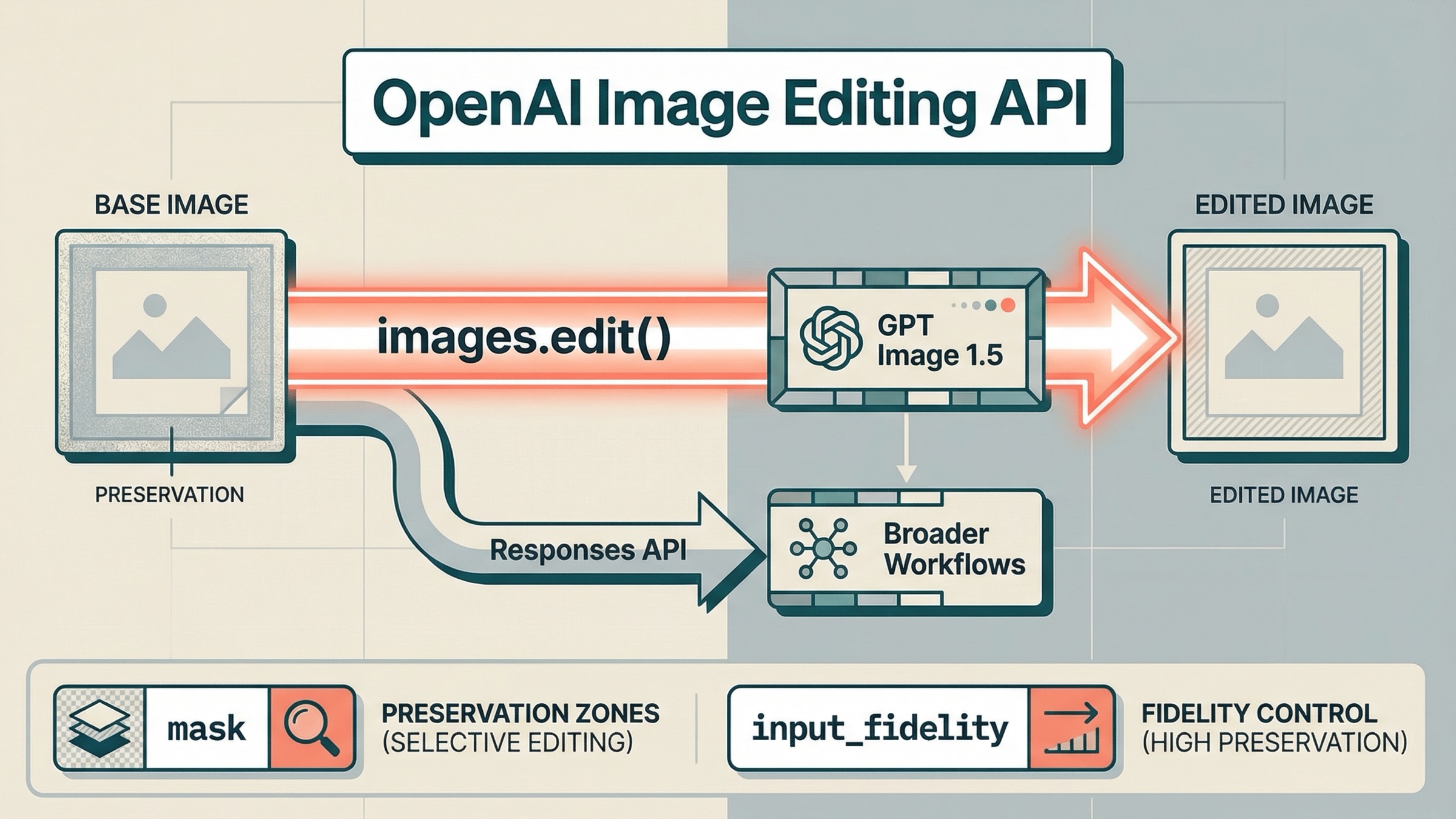
今日 OpenAI API で画像編集をしたいなら、2026年3月23日 時点の safest default はかなりはっきりしています。まずは direct な Images API と gpt-image-1.5 から始めることです。多くの edit-first task では、SDK なら client.images.edit()、HTTP なら POST /v1/images/edits が最短ルートになります。Responses API に移るのは、画像編集がより大きな会話、assistant、agent workflow の一部になる時です。
この判断が大事なのは、OpenAI の image docs がまだ複数ページに分かれているからです。メインの image generation guide は direct edit examples で gpt-image-1.5 を使っています。現在の GPT Image 1.5 page も、これを latest image generation model と位置づけています。ところが、より広い Images and vision guide には、latest image model が gpt-image-1 と書かれた古い文脈がまだ残っています。1ページだけ読むと code は合っていても routing が stale になりやすいのです。
さらに高くつく誤解があります。多くの開発者は “image editing API” と聞くと、Photoshop のような strict local patching を想像します。しかし current docs の書き方はもっと慎重です。OpenAI は prompt で最終的な画像全体を説明するよう求めています。これは erased area だけを書けばよい、という意味ではありません。Community threads を見ても、masked GPT Image edit が strict な pixel-only inpainting ではなく、より広い semantic rewrite に見えるという不満は今もあります。このページの目的は、その期待値を最初に正すことです。
要点まとめ
- OpenAI の直接画像編集は
images.edit()とgpt-image-1.5から始める。 - mask は「どこを重視するか」を伝えるためのもので、strict な pixel-boundary patch の保証ではない。
- 顔、logo、layout、brand visual の preservation が重要な時だけ
input_fidelity="high"を追加する。 - 編集が broader multimodal / agent workflow の一部になった時だけ Responses に移る。
まず覚えるべき current direct path
普通の edit workflow なら、最短で安全な mental model は次の通りです。
- 1枚以上の input image を渡す
- ほしい final result を説明する
- preservation controls は必要な時だけ付ける
- 返ってきた base64 image を保存する
現在の direct な JavaScript pattern はこうです。
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1.5", image: [fs.createReadStream("room.jpg")], prompt: "Replace the empty wall art with a framed abstract poster. Preserve the room layout, lighting, shadows, and all furniture. Do not change the camera angle.", input_fidelity: "high", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; const imageBuffer = Buffer.from(imageBase64, "base64"); fs.writeFileSync("room-edited.jpg", imageBuffer);
Python でも同じくらい straightforward です。
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.edit( model="gpt-image-1.5", image=[open("room.jpg", "rb")], prompt=( "Replace the empty wall art with a framed abstract poster. " "Preserve the room layout, lighting, shadows, and all furniture. " "Do not change the camera angle." ), input_fidelity="high", size="1024x1024", quality="medium", output_format="jpeg", output_compression=80, ) image_base64 = result.data[0].b64_json image_bytes = base64.b64decode(image_base64) with open("room-edited.jpg", "wb") as f: f.write(image_bytes)
raw HTTP で見るなら、重要なポイントはひとつです。image edits は JSON ではなく multipart form data です。
bashcurl https://api.openai.com/v1/images/edits \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -F "model=gpt-image-1.5" \ -F "image[]=@room.jpg" \ -F 'prompt=Replace the empty wall art with a framed abstract poster. Preserve the room layout, lighting, shadows, and all furniture. Do not change the camera angle.' \ -F "input_fidelity=high" \ -F "size=1024x1024" \ -F "quality=medium"
これが最良の starting point である理由は、workflow が明快だからです。現在の edit-capable model を選び、source image を渡し、final image を説明し、base64 output を受け取る。general reasoning model に “edit すべきか” を判断させる必要も、conversation state を最初から扱う必要もありません。
より広い API surface の整理が必要なら、日本語の OpenAI Image API tutorial が次の読み先です。このページは intentionally narrow に、image editing API の route だけを扱います。
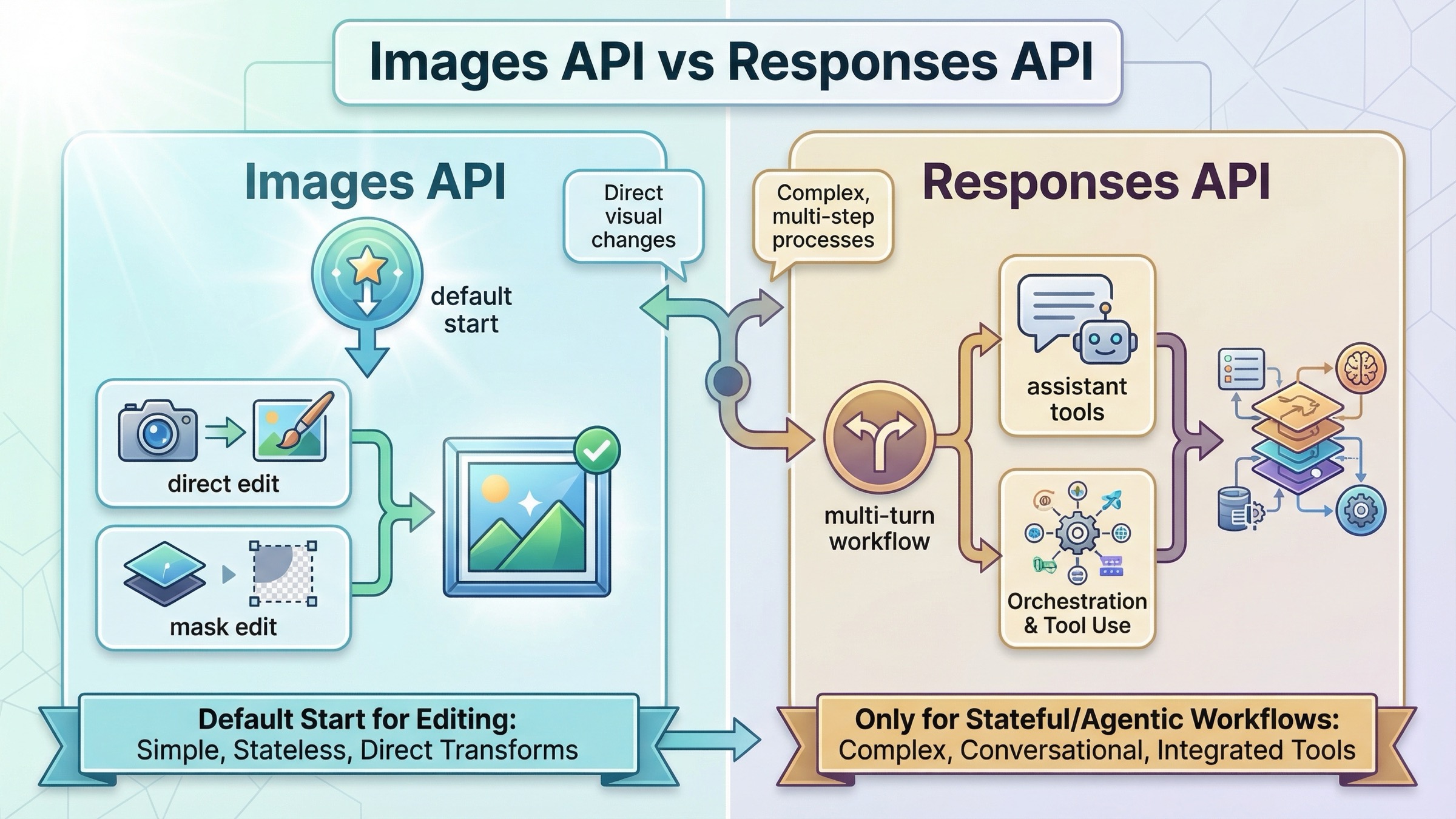
Images API と Responses はどちらを使うべきか
ここが今も page one で十分にクリアではない部分です。
| 状況 | 先に選ぶべき route | 理由 |
|---|---|---|
| 1枚または複数枚の source image を編集して保存したい | Images API | 最短の direct edit path で、request contract も追いやすい |
| 顔、logo、product shot を保ちながら要素を差し替えたい | Images API | input_fidelity=high と組み合わせた direct edit flow が最も分かりやすい |
| mask で編集対象の位置を誘導したい | Images API | mask input、multipart upload、output handling がすでに揃っている |
| 会話の中で前の出力を引き継いで edit を続けたい | Responses API | stateful な follow-up を管理しやすい |
| reasoning、tool use、image edits をまとめた assistant を作りたい | Responses API | 画像編集が larger workflow の one tool になるため |
一番大切なルールはこれです。Responses が新しそうに見えるからという理由だけで、最初からそちらを選ばないこと。 current tool guide は、Responses が broader hosted image-generation flow 用であることを明確にしています。しかも GPT Image model IDs は Responses API の top-level model には使えません。Responses では gpt-5 のような text-capable main model を置き、image generation / edit は hosted tool に担当させます。
つまり Responses は powerful ですが、同時に abstraction を選び間違えやすいのです。もし今日 ship したい feature が “画像を受け取り編集して返す endpoint” なら、まず direct Images API を通してください。multi-turn editing、conversation memory、other tools が本当に必要になった時に初めて Responses が自然な選択になります。
prompt の前に edit mode を見分ける
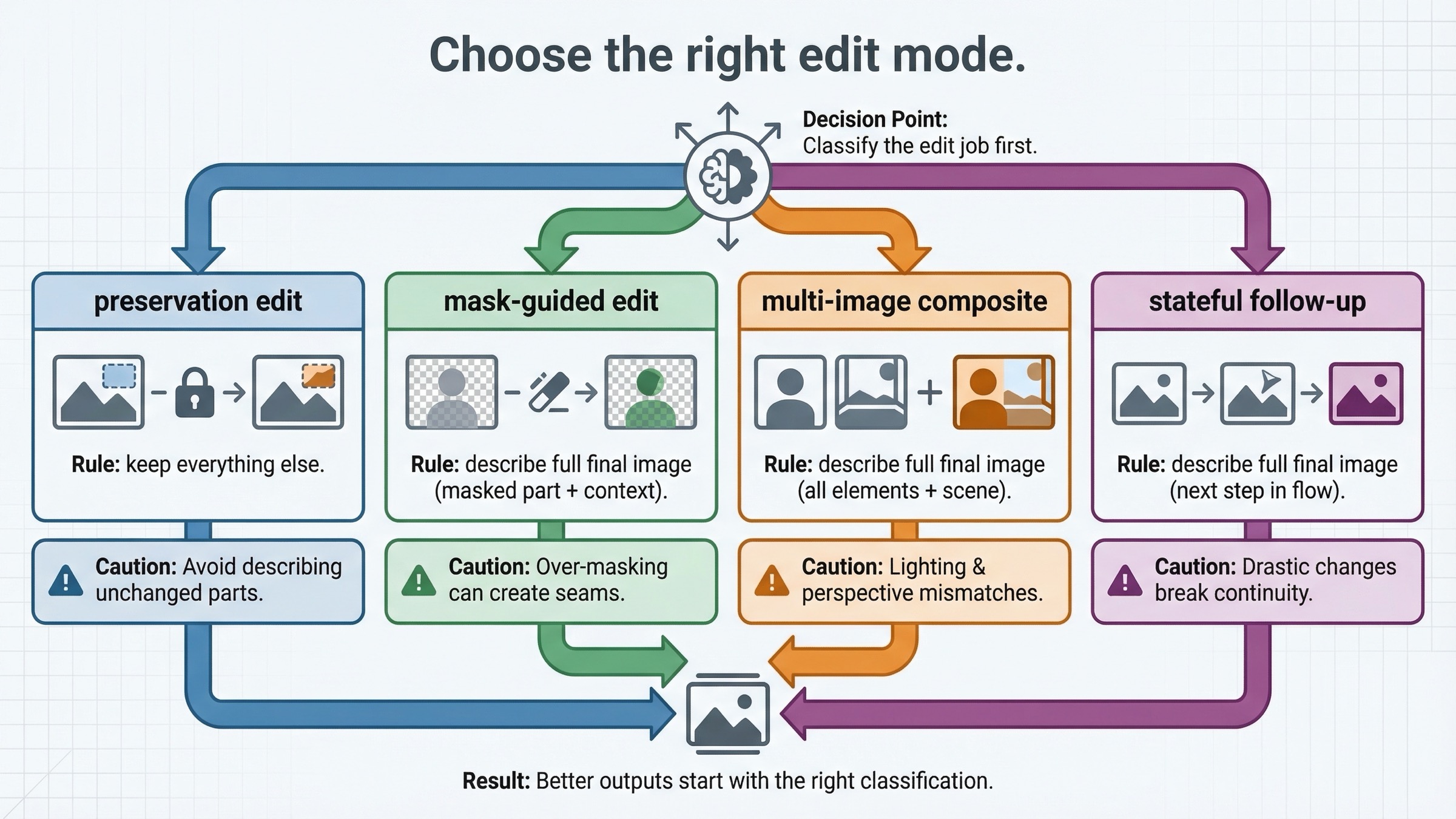
弱い tutorials は “image editing” をひとつの操作のように扱いがちですが、実際はそうではありません。まず どの種類の edit なのか を決めてから prompt を書いたほうが、結果はずっと安定します。
1つ目は preservation-heavy single-image edit です。欲しい scene はすでにあり、制御された変更だけを加えたい時です。服を変える、看板を足す、wall art を差し替える、邪魔なものを消す、object を軽く restyle する、composition を保ったまま mood を変える。こうした仕事では creativity より preservation が重要なので、input_fidelity="high" が効きやすいです。
2つ目は mask-guided edit。ここでは “何を変えるか” だけでなく “どこを重視するか” も伝えます。これは役に立ちますが、GPT Image を deterministic local patch tool に変えるわけではありません。mask は steering device であって、そこ以外が strict に untouched であることの保証ではありません。
3つ目は multi-image reference / compositing edit です。current guide と cookbook は、複数の input image を渡して、ある画像の要素を別の画像に持ち込む flow を示しています。たとえば:
- image 2 の logo を image 1 の shirt に置く
- image 2 の dog を image 1 の scene に入れる
- 同じ product を新しい environment に置き直す
4つ目は iterative follow-up editing。最初の出力がかなり近いが、さらに会話の流れの中で追い込みたい時です。ここでは direct one-off calls より、Responses の stateful flow のほうが扱いやすくなります。
この区別を早い段階で入れる理由は、mode ごとに prompt style が違うからです。preservation-heavy edit では “keep everything else” が重要になります。mask edit では final image 全体の説明と location guidance が必要です。multi-image composite では、どの input から何を取り、base image の何を保つかを明示する必要があります。
mask と input_fidelity は実際にどう効くのか

ここが、多くの読者が本当は知りたい部分です。
現在の image generation guide では、image と mask は同じ format と size でなければならず、payload は 50 MB 未満、さらに mask には alpha channel が必要 と説明されています。そして最も重要なのは、消した領域だけではなく、望む final image 全体を記述すること です。
この1行は API の理解を大きく変えます。モデルは単に穴を埋めているのではなく、source image、mask、prompt を合わせて読み、semantic に一貫した final output を組み立てています。
だから community complaints にも理由があります。OpenAI Developer Community の 2025年4月27日 のスレッドでは、masked edits が whole image regeneration のように感じられるという報告がありました。後の返信では、当時の gpt-image-1 について precise inpainting が known limitation だとする OpenAI Support の説明も引用されています。GPT Image 1.5 が preservation-heavy edits でより強くなっているのは確かですが、operational lesson は変わりません。masked workflow は semantic edit system として評価し、strict local surgery を前提にしない ことです。
input_fidelity="high" は、style や features をより注意深く保ちたい時に効きます。OpenAI は direct guide の logo placement でこれを使っていますし、Azure OpenAI の current edit guide も、subtle edits で facial features などを保つために high input fidelity が有効だと説明しています。向いているのは次のようなケースです。
- 背景だけ変えて product はそのまま残したい
- 服装だけ変えて顔の identity は保ちたい
- branded logo を object や garment に載せたい
- camera angle や composition を崩さず小さな scene adjustment をしたい
tradeoff は明快です。強い preservation effort は、ふつう cost と caution を増やします。もし task がそこまで preservation を要求していないなら、常に high fidelity を付ける意味はあまりありません。
より良い habit は次です。
- まずシンプルな direct edit を1回
- preservation が重要な時だけ
input_fidelity=high - location guidance が必要な時だけ mask
- prompt は final image、preserved elements、変える1〜2点に集中させる
最初の結果が close なら、すぐ giant prompt にしないことです。狭い follow-up correction のほうが制御しやすい場面が多いです。
Preservation-heavy な edits は小さく刻むほうが強い
現在の GPT Image 1.5 prompting guide が useful なのは、parameter list というより production advice に近いからです。translation、compositing、style preservation、scene changes のどれを見ても、共通しているのは explicit constraints と small iterative changes の強さです。
実際の product prompts でも、この考え方を持つべきです。
悪い edit prompt:
textMake this look better, more modern, cleaner, more premium, maybe add some flowers, maybe change the colors, and make it suitable for a landing page.
より良い preservation-first prompt:
textReplace only the poster on the wall with a framed abstract print. Preserve the room layout, furniture, lighting, floor shadows, and camera angle. Do not move or redesign any other object. Photorealistic interior photography.
より良い compositing prompt:
textPlace the logo from image 2 onto the front of the tote bag in image 1. Match the bag's fabric texture and lighting. Keep the model, pose, background, and camera framing unchanged.
より良い follow-up prompt:
textKeep the edited image exactly the same, but make the poster slightly larger and reduce glare on the frame. Do not change anything else.
最後の1文はとても重要です。元画像の価値が高いほど、style を追いかける prompt writer ではなく、state を守る operator のように考えるべきです。
だからこそ、OpenAI の 2025年12月16日 の release post も意味があります。OpenAI は GPT Image 1.5 を、branded logos、key visuals、facial consistency を保つ edits で GPT Image 1 より強い model として位置づけました。これは every prompt が完璧になるという約束ではありません。今はモデルの最低能力よりも、prompt discipline と sequencing の影響がより大きい、という意味です。
次に model-level の routing を確認したいなら、日本語の OpenAI image generation API models guide に進むのが自然です。
Troubleshooting: page one がまだ十分に触れていない failure points
1つ目は 最初から wrong API surface を選ぶこと。画像編集だけが必要なら、Responses workflow を組む必要はありませんし、top-level model に gpt-image-1.5 を入れるのも間違いです。まず direct Images API、その後に本当に broader workflow が必要なら Responses です。
2つ目は freshness の基準にする official page を間違えること。2026年3月23日 時点で GPT Image 1.5 page は latest image generation model と書いていますが、Images and vision guide には gpt-image-1 が latest と読める古い文脈が残っています。internal docs や blog が間違った page を anchor にすると、code が動いていても routing judgement が stale に見えます。
3つ目は raw edit endpoint に JSON を送ること。direct image edits は multipart form data です。curl や custom HTTP client で触る時、この detail は optional ではありません。
4つ目は mask を hard promise として扱うこと。もし workflow が “ごく小さな局所パッチで collateral changes はゼロ” を必要とするなら、その assumption は早い段階で test すべきです。docs に mask と書いてあること自体を guarantee と読んではいけません。
5つ目は changed object だけを書く prompt。OpenAI の current guide は、desired final image 全体を書くよう求めています。たとえば “add a beach ball” だけだと、他の要素をどう再解釈してよいかモデルに自由を与えすぎます。
6つ目は access と syntax を同じ問題だと思うこと。GPT Image 1.5 には current tier limits があり、model page でも Free not supported と明記されています。usable image が返る前に request が失敗するなら、prompt を直す前に access を確認してください。この branch が本当の blocker なら、日本語の OpenAI image generation API verification guide が次の読み先です。
7つ目は 1回の request に変化を詰め込みすぎること。preservation-heavy task では、巨大な compound prompt は失敗原因を見えにくくします。composition なのか preservation なのか wording なのか mask なのかが分からなくなるからです。1つの edit、その後に1つの follow-up correction のほうが、今でも cleaner な production habit です。
FAQ
今 edit に使うなら gpt-image-1 と gpt-image-1.5 のどちらですか。
新しい direct edit work なら gpt-image-1.5 です。2026年3月23日時点で current GPT Image 1.5 page はこれを latest image generation model としています。gpt-image-1 は older workflow の維持や比較に残すものです。
なぜ mask edit が masked area より広く変わるのですか。
GPT Image edits が guided semantic rewrites だからです。OpenAI の current guide は final image 全体を記述するよう求めており、community threads でも hard-boundary inpainting を期待した users が broader rerenders を経験しています。
すべての edit で input_fidelity=high が必要ですか。
必要ありません。顔、logo、product geometry、camera angle など、重要な visual identity を保つ必要がある時だけ使います。もっと generative な task なら、常に high にする理由はありません。
いつ Images API から Responses に移るべきですか。
edit が multi-turn conversation、assistant workflow、tool-using product の一部になった時です。画像編集そのものが ship したい feature なら、direct Images API のままでいるほうが自然です。
最終結論
現在の clean rule はこれです。OpenAI API で画像編集をするなら、まず images.edit() と gpt-image-1.5 から始めてください。mask はモデルの注目位置を導くために使いますが、prompt は常に final image 全体を指定するつもりで書くべきです。input_fidelity=high は preservation が仕事そのものになっている時だけ追加し、すべての request の default にしないことです。
page one がまだ十分に解いていないのはここです。勝ち筋の答えは “OpenAI は画像編集できる” ではなく、“direct edit path はどれか、alternate route に移るタイミングはいつか、そして mask が何を保証しないか” です。
より広い API surface が必要なら OpenAI Image API tutorial を読んでください。次に必要なのが working generation examples なら OpenAI image generation API example が自然な続きです。