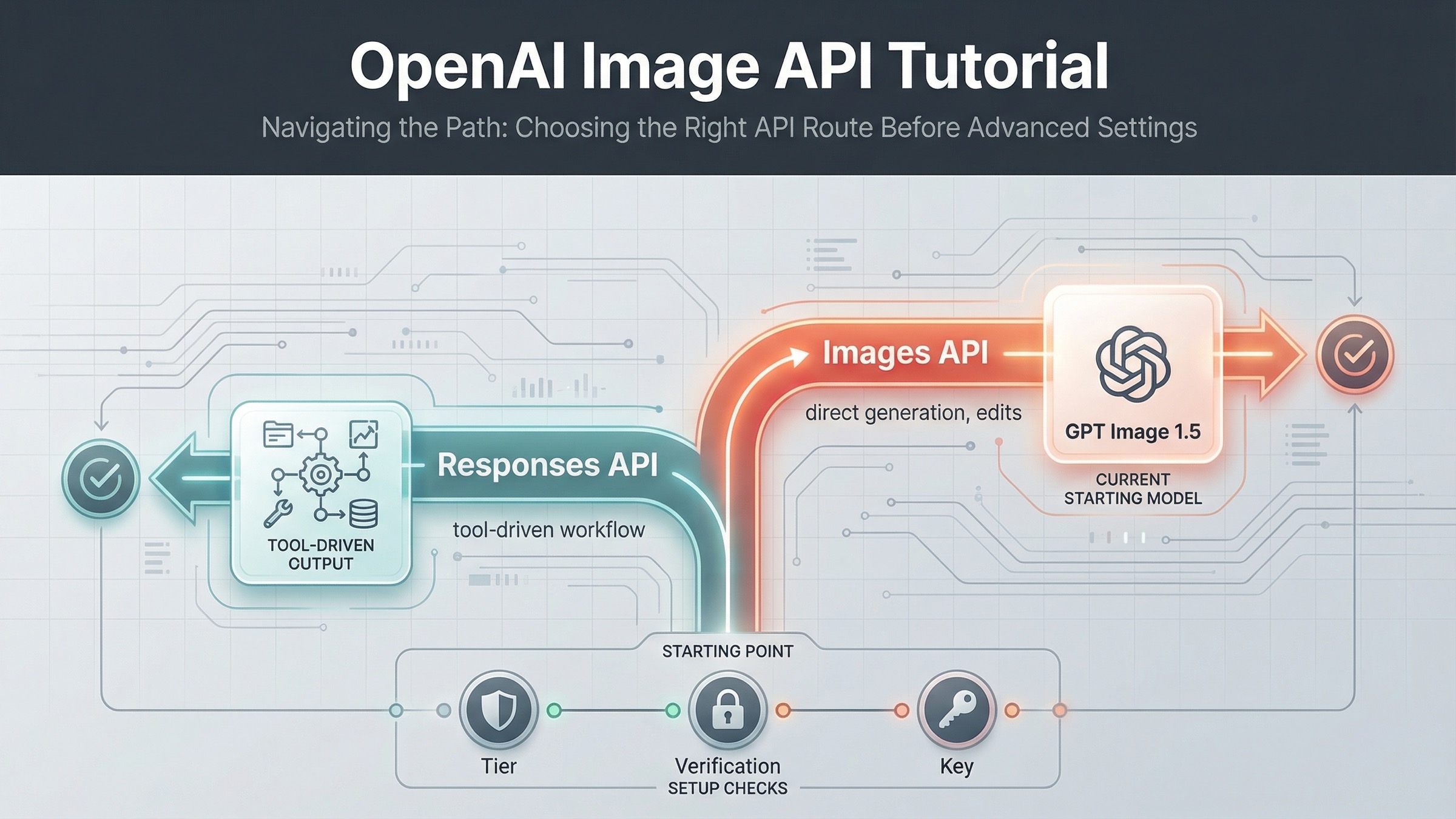
2026 年 3 月 22 日時点で、いちばん安全な初期ルートはこうです。直接画像を生成したい、または既存画像を編集したいならまず Images API を使う。画像生成が larger multimodal workflow の一部なら Responses API を使う。 この判断を先に置くだけで、かなり多くの遠回りを防げます。
この keyword がややこしく見えるのは、OpenAI が必要な情報を複数のページに分けているからです。主 image generation guide は direct generation と edits を説明します。広い images and vision guide は Responses API の image_generation tool を見せます。現在の models catalog は、GPT Image 1.5 が current flagship、gpt-image-1-mini が budget lane、chatgpt-image-latest が ChatGPT alias、DALL-E 3 が deprecated だと整理しています。1 ページだけ読むと、route 全体が見えません。
だから多くの tutorials は、コードは合っていても順序が悪いのです。古い DALL-E 前提のまま始めたり、usage tier や organization verification を確認しないまま SDK 側だけ触ったりします。この記事では、その順序を実務向けに組み直します。
要点まとめ
- direct generation / single-step edits / 最短 onboarding なら Images API。
- 画像生成が assistant workflow の 1 tool なら Responses API。
- デフォルトの current model は
gpt-image-1.5。cost-first のときだけgpt-image-1-miniを基準比較する。 - サンプルが正しく見えても失敗するなら、まず tier、verification、active org、API key を確認する。
まず route を決める:Images API か Responses API か
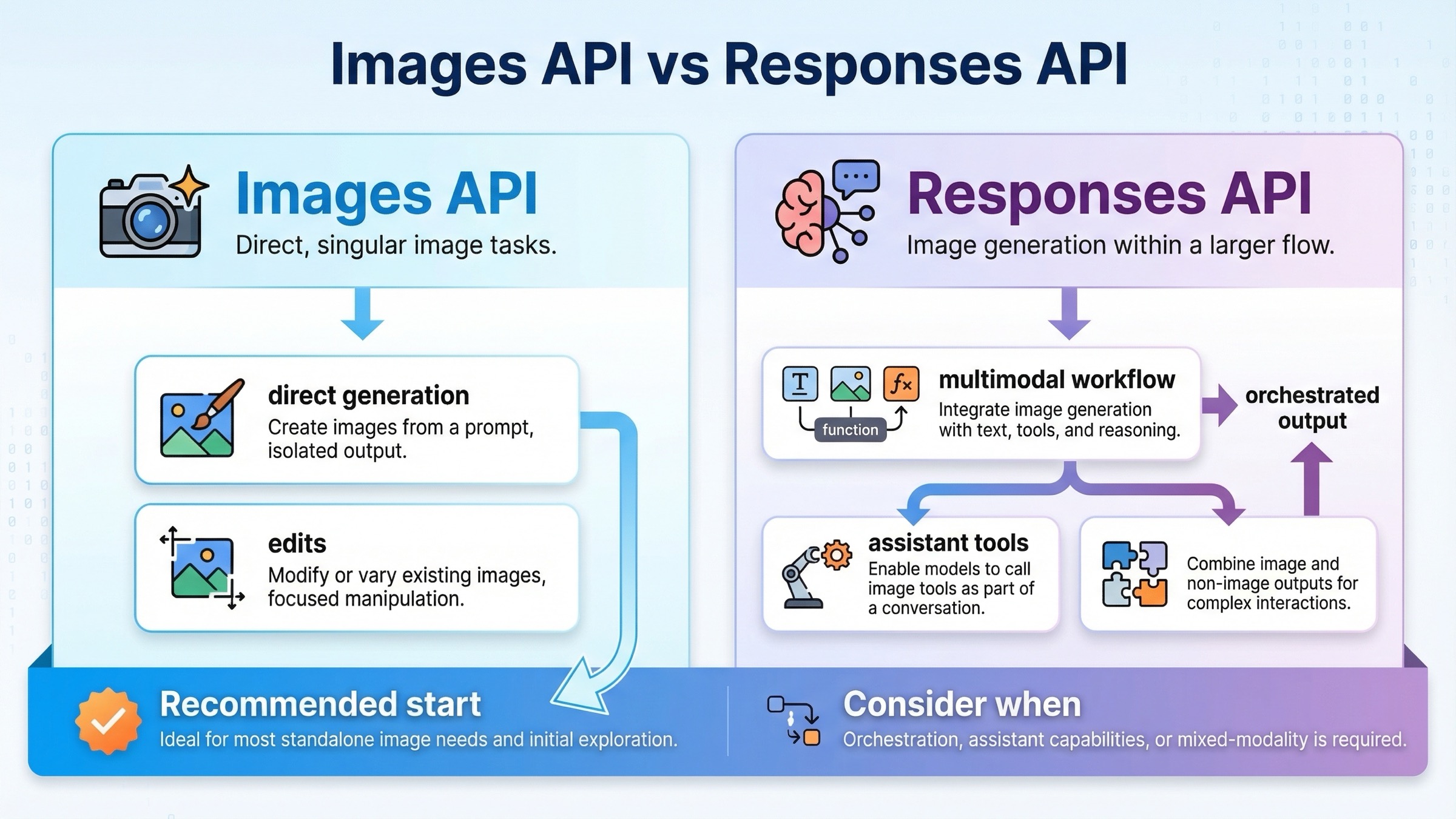
このテーマでは、どの parameter を先に覚えるかより、どの API surface から始めるかの方が重要です。
| 状況 | 先に選ぶべきルート | 理由 |
|---|---|---|
| 1 回の request で画像を作って保存したい | Images API | 最短で、tutorial としても理解しやすい |
| 既存画像を編集したい | Images API | edit、mask、input_fidelity の説明がここにまとまっている |
| 画像生成が text や tools と一緒に流れる | Responses API | image generation を tool として組み込める |
| まずチームで working sample を通したい | Images API | 抽象が少なく、初手の失敗原因が切り分けやすい |
| assistant や agent の一部として画像を返したい | Responses API | larger workflow に自然に入る |
実務ルールは明快です。画像生成そのものが機能なら client.images.generate() / client.images.edit() を使う。画像生成が larger flow の一部なら client.responses.create() に切り替える。
公式 docs もこの分岐自体は示していますが、別々のページに分かれています。reference としては十分でも、tutorial intent に対しては不親切です。だから本文でも parameter に入る前に route を固定します。
コードより先に access と model ID を確認する
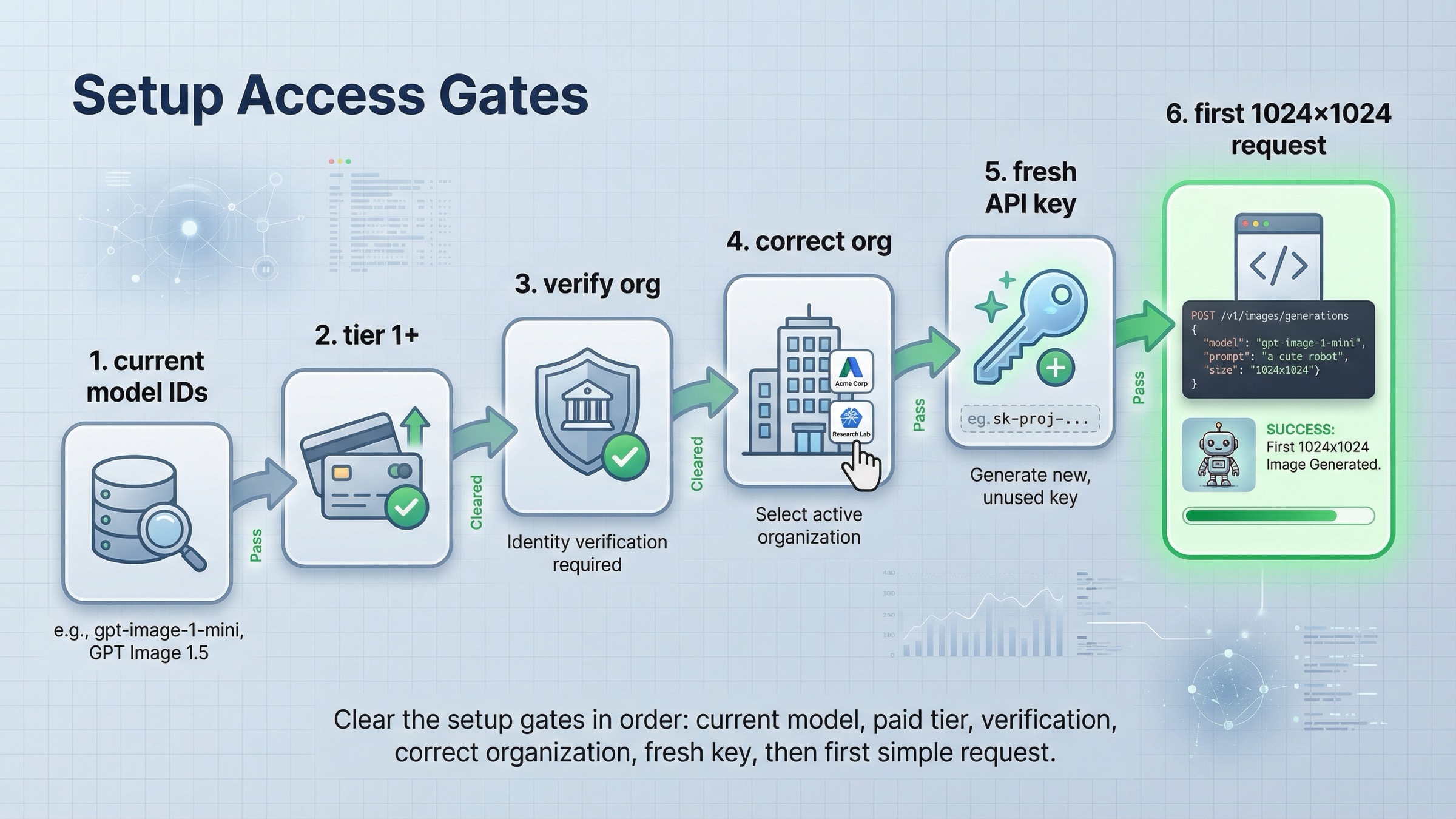
この query でいちばん時間を失いやすいのは、コードが悪いと思い込んで setup gate を後回しにすることです。
まず current model IDs を確認します。現行の OpenAI image family はおおむね次の整理で考えると分かりやすいです。
| モデル | 今の位置づけ | 使いどころ |
|---|---|---|
| GPT Image 1.5 | current flagship | 新規プロジェクト、quality-first、edits、より安定した prompt following |
gpt-image-1-mini | budget lane | cheap tests、prototypes、volume-first |
chatgpt-image-latest | ChatGPT alias | ChatGPT の current image snapshot を意図的に使いたいとき |
| GPT Image 1 | previous model | legacy compatibility や migration reference |
| DALL-E 3 / DALL-E 2 | deprecated | fresh tutorial のデフォルトにしない |
この整理が必要なのは、検索結果にまだ古い pages が混ざるからです。GPT Image 1 や DALL-E 3 を主語にした tutorial をそのまま current default にすると、最初から route がずれます。
次に access。現行の API Model Availability by Usage Tier and Verification Status は、GPT-image-1 と GPT-image-1-mini が tiers 1 through 5 の API users に開かれ、一部 access は organization verification に依存すると書いています。さらに current GPT Image 1.5 page は Free not supported とし、Tier 1 は 100,000 TPM / 5 IPM からだと示しています。つまり tutorial failure は code の前に起こり得ます。
もし verification が怪しいなら、prompt をいじる前に current API Organization Verification を見てください。OpenAI は、正しい organization を確認し、最大 30 分待ち、新しい API key を作り、session を更新してから再試行すると案内しています。これは code branch ではなく access branch です。
SDK install 自体はシンプルです。
bashnpm install openai
bashpip install openai
そのうえで OPENAI_API_KEY を設定し、最初の request はできるだけ boring に保ちます。1024x1024、短い prompt、single image、edit なし。 現在の guide でも square image が default で最も速い starting point だと明示されています。
Images API で最初の 1 枚を通す
direct tutorial として最初に見せるなら、Images API がいちばん分かりやすいです。model choice、output settings、save flow が 1 本でつながるからです。
JavaScript の最小例はこうです。
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.generate({ model: "gpt-image-1.5", prompt: "Create a clean editorial illustration of a robot camera operator in a bright studio", size: "1024x1024", quality: "medium", output_format: "jpeg", output_compression: 80, }); const imageBase64 = result.data[0].b64_json; const imageBytes = Buffer.from(imageBase64, "base64"); fs.writeFileSync("openai-image-api-demo.jpg", imageBytes);
Python もほぼ同じです。
pythonfrom openai import OpenAI import base64 client = OpenAI() result = client.images.generate( model="gpt-image-1.5", prompt="Create a clean editorial illustration of a robot camera operator in a bright studio", size="1024x1024", quality="medium", output_format="jpeg", output_compression=80, ) image_base64 = result.data[0].b64_json image_bytes = base64.b64decode(image_base64) with open("openai-image-api-demo.jpg", "wb") as f: f.write(image_bytes)
この path が良いのは、current flagship model を明示し、safe default の size / quality で始め、base64 output の扱いまでその場で完結するからです。
そこから edits に進めます。current guide は multi-image edit と input_fidelity も示しています。入力画像への近さをより保ちたいなら、input_fidelity: "high" が今いちばん覚える価値のある option の 1 つです。
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const result = await client.images.edit({ model: "gpt-image-1.5", image: [ fs.createReadStream("woman.jpg"), fs.createReadStream("logo.png"), ], prompt: "Add the logo to the woman's jacket as if stitched into the fabric.", input_fidelity: "high", }); const imageBase64 = result.data[0].b64_json; fs.writeFileSync( "woman-with-logo.png", Buffer.from(imageBase64, "base64") );
大事なのは、最初の direct generation が安定してから edit に進むことです。初手から edit、transparency、複数入力、large aspect ratio を同時に持ち込むと、何が失敗原因なのか分からなくなります。
Responses API を選ぶべき場面
Responses API は「より新しいから最初に使う」ものではありません。画像生成が larger reasoning flow の一部であるときにこそ価値が出ます。だから current docs でも responses.create() の中に image_generation tool を置く例が使われています。
JavaScript の official pattern は次のような形です。
jsimport fs from "fs"; import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY, }); const response = await client.responses.create({ model: "gpt-5", input: "Draw a transparent sticker-style icon of a paper airplane for a travel app", tools: [ { type: "image_generation", background: "transparent", quality: "high", }, ], }); const imageBase64 = response.output .filter((item) => item.type === "image_generation_call") .map((item) => item.result)[0]; fs.writeFileSync("paper-airplane.png", Buffer.from(imageBase64, "base64"));
Python でも同じ発想です。
pythonfrom openai import OpenAI import base64 client = OpenAI() response = client.responses.create( model="gpt-4.1-mini", input="Generate a product hero image of a ceramic mug on a white background", tools=[{"type": "image_generation"}], ) image_data = [ output.result for output in response.output if output.type == "image_generation_call" ] if image_data: with open("mug.png", "wb") as f: f.write(base64.b64decode(image_data[0]))
この route が向いているのは、text、tools、images を 1 つの assistant flow にまとめたいときです。逆に、「1 枚作って保存する」だけなら、Responses API は tutorial としての初速を遅くします。
日付面でも 1 つ押さえるべき点があります。OpenAI changelog では、2025 年 12 月 19 日に gpt-image-1.5 と chatgpt-image-latest が Responses API の image generation tool に追加されたと書かれています。つまり、launch 当時の “coming soon” 記述をそのまま current guidance に持ち込むべきではありません。
結果とコストを変える設定
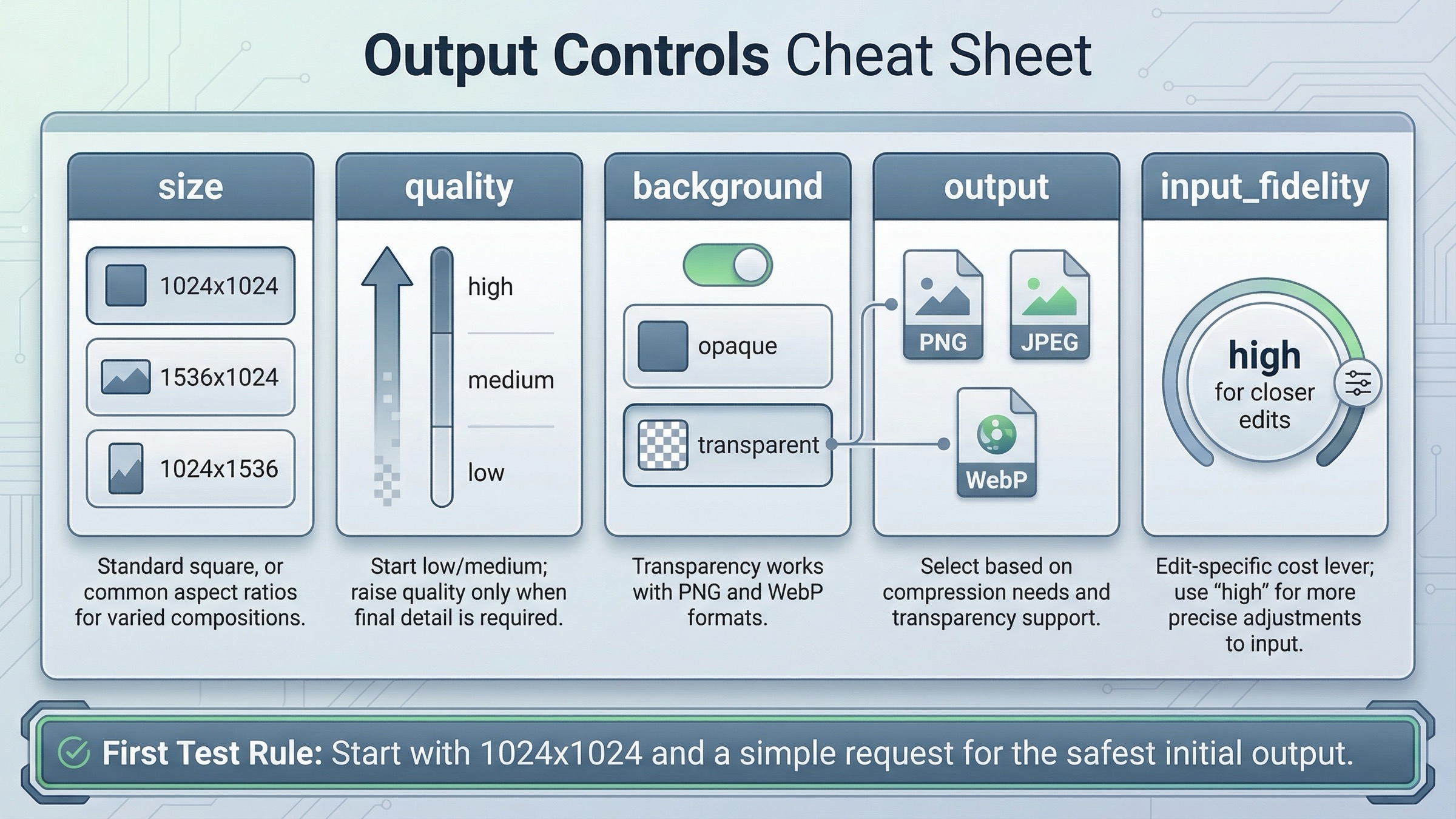
最初の request が通った後は、全部の advanced option を一気に触るより、どの設定が何を変えるかを把握する方が価値があります。
current guide で特に重要なのは次のグループです。
sizequalitybackgroundoutput_formatoutput_compressioninput_fidelity
覚え方は簡単で、「どの decision を変えるか」で見ることです。
Size は composition と cost を変えます。最初は 1024x1024 に固定するのが安全です。現在の guide でも、square image が default で fastest starting point だとされています。
Quality は latency と spend を変えます。current GPT Image 1.5 page では 1024x1024 low が $0.009、medium が $0.034、high が $0.133 です。prototype や smoke test の段階で high を default にする理由は薄いです。
Background は transparent asset を作るときに意味を持ちます。current docs では background: "transparent" が PNG と WebP で有効だと説明されています。ここを知らずに transparency issue を model quality と誤解するケースは多いです。
Output format と compression は delivery shape の選択です。Image API は base64-encoded image data を返し、default format は PNG。必要なら JPEG や WebP を使えます。latency が優先なら JPEG の方が practical な場面も多いです。
input_fidelity は edit-specific lever です。closer edit を優先するときに重要ですが、first request に持ち込むには情報量が多すぎます。だから tutorial でも後半で扱う方が自然です。
運用上の原則は 1 つです。1 回に 1 つの変数だけ変える。 model、size、quality、background、edit inputs を同時に変えると、結果の改善も失敗原因も読めなくなります。
もし次の関心が “どう動かすか” ではなく “scale 時にいくらかかるか” に移っているなら、次は日本語版の OpenAI Image Generation API の価格ガイド の方が役に立ちます。
多くの tutorials が先に教えない failure branch
この topic で時間を失いやすいのは syntax ではなく diagnosis order です。happy path だけ見せる tutorials だと、失敗したときにどこから疑うべきかが残りません。
まず 403 verification error。エラーが organization verification を明示しているなら、prompt や SDK version を変える前に access branch を確認します。OpenAI の current help-center guidance は、正しい organization、最大 30 分の待機、新しい API key、session refresh の順を勧めています。Community threads には、dashboard では verified なのに Images Playground がまだ block する例が複数あります。これは code failure ではなく context failure です。
次に funded に見えるのに 429。これは本当に多い誤判定です。OpenAI Developer Community では、credits を入れても rate_limit_exceeded が出る image model threads が確認できます。ここで見るべきなのは visible balance ではなく usage tier です。
さらに edit と mask の条件。current guide は、edit image と mask が 同じ format、同じ size、50MB 未満であることを明示しています。ここを外すと edit path が random に見えます。
もう 1 つの silent failure は、古い URL-oriented mental model です。current GPT Image route は base64 image data を中心に扱います。古い tutorial のまま hosted URL を前提に downstream logic を組むと、request が成功しても後工程で混乱します。
問題が自分の request だけに見えないなら OpenAI Status を先に確認してください。2026 年 3 月 22 日時点の public status は正常です。つまり今日の local failure は global incident より account / config 側を先に疑う方が妥当です。
verification そのものが main blocker なら、続きは日本語版の OpenAI Image API の認証エラー対策 の方が深く役立ちます。
本番前チェックリスト
最初の request が通ったあとにやるべきなのは、必要な decision を固定することです。
- route を固定する。 direct generation / edits は Images API に残す。画像生成が larger flow の一部なら Responses API に移る。
- model を固定する。
まず GPT Image 1.5。cost-first branch として
gpt-image-1-miniを別に比較する。 - default output profile を決める。 size、quality、format を 1 つ決めてから options を増やす。
- failure context を記録する。 active org、model ID、endpoint、failure type を残す。
- tutorial success と budget success を分ける。 1 回動いたことと、scale で妥当なことは別です。
次に読む価値が高いのは次の 4 本です。
- OpenAI Image Generation API の価格ガイド
- OpenAI Image API の認証エラー対策
- English fallback: How to get an OpenAI API key
- English fallback: OpenAI API key requirements
要するに、現在の OpenAI Image API チュートリアルで一番大切なのは、コードを増やすことではなく、正しい API route、current model IDs、access gates の順に整理することです。 この順番さえ守れば、topic 全体は検索結果よりずっとシンプルになります。
FAQ
最初に覚えるべきは Images API と Responses API のどちらですか。
direct generation と edits なら Images API です。Responses API は、画像生成が assistant や agent workflow の 1 step になるときに強みが出ます。
fresh tutorial の default model は何ですか。
多くのケースでは gpt-image-1.5 が current default です。cost が第一条件なら、その後で gpt-image-1-mini を比較します。
sample code は正しく見えるのに、なぜ失敗するのですか。
よくある原因は syntax ではなく、usage tier、organization verification、active org、古い API key です。
chatgpt-image-latest はいつ使うべきですか。
ChatGPT の current image snapshot を明示的に使いたいときだけです。長期の production tutorial なら、通常は gpt-image-1.5 の方が扱いやすいです。