Claude Code 속도 제한에는 완전히 다른 두 가지 유형이 있으며, 이를 혼동하는 것이 개발자들이 잘못된 해결책에 시간을 낭비하는 가장 큰 이유입니다. Pro 플랜에서 모호한 "사용량 한도 도달" 배너를 보고 있든, API에서 정확한 HTTP 429 오류를 받고 있든, 이 가이드는 정확한 병목 지점을 파악하고, 올바른 해결책을 적용하며, 속도 제한이 워크플로우를 방해하지 않는 습관을 만드는 데 도움을 드립니다.
핵심 요약
Claude Code는 두 가지 독립적인 제한 시스템을 적용합니다: 구독 할당량(Pro 및 Max 플랜의 5시간 롤링 윈도우, Claude.ai와 공유)과 API 속도 제한(지출 티어에 따른 분당 RPM/ITPM/OTPM 상한). 구독 제한에 대한 가장 빠른 해결책은 5시간 리셋을 기다리거나 Max로 업그레이드하는 것입니다. API 제한의 경우 지수 백오프를 구현하거나, 프롬프트 캐싱으로 실질적인 토큰 소비를 최대 80%까지 줄이거나, 분당 제한 없이 토큰당 과금하는 laozhang.ai와 같은 서드파티 API 서비스를 통해 요청을 라우팅하는 방법이 있습니다.
Claude Code에 속도 제한이 걸리는 이유 (두 가지 별도 시스템)
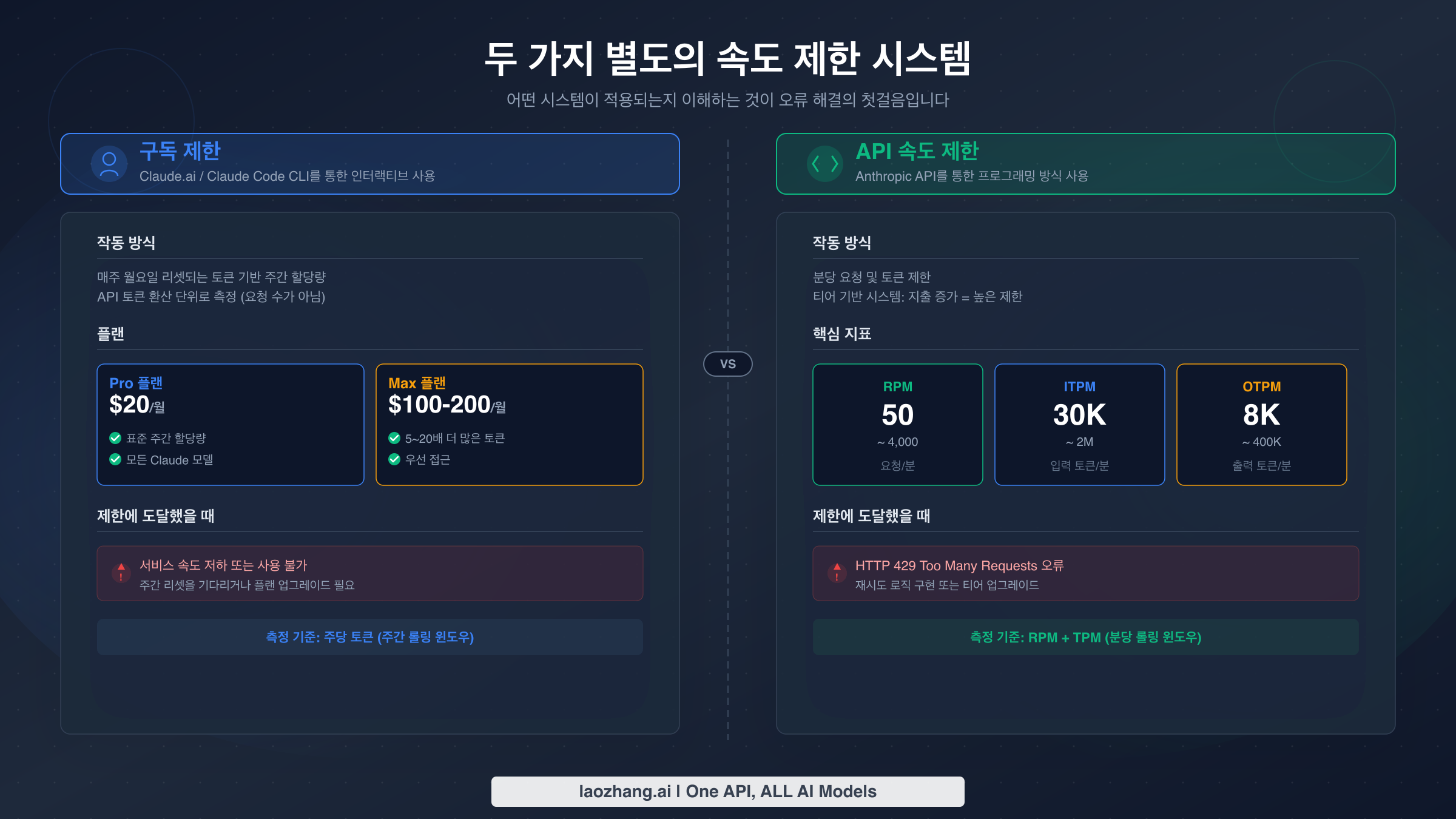
Claude Code 속도 제한에 대해 가장 중요하게 이해해야 할 것은, 도구 사용량을 제어하는 완전히 별개인 두 가지 시스템이 존재한다는 점입니다. 대부분의 온라인 트러블슈팅 가이드는 이 두 시스템을 혼동하여, 개발자들이 귀중한 코딩 시간을 낭비하게 만듭니다. 어떤 시스템이 여러분을 제한하고 있는지 이해하면 해결책이 5초 만에 끝날지, 5분이 걸릴지가 결정됩니다.
시스템 1 — 구독 할당량은 유료 플랜(Pro $20/월, Max 5x $100/월, Max 20x $200/월, Anthropic 가격 페이지 기준, 2026년 3월 확인)을 통해 Claude Code를 사용할 때 적용됩니다. 이 할당량은 5시간 롤링 윈도우에 걸친 총 사용량을 측정하며, Claude.ai 채팅과 Claude Code 간에 공유됩니다. 구독 할당량이 소진되면, Claude Code는 표준 HTTP 오류 코드 대신 "사용량 한도에 도달했습니다" 또는 "현재 한도에 도달했습니다"와 같은 소프트 메시지를 표시합니다. 핵심적으로 알아야 할 점은 더 무거운 모델이 할당량을 더 빠르게 소모한다는 것입니다. Opus 4.6은 같은 대화 길이에서 Sonnet 4.6보다 약 5배 많은 리소스를 사용하기 때문에, Opus를 기본으로 사용하는 Max 플랜 사용자가 놀라울 만큼 빠르게 제한에 걸릴 수 있습니다.
시스템 2 — API 속도 제한은 여러분(또는 여러분을 대신하는 도구)이 Anthropic Messages API에 직접 호출을 할 때 적용됩니다. 이 제한은 분당 요청 수(RPM), 분당 입력 토큰 수(ITPM), 분당 출력 토큰 수(OTPM)로 측정됩니다. 구독 플랜이 아닌 API 조직의 지출 티어에 연결되며, 초과 시 retry-after 헤더가 포함된 표준 HTTP 429 응답 코드를 반환합니다. API는 토큰 버킷 알고리즘을 사용하므로(Anthropic 속도 제한 페이지 문서, 2026년 3월 확인) 고정 간격으로 리셋되는 것이 아니라 용량이 지속적으로 보충됩니다.
이 두 시스템은 독립적으로 작동합니다. API 속도 제한에는 충분한 여유가 있으면서도 구독 할당량이 소진될 수 있고, 그 반대도 가능합니다. 최근 Pro에서 Max 5x로 업그레이드한 개발자가 구독 제한은 사라졌지만, Claude Code의 멀티턴 대화가 시스템 프롬프트, 파일 내용, 도구 사용 토큰을 모든 요청에 번들로 포함하기 때문에 API 티어 ITPM 상한에 걸리는 것을 발견할 수도 있습니다. Claude Code 무료 티어가 이 구조에서 어떻게 작동하는지 궁금하시다면, 무료 플랜은 양쪽 모두에서 더 엄격한 제한이 적용됩니다.
구독 속도 제한 — Pro, Max 5x, Max 20x 할당량
구독 제한은 대부분의 Claude Code 사용자가 가장 먼저 마주치는 제한입니다. 모든 유료 플랜에 Claude Code 접근이 포함되어 있고, 할당량이 모든 Claude 제품에서 공유되기 때문입니다. Anthropic이 2025년 8월 28일에 주간 할당량을 도입했을 때 — TechCrunch 등 여러 매체에서 광범위하게 다룬 변경 사항 — 개발자 커뮤니티는 장시간 코딩 세션에서 Claude Code를 얼마나 적극적으로 활용할 수 있는지에 대한 큰 변화를 겪었습니다.
다음 표는 개인 사용자를 위한 현재 구독 티어를 요약합니다(claude.com/pricing 및 서드파티 보고서에서 확인, 2026년 3월):
| 플랜 | 월 가격 | 5시간당 대략적 메시지 수 | 사용 가능 모델 | 자동 다운그레이드 임계값 |
|---|---|---|---|---|
| Free | $0 | 매우 제한적 (수요에 따라 변동) | Sonnet, Haiku | 해당 없음 |
| Pro | $20 (연간 $17/월) | ~45 메시지 | Sonnet 4.6 | 해당 없음 |
| Max 5x | $100 | ~225 메시지 (Pro의 5배) | Sonnet 4.6, Opus 4.6 | 사용량 20%에서 Opus → Sonnet |
| Max 20x | $200 | ~900 메시지 (Pro의 20배) | Sonnet 4.6, Opus 4.6 | 사용량 50%에서 Opus → Sonnet |
이 제한이 실제로 어떻게 느껴지는지에 영향을 미치는 몇 가지 중요한 세부 사항이 있습니다. 첫째, "메시지" 지표는 대략적인 수치입니다. 각 상호작용의 토큰 소비량은 코드베이스 컨텍스트 크기, 대화에 포함된 파일 수, Claude Code가 파일 읽기나 bash 명령 같은 도구 호출을 실행하는지 여부에 따라 크게 달라집니다. 단일 파일에 대한 간단한 질문은 하나의 "메시지 단위"를 소비할 수 있지만, 수십 개의 파일을 다루는 복잡한 리팩토링 작업은 단일 턴에서 10개 이상의 메시지에 해당하는 양을 소비할 수 있습니다.
둘째, Max 플랜의 자동 다운그레이드 동작은 축복이자 불편함입니다. Opus 사용량이 임계값(Max 5x에서 20%, Max 20x에서 50%)에 도달하면, Claude Code는 후속 상호작용에서 자동으로 Sonnet으로 전환합니다. 이는 남은 할당량을 가벼운 작업에 보존하지만, 모델의 추론 품질이 세션 중간에 눈에 띄게 떨어지면 당혹스러울 수 있습니다. /model 명령으로 이를 재지정할 수 있지만, 그렇게 하면 남은 할당량이 훨씬 빠르게 소진됩니다.
셋째, 많은 사용자를 놀라게 하는 점은, 구독 할당량이 Claude.ai 웹 채팅과 Claude Code 간에 공유된다는 것입니다. 오전에 Claude.ai 인터페이스에서 긴 대화를 했다면, 오후의 Claude Code 할당량은 그만큼 줄어듭니다. 한 팀원이 리서치(채팅 통해)와 구현(Claude Code 통해)을 모두 담당하는 팀에서는 이를 어렵게 발견하는 경우가 많습니다.
2026년 1월의 논란은 구독 제한이 기술적으로 설계대로 작동하더라도 어떻게 예측 불가능하게 느껴질 수 있는지를 보여주기 때문에 자세히 살펴볼 가치가 있습니다. Anthropic이 2025년 12월 25일~31일 동안 홀리데이 프로모션으로 사용량 한도를 두 배로 늘린 후, 많은 사용자가 1월 1일 정상 할당량이 복원되었을 때 약 60% 감소한 것처럼 느꼈다고 보고했습니다. Anthropic은 제한이 표준 기준선으로 돌아갔을 뿐이라고 해명했지만, 그 대비가 정상 제한을 제한적으로 느끼게 만들었습니다. 이 현상은 Reddit, Hacker News, Discord의 개발자 커뮤니티에서 광범위한 토론을 일으켰습니다.
상황은 2026년 2월 Hacker News 스레드에서 해당 사용량 없이도 속도 제한이 발생하는 사례가 보고되면서 더욱 복잡해졌습니다. Anthropic은 토큰 소비 버그를 확인할 수 없다고 밝혔지만, 커뮤니티는 자동 대화 인덱싱, 컨텍스트 윈도우 관리, 도구 사용 오버헤드 등 Claude Code의 백그라운드 작업이 사용자가 명시적으로 승인하지 않은 토큰을 소비하는 여러 시나리오를 문서화했습니다. 이는 Claude Code의 중요한 특성을 강조합니다: 모든 토큰을 직접 제어하는 단순한 API 호출과 달리, Claude Code의 에이전트형 동작은 시스템 프롬프트, 파일 읽기, 내부 추론 단계를 통해 터미널에서 보이는 "메시지"로 나타나지 않으면서도 할당량 소비에 기여하는 상당한 토큰 오버헤드를 생성합니다.
이러한 숨겨진 토큰 소비를 이해하는 것이 구독 제한을 효과적으로 관리하는 핵심입니다. 터미널에서 하나의 교환으로 보이는 단일 Claude Code 상호작용이 실제로는 여러 내부 API 호출 — 파일 읽기, 명령 실행, 코드베이스 검색 — 을 포함할 수 있으며, 각각이 할당량에 대해 토큰을 소비합니다. 이것이 Pro 사용자를 위한 "5시간당 약 45 메시지" 지표가 크게 부정확하게 느껴질 수 있는 이유입니다: 복잡한 코딩 작업은 사용자 관점에서 단일 상호작용처럼 보이는 것에서 15개 "메시지" 분량의 토큰을 소비할 수 있습니다.
API 속도 제한 — 티어별 RPM, ITPM, OTPM

API 속도 제한은 Anthropic Messages API에 대한 직접 호출을 관리하며, 누적 크레딧 구매에 기반한 4개 티어로 구성됩니다. 구독 할당량과 달리, 이 제한은 정확하게 정의되어 있으며 코드에서 프로그래밍 방식으로 처리할 수 있는 구조화된 오류 응답을 반환합니다. 더 자세한 분석은 Claude API 할당량 티어 및 제한 완벽 가이드를 참조하세요.
다음은 가장 많이 사용되는 모델의 현재 티어별 API 속도 제한입니다(platform.claude.com/docs/en/api/rate-limits에서 확인, 2026년 3월):
| 모델 | Tier 1 (RPM / ITPM / OTPM) | Tier 2 | Tier 3 | Tier 4 |
|---|---|---|---|---|
| Sonnet 4.x | 50 / 30K / 8K | 1,000 / 450K / 90K | 2,000 / 800K / 160K | 4,000 / 2M / 400K |
| Opus 4.x | 50 / 30K / 8K | 1,000 / 450K / 90K | 2,000 / 800K / 160K | 4,000 / 2M / 400K |
| Haiku 4.5 | 50 / 50K / 10K | 1,000 / 450K / 90K | 2,000 / 1M / 200K | 4,000 / 4M / 800K |
티어 간 이동을 위해서는 누적 크레딧 구매가 필요합니다: Tier 1에 $5, Tier 2에 $40, Tier 3에 $200, Tier 4에 $400. 각 티어에는 월간 지출 한도도 있습니다 — 각각 $100, $500, $1,000, $200,000 — 이는 별도의 안전장치로 작동합니다.
Anthropic 속도 제한에서 가장 강력하지만 가장 잘 알려지지 않은 기능 중 하나가 캐시 인식 ITPM입니다. 대부분의 현재 모델에서 캐시된 입력 토큰은 ITPM 속도 제한에 포함되지 않습니다. 즉, 프롬프트 캐싱을 효과적으로 활용하여 80%의 캐시 히트율을 달성하면, 분당 명목 토큰 한도의 5배를 효과적으로 처리할 수 있습니다. Tier 4 ITPM 한도 2,000,000의 경우, 캐싱이 최적화되면 분당 총 10,000,000개의 입력 토큰을 효과적으로 처리할 수 있습니다. 자세한 구현 가이드는 Claude API 프롬프트 캐싱 가이드를 참조하세요.
토큰 버킷 알고리즘은 버스트 동작에 영향을 미치므로 특별한 주의가 필요합니다. 매분 리셋되는 단순 카운터와 달리, 토큰 버킷은 최대 한도까지 일정한 속도로 지속적으로 보충됩니다. 이는 60 RPM 속도가 대략 초당 1 요청으로 적용될 수 있음을 의미합니다. 이 순간 속도를 초과하는 짧은 버스트는 전체 분에 대한 평균 사용량이 한도 이내라도 429 오류를 트리거할 수 있습니다. 루프에서 연속으로 빠르게 요청을 보내는 개발자는 이 동작에 특히 쉽게 마주칩니다.
속도 제한은 API 키별이 아닌 조직 수준에서 적용됩니다. 조직에 동일한 API 계정을 공유하는 여러 프로젝트나 팀원이 있으면, 모든 요청이 같은 풀에서 인출됩니다. 이것이 개별 애플리케이션이 적당한 요청만 하고 있는 것처럼 보여도 429 오류가 나타날 수 있는 이유입니다 — 다른 팀원의 워크로드가 공유 용량을 소비하고 있을 수 있습니다. 팀을 위해 Anthropic은 워크스페이스 수준의 제한 구성을 제공합니다: 조직 관리자가 전체 용량의 일부를 각 워크스페이스에 할당하여, 단일 프로젝트가 전체 조직의 속도 제한 예산을 독점하는 것을 방지할 수 있습니다. 예를 들어, 조직이 Sonnet에 대해 Tier 3 한도 800,000 ITPM을 가지고 있다면, 프로덕션 워크스페이스에 500,000을, 개발에 300,000을 할당하여 개발 실험이 프로덕션 시스템을 굶기지 않도록 할 수 있습니다.
이러한 API 제한이 Claude Code 사용에 미치는 실질적 영향은 Claude Code의 구성 방식에 크게 좌우됩니다. Claude Code가 구독을 통해 운영될 때(Pro 및 Max 플랜의 기본값), Anthropic의 내부 인프라와 구독 할당량을 사용합니다 — API 티어 제한이 아닙니다. 그러나 Claude Code를 자체 API 키를 사용하도록 구성하면(환경 변수 또는 --api-key 플래그를 통해), 구독 할당량 대신 API 티어 제한을 사용합니다. 이 구분은 파워 유저에게 매우 중요합니다: 월 $200,000 지출 한도의 Tier 4 API 계정을 가지고 있다면, Claude Code를 API 키로 구성하는 것이 Max 20x 구독 플랜보다 훨씬 더 많은 처리량을 제공합니다. 단, 고정 월 요금 대신 토큰당 비용을 지불하게 됩니다.
또한 Anthropic이 최근 Opus 4.6에 대해 fast mode를 도입했으며, 이는 표준 Opus 한도와 별도의 전용 속도 제한이 있다는 점도 주목할 만합니다. fast mode의 리서치 프리뷰를 사용하고 있다면, 표준 Opus 할당과는 다른 속도 제한 오류를 만날 수 있습니다. fast mode의 응답 헤더는 표준 anthropic-ratelimit-* 헤더 대신 anthropic-fast-* 접두사가 붙은 헤더를 사용하므로, fast mode를 표준 추론과 함께 사용한다면 모니터링 코드에서 두 세트의 헤더를 모두 확인해야 합니다.
어떤 속도 제한에 걸렸는지 확인하는 방법
어떤 속도 제한 시스템이 여러분을 제한하고 있는지 정확히 진단하는 것이 올바른 해결책을 적용하기 위한 핵심적인 첫 번째 단계입니다. 증상이 충분히 다르기 때문에, 무엇을 찾아야 하는지 안다면 보통 몇 초 안에 원인을 파악할 수 있습니다.
구독 제한 지표는 비교적 비공식적입니다. Claude Code는 터미널에 "Usage limit reached" 또는 "You've run out of messages for now — please wait"와 같은 메시지를 표시합니다. 제한이 API 호출 전 애플리케이션 레이어에서 적용되기 때문에 HTTP 상태 코드는 없습니다. Claude.ai 웹 인터페이스에도 5시간 윈도우가 리셋되는 시점을 나타내는 카운트다운 타이머가 표시될 수 있으며, 할당량이 공유되므로 이 타이머는 Claude Code에도 동일하게 적용됩니다.
API 속도 제한 지표는 정확하고 기계 판독 가능합니다. 어떤 제한이 초과되었는지(요청, 입력 토큰, 또는 출력 토큰)를 명시하는 JSON 오류 본문과 함께 HTTP 429 응답을 받게 됩니다. 응답에는 정확히 몇 초를 대기해야 하는지 알려주는 retry-after 헤더가 포함됩니다. 또한 모든 성공적인 API 응답에는 잔여 용량을 실시간으로 모니터링할 수 있는 속도 제한 헤더 세트가 포함됩니다:
pythonimport anthropic client = anthropic.Anthropic() try: response = client.messages.create( model="claude-sonnet-4-6-20250514", max_tokens=1024, messages=[{"role": "user", "content": "Hello"}] ) # 응답 헤더에서 잔여 용량 확인 print(f"Requests remaining: {response.headers.get('anthropic-ratelimit-requests-remaining')}") print(f"Input tokens remaining: {response.headers.get('anthropic-ratelimit-input-tokens-remaining')}") print(f"Output tokens remaining: {response.headers.get('anthropic-ratelimit-output-tokens-remaining')}") print(f"Reset time: {response.headers.get('anthropic-ratelimit-requests-reset')}") except anthropic.RateLimitError as e: print(f"Rate limited! Retry after: {e.response.headers.get('retry-after')} seconds") print(f"Error details: {e.message}")
이해할 가치가 있는 세 번째, 덜 일반적인 시나리오가 있습니다: 가속 제한(acceleration limits). 명목상의 RPM 및 TPM 상한 이내더라도, Anthropic API는 사용량의 급격한 스파이크를 제재하는 가속 제한을 적용합니다. 조직의 트래픽이 짧은 시간 내에 크게 증가하면 — 예를 들어 몇 분 안에 0개에서 수백 개의 요청으로 — 공개된 속도 제한에 도달하기 전에 429 오류를 받을 수 있습니다. 해결책은 요청을 폭발적으로 보내는 대신 트래픽을 점진적으로 늘리는 것입니다. 이 동작은 빌드 프로세스 시작 시 여러 Claude Code 인스턴스를 동시에 실행하는 CI/CD 파이프라인에 특히 관련이 있습니다.
구독 제한인지 API 제한인지 확실하지 않다면, 다음 세 가지 신호를 순서대로 확인하세요. 첫째, 오류 형식을 확인합니다 — Claude Code 터미널에서 구조화된 HTTP 오류가 아닌 대화형 메시지라면 구독 제한입니다. 둘째, Claude.ai 웹 인터페이스를 확인합니다 — 여기에도 사용량 제한 배너가 표시되면 구독 할당량이 소진된 것입니다. 셋째, API 응답 헤더를 확인합니다 — 잔여 토큰이나 요청이 0이면 API 속도 제한에 걸린 것입니다. 429 오류에 대한 더 많은 트러블슈팅 패턴은 Claude API 429 속도 제한 오류 해결 가이드에서 추가적인 엣지 케이스를 다룹니다.
"Rate Limit Reached" 오류를 해결하는 8가지 검증된 방법
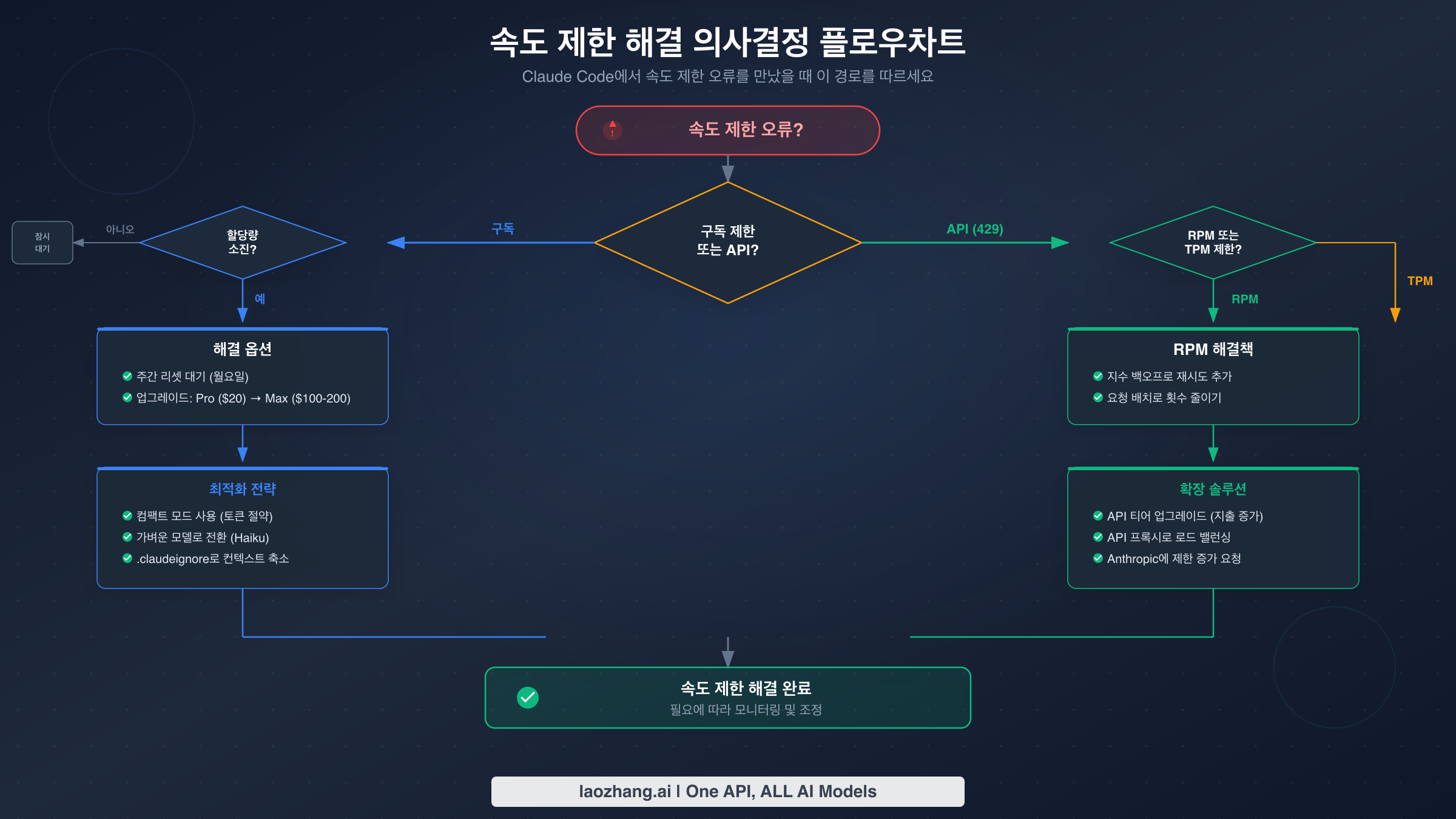
속도 제한에 걸렸을 때, 올바른 해결책은 어떤 시스템이 이를 트리거했는지와 작업 재개가 얼마나 급한지에 따라 달라집니다. 다음은 가장 빠른 임시 해결책부터 가장 지속 가능한 장기 솔루션까지 정리한 8가지 전략입니다.
해결책 1: 롤링 윈도우 리셋을 기다리세요. 구독 제한의 경우, 5시간 롤링 윈도우는 오래된 사용량이 만료됨에 따라 용량이 점진적으로 돌아온다는 의미입니다. 전체 5시간을 기다릴 필요는 없습니다 — 30~60분의 비활성 시간만으로도 몇 번의 추가 상호작용에 충분한 할당량이 확보되는 경우가 많습니다. API 속도 제한의 경우, 토큰 버킷이 지속적으로 보충되므로 retry-after 헤더에 명시된 초만큼만 기다리면 보통 충분합니다.
해결책 2: 더 가벼운 모델로 전환하세요. Opus 4.6을 사용하다가 구독 제한에 걸렸다면, /model 명령으로 Sonnet 4.6으로 전환하면 같은 잔여 할당량으로 약 5배 더 많은 상호작용이 가능합니다. Sonnet은 대부분의 코딩 작업을 효과적으로 처리하며, 파일 편집, 테스트 작성, 코드 탐색 같은 일상적인 작업에서 품질 차이는 미미합니다. 복잡한 아키텍처 결정이나 미묘한 버그 추적처럼 더 깊은 추론이 정말 필요한 작업에만 Opus를 예약하세요.
해결책 3: 대화 컨텍스트 크기를 줄이세요. Claude Code는 시스템 프롬프트, 대화 기록, 파일 내용, 도구 사용 토큰을 모든 요청에 번들로 포함합니다. /clear로 새 대화를 시작하거나 Claude Code를 닫았다 다시 열면, 각 요청의 크기를 부풀리는 축적된 기록 토큰이 제거됩니다. 컨텍스트에 가져오는 파일에 대해 전략적으로 생각하세요 — 특정 파일 몇 개만 필요할 때 전체 디렉토리를 로드하지 마세요.
해결책 4: API 제한에 대해 지수 백오프를 구현하세요. 프로그래밍 방식의 API 접근에서 지터가 포함된 지수 백오프는 업계 표준 접근법입니다. 다음은 프로덕션에 바로 사용할 수 있는 구현입니다:
pythonimport time import random import anthropic def call_with_backoff(client, max_retries=5, **kwargs): """속도 제한 오류 시 지수 백오프로 Anthropic API를 호출합니다.""" for attempt in range(max_retries): try: return client.messages.create(**kwargs) except anthropic.RateLimitError as e: retry_after = int(e.response.headers.get("retry-after", 2 ** attempt)) wait_time = retry_after + random.uniform(0, 1) print(f"Rate limited. Waiting {wait_time:.1f}s (attempt {attempt + 1}/{max_retries})") time.sleep(wait_time) raise Exception(f"Failed after {max_retries} retries") client = anthropic.Anthropic() response = call_with_backoff( client, model="claude-sonnet-4-6-20250514", max_tokens=2048, messages=[{"role": "user", "content": "Analyze this code for bugs..."}] )
해결책 5: 프롬프트 캐싱을 활성화하고 최적화하세요. 대부분의 현재 Claude 모델에서 캐시된 입력 토큰은 ITPM 제한에 포함되지 않으므로, 효과적인 캐싱은 실질적인 처리량을 5배 이상 높일 수 있습니다. 시스템 지침, 대용량 컨텍스트 문서, 도구 정의를 캐시 제어 중단점과 함께 메시지 시작 부분에 배치하세요. Claude Console의 Usage 페이지에서 캐시 히트율을 모니터링하고 70% 이상을 목표로 하세요.
해결책 6: 여러 모델 엔드포인트에 요청을 분산하세요. API 속도 제한이 각 모델 클래스에 별도로 적용되므로, Sonnet과 Haiku를 각각의 제한까지 동시에 사용할 수 있습니다. 코드 포매팅, 문서 생성, 기본 완성 같은 간단한 작업은 Haiku 4.5로 라우팅하고, 더 복잡한 추론 작업은 Sonnet 4.6에 예약하세요. 이렇게 하면 티어 업그레이드 없이 총 처리량을 두세 배로 높일 수 있습니다.
해결책 7: 플랜 또는 API 티어를 업그레이드하세요. 지속적으로 제한에 걸린다면, 업그레이드가 가장 비용 효율적인 해결책일 수 있습니다. Pro($20/월)에서 Max 5x($100/월)로 이동하면 구독 할당량이 5배 늘어나고 Opus에 접근할 수 있습니다. API 측에서는 Tier 1에서 Tier 2로 이동하는 데 누적 $40의 크레딧 구매만 필요하지만, RPM이 20배(50 → 1,000), Sonnet의 ITPM이 15배(30K → 450K) 증가합니다.
해결책 8: 서드파티 API 서비스를 통해 라우팅하세요. 구독 제한에 자주 걸리면서 티어 진급 관리 없이 API 수준의 유연성을 원하는 개발자에게, 서드파티 API 라우팅 서비스는 대안적인 경로를 제공합니다. laozhang.ai와 같은 서비스는 분당 속도 제한 없이 소비한 토큰당 과금하는 OpenAI 호환 엔드포인트를 통해 Claude 모델에 접근할 수 있게 합니다. 이 접근법은 Claude Code 구독 대신 직접 API 호출을 하므로 구독 할당량을 완전히 우회하며, 라우팅 서비스가 여러 API 키에 걸쳐 로드 밸런싱을 처리하여 조직별 제한을 피합니다.
서드파티 API 라우팅을 활용한 구독 제한 우회
구독 할당량이 지속적인 병목이 될 때, Claude Code를 서드파티 API 엔드포인트로 구성하면 경험이 근본적으로 달라질 수 있습니다. 집중적인 코딩 세션에서 소진되는 고정 월간 할당량 대신, 실제로 소비한 토큰에 대해서만 비용을 지불합니다. 이는 효과적 한도가 임의적인 사용량 상한이 아닌 여러분의 예산이 된다는 것을 의미합니다.
핵심 아이디어는 간단합니다: Claude Code는 Anthropic Messages API 형식을 구현하는 모든 엔드포인트로 API 요청을 보내도록 구성할 수 있습니다. laozhang.ai와 같은 서드파티 라우팅 서비스는 이러한 요청을 수락하고, Anthropic의 인프라(또는 동등한 모델 제공자)로 전달하며, 직접 API 가격에 준하는 토큰당 요금을 청구합니다. 이러한 서비스는 일반적으로 여러 조직에 걸친 API 키 풀을 유지하므로, 개별 개발자를 제약하는 조직별 속도 제한이 훨씬 더 큰 용량 풀에 분산됩니다.
다음은 라우팅 서비스를 사용할 수 없을 때 공식 API로 자동 폴백하도록 Claude Code를 대체 API 엔드포인트로 구성하는 방법입니다:
pythonimport os import anthropic # Fallback: 직접 Anthropic API (티어 속도 제한 적용) ENDPOINTS = [ { "base_url": "https://api.laozhang.ai/v1", "api_key": os.environ.get("LAOZHANG_API_KEY"), "name": "laozhang.ai routing" }, { "base_url": "https://api.anthropic.com", "api_key": os.environ.get("ANTHROPIC_API_KEY"), "name": "Anthropic direct" } ] def create_message_with_fallback(messages, model="claude-sonnet-4-6-20250514", max_tokens=4096): """각 엔드포인트를 순서대로 시도하고, 속도 제한 시 폴백합니다.""" for endpoint in ENDPOINTS: if not endpoint["api_key"]: continue try: client = anthropic.Anthropic( base_url=endpoint["base_url"], api_key=endpoint["api_key"] ) response = client.messages.create( model=model, max_tokens=max_tokens, messages=messages ) print(f"Success via {endpoint['name']}") return response except anthropic.RateLimitError: print(f"Rate limited on {endpoint['name']}, trying next...") continue except Exception as e: print(f"Error on {endpoint['name']}: {e}, trying next...") continue raise Exception("All endpoints exhausted")
Claude Code CLI에서 특별히 사용하려면, 세션 시작 전에 환경 변수 ANTHROPIC_BASE_URL을 라우팅 서비스를 가리키도록 설정할 수 있습니다. 이렇게 하면 구성 파일을 수정하지 않고도 Claude Code의 모든 API 호출이 대체 엔드포인트를 통해 리디렉션됩니다. 트레이드오프는 비용 투명성입니다 — 예측 가능한 월 구독료 상한에 의존하는 대신 토큰당 지출을 수동으로 모니터링해야 합니다.
이 접근법은 예측 불가능한 사용 패턴을 가진 개발자에게 가장 적합합니다: 어떤 날은 Claude Code를 거의 사용하지 않고, 다른 날은 8시간 동안 집중적인 페어 프로그래밍 세션을 합니다. 토큰당 과금 모델은 조용한 날에 돈을 낭비하거나 바쁜 날에 속도 제한에 걸리는 티어에 강제되는 대신 실제 소비에 비용을 맞출 수 있게 합니다.
서드파티 라우팅 서비스를 평가할 때 고려해야 할 중요한 사항이 있습니다. 첫째, 서비스가 필요한 특정 Claude 모델을 지원하는지 확인하세요 — 일부 라우팅 제공자는 Sonnet만 제공하고, 다른 제공자는 Opus와 Haiku를 포함한 전체 모델 라인업을 제공합니다. 둘째, 지연 시간의 영향을 이해하세요 — 중개자를 통한 라우팅은 요청당 50~200ms의 소량의 네트워크 오버헤드를 추가하며, 이는 Claude Code의 인터랙티브 워크플로우에서는 무시할 수 있지만 지연 시간에 민감한 배치 처리에서는 알아둘 가치가 있습니다. 셋째, 서비스가 Claude Code의 실시간 출력 표시에 의존하는 스트리밍 응답을 지원하는지 확인하세요. 넷째, 가격을 신중하게 평가하세요 — 토큰당 비용은 직접 API 가격과 비슷할 수 있지만, 일부 서비스는 마크업을 추가하거나 최소 월 요금을 부과합니다. 최고의 라우팅 서비스는 Anthropic의 공식 요금을 따르면서도 풀링된 속도 제한과 여러 API 조직 간 자동 페일오버라는 추가 혜택을 제공하는 투명한 토큰당 가격을 제공합니다.
이 접근법을 대규모로 검토하는 팀의 경우, 1주일 동안 비교를 실행할 가치가 있습니다: 현재 플랜에서의 실제 토큰 소비량을 추적하고, 같은 사용량이 라우팅 서비스를 통해 얼마에 해당하는지 계산하며, 금전적 비용과 속도 제한에 걸리지 않는 것의 생산성 영향을 모두 비교하세요. 많은 팀이 토큰 비용은 구독과 비슷하지만, 속도 제한 중단의 제거가 전환을 정당화하는 측정 가능한 생산성 향상을 가져온다는 것을 발견합니다.
대량 Claude Code 사용자를 위한 예방 전략
속도 제한을 처리하는 가장 효과적인 방법은 애초에 걸리지 않는 것입니다. 이 전략들은 수천 번의 Claude Code 세션에서 관찰된 패턴과 Claude Code 공식 문서의 권장 사항에서 도출되었습니다.
전략 1: 최소한의 컨텍스트 팽창을 위해 대화를 구조화하세요. 모든 Claude Code 상호작용은 축적된 대화 기록을 이어가므로, 각 교환마다 토큰 소비가 증가합니다. 마라톤 세션을 하기보다 자주 새 대화를 시작하세요. 긴 작업에서 컨텍스트를 유지해야 할 때는 /compact 명령을 사용하여 대화 기록을 요약하고 압축하세요. Claude Code가 읽어야 하는 파일에 대해 명시적이어야 합니다 — 특정 파일 세 개만 필요할 때 "src 디렉토리 전체를 봐줘" 같은 광범위한 명령은 피하세요.
전략 2: 모델 라우팅을 전략적으로 사용하세요. 모든 작업에 가장 강력한 모델이 필요한 것은 아닙니다. 정신적 분류 체계를 만드세요: 빠른 파일 검색, 포매팅, 간단한 편집에는 Haiku를; 표준 코딩 작업, 디버깅, 테스트 생성에는 Sonnet을; Sonnet이 일관되게 틀리는 작업이나 복잡한 아키텍처 추론, 미묘한 버그에만 Opus를 사용하세요. Max 플랜에서는 Opus 소비량을 주시하고 자동 다운그레이드 임계값이 작동하기 전에 자발적으로 Sonnet으로 전환하세요 — 자발적 전환은 타이밍을 제어할 수 있지만, 자동 다운그레이드는 워크플로우 중간에 발생합니다.
전략 3: 관련 작업을 배치로 처리하세요. 5개 파일을 편집하기 위해 5개의 별도 요청을 보내는 대신, 하나의 프롬프트에 5개 편집 내용을 모두 설명하세요. Claude Code는 다중 파일 작업을 효율적으로 처리하며, 각 배치는 구독 할당량에 대해 5개가 아닌 1개의 상호작용으로 카운트됩니다. 마찬가지로, 코드를 리뷰할 때는 하나씩 보내지 말고 모든 질문을 하나의 프롬프트에서 물어보세요. 이 접근법은 Claude가 각 질문을 고립되어 답하는 대신 질문 간의 관계를 고려할 수 있으므로 더 나은 결과를 제공합니다.
전략 4: 사용량을 사전에 모니터링하세요. API 사용의 경우, 매 응답의 속도 제한 헤더를 확인하여 벽에 부딪히기 전 얼마나 많은 용량이 남아 있는지 확인하세요. 구독 할당량의 경우, Claude.ai 인터페이스가 현재 사용량 수준을 보여줍니다. 일부 개발자는 API 소비 패턴을 추적하고 사용량이 티어 한도의 70%에 도달하면 알림을 보내는 간단한 대시보드를 구축하여, 중단 전에 워크플로우를 조정할 시간을 확보합니다. Claude Console Usage 페이지는 시간당 최대 토큰 사용률을 속도 제한 상한과 함께 보여주는 차트를 제공하며, 이는 소비 패턴을 이해하는 데 매우 유용합니다.
전략 5: 인프라 수준에서 프롬프트 캐싱을 구현하세요. Claude API 위에 애플리케이션을 구축하고 있다면, 프롬프트 캐싱을 사후 처리가 아닌 일급 아키텍처 관심사로 만드세요. 정적 콘텐츠(시스템 프롬프트, 도구 정의, 대용량 참조 문서)를 적절한 캐시 중단점과 함께 모든 요청의 시작 부분에 배치하세요. 80%의 캐시 히트율로 실질적인 ITPM 용량이 5배 증가하며, 이는 추가 비용 없이 2개 전체 티어를 업그레이드하는 것과 동등합니다. 높은 캐시 히트율을 달성하는 핵심은 요청 구조의 일관성입니다 — 시스템 프롬프트와 도구 정의가 요청 간에 동일하면 완벽하게 캐시됩니다. 접두사 콘텐츠의 작은 변경도 캐시를 무효화할 수 있으므로, 프롬프트 템플릿을 표준화하고 캐시 중단점을 전략적으로 사용하세요.
전략 6: 비피크 시간대에 무거운 워크로드를 스케줄링하세요. Anthropic이 공식적으로 시간대별 사용량 데이터를 공개하지는 않지만, 커뮤니티 관찰에 따르면 북미 비피크 시간대(태평양 시간 기준 대략 오전 2시~8시)에 속도 제한이 더 여유롭게 느껴진다고 일관되게 보고합니다. 이는 전체 플랫폼 부하가 낮아 토큰 버킷이 더 빠르게 보충되고 같은 인프라 용량을 놓고 경쟁하는 요청이 적기 때문일 가능성이 높습니다. 실시간 상호작용이 필요하지 않은 배치형 작업 — 문서 생성, Claude에 대한 대규모 테스트 스위트 실행, 코드 리뷰 처리 등 — 을 비피크 시간대로 스케줄링하면 속도 제한 중단의 빈도를 줄일 수 있습니다.
전략 7: 비인터랙티브 워크로드에는 Batch API를 사용하세요. 즉각적인 응답이 필요하지 않은 작업의 경우, Message Batches API는 실시간 API와 별도의 속도 제한을 가진 전용 경로를 제공합니다. 배치 요청은 Tier 1에서 최대 100,000개 항목(Tier 4에서 500,000개)을 큐에 넣을 수 있으며, 배치 처리는 표준 API 가격보다 50% 저렴합니다. 이는 코드베이스 전체 문서 생성, 대량 코드 리뷰, 데이터 추출 작업처럼 모든 요청을 한 번에 제출하고 나중에 결과를 수집할 수 있는 대량 작업에 이상적입니다. 배치 큐 제한은 대부분의 개발자가 이에 도달하지 않을 만큼 넉넉하여, 비동기 작업에 대해 사실상 무제한 처리량을 제공합니다.
자주 묻는 질문
사용량이 16%만 표시되는데 Max 플랜에서 왜 속도 제한에 걸리나요?
Claude 인터페이스에 표시되는 사용량 백분율은 전체 할당량 소비를 측정하지만, 속도 제한은 더 짧은 시간 윈도우 내의 버스트 패턴에 의해서도 트리거될 수 있습니다. 복잡한 요청을 빠르게 연속으로 보내면, 전체 5시간 할당량에 여유가 있어도 분당 처리량 제한을 초과할 수 있습니다. 또한, Opus 4.6은 상호작용당 Sonnet 4.6보다 약 5배 많은 리소스를 소비하므로, Opus에만 사용된 Max 5x 할당량의 16%는 백분율이 시사하는 것보다 훨씬 더 많은 토큰 교환을 나타냅니다. 사용량 미터가 백분율을 계산하는 방식에 대한 일반적인 오해도 있습니다 — 모델 복잡도를 고려한 가중 평균을 반영하므로, 10개의 Opus 대화가 16%를 표시하면서도 80개의 Sonnet 대화와 동일한 원시 컴퓨팅을 소비할 수 있습니다.
구독 제한과 API 제한의 차이점은 무엇인가요?
구독 제한은 Claude Pro 또는 Max 플랜의 일부이며, 5시간 롤링 윈도우에 걸쳐 적용되고, Claude.ai와 Claude Code 간에 공유되며, 대화형 "사용량 한도에 도달했습니다" 메시지를 생성합니다. API 속도 제한은 조직의 지출 티어(누적 $5~$400+ 구매)에 연결되고, 분당 RPM/ITPM/OTPM으로 측정되며, 구조화된 헤더와 함께 HTTP 429를 반환하고, 직접 API 호출에만 적용됩니다. 두 시스템은 완전히 독립적이어서, 한쪽을 소진하면서 다른 쪽에는 완전한 용량이 있을 수 있습니다. 구독 제한은 방문자 상한이 있는 월 체육관 회원권으로, API 제한은 입장 속도 제한이 있는 사용당 과금 시설로 생각하면 됩니다.
대화 기록을 지우면 속도 제한에 도움이 되나요?
향후 요청에 대해서는 네 — /clear로 기록을 지우면 각 API 호출에 번들되는 컨텍스트가 줄어들어 후속 상호작용의 토큰 소비가 감소합니다. 그러나 이미 소비된 할당량을 소급해서 복원하지는 않습니다. 이전 교환에서 사용된 토큰은 이미 한도에 대해 카운트되었습니다. 기록 지우기는 소급 수정이 아닌 예방 전략입니다. 그렇지만 영향은 상당할 수 있습니다: 50개의 주고받은 대화가 있는 세션은 이후 모든 요청에 100,000개 이상의 토큰 기록을 포함할 수 있습니다. 해당 기록을 지우고 새로 시작하면 요청당 토큰 소비를 80% 이상 줄일 수 있으며, 이는 이후의 할당량 소진 속도를 직접적으로 늦추는 효과가 있습니다.
다른 API 엔드포인트를 사용하여 제한을 피할 수 있나요?
네. ANTHROPIC_BASE_URL을 서드파티 라우팅 서비스로 설정하면 Claude Code의 API 호출이 다른 속도 제한 정책을 가진 대체 엔드포인트를 통해 리디렉션됩니다. laozhang.ai와 같은 서비스는 여러 API 조직에 걸쳐 용량을 풀링하여, 개별 Tier 1 또는 Tier 2 계정보다 효과적으로 더 높은 분당 처리량을 제공합니다. 트레이드오프는 고정 월간 할당량 대신 소비한 토큰당 비용을 지불한다는 것입니다. 이 접근법은 일별 사용량 변동이 극심한 개발자에게 특히 유용합니다 — 어떤 날은 사용량 제로, 다른 날은 12시간 마라톤 세션 — 토큰당 과금 모델이 피크 일을 위한 구독 여유를 요구하는 대신 실제 소비에 비용을 맞추기 때문입니다.
속도 제한 리셋에는 얼마나 걸리나요?
구독 할당량의 경우, 5시간 롤링 윈도우는 오래된 상호작용이 만료됨에 따라 용량이 점진적으로 돌아온다는 의미입니다 — 전체 5시간을 기다릴 필요가 없습니다. 실제로, 대부분의 사용자는 3060분의 비활성 시간이 몇 번의 추가 상호작용에 충분한 할당량을 확보하며, 가벼운 모델은 처음에 덜 소비했으므로 할당량이 더 빠르게 복구됩니다. API 속도 제한의 경우, 토큰 버킷이 지속적으로 보충됩니다. 429 응답의 60초 범위입니다. 가속 제한(갑작스러운 사용량 스파이크로 트리거됨)은 수 분의 더 긴 쿨다운 기간이 필요할 수 있습니다.retry-after 헤더가 정확히 몇 초를 기다려야 하는지 알려주며, 일반적으로 제한을 얼마나 초과했는지에 따라 1
한도에 도달하기 전에 현재 사용량을 확인하는 방법이 있나요?
API 사용의 경우, 모든 성공적인 요청의 응답 헤더를 확인하세요 — anthropic-ratelimit-requests-remaining, anthropic-ratelimit-input-tokens-remaining, anthropic-ratelimit-output-tokens-remaining이 정확히 얼마나 많은 용량이 남아 있는지 알려줍니다. Claude Console의 Usage 페이지는 피크 소비율을 속도 제한 상한과 함께 보여주는 이력 차트를 제공하여, 패턴을 이해하고 용량 필요를 계획하는 데 도움이 됩니다. 구독 할당량의 경우, Claude.ai 웹 인터페이스가 사용량 표시기를 보여주지만, API 헤더보다 업데이트가 덜 빈번합니다. 일부 개발자는 모든 API 호출 후 이러한 헤더 값을 로깅하는 경량 모니터링 스크립트를 구축하여, 잔여 용량이 한도의 20% 이하로 떨어질 때 알림을 보내는 조기 경보 시스템을 만듭니다.