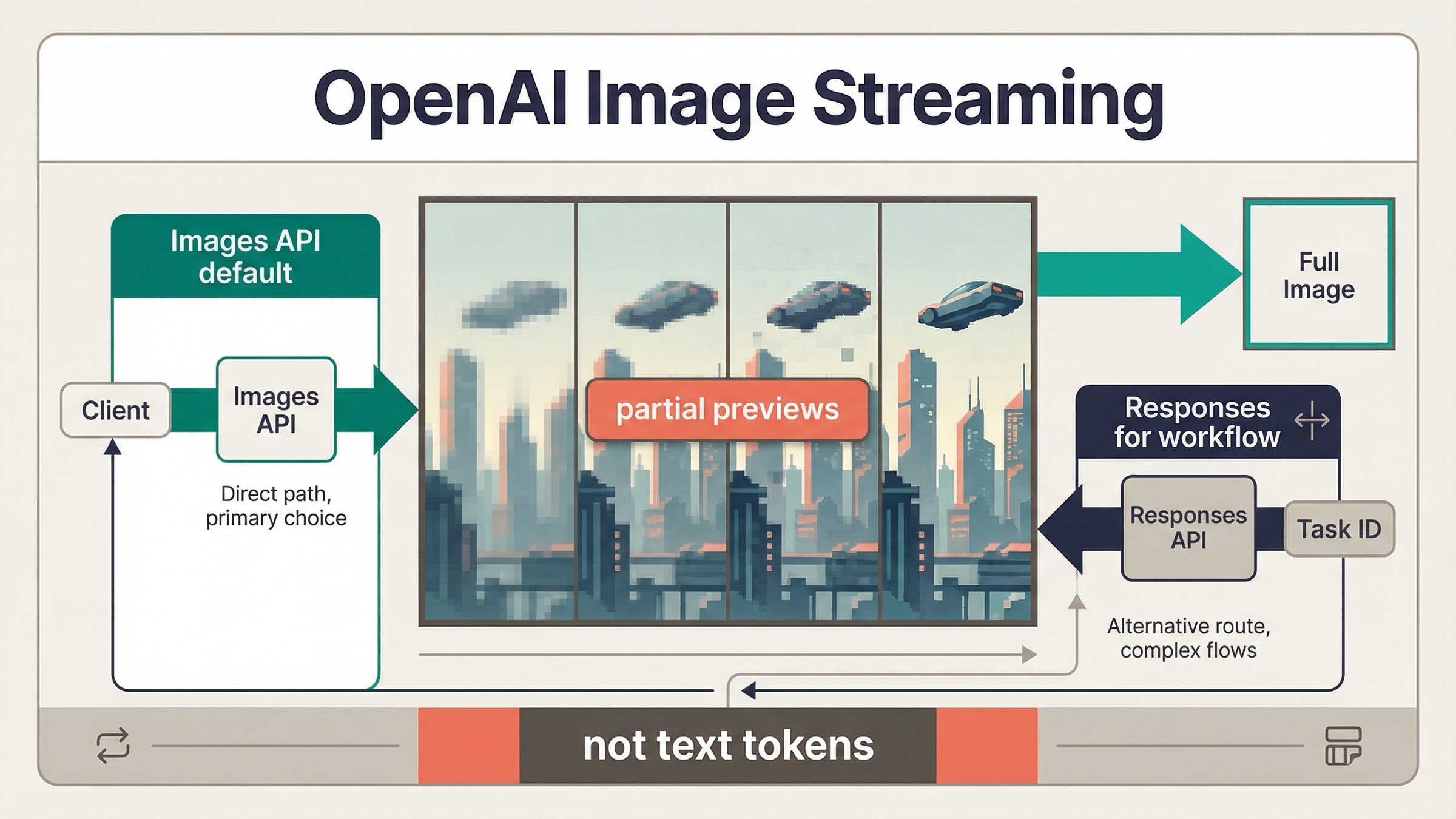
2026년 3월 23일 기준으로 OpenAI image generation 은 streaming 을 지원합니다. 다만 지금 OpenAI 가 문서화하는 streaming 은 text-style token streaming 이 아닙니다. 실제로는 최종 이미지가 아직 생성되는 동안 도착하는 partial-image previews 입니다. 이 차이는 단순한 용어 문제가 아니라, UI 에 무엇을 약속할 수 있는지와 어떤 API surface 를 먼저 연결해야 하는지를 바꿉니다.
만약 만들고 있는 것이 direct image feature 라면, 가장 안전한 현재 기본 경로는 단순합니다. 먼저 Images API 를 쓰고 client.images.generate() 에서 partial previews 를 스트리밍한다. 반대로 이미지 생성이 더 큰 assistant 나 multimodal workflow 안의 한 tool 에 불과하다면, 그때는 Responses API 와 hosted image_generation tool 이 더 자연스럽습니다. 많은 약한 페이지가 이 두 경로를 흐리게 섞어 놓기 때문에 keyword 가 필요 이상으로 어렵게 느껴집니다.
이 주제가 계속 헷갈리는 또 다른 이유는 OpenAI 의 공식 페이지들이 streaming 을 같은 층위에서 설명하지 않기 때문입니다. 현재 image generation guide 는 Responses API 와 Images API 양쪽 모두에서 streaming 을 문서화합니다. 그런데 현재 GPT Image 1.5 model page 는 feature table 에 아직도 Streaming: Not supported 라고 적고 있습니다. 이 순서를 잘못 읽으면 문서가 서로 모순되는 것처럼 보이므로, 이 글은 그 충돌을 먼저 정리합니다.
핵심 요약
- OpenAI image generation 은 현재 streaming 을 지원한다. 하지만 흐르는 것은 partial-image previews 이지 text tokens 가 아니다.
- 이미지 생성 자체가 기능이면 Images API 부터 시작한다.
- 이미지 생성이 larger workflow 의 한 tool 이면 Responses API 를 쓴다.
- event name 은 surface 마다 다르다. Images API 는
image_generation.partial_image, Responses API 는response.image_generation_call.partial_image를 쓴다. partial_images를 요청해도 preview 개수가 항상 그대로 오지는 않는다. current guide 는0에서3까지 설정 가능하다고 설명하며, generation 이 빠르면 더 적게 올 수 있다고 말한다.
먼저 이해할 것: 지금 OpenAI image streaming 이 뜻하는 바
이 키워드를 가장 쉽게 오해하는 방식은 text generation 의 mental model 을 그대로 가져오는 것입니다. 개발자가 "OpenAI image generation 이 streaming 되나"라고 물을 때 실제로는 보통 두 가지를 확인합니다.
- 최종 이미지가 끝나기 전에 progressive visual feedback 을 보여줄 수 있는가
- image model 이 text model 처럼 token-sized chunks 를 계속 내보내는가
현재 OpenAI 의 답은 첫 번째는 yes, 두 번째는 no 입니다. current image generation guide 는 Responses API 와 Image API 양쪽이 streaming image generation 을 지원한다고 말한 뒤, 그 지원 형태를 partial images 로 정의합니다. 그리고 partial_images 는 0 에서 3 사이로 설정할 수 있지만, final image 가 빨리 끝나면 요청한 수보다 적은 previews 만 받을 수 있다고 경고합니다.
즉 product expectation 은 "마지막 픽셀까지 작은 렌더 조각이 계속 온다"가 아닙니다. 올바른 기대값은 "generation 이 진행되는 동안 소수의 preview images 를 받아서 보여주고, 완료되면 final image 처리 경로로 넘긴다"입니다. 이것만으로도 UX 는 충분히 좋아질 수 있습니다. 특히 image generation 을 덜 블랙박스처럼 보이게 해야 하는 제품이라면 유용합니다. 다만 many developers 가 streaming 이라는 단어에서 기대하는 범위보다 계약이 좁다는 점은 분명히 이해해야 합니다.
그래서 첫 번째 구현 선택이 중요합니다. prompt, preview 몇 장, final image 만 필요하다면 Images API 가 mental model 을 더 깨끗하게 유지합니다. conversation state, tool orchestration, broader agent workflow 가 필요하다면 Responses API 가 더 맞습니다. current docs 는 두 경로를 모두 지원합니다. 실수는 둘을 모든 프로젝트에 똑같이 좋은 첫 선택으로 보는 것입니다.
Images API vs Responses API: 올바른 streaming surface 고르기
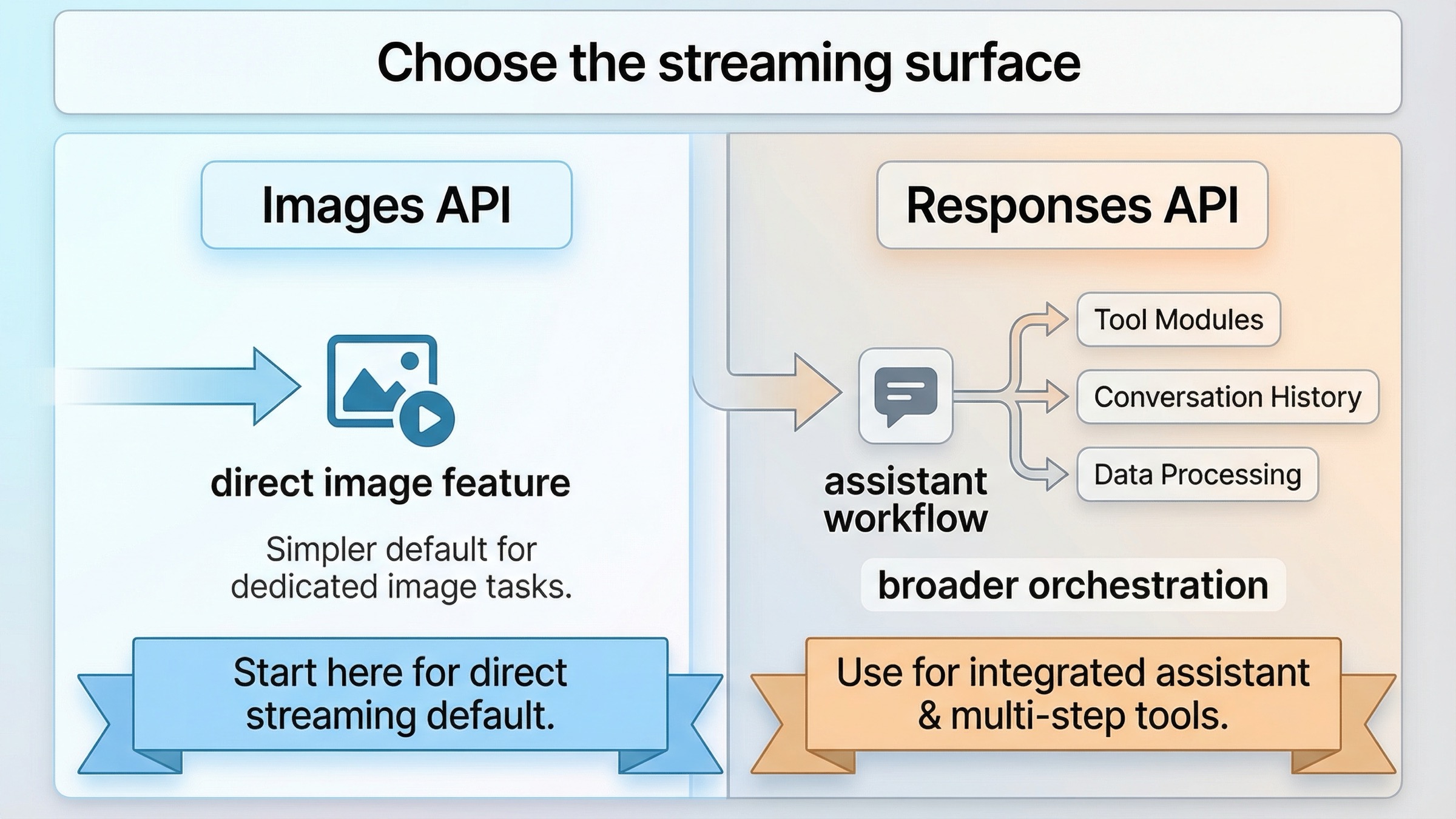
이 keyword 는 "어느 endpoint 가 더 최신인가"를 묻지 않고, "지금 만들고 있는 제품에 맞는 surface 가 무엇인가"를 묻기 시작하면 훨씬 단순해집니다.
| 상황 | 더 나은 기본값 | 이유 |
|---|---|---|
| direct image feature 에서 preview 와 final image 가 모두 필요하다 | Images API | request shape 이 가장 단순하고 image-only path 의 event loop 가 가장 깔끔하다 |
| 이미지 생성이 broader assistant / multimodal flow 안의 일부다 | Responses API | image generation 을 larger reasoning / conversation workflow 의 tool 로 넣을 수 있다 |
| 내 account 에서 streaming 이 되는지 가장 빨리 확인하고 싶다 | Images API | moving parts 가 적고 top-level orchestration 을 아직 생각하지 않아도 된다 |
| mainline model 이 prompt 를 다듬거나 다른 tool 을 함께 조정해야 한다 | Responses API | image 가 유일한 output 이 아니라면 hosted image_generation tool 이 더 자연스럽다 |
| docs confusion 을 처음부터 줄이고 싶다 | 먼저 Images API, 필요하면 이후 Responses | event handling 과 orchestration 을 의심하기 전에 route uncertainty 를 한 층 줄일 수 있다 |
실무 규칙은 간단합니다. 이미지 생성 자체가 기능이면 direct route 로 시작한다. Images API 로 partial previews 가 오는지 확인하고, 제품이 정말 필요할 때만 Responses layer 를 추가한다. 이미지 생성이 여러 tool 중 하나라면 처음부터 Responses 로 가는 편이 자연스럽습니다.
현재 images and vision guide 도 이 분기를 지지합니다. 이 guide 는 Image API 나 Responses API 로 이미지를 생성/편집할 수 있다고 설명하며, Responses example 에서는 gpt-4.1-mini 같은 mainline model 에 hosted image_generation tool 을 붙입니다. 이는 OpenAI 가 Responses path 를 "mainline model 이 orchestration 을 맡고, image generation 은 그 안의 tool"로 보고 있다는 강한 힌트입니다.
가장 빨리 통과시키는 방법: Images API 부터
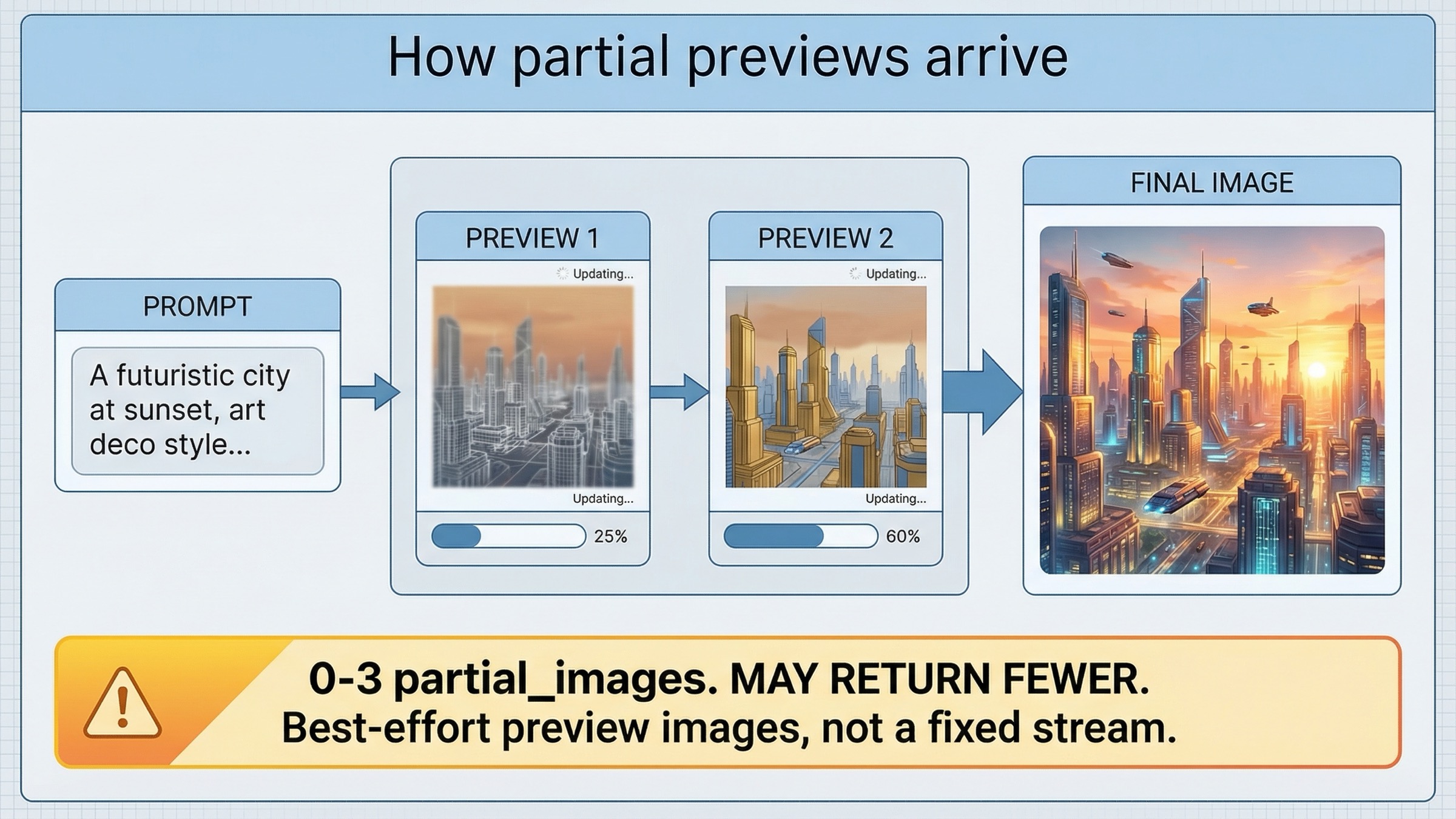
목표가 streaming path 를 빨리 증명하는 것이라면 Images API 가 여전히 가장 좋은 출발점입니다. current guide 는 gpt-image-1.5, stream: true, partial_images: 2 라는 direct pattern 을 보여줍니다. 저는 먼저 이 route 를 통과시키겠습니다.
JavaScript 예제는 다음과 같습니다.
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const stream = await client.images.generate({ model: "gpt-image-1.5", prompt: "Create a clean editorial illustration of a camera drone hovering over a bright city skyline at sunrise", stream: true, partial_images: 2, }); for await (const event of stream) { if (event.type === "image_generation.partial_image") { const index = event.partial_image_index; const imageBytes = Buffer.from(event.b64_json, "base64"); fs.writeFileSync(`preview-${index}.png`, imageBytes); } }
Python 도 거의 같습니다.
pythonfrom openai import OpenAI import base64 client = OpenAI() stream = client.images.generate( model="gpt-image-1.5", prompt="Create a clean editorial illustration of a camera drone hovering over a bright city skyline at sunrise", stream=True, partial_images=2, ) for event in stream: if event.type == "image_generation.partial_image": index = event.partial_image_index image_bytes = base64.b64decode(event.b64_json) with open(f"preview-{index}.png", "wb") as f: f.write(image_bytes)
이 route 가 좋은 이유는 세 가지입니다.
첫째, 가장 단순한 경로를 증명합니다. current image model 을 명시하고, 소수의 previews 를 요청하며, image-specific event 하나만 listen 합니다. 질문이 "streaming 이 되나"라면 이보다 더 깨끗한 첫 테스트는 드뭅니다.
둘째, debug tree 가 훨씬 깔끔해집니다. preview 가 오지 않으면 account access, model choice, event handling 을 먼저 의심하면 됩니다. 더 큰 Responses workflow 안쪽이 문제인지까지 한꺼번에 고민할 필요가 없습니다. 현재 GPT Image 1.5 page 는 여전히 Free not supported 라고 쓰고 있고, image rate limits 도 Tier 1 의 100,000 TPM / 5 IPM 에서 시작하므로 SDK 예제를 탓하기 전에 access assumptions 를 먼저 제거하는 편이 낫습니다.
셋째, UI expectation 을 처음부터 올바르게 고정합니다. guide 는 0 에서 3 까지 partial images 를 요청할 수 있다고 하지만, final image 가 빨리 끝나면 더 적은 preview 만 올 수 있다고도 말합니다. 이는 guaranteed frame contract 가 아니라 preview signal 입니다. 제품이 이 semantics 를 정직하게 처리할 수 있다면, direct Images API route 만으로도 충분한 경우가 많습니다.
direct generation 과 edits 전반까지 팀에 설명해야 한다면, 다음 단계로는 OpenAI Image API 튜토리얼 이 더 좋은 확장 읽기입니다. streaming 질문이 정리된 뒤에는 그쪽이 전체 surface 를 보기에 더 낫습니다.
언제 Responses API 가 더 낫나
Responses path 가 틀린 것은 아닙니다. 다만 이 keyword 에 대한 첫 기본값으로는 대체로 과하다는 뜻입니다.
OpenAI 의 current image generation guide 가 보여주는 streamed Responses example 은 대략 다음과 같습니다.
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const stream = await client.responses.create({ model: "gpt-5", input: "Create a transparent sticker-style icon of a paper airplane for a travel app", stream: true, tools: [{ type: "image_generation", partial_images: 2 }], }); for await (const event of stream) { if (event.type === "response.image_generation_call.partial_image") { const index = event.partial_image_index; const imageBytes = Buffer.from(event.partial_image_b64, "base64"); fs.writeFileSync(`preview-${index}.png`, imageBytes); } }
이 경로는 image 가 유일한 output 이 아닐 때 유용합니다. 예를 들면 다음과 같습니다.
- text 와 image 를 모두 반환하는 multimodal assistant
- 언제 image generation 을 부를지 mainline model 이 판단해야 하는 workflow
- prompt revision 이나 다른 tool coordination 이 image output 전후에 필요한 시스템
current guide 는 이 추가 레이어도 드러냅니다. Responses API 에서는 mainline model 이 image generation call 에 들어가는 prompt 를 수정할 수 있고, 완료된 call 에서 revised_prompt 를 확인할 수 있습니다. surrounding workflow 자체가 product value 라면 Responses path 가 확실히 더 자연스럽습니다.
하지만 한 가지 함정은 막아야 합니다. 최종 output 이 image 라고 해서 top-level model 자리에 gpt-image-1.5 를 넣는 surface 로 생각하면 안 됩니다. current docs 는 Responses image generation 을 gpt-4.1 이나 gpt-5 같은 mainline model + hosted image_generation tool 의 조합으로 설명합니다. 이 mental model 을 뒤집으면 streaming problem 이 아니라 route problem 을 디버깅하게 됩니다.
그래서 올바른 recommendation 은 "Responses 가 더 modern 하니 어디서나 쓰자"가 아닙니다. orchestration 이 feature 면 Responses, image generation 자체가 feature 면 Images API. 이 정도면 충분합니다.
왜 docs 가 서로 모순처럼 보이나
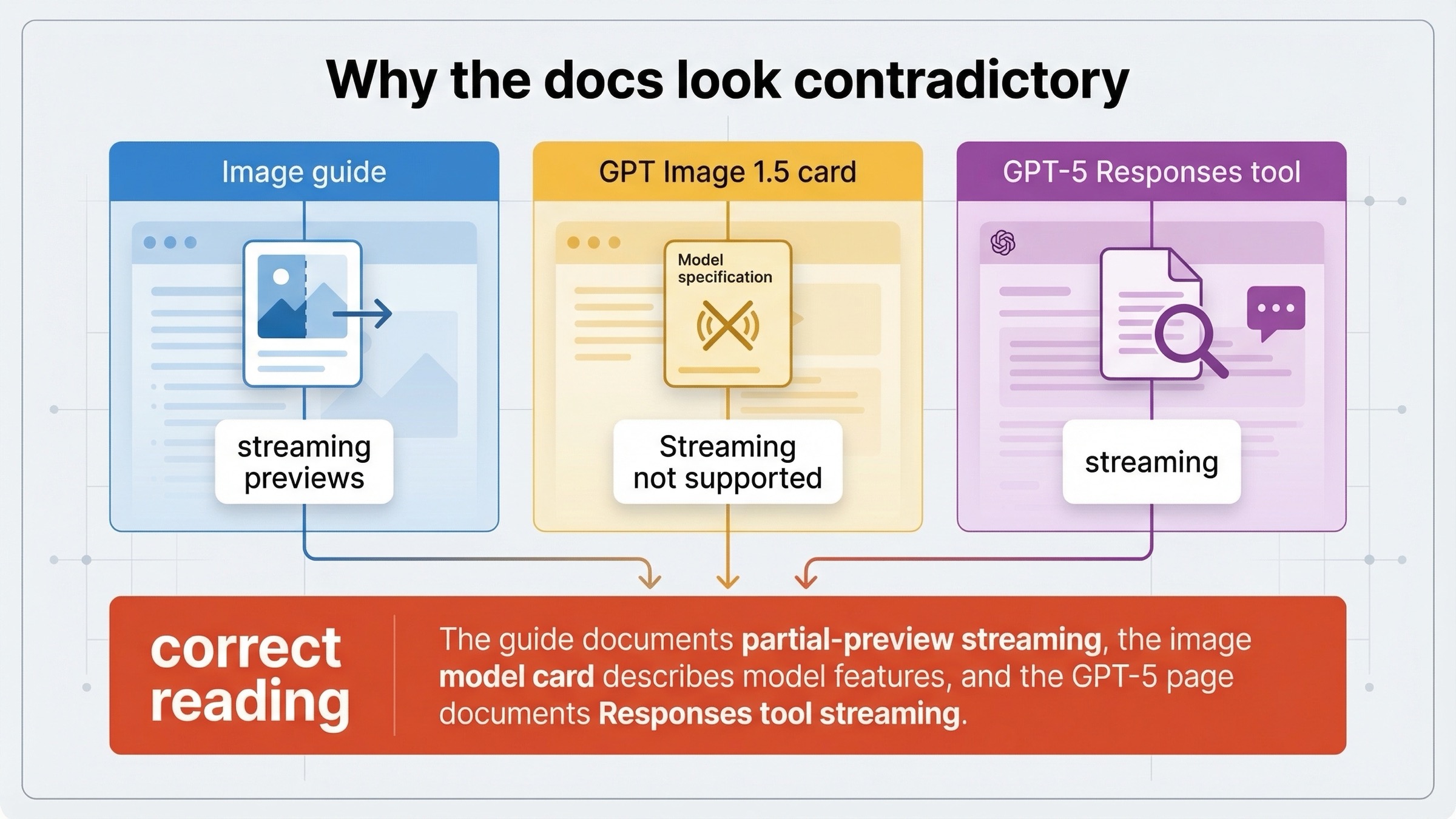
이 부분이야말로 현재 ranking pages 가 가장 약한 지점입니다.
현재 image generation guide 는 Responses API 와 Image API 둘 다 streaming image generation 을 지원한다고 말하고, 각 surface 의 concrete event loop 를 보여주며, 그 의미를 partial-image previews 로 규정합니다.
반면 현재 GPT Image 1.5 model page 는 feature table 에 여전히 Streaming: Not supported 라고 적고 있습니다.
그리고 현재 GPT-5 model page 는 streaming is supported 라고 쓰며, image_generation tool 이 Responses API 에서 지원된다고 설명합니다.
이 셋을 가장 깔끔하게 정리하면 다음과 같습니다.
- image guide 는 API surface behavior 로서의 partial-preview streaming 을 설명한다
- GPT-5 page 는 mainline model behavior 와 Responses 안의 tool support 를 설명한다
- GPT Image model card 는 image model 이 text 처럼 generic streaming 을 한다고 약속하는 문서가 아니다
이 해석은 OpenAI 가 실제로 공개하는 examples 와도 맞습니다. 질문이 "generation 중 preview images 를 받을 수 있나"라면 답은 yes 입니다. 질문이 "image model 이 text model 처럼 token chunks 를 흘리나"라면 답은 no 입니다. current image guide 가 설명하는 것은 그 의미의 streaming 이 아닙니다.
오래된 tutorials 이 다르게 들리는 이유도 같습니다. OpenAI 가 API image model 을 발표한 2025년 4월 23일 launch post 에서는 gpt-image-1 이 먼저 Images API 에 나왔고 Responses support 는 "coming soon" 이라고 했습니다. 그 시기의 mental model 을 계속 끌고 오면 Images-first 인식과 좁은 streaming 정의를 그대로 유지하게 됩니다. docs 는 앞으로 갔지만 옛 wording 은 자동으로 사라지지 않습니다.
시간을 낭비하게 만드는 흔한 mistakes
이 주제의 실패는 깊은 알고리즘 문제가 아니라 route, naming, expectation 의 실수에서 많이 나옵니다.
1. 선택한 surface 와 event name 이 맞지 않는다
direct Images API 에서는 image_generation.partial_image, Responses API 에서는 response.image_generation_call.partial_image 를 사용합니다. 서로 바꿔 쓸 수 없습니다. surface 는 맞았는데 handler 의 event name 이 틀리면 streaming 이 고장난 것처럼 보입니다.
2. direct image feature 인데 처음부터 Responses 로 간다
prompt, preview 몇 장, final asset 만 필요하다면 Images API 가 더 깔끔한 first success 를 줍니다. Responses 로 시작하면 가장 단순한 stream 을 검증하기도 전에 여분의 abstraction layer 를 얹게 됩니다.
3. partial_images 를 고정 프레임 수 보장으로 본다
current guide 는 partial_images 를 0 부터 3 까지 설정할 수 있다고 말하면서도, generation 이 빠르면 요청한 수보다 적게 도착할 수 있다고 적습니다. previews 는 best-effort progress UX 로 봐야지 guaranteed frame contract 로 보면 안 됩니다.
4. model card 와 guide 를 같은 층의 설명으로 읽는다
둘은 다릅니다. guide 는 API surface 의 streamed partial-image delivery 를 설명하고, model card 는 broader catalog table 안에서 image-model features 를 설명합니다. 둘을 하나로 눌러 읽으면 현재 support 를 과소평가하거나 guarantee 를 과대평가하게 됩니다.
5. access assumptions 를 확인하기 전에 code 부터 의심한다
현재 GPT Image 1.5 page 는 Free 불가를 유지하고 있고, launch post 도 organization verification 필요 가능성을 언급합니다. 첫 streamed test 가 아무 것도 하지 않는다면 event loop 만 의심하지 말고, account 와 organization 이 선택한 image model 에 실제로 접근 가능한지 먼저 확인해야 합니다.
6. gpt-image-1 시절 가정으로 2026 구현을 한다
new work 의 current anchor 는 gpt-image-1.5 입니다. 초기 gpt-image-1 launch mental model 이 아닙니다. broader OpenAI image routes 도 정리해야 한다면 다음에는 OpenAI image generation API models 가이드 를 보는 편이 빠릅니다.
FAQ
preview frames 를 정확히 두 장으로 강제할 수 있나.
아니요. current image generation guide 는 partial_images 를 0 에서 3 까지 설정할 수 있다고 말하지만, final image 가 빨리 끝나면 요청한 것보다 적은 previews 만 받을 수 있다고도 설명합니다. partial images 는 best-effort preview signals 로 봐야 합니다.
이 문제는 Realtime API 로 접근해야 하나.
지금 기준 default answer 는 아닙니다. current image generation guide 가 명시하는 경로는 Images API 와 Responses API 위의 streamed partial-image previews 입니다. OpenAI 가 더 직접적인 Realtime image-preview pattern 을 내기 전까지는 이 문서화된 path 를 기준으로 삼는 것이 맞습니다.
request 에 어떤 model 을 넣어야 하나.
direct Images API path 라면 gpt-image-1.5 로 시작합니다. Responses path 라면 current docs pattern 대로 top-level model 에 gpt-4.1 이나 gpt-5 같은 mainline model 을 넣고 hosted image_generation tool 을 붙입니다.
최종 추천
이 페이지에서 한 줄만 기억한다면, 현재 OpenAI image generation streaming 은 partial-image preview streaming 을 뜻하며, image generation 이 단일 feature 인 한 Images API 가 가장 안전한 기본 경로 라는 점입니다.
이 답이 단순한 "된다"보다 더 유용한 이유는 다음 행동을 정해 주기 때문입니다. 먼저 gpt-image-1.5 로 direct streamed Images API request 를 하나 통과시키고, UI 가 best-effort preview arrival 을 정직하게 처리하는지 확인한다. 그 다음에만 Responses API 로 올라간다. 이 순서가 가장 낭비가 적습니다.
streaming 질문이 정리된 뒤 더 넓은 route map 이 필요하다면 direct generation 과 edits 는 OpenAI Image API 튜토리얼 로, preserve-heavy edits 가 다음 문제라면 OpenAI image editing API 가이드 로 이어서 보면 됩니다.