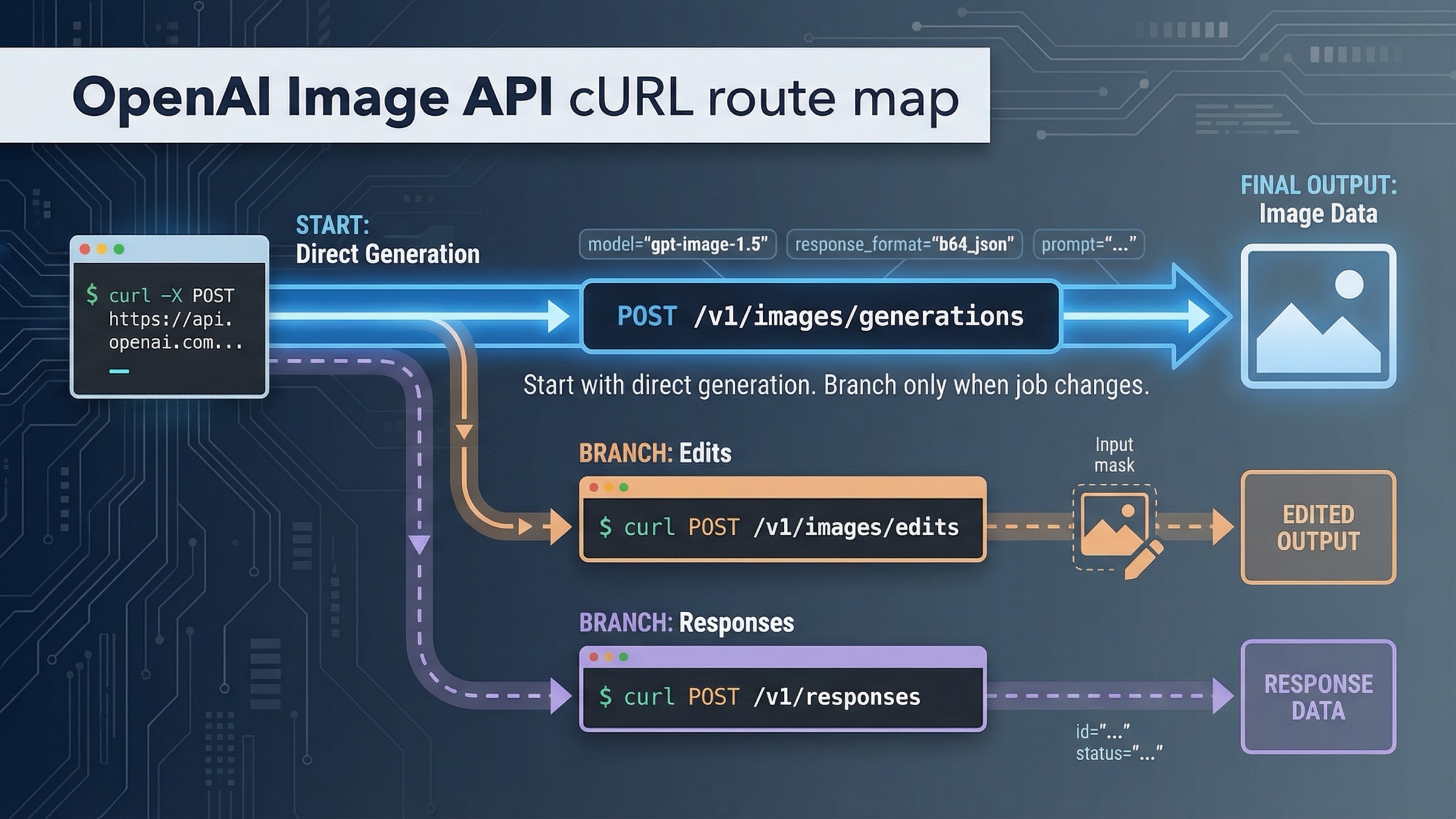
OpenAI image generation API cURL の現在の正解を短く言うと、まずは POST /v1/images/generations から始め、返ってきた JSON を保存し、.data[0].b64_json を明示的にデコードしてファイルにすることです。単発の prompt-to-image を shell や backend smoke test で確認したいなら、今でもこれが最も安全で壊れにくいスタート地点です。
この default を変えるべき場面は 2 つしかありません。すでに入力画像があり、その画像を編集したいなら POST /v1/images/edits に進みます。画像生成がより大きな multimodal workflow の一部であり、tool orchestration 自体が主題なら POST /v1/responses に進み、image_generation tool を使います。それ以外の複雑化は、たいてい最初の成功ループを不必要に遠回りさせます。
この query が必要以上に分かりにくく見える理由は、OpenAI が答えを複数のページに分散しているからです。image generation guide は全体のルートと主要パラメータを説明します。Images API reference は raw endpoint の契約を示します。Responses image_generation tool guide は別 surface の tool ルートを説明します。そして 2026年3月24日 の時点でも、guide には https://api.openai.com/v1/images を使う GPT Image cURL 断片が残っている一方、reference は /images/generations と /images/edits を raw route として明記しています。このページはそのずれを、実際に動く operator workflow に組み直すためにあります。
要点まとめ
- 最初の cURL テストは
POST /v1/images/generationsとgpt-image-1.5で始める。 - GPT image models はデフォルトで
b64_jsonを返し、hosted image URL を前提にしない。 - 入力画像があるときだけ
POST /v1/images/editsに進む。 - 画像生成がより大きな tool workflow の一部であるときだけ
POST /v1/responsesに進む。
POST /v1/images/generations から始めて単発の画像生成を先に通す

やりたいことが「terminal から prompt を送り、1 枚の画像を返してもらう」なのであれば、今でも最初に使うべき surface は direct Images API です。公式の Images API reference は POST /images/generations を raw generation route として記載しているので、完全な URL は https://api.openai.com/v1/images/generations になります。
この route を最初に勧めるべき理由は、最初の成功ループを最小にできるからです。
- JSON を送る
- JSON を受け取る
- base64 を取り出す
- 画像ファイルとして保存する
さらに、これは現行の model lineup とも整合しています。公式の All models は GPT Image 1.5 を current state-of-the-art image generation model として列挙し、chatgpt-image-latest、gpt-image-1、gpt-image-1-mini を別の lane として並べています。したがって、新しい cURL 例の default は gpt-image-1.5 であるべきで、旧世代の mental model に引きずられるべきではありません。
最初に使うべき request は次のようなものです。
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Create a clean editorial illustration of a robot camera operator in a bright studio", "size": "1024x1024", "quality": "medium" }' > response.json
ここで重要なのは、最初の request を意図的に地味にしておくことです。公式 guide は、正方形画像が通常最も速く、1024x1024 が default size だと今でも説明しています。最初の 1 本で透明背景、横長構図、streaming partial images、圧縮形式、複数画像 edit まで同時に証明しようとすると、失敗したときの切り分けが難しくなります。最初の request で確認したいのは、account access、endpoint、payload shape、response shape、そして file output path だけです。
多くの読者が必要とする route split は、実際には次の表で十分です。
| 状況 | 最適な raw path | model の置き方 | それが default である理由 |
|---|---|---|---|
| テキスト prompt から 1 枚生成したい | POST /v1/images/generations | gpt-image-1.5 をそのまま使う | 最短で、最もデバッグしやすい |
| 既存画像を編集したい | POST /v1/images/edits | ここでも gpt-image-1.5 | 同じ Images API family だが request は multipart になる |
| 画像生成がより大きな assistant flow の一部 | POST /v1/responses + image_generation tool | top-level は gpt-5 のような text model | orchestration が本題のときだけ意味がある |
この表が重要なのは、SERP 上位の多くのページが generation、edits、Responses を 1 つの「image API example」として平坦に扱ってしまうからです。実際にはそうではありません。役割が違います。
もし次の疑問が「品質よりコストを優先したいならどうするか」であれば、現行カタログにある gpt-image-1-mini が budget lane になります。endpoint は同じでも、最初に benchmark すべき model は変わります。その判断を深めたい場合は、日本語版 OpenAI image generation API models を読む方が先です。
レスポンスが実際に返すものと安全なデコード手順

cURL で一番つまずきやすいのは、多くの場合 POST そのものではありません。問題は、その直後に何をするかです。
公式の Images API reference は Image object に b64_json、revised_prompt、url があると説明したうえで、shell 利用者にとって一番大事な注意も書いています。GPT image models では b64_json がデフォルトで返り、URL output を前提にしない という点です。だからこそ、良い cURL 記事は request body を示すだけでは不十分で、decode step まで閉じる必要があります。
一番安全な運用習慣は、まず生の response を保存することです。
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Create a clean editorial illustration of a robot camera operator in a bright studio", "size": "1024x1024", "quality": "medium" }' > response.json jq '.data[0] | {has_b64_json: has("b64_json"), revised_prompt, url}' response.json
この jq の確認は回り道ではありません。response shape を先に確認できるので、request 自体は成功しているのに最終ファイルが壊れる、といった問題を切り分けやすくなります。
Linux や GNU base64 がある環境なら、decode は短く書けます。
bashjq -r '.data[0].b64_json' response.json | base64 --decode > openai-image.png
macOS では通常 -D を使います。
bashjq -r '.data[0].b64_json' response.json | base64 -D > openai-image.png
GNU と BSD の違いを完全に避けたいなら、Python に任せる方が手堅いです。
bashjq -r '.data[0].b64_json' response.json \ | python -c 'import sys, base64; sys.stdout.buffer.write(base64.b64decode(sys.stdin.read()))' \ > openai-image.png
ここがまさに page one を上回れる部分です。弱い cURL 例は request を出すところまでで止まり、decode path を閉じません。あるいは author の環境でだけ動く base64 pipe を示し、読者に broken output file のデバッグを丸投げします。
もう 1 つ重要なのは、古い image API の mental model を引きずらないことです。昔のコンテンツでは .data[0].url を happy path の中心に置くものが多くありました。しかし現行の GPT image route はそうではありません。script がまだ .data[0].url を待っているなら、いまの API 世代とズレています。
guide と reference の不一致が実際の問題になるのもこの段階です。guide には /v1/images 断片が残っていても、raw contract としては /images/generations を anchor にした方が安全です。cURL-first の読者には、その方が実装として defend しやすいからです。
より広い language-by-language example が必要なら OpenAI image generation API example に進めば十分です。このページは、raw HTTP workflow を安定させることに集中しています。
既存画像があるときだけ multipart の POST /v1/images/edits に切り替える
すでに product image、brand asset、reference image があるなら、generation route を無理に編集チュートリアル化する必要はありません。正しい動きは surface を変えることではなく、direct Images API のまま edit branch に進むことです。
公式の Images API reference は POST /images/edits を raw edit endpoint として記載し、image generation guide には image[] を繰り返す multipart cURL example もあります。
形は次のようになります。
bashcurl -s -D >(grep -i x-request-id >&2) \ -o >(jq -r '.data[0].b64_json' | base64 --decode > edited-image.png) \ -X POST "https://api.openai.com/v1/images/edits" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "image[]=@product-shot.png" \ -F "image[]=@logo.png" \ -F 'prompt=Place the logo on the product box as if it were printed on the packaging.'
ここで一番覚えるべきことは 1 つです。generation は JSON、edits は multipart です。多くの 400 系エラーは、パラメータが変というより、編集 request を prompt-only generation と同じ JSON shape で送っていることから始まります。
もう 1 つの分岐は fidelity です。公式 guide は、gpt-image-1.5 を使う場合、最初の 5 枚の入力画像について input_fidelity=high を使うと preservation が強くなると説明しています。logo、顔、構図、ブランド要素の保持が重要な edit では、この option は意味があります。
raw cURL ではこうなります。
bashcurl -s \ -X POST "https://api.openai.com/v1/images/edits" \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "image[]=@woman.jpg" \ -F "image[]=@logo.png" \ -F "input_fidelity=high" \ -F 'prompt=Add the logo to the woman'\''s jacket as if stitched into the fabric.' \ > edit-response.json
ただし input_fidelity=high は常に足すべき「上位互換 option」ではありません。source image の保全が実際に重要なときだけ使うべきで、速度やコストを優先する loose transform では無理に入れる必要はありません。
この節で多くの tutorial が誤るのは、「より高度な image task だから Responses に行くべきだ」と暗に教えてしまう点です。これは違います。Editing は今でも direct Images API の一等ユースケースです。変わるのは request shape であって、surface そのものではありません。
編集に特化した深い説明が必要なら OpenAI image editing API を読む方が適切です。この query では、multipart edits に切り替える条件が明確になれば十分です。
画像生成がより大きな workflow の一部である場合だけ /v1/responses に進む
Responses image_generation tool guide が解いているのは、別の問題です。画像生成が 1 つの output ではなく、より大きな model interaction の中の tool になったとき、どう組むべきかを説明しています。
ここで大事なのは「Responses の方が新しい」ではなく、field の責務が変わる ことです。
guide は明示的に、GPT image models は Responses API の top-level model field に置かない と説明しています。/v1/responses を使うとき、top-level model は gpt-4.1 や gpt-5 のような text-capable model であり、image_generation tool が内部で image layer を扱います。
raw cURL は次のようになります。
bashcurl https://api.openai.com/v1/responses \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-5", "input": "Generate a transparent sticker-style icon of a paper airplane for a travel app", "tools": [ { "type": "image_generation", "background": "transparent", "quality": "high" } ] }' > responses-output.json jq -r '.output[] | select(.type=="image_generation_call") | .result' responses-output.json \ | python -c 'import sys, base64; sys.stdout.buffer.write(base64.b64decode(sys.stdin.read()))' \ > plane.png
この route が正しいのは、たとえば次のような場面です。
- 同じ request から text と image の両方が出る
- model が画像生成 tool を呼ぶかどうか判断する
- image output が assistant / agent flow の一部である
逆に、次のような場面では過剰です。
- 単に 1 枚生成したいだけ
- まず raw endpoint access を確認したい
- account state や model name や decode path の確認がまだ終わっていない
実務ルールは単純です。新しそうだからという理由だけで Responses から始めない。tool orchestration が仕事の本体のときにだけ Responses を使う。それ以外では、最初の成功ループをむしろ遠ざけます。
より広い tutorial が必要なら OpenAI image API tutorial を参照すれば十分です。このページでは Responses branch を意図的に狭く保っています。そうしないと default workflow が見えなくなるからです。
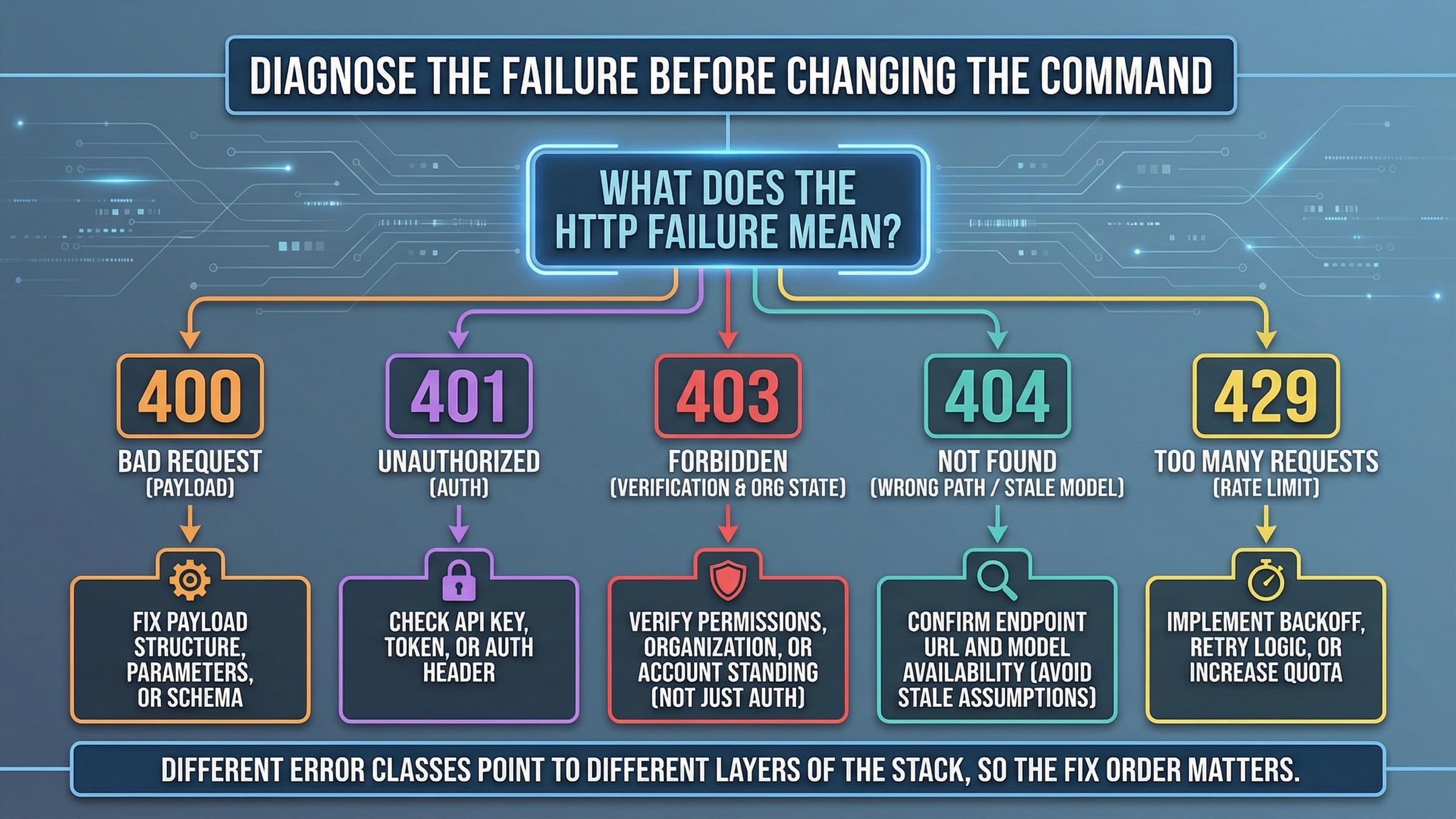
Troubleshooting: cURL の失敗で payload 問題と access 問題をどう見分けるか
この query で上位ページが一番弱くなりやすいのが、ここです。
cURL の例が失敗したとき、次に考えるべきなのは「どのパラメータをランダムに変えるか」ではありません。まず「どの failure class なのか」を見分ける必要があります。payload、key、organization state、model assumption、rate limit では fix order がまったく違うからです。
最初の見分けには次の表が役に立ちます。
| 見えている症状 | 典型的な意味 | 先に確認すべきこと |
|---|---|---|
400 Bad Request | JSON shape の誤り、Content-Type の誤り、または edits を JSON で送っている | endpoint、body format、-d と -F の使い分け |
401 Unauthorized | API key が無効、欠落、あるいは header に正しく入っていない | OPENAI_API_KEY、shell expansion、project key |
403 と verification / image-access wording | payload より account state の問題である可能性が高い | organization verification、active org、propagation、新しい key |
404 または model-not-found wording | path の誤り、古い model assumption、rollout 初期の snippet | endpoint path と model name の再確認 |
429 または rate-limit wording | malformed request ではなく throughput / tier の問題 | rate limits、usage tier、request volume や quality |
特に 403 はコードの問題に見えやすいので注意が必要です。公式の API Organization Verification は、verification が image generation capabilities を unlock し、not-verified wording が残る場合は 最大 30 分待つ、新しい API key を作る、セッションを更新する、正しい organization が active か確認する という順番を勧めています。これは optional cleanup ではなく、この failure class に対する最も価値の高い fix sequence です。
さらに、API Model Availability by Usage Tier and Verification Status には gpt-image-1 と gpt-image-1-mini は tiers 1 through 5 で利用可能だが、一部 access は organization verification に依存する とあります。したがって 403 や 429 を見たら、最初から JSON typo と決めつけるのは危険です。
404 は別の種類の時間差です。OpenAI の GPT-Image-1.5 rollout thread には、2025年12月16日 の rollout 初期に model does not exist が出ていた記録があります。これが、今でも古い snippet が SERP に残る理由を説明します。ただし、それを現在の default explanation にしてはいけません。今日の順番は、まず path、次に model name、その後に copied snippet の古さを疑う方が正しいです。
もう 1 つ見落とされがちな failure mode は、HTTP error ですらありません。200 OK なのに出力ファイルが空、または壊れている ケースです。この場合は API 自体ではなく、decode step が間違っていることが多いです。だからこそ response.json を残し、.data[0].b64_json の有無を明示的に確認する習慣が重要です。
また、公式 edit example が示しているように、可能なら request ID を出しておくと次の切り分けがかなり速くなります。
bashcurl -s -D >(grep -i x-request-id >&2) \ -o response.json \ https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Create a clean editorial illustration of a robot camera operator in a bright studio", "size": "1024x1024", "quality": "medium" }'
request ID は bad request を直してくれるわけではありませんが、problem が OpenAI 側か account state 側にあるときの次の行動をかなり短くします。
verification が blocker だと分かっているなら、次の読み先は OpenAI image generation API verification です。
最初の request が通ってから変えるべきパラメータ
base request が成功してからであれば、ようやく optimization に入れます。公式 guide と reference を合わせると、現時点で重要なのは次の knobs です。
size:1024x1024、1024x1536、1536x1024、またはautoquality:low、medium、high、またはautobackground:transparent、opaque、またはautooutput_format:png、webp、jpeg
ここでも一番大事なのは順番です。最初の request がまだ成功していないのに size、quality、output format、transparency を同時に変えると、access の問題なのか、payload shape の問題なのか、output handling の問題なのか、baseline が失われます。
多くの one-shot generation test では、次の default が安全です。
sizeは1024x1024qualityはmedium- 透明背景が本当に requirement でない限り
backgroundは default のまま - file-format optimization は route が証明された後
透明背景が必要であれば、その branch も current docs にあります。request を少し明示的にするだけです。
bashcurl https://api.openai.com/v1/images/generations \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-image-1.5", "prompt": "Draw a transparent sticker-style icon of a paper airplane for a travel app", "size": "1024x1024", "quality": "high", "background": "transparent", "output_format": "png" }' > transparent-response.json
転送サイズの方を優先したいなら、core path を確認したあとで jpeg や webp に寄せれば十分です。streaming や partial_images も current guide にはありますが、それは optimize-later feature であり、この query の main answer ではありません。
この話題では prompt tuning を最初の最適化にしたくなりがちですが、raw API workflow では順番が違います。より安全なのは次の順番です。
- endpoint と output path を証明する
- decode path を証明する
- 正しい route branch を証明する
- その後に quality、size、background、prompt detail を最適化する
次に気になるのが raw HTTP shape ではなく cost なら、日本語版 OpenAI image generation API pricing に進む方が自然です。価格は route が安定してからの方が判断しやすくなります。
最終提案
この query に対する一番短く安全な rule は次のとおりです。まず POST /v1/images/generations で始め、b64_json を明示的にデコードし、入力画像があるときだけ multipart の /v1/images/edits に進み、画像生成がより大きな tool-driven flow に入るときだけ /v1/responses に進む。
この rule が SERP 平均より強いのは、見栄えのする request snippet だけで終わらず、shell workflow 全体を閉じているからです。OpenAI の current docs が guide、reference、model pages、help pages に分かれている現実も踏まえています。強い cURL 記事に必要なのは、その分散した情報を 1 つの実装フローに縫い合わせ、読者が実際に動かせる形にすることです。