решений. Решения 1 и 2 — фундамент, который должен реализовать каждый проект: задержка для устойчивости и повышение уровня для ёмкости. Решения 3, 4 и 5 — стратегии масштабирования, отвечающие на разные ограничения: Batch API для оптимизации затрат, когда задержка некритична, мультипроект для бесплатного масштабирования в экосистеме Google, и API-прокси для максимальной простоты и неограниченной пропускной способности.
Для разработчиков, которые только начинают работать с генерацией изображений Gemini и получают ошибки 429 на бесплатном уровне, самый быстрый путь к решению: во-первых, реализуйте экспоненциальную задержку для корректной обработки текущих ошибок. Во-вторых, включите биллинг на проекте для перехода на Tier 1 — это часто единственное наиболее значимое изменение, поскольку оно кардинально увеличивает квоты по всем четырём измерениям. Эти два шага решают проблему ошибок 429 для подавляющего большинства рабочих нагрузок разработки и продакшна от низкого до среднего объёма.
Для высоконагруженных продакшн-задач с генерацией тысяч изображений ежедневно оптимальная стратегия зависит от требований к задержке. Если изображения можно генерировать асинхронно (каталоги электронной коммерции, конвейеры маркетингового контента, обучающие данные для ML), Batch API (Решение 3) обеспечивает лучшую экономическую эффективность со скидкой 50% и собственным отдельным пулом квот. Если вам нужна генерация изображений в реальном времени в масштабе, комбинируйте повышение уровня (Решение 2) с мультипроектным распределением (Решение 4) для умножения эффективных лимитов. А если вы хотите полностью исключить проблему лимитов, API-прокси (Решение 5) переносит всё управление квотами на провайдера.
Часто задаваемые вопросы
Как долго длится ограничение 429 в Gemini API?
Для лимитов RPM, TPM и IPM окно составляет скользящие 60 секунд — если вы прекратите отправку запросов, квота обновится в течение минуты. Для лимитов RPD необходимо ждать до полуночи по тихоокеанскому времени для сброса дневного счётчика. Ручного сброса любого счётчика лимитов не существует — единственные варианты: ожидание естественного сброса или увеличение лимитов через повышение уровня.
Можно ли получить исключение из лимитов от Google?
Google не предоставляет индивидуальных исключений из лимитов для Gemini API. Система уровней — это официальный путь для увеличения лимитов. Если вам нужны лимиты выше Tier 3, рекомендуемый подход — обратиться в отдел продаж Google Cloud для заключения корпоративного соглашения, которое может включать пользовательские квоты.
Помогает ли использование нескольких API-ключей в одном проекте?
Нет. Лимиты применяются на уровне проекта, а не API-ключа. Создание дополнительных ключей в одном проекте не увеличивает квоту ни по одному измерению. Чтобы получить выгоду от нескольких ключей, каждый должен принадлежать отдельному проекту Google Cloud (см. Решение 4).
В чём разница между ошибками 429 и 503?
Ошибка 429 означает, что вы превысили выделенную квоту — нужно либо подождать обновления квоты, либо увеличить лимиты. Ошибка 503 означает, что сервис Google временно недоступен, что не связано с вашим использованием. Для ошибок 503 обычно достаточно простого повтора через 1-5 секунд. Для ошибок 429 нужны целенаправленные решения, описанные в этом руководстве.
Batch API всегда будет на 50% дешевле?
Ценообразование Batch API от Google стабильно установлено на уровне 50% от цены API реального времени с момента его введения. Хотя цены могут измениться, скидка стимулирует разработчиков использовать пакетную обработку, которая более эффективна для инфраструктуры Google. Проверяйте текущие цены на официальной странице ценообразования Gemini перед построением финансовых прогнозов.
Как мониторить использование лимитов в реальном времени?
Google Cloud Console предоставляет мониторинг квот в реальном времени в разделе IAM и администрирование > Квоты. Отфильтруйте сервис «generativelanguage.googleapis.com», чтобы увидеть все квоты Gemini API с графиками использования. Также можно настроить оповещения о квотах для уведомления при настраиваемых порогах (например, 80% использования), что даёт раннее предупреждение до появления ошибок 429 в продакшене. Для программного мониторинга Cloud Monitoring API позволяет запрашивать метрики использования квот и интегрировать их в существующие дашборды или системы оповещения.
Можно ли увеличить лимиты бесплатного уровня без оплаты?
Нет. Лимиты бесплатного уровня фиксированы и были значительно сокращены в декабре 2025 года. Единственный способ увеличить лимиты — включить биллинг на проекте (что повышает до Tier 1) или использовать подход мультипроектного распределения, описанный в Решении 4. Google периодически корректирует квоты бесплатного уровня, но тенденция направлена на ужесточение ограничений по мере масштабирования сервиса, что делает бесплатный уровень подходящим преимущественно для разработки и экспериментов, а не для продакшн-нагрузок.